
Nvidia GeForce GTX 1080, le premier GPU 16nm en test !



Pascal et Async Compute : du mieux ?
Nous vous en avons déjà parlé à plusieurs reprises, notamment ici, DirectX 12 ou encore Vulkan supportent plusieurs files de commandes, ce qui ouvre la voie à plusieurs types d'optimisations.
A la base de leur moteur, les développeurs créent des Command Queues qui sont des files d'attente dans lesquelles vont prendre place des listes de commandes de rendu qui, sur les API classiques, seront exécutées séquentiellement par le GPU pour créer la représentation 3D de la scène. La 10ème liste de commandes à y prendre place devra toujours attendra que les 9 autres aient été exécutées par le GPU avant d'être traitée. Mais avec les API récentes et leur support du Multi Engine, il est possible d'exploiter plusieurs Command Queues de types graphics, compute ou copy, ce qui permet par exemple de faire traiter certaines tâches en priorité mais aussi en parallèle.
Sur ce point Microsoft et Khronos ont repris exactement la structure qu'AMD avait mise en place avec son API Mantle. Une victoire pour AMD qui a dessiné le Multi Engine en suivant les contours de l'architecture de ses GPU. Son service de marketing technique en a profité pour communiquer énormément sur le sujet en mettant en avant des gains de performances sous la bannière Async Compute ou calcul asynchrone.

Illustration du Multi Engine de DirectX 12. Dans cet exemple extrême les performances progressent de 50%.
Pourquoi un gain de performances ? Imaginez que deux commandes de rendu saturent les unités de calcul, il n'y a aucun intérêt à essayer de les traiter en parallèle par rapport à une exécution en série classique. Par contre si une partie du rendu sature les unités de calcul alors qu'une autre sature l'interface mémoire, l'intérêt de l'exécution concomitante est évident et le gain de performances peut être substantiel. C'est à cette sous-possibilité du Multi Engine qu'AMD fait référence en parlant de l'Async Compute. Une terminologie que nous estimons cependant très mal choisie puisqu'il est possible de traiter deux tâches de manière asynchrone sans que cela ne se fasse en parallèle et inversement.
Comme nous l'avons vu avec Ashes of the Singularity, le premier jeu Direct3D 12 à exploiter cette possibilité, si les Radeon parviennent à en tirer en bénéfice, il n'en est rien pour les GeForce Kepler et Maxwell.
Les Radeon disposent d'un processeur de commande plutôt évolué, associé à des ACE (Asynchronous Compute Engines), capable de prendre en charge automatiquement et efficacement plusieurs files de commandes. Malheureusement, il en va différemment pour les GeForce dont le processeur de commandes ne gère plusieurs files efficacement qu'en mode compute pur. Dès que du rendu 3D est impliqué, cela se complique.
Nvidia explique que les GPU Maxwell sont capables de prendre en charge 32 files dont une peut être de type graphics mais ne peuvent pas gérer automatiquement la répartition des ressources. En d'autres termes, par défaut, ces GPU vont les exécuter en alternance tout en souffrant des commandes de synchronisation. Il est par contre possible de définir statiquement, via un profil de jeu, une répartition de ces ressources. Par exemple : 12 SM peuvent être attribués à un file et 4 à une autre. C'est en pratique peu efficace puisqu'un partage fixe correspond rarement aux charges instantanées traitées par le GPU.
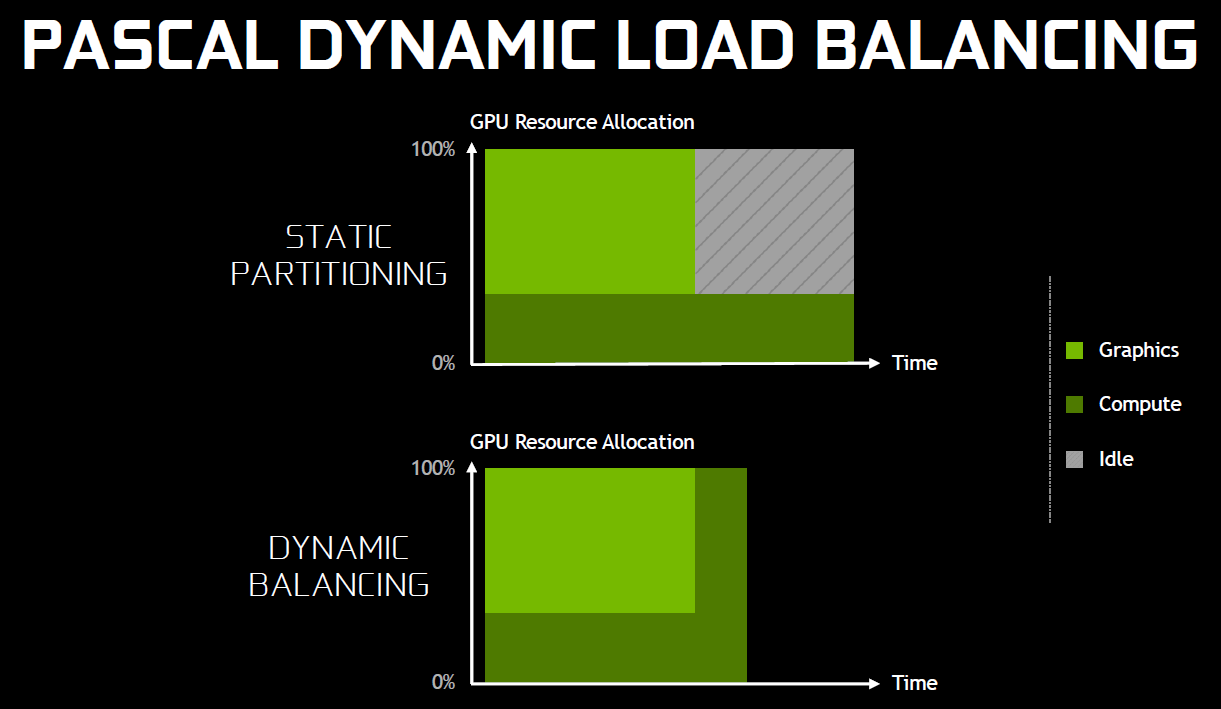
Avec les GPU Pascal, Nvidia a fait évoluer quelque peu son processeur de commande pour permettre au GPU de piloter dynamiquement cette attribution des SM. Une petite évolution dont nous ne sommes pas certains de la portée réelle. Nous n'avons par exemple pas noté de gain dans Ashes of the Singularity. Certes nous pouvons observer que la petite baisse de performance de 1-2% (liée aux commandes de synchronisation qui pilotent "Async Compute"), notée sur Maxwell avec de précédents pilotes, a disparu. Nous pouvons même observer un gain de 1-2% avec certains paramètres graphiques, mais vous conviendrez que c'est loin d'être convainquant.
Nvidia admet que dans ce jeu l'amélioration est anecdotique mais promet que dans d'autres titres à venir des gains plus importants devraient être mesurables. Nous vérifierons bien entendu cela dès que possible.
Ceci étant dit, nous estimons que notre précédente analyse reste d'actualité. Le principe de base sur lequel repose la tentative d'exécution concomitante des tâches est que le GPU n'exploite pas à 100% ses différents types d'unités. Le gain potentiel est donc lié au taux d'utilisation de chaque unité. Plus il est élevé, moins le gain peut être important, d'autant plus qu'avoir recours à l'exécution concomitante implique de mettre en place de coûteuses barrières de synchronisation. Si les GeForce ont de base un meilleur taux d'utilisation de leurs unités que les Radeon, il y a moins de raison de chercher une synergie entre les exécutions de différentes tâches.
Un autre élément à prendre en compte est que l'architecture des GeForce depuis plusieurs générations a décentralisé plusieurs aspects du pipeline graphique qui prennent place dans les SM. C'est le cas du traitement de la géométrie par exemple ou encore du transfert des pixels vers les ROP. Par conséquent, répartir les SM entre deux tâches ne permet pas à l'une d'elle d'exploiter la puissance géométrique ou le fillrate inutilisés par l'autre. Même la puissance de calcul est difficilement attribuable à une tâche donnée. Au vu de son architecture, il nous semble que pour réellement profiter de l'exécution concomitante, les GeForce Pascal devraient exécuter ces multiples tâches à l'intérieur de chaque SM et non leur attribuer un certain nombre de SM entiers, que ce soit dynamiquement ou pas. C'est assez différent pour les Radeon, dont l'architecture semble gérer ces tâches multiples bien plus finement.
La préemption progresse
Un autre aspect d'Async Compute représente la possibilité de traiter des tâches en alternance de manière désynchronisée et éventuellement en priorité. Pour cela, il faut interrompre et mettre en pause le travail en cours du GPU pour passer sur une autre tâche, c'est la préemption.
Cela permet de supporter un environnement multitâche sur GPU, mais également d'exécuter le time warping dans le cadre de la VR. Cette technique consiste pour rappel, juste avant chaque rafraîchissement de l'écran, à déformer la dernière image terminée sur base des informations de positionnement les plus récentes. De quoi simuler le point de vue réel et réduire la latence perçue.
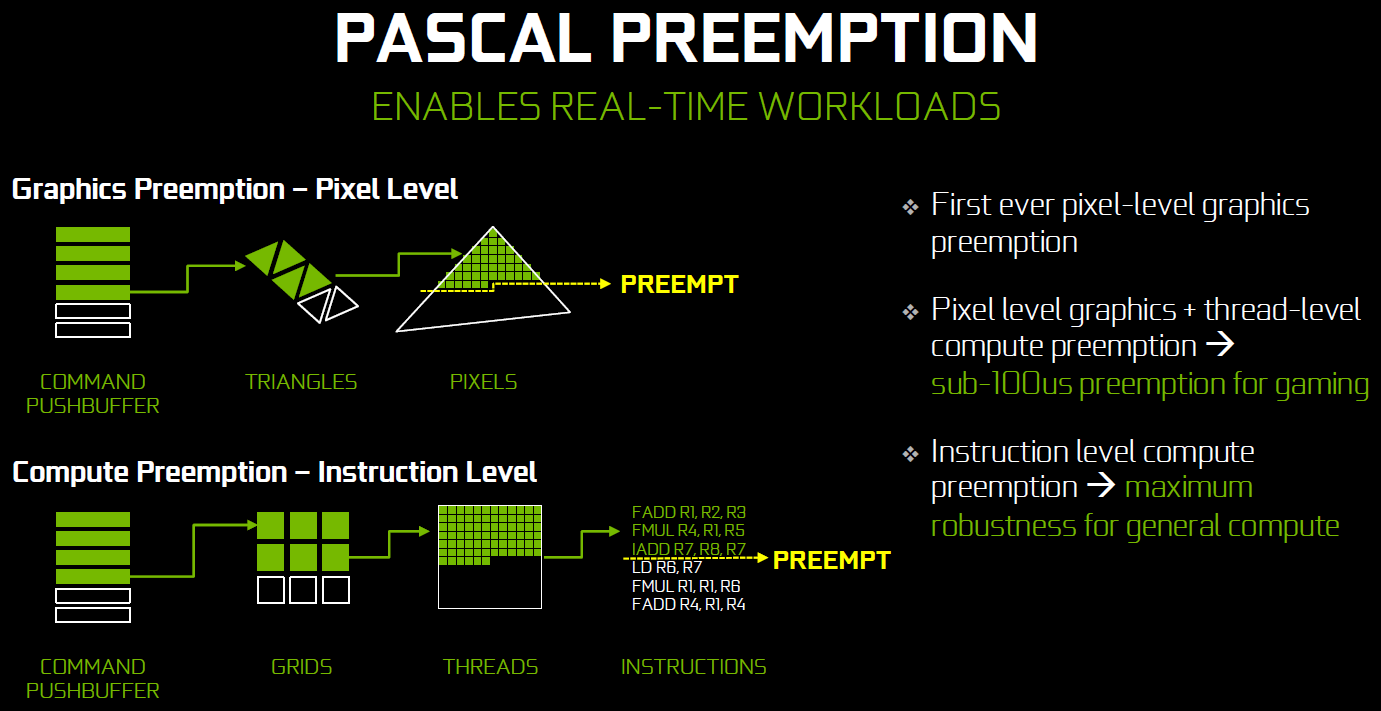
Peu loquace en détails concernant l'exécution concomitante, Nvidia met par contre fortement en avant les améliorations apportées à la préemption qui permet sur Pascal de stopper plus rapidement une tâche en cours pour passer à une autre. Les GPU Pascal peuvent faire de la préemption au niveau du pixel en mode graphics et au niveau du thread en mode compute. Les GPU Maxwell et les Radeon ne peuvent le faire que par triangle par exemple. De quoi réduire quelque peu la latence dans le cadre de la VR et du time warping.

[ Time warping sur Maxwell ] [ et sur Pascal ]
Dans cet exemple, un GPU Pascal ne doit pas lancer la time warping aussi tôt qu'un GPU Maxwell, ce qui augmente les performances et réduit la latence en utilisant des données de positionnement plus récentes.
Rappelons que dans certains cas, un triangle peu représenter un temps de rendu très élevé, notamment lorsqu'une image entière est plaquée sur 1 ou 2 triangles en vue de recevoir un effet de post processing très gourmand. Sur les GPU autres que Pascal, quand le time warping intervient à ce très mauvais moment, il est possible qu'il ne puisse pas être exécuté avant l'affichage à moins de prendre une marge de sécurité énorme.
Nvidia précise par ailleurs que le délai pour le changement de tâches a été réduit à moins de 100 µs une fois la tâche en cours terminée, soit une fois que les pixels ou les threads sur lesquels le GPU a commencé à travailler sont terminés.
En mode CUDA pur, les GPU Pascal peuvent aller plus loin et faire de la préemption au niveau le plus bas possible : celui des instructions. Dans ce cas, dès que la commande est passée, le GPU s'interrompt immédiatement et transfère le tout en mémoire. Bien plus d'informations doivent être conservées, telles que tous les registres de tous les threads en vol, ce qui peut avoir un coût plus important. Une possibilité à ne pas utiliser pour alterner en permanence entre deux tâches par exemple.
2 - GP104 : 7.2 milliards de transistors en 16 nm
3 - Pascal et Async Compute : du mieux ?
4 - Pascal et le SMPE pour la VR et le surround
5 - SLI amélioré, Fast Sync, Moteur vidéo HDR
6 - Spécifications et Direct3D 12
7 - La GeForce GTX 1080 Founders Edition
8 - Protocole de test
9 - Performances théoriques : pixels
10 - Performances théoriques : géométrie
11 - Fermi vs Kepler vs Maxwell vs Pascal
12 - Consommation, efficacité énergétique
13 - Nuisances sonores, températures, photos IR
14 - Benchmark : 3DMark Fire Strike
15 - Benchmark : Anno 2205
16 - Benchmark : Ashes of the Singularity
17 - Benchmark : Battlefield 4
18 - Benchmark : Crysis 3
20 - Benchmark : DOOM
21 - Benchmark : Dying Light
22 - Benchmark : Evolve
23 - Benchmark : Fallout 4
24 - Benchmark : Far Cry Primal
25 - Benchmark : Grand Theft Auto V
26 - Benchmark : Hitman
27 - Benchmark : Project Cars
28 - Benchmark : Rise of the Tomb Raider
29 - Benchmark : Star Wars Battlefront
30 - Benchmark : The Division
31 - Benchmark : The Witcher 3 Wild Hunt
32 - Récapitulatif des performances
33 - GPU Boost : pourquoi ? comment ?
34 - Overclocking : 2 GHz à portée de click
35 - Conclusion
Contenus relatifs
- [+] 26/10: Nvidia pré-annonce les GeForce GTX ...
- [+] 17/10: Destiny 2 de retour chez Nvidia
- [+] 27/09: Nvidia offre Middle Earth: Shadow o...
- [+] 22/08: Destiny 2 de nouveau offert chez Nv...
- [+] 14/06: Destiny 2 pour les GTX 1080 et 1080...
- [+] 31/05: Computex: Nvidia annonce les GTX 10...
- [+] 29/05: Desktop, mobile et en box : la GTX ...
- [+] 25/04: Les GTX 1080 et 1060 ''OC'' disponi...
- [+] 28/03: For Honor ou Ghost Recon en bundle ...
- [+] 01/03: GDC: Nvidia va proposer des GTX 108...