
Intel Core i7-6700K, i5-6600K et Z170 : Skylake en test
Publié le 05/08/2015 (Mise à jour le 28/09/2015) par Guillaume Louel et Marc Prieur



Les nouveautés côté processeur et overclockingFaute de documentation, il est malheureusement difficile de connaitre quelles sont les améliorations apportées par Intel au niveau du front-end (récupération et décodage des instructions x86, prédiction de branchement), du scheduler (réorganisation de l'ordre d'exécution des instructions) voire des unités de calculs. Aidé d'AIDA64 nous avons effectué des mesures de latence et de débit pour les instructions supportées par Skylake (ici, à comparer à ce fichier pour Haswell)et les unités d'exécution sont généralement plus rapides, avec notamment un gain de 25% pour les instructions de type FMA.

Puisqu'on parle d'instruction, Skylake ne supporte finalement pas l'AVX-512 sur Core i7 et i5, il sera réservé aux Xeon comme nous l'avions déjà indiqué. Les instructions TSX, désactivées sur Haswell suite à un bug, sont comme sur Broadwell de retour et les instructions ADX et RDSEED introduites sur Broadwell sont de la partie. La seule nouveauté de Skylake tel qu'introduit aujourd'hui se situe donc au niveau des instructions Intel MPX qui permettent d'augmenter la sécurité des logiciels en permettant de vérifier au moment de l'exécution que les références mémoires prévues dans un programme ne sont pas utilisées de manière malicieuse (via un buffer overflow par exemple).
Côté cache le gros changement opéré par Intel est le retour à un cache L2 associatif à 4 voies, contre 8 depuis les premiers Core i7. Cela simplifie la gestion du cache et devrait le rendre moins énergivore, mais avec un impact négatif sur les performances. En effet une ligne mémoire ne disposera plus de 8 options mais de 4 pour être stockée en cache, ce qui augmente potentiellement le risque de conflit avec une autre ligne mémoire utile et donc les défauts de cache conflictuel.
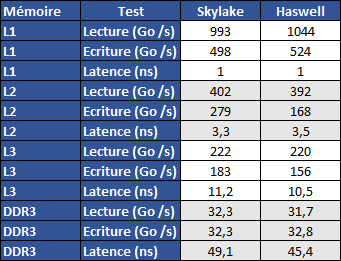
La vitesse mesurée sous AIDA64 montre à fréquence équivalente (4 GHz) un cache L1 légèrement moins rapide en débit mais équivalent en latence avec à 1ns soit 4 cycles, côté L2 on note une forte hausse (+66%) du débit en écriture et une baisse de l'ordre de 1 cycle de la latence. Le débit en écriture du cache L3 monte également (+18%) mais sa latence est en hausse, passant de 42 à 45 cycles environ. La latence d'accès à la DDR3-2133 augmente également par rapport à Haswell.
Au-delà du cache la gestion de la mémoire évolue également avec le support au niveau du contrôleur mémoire de la DDR4, que nous avons largement décrite à l'occasion du lancement des Haswell-E, en sus de la DDR3. Officiellement la DDR3 n'est plus supportée qu'en version 1.35V ("DDR3L") en DDR3-1600, mais en pratique nous n'avons pas rencontré de problème avec de la mémoire classique à 1.50V et même en 1.65V (nous vous conseillons toutefois de vous limiter à 1.50V), la DDR4 peut être de type DDR4-2133 ou plus via overclocking.
Puisqu'on parle de l'overclocking, Intel introduit quelques nouveautés sur Skylake, la principale étant un découplage complet des fréquences PCIe et DMI et de la BCLK. Complètement lié sur LGA 1155 ce qui limitait l'overclocking par le bus à quelques %, sur LGA 1150 Intel avait introduit des ratios permettant un peu plus de liberté. Cette fois le découplage est complet et quelle que soit la vitesse du bus BCLK choisie le PCIe et le DMI resteront à 100 MHz ce qui permet de laisser libre cours aux envies des overclockeurs, à condition bien entendu d'utiliser des ratios adéquat pour les éléments qui restent concernés (CPU, iGPU, DDR).

Un retour salutaire sur le papier, mais en pratique il ne sera vraiment utile que si il permet l'overclocking sur les processeurs "non K", et rien ne permet à ce jour de l'affirmer. A défaut, il s'agira juste d'une fioriture utile pour les chercheurs de records en tout genre prêts à passer du temps pour quelques points de benchmarks.
Côté coefficients multiplicateurs Skylake est par ailleurs capable d'atteindre les x83, contre x80 sur Haswell, alors que les ratios mémoire permettent d'avoir une granularité par saut de fréquence de 100/133 MHz contre 200/266 MHz auparavant, avec un maximum en DDR4-4133 (et plus en augmentant la BCLK bien sûr).
Mise à jour du 19/08/2015 : Lors de l'IDF nous avons pu en apprendre plus, vous trouverez ci-dessous notre actualité publiée à cette occasion pour la partie CPU :
Enfin ! Comme promis, Intel profite de l'IDF pour commencer a parler des détails de l'architecture de Skylake au travers de plusieurs sessions qui ont eu lieu en cette première journée. Nous avons tenté de regrouper le maximum d'informations dans cette longue actualité, en sachant que le constructeur tend a lâcher au compte goutte les détails d'une session à l'autre, il n'est pas impossible que certains détails ne soient dévoilés que dans les jours à venir ! Nous allons tenter de noter les différences par rapport à Haswell, vous pouvez vous rafraichir la mémoire en relisant notre article.

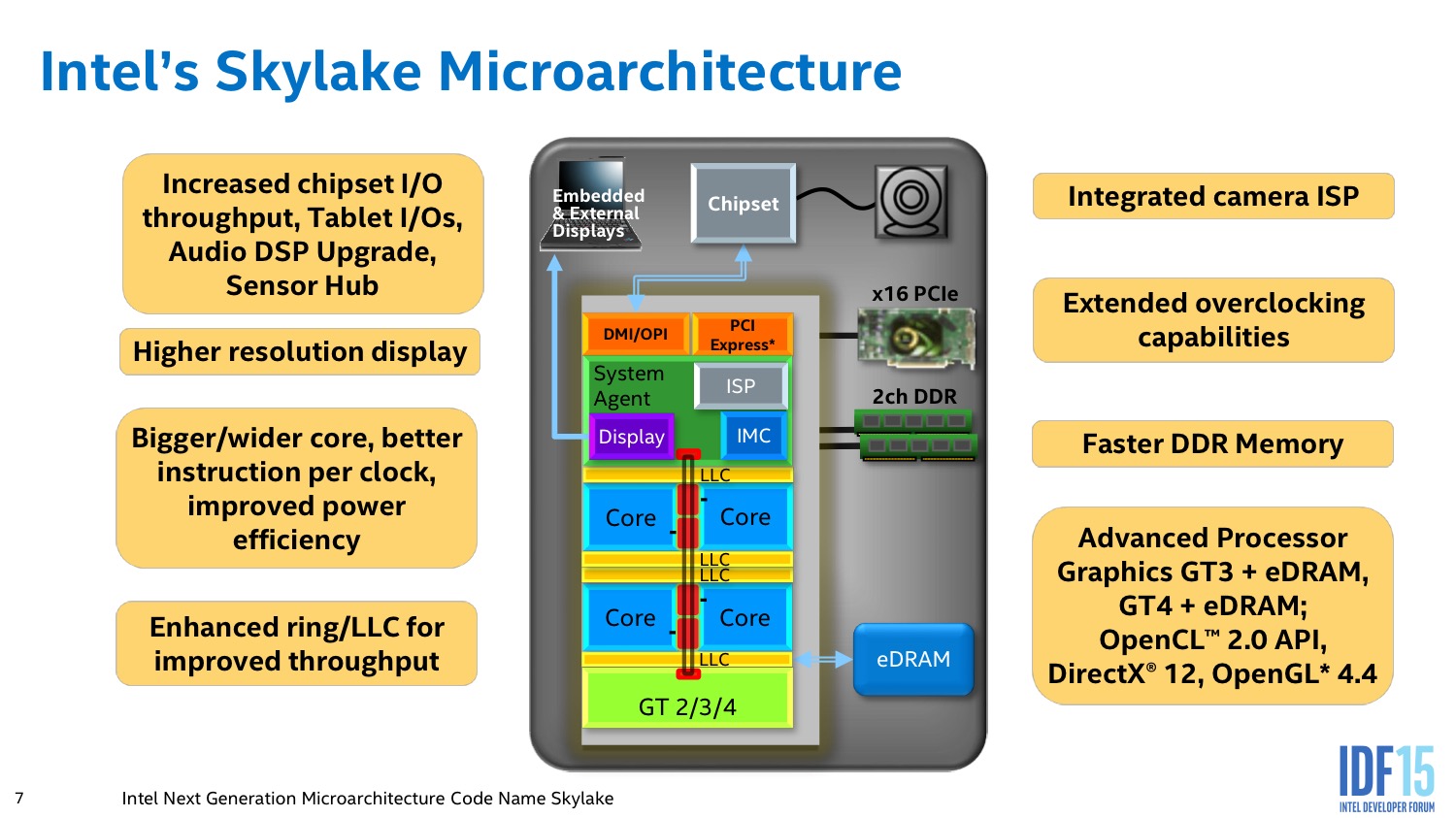
Avant de commencer, on notera que le constructeur travaille sur Skylake depuis plusieurs années (plus de 5) et que le projet, réalisé en Israel (Intel alterne deux équipes, une en Israel, l'autre dans l'Oregon) aura été modifié plusieurs fois pour rajouter successivement des TDP de 15 watts (avec les Ultrabook lancés à partir de 2008) puis de 4.5W (Core M) ainsi que des variations de packaging. On notera aussi, et c'est une première, que les détails que nous indiquons en dessous ne concernent que la version grand public de Skylake. La version serveur profitera de choix différents au niveau de l'architecture, on sait par exemple que seule la version serveur de Skylake supportera l'AVX512, mais les différences devraient être plus larges.
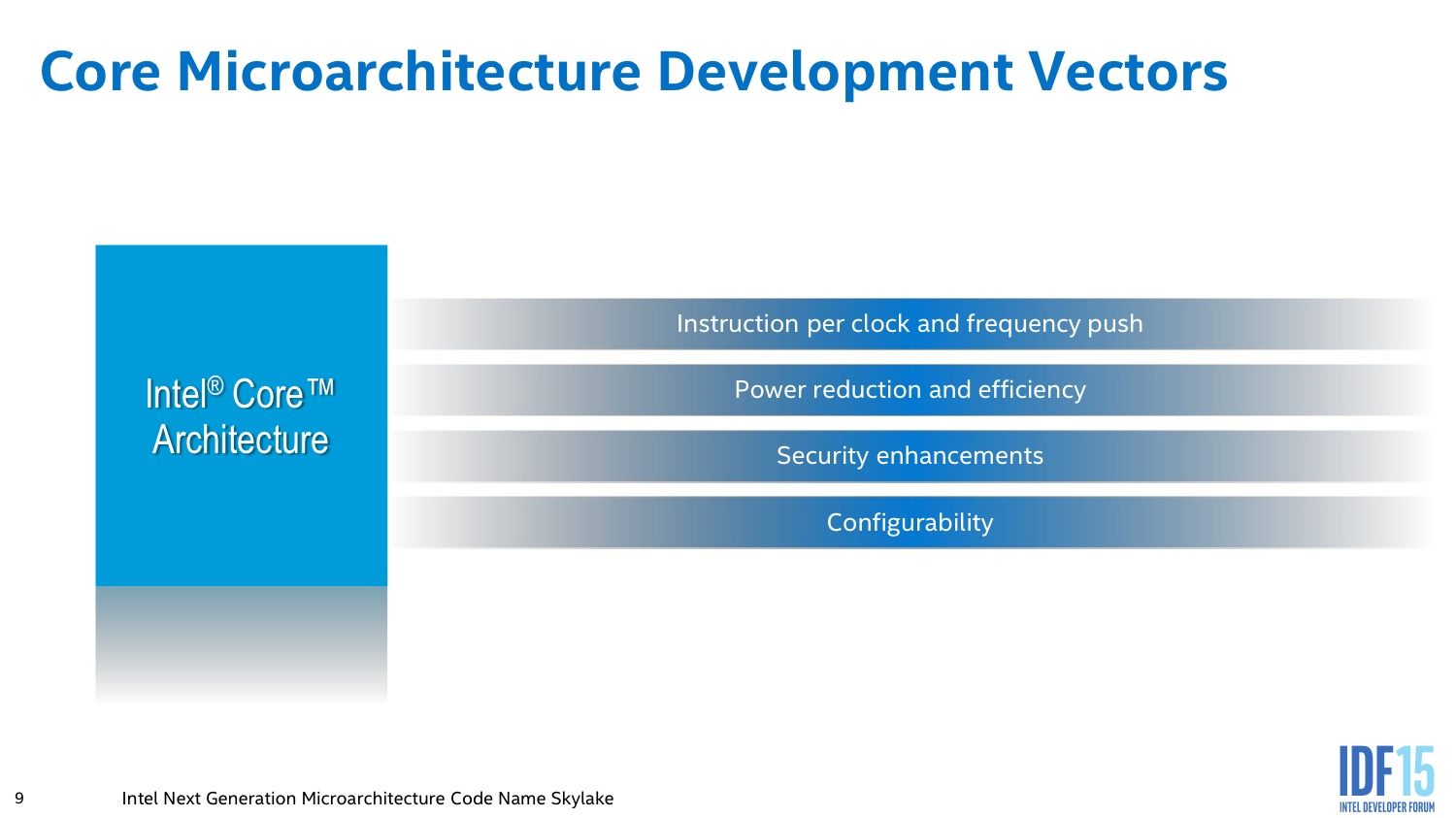
Frontend, scheduler et unités d'execution
Dans les grandes lignes on ne notera pas de changement majeur sur le frontend qui reste de type 4-way (jusque 4 instructions x86 décodées en simultanées) comme pour Sandy Bridge et Haswell. En pratique de ces quatre instructions CISC, jusque 6 micro-ops (les instructions RISC) peuvent toujours être générées.
En amont du décodage, on retrouve la prédiction de branchement qui évolue par contre significativement. Intel ne rentre pas dans les détails de l'algorithme mais indique qu'il est plus intelligent et capable de considérer des branchements beaucoup plus longs qu'auparavant. De la même manière, Intel a augmenté la taille des différents buffers durant les différentes étapes du front-end, un changement que l'on retrouve a presque toutes les nouvelles architectures.
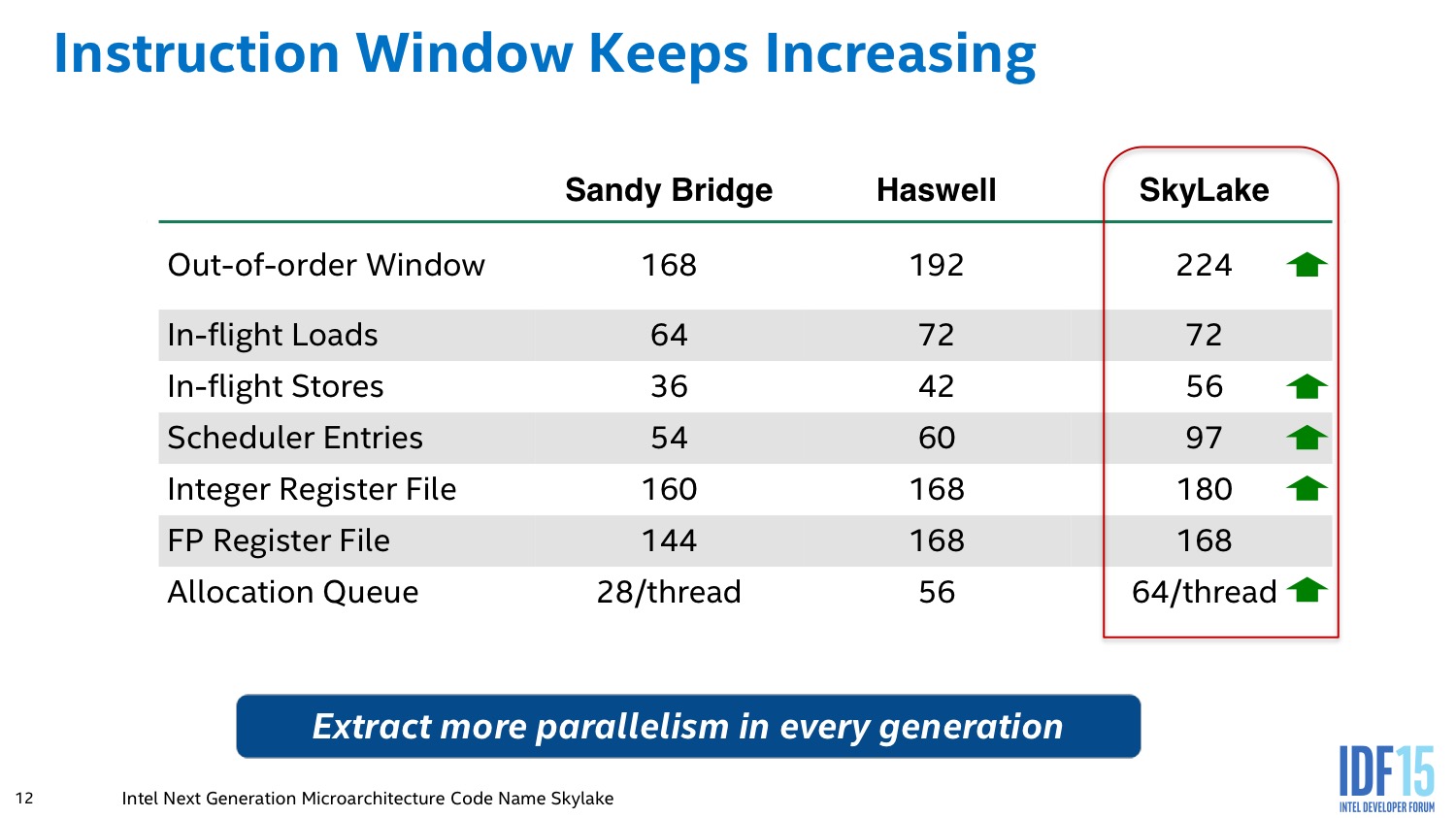
Les micro-ops décodées sont en effet stockées dans deux files capables d'en stocker 64 par thread (contre un buffer unique de 56 pour Haswell), un changement majeur qui permet au scheduler de tenter d'extraire un maximum de parallélisme.
Le scheduler a pour but de dispatcher les micro-ops vers les unités d'exécution. Il profite des files rallongées et de certains changements au niveau de ses algorithmes dans la gestion de l'hyperthreading.


Le point le plus flou pour l'instant concerne les unités d'exécution. Pour rappel, avec Haswell on disposait de 8 ports sur lesquels étaient répartis de multiples unités d'exécution (ALU pour les instructions sur les entiers, des unités AVX/flottants, les chargements/sauvegardes de données en mémoire, les branchements ). Pour l'instant tout ce que l'on sait, c'est que le nombre d'unités a augmenté sans savoir celles qui ont été ajoutées. Deux autres détails ont été donnés par les ingénieurs d'Intel : l'unité en charge des divisions gagne en flexibilité, tandis que la latence de traitement de certaines instructions FPU serait en baisse. Intel nous a promis que nous aurions plus de détails sur ces points dans une session à venir.
Globalement les changements sont intéressants dans le sens ou ils permettent en théorie de maximiser un peu plus l'utilisation des unités d'exécution de chaque coeur, ce qui peut se traduire dans certains cas par une augmentation importante des performances. Le constructeur a par ce biais réussi à améliorer significativement ses résultats dans un des benchmarks SPEC sur un coeur (ce qui a valu à nos confrères allemands de ressortir la rumeur - évidemment fausse - d'un hyperthreading inversé en fin de semaine dernière !). Les changements restent cependant très localisés et dans l'absolu, Intel continue d'affiner les grandes lignes d'une architecture Core, certes excellente, mais qui reste la même dans les grandes lignes depuis des années.
Jeu d'instruction
Lors de notre test de Skylake, nous avions noté la présence d'une nouveauté dans le jeu d'instruction : MPX, Memory Protection Extension. Ces instructions permettent de rajouter des vérifications sur les adresses mémoires accessibles pour éviter les attaques type buffer overflow et empêcher un processus d'accéder a de la mémoire a laquelle il n'a pas droit. Nous n'avons pas encore obtenu plus de détail sur ces instructions.


Par contre, une autre nouveauté complémentaire concerne ce que le constructeur appelle SGX, pour Software Guard Extension. Ces instructions permettent de créer des zones mémoires protégées qui ne sont accessibles qu'au processus qui les a crée, et qui, dans le cas ou les données auraient été tout de même corrompues, couperait le fonctionnement du process concerné afin de maximiser sa sécurité. De la même manière, l'utilisation d'une zone mémoire sécurisée (Secure Enclave) désactive toutes les possibilités de deboguage sur le système.


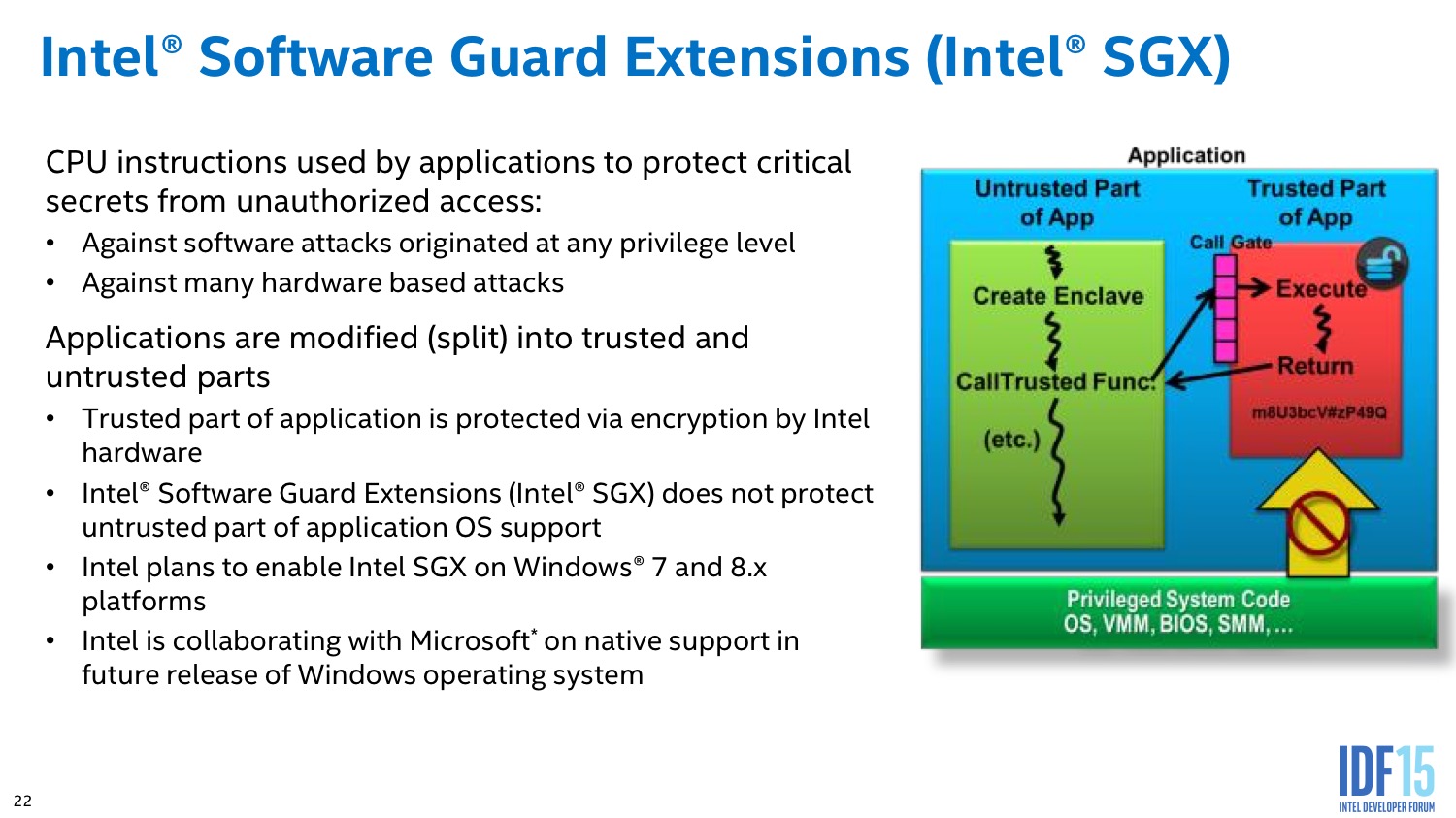
Si l'on imagine aisément l'utilité de ces extensions dans certaines situations dans le monde de l'entreprise, d'un point de vue grand public on pensera surtout aux implémentations éventuelles de DRM qui pourraient utiliser ces technologies à l'avenir.
Gestion de l'alimentation
Un gros travail a également été réalisé sur la gestion de l'alimentation avec un usage accru du power gating de certaines unités gourmandes, c'est notamment le cas des unités AVX2 qui sont éteintes lorsqu'elles ne sont pas sollicitées. Des économies ont été réalisées à tout les niveaux, particulièrement celui des interconnexions et des I/O pour limiter au maximum la consommation.
Les ingénieurs ont travaillé plus spécifiquement sur les scénarios idle ou « presque » idle comme la lecture vidéo pour augmenter au maximum la longévité de la batterie en usage mobile. Parmi les solutions retenues pour arriver à ce but, on retrouve l'ajout de domaines d'horloges séparés pour le System Agent, le contrôleur mémoire et l'I/O eDRAM (pour les modèles qui en sont pourvus).
Un travail important a également été réalisé sur l'unité de gestion de l'énergie (Power Control Unit) pour la rendre un peu plus intelligente dans de multiples scénarios ou elle devient capable d'estimer un risque de throttling et de réduire a l'avance la fréquence pour éviter d'atteindre la température maximale à laquelle un throttling sévère est inéluctable.




L'autre choix concerne l'utilisation du Duty Cycle Control en lieu et place d'un changement de fréquence. Comme indiqué par Intel, réduire la fréquence (via les P-States pour les coeurs) permet de diminuer la consommation de manière linéaire, et il est souvent plus efficace d'éteindre et d'allumer (un peu a la manière d'un contrôleur PWM) les unités tout en gardant une fréquence plus élevée.
Speed Shift
L'autre changement majeur concernant la PCU est ce qu'Intel appelle Speed Shift, un changement fondamental du fonctionnement des P-States. Pour rappel, la fréquence du processeur est gérée à la fois par le processeur lui même et le système d'exploitation. Le processeur propose une table dite de P-States (via les tables ACPI) qui indique les différents couples de tensions/fréquences qu'il peut utiliser.



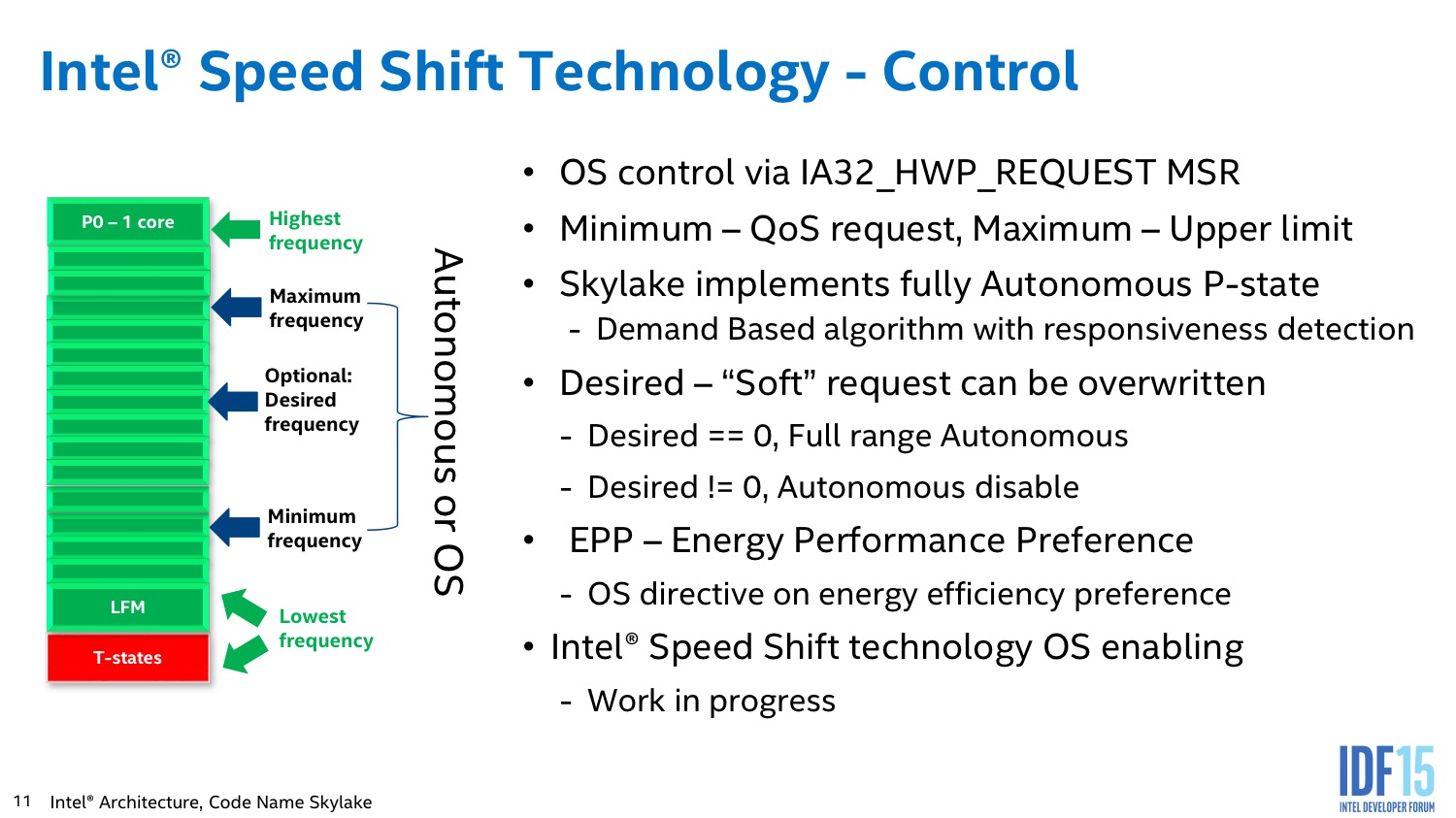
Dans un fonctionnement classique, le système d'exploitation, en fonction de la charge qu'il traite, va contrôler explicitement les changements de P-States (ce qui requiert une latence d'environ 30ms selon Intel) en choisissant un niveau (par exemple, P1, la fréquence maximale « non turbo »). Il y a cependant - chez Intel - deux exceptions à cette règle. La première concerne les fréquences Turbo qui varient en fonction du nombre de coeurs actifs. Cette gestion s'effectue directement par le processeur. L'autre est le cas du throttle lorsque l'on dépasse la température de fonctionnement critique. Dans ce cas le processeur effectue seul (heureusement !) le throttling en passant dans les modes dits de contrôle thermique.
L'idée de Speed Shift est de changer la relation entre le système d'exploitation et le processeur. D'une, avec Speed Shift le processeur expose désormais la totalité des fréquences disponibles, y compris les modes Turbo gérés jusqu'ici de manière transparente. Ensuite, le système d'exploitation va donner une sorte d'indication globale pour indiquer s'il faut privilégier la performance ou l'économie d'énergie (remplaçant le concept des modes performance/balanced/etc que l'on retrouvait par exemple sous Windows 7, ainsi que le mode batterie/alimentation pour les portables). Enfin, par défaut le PCU est capable de gérer tout seul les P-States en choisissant automatiquement le mode qui semble le plus adapté à la volée et de manière complètement autonome.
Par dessus ceci, le système d'exploitation peut décider d'intervenir, mais cela se fait d'une manière nouvelle. En effet, le système définit une fréquence minimale ainsi qu'une fréquence maximale, laissant là encore au PCU une marge de manoeuvre pour optimiser automatiquement au mieux en fonction de la charge. Il est également possible de demander une fréquence précise, de manière optionnelle, mais cela se fait en plus des fréquences mini et maxi et n'est en rien garanti.
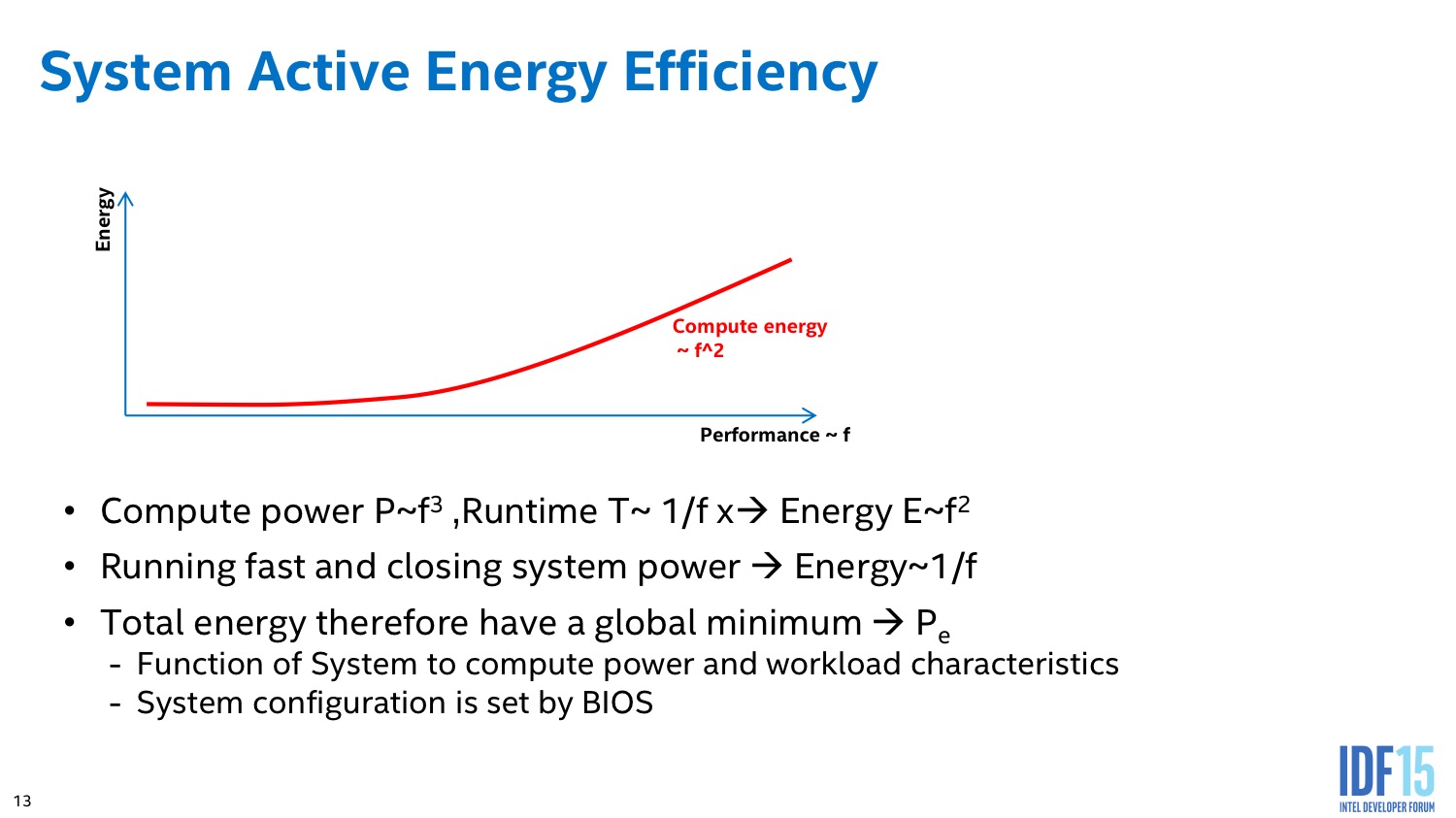
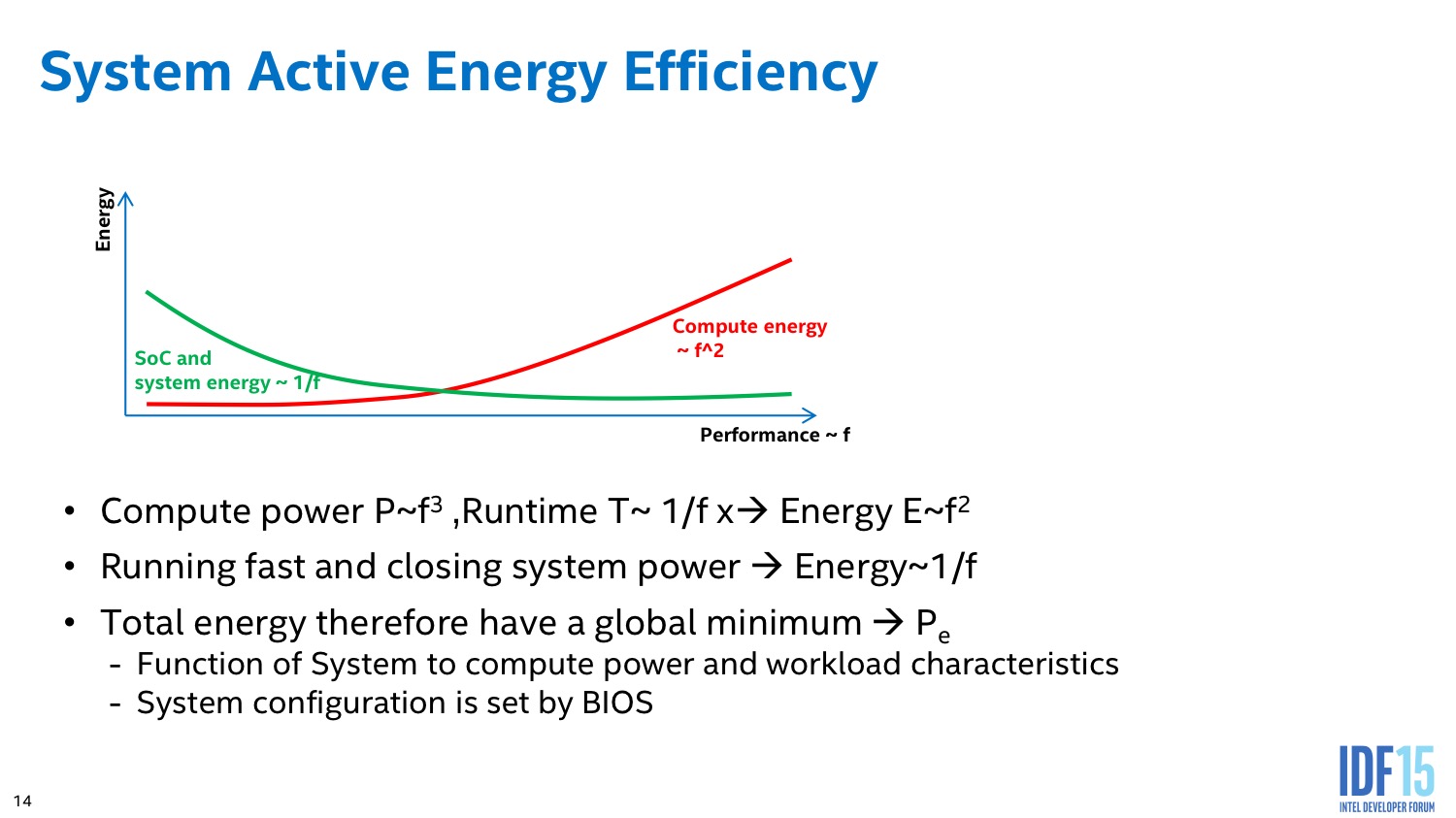
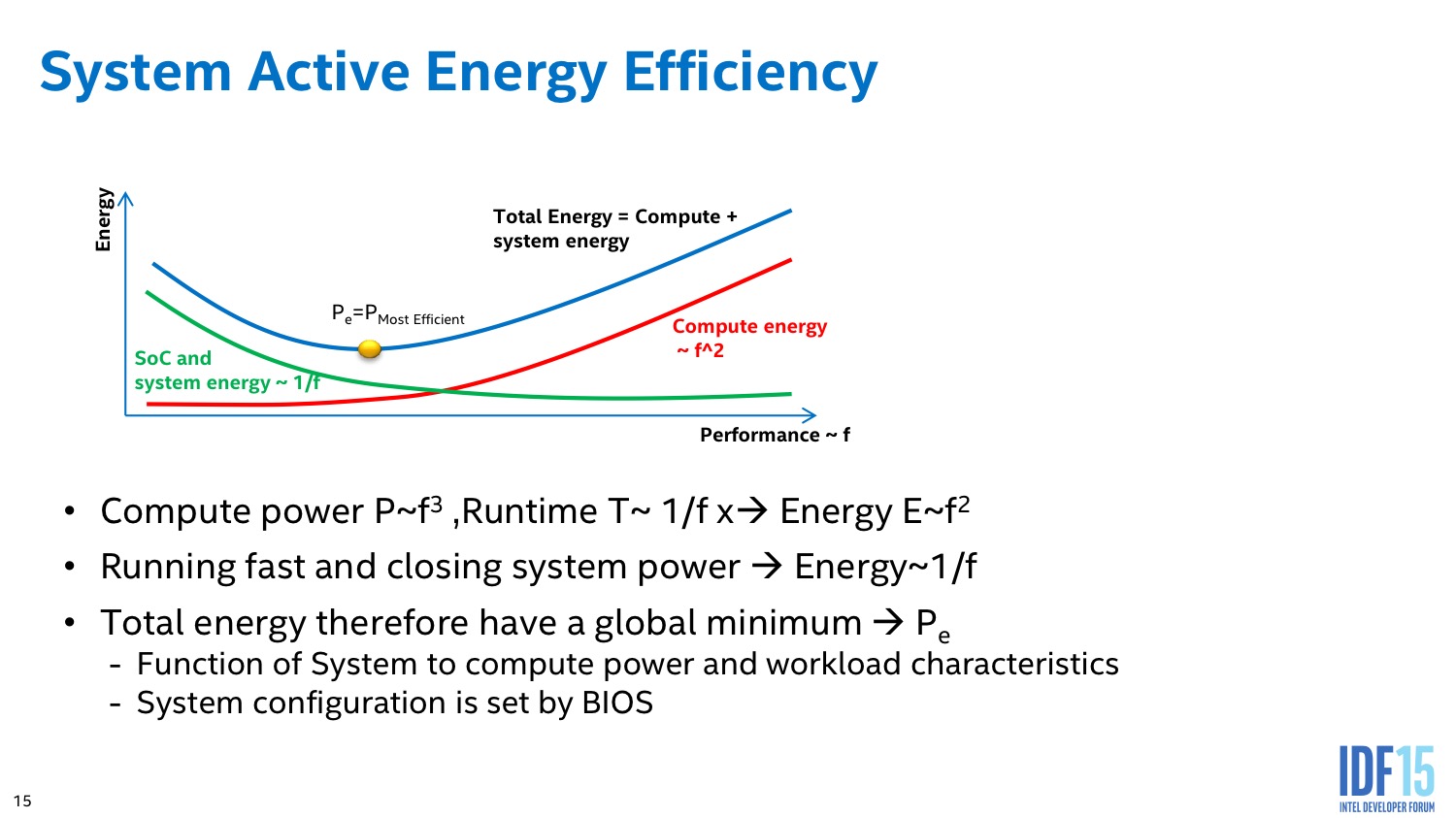
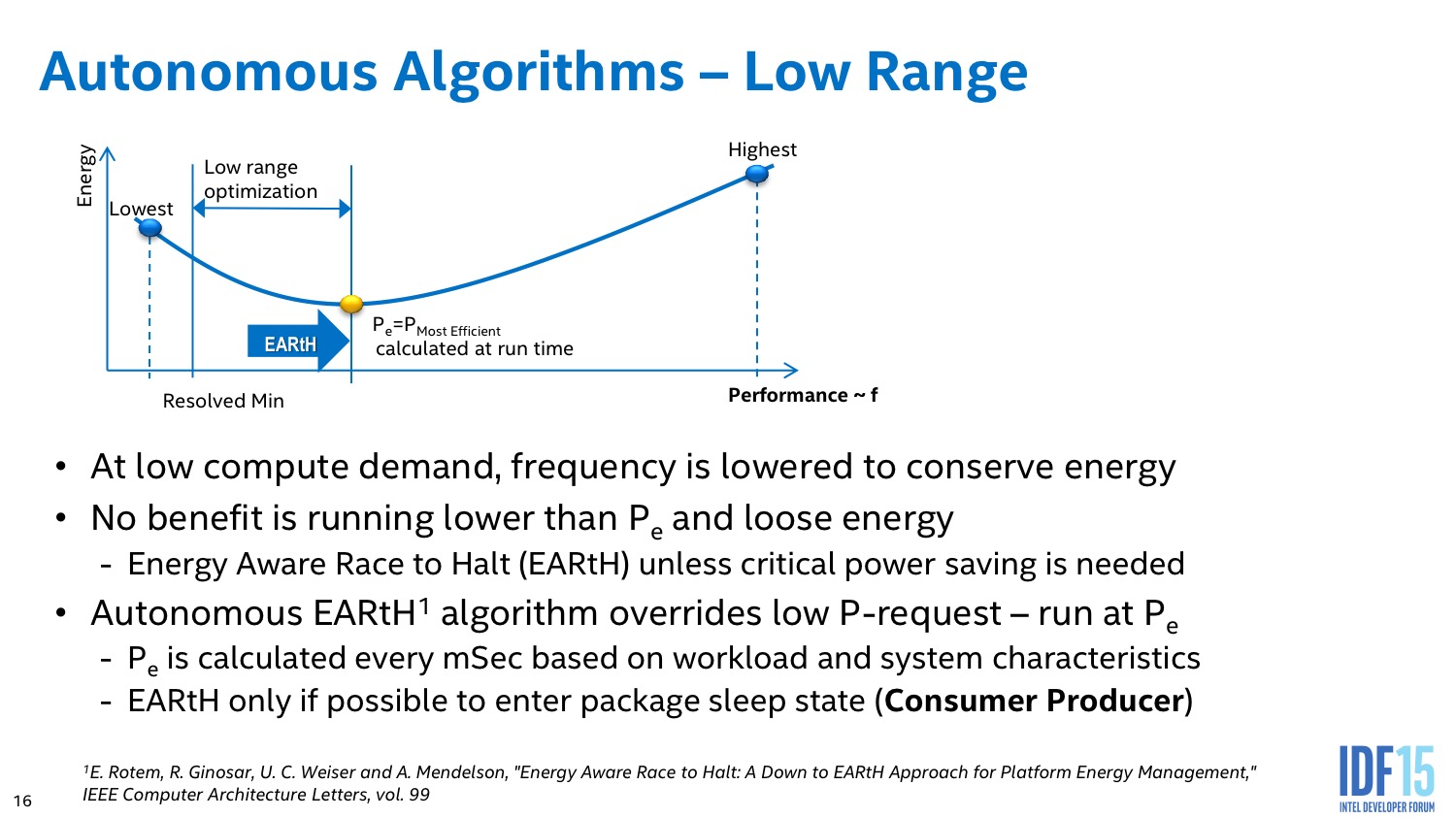



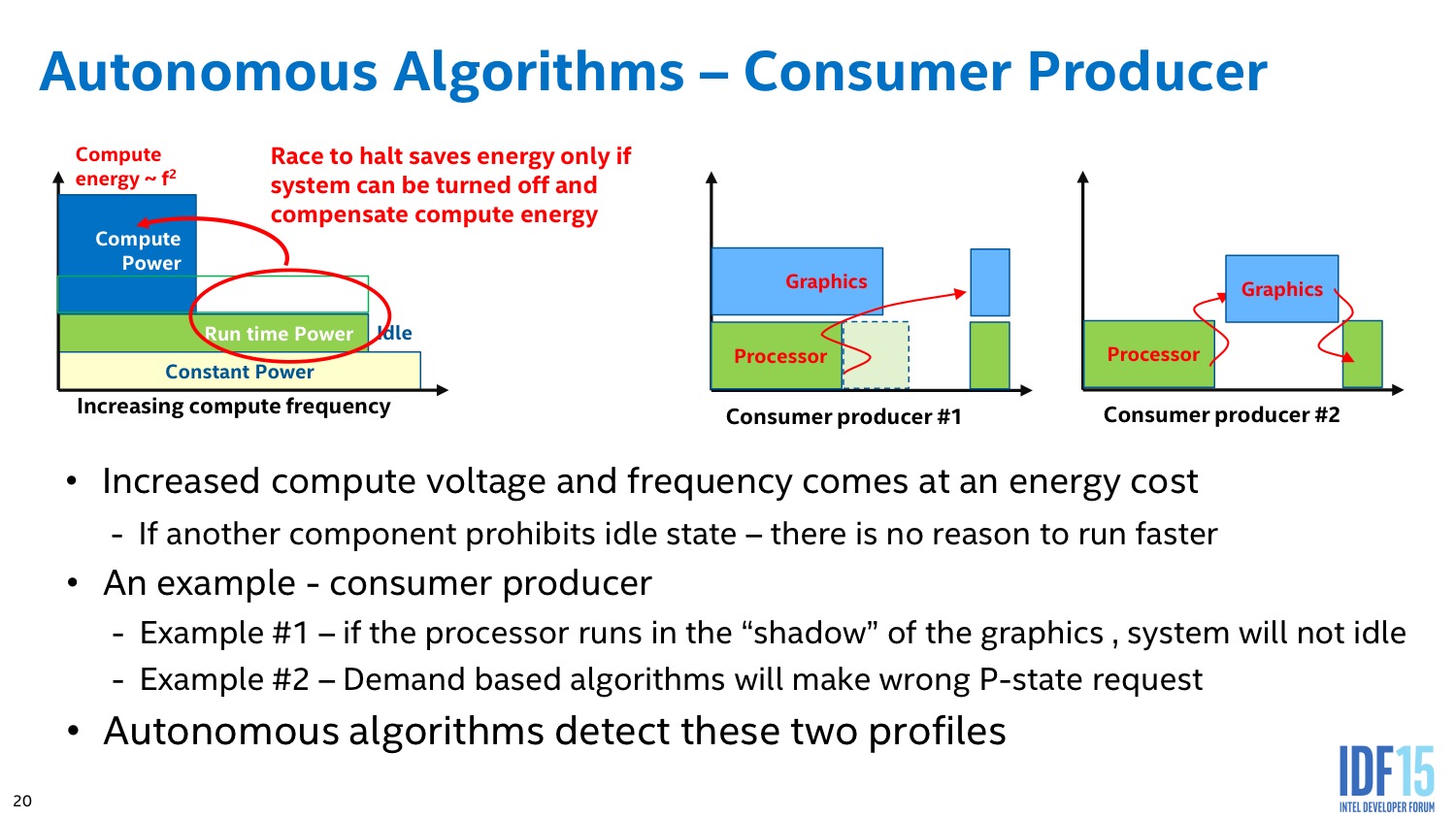
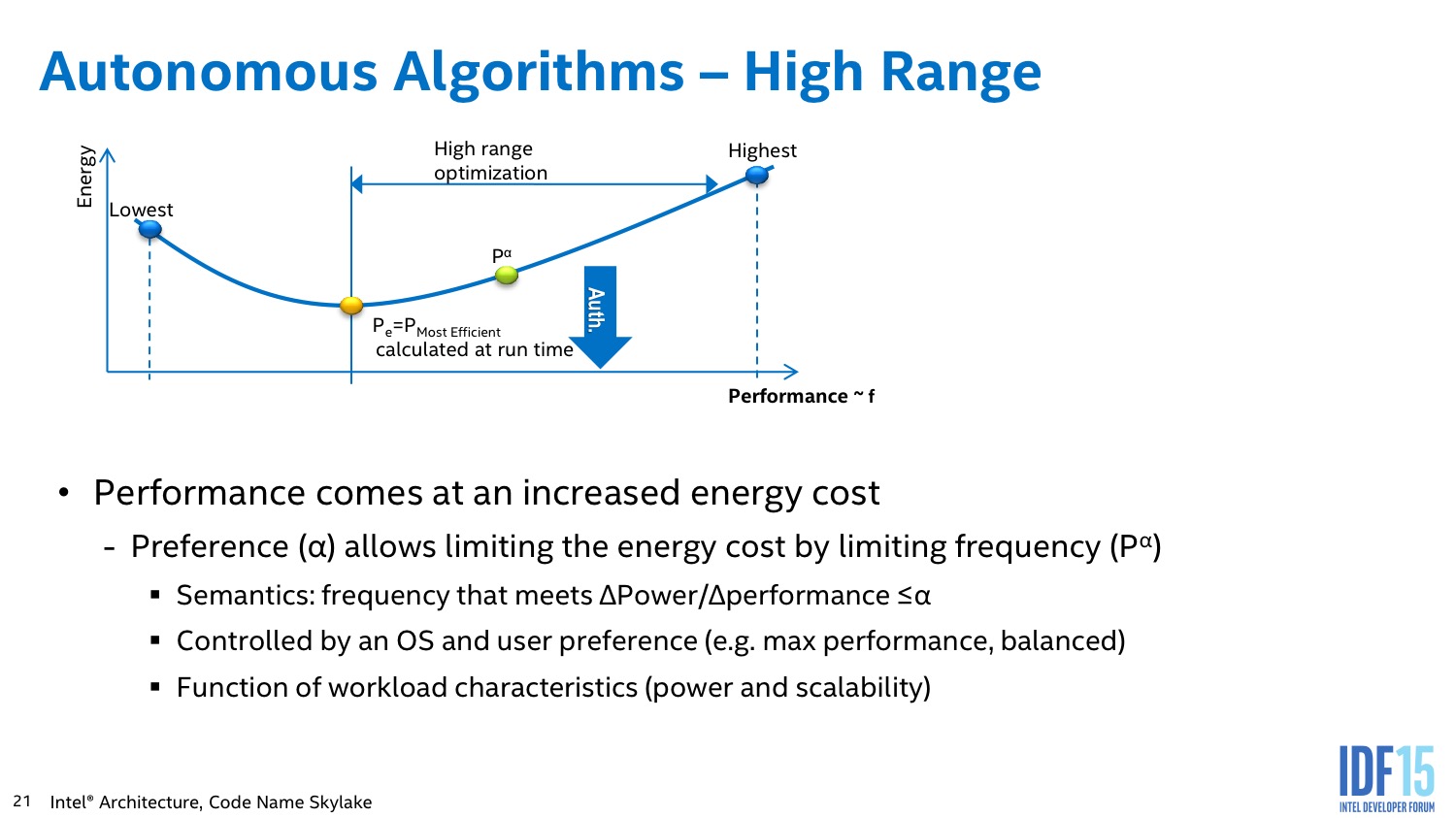
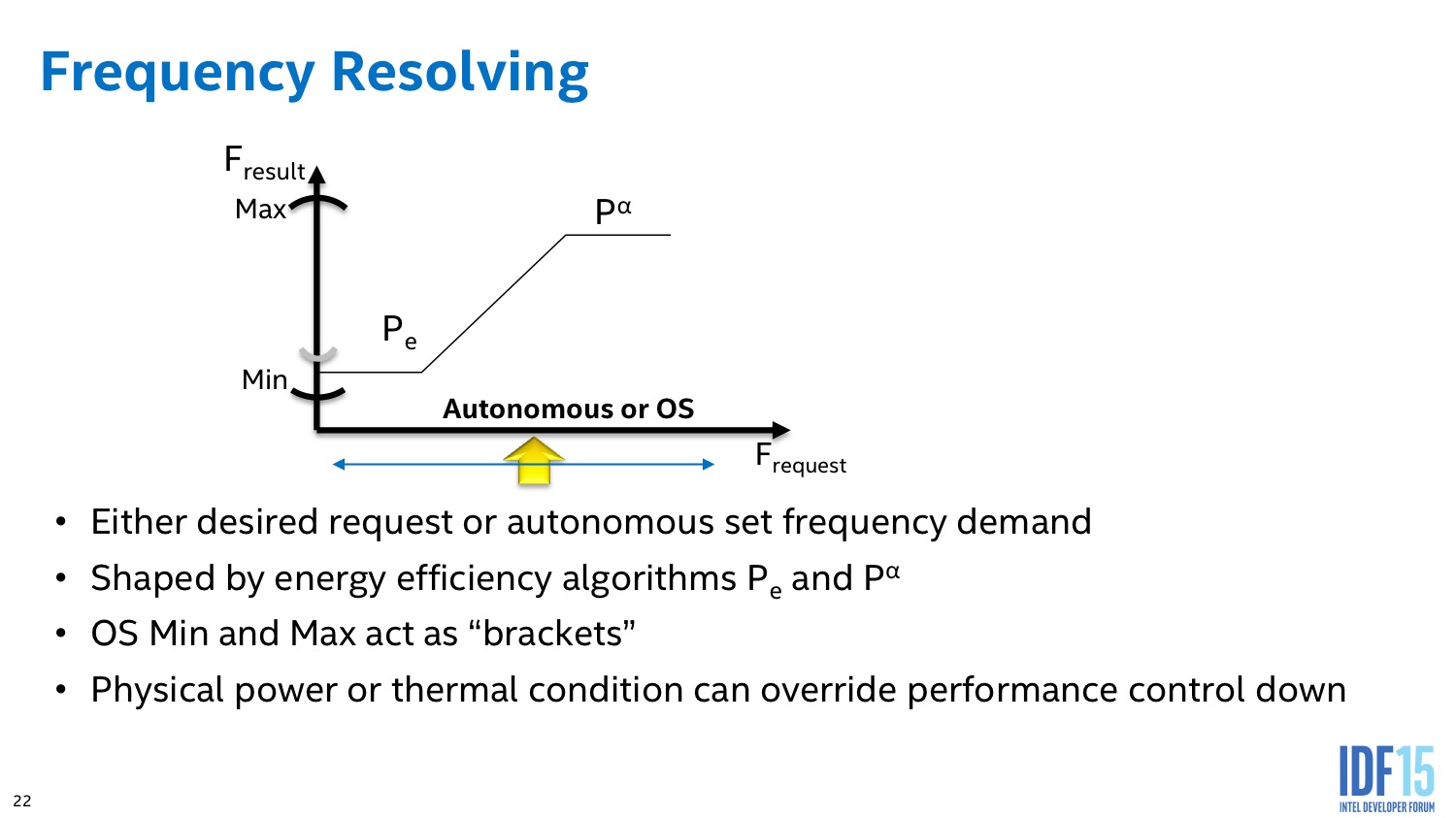
Intel implémente des algorithmes avancés dans son PCU qui tentent d'estimer en permanence s'il est plus intéressant de limiter la fréquence dans le cas d'une charge légère constante, ou au contraire de pousser la fréquence pour pouvoir éteindre le plus rapidement possible les unités et sauver de l'énergie au final.
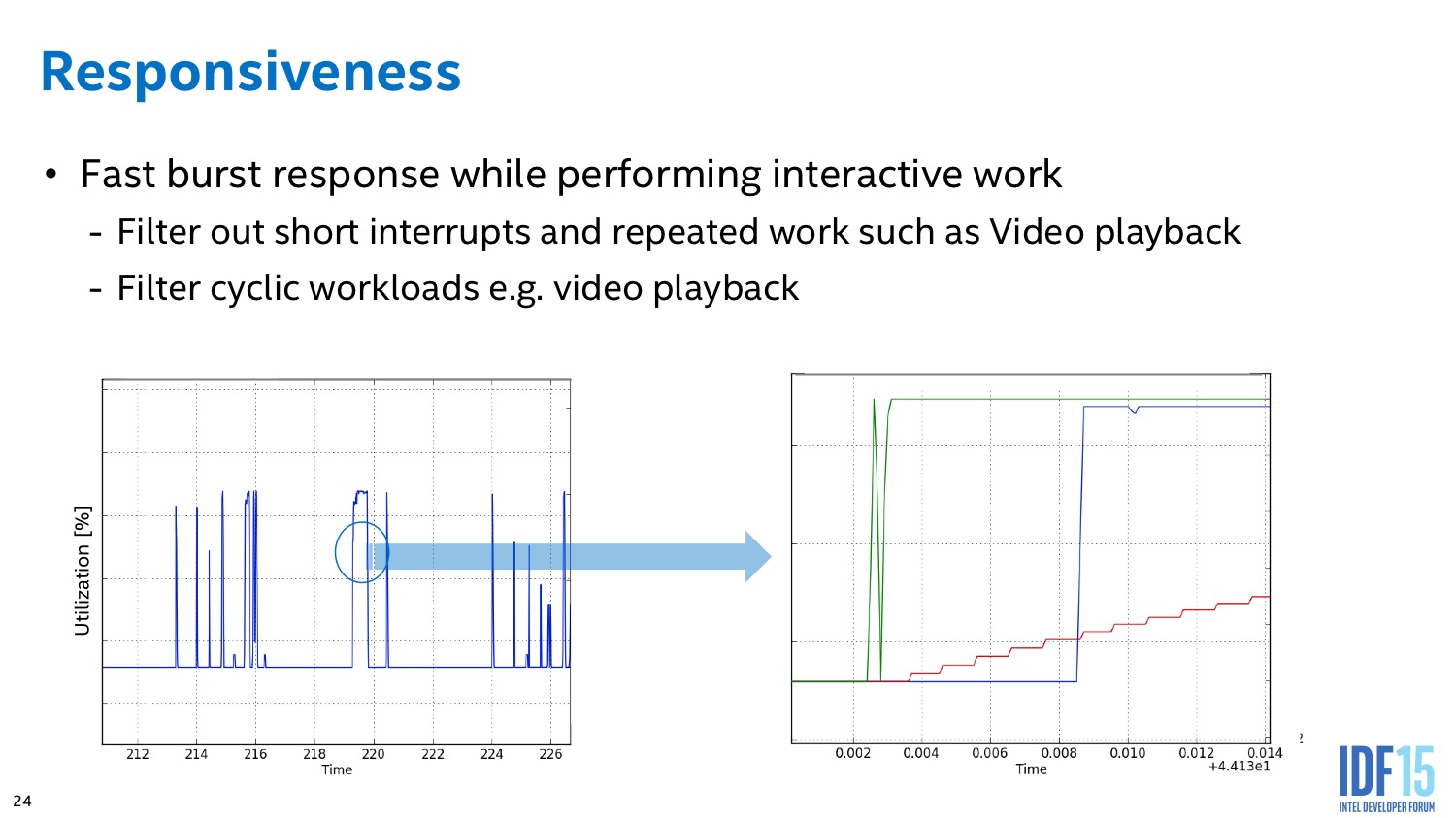
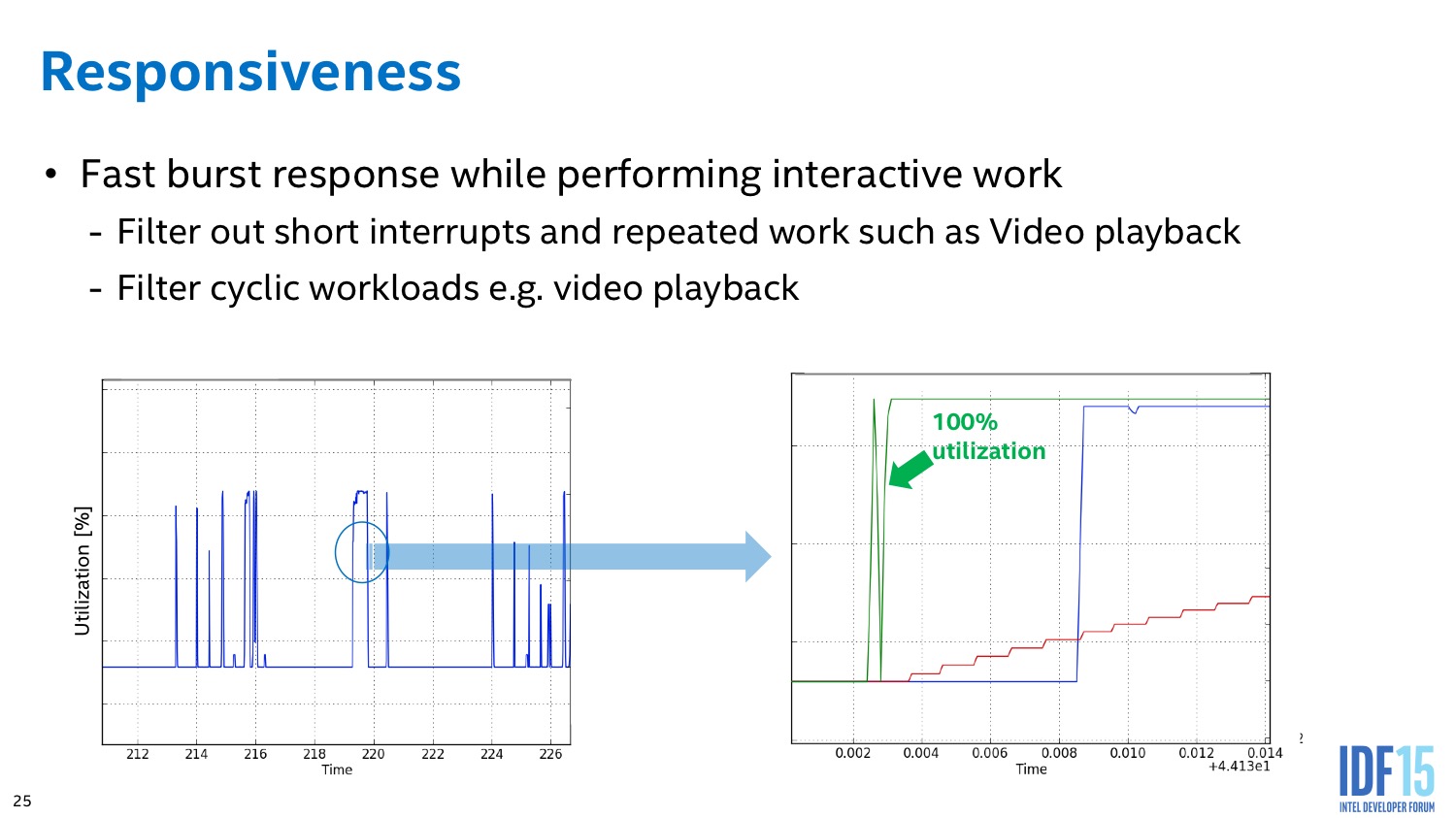
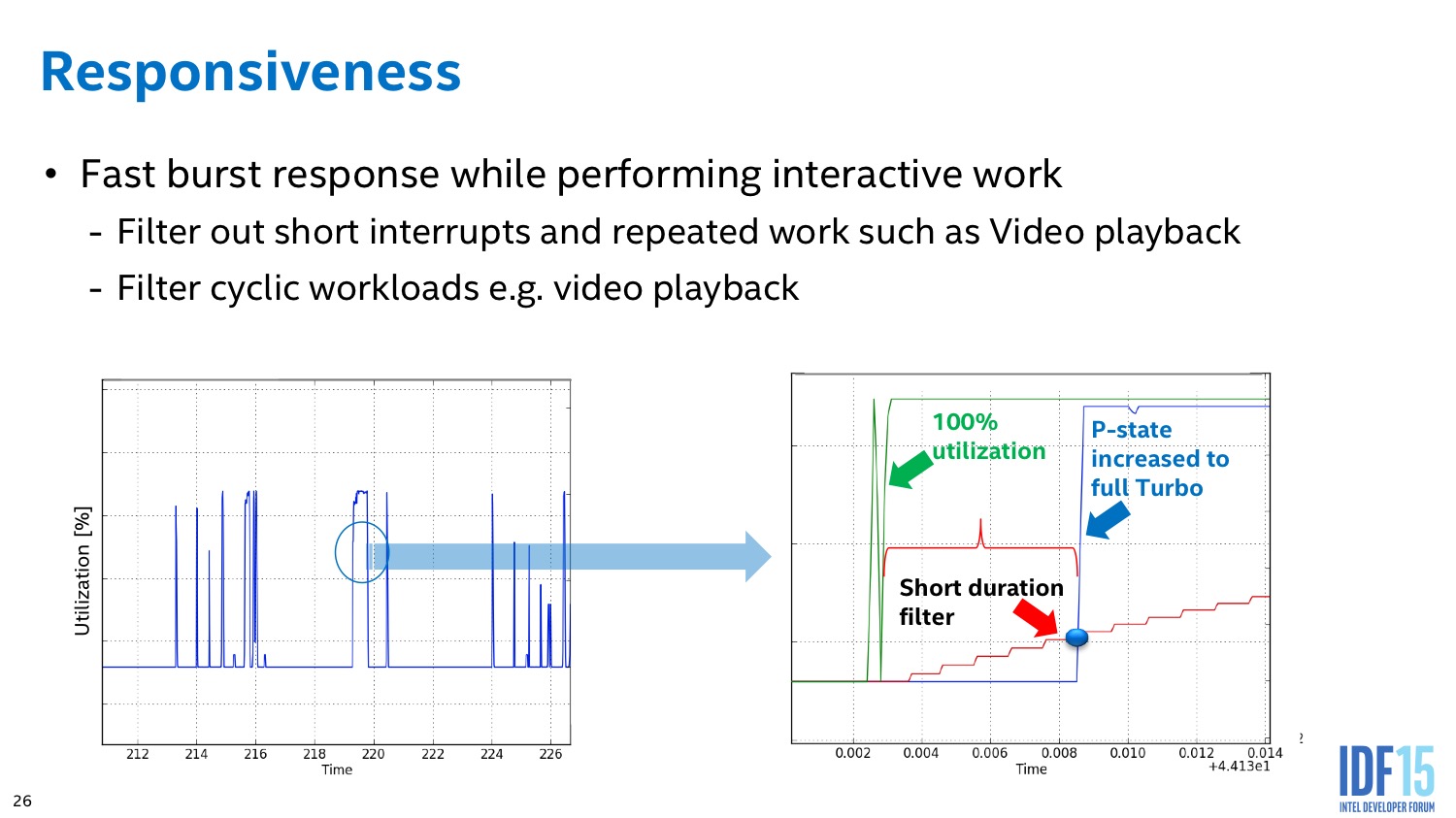
L'algorithme du PCU tente également de détecter les situations ou l'on interagit avec le système pour améliorer le côté responsif du système. L'idée de base telle que voulue par les concepteurs du système était de passer le plus rapidement possible en mode turbo lorsque l'on détecte une interaction (réveil, souris, etc) pour donner l'impression que le système est plus réactif. En pratique le PCU tente de détecter les charges typiques d'une interaction et utilise plusieurs systèmes pour filtrer des charges plus longues (lecture vidéo), ou tellement courtes qu'elles ne mériteraient pas que la fréquence augmente.
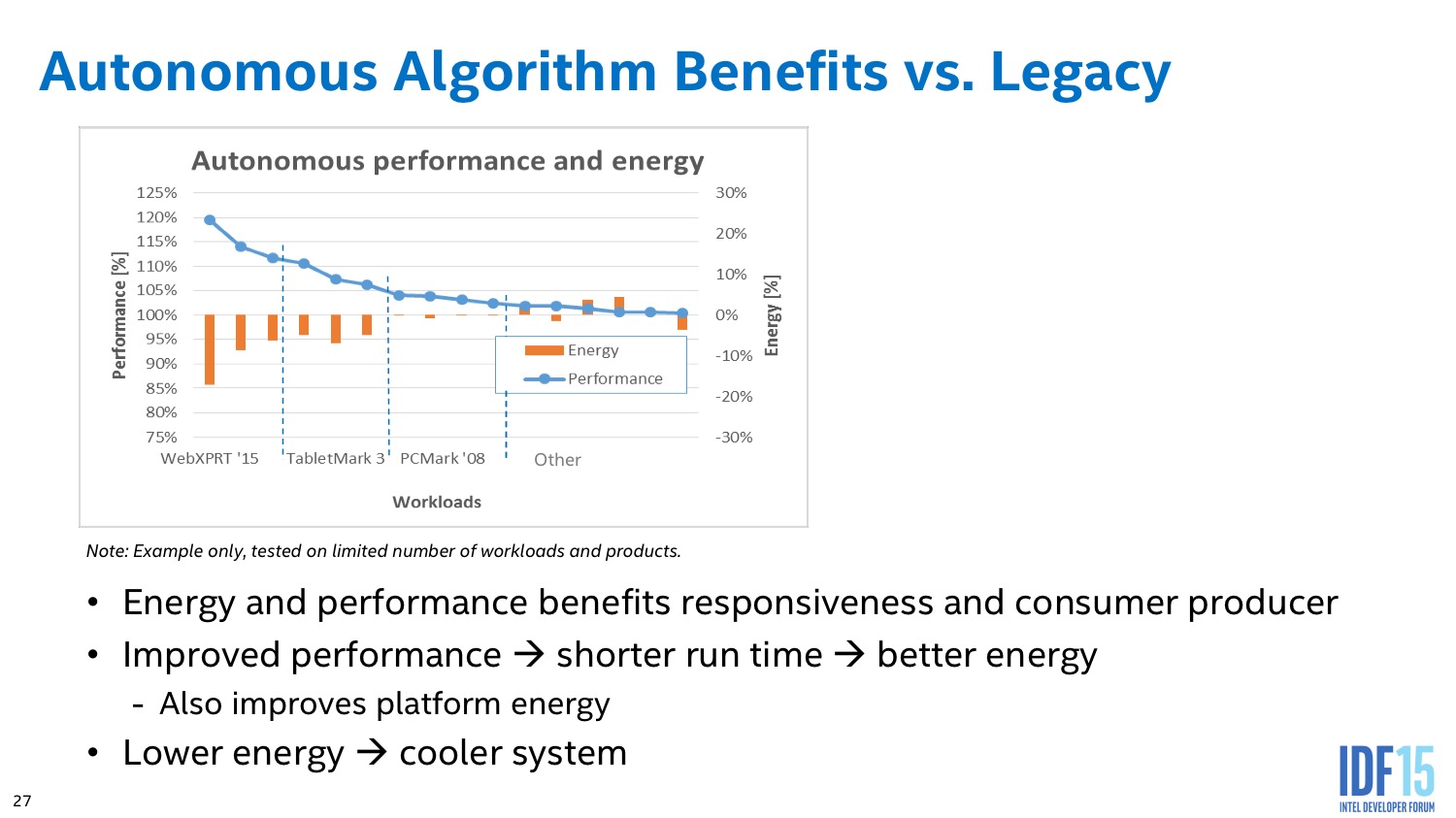
En pratique en tout cas,Intel indique être capable de réduire à la fois la consommation tout en ne sacrifiant pas sur les performances. Vous pouvez voir sur ce slide quelques résultats annoncés par le constructeur même s'il n'est pas rentré plus dans les détails !
Speed Shift changeant fondamentalement le mode d'interaction entre le processeur et système d'exploitation, on ne sera pas surpris d'apprendre que son support doit être explicite, et est donc aujourd'hui limité. Aujourd'hui, seul Windows 10 est capable de l'exploiter. Sur tous les autres OS, le fonctionnement reste à l'ancienne.
Il est intriguant de voir qu'Intel n'a pas encore publié de patch pour Linux pour y ajouter le support de Speed Shift. D'autres technologies de Skylake comme MPX ont en effet eu droit à un support dès janvier sous Linux. Malgré tout, l'idée de rénover le concept fort vieux des P-States est une excellente idée, laisser la main au processeur sur sa fréquence parait presque une évidence et il sera très intéressant de voir l'impact pratique qu'aura cette technologie sur la conservation de la batterie sur les versions mobiles de Skylake.
eDRAM, IVR, Chipset
Un autre changement important concerne la manière dont la mémoire eDRAM est interfacée avec le processeur. Avec Broadwell par exemple, l'eDRAM est interfacée derrière le cache LLC et peut contenir de la mémoire utilisée par l'IGP ou par les coeurs mémoires (des tags dans le LLC marquent qui utilise quoi).

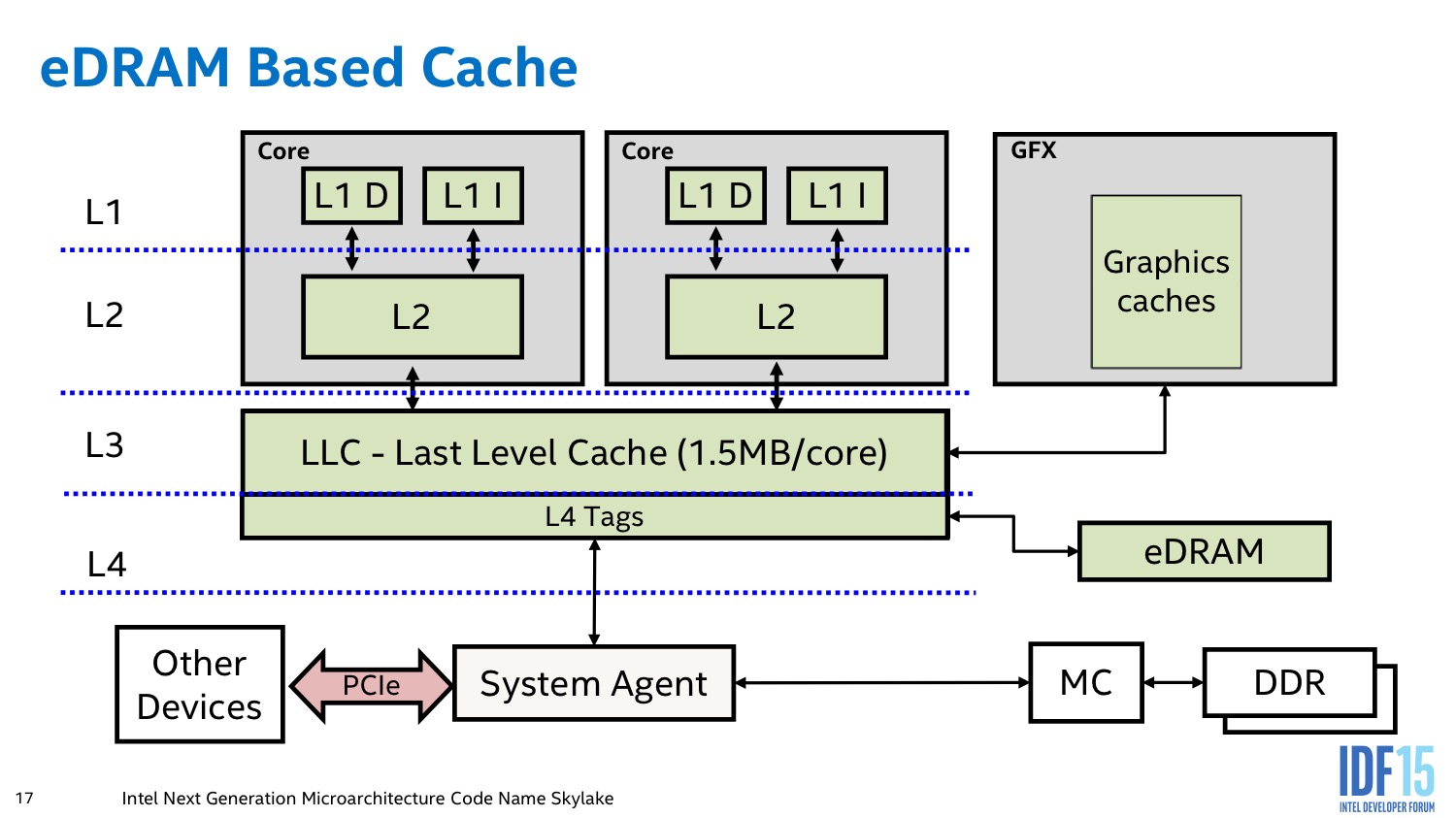
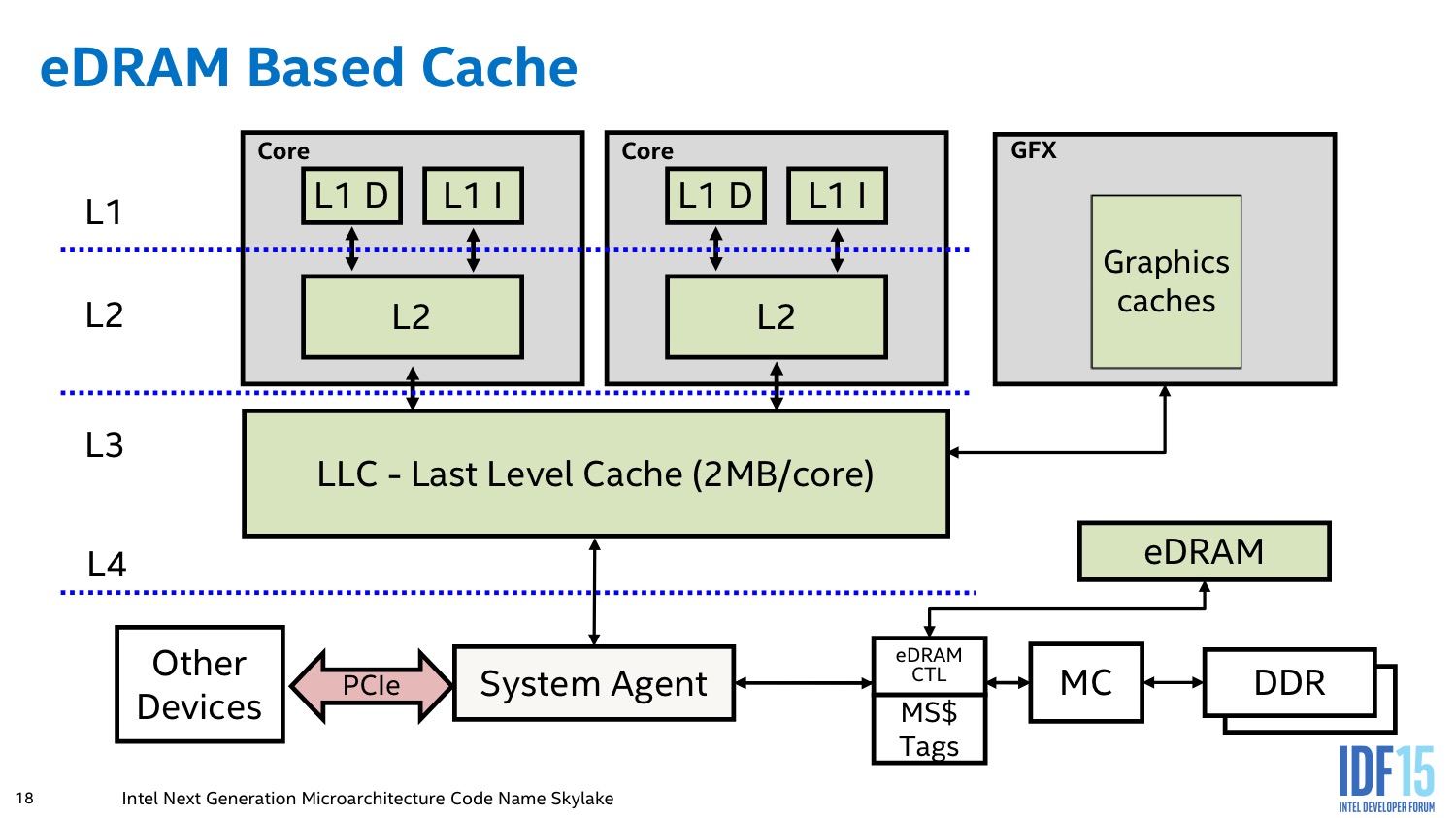

Avec Skylake l'eDRAM se retrouve placée entre le LLC et le contrôleur mémoire, s'intégrant de manière encore plus transparente dans la hiérarchie mémoire. En pratique ce changement permet de mettre en cache des données qui peuvent venir d'un peu partout. Le L4 peut ainsi contenir en cache des requêtes PCI Express ou du chipset.
Cette transparence est cependant débrayable dans le cadre d'une utilisation graphique. Le pilote graphique Intel dispose d'un mode d'accès spécifique qui lui permet de demander où il souhaite que soit mises en cache certaines informations. Il peut demander a ce que des informations soient stockées dans le L3, ou dans l'eDRAM au choix, ou au contraire nulle part. Des décisions que le pilote, selon Intel, est plus a même d'estimer correctement. L'impact réel de ce changement est difficile à évaluer même si potentiellement il devrait profiter aux utilisations non graphiques.
On notera sur la question de la suppression du régulateur de tension intégrée que les ingénieurs nous ont donné une réponse : la décision de les supprimer a été prise spécifiquement à cause des modèles 4.5W ou l'IVR était inefficace. Une « meilleure » solution, s'ils avaient eu plus de temps selon les ingénieurs d'Intel aurait été de supprimer l'IVR uniquement sur les modèles basse consommation et de les garder sur les autres. Un sous-entendu qui laisse penser que le constructeur pourrait opter pour cette séparation a l'avenir pour Cannonlake.

Notons pour terminer que le chipset, au delà des changements déjà évoqués dans notre article, propose une particularité originale : il est désormais capable d'entrer en mode throttling en cas de surchauffe. L'idée est surtout d'éviter la situation ou, a cause d'une surchauffe de la plateforme, le PCH pourrait mettre en péril le système. Intel gagne surtout un peu de marge pour les puces 4.5 et 15W qui incluent dans le package le PCH, jusque à côté du die cpu/graphique.
Sommaire
1 - Introduction
2 - LGA 1151 et Z170 Express
3 - Nouveautés côté CPU & OC
4 - Nouveautés côté GPU
5 - Core i7-6700K, i5-6600K, ASUS Z170-A et G.SKILL DDR4-3600
6 - CPU : DDR4 vs DDR3 en pratique
7 - CPU : Sandy Bridge vs Ivy Bridge vs Haswell vs Skylake à 4 G
8 - CPU : Overclocking en pratique
9 - HD Graphics 530 en pratique : Jeux
10 - HD Graphics 530 en pratique : OpenCL, QuickSync
11 - HD Graphics 530 en pratique : H.265, Consommation
12 - Protocole CPU, Consommation et efficacité énergétique
2 - LGA 1151 et Z170 Express
3 - Nouveautés côté CPU & OC
4 - Nouveautés côté GPU
5 - Core i7-6700K, i5-6600K, ASUS Z170-A et G.SKILL DDR4-3600
6 - CPU : DDR4 vs DDR3 en pratique
7 - CPU : Sandy Bridge vs Ivy Bridge vs Haswell vs Skylake à 4 G
8 - CPU : Overclocking en pratique
9 - HD Graphics 530 en pratique : Jeux
10 - HD Graphics 530 en pratique : OpenCL, QuickSync
11 - HD Graphics 530 en pratique : H.265, Consommation
12 - Protocole CPU, Consommation et efficacité énergétique
13 - CPU Rendu 3D : Mental Ray et V-Ray
14 - CPU Compilation : Visual Studio et MinGW-w64/GCC
15 - CPU Compression : WinRAR et 7-Zip
16 - CPU Encodage : x264 et x265
17 - CPU Traitement photo : Lightroom et DxO
18 - CPU IA d'échecs : Stockfish et Fritz
19 - CPU Jeux 3D : Crysis 3 et Arma III
20 - CPU Jeux 3D : X-Plane 10 et F1 2013
21 - CPU Jeux 3D : Watch Dogs et Total War : Rome 2
22 - CPU Jeux 3D : Company of Heroes 2 et Anno 2070
23 - Indices de performance CPU
24 - Conclusion
14 - CPU Compilation : Visual Studio et MinGW-w64/GCC
15 - CPU Compression : WinRAR et 7-Zip
16 - CPU Encodage : x264 et x265
17 - CPU Traitement photo : Lightroom et DxO
18 - CPU IA d'échecs : Stockfish et Fritz
19 - CPU Jeux 3D : Crysis 3 et Arma III
20 - CPU Jeux 3D : X-Plane 10 et F1 2013
21 - CPU Jeux 3D : Watch Dogs et Total War : Rome 2
22 - CPU Jeux 3D : Company of Heroes 2 et Anno 2070
23 - Indices de performance CPU
24 - Conclusion
Vos réactions
Contenus relatifs
- [+] 09/05: AMD Ryzen 7 2700, Ryzen 5 2600 et I...
- [+] 05/04: Pas de MAJ Microcode pour les Gulft...
- [+] 03/04: Intel lance la 2ème vague de sa 8èm...
- [+] 15/03: Microcode final pour Spectre chez I...
- [+] 07/02: Windows 10, Meltdown et Spectre : q...
- [+] 15/01: NZXT lance une carte mère ! (MAJ)
- [+] 22/12: Samsung grave de la DRAM en ''1ynm'...
- [+] 06/11: Des CPU Intel avec GPU... AMD !
- [+] 16/10: Deux jeux offerts avec les i7-7700K...
- [+] 09/10: Coffee Lake : avalanche de cartes m...