| |
| |
| Radeon Instinct et Vega : AMD mise sur l'IA Cartes Graphiques Publié le Lundi 12 Décembre 2016 par Damien Triolet URL: /news/14875/radeon-instinct-vega-amd-mise-ia.html AMD a décidé de suivre la voie de Nvidia en mettant en place une stratégie spécifique pour conquérir le marché émergent de l'intelligence artificielle. La société compte pour cela sur un écosystème ouvert, sa future architecture GPU Vega et sur des synergies avec la plateforme serveur Zen.  Lors de l'AMD Tech Summit qui s'est tenu la semaine passée, AMD a présenté sa stratégie par rapport au marché émergent de l'intelligence artificielle, ou intelligence machine, qui passe en l'état actuel des choses principalement par le deep learning. Nous en avons déjà parlé à plusieurs reprises, rappelons simplement qu'il s'agit d'une part d'entraîner un réseau de neurones numériques (par exemple à faire la différence entre en chien et un chat en cherchant des points commun entre des milliers de photos identifiées) et d'autre part de déployer ce réseau en vue d'une exploitation pratique (par exemple ne distribuer de la nourriture qu'aux chiens). L'entraînement d'un réseau tout comme son exploitation, ou inférence, a besoin de puissance de calcul et représente une opportunité pour les accélérateurs de tous types dont bien entendu les GPU. L'accélération du deep learning est d'ailleurs actuellement dominée par Nvidia qui, en plus d'un écosystème logiciel complet, propose des produits spécifiques pour l'entraînement et pour l'inférence, particulièrement dans le cadre de la conduite automatisée qui représente un débouché prometteur. Les GPU proposés par AMD sont également adaptés à ces tâches, et sont déjà exploités dans une certaine mesure, mais pour aller plus loin une initiative spécifique était nécessaire. C'est là qu'intervient Radeon Instinct avec de nouveaux accélérateurs positionnés vers ce marché, un écosystème logiciel plus complet et une future architecture GPU, Vega, qui va proposer quelques optimisations utiles.  Grossièrement la gamme de Radeon Instinct s'inscrit dans la continuité des FirePro S, les accélérateurs dédiés aux serveurs, mais avec un positionnement stratégique retravaillé pour coller à un marché en pleine explosion. Les 3 nouvelles cartes dédiées à l'accélération prennent ainsi les noms de Radeon Instinct MI6, MI8 et MI25, MI étant une référence à Machine Intelligence et le nombre qui suit une référence à leur puissance de calcul. Serveur oblige il s'agit dans tous les cas de solutions passives. La Radeon Instinct MI6 est équivalente à une Radeon RX 480 avec un GPU Polaris 10, une puissance de calcul de 5.7 Tflops, une bande passante de 224 Go/s et une consommation annoncée à moins de 150W. Le modèle MI8 est pour sa part dérivé de la Radeon Nano et propose 8.2 Tflops et 512 Go/s pour une consommation de moins de 175W. C'est bien entendu la Radeon Instinct MI25 qui est la plus intéressante, même si elle ne sera pas disponible directement puisqu'il s'agit d'un futur accélérateur basé sur le GPU Vega 10. Cet accélérateur offrira une puissance de calcul de 25 Tflops, mais attention, il s'agit de calcul au format FP16 via le support du packed math. Tout comme Nvidia le fait sur le GP100 et le Tesla P100, AMD a conçu ses nouvelles unités de calcul de manière à ce qu'elles puissent exécuter au choix soit des instructions FP32, soit un vecteur de 2 instructions FP16. De quoi doubler la puissance de calcul lorsqu'une précision réduite est suffisante, en opposition aux Radeon récentes qui ne supportent le format FP16 qu'au niveau du stockage dans les registres, mais pas au niveau des unités d'exécution. 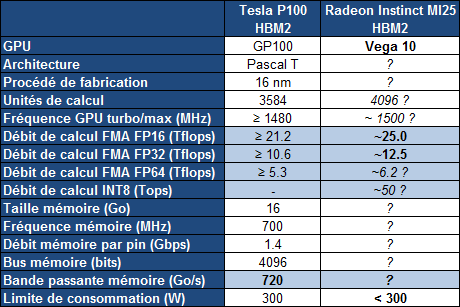 AMD parle également de High Bandwidth Cache and Controller. Sachant que Vega supportera la mémoire HBM2, cela semble indiquer qu'elle sera exploitée en tant que cache et donc possiblement en complément d'un autre type de mémoire, le tout piloté par un nouveau contrôleur. Enfin, AMD donne une première information concernant la consommation de ce futur GPU haut de gamme. Il est question de moins de 300W mais au vu des chiffres communiqués pour les autres Radeon Instinct, c'est à priori 300W et pas moins pour Vega 10. C'est similaire au Tesla P100 et il restera à voir si les déclinaisons orientées vers les joueurs pousseront la limite de consommation vers le haut comme pour la Radeon Fury X, ou la limiteront comme pour la (GeForce) Titan X. Pour atteindre 25 Tflops en FP16, et donc 12.5 Tflops en FP32, plusieurs options sont possibles, mais la plus probable est un GPU composé de 4096 unités de calcul cadencée à +/- 1.5 GHz. Enfin, lors de la présentation de ces cartes, Liam Madden de Xilinx a précisé voir beaucoup d'intérêt dans le format 8-bit, ce qui laisse penser qu'un certain niveau de support est présent à ce niveau, comme le fait Nvidia sur ses GPU Pascal dédiés à l'inférence (autres que le GP100). A noter qu'AMD mentionne des NCU, ce qui signifie probablement New Compute Unit et d'autres améliorations peuvent donc être au programme.  Pour accompagner ces accélérateurs, l'aspect logiciel est évidemment crucial. AMD se base à ce niveau sur sa plateforme ROCm dédiée au calcul hétérogène et qui est déjà en partie optimisée pour l'accélération des frameworks principaux dédiés au deep learning, tels que Caffe, entre autre grâce à la prise en charge depuis quelques temps du code CUDA (via des outils de portage). AMD proposera également MIOpen au premier trimestre 2017, une réponse au cuDNN de Nvidia et donc une librairie dédiée à l'accélération par ses GPU des routines les plus courantes liées au deep learning. Autant pour ROCm que pour MIOpen, AMD insiste sur une approche open source pour convaincre les développeurs. Enfin, AMD fait part de son intérêt pour les interconnexions nouvelles qui vont permettre d'aller au-delà des limitations du PCI Express 3.0, et sur la possibilité de fournir une plateforme complète sur base de serveurs Zen. De tels serveurs sont déjà prévus chez SuperMicro (SYS 1028GQ-TRT), Inventec (G888, 100 Tflops avec 4 MI25 et rack de 3 petaflops avec 120 MI25) et Falconwitch (PS1816, 400 Tflops avec 16 MI25).  Nous avons profité de notre présence sur place pour interroger Raja Koduri sur l'opportunité d'apporter des modifications spécifiques pour le deep learning à l'architecture de ses GPU. Comme à son habitude le chef de file du Radeon Technology Group s'est montré très pragmatique. Si quelques petites touches peuvent être utiles, les algorithmes évoluent beaucoup trop rapidement pour des modifications de grande ampleur. Et de préciser que face à une approche très brute force du deep learning il n'est pas impossible de découvrir un beau matin une technique totalement différente qui réduira à néant certains travaux précédents. Face à cela, Raja Koduri estime que la flexibilité et les performances de base de son architecture, et surtout de son compilateur, restent garants de la pertinence de ses GPU dans le domaine de l'intelligence machine. Si des architectures spécifiques à certains algorithmes ont été développées par différents acteurs, il ne pense pas que cela ira plus loin que des implémentations de type FPGA, tout du moins à court et moyen termes.   Enfin, terminons par préciser qu'un prototype de Radeon Instinct était déjà en démonstration la semaine passée et était occupé à entraîner un réseau. Impossible cependant d'observer la carte de plus près que ce que n'offre notre cliché, AMD ayant pris soin de camoufler la moindre ouverture du boîtier qui l'embarquait. Aucune information précise n'a été communiquée sur la disponiblité du GPU Vega 10 et de la Radeon Instinct MI25, AMD se contentant de parler du premier semestre 2017, ce qui revient en général à exclure le premier trimestre. Il faudra donc patienter encore quelques mois avant de voir débarquer ce GPU très attendu, même si d'ici là quelques aspects techniques devraient être dévoilés. Vous pourrez retrouver l'intégralité de la présentation d'AMD ci-dessous :          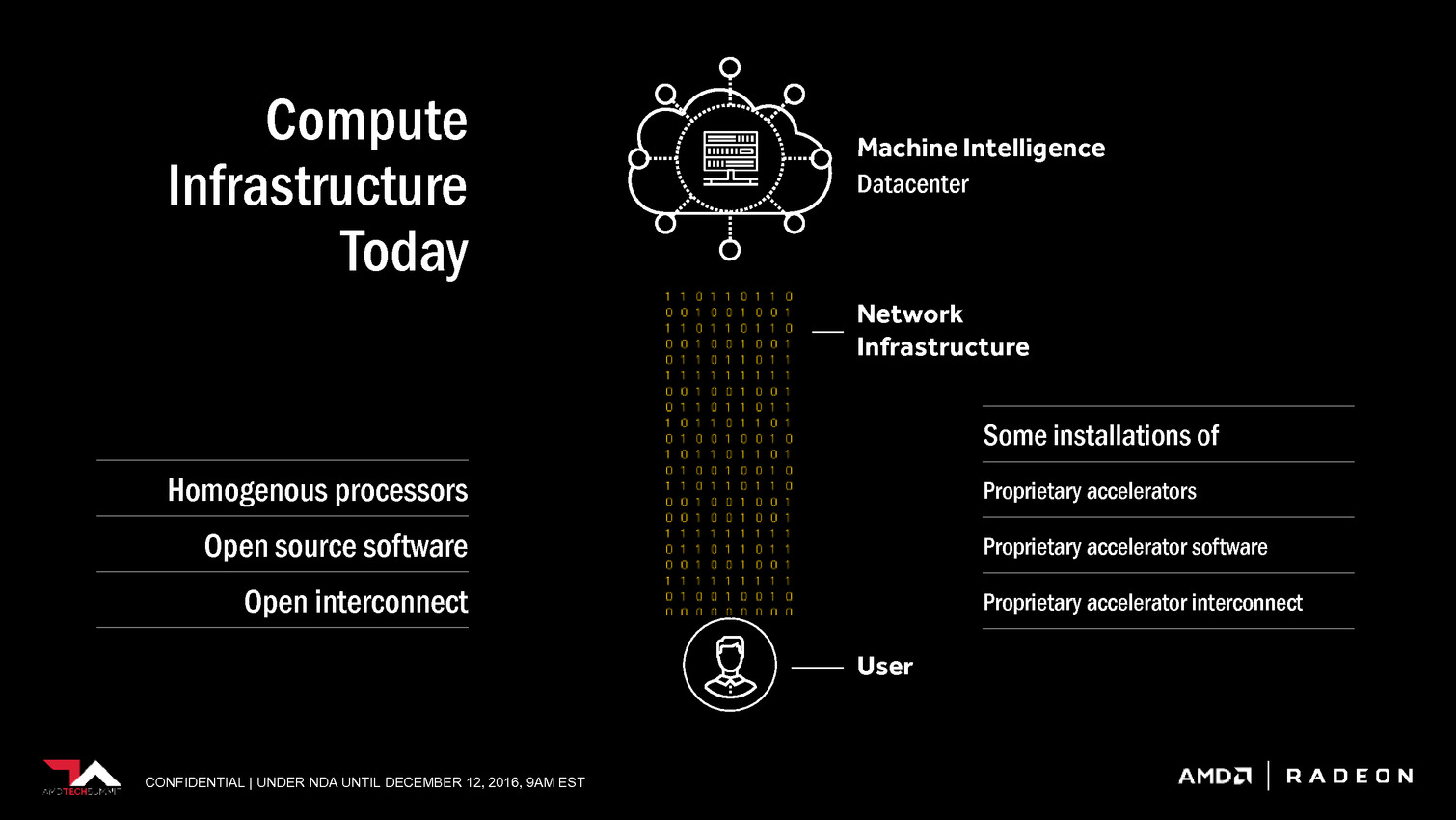 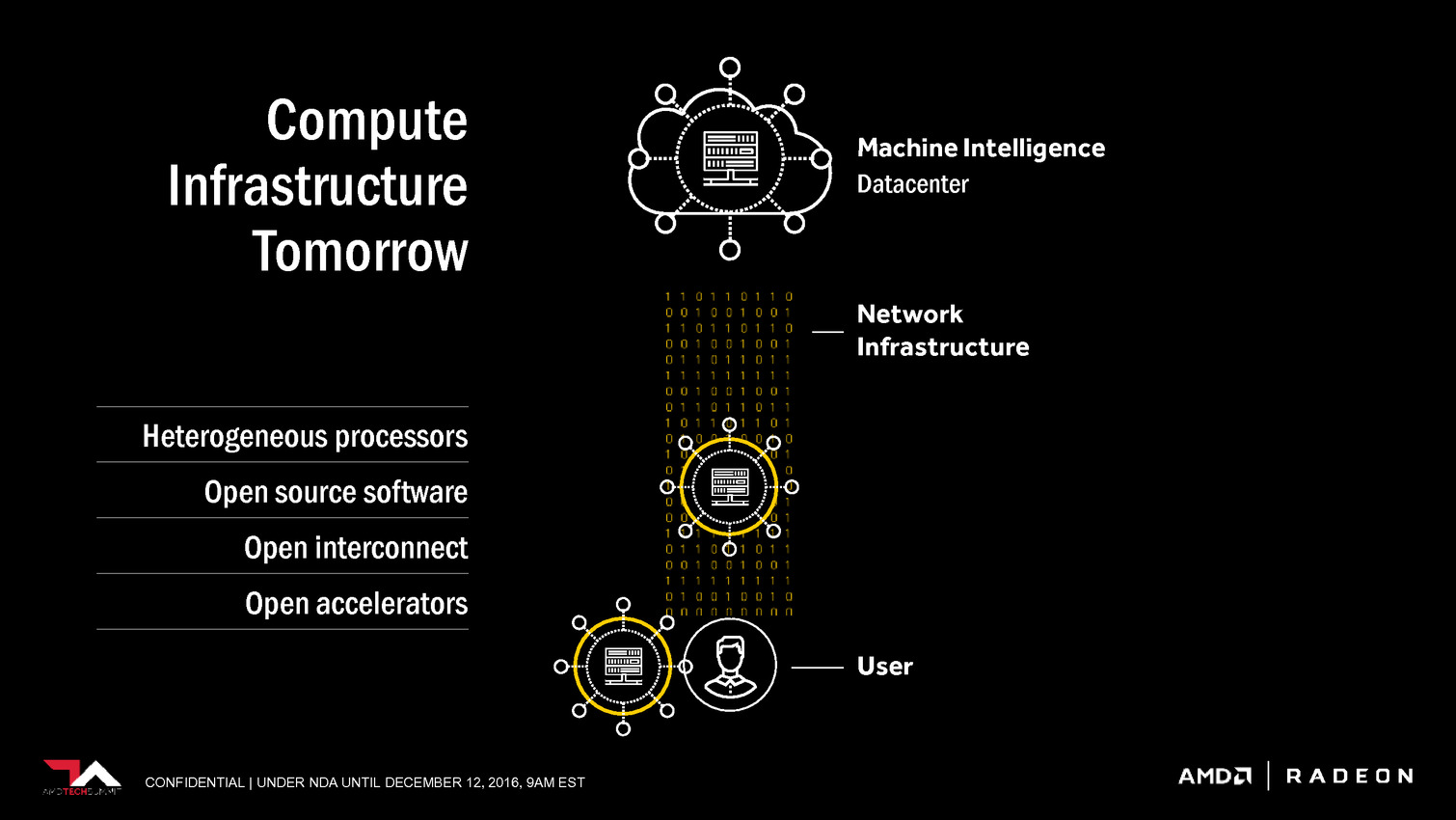  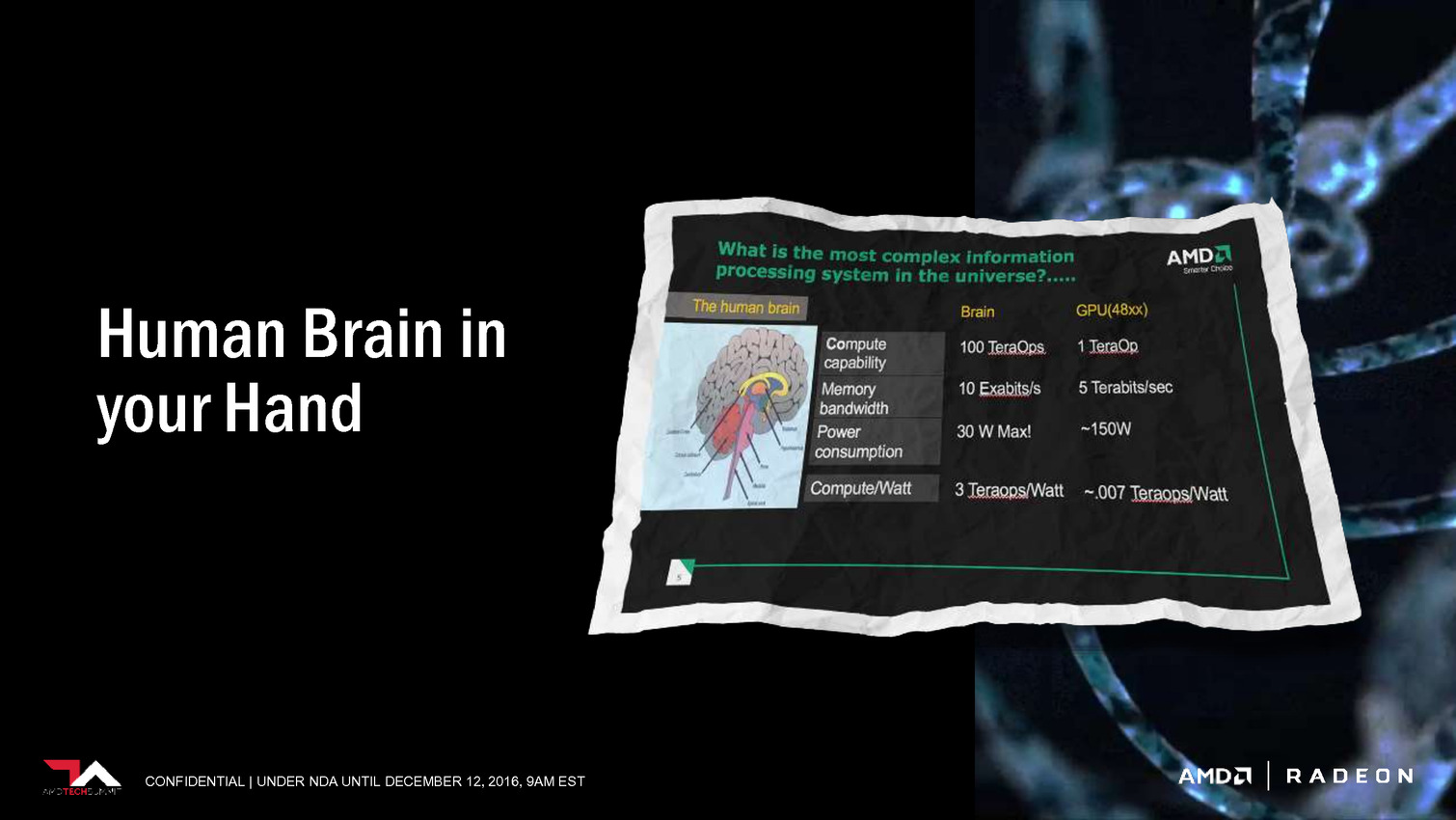                    Copyright © 1997-2026 HardWare.fr. Tous droits réservés. |