
AMD Radeon HD 7970 & CrossFireX en test : 28nm et GCN
Publié le 22/12/2011 (Mise à jour le 24/12/2011) par Damien Triolet



GCN : l'abandon du VLIWDepuis les Radeon 9700 Pro, AMD utilise une architecture VLIW, qui a évolué progressivement pour atteindre un niveau de flexibilité très élevé sur les dernières générations. VLIW, ou Very Long Instruction Word, consiste à exécuter des instructions complexes, qui sont en réalité l'assemblage d'une série d'instructions plus simples. C'est ce que nous décrivions comme comportement vectoriel pour les Radeon (vec4 ou vec5), en opposition au comportement scalaire des GeForce : pour chaque pixel, par exemple, 5 instructions pouvaient être exécutées de front. Un modèle issu de l'évolution naturelle des GPU dont la tâche de base consiste à calculer des couleurs (4 composantes : rouge, vert, bleu et transparence) et des coordonnées (3 ou 4 composantes). Exécuter 5 instructions de front permettait de profiter du parallélisme naturel entre ces composantes en laissant un peu de place pour les quelques opérations scalaires à traiter.
Cypress, le GPU d'une Radeon HD 5800, embarque des CU qui contiennent chacun une grosse unité de calcul SIMD capable d'exécuter chaque cycle 5 instructions de front sur 16 éléments (pixels, vertices, threads ). Avec Cayman, le GPU des Radeon HD 6900, AMD a simplifié quelque peu ce modèle pour revenir à une unité SIMD plus efficace qui exécute 4 instructions de front, toujours sur 16 éléments. Pour Tahiti et les autres GPU GCN, cette grosse unité est éclatée et devient 4 petites unités SIMD chacune capables d'exécuter une instruction sur 16 éléments.
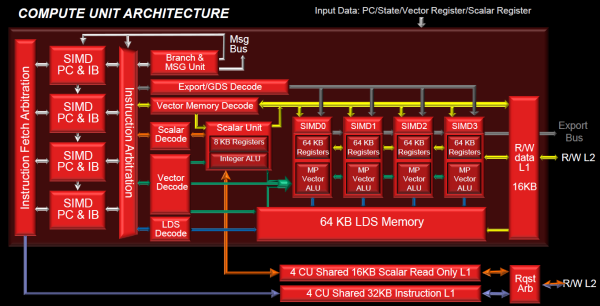
En réalité la grosse unité SIMD de Cayman et les 4 petites unités SIMD de Tahiti sont probablement identiques, seule la manière de les alimenter étant réellement différente. Du côté des Radeon, tous les éléments à traiter sont organisés en groupes de 64, appelés wavefront. Des groupes qui sont plus gros que la longueur des unités SIMD (16) pour simplifier le travail des schedulers et s'accomoder plus facilement de la latence des unités de calcul.
Dans le cas de Cayman, un de ces groupes sera donc traité en 4 cycles avec jusqu'à 4 instructions en parallèle. Pour Tahiti, c'est une seule instruction mais sur 4 wavefronts qui sera traitée tous les 4 cycles. Tahiti doit donc pouvoir jongler avec beaucoup plus d'éléments en même temps : au moins 256. Un chiffre à comparer à 128 et non 64 pour Cayman : avec une latence de 8 cycles pour les unités de calcul, chaque CU de Cayman doit jongler en permanence avec 2 wavefronts. Avec Tahiti et GCN AMD a ramené la latence des unités de calcul à 4 cycles pour éviter de faire exploser le nombre d'éléments en vol requis pour utiliser toutes les unités de calcul. Ils sont au final doublés, ce qui reste raisonnable.

Notez enfin une petite subtilité : si Cayman peut exécuter directement une instruction sur toutes ses unités de calcul, ce n'est pas le cas pour Tahiti. Le scheduler présent dans chaque CU peut ordonner l'exécution d'une instruction à une seule SIMD par cycle. Au démarrage, la seconde SIMD perd ainsi 1 cycle, la troisième 2 cycles et la quatrième 3 cycles, ce qui représente une perte de 192 flops. Un chiffre qui est cependant négligeable lorsque les programmes à exécuter sont longs et qui est compensé par la latence plus faible.
En pratique, quelle différence ? Voici quelques exemples, comparant l'architecture VLIW 4 des Radeon HD 6900 (8 cycles de latence, vec4) à l'architecture GCN des Radeon HD 7900 (4 cycles de latence + 3 cycles de "démarrage", scalaire), en supposant que chaque CU est alimenté avec 2 / 4 / 8 groupes de 64 éléments à traiter :
1 instruction scalaire à exécuter :
CU VLIW 4 : 16 / 24 / 40 cycles
CU GCN : 11 / 11 / 15 cycles
100 instructions scalaires à exécuter :
CU VLIW 4 : 408 / 808 / 1608 cycles
CU GCN : 207 / 207 / 407 cycles
1 instruction vec3 à exécuter :
CU VLIW 4 : 16 / 24 / 40 cycles
CU GCN : 19 / 19 / 31 cycles
100 instructions vec3 à exécuter :
CU VLIW 4 : 408 / 808 / 1608 cycles
CU GCN : 607 / 607 / 1207 cycles
1 instruction vec4 à exécuter :
CU VLIW 4 : 16 / 24 / 40 cycles
CU GCN : 23 / 23 / 39 cycles
100 instructions vec4 à exécuter :
CU VLIW 4 : 408 / 808 / 1608 cycles
CU GCN : 807 / 807 / 1607 cycles
Lorsque les CU de l'architecture GCN sont alimentés avec au moins 256 éléments ils sont ainsi toujours plus performants que les CU VLIW 4, avec une différence insignifiante lorsque 4 instructions peuvent être traitées en parallèle mais qui peut monter à près de 4x avec des instructions scalaires exécutées en série ! Lors du rendu 3D nous nous situons en moyenne quelque part entre les résultats en vec3 et vec4. Il faut dire que le compilateur d'AMD est particulièrement performant pour extraire ce parallélisme compte tenu de l'expérience acquise depuis toutes ces années. Sous-alimentée en éléments à traiter, les CU GCN peuvent par contre être moins performantes.

L'intérêt de cette nouvelle organisation se retrouvera principalement du côté compute où le code peut se prêter moins bien à la vectorisation que le rendu 3D. Ce dernier en profitera cependant progressivement, son évolution faisant qu'il se détache de plus en plus du traitement des couleurs et de positions qui se vectorisent facilement. GCN permettra également à AMD de passer moins de temps à travailler son compilateur et d'affecter ces ressources à d'autres optimisations.
AMD a également ajouté dans chaque CU une unité de calcul scalaire qui pourra être exploitée pour traiter des opérations qui ne doivent pas obligatoirement être exécutées pour chaque élément d'un groupe via les SIMD, ce qui peut par exemple servir à optimiser certains branchements. Cette unité ne sera pas exposée directement dans les langages graphiques, mais pourra être exploitée par le compilateur.
Une unité dédiée à traiter les branchements en eux-mêmes reste présente, étendue pour gérer les messages liés au débogage.
Sommaire
1 - Introduction
2 - Tahiti : 2048 unités de calcul et bus 384 bits
3 - GCN : l'abandon du VLIW
4 - GCN : des caches et 2 ACE pour le GPU computing
5 - Video Codec Engine et HDMI 1.4a 3 GHz
6 - PowerTune et ZeroCore Power
7 - Spécifications, Radeon HD 7970 de référence, overclocking
8 - PowerTune : influence sur les performances
9 - Consommation et performances/watt
10 - Nuisances sonores et température GPU
11 - Thermographie infrarouge
12 - Performances théoriques : pixels
13 - Performances théoriques : géométrie
2 - Tahiti : 2048 unités de calcul et bus 384 bits
3 - GCN : l'abandon du VLIW
4 - GCN : des caches et 2 ACE pour le GPU computing
5 - Video Codec Engine et HDMI 1.4a 3 GHz
6 - PowerTune et ZeroCore Power
7 - Spécifications, Radeon HD 7970 de référence, overclocking
8 - PowerTune : influence sur les performances
9 - Consommation et performances/watt
10 - Nuisances sonores et température GPU
11 - Thermographie infrarouge
12 - Performances théoriques : pixels
13 - Performances théoriques : géométrie
14 - Protocole de test
15 - Benchmark : Anno 2070
16 - Benchmark : Batman Arkham City
17 - Benchmark : Battlefield 3
18 - Benchmark : Bulletstorm
19 - Benchmark : Civilization V
20 - Benchmark : Crysis 2
21 - Benchmark : F1 2011
22 - Benchmark : Metro 2033
23 - Benchmark : Project Cars
24 - Benchmark : Total War Shogun 2
25 - Récapitulatif des performances
26 - Conclusion
15 - Benchmark : Anno 2070
16 - Benchmark : Batman Arkham City
17 - Benchmark : Battlefield 3
18 - Benchmark : Bulletstorm
19 - Benchmark : Civilization V
20 - Benchmark : Crysis 2
21 - Benchmark : F1 2011
22 - Benchmark : Metro 2033
23 - Benchmark : Project Cars
24 - Benchmark : Total War Shogun 2
25 - Récapitulatif des performances
26 - Conclusion
Vos réactions
Contenus relatifs
- [+] 14/08: AMD annonce son bundle Never Settle...
- [+] 06/08: Baisse de prix sur les Radeon 7900
- [+] 05/08: Never Settle Forever, nouveau souff...
- [+] 15/05: AMD muscle Never Settle Reloaded
- [+] 12/04: Bundle: AMD ajoute Far Cry 3 Blood ...
- [+] 03/02: AMD HD 7900 & 7800: nouveau bundle ...
- [+] 26/10: Asus Radeon HD 7970 Matrix Platinum...
- [+] 26/10: Comparatif : les Radeon HD 7970 et ...
- [+] 11/10: MSI dope sa HD7970 Lightning
- [+] 28/09: Asus officialise ses Matrix HD7970