
Nvidia Titan X 12 Go en test : pour 1300, Pascal enfonce le clou !



GP102 : 12 milliards de transistors en 16 nm
Tout comme cela a été le cas sur la génération Maxwell, Nvidia a développé au moins 3 GPU Pascal "G" destinés aux GeForce, qu'elles en portent ou pas officiellement le nom, en suivant à peu près des proportions de type 1, 2 et 3. Nous avons déjà pu apercevoir le numéro 2 avec le GP104 de la GeForce GTX 1080, et récemment le numéro 1 avec le GP106 de la GeForce GTX 1060. C'est cette fois le numéro 3 que Nvidia introduit aujourd'hui avec la nouvelle Titan X. Prénommé GP102, ce GPU embarque pas moins de 12 milliards de transistors et peut être vu comme une version "GeForce" du GP100 spécifique aux accélérateurs Tesla.
Le GP102 reprend exactement la même architecture Pascal que les GP104 /GP106 et vous pourrez retrouver les détails la concernant dans les premières pages du dossier consacré à la GeForce GTX 1080.
Comme les autres GPU Pascal, il est produit pour Nvidia par TSMC sur le procédé de fabrication 16 nm FinFET Plus (FF+). Après plus de 4 ans de GPU fabriqués en 28 nm chez le même TSMC, le passage au 16 nm FF+ représente une évolution significative qui permet de nouveaux compromis plus avantageux en termes de consommation énergétique, de performances et de fonctionnalités. Comme les GP104 et GP106, le GP102 profitent de circuits qui ont été travaillés de manière à pouvoir atteindre de très hautes fréquences sans pour autant sacrifier le rendement énergétique.
 Le GP102 et ses 12 Go de mémoire GDDR5X interfacés en 384-bit.
Le GP102 et ses 12 Go de mémoire GDDR5X interfacés en 384-bit.Voici comment se situe le GP102 parmi les GPU récents :
- GP100 : 15.3 milliards de transistors pour 610 mm²
- GP102 : 12.0 milliards de transistors pour 471 mm²
- Fiji : 8.9 milliards de transistors pour 598 mm²
- GM200 : 8.0 milliards de transistors pour 601 mm²
- GP104 : 7.2 milliards de transistors pour 314 mm²
- GK110 : 7.1 milliards de transistors pour 561 mm²
- Hawaii : 6.2 milliards de transistors pour 438 mm²
- Polaris 10 : 5.7 milliards de transistors pour 232 mm²
- GM204 : 5.2 milliards de transistors pour 398 mm²
- Tonga : 5.0 milliards de transistors pour 368 mm²
- GP106 : 4.4 milliards de transistors pour 200 mm²
- GK104 : 3.5 milliards de transistors pour 294 mm²
- Polaris 11 : ???
- GM206 : 2.9 milliards de transistors pour 228 mm²
- Pitcairn : 2.8 milliards de transistors pour 212 mm²
- GK106 : 2.5 milliards de transistors pour 214 mm²
- Bonaire : 2.1 milliards de transistors pour 158 mm²
Le GP102 fait partie des gros GPU, même s'il se contente de 471 mm² et ne cherche pas à se rapprocher des limites du procédé de fabrication. Il représente probablement le plus gros GPU que l'architecture Pascal autorise dans le cadre d'une carte graphique raisonnablement refroidie.
GP102 : GP104 x 1.5
Pour comprendre l'architecture du GP102, quelques rappels s'imposent concernant la manière dont Nvidia schématise l'organisation interne de ses GPU. A un niveau élevé, ils se composent de un ou plusieurs GPC (Graphics Processing Cluster). Chacun contient un rasterizer chargé de projeter les primitives et de le découper en pixels.
A l'intérieur de ces GPC, nous retrouvons un ou plusieurs TPC (Texture Processor Cluster). Ne vous fiez pas à ce nom, vestige de précédentes architectures, le TPC est aujourd'hui décrit comme la structure qui représente le Polymorph Engine, nom donné à l'ensemble des petites unités fixes dédiées au traitement de la géométrie (chargement des vertices, tessellation etc.).
Enfin, au plus bas niveau, ces TPC intègrent un ou plusieurs SM (Streaming Multiprocessor) qui représentent le coeur de l'architecture. C'est à leur niveau que prennent place les unités de calcul (affreusement appelés "CUDA cores" par le marketing), les unités de texturing, les registres ou encore la mémoire partagée utile au GPU computing.
Sur base de ces éléments, voici comment est organisé le GP102 ainsi que la version qui en est exploitée sur la Titan X :

[ GP102 ] [ GP102 sur Titan X ? ] [ GP102 sur Titan X ? ]
Nous pouvons observer que le GP102 intègre 6 GPC, soit deux de plus que pour le GP104. Ils contiennent chacun 5 SM, comme pour les autres GPU de la famille. L'interface mémoire progresse également de 50% avec 96 ROP et un bus 384-bit.
Pour la Titan X, Nvidia a désactivé 2 SM, de manière à faciliter la production en autorisant la validation de certaines puces qui ont de petits défauts sur certains SM. Nous ne savons pas comment ces 2 SM sont répartis dans les GPC. A noter que s'ils sont désactivés dans le même GPC, le fillrate sera réduit de 96 à 92 pixels par cycle, ce qui semble être le cas sur notre échantillon de test. Nous ne savons pas si ce cas de figure est généralisé, mais l'impact sur les performances devrait être minime.
Voici pour comparaisons les spécificités de quelques GPU Nvidia sur 3 générations :
- GP100 : 6 GPC, 60 SM, 3840 FP32, 128 ROP ?, bus 4096-bit, 4096 Ko de L2
- GP102 : 6 GPC, 30 SM, 3840 FP32, 96 ROP, bus 384-bit, 3072 Ko de L2
- GM200 : 6 GPC, 24 SM, 3072 FP32, 96 ROP, bus 384-bit, 3072 Ko de L2
- GK110 : 5 GPC, 15 SM, 2880 FP32, 48 ROP, bus 384-bit, 1536 Ko de L2
- GP104 : 4 GPC, 20 SM, 2560 FP32, 64 ROP, bus 256-bit, 2048 Ko de L2
- GM204 : 4 GPC, 16 SM, 2048 FP32, 64 ROP, bus 256-bit, 2048 Ko de L2
- GK104 : 4 GPC, 8 SM, 1536 FP32, 32 ROP, bus 256-bit, 512 Ko de L2
- GP106 : 2 GPC, 10 SM, 1280 FP32, 48 ROP, bus 192-bit, 1536 Ko de L2
- GM206 : 2 GPC, 8 SM, 1024 FP32, 32 ROP, bus 128-bit, 1024 Ko de L2
- GK106 : 3 GPC, 5 SM, 960 FP32, 24 ROP, bus 192-bit, 384 Ko de L2
Par rapport au GM200, le GP102 apporte 25% d'unités de calcul et de texturing en plus, un chiffre qui tombe à 17% si nous prenons en compte la version exploitée sur la Titan X. Ce n'est pas très impressionnant vu sous ce seul aspect, mais il ne faut pas oublier que la fréquence va faire un bond énorme en avant :
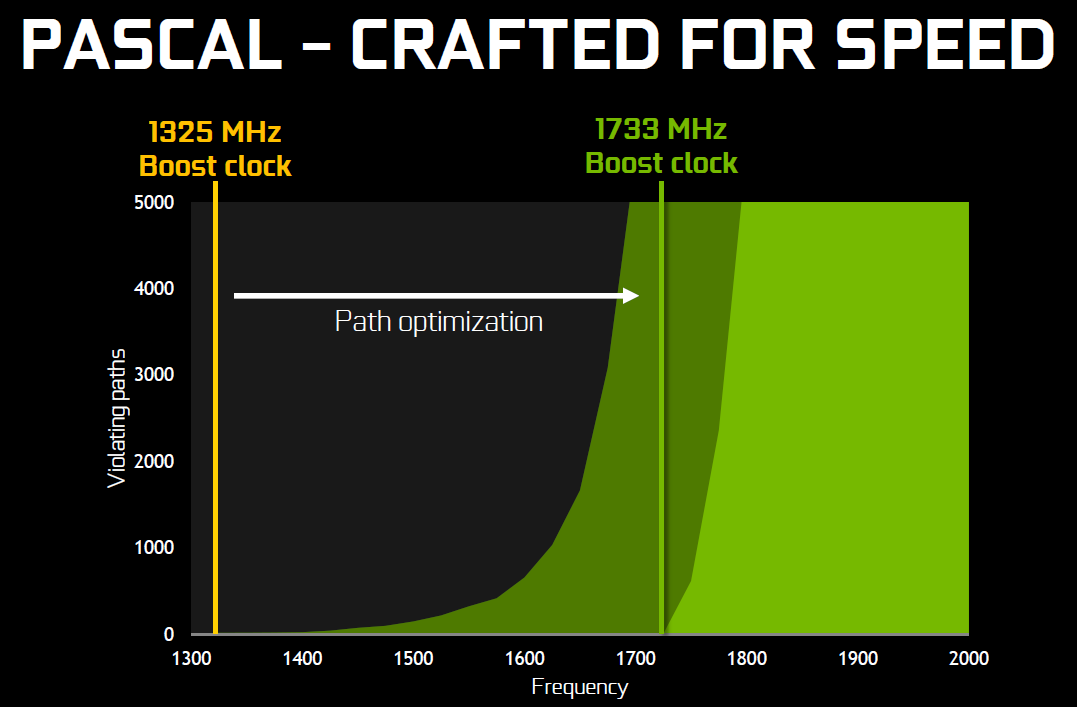
Nvidia nous avait indiqué ne pas avoir travaillé particulièrement les fréquences du GP100, qui profite simplement des gains automatiques liés au 16 nm, mais il en va tout autrement pour les GP102, GP104 et GP106. Nvidia explique avoir passé en revue le moindre circuit du GPU pour retravailler tout point faible qui entravait la montée en fréquence. De quoi pouvoir proposer une fréquence turbo de référence de 1530 MHz sur la Titan X (Pascal) soit un bond énorme de 42% par rapport aux 1075 MHz du GM200 qui équipe la GTX Titan X (Maxwell). Et cela tout en laissant une marge d'overclocking importante puisque ces GPU Pascal G sont capable d'atteindre 2 GHz, à condition de pouvoir alimenter et refroidir la bête bien entendu !
Pour accompagner cette évolution de la puissance du GPU, il faut évidemment une interface mémoire capable de l'alimenter correctement. Nvidia reprend ici la même GDDR5X que celle introduite avec la GTX 1080. Elle permet d'atteindre un débit par pin de 10 Gbps, 43% plus élevé que les 7 Gbps de la mémoire exploitée sur la génération précédente.
Et pour aller un peu plus loin dans la progression, Nvidia a pour rappel amélioré son système de compression sans perte du framebuffer. Plus spécifiquement, c'est le codage différentiel pour les couleurs, également appelé compression delta, qui progresse à nouveau. De quoi faire progresser la bande passante mémoire effective de 20% supplémentaires par rapport aux GPU Maxwell.
Pascal et deep learning
Le deep learning, ou l'apprentissage progressif par un réseau de neurones artificiels, est un débouché pour les GPU qui intéresse fortement Nvidia, même s'il s'agit d'un monde qui bouge beaucoup et dans lequel il est difficile de dire quelle solution s'imposera. Actuellement, les GPU Nvidia font parties des solutions les plus utilisées, notamment grâce à l'ensemble de bibliothèques et de SDK qui sont proposés aux développeurs. C'est le cas de cuDNN (CUDA Deep Neural Network) qui évolue progressivement et dont la version 5 promet des gains conséquents. Elle n'est cependant pas encore disponible publiquement pour la RC de CUDA 8.0 qui est optimisée pour les GPU Pascal.
Car les GPU Pascal ont certains avantages sur leurs prédécesseurs quand il s'agit de traiter les algorithmes liés au deep learning et particulièrement l'inférence qui consiste en l'exploitation par un "client" d'un réseau neuronal qui a été entraîné au préalable. C'est par exemple le cas du système de pilotage d'une voiture.
Alors que le GP100 dispose d'unités de calcul capable de traiter le format FP16 à double vitesse, pour doubler la puissance de calcul quand une faible précision est suffisante, les autres GPU Pascal, les GP102/GP104/GP106, profitent de deux instructions spécifiques à l'inférence : DP4A et DP2A. Il s'agit de produits scalaires avec accumulation qui ont la particularité d'exploiter des valeurs 8-bit et 16-bit associées dans des registres 32-bit. Avec un support natif de ces instructions, il est donc possible de traiter ces opérations 4x plus rapidement (INT8 avec DP4A) ou 2x plus rapidement (INT16 avec DP2A).
Voici la description qui en est faite dans le guide de CUDA 8.0 :
DP4A :
dp4a.atype.btype d, a, b, c;
.atype = .btype = { .u32, .s32 };
d = c;
// Extract 4 bytes from a 32bit input and sign or zero extend
// based on input type.
Va = extractAndSignOrZeroExt_4(a, .atype);
Vb = extractAndSignOrZeroExt_4(b, .btype);
for (i = 0; i < 4; ++i) {
d += Va[i] * Vb[i];
}
DP2A :
dp2a.mode.atype.btype d, a, b, c;
.atype = .btype = { .u32, .s32 };
.mode = { .lo, .hi };
d = c;
// Extract two 16-bit values from a 32-bit input and sign or zero extend
// based on input type.
Va = extractAndSignOrZeroExt_2(a, .atype);
// Extract four 8-bit values from a 32-bit input and sign or zer extend
// based on input type.
Vb = extractAndSignOrZeroExt_4(b, .btype);
b_select = (.mode == .lo) ? 0 : 2;
for (i = 0; i < 2; ++i) {
d += Va[i] * Vb[b_select + i];
}
Ces instructions DP4A et DP2A sont spécifiques au niveau de fonctionnalité CUDA sm_61 qui correspond aux GP102, GP104 et GP106. Le GP100 est de niveau sm_60 et ne supporte donc pas ces instructions, ce qui est étrange même s'il est plutôt dédié à l'entraînement des réseaux neuronaux qu'à l'inférence.
Si Nvidia met fortement en avant ce point avec la Titan X, ce n'est pas une fonctionnalité que lui est exclusive. Toutes les GeForce et Quadro Pascal peuvent également profiter de ces instructions à leur débit maximal.
2 - GP102 : 12 milliards de transistors, DP4A et DP2A
3 - Spécifications et Direct3D 12
4 - La Titan X (Pascal)
5 - Protocole de test
6 - Performances théoriques : pixels
7 - Performances théoriques : géométrie
8 - Consommation, efficacité énergétique
9 - Nuisances sonores, températures, photos IR
10 - Benchmark : 3DMark Fire Strike et Time Spy
11 - Benchmark : Anno 2205
12 - Benchmark : Ashes of the Singularity
13 - Benchmark : Battlefield 4
14 - Benchmark : Crysis 3
15 - Benchmark : DiRT Rally
17 - Benchmark : Dying Light
18 - Benchmark : Fallout 4
19 - Benchmark : Far Cry Primal
20 - Benchmark : Grand Theft Auto V
21 - Benchmark : Hitman
22 - Benchmark : Project Cars
23 - Benchmark : Rise of the Tomb Raider
24 - Benchmark : Star Wars Battlefront
25 - Benchmark : The Division
26 - Benchmark : The Witcher 3 Wild Hunt
27 - Récapitulatif des performances
28 - Overclocking et fréquences
29 - Conclusion
Contenus relatifs
- [+] 04/05: Nvidia abandonne son GeForce Partne...
- [+] 18/04: ASUS AREZ, l'effet GeForce Partner ...
- [+] 10/04: Nvidia : fin du support Fermi et 32...
- [+] 27/03: Pilotes Radeon et GeForce pour Far ...
- [+] 20/03: Pilotes GeForce 391.24 pour Sea of ...
- [+] 20/03: Microsoft annonce DirectX Raytracin...
- [+] 08/03: 3 millions de GPU vendus pour le mi...
- [+] 09/02: Résultats records pour Nvidia
- [+] 30/01: Pilotes GeForce 390.77 pour Metal G...
- [+] 25/01: AMD annonce la restructuration de R...