
AMD Ryzen 7 1800X en test, le retour d'AMD ?



Pour bien comprendre le profil de performance de Ryzen, il est important de revenir sur son architecture. La plupart des détails avaient été dévoilés précédemment durant la conférence HotChips, mais de nouveaux détails - les plus importants - ont été dévoilés ces derniers jours (voir ces toutes dernières heures...) par AMD.
Le jeu d'instructions

Avant d'entrer dans les détails, faisons le point sur les jeux d'instructions. AMD se met à jour en supportant à peu près toutes les extensions existantes, on retrouve ainsi AVX et AVX2, l'accélération des instructions SHA, mais aussi des choses plus originales comme les instructions de mémoire transactionnelle (TSX), introduites avec assez peu de succès par Intel pour Haswell.
AMD rajoute en prime deux nouvelles instructions, dont une pour libérer une ligne de cache, et l'autre pour combiner des pages mémoires. AMD est donc aligné sur ce que proposait Intel jusque Broadwell, Skylake n'ajoutant que SGX et MPX dont l'utilisation est plus particulière, servant comme on pouvait le craindre à la mise au point de DRMs !
Les instructions FMA4, XOP et TBM, introduites par AMD sur Bulldozer/Piledriver et non utilisées par Intel, sont par contre abandonnées.
Un coeur Zen en pratique
Le responsable (post Jim Keller) de l'architecture Zen, Mike Clark, la décrit lui même comme une architecture "équilibrée" (il a utilisé précisément le mot balanced).

Sur ce schéma on retrouve les grandes lignes d'un coeur Zen. Pour rappel ce schéma commence en haut à droite, avec la partie Branch Prediction où les instructions arrivent avant d'être décodées. On notera que chaque coeur dispose d'un cache L1 d'instructions de 64 Ko, et d'un cache L1 de données de 32 Ko. Chaque coeur dispose enfin d'un cache L2 de 512 Ko.
Le point important à retenir sur ce schéma est qu'AMD distingue clairement le chemin "Integer" (bloc rouge, opérations sur les nombres entiers, et toutes les opérations classiques comme les boucles, etc...) et le chemin "Floating Point" (bloc orange, opération sur les nombres à virgules plus gourmandes).
Le choix de séparer les opérations entières et flottantes est une particularité de l'architecture Zen. A titre de comparaison, Intel mélange toutes ses unités de calcul sur des ports (des files indépendantes), ne séparant pas le traitement des instructions entières et flottantes.
Par le passé, cette scission était nécessaire pour AMD, l'architecture Bulldozer regroupait dans un module deux blocs "Integer" et partageait un seul bloc "Floating Point". AMD a voulu conserver l'idée de la séparation tout en résolvant les problèmes restant, nous y reviendrons.
Le front-end

Tout en haut du graphique d'architecture précédent, on retrouve la partie du front end qui récupère (fetch) les instructions. Son rôle est d'extraire les instructions à exécuter, la prédiction de branchements (on parle de conditions, si elle est vraie, effectue ceci, sinon, effectue cela) tentant de déterminer à l'avance le résultat de la condition pour pouvoir commencer a travailler sur la bonne "branche". Cette prédiction est effectuée par un perceptron , un type de réseau neuronal simple. Deux branches par cycles peuvent être évaluées, par le perceptron,
Le TLB (un cache pour traduire les adresses mémoires virtuelles) est intégré et tout le mécanisme a été amélioré pour être plus efficace en ajoutant une table pour les adresses de retour des branches (l'endroit ou l'exécution doit se poursuivre à la fin de la branche, le bloc d'instruction exécuté après la condition).
Décodage des instructions
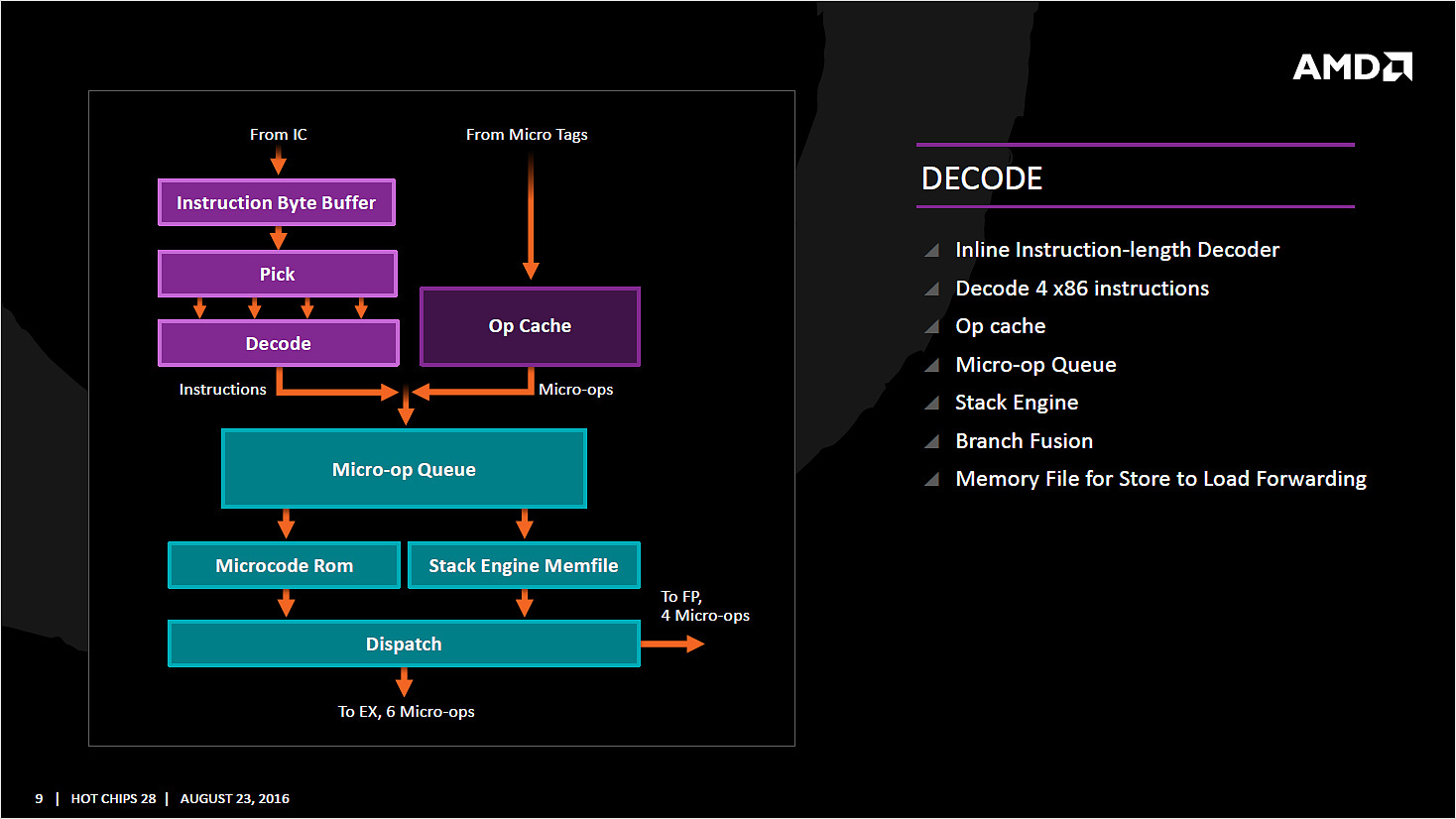
Les instructions récupérées vont ensuite être placées dans le cache d'instruction avant d'être décodées. C'est ici que les instructions x86 sont lues par le processeur, qui les transforme en des micro-opérations (micro-op) qui seront exécutées par la suite dans le pipeline. On rappellera que le jeu d'instructions x86 est particulièrement large (CISC), pour plus d'efficacité les processeurs travaillent en interne (sur les unités d'exécution plus bas) sur un jeu de micro-opérations réduit (RISC).
Les décodeurs sont capables de traiter jusque quatre instructions par cycle (c'est équivalent à ce que propose Intel sur Haswell et Skylake) qui sont transformées en jusque 6 micro-op. Certaines instructions peuvent être fusionnées en une seule micro-op (notamment celles de branchements), là encore les similarités avec ce que propose Intel sont fortes.
Comme chez Intel, AMD utilise un cache qui stocke la correspondance entre une instruction décodée et la micro opération qui en est issue. Le jeu d'instructions x86 comportant un bon millier d'instructions de tailles variables, l'idée est de garder en cache les instructions les plus récemment décodées en mémoire pour pouvoir les traduire automatiquement en micro-op sans repasser par la case décodage. Cela permet d'ajouter plusieurs micro-op supplémentaires par cycle à traiter.
Par rapport à ses architectures précédentes, AMD dit avoir "significativement" augmenté la taille de son Op Cache et que ce seul changement est responsable d'une grande partie des gains d'IPC et de consommation.
On y retrouve une logique semblable aux évolutions architecturales que l'on a vu à la concurrence : le front-end joue un rôle excessivement important dans les architectures x86 sur les performances du reste de la puce et il est important de le peaufiner. Le voir soigné de la sorte est plutôt prometteur sur l'IPC de Zen, ce que nous vérifierons en pratique dans quelques pages !
On notera que les micro-ops sont placées dans une file, ou plus exactement deux files. AMD implémente pour rappel le SMT (Simultaneous Multi Threading) qui permet de gérer deux threads par coeur (l'HyperThreading est le nom marketing de l'implémentation SMT d'Intel). La file de micro-op est ainsi scindée en deux (ce qui est identique à ce que fait Intel pour Sandy Bridge et Skylake, Haswell ayant utilisé une file commune). Les instructions vont enfin être dispatchées vers les ports. En pratique 10 micro ops peuvent être envoyées (6 vers la partie "Integer" de la puce, 4 vers la partie "Floating Point"), soit deux de plus que sur Haswell (Intel ne nous a pas donné l'information pour Skylake).
Les unités d'exécution

Les micro-op vont être dispatchées vers 6 files d'exécution (l'équivalent des ports d'Intel) dont la taille a été significativement augmentée (14 entrées par file, soit 84 pour cette partie de la puce, Skylake en compte 97 en tout mais il faut ajouter celles dédiées aux opérations FP, nous y reviendrons).
AMD dispose de deux files dédiées aux opérations mémoires (AGU, address generation unit) qui asservissent un système de lecture/écriture mémoire (Load/Store) sur lequel on reviendra.
Quatre files sont dédiées aux instructions de "calcul" et de branchements. AMD les appelle ALU sur son schéma, il s'agit en pratique d'une série d'unités d'exécution. Chaque ALU regroupe au minimum la possibilité de traiter les instructions logiques de base. AMD ne le détaille pas sur son schéma, mais d'autres unités sont présentes.
Le constructeur nous a confirmé que deux des ALU contiennent une unité dédiée au branchement, une ALU contient une unité gérant les divisions, une ALU contient une unité gérant les multiplications entières, et enfin une ALU contient une unité dédié au CRC32.
L'efficacité de ces unités dépendra en grande partie de la capacité du front-end à les alimenter, mais sur le papier là encore, le design semble largement adéquat pour maximiser le nombre d'instructions traitées par cycle.
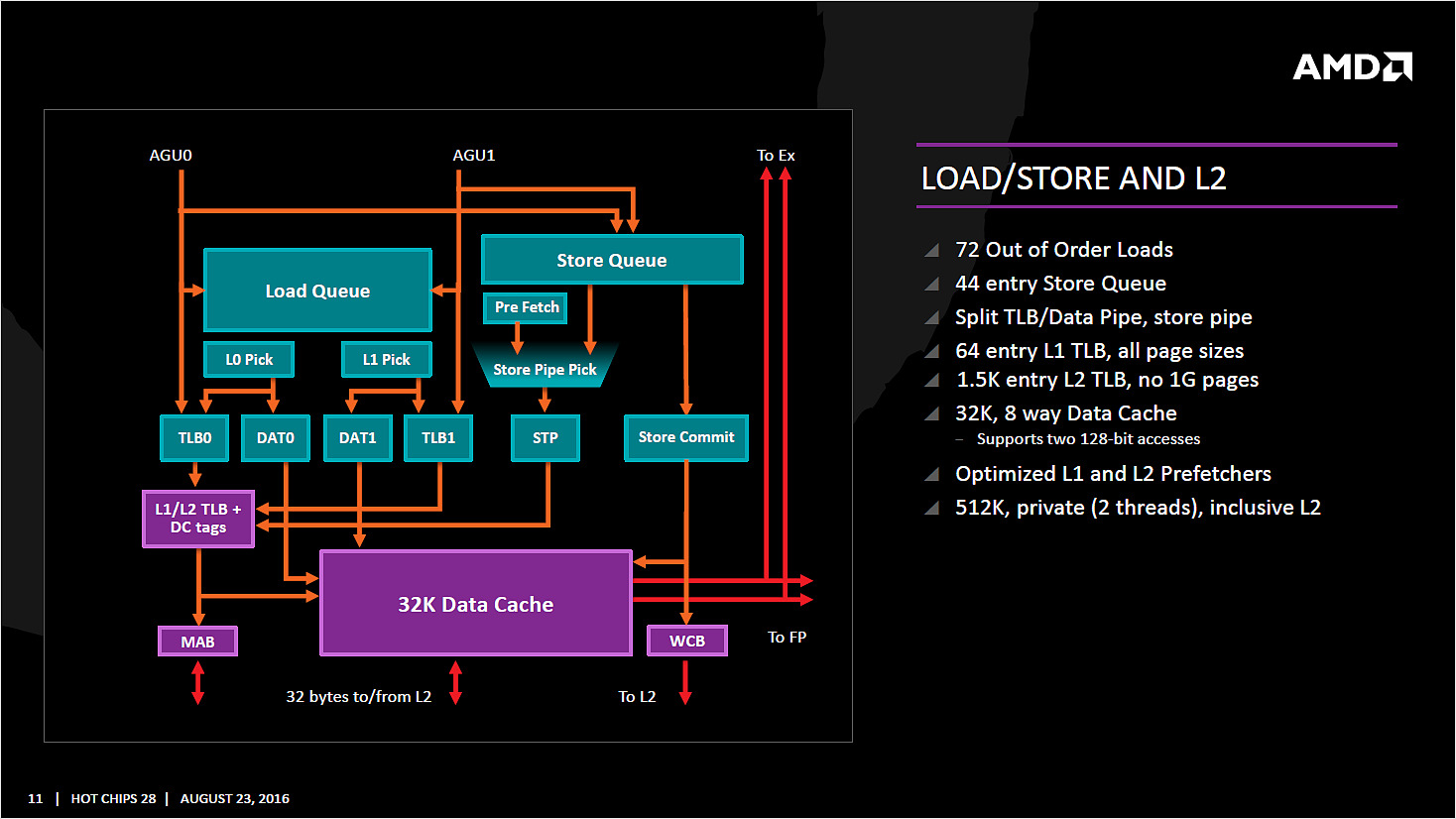
Comme nous le disions, les AGU asservissent les unités qui lisent et écrivent les données dans le sous-système de cache. On retrouve des longueurs de files comparables à ce que l'on a chez le concurrent (72/44 pour Zen, 72/42 pour Haswell et 72/56 pour Skylake).
Pour les chargements, AMD rentre dans le détail en indiquant qu'un des autres points faibles de ses architectures précédentes était lié aux opérations de chargement mémoire. Deux accès séparés de 128 bits en lecture sont désormais possibles, et les unités peuvent accéder en simultanée au cache L1 et au cache TLB pour maximiser le débit, et ainsi streamer les données rapidement du cache L2 vers le L1.
L'efficacité des prefetchers (qui tentent de récupérer les informations en avance du moment ou le processeur en aura besoin) est indiquée comme meilleure sans plus de détails.

Si l'on revient en arrière, le dispatcher de micro-op pouvait envoyer jusque 6 instructions vers la partie Integer, et quatre vers la partie Floating point.
Le scheduler dédié aux unités flottantes dispose ici de 96 entrées ce qui nous donne un total de 180 entrées par coeur (contre 97 pour Skylake). Il s'agit même en pratique d'un double scheduler.
C'était l'un des points faibles du design séparé que l'on évoquait plus haut : sur Bulldozer un scheduler trop petit sur la partie FP pouvait arriver à bloquer la partie Integer du CPU, un cas qui visiblement était assez fréquent.
Avec un double scheduler, AMD dit avoir résolu le problème en pratique. On disposerait désormais bel et bien de deux blocs réellement indépendants pouvant travailler en parallèle (et ne se bloquant plus l'un l'autre).
Quatre unités d'exécution FP 128 bits sont donc présentes, deux dédiées plus spécifiquement aux multiplications et deux aux additions. Elles peuvent être combinées pour réaliser jusque 2 FMA 128 bits en parallèle par cycle. Sur ce point AMD est en retrait puisque depuis Haswell, les architectures Intel peuvent effectuer deux FMA 256 bits par cycle et ont donc l'avantage dans ce type de charge en AVX2, certes assez rare en pratique. C'est un point sur lequel l'architecture de Zen peut être limitée.
Les caches mémoires
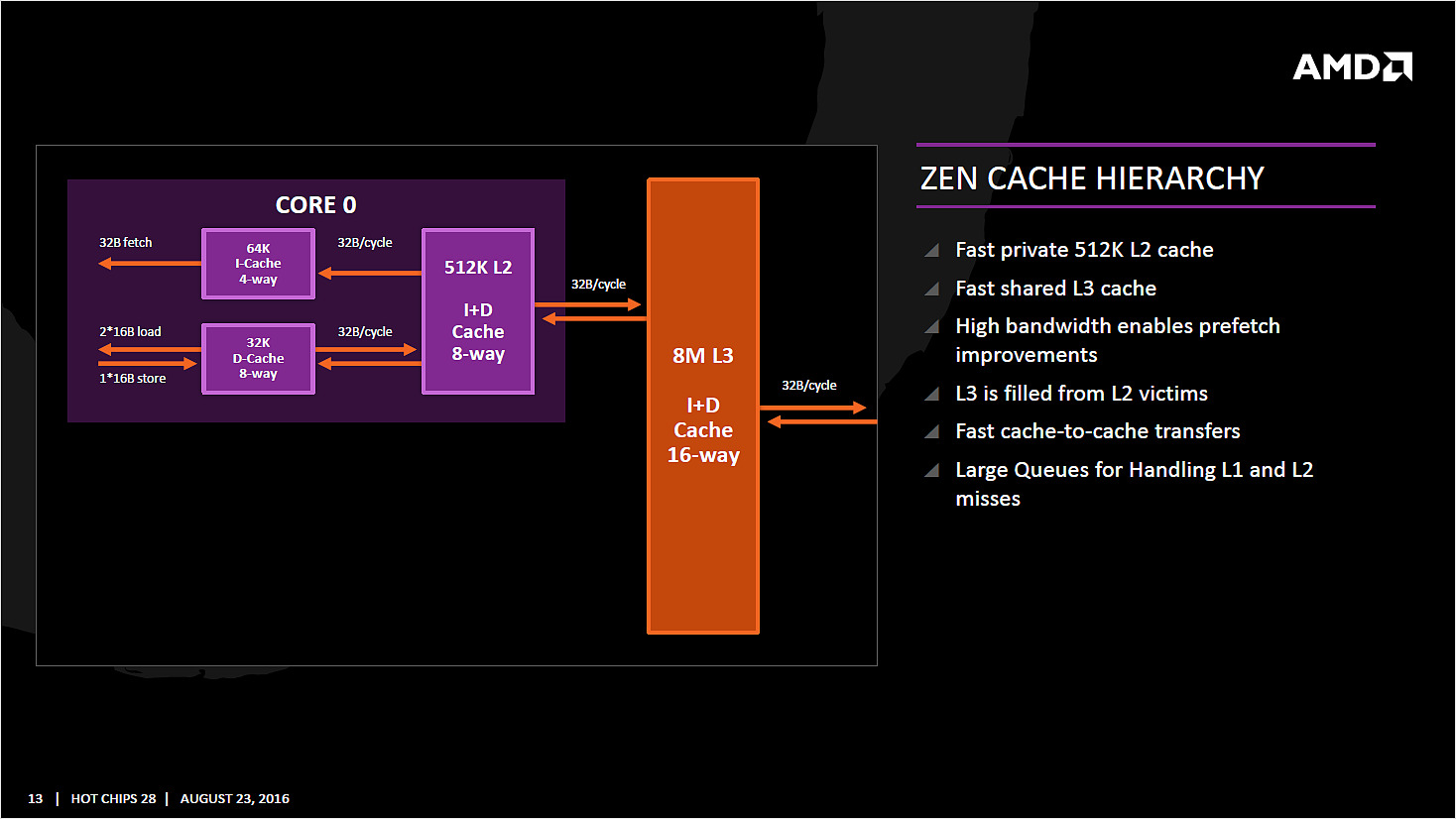
Chaque coeur dispose bien entendu de ses propres caches. On retrouve pour chaque coeur un cache L1 d'instructions de 64 Ko, et un cache L1 de données de 32 Ko. On y retrouve également un cache de niveau 2 de 512 Ko. Un des changements principaux est sur le type de cache utilisé : AMD a choisi d'utiliser un cache L1 write back au lieu du write through utilisé précédemment, s'alignant là aussi sur ce que fait Intel.
Cela devrait assurer une bien meilleure bande passante mémoire pour le L1 par rapport aux architectures précédentes d'AMD.
2 - Zen, une architecture équilibrée
3 - Ryzen, un SoC Zen 8 coeurs
4 - Ryzen 7 1800X, la gamme, DDR4
5 - Chipsets, plateforme AM4 et ASUS Crosshair VI Hero
6 - Piledriver, Zen et Broadwell-E à 3 GHz
7 - Impact du SMT/HT
8 - Retour sur le SMT et mode High Performance
9 - Overclocking en pratique
10 - Consommation, efficacité énergétique et "TDP"
11 - Protocole de test
12 - Compression : 7-Zip et WinRAR
13 - Compilation : Visual Studio et MinGW-w64/GCC
15 - IA d'échecs : Stockfish et Komodo
16 - Traitement photos : Lightroom et DxO Optics Pro
17 - Rendu 3D : Mental Ray et V-Ray
18 - Jeux 3D : Project Cars et F1 2016
19 - Jeux 3D : Civilization VI et Total War : Warhammer
20 - Jeux 3D : GTA V et Watch Dogs 2
21 - Jeux 3D : Battlefield 1 et The Witcher 3
22 - Indices de performance
23 - Retour sur le sous-système mémoire
24 - Retour sur le sous-système mémoire, suite
25 - Conclusion
Contenus relatifs
- [+] 09/05: AMD Ryzen 7 2700, Ryzen 5 2600 et I...
- [+] 23/04: MAJ de notre test des Ryzen 7 2700X...
- [+] 19/04: AMD Ryzen 2700X et 2600X : Les même...
- [+] 13/04: Les AMD Ryzen Pinnacle Ridge en pré...
- [+] 14/03: Des failles de sécurité spécifiques...
- [+] 08/03: Quatre Ryzen+ Pinnacle Ridge pour a...
- [+] 21/02: AMD Ryzen 5 2400G et Ryzen 3 2200G ...
- [+] 12/02: AMD lance les APU Ryzen 5 2400G et ...
- [+] 09/02: AMD Ryzen 3 2200G et 5 2400G : MAJ ...
- [+] 07/02: Windows 10, Meltdown et Spectre : q...