Les contenus liés au tag Vega
Afficher sous forme de : Titre | FluxAMD Vega au premier semestre 2017
La HBM2 Hynix dispo ce troisième trimestre
GDC: AMD dévoile sa roadmap GPU : Polaris, Vega, Navi
Architecture Vega 10 : AMD lève le voile



A l'occasion du CES, AMD nous en dit un petit peu plus sur le futur GPU Vega 10 et dévoile quelques points techniques de son architecture qui vont permettre d'améliorer le rendement en jeu et de monter en puissance dans le monde de l'intelligence artificielle.

Suivant la même formule que l'an passé avec Polaris, AMD a décidé de nous aider à patienter en dévoilant quelques éléments de sa nouvelle architecture GPU, dont le premier exemplaire, Vega 10, vise le haut de gamme et est annoncé pour le premier semestre 2017.
Au menu : une refonte du sous-système mémoire pour pouvoir prendre en charge une masse de données toujours plus imposantes, de nouveaux moteurs géométriques pour mieux traiter des décors plus riches, de nouveaux moteurs de rastérisation pour calculer moins de pixels inutiles et des unités de calcul plus efficaces pour donner un coup de boost à leurs performances.
A travers cette annonce, AMD explique avec quelques détails techniques comment ces évolutions ont été mises en place.

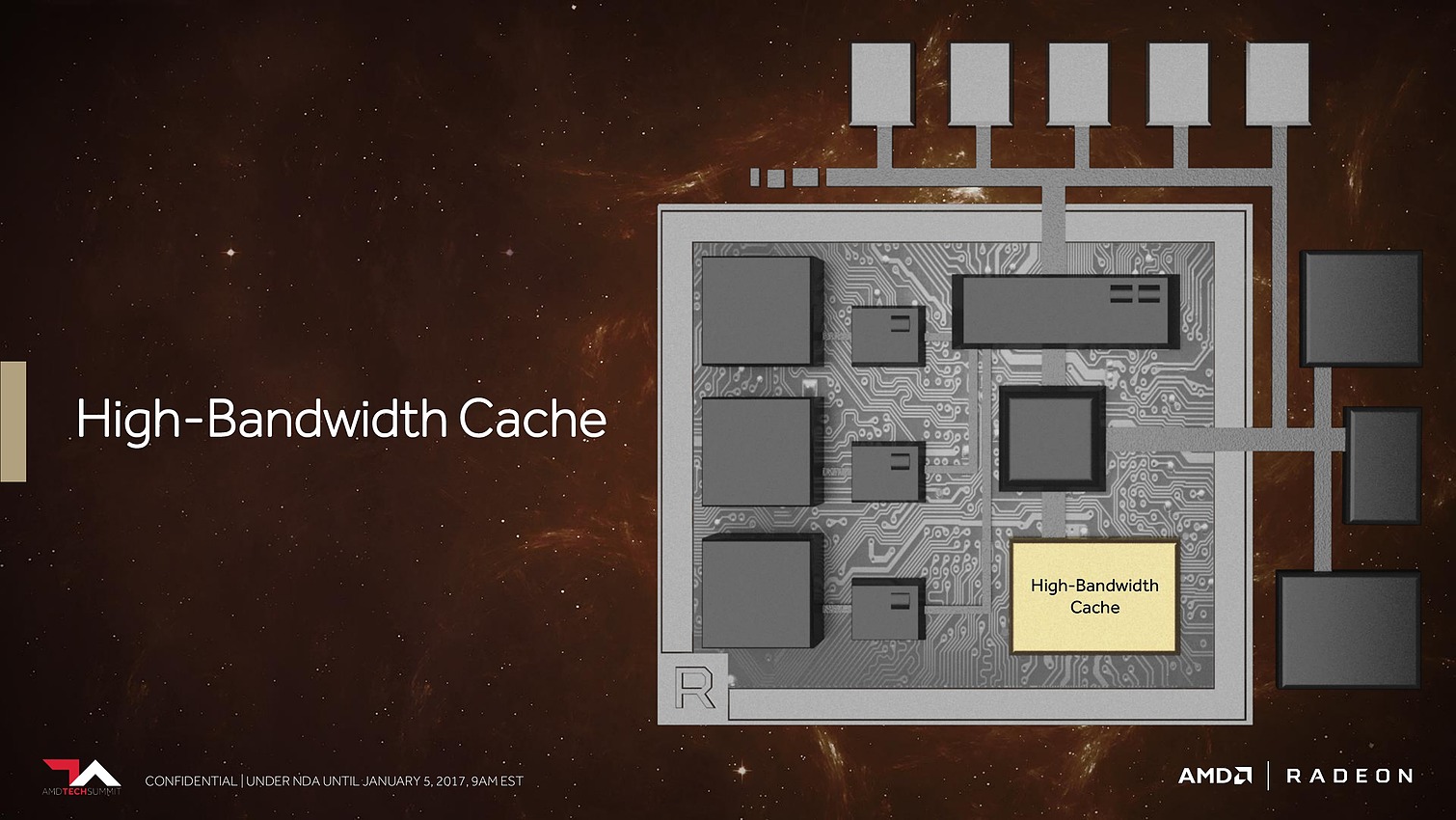




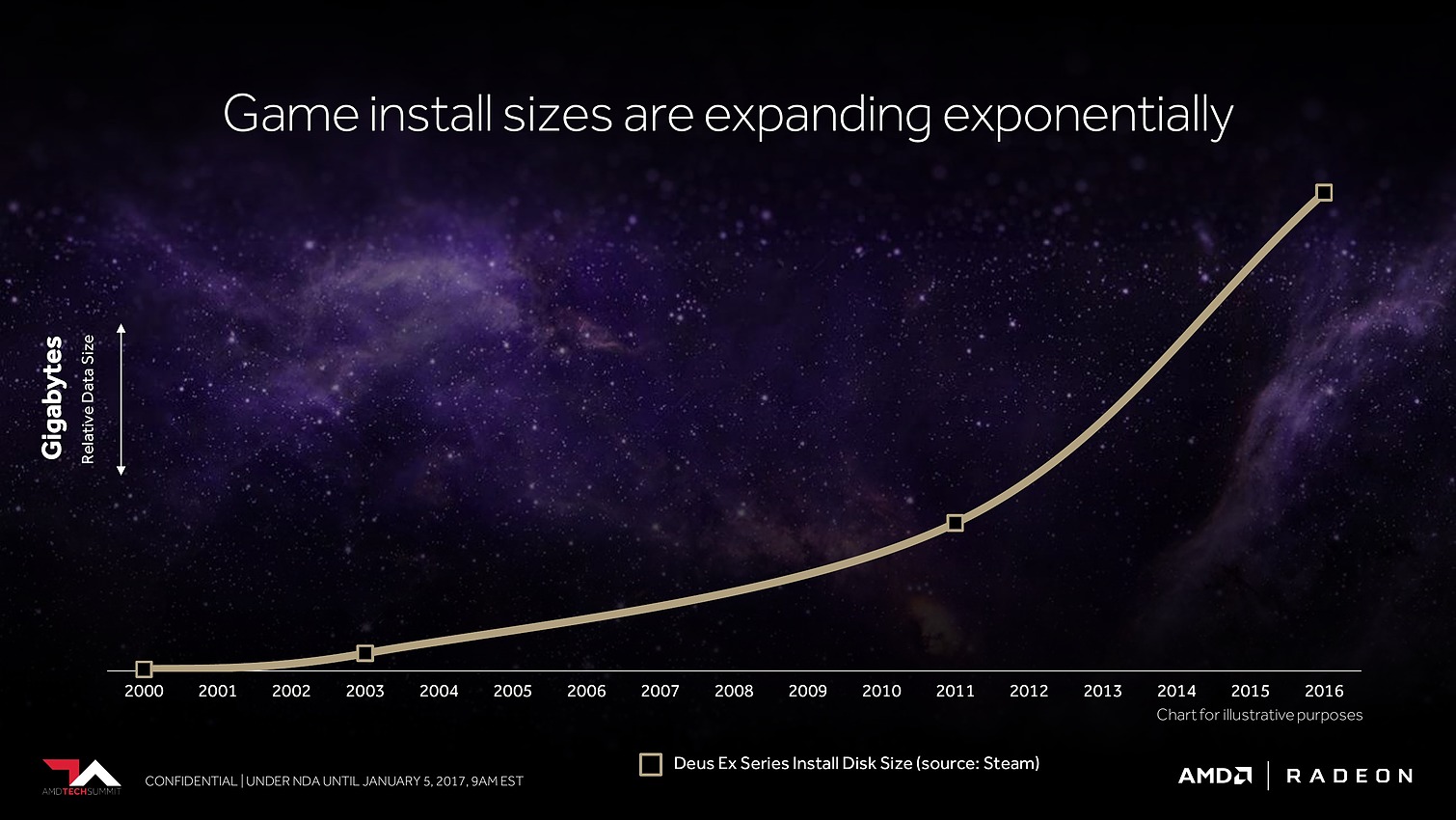
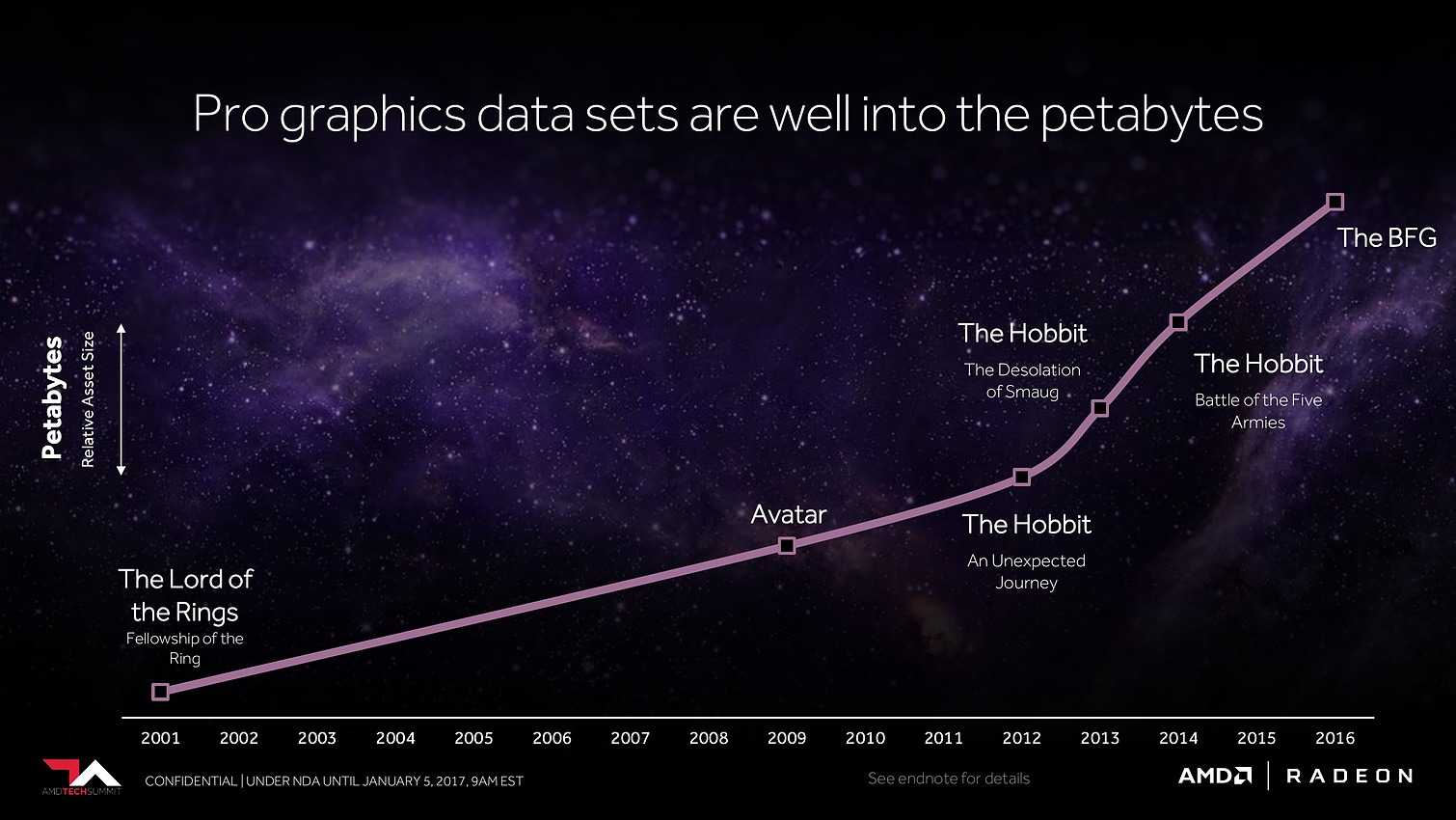
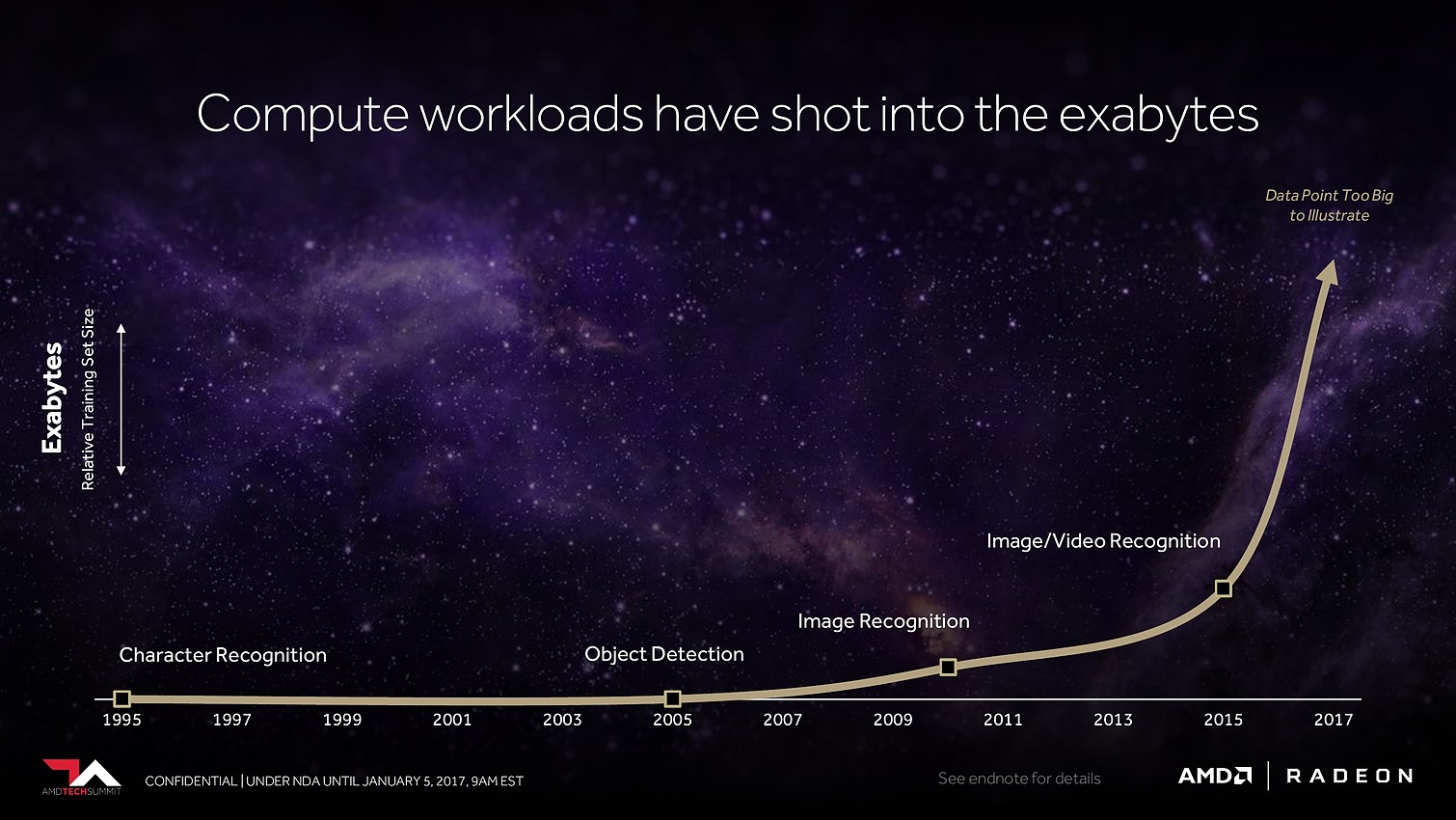
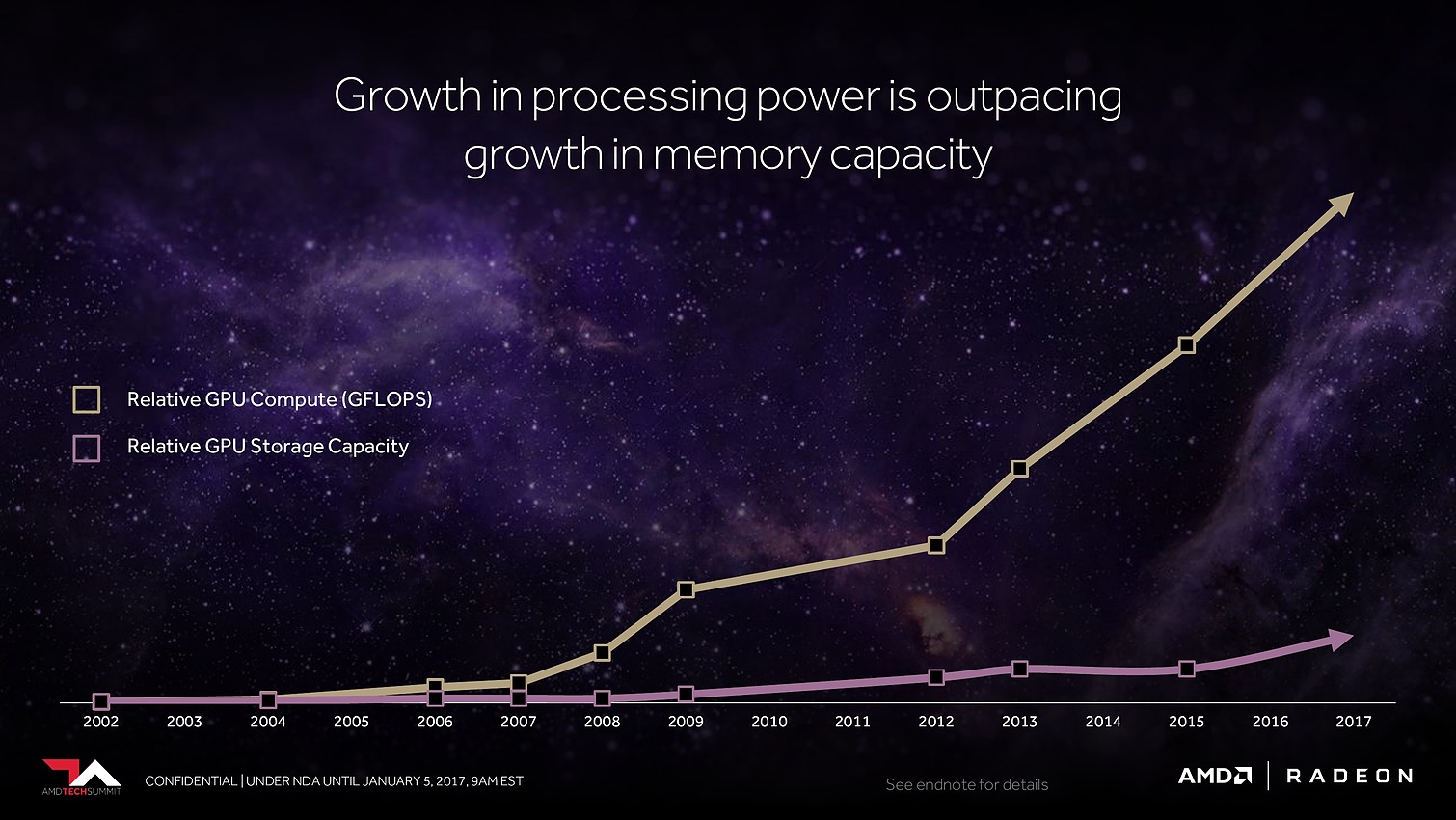
Avec Vega, AMD annonce avoir mis en place l'architecture mémoire pour GPU la plus avancée du marché, pour pouvoir répondre aux besoins actuels et futurs dans les domaines où la taille des data sets est en train d'exploser. Il serait déjà question de pétaoctets dans l'animation 3D voire même d'exaoctets dans le GPU computing et l'intelligence artificielle. Pour s'y attaquer, Vega est capable d'adresser jusqu'à 512 To grâce à un espace de mémoire virtuelle étendu (49-bit) qui va au-delà des 256 To du x64 (48-bit).
Bien entendu, le GPU Vega 10 ne recevra pas autant de mémoire dédiée. Il sera associé à 2 modules de mémoire HBM2 pour un bus combiné de 2048-bit. Sur base des premiers modules disponibles qui sont de type 4 Go (4-Hi), Vega 10 sera ainsi associé à 8 Go de HBM2, mais pourra passer à 16 Go quand les modules 8-Hi seront disponibles.
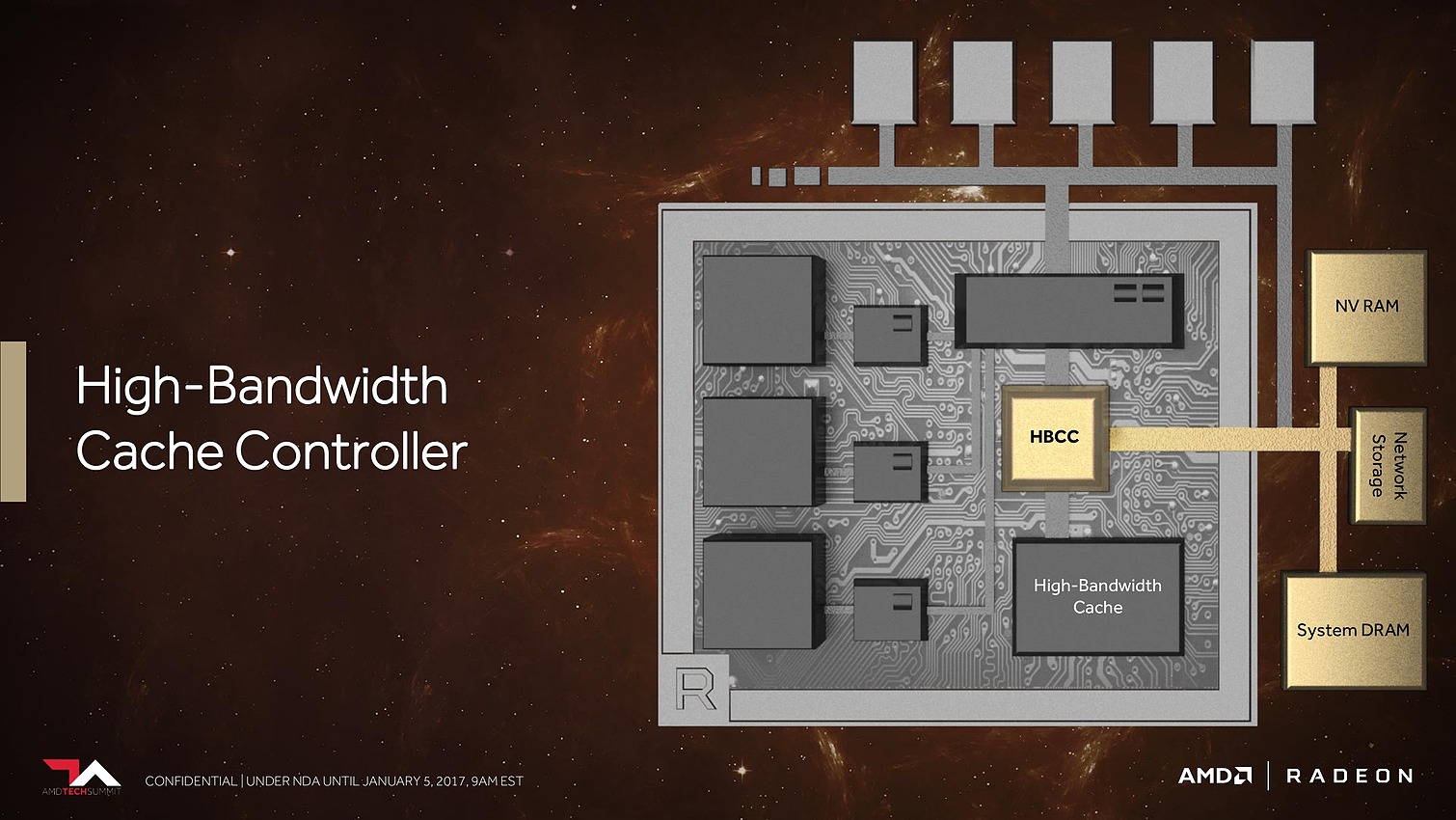
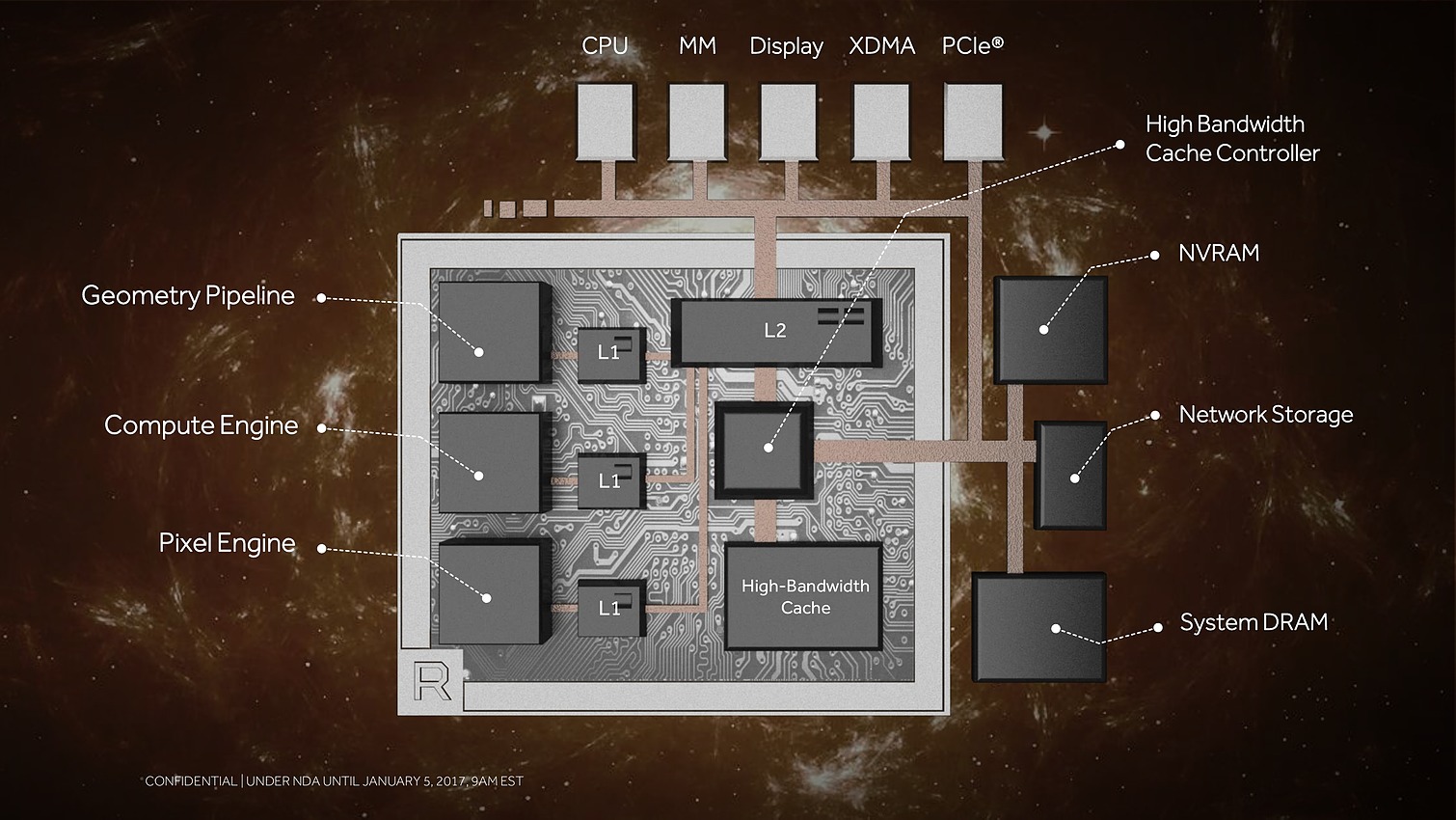
8 Go, voire 16 Go, c'est bien peu par rapport aux data sets auxquels AMD compte s'attaquer. Pour pouvoir s'y attaquer plus efficacement, AMD a revu le contrôleur mémoire qui s'appelle dorénavant High Bandwidth Cache Controller alors que la mémoire HBM2 est présentée comme un cache local (High Bandwidth Cache). Le HBCC a été conçu et optimisé pour piloter les mouvements de données à partir de l'énorme espace adressable. Qu'elles se situent dans la mémoire système, dans de la flash rattachée au GPU ou ailleurs sur le réseau, le but est faire en sorte qu'à chaque instant un maximum de données utiles se retrouvent dans la HBM2.
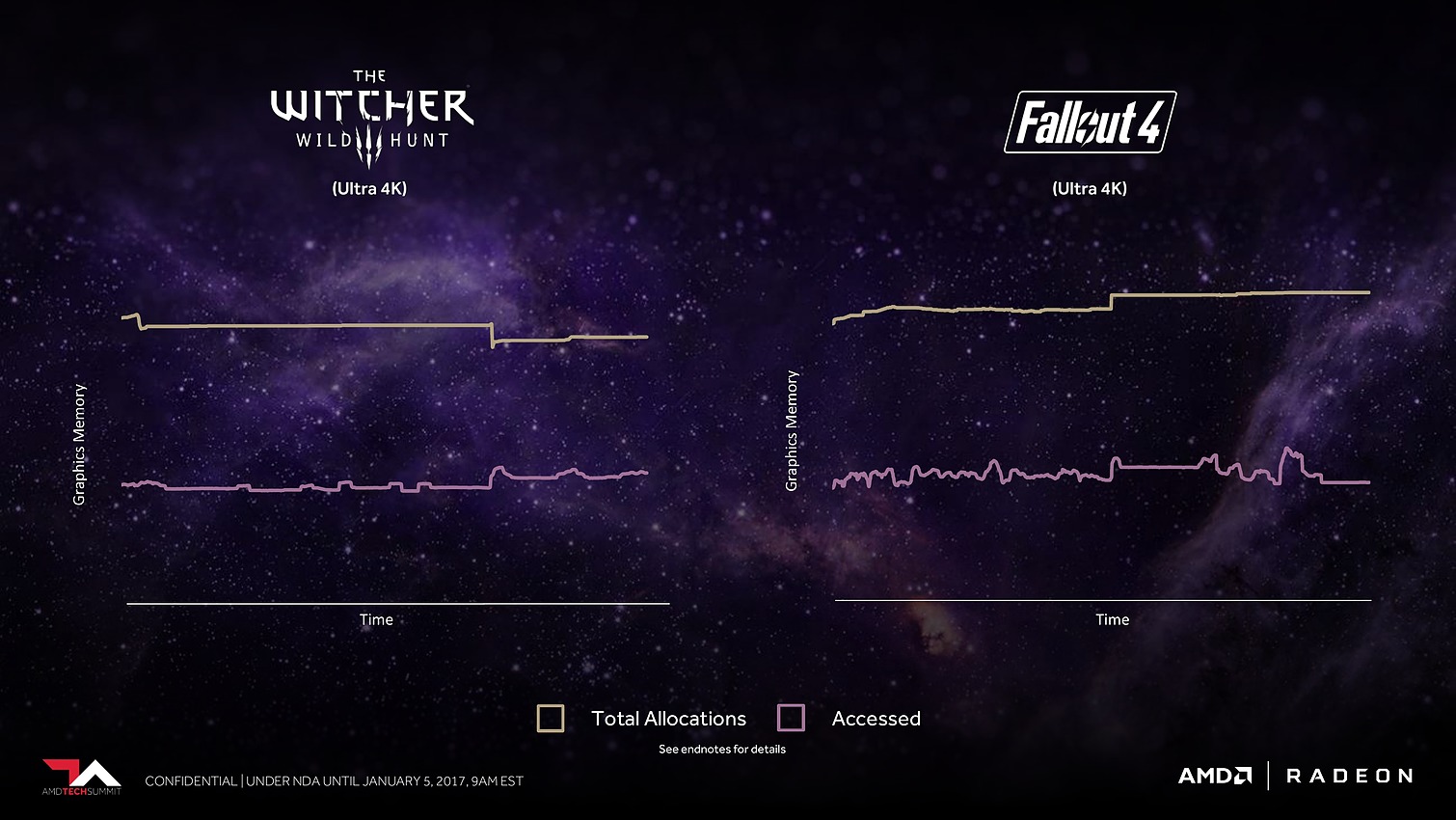
C'est évidemment principalement important dans le monde professionnel, mais AMD en parle également au niveau des jeux vidéo, probablement pour anticiper les critiques par rapport à une mémoire de "seulement" 8 Go contre 12 Go sur une Titan X de Nvidia. A ce sujet, AMD explique que pour chaque image générée moins de la moitié de la mémoire utilisée est réellement exploitée. Il y a donc des opportunités d'optimisation et le HBCC est annoncé comme capable de faire mieux que les contrôleurs et pilotes classiques.
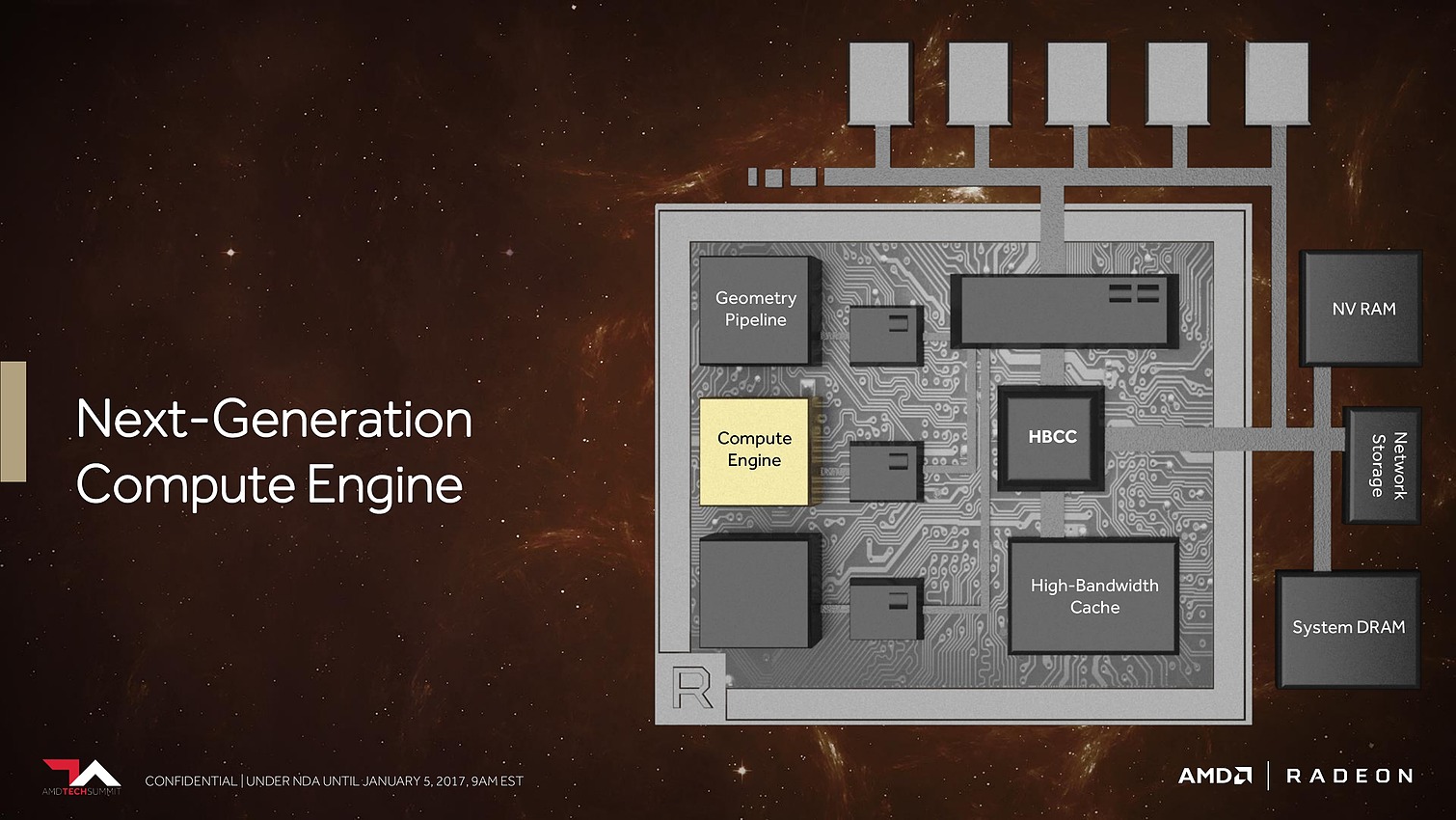



Ensuite, ce sont évidemment les unités de calcul qui vont recevoir quelques améliorations. AMD explique tout d'abord les avoir retravaillées pour autoriser une montée en fréquence significative, et réduire l'écart avec Nvidia sur ce point. Mais ce n'est pas tout et le taux d'IPC devrait également progresser. AMD en dit peu à ce niveau et s'est contenté de nous indiquer avoir élargi le cache d'instructions, ce qui boosterait notamment le débit d'opérations sur 3 opérandes. Reste évidemment à voir à quel niveau se situeront les gains en pratique pour ces Next-Gen Compute Units (NCU).
L'autre grosse nouveauté concernant les unités de calcul est le packed math qui représente le support natif de la démi précision ou FP16. Pour rappel, les GPU GCN 3 (Tonga/Fiji) et GCN4 (Polaris), supportent déjà le FP16 mais uniquement pour gagner de la place au niveau des registres, les opérations étant traitées par les unités de calcul FP32 à débit identique.
Avec Vega, chaque SIMD d'unité de calcul FP32 pourra travailler sur des vecteurs 2-way en FP16. C'est identique à ce que fait Nvidia sur le GP100 ou sur Tegra et cela permet de doubler la puissance de calcul en demi précision si le compilateur arrive à extraire des paires d'opérations à traiter en parallèle. AMD précise que si ce n'est pas le cas, des gains pourront malgré tout ressortir au niveau de la consommation énergétique, et que son approche permet de gérer indépendamment les parties hautes et basses des registres pour plus d'efficacité.
Enfin, AMD a ajouté le support du calcul en 8-bit mais il est spécifique au deep learning, comme le fait Nvidia sur GP102/104/106/107). Contrairement au FP16 il ne s'agit donc pas d'un support généralisé mais d'une ou de quelques instructions spécifiques telles que DP4A (produit scalaire avec accumulation).
Au final, AMD parle donc par NCU de 128 ops 32-bit par cycle (= 64 FMA FP32 comme sur tous les GPU GCN), 256 ops 16-bit par cycle (= 128 FMA FP16) et de 512 ops 8-bit par cycle (= 64 DP4A). Aucune information concernant le débit en FP64 qui est juste annoncé comme configurable.
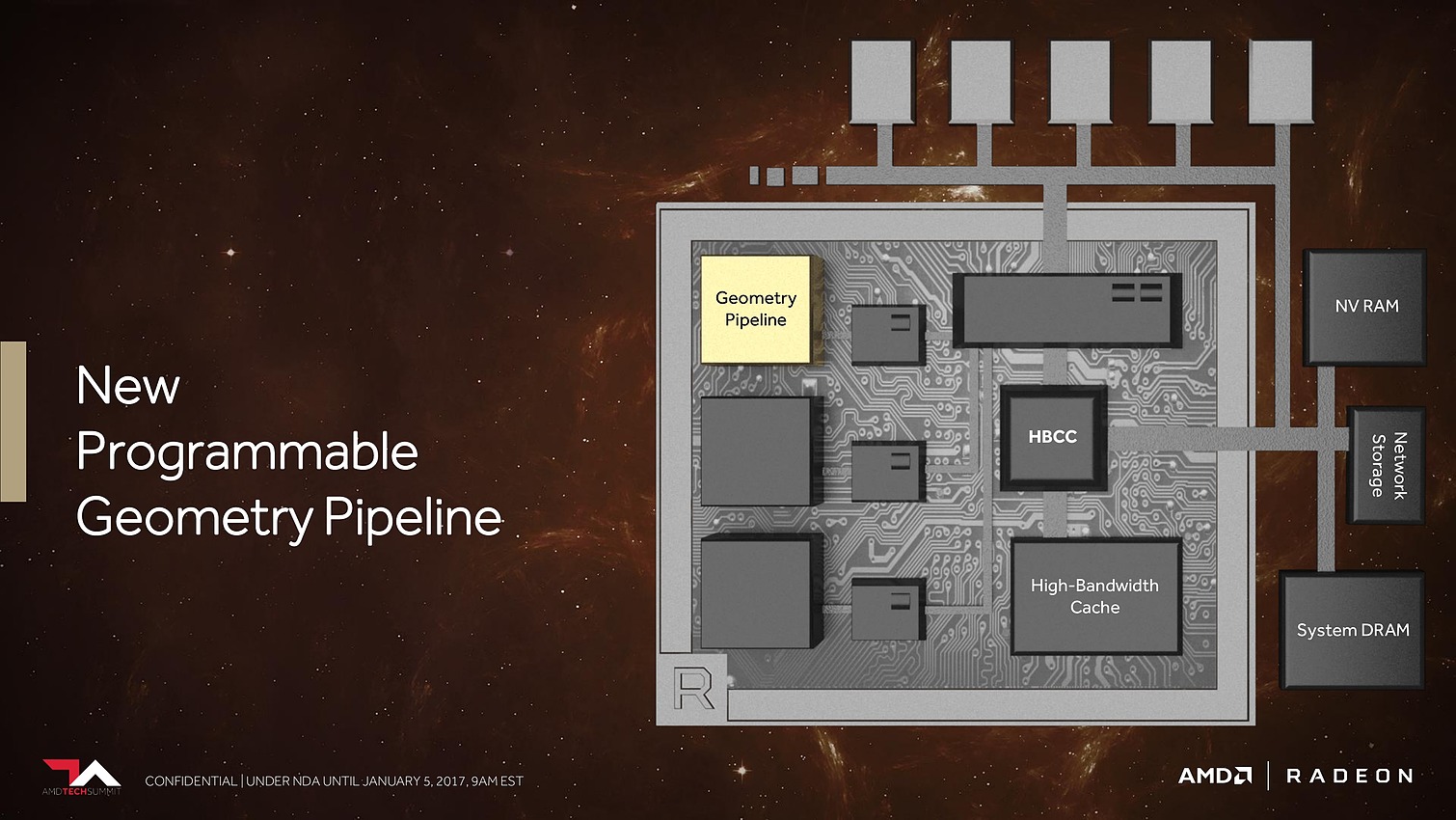

Plus spécifiquement pour le jeu vidéo cette fois, AMD a retravaillé ses moteurs géométriques sur 3 fronts. Tout d'abord leur débit va augmenter d'un facteur supérieur à 2x, AMD parle de 11 triangles par cycle avec 4 moteurs géométriques pour un GPU Vega, sans préciser s'il s'agit de Vega 10. Nous supposons qu'il s'agit ici du débit d'éjection des triangles qui tournent le dos à la caméra par exemple. Ce débit supérieur était jusqu'ici un des gros avantages des GPU Nvidia, qu'AMD devrait donc rattraper.
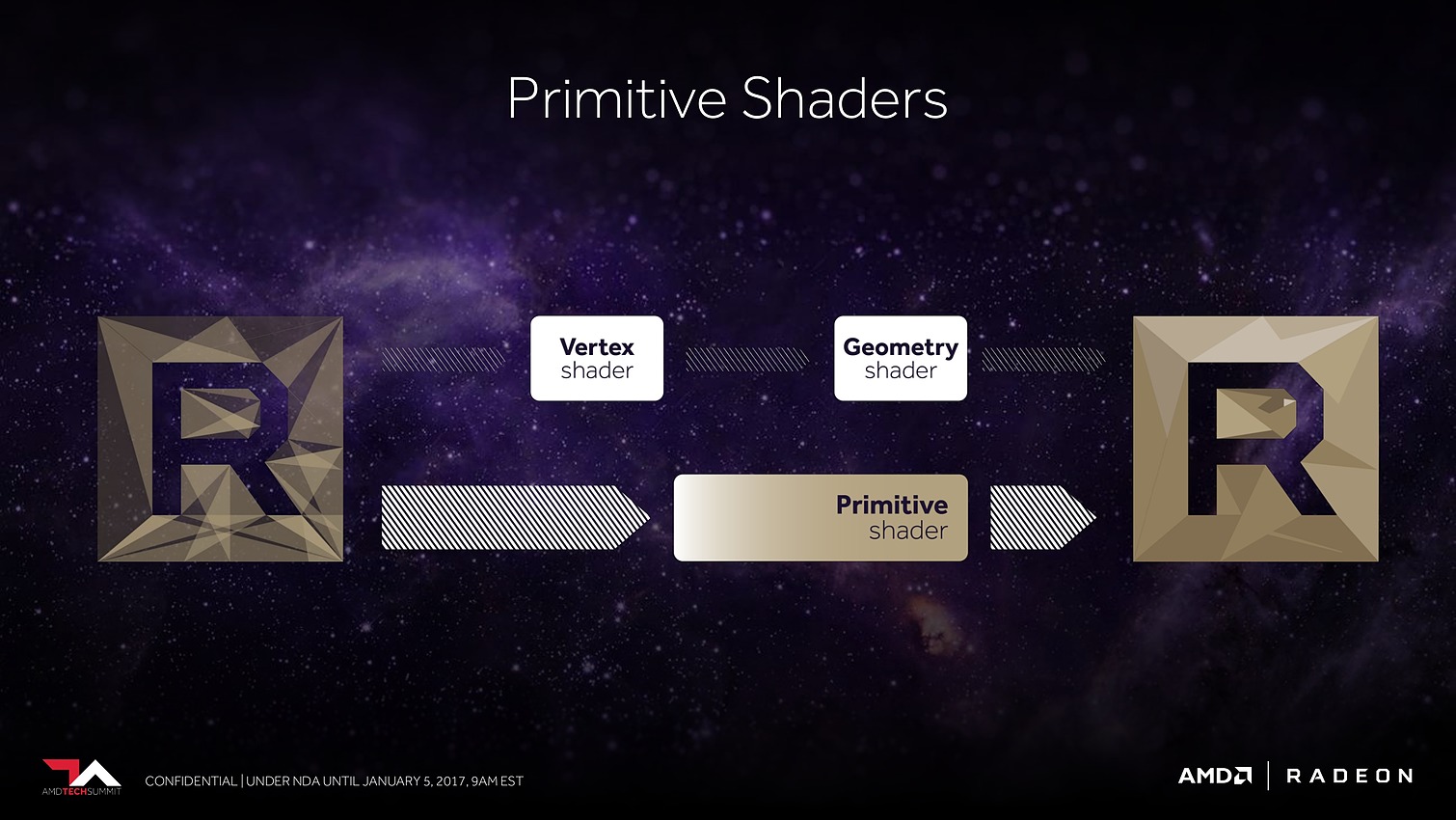
Ensuite, AMD proposera aux développeurs un nouveau type de shaders, les Primitive Shaders qui permettront de remplacer les Vertex Shaders et les Geometry Shaders. Nous ne savons pas exactement comment tout cela fonctionnera et sera exposé, mais cela devrait permettre de faciliter l'implémentation de pipelines de rendu personnalisés. AMD indique par ailleurs qu'ils permettront de booster le taux d'éjection des primitives mais nous ne savons pas si cela correspond au débit de 11 triangles par cycle noté ci-dessus ou si ce gain se fera en complément.
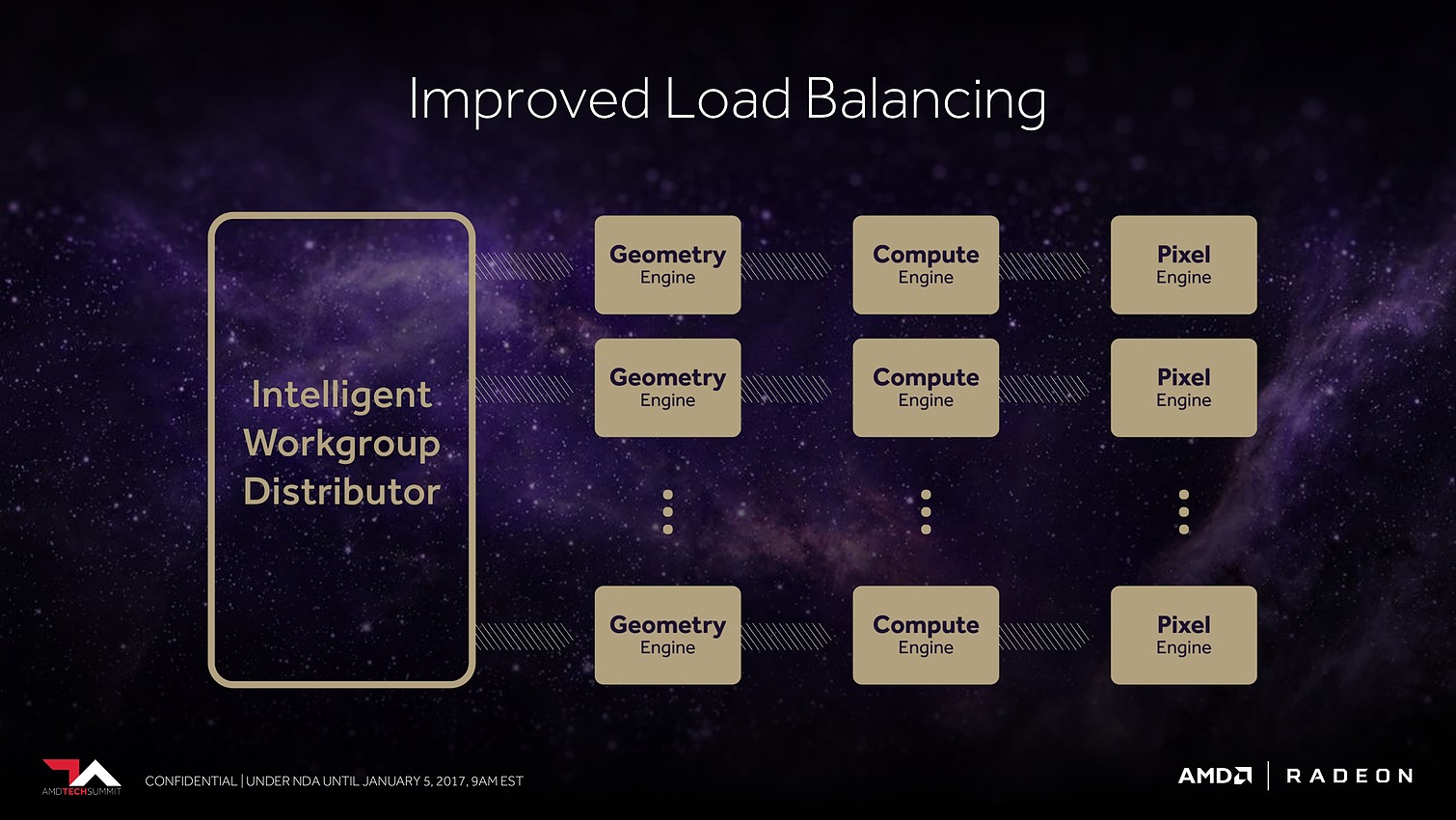
Enfin, suite à des retours constructifs de développeurs sur console, qui cherchaient à optimiser au maximum les performances, AMD s'est rendu compte que son algorithme de load balancing pouvait être amélioré pour mieux exploiter les ressources disponibles. Il a donc été revu.
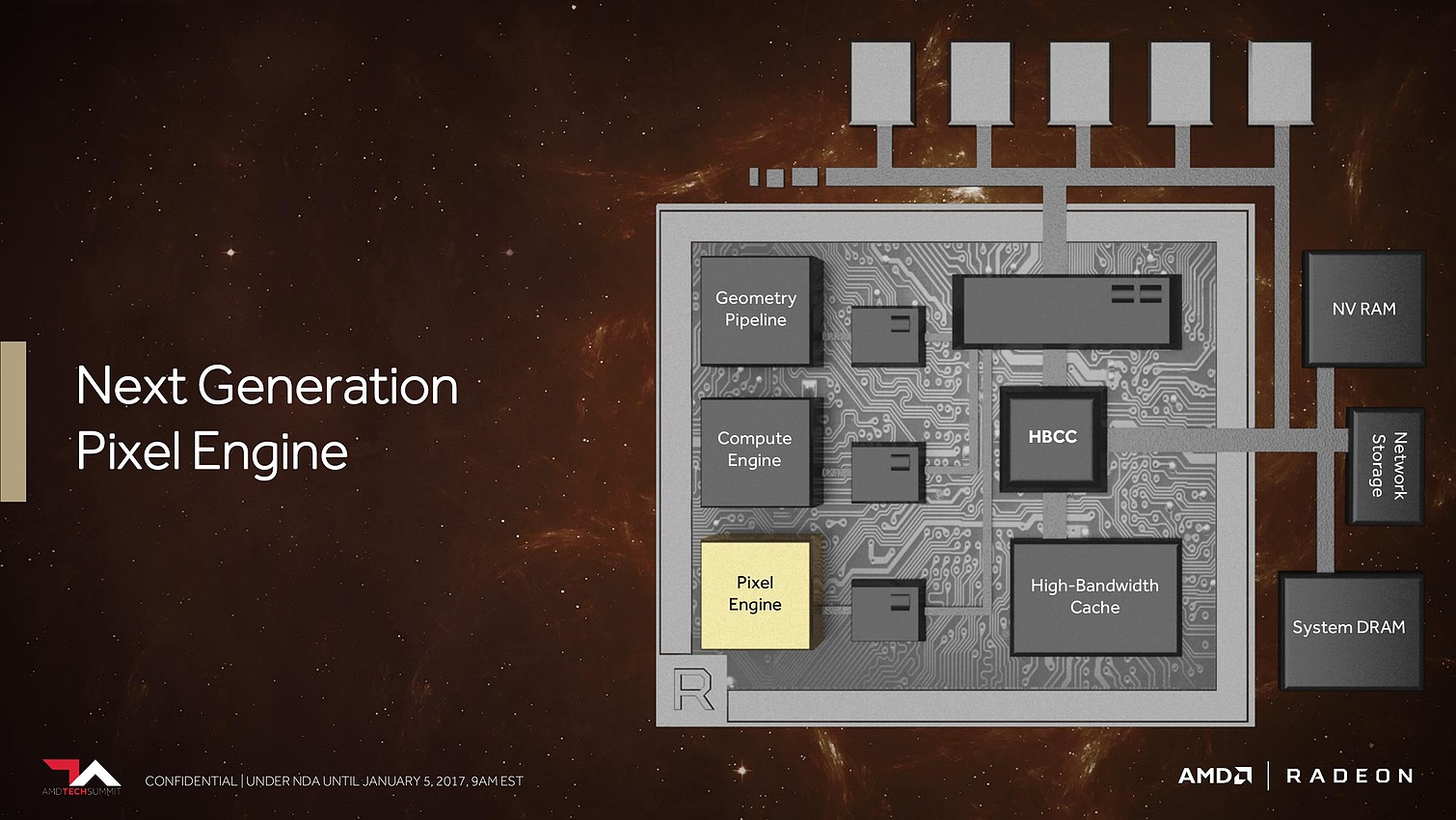

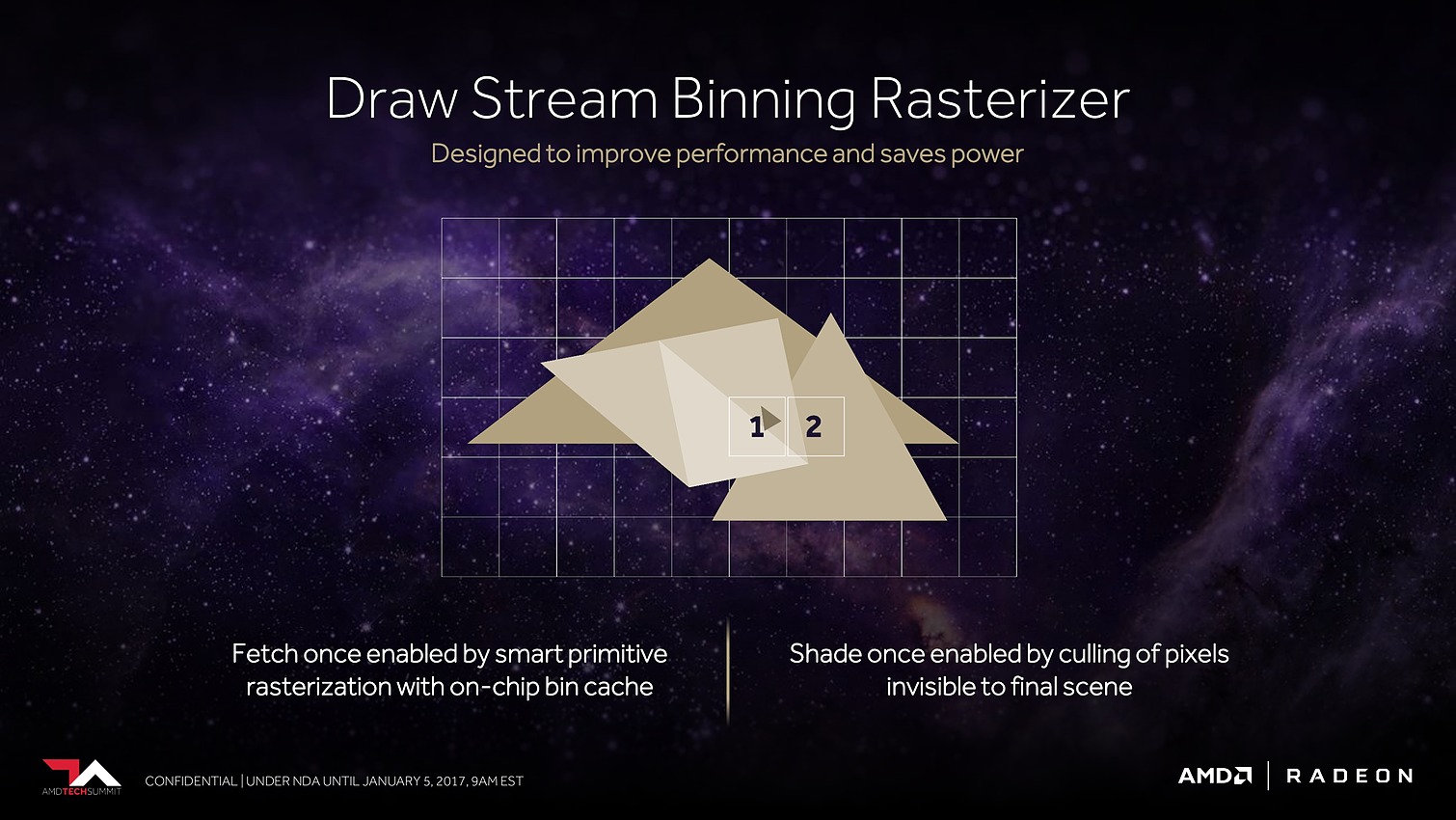

Le dernier point mis en avant par AMD concerne les pixels. Avec tout d'abord des moteurs de rastérisation revus. AMD parle de draw stream binning rasterizer. Derrière ce charabia technique se cache une approche similaire à celle exploitée par Nvidia sur les GPU Maxwell et Pascal. Elle consiste à faire une exploitation opportuniste du principe du tile renderingpour éviter de calculer trop de pixels masqués.
Il ne s'agit pas d'avoir recours à un rendu en 2 passes comme le font certains GPU mobiles pour appliquer fermement la technique, mais plutôt d'utiliser un petit buffer interne avant la rastérisation qui permet de traiter celle-ci quand l'information de couverture de plus de triangles est connue. Si ces informations permettent d'éviter de générer des pixels masqués, c'est tout bonus, si ce n'est pas le cas le traitement se fait de manière classique. D'où le côté opportuniste de la technique qui ne souffre pas des désavantages des approches des GPU mobiles.
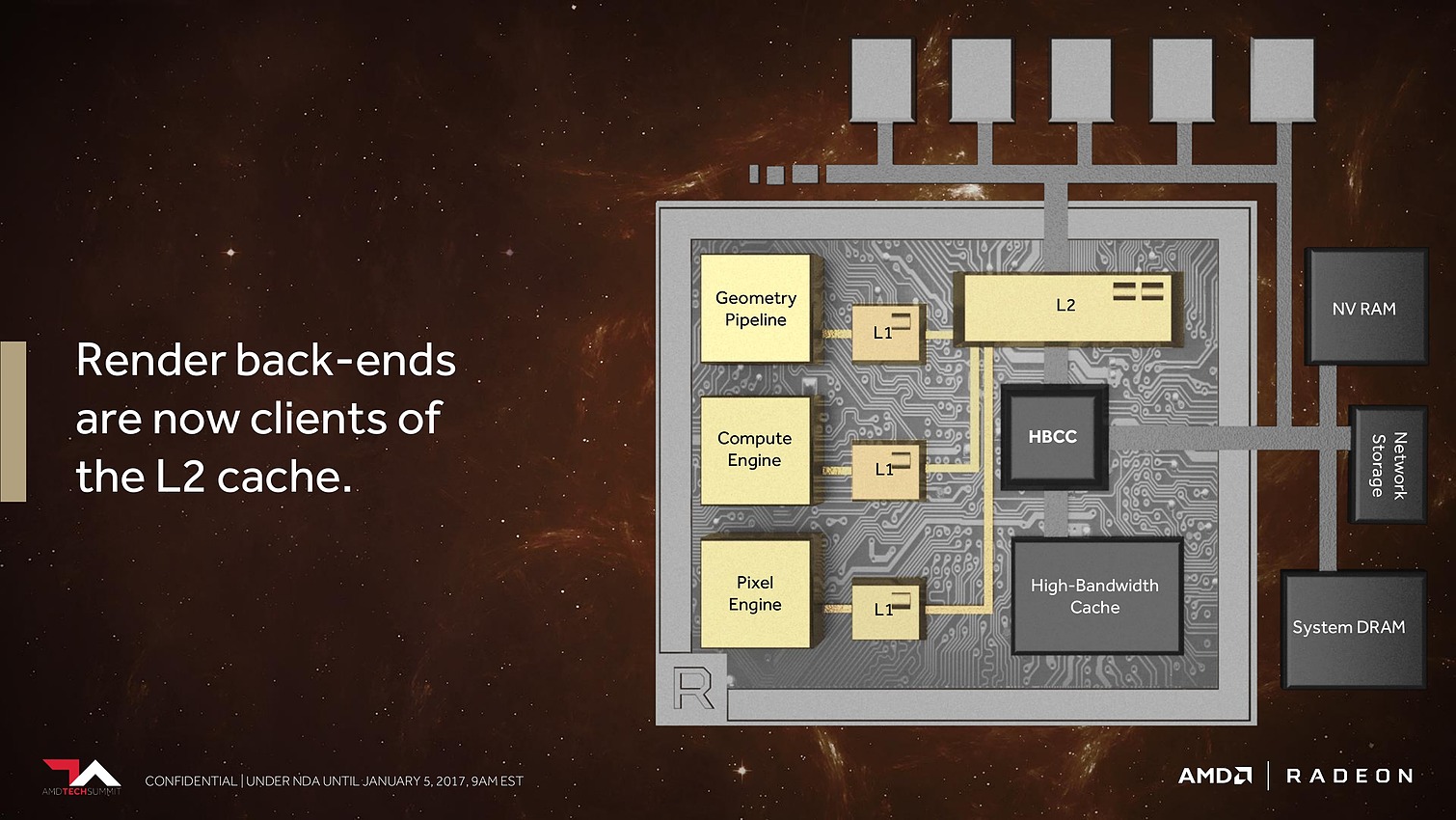
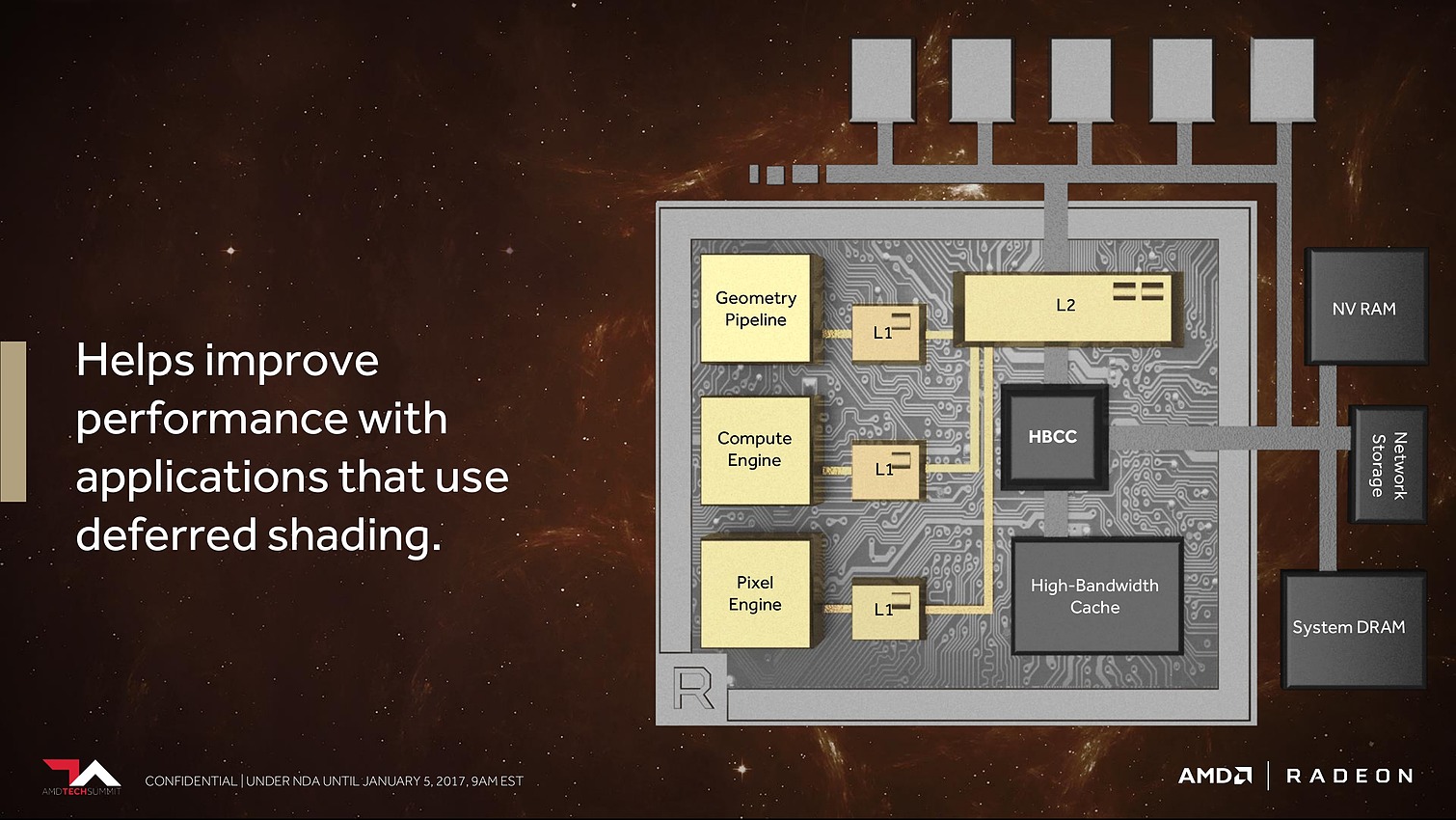
Les ROP ont eux aussi été revus. Leurs capacités exactes restent inconnues, mais au lieu d'exploiter de petits buffers spécifiques, ils deviennent des clients du gros cache L2. Selon AMD cela permet un gain appréciable dans les moteurs de type rendu différé qui sont devenus très courants dans les jeux vidéo.
Après ces quelques caractéristiques techniques de l'architecture Vega, intéressons-nous au GPU Vega 10 dans son ensemble. Physiquement tout d'abord puisque nous avons pu l'apercevoir brièvement dans les mains de Raja Koduri, responsable du groupe Radeon Technology (RTG) lors d'un évènement presse organisé par AMD le mois passé :

Nous pouvons apercevoir sur cette photo, prise rapidement au smartphone, un énorme die placé sur un interposer qui reçoit également 2 modules HBM2. Nous pouvons estimer la taille du die de Vega 10 entre 500 et 550 mm² (soit plus que les 471mm² du GP102, mais moins que les 610 mm² du GP100). C'est ce qui explique pourquoi AMD s'est contenté d'un bus 2048-bit, contrairement aux 4096-bit de Fiji dont les modules HBM1 prenaient beaucoup moins de place.
Pour pouvoir placer 4 modules HBM2 avec un gros die pour le GP100, Nvidia a de son côté recours à une double exposition très coûteuse, seule possibilité actuelle pour concevoir un interposer suffisamment grand pour recevoir l'ensemble. Avec Vega 10 AMD vise autant le marché professionnel que les joueurs et a donc opté pour une solution (un peu) plus raisonnable en termes de coûts de production.
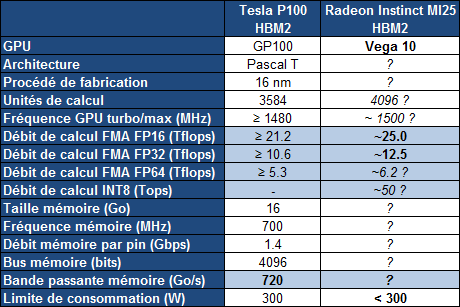
Quelles pourraient être les spécifications complètes d'une Radeon basée sur le GPU Vega 10 ? Nous avons rassemblé dans le tableau qui suit nos suppositions actuelles basées sur les quelques éléments dévoilés par AMD, notamment lors de l'annonce de la Radeon Instinct MI25 :
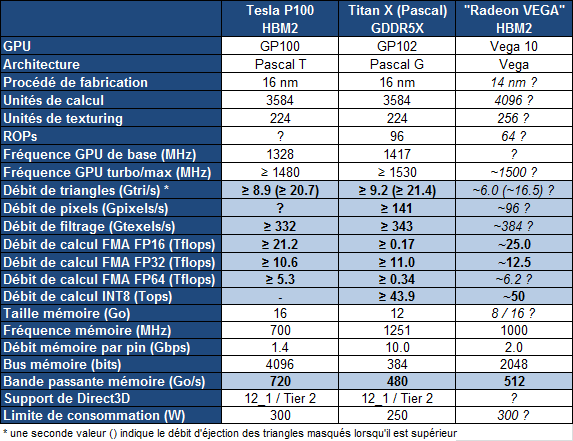
Reste bien entendu que pour pouvoir réellement concurrencer le GP102 (Titan X), et pas seulement se contenter de battre le GP104 (GTX 1080), il faudra que les avancées dévoilées aujourd'hui par AMD portent réellement leurs fruits en pratique.
Est-ce que le HBCC sera efficace dans le cadre du jeu vidéo si 8 Go deviennent insuffisants ? Est-ce que le FP16 sera exploité par certains jeux ? Est-ce que les développeurs seront intéressés par les Primitive Shaders ? Est-ce que le boost au niveau du débit des moteurs géométrique se retrouvera en pratique ? Quel sera le gain réel en terme d'IPC ? La nouvelle approche pour la rastérisation permettra-t-elle de rattraper Nvidia en terme d'efficacité ?
A l'heure actuelle, AMD ne nous fournit aucune information ou donnée pour permettre de quantifier ou de se faire une idée de ce que tout cela va apporter. Nous ne pouvons pas oublier que les avancées dévoilées de la même manière pour Polaris ont au final produit des résultats mitigés par rapport aux espérances suscitées (nous avons noté 8% de mieux en jeu entre GCN3 et GCN4). Avec Vega, nous avons par contre l'impression qu'AMD a enfin pris le recul nécessaire pour observer ce que Nvidia a fait de bien pour rendre plus efficaces ses dernières générations de GPU. De quoi s'engager dans une voie similaire avec Vega, ce qui laisse augurer de bonnes choses. Nous sommes évidemment impatients d'en savoir plus !
Vous pourrez retrouver l'intégralité de la présentation d'AMD ci-dessous :











Vega 10: 4096 unités, 1.5 GHz, 8 Go de HBM2 ?
Comme nous l'indiquions dans l'actualité consacrée aux Radeon Instinct, les premières informations officielles concernant Vega 10 sont de sortie. Pour rappel, il s'agit d'un futur GPU haut de gamme d'AMD basé sur une nouvelle architecture.
Parmi les informations dévoilées par AMD, notons l'exploitation de NCU (New Compute Units ?) avec support du packed math. Cette approche consiste à doubler la puissance de calcul en FP16 en modifiant les SIMD FP32 pour leur faire traiter des vecteurs 2D en FP16. C'est également ce que fait Nvidia avec le GP100 du Tesla P100 mais également sur ses derniers GPU intégrés aux SoC Tegra. Le FP16 peut être utile dans le cadre du GPU computing mais également dans celui du jeu vidéo lorsque la précision FP32 n'est pas nécessaire.
Les GPU Polaris n'offrent actuellement qu'un support limité du FP16 au niveau des registres, pour gagner de la place et de la bande passante à leur niveau. Avec Vega 10 tel que configuré sur la Radeon Instinct MI25, il sera en plus possible de doubler la puissance de calcul pour atteindre 25 Tflops en FP16 contre 12.5 Tflops en FP32. Un dernier chiffre qui représente plus du double d'une Radeon RX 480 et laisse penser que Vega 10 pourrait être équipé de 4096 unités de calcul et profiter d'une fréquence d'au moins 1.5 GHz.
AMD a également communiqué une consommation de <300W pour son accélérateur. Vega 10 sera donc à priori gourmand et nous pouvons supposer qu'AMD se retrouvera avec des options similaires à celles qui se sont présentées avec Fiji : pousser la limite de consommation pour maintenir autant que possible la fréquence maximale (Fury X), limiter la consommation pour maximiser le rendement énergétique et proposer un design compact (Nano) ou un compromis intermédiaire adapté à l'environnement compétitif du moment.
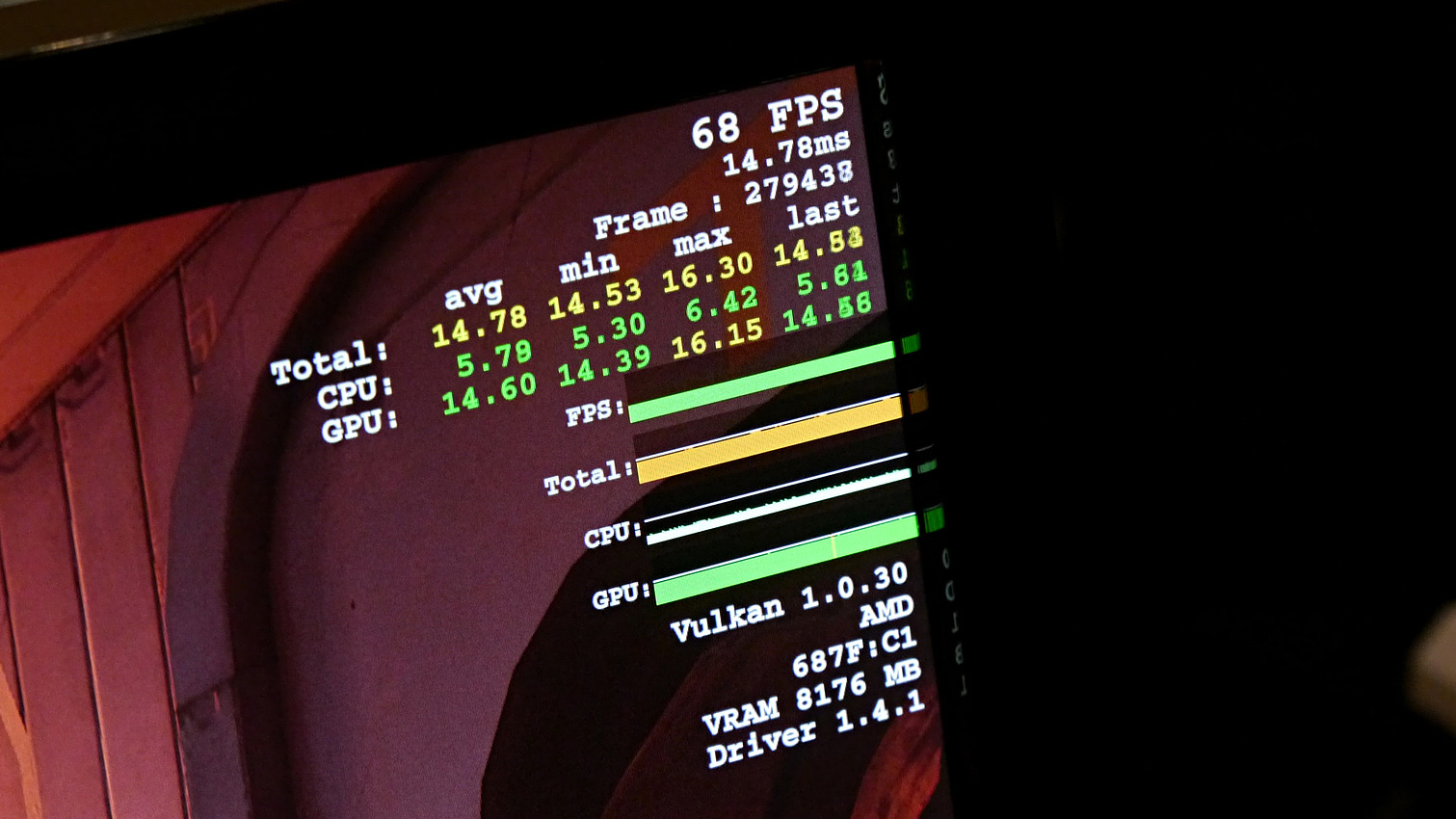
Mais une autre information qui était en principe sous embargo a été dévoilée par l'interface de Doom qui était en démonstration, comme l'ont constaté nos confrères allemands de Golem . Le prototype de Vega 10 exploité était équipé de 8 Go de mémoire.
Une information importante puisque les premiers modules HBM2 disponibles, et de toute évidence exploités ici par AMD, sont des modules 4Hi de 4 Go. En d'autres termes, Vega 10 exploiterait la HBM2 via un bus 2048-bit, ce qui correspondrait, avec un débit par pin de 2 Gbps, à une bande passante de 512 Go/s. Un chiffre identique à celui de Fiji et de sa mémoire HBM1 interfacée en 4096-bit.
Si une absence d'évolution sur ce point par rapport à Fiji peut sembler étrange, il y a probablement d'autres aspects à prendre en compte au niveau du sous-système mémoire de Vega 10. Par ailleurs il faut rappeler qu'une Radeon RX 480 se contente de 256 Go/s et que la Titan X plafonne à 480 Go/s. Attendez-vous à ce que plus d'informations soient communiquées d'ici quelques semaines.
Radeon Instinct et Vega : AMD mise sur l'IA
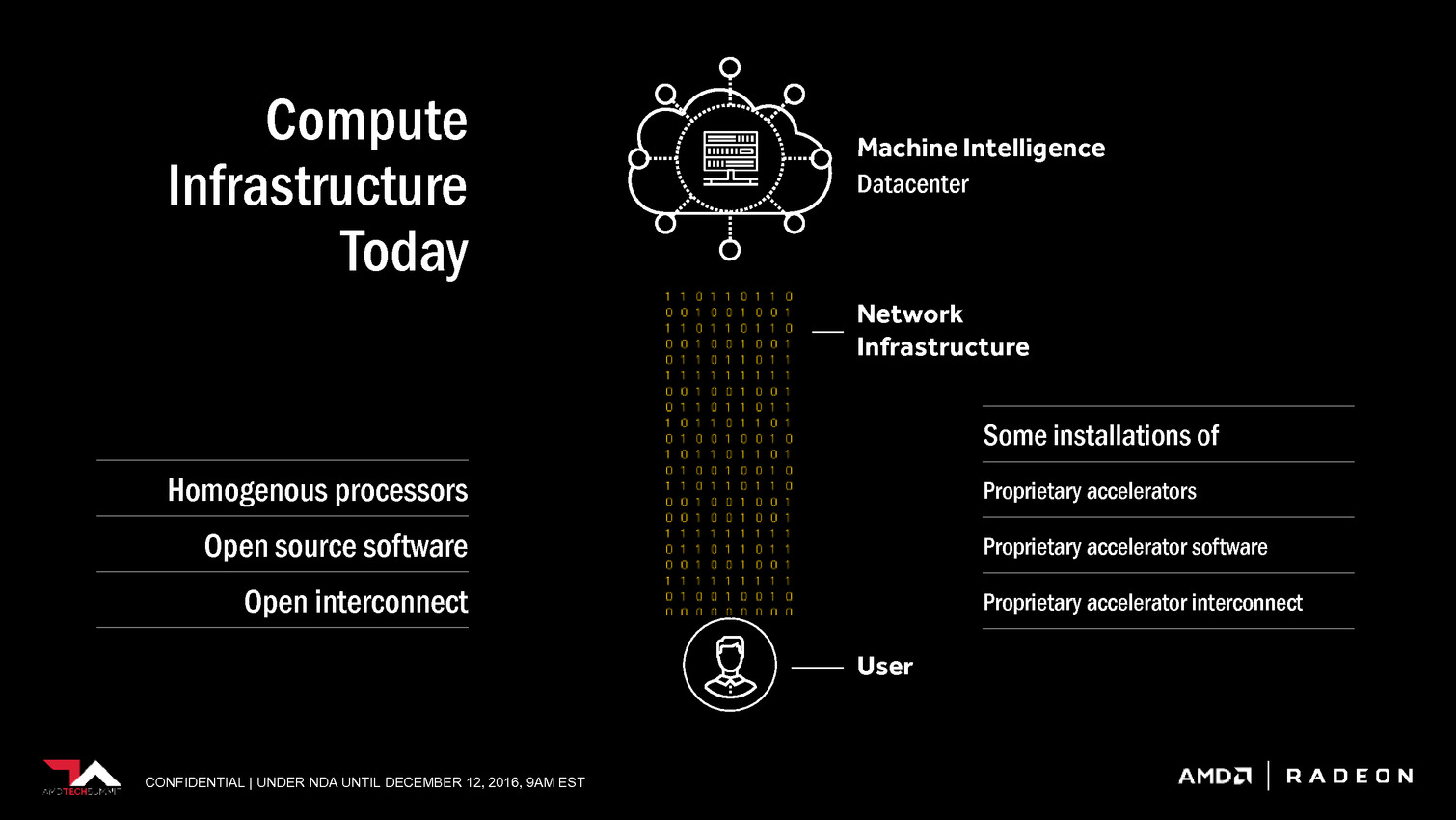
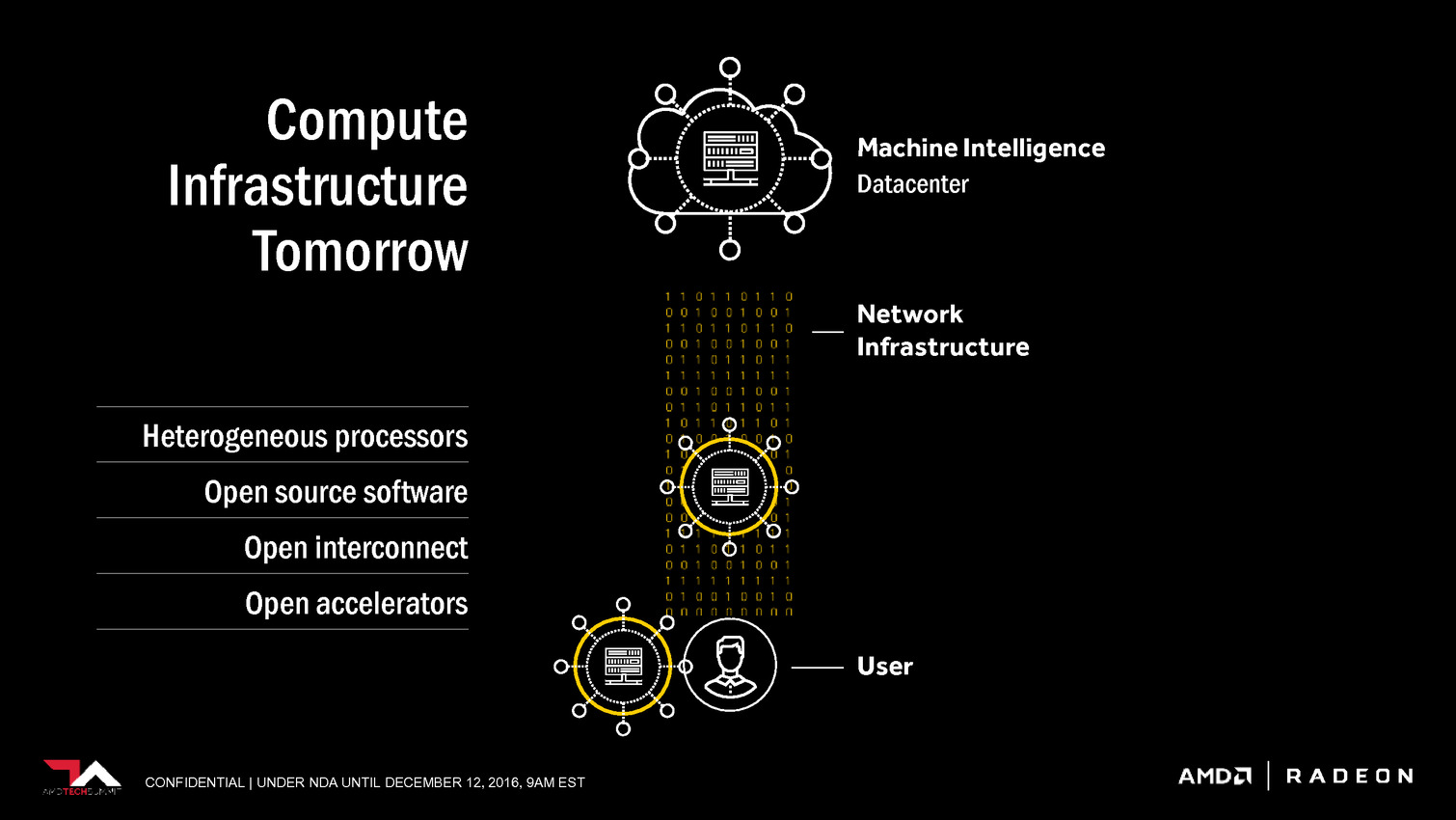
AMD a décidé de suivre la voie de Nvidia en mettant en place une stratégie spécifique pour conquérir le marché émergent de l'intelligence artificielle. La société compte pour cela sur un écosystème ouvert, sa future architecture GPU Vega et sur des synergies avec la plateforme serveur Zen.

Lors de l'AMD Tech Summit qui s'est tenu la semaine passée, AMD a présenté sa stratégie par rapport au marché émergent de l'intelligence artificielle, ou intelligence machine, qui passe en l'état actuel des choses principalement par le deep learning. Nous en avons déjà parlé à plusieurs reprises, rappelons simplement qu'il s'agit d'une part d'entraîner un réseau de neurones numériques (par exemple à faire la différence entre en chien et un chat en cherchant des points commun entre des milliers de photos identifiées) et d'autre part de déployer ce réseau en vue d'une exploitation pratique (par exemple ne distribuer de la nourriture qu'aux chiens).
L'entraînement d'un réseau tout comme son exploitation, ou inférence, a besoin de puissance de calcul et représente une opportunité pour les accélérateurs de tous types dont bien entendu les GPU. L'accélération du deep learning est d'ailleurs actuellement dominée par Nvidia qui, en plus d'un écosystème logiciel complet, propose des produits spécifiques pour l'entraînement et pour l'inférence, particulièrement dans le cadre de la conduite automatisée qui représente un débouché prometteur.
Les GPU proposés par AMD sont également adaptés à ces tâches, et sont déjà exploités dans une certaine mesure, mais pour aller plus loin une initiative spécifique était nécessaire. C'est là qu'intervient Radeon Instinct avec de nouveaux accélérateurs positionnés vers ce marché, un écosystème logiciel plus complet et une future architecture GPU, Vega, qui va proposer quelques optimisations utiles.

Grossièrement la gamme de Radeon Instinct s'inscrit dans la continuité des FirePro S, les accélérateurs dédiés aux serveurs, mais avec un positionnement stratégique retravaillé pour coller à un marché en pleine explosion. Les 3 nouvelles cartes dédiées à l'accélération prennent ainsi les noms de Radeon Instinct MI6, MI8 et MI25, MI étant une référence à Machine Intelligence et le nombre qui suit une référence à leur puissance de calcul. Serveur oblige il s'agit dans tous les cas de solutions passives.
La Radeon Instinct MI6 est équivalente à une Radeon RX 480 avec un GPU Polaris 10, une puissance de calcul de 5.7 Tflops, une bande passante de 224 Go/s et une consommation annoncée à moins de 150W. Le modèle MI8 est pour sa part dérivé de la Radeon Nano et propose 8.2 Tflops et 512 Go/s pour une consommation de moins de 175W.
C'est bien entendu la Radeon Instinct MI25 qui est la plus intéressante, même si elle ne sera pas disponible directement puisqu'il s'agit d'un futur accélérateur basé sur le GPU Vega 10. Cet accélérateur offrira une puissance de calcul de 25 Tflops, mais attention, il s'agit de calcul au format FP16 via le support du packed math.
Tout comme Nvidia le fait sur le GP100 et le Tesla P100, AMD a conçu ses nouvelles unités de calcul de manière à ce qu'elles puissent exécuter au choix soit des instructions FP32, soit un vecteur de 2 instructions FP16. De quoi doubler la puissance de calcul lorsqu'une précision réduite est suffisante, en opposition aux Radeon récentes qui ne supportent le format FP16 qu'au niveau du stockage dans les registres, mais pas au niveau des unités d'exécution.
AMD parle également de High Bandwidth Cache and Controller. Sachant que Vega supportera la mémoire HBM2, cela semble indiquer qu'elle sera exploitée en tant que cache et donc possiblement en complément d'un autre type de mémoire, le tout piloté par un nouveau contrôleur.
Enfin, AMD donne une première information concernant la consommation de ce futur GPU haut de gamme. Il est question de moins de 300W mais au vu des chiffres communiqués pour les autres Radeon Instinct, c'est à priori 300W et pas moins pour Vega 10. C'est similaire au Tesla P100 et il restera à voir si les déclinaisons orientées vers les joueurs pousseront la limite de consommation vers le haut comme pour la Radeon Fury X, ou la limiteront comme pour la (GeForce) Titan X.
Pour atteindre 25 Tflops en FP16, et donc 12.5 Tflops en FP32, plusieurs options sont possibles, mais la plus probable est un GPU composé de 4096 unités de calcul cadencée à +/- 1.5 GHz. Enfin, lors de la présentation de ces cartes, Liam Madden de Xilinx a précisé voir beaucoup d'intérêt dans le format 8-bit, ce qui laisse penser qu'un certain niveau de support est présent à ce niveau, comme le fait Nvidia sur ses GPU Pascal dédiés à l'inférence (autres que le GP100). A noter qu'AMD mentionne des NCU, ce qui signifie probablement New Compute Unit et d'autres améliorations peuvent donc être au programme.

Pour accompagner ces accélérateurs, l'aspect logiciel est évidemment crucial. AMD se base à ce niveau sur sa plateforme ROCm dédiée au calcul hétérogène et qui est déjà en partie optimisée pour l'accélération des frameworks principaux dédiés au deep learning, tels que Caffe, entre autre grâce à la prise en charge depuis quelques temps du code CUDA (via des outils de portage). AMD proposera également MIOpen au premier trimestre 2017, une réponse au cuDNN de Nvidia et donc une librairie dédiée à l'accélération par ses GPU des routines les plus courantes liées au deep learning. Autant pour ROCm que pour MIOpen, AMD insiste sur une approche open source pour convaincre les développeurs.
Enfin, AMD fait part de son intérêt pour les interconnexions nouvelles qui vont permettre d'aller au-delà des limitations du PCI Express 3.0, et sur la possibilité de fournir une plateforme complète sur base de serveurs Zen. De tels serveurs sont déjà prévus chez SuperMicro (SYS 1028GQ-TRT), Inventec (G888, 100 Tflops avec 4 MI25 et rack de 3 petaflops avec 120 MI25) et Falconwitch (PS1816, 400 Tflops avec 16 MI25).

Nous avons profité de notre présence sur place pour interroger Raja Koduri sur l'opportunité d'apporter des modifications spécifiques pour le deep learning à l'architecture de ses GPU. Comme à son habitude le chef de file du Radeon Technology Group s'est montré très pragmatique. Si quelques petites touches peuvent être utiles, les algorithmes évoluent beaucoup trop rapidement pour des modifications de grande ampleur.
Et de préciser que face à une approche très brute force du deep learning il n'est pas impossible de découvrir un beau matin une technique totalement différente qui réduira à néant certains travaux précédents. Face à cela, Raja Koduri estime que la flexibilité et les performances de base de son architecture, et surtout de son compilateur, restent garants de la pertinence de ses GPU dans le domaine de l'intelligence machine. Si des architectures spécifiques à certains algorithmes ont été développées par différents acteurs, il ne pense pas que cela ira plus loin que des implémentations de type FPGA, tout du moins à court et moyen termes.

Enfin, terminons par préciser qu'un prototype de Radeon Instinct était déjà en démonstration la semaine passée et était occupé à entraîner un réseau. Impossible cependant d'observer la carte de plus près que ce que n'offre notre cliché, AMD ayant pris soin de camoufler la moindre ouverture du boîtier qui l'embarquait.
Aucune information précise n'a été communiquée sur la disponiblité du GPU Vega 10 et de la Radeon Instinct MI25, AMD se contentant de parler du premier semestre 2017, ce qui revient en général à exclure le premier trimestre. Il faudra donc patienter encore quelques mois avant de voir débarquer ce GPU très attendu, même si d'ici là quelques aspects techniques devraient être dévoilés.
Vous pourrez retrouver l'intégralité de la présentation d'AMD ci-dessous :



























Résultats AMD pour le troisième trimestre
 AMD a annoncé hier soir ses résultats pour le troisième trimestre 2016. Le constructeur enregistre un chiffre d'affaire en hausse de 1,307 milliard, 23% de plus qu'en 2015 sur la même période qui avait été particulièrement difficile. Séquentiellement, le chiffre d'affaire est en hausse de 27%.
AMD a annoncé hier soir ses résultats pour le troisième trimestre 2016. Le constructeur enregistre un chiffre d'affaire en hausse de 1,307 milliard, 23% de plus qu'en 2015 sur la même période qui avait été particulièrement difficile. Séquentiellement, le chiffre d'affaire est en hausse de 27%.
Le constructeur parle de ventes record sur son activité "semi-custom", porté notamment par l'arrivée de la génération intermédiaire de consoles chez Microsoft et Sony, mais aussi des ventes GPU et APU en hausse.
Cela n'empêche pas le constructeur d'enregistrer une perte de 293 millions, une perte que l'on doit à la renégociation de l'accord WSA qui lie AMD a GlobalFoundries. AMD a pris une charge exceptionnelle de 340 millions pour couvrir le coût de cette renégociation, qui n'imputera plus les trimestres à venir.
Sans cette charge, AMD aurait enregistré un bénéfice mais comme nous l'indiquions a l'époque, cette renégociation était probablement indispensable pour AMD pour leur permettre de produire plus librement leurs GPU, par exemple, chez TSMC. Les incertitudes du 7nm de GlobalFoundries (et l'absence de 10nm) font qu'il était plus qu'indispensable à AMD de ne pas se retrouver enfermé avec un fondeur qui ne serait pas compétitif.
Dans la session de questions/réponses, la CEO Lisa Su a confirmé que Zen en version desktop (Summit Ridge) est toujours prévu pour le premier trimestre, et que la version serveur sera lancée au second trimestre 2017. L'échantillonnage des puces est en cours chez les partenaires d'AMD et se passerait "bien".
Côté GPU, Vega est toujours confirmé pour le premier semestre sans plus de détails. Il est probable qu'il s'agira d'un des produits "16nm", qui sera fabriqué chez TSMC grace à la renégociation de l'accord, interrogé pour en savoir plus sur la répartition à venir entre les multiples sources de fabrication, AMD s'est contenté d'évoquer des choix au cas par cas, ou en fonction des clients.
Par rapport à la situation financière difficile d'AMD, ces résultats sont plutôt encourageants. Malgré tout et comme pour Intel il y a quelques jours, les investisseurs poussent l'action à la baisse (-6% avant l'ouverture des marchés), en grande partie à cause du déclin du marché du PC et des perspectives sur le dernier trimestre.
Le Radeon Technologies Group remonte la pente
Pour rappel, en septembre dernier, AMD s'est réorganisé de manière à mettre en place une division à peu près indépendante qui se focaliserait sur tout le pan "graphique" de ses activités. Le Radeon Technologies Group était né et s'apparentait en quelque sorte à une reformation de l'ancien ATI qui avait été progressivement intégré au sein d'AMD. Un an après c'est l'occasion pour cette division graphique de faire le point.
L'intérêt de la réorganisation était de donner plus d'agilité et de liberté aux équipes chargées des GPU et des cartes graphiques, que ce soit en termes de stratégie commerciale, de communication ou d'utilisation de son budget. Face à un délitement de ses parts de marché, un changement significatif était devenu important pour lutter plus efficacement contre Nvidia dans l'écosystème PC. C'est Raja Koduri, ex architecte et ex CTO qui, après un passage chez Apple, a pris la direction de ce Radeon Technologies Group (RTG).
Sa mission était on ne peut plus claire : stopper la chute des parts de marché et remonter la pente. Pour y parvenir, ce n'est pas réellement plus de moyens qui ont été donnés à Raja Koduri, mais plutôt l'opportunité de faire mieux avec ce qui est disponible et de revoir certaines priorités. Le premier changement visible pour les utilisateurs a été une refonte de la stratégie liée aux pilotes accompagnée d'une nouvelle interface et d'un changement de marque.
Le RTG a ensuite peaufiné sa manière de collaborer avec les développeurs, notamment avec le portail GPUOpen, avec un timing qui a suivi l'arrivée des nouvelles API. Un investissement important a également été effectué au niveau de la réalité virtuelle. Si cette technique d'affichage ne génère pas encore énormément de revenus, elle offre par contre pas mal de visibilité, ce qui est toujours bon à prendre en plus de se positionner sur ce nouveau marché. Et évidemment de nouveaux produits ont été lancés avec la famille de Radeon RX 400 Polaris. Si tout n'a pas été parfait concernant leur lancement, et si elles ne peuvent pas concurrencer les GeForce sur le haut de gamme, elles représentent sans aucun doute de meilleurs produits par rapport à l'ancienne gamme.

Hier, lors d'une conférence avec la presse, Raja Koduri a expliqué être satisfait des résultats et du travail de ses équipes, beaucoup a été fait au cours des 12 derniers mois, tout en indiquant leur rappeler régulièrement qu'il reste encore énormément à faire. Comme nous l'avons vu dans les chiffres de parts de marché, la division RTG d'AMD est effectivement en train de remonter la pente. Il est question d'une progression de 26% à 34% de ses parts de marchés entre Q4 2015 et Q2 2016 (cartes graphiques desktops + mobiles). Un résultat très encourageant pour Raja Koduri. Toujours très pragmatique et réaliste, il précise que ce résultat est d'autant plus appréciable qu'il a été obtenu alors même que Nvidia ne lui a pas facilité la tâche avec de bons produits et une exécution sans faille.
Quid de la suite ? Malheureusement, nous n'en saurons pas plus sur les futurs produits et technologies qui seront proposés par le RTG. Raja Koduri s'est contenté de rappeler avoir mentionné il y a peu le premier semestre 2017 pour les très attendus GPU Vega, en précisant cependant que des détails les concernant seraient dévoilés avant les fêtes de fin d'année. Une stratégie de communication qui semble donc à peu près similaire à celle engagée pour Polaris et qui consiste en partie à occuper l'espace pour gagner du temps.
Cette approche, souvent nécessaire pour une société en position de challenger, est évidemment à double tranchant puisqu'elle revient à dévoiler certains éléments à la concurrence et peut conduire à s'avancer trop tôt sur des aspects qui ne sont pas encore garantis. Lors d'une précédente discussion avec Raja Koduri, après que la campagne de communication axée sur l'efficience de Polaris ait été lancée mais avant les tests des Radeon RX 400, ce dernier nous avait indiqué qu'il était crucial de trouver avec ses équipes un bon équilibre pour faire en sorte de bénéficier d'un peu de teasing sans prendre le risque de décevoir en survendant certains aspects. Nous espérons évidemment que cet équilibre aura été mieux calibré et attendons avec impatience d'en savoir plus sur la génération Vega.