
AMD Radeon R9 290X et R9 290 en test : Hawaii sort ses watts
Publié le 24/10/2013 (Mise à jour le 06/11/2013) par Damien Triolet



Hawaii : l'architecture du GPUComme tous les GPU AMD depuis Tahiti et la Radeon HD 7900, Hawaii est basé sur l'architecture GCN qui a la particularité d'exploiter ses unités vectorielles de façon à ce qu'elles présentent un comportement scalaire plus efficace du point de vue des shaders, ces programmes qui sont exécutés sur la géométrie ou les pixels. Nous avions détaillé cette évolution de l'architecture graphique d'AMD vers GCN lors de sa sortie.
A sa base, cette architecture repose sur des blocs fondamentaux appelés Compute Units (CU) qui intègrent chacun 64 unités de calcul (les "cores" en langage marketing), 4 unités de texturing, des caches et toute la logique de contrôle nécessaire au bon fonctionnement de l'ensemble. Voici résumées les spécifications des 6 GPU GCN actuels :
Oland : 6 CU, 1 triangle par cycle, 8 ROP, L2 256 Ko, 128 bits
Cape Verde : 10 CU, 1 triangle par cycle, 16 ROP, L2 512 Ko, 128 bits
Bonaire : 14 CU, 2 triangles par cycle, 16 ROP, L2 512 Ko, 128 bits
Pitcairn : 20 CU, 2 triangles par cycle, 32 ROP, L2 512 Ko, 256 bits
Tahiti : 32 CU, 2 triangles par cycle, 32 ROP, L2 768 Ko, 384 bits
Hawaii : 44 CU, 4 triangles par cycle, 64 ROP, L2 1024 Ko, 512 bits
Plus en détail, voici les représentations de l'architecture des 4 derniers GPU listés, retravaillées sur base des dernières informations qui vont nous permettre de reparcourir l'architecture GCN avec quelques détails supplémentaires :
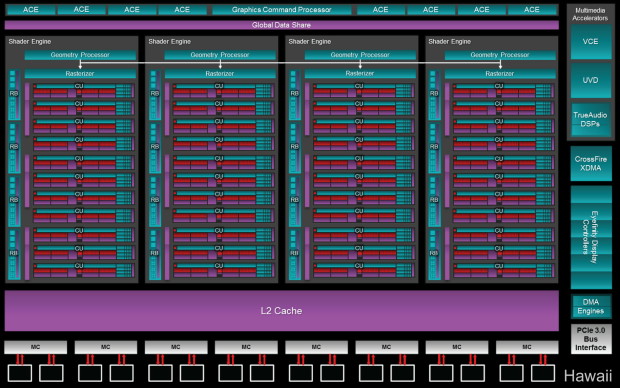
[ Bonaire ] [ Pitcairn ] [ Tahiti ] [ Hawaii ]
Pour les versions plus grandes de ces diagrammes :
Lors de la présentation du GPU Hawaii, nous avons pu en savoir plus sur l'organisation interne des GPU GCN, détails qu'AMD n'avait pas communiqués jusqu'ici et qui rendent les précédents diagrammes d'architecture légèrement incorrects.
AMD introduit le concept de Shader Engine, une structure qui comprend une unité de traitement géométrique ainsi que les blocs d'unités de calcul et de ROP (ou RB, Render Back-ends) qu'elle alimente. Pour certains GPU GCN, vient s'ajouter le concept de Shader Array, des sous-ensembles d'unités de calcul et de ROP présents à l'intérieur d'un Shader Engine. Ces concepts sont bien entendu comme toujours une représentation imaginée et simplifiée de l'architecture, l'implémentation physique étant plus complexe et souvent différente.
La raison de cette subdivision en Shader Engines et en Shader Arrays est liée d'une part à des contraintes physiques (consommation, répartition des points chauds sur la puce etc.) et d'autre part à la volonté de faciliter la distribution équilibrée des différentes tâches, principalement des pixels. Chaque groupe de ROP se voit assigner statiquement un ensemble de petites zones (tiles) de l'image qui est ainsi virtuellement quadrillée. Lorsqu'un triangle est pris en charge par un moteur géométrique, celui-ci doit donc être répliqué dans tous les rasterizers qui correspondent aux zones de l'écran qu'il affecte, ce qui est par exemple le cas de tous les triangles de plus de quelques pixels, raison pour laquelle un bus de communication relie tous les moteurs géométriques entre eux sur ces diagrammes.
En d'autres termes, n'importe quel rasterizer ne peut pas générer des pixels qui correspondent à n'importe quelle zone de l'écran. Et n'importe quel Shader Engine / Shader Array ne peut pas calculer et écrire en mémoire n'importe quel pixel.
Cette approche relativement rigide permet de répartir d'une manière équilibrée les pixels entre les différentes unités de calcul et ROP. Elle impacte directement la possibilité des proposer des versions castrées de ces GPU. Pour conserver cet équilibre, AMD doit ainsi désactiver un nombre de CU proportionnel au nombre de SE/SA. Par exemple il n'est pas possible de créer un GPU Pitcairn avec 18 CU, la version castrée du GPU doit obligatoirement passer à 16 ou 12. Il en va de même pour Tahiti et Hawaii (le nombre de CU passe de 44 à 40 pour la Radeon R9 290). Par contre les CU de Bonaire et Cape Verde peuvent être désactivés par paires alors qu'un seul CU à la fois peut-être désactivé sur Oland, ce qu'AMD a fait pour la Radeon R7 240.
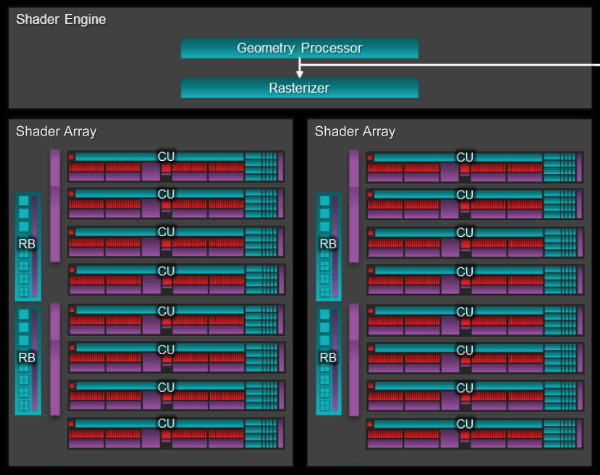
A l'intérieur d'un Shader Engine, peuvent se retrouver un ou deux Shader Arrays, concept qui s'efface dans le premier cas par souci de simplification. A l'intérieur du Shader Array nous retrouvons un certain nombre de Compute Units, de 5 à 11 suivant les designs proposés par AMD, mais nul doute que l'architecture est prévue pour aller au-delà.
À côté des CU, prennent place les mémoires qu'ils se partagent par groupe de 4 maximum (les barres verticales violettes sur les diagrammes) : cache L1 pour les unités scalaires/constantes (K$ 16 Ko) et cache L1 pour les instructions (I$ 32 Ko). Dans le cas de Tahiti illustré ici, avec 8 CU par Shader Array, ceux-ci se regroupent par 4 au niveau de ces petits caches. Dans le cas de Hawaii, avec 11 CU par Shader Engine, le dernier groupe n'est composé que de 3 CU. Pitcairn est le moins efficace au niveau de l'implémentation puisqu'il faut deux ensembles de caches pour seulement 5 CU.
Enfin, tout à gauche, nous retrouvons les partitions de ROP (RB), jusqu'à 4 par Shader Engine. Chaque partition représente 4 ROP capables de prendre en charge et écrire en mémoire jusqu'à 4 couleurs ainsi que 16 valeurs Z, et englobe les différents caches nécessaires à leur fonctionnement optimal. Avec GCN 1.1, soit Bonaire et Hawaii, les performances des ROP ont été revues à la hausse, notamment en HDR FP16, grâce à un regroupement plus intelligent des pixels qui permet de les stocker et de les réordonner jusqu'à 2x plus efficacement. Par ailleurs les ROP sont capables de détecter plus efficacement quand les écritures sont inutiles lors du mélange de pixels de manière à pouvoir les éviter et économiser de la bande passante mémoire. AMD nous indique par ailleurs que ces deux optimisations permettent également d'économiser de l'énergie au niveau des ROP, ce qui a probablement participé à permettre de doubler leur nombre entre Tahiti et Hawaii.
Alors que les ROP sont connectés directement aux contrôleurs mémoire puisqu'ils intègrent déjà un cache hyper spécialisé, les CU, via toutes leurs voies de lectures/écritures, sont connectés au cache L2 qui passe à 1 Mo sur Hawaii. C'est 33% de plus que pour Tahiti, au niveau de sa taille mais également au niveau de la bande passante interne qui y est proportionnelle. Entre les différents L1 et le cache L2 de Hawaii, la bande passante combinée peut ainsi atteindre 1 To/s. Le tout alimente ensuite le bus mémoire de 512-bit.
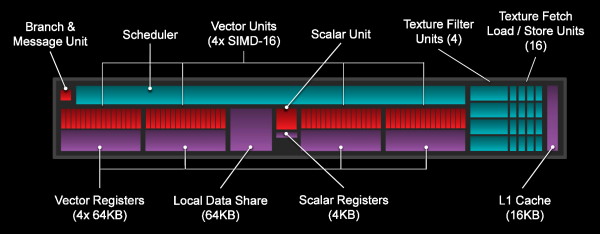
Au cur de chaque CU, nous retrouvons les 4 unités vectorielles 16D (SIMD) qui forment les 64 "cores" mis en avant par le marketing. Chaque SIMD dispose d'un fichier registres dédié de 64 Ko et chacune de ses lignes d'exécution est capable d'effectuer une opération de type FMA 32-bit par cycle (2 flops). Les instructions complexes sont traitées en plusieurs cycles par les SIMD, contrairement à l'architecture Nvidia qui dispose d'unités dédiées.
Ces SIMD sont capables de traiter les opérations en double précision (64-bit) en 16 cycles soit à 1/16ème de leur débit classique. AMD a cependant la possibilité d'augmenter ce débit en complexifiant ses unités de calcul. Tahiti est ainsi passé à un débit de 1/4 alors que Hawaii dans sa version R9 290X se contente de 1/8ème sans que nous ne sachions avec certitude s'il s'agit du maximum dont est capable le GPU ou s'il a été bridé pour donner un avantage sur ce point à sa version FirePro.
Toute la logique de contrôle est intégrée au niveau du CU ainsi que 64 Ko de mémoire partagée (LDS, Local Data Share) et un ensemble de 4 unités de texturing et 16 unités de lectures/écritures qui leur sont liées. Celles-ci accèdent à la mémoire externe via un cache L1 de 16 Ko.
Pour les GPU GCN 1.1, les CU ont été mis à jour pour intégrer la mémoire partagée dans un espace mémoire unifié (flat addressing), évolution nécessaire pour la HSA qui facilitera notamment le travail des compilateurs dans le cadre du GPU Computing. Seconde petite évolution : AMD a amélioré la précision des instructions natives LOG et EXP, ce qui devrait permettre de les privilégier dans plus de cas par rapport aux macros moins performantes (pour le détail, la précision passe à 1 ULP).

Si nous revenons à un niveau plus élevé de l'architecture, Hawaii est le premier GPU AMD à disposer de 4 processeurs géométriques, ce qui veut dire qu'il peut prendre en charge jusqu'à 4 primitives (triangles, lignes, points) par cycle. L'unité de tessellation étant présente à ce niveau (elle est distribuée dans les ensembles d'unités de calcul chez Nvidia), la capacité de Hawaii à générer des triangles est également doublée par rapport à Bonaire/Pitcairn/Tahiti.
Pour rappel, lorsque la quantité de triangles et données associées qui sont générés est élevée, ils doivent être dirigés vers la mémoire vidéo, ce qui est moins efficace que de tout garder à l'intérieur du GPU mais permet d'éviter d'engorger celui-ci à un point tel qu'il serait totalement paralysé. Pour gagner en efficacité dans certains cas, AMD indique avoir apporté quelques optimisations au niveau du buffer utilisé pour le transfert en mémoire vidéo du flux de données généré par la tessellation. Par ailleurs, pour éviter d'y avoir recours autant que possible, la mémoire partagée peut être exploitée d'une manière plus flexible en tant que cache pour les données géométriques. Compte tenu du gain que nous avons observé sur tous les GPU GCN avec les pilotes récents, nous supposons que ce dernier point est une évolution logicielle qui n'est pas spécifique à Hawaii.
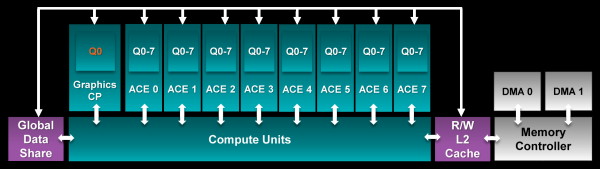
Bien qu'AMD ne mette que très peu en avant ce point, ou tout du moins évite d'en parler, Bonaire et Hawaii introduisent une légère évolution de l'architecture GCN que nous qualifions de 1.1. En plus de petits détails décrits ci-dessus, ces évolutions concernent principalement le processeur de commande du GPU et sont destinées au GPU Computing et à la HSA (Heterogeneous System Architecture).
Parmi ces évolutions, notons le support de 8 files d'attente par compute pipeline (ACE, Asynchronous Compute Engine), ce qui va dans le sens de la technologie Hyper Q de Nvidia réservée aux Tesla K20 et permet de mieux alimenter le GPU en évitant que lors de dépendances entre kernels (programmes à exécuter), le GPU ne se retrouver bloqué en attendant le résultat de l'un d'eux. Ainsi, les 2 ACE de Bonaire permettent de supporter jusqu'à 16 files d'attente alors que Hawaii passe, comme les GPU intégrés aux APU des PS4 et Xbox One, à 8 ACE et donc à 64 files d'attente. De quoi autoriser un gain d'efficacité significatif du GPU Computing où de nombreuses petites tâches doivent être traitées, ce qui revient à rendre son utilisation envisageable en pratique dans plus de cas.
Un adressage mémoire unifié est également au programme et de nouvelles instructions font leur apparition dont certaines dédiées au débogage du code. Vous pourrez retrouver un extrait du document qui détaille l'évolution du jeu d'instruction (mais qui a été retiré par AMD le temps d'en corriger certaines notations qui étaient peu claires au niveau du nom des différentes architectures) dans le dossier que nous avions consacré à Bonaire il y a 6 mois de cela.
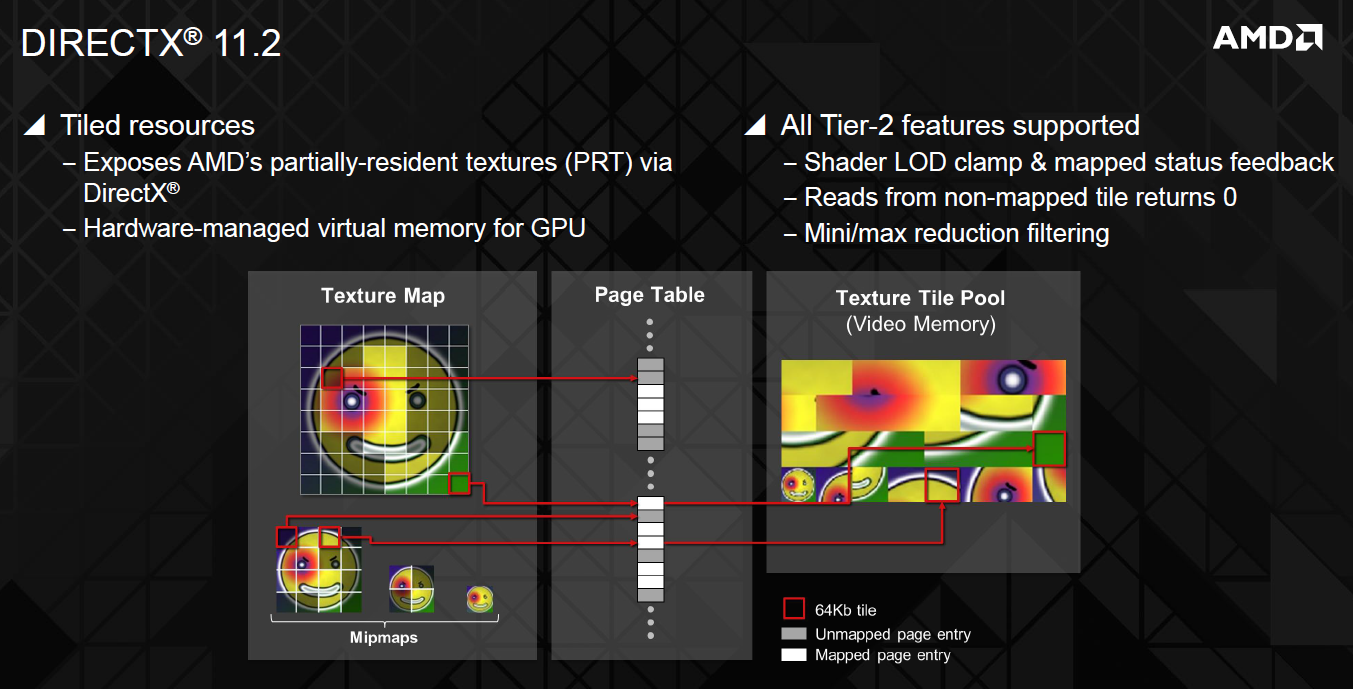
La dernière nouveauté se situe au niveau du support complet (Tier2) d'une fonctionnalité optionnelle de DirectX 11.2 : les Tiled Resources, sujet que nous avons déjà évoqué. Rappelons que DirectX 11.2, ou plutôt Direct3D 11.2, n'introduit que de petites nouveautés optionnelles pour les niveaux matériels 11_0 et 11_1 et qu'aucun niveau matériel 11_2 n'existe au grand dam des fabricants de GPU qui ont l'habitude d'essayer de mettre en avant ce point.
Parler de GPU de génération DirectX 11.2 est donc un non-sens dont ne manqueront cependant pas d'abuser certains acteurs de l'industrie. Support complet des tiled resources ou pas, Bonaire et Hawaii ne sont en réalité pas plus DirectX 11.2 qu'une Radeon R9 280X, qu'une Radeon HD 7000, qu'une GeForce GTX 700 ou qu'une Radeon HD 3000 !
Sommaire
1 - Introduction
2 - Hawaii : l'architecture du GPU
3 - TrueAudio
4 - Powertune évolue
5 - CrossFire et Eyefinity aussi
6 - Performances théoriques : pixels
7 - Performances théoriques : géométrie
8 - Spécifications, la Radeon R9 290X de référence
9 - La Radeon R9 290 de référence
10 - Consommation
11 - Bruit et températures
12 - PowerTune en pratique
13 - Protocole de test
14 - Benchmark : Alan Wake
15 - Benchmark : Anno 2070
16 - Benchmark : Batman Arkham Origins
2 - Hawaii : l'architecture du GPU
3 - TrueAudio
4 - Powertune évolue
5 - CrossFire et Eyefinity aussi
6 - Performances théoriques : pixels
7 - Performances théoriques : géométrie
8 - Spécifications, la Radeon R9 290X de référence
9 - La Radeon R9 290 de référence
10 - Consommation
11 - Bruit et températures
12 - PowerTune en pratique
13 - Protocole de test
14 - Benchmark : Alan Wake
15 - Benchmark : Anno 2070
16 - Benchmark : Batman Arkham Origins
17 - Benchmark : Battlefield 3
18 - Benchmark : Battlefield 4
19 - Benchmark : BioShock Infinite
20 - Benchmark : Crysis 3
21 - Benchmark : Far Cry 3
22 - Benchmark : GRID 2
23 - Benchmark : Hitman Absolution
24 - Benchmark : Max Payne 3
25 - Benchmark : Metro Last Light
26 - Benchmark : Sleeping Dogs
27 - Benchmark : Splinter Cell Blacklist
28 - Benchmark : Tomb Raider
29 - Récapitulatif des performances
30 - Trop de variabilité ?
31 - Conclusion
18 - Benchmark : Battlefield 4
19 - Benchmark : BioShock Infinite
20 - Benchmark : Crysis 3
21 - Benchmark : Far Cry 3
22 - Benchmark : GRID 2
23 - Benchmark : Hitman Absolution
24 - Benchmark : Max Payne 3
25 - Benchmark : Metro Last Light
26 - Benchmark : Sleeping Dogs
27 - Benchmark : Splinter Cell Blacklist
28 - Benchmark : Tomb Raider
29 - Récapitulatif des performances
30 - Trop de variabilité ?
31 - Conclusion
Vos réactions
Contenus relatifs
- [+] 15/04: La FirePro W9100 passe à 32 Go
- [+] 09/07: AMD lance la FirePro S9170: Hawaii ...
- [+] 23/06: MSI Radeon R9 390X Gaming 8 Go en t...
- [+] 18/06: AMD lance les Radeon R300 : vaste r...
- [+] 01/06: DiRT Rally offert avec les Radeon R...
- [+] 04/02: Nouvelles versions des R9 290(X) Tr...
- [+] 28/01: Sapphire passe la R9 290X Tri-X à 8...
- [+] 07/11: 8 Go sur R9 290X chez Sapphire et X...
- [+] 06/11: R9 290X Gaming 8 Go chez MSI
- [+] 06/11: Civ Beyond Earth offert avec les GP...