
AMD Threadripper 1950X et 1920X en test : Quelque chose d'Epyc !



Pour le lancement de Threadripper, AMD aurait réservé les deux meilleurs pourcents de ses dies Zeppelin en stepping B1. Si quatre dies sont présents physiquement, seulement deux sont actifs. Dans tous les cas les CCX sont organisés de manière symétrique, ainsi chaque die du 1920X est configuré en 3+3, comme sur un 1600X par exemple.
Chaque die Zeppelin est pour rappel un SoC qui inclut en plus des huit coeurs, la gestion de 32 lignes PCI Express, deux canaux mémoires, et divers ports SATA/USB.
Threadripper exploite donc ces spécificités, chaque die est relié à quatre slots DIMM sur deux canaux mémoires et chaque die expose ses 32 lignes PCI Express pour obtenir les caractéristiques annoncées par AMD (4 canaux et 64 lignes).
Reste qu'il faut relier ces dies entre eux, et AMD passe pour cela par son Infinity Fabric, la même que celle utilisée pour relier les deux CCX à l'intérieur d'un Zeppelin. La même ou presque !
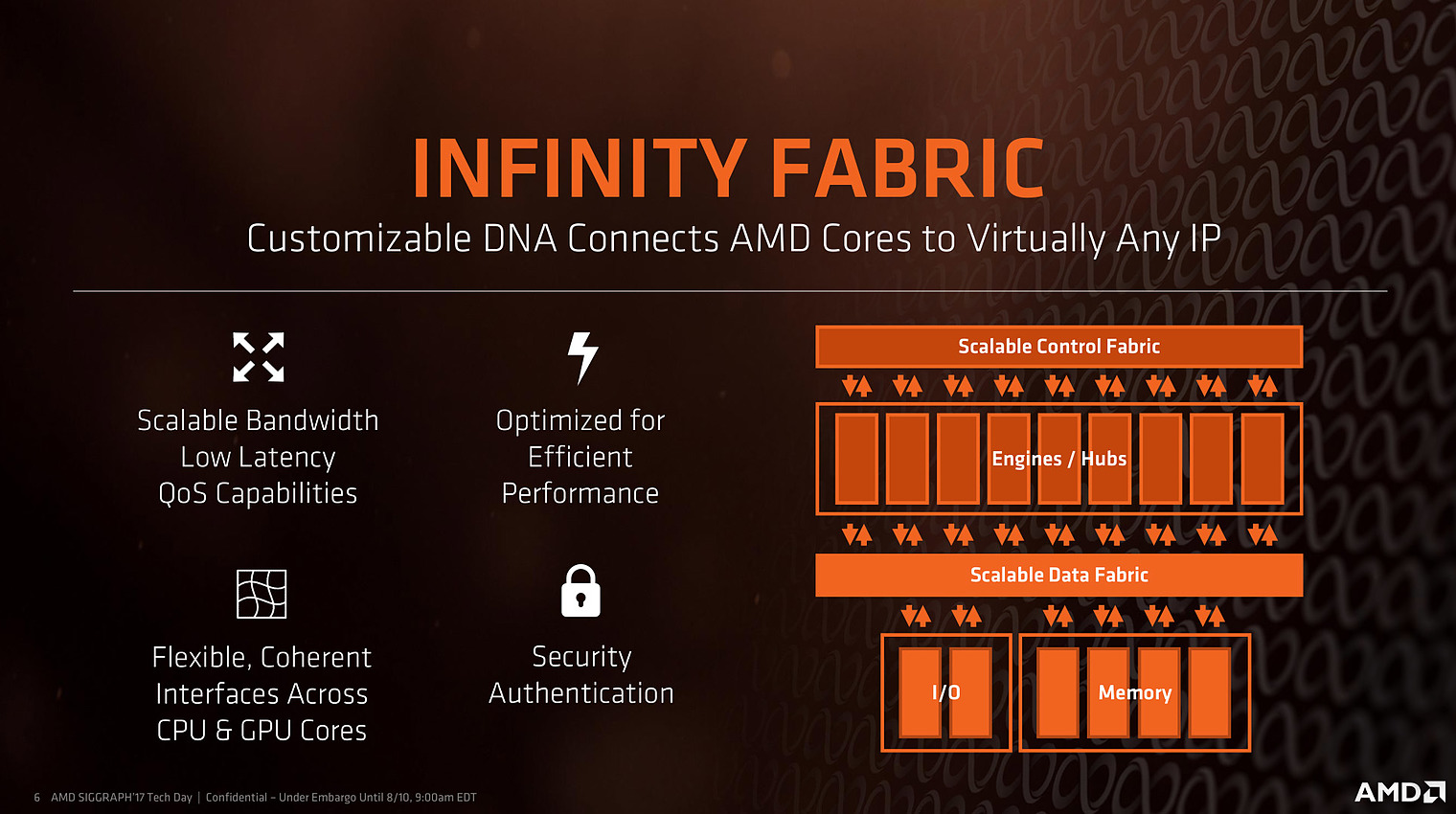


AMD a développé son Infinity Fabric pour qu'elle puisse être utilisée partout, que ce soit à l'intérieur des dies d'un CPU (Ryzen), d'un GPU (Vega), des dies, ou même pour relier des sockets entre eux. L'idée derrière cette Infinity Fabric est de créer des blocs réutilisables dans tous les designs du constructeur pour gagner du temps dans le développement. Le protocole de données est basé sur une version améliorée d'HyperTransport, et l'on retrouve une couche de contrôle ainsi qu'une Data Fabric qui n'est ni plus ni moins qu'un switch entre divers interlocuteurs.
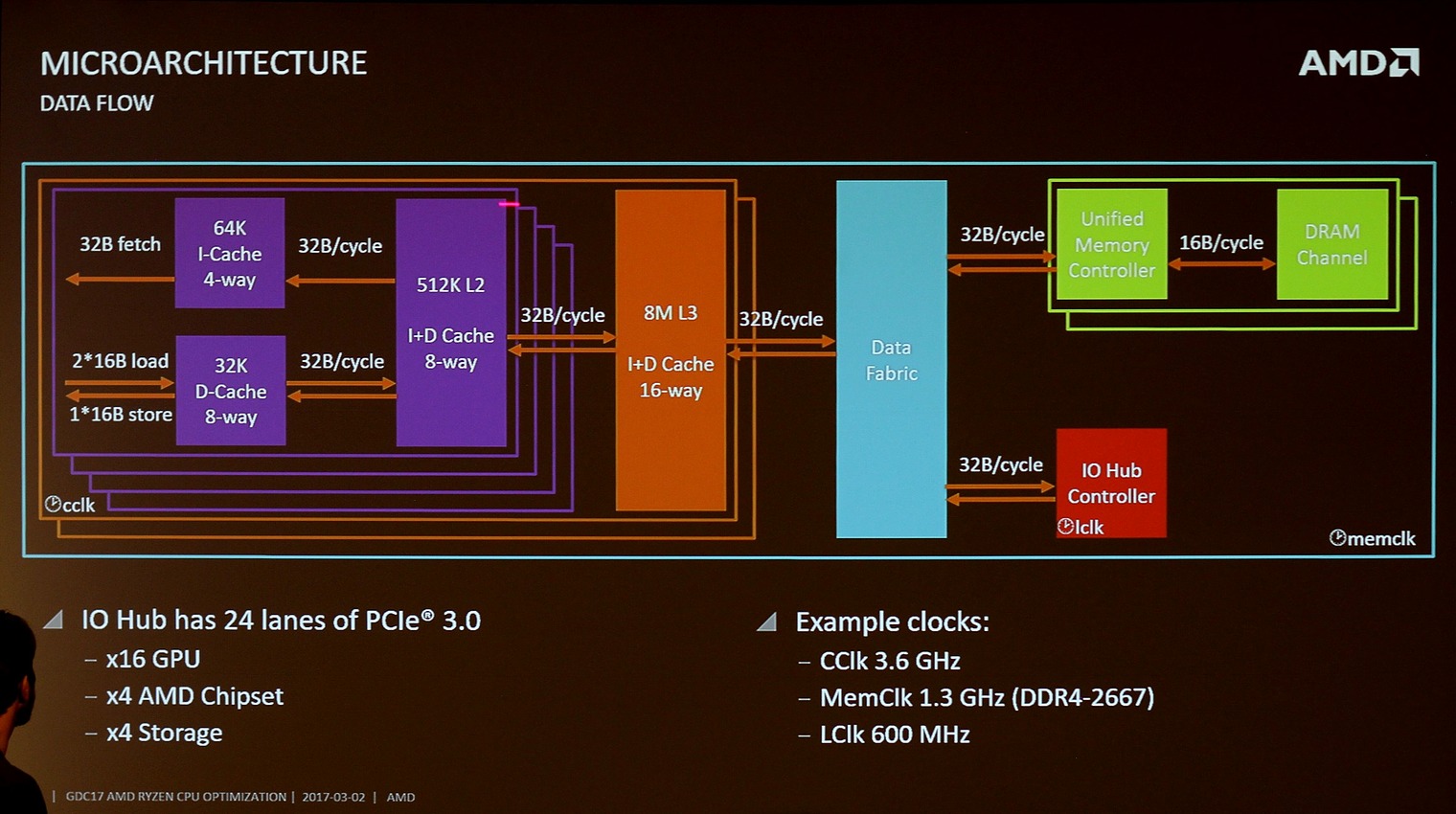
Dans le cas de Ryzen, on retrouve sur ce schéma ci-dessus une explication de l'interconnexion interne dans Zeppelin. Chaque CCX (chaque bloc de quatre coeurs) dispose d'un bus cadencé à la fréquence de la mémoire (1200 MHz en DDR4-2400 par exemple) qui le relie au Data Fabric et permettant de transférer 32 octets par cycle (38.4 Go/s de bande passante). De la même manière, chaque contrôleur mémoire dispose du même bus (38.4 Go/s de bande passante) tandis que la partie IO se contente d'un bus cadencé à 600 MHz et donc d'une bande passante théorique de seulement 19.2 Go/s (la bande passante théorique de 16 lignes PCI Express 3.0 est de 15.75 Go/s, et de 24 lignes de 23.6 Go/s).
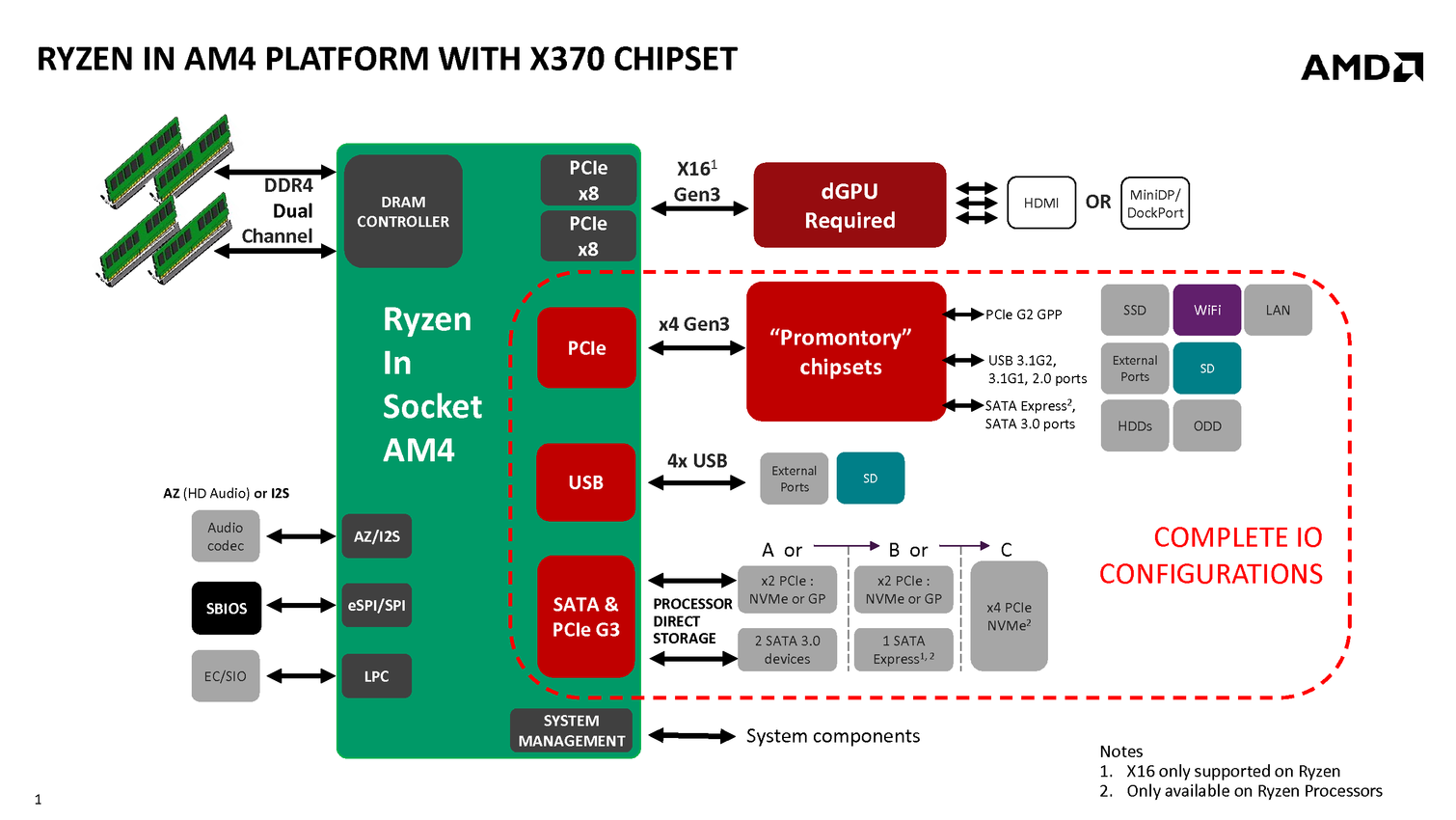
Sur les 24 lignes, seules 16 sont exploitées sur Ryzen pour des cartes graphiques, quatre sont réservées à l'interconnexion avec le chipset Promontory, et quatre pour le stockage (sous la forme de slots M.2 ou de ports SATA). L'USB « CPU » passe aussi par ce hub, chaque die Zeppelin exposant 4 ports USB 3.0.
Dans le cas de Threadripper, 8 lignes supplémentaires sont disponibles dans chaque die pour les cartes graphiques, montant le total à 48 lignes sur deux dies (l'implémentation exacte dépendra des cartes mères), tandis que 8 lignes par die restent bloquées pour le stockage et l'interconnexion chipset. Bien entendu, un seul die est relié au chipset ce qui permet de réutiliser les 4 lignes de l'autre die pour rajouter un slot M.2 par exemple.

Seuls 7 périphériques PCI Express semblent cependant pouvoir être gérés en simultanée (4 par die dont un chipset), dans le cas improbable ou vous utiliseriez 6 cartes PCI Express x8, un seul SSD M.2 pourra être connecté directement sur les lignes de Threadripper. Un petit détail qui ne fâchera personne.
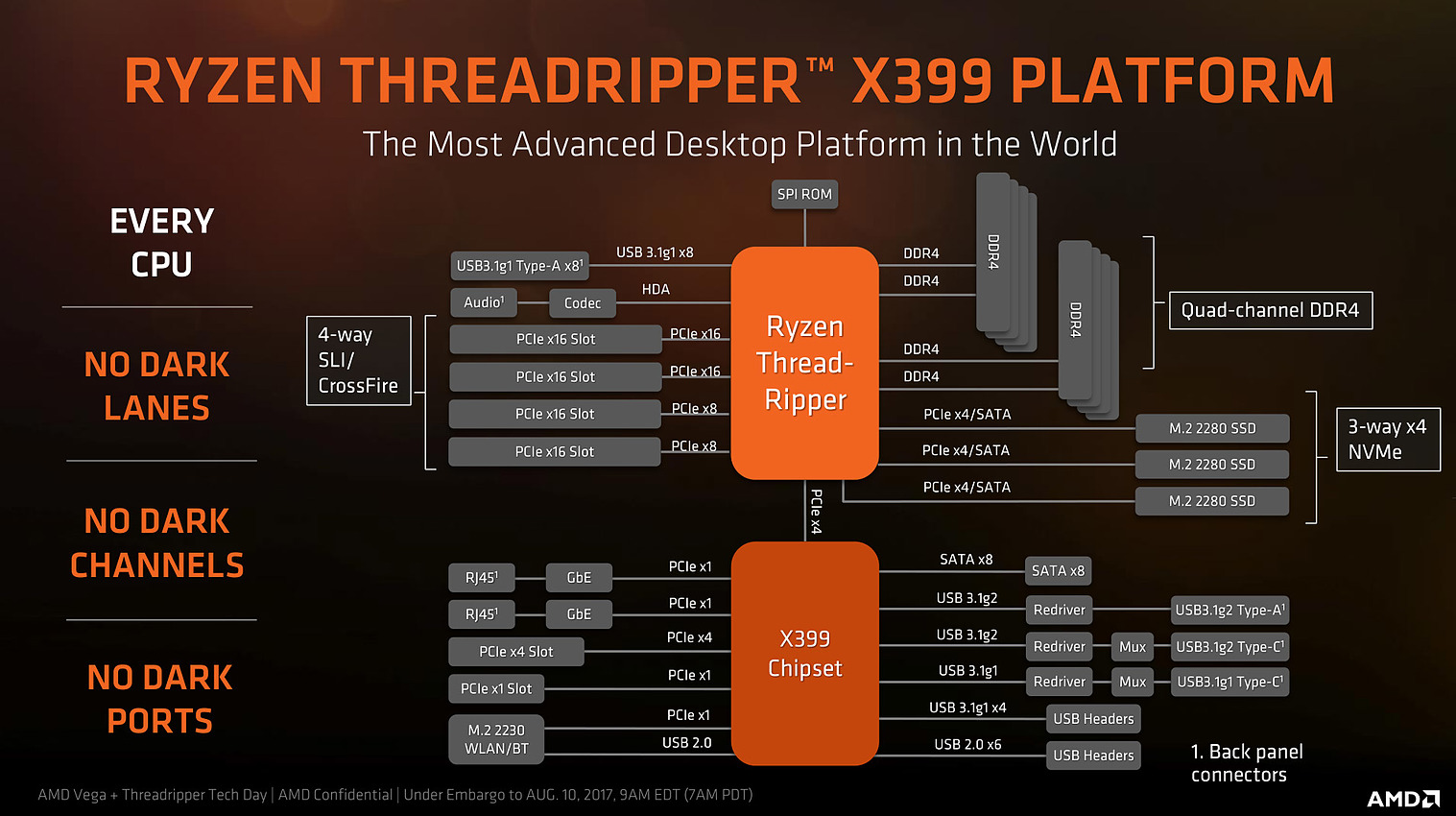
Le résumé par AMD des interconnexions vu de haut niveau
Nous avons demandé à AMD si, pour compenser l'activation de ces lignes, la fréquence du bus qui relie à l'IOhub avait été augmentée, nous attendons actuellement la réponse (comme d'autres) et mettront à jour cet article lors que nous les auront.
L'autre changement par rapport au schéma ci-dessus pour Ryzen concerne l'interconnexion. Car comme nous vous l'indiquions, AMD utilise aussi son Infinity Fabric comme l'indique ce bien particulier schéma :

Chaque die est représenté en gris, et l'on voit l'interconnexion entre les CCX représentée par le gros symbole infini. Un plus petit symbole infini, à 90°, relie les deux dies. Si nous qualifions le schéma de particulier, c'est parce que la taille des symboles ne représente pas du tout la taille des interconnexions !

De la même manière, l'Infinity Fabric externe est un système de switchs avec un lien jusque chaque die, un lien qui disposerait selon AMD d'une bande passante dans chaque sens (mesurée) de 102.22 Go/s. Un chiffre significativement plus haut que la bande passante théorique que l'on retrouve dans les liens entre les CCX (AMD annonçait en bande passante mesurée 21 Go/s environ). Il y a un facteur de quatre et AMD explique que ce bus fonctionne lui aussi à la fréquence mémoire, mais est quad pumped (4 données par clock) ce qui nous donne 128 octets par cycle.
On pourra donc se poser légitimement la question de pourquoi l'on retrouve un bus externe quatre fois plus rapide que le bus interne qui relie chaque CCX au switch. Au minimum, le bus externe semble au moins deux fois trop grand ou le bus des CCX deux fois trop petit.
Nous avons demandé à AMD la raison derrière ce design qui nous semble particulièrement asymétrique et attendons encore une réponse au moment de la publication de cet article. On pourrait supposer que le design original comptait possiblement sur une bande passante plus large à l'intérieur des CCX que ce que l'on voit dans le produit final.
Notez enfin pour terminer que si AMD n'utilise aujourd'hui que deux dies, rien n'empêcherait le constructeur en théorie d'en utiliser trois ou quatre. Certes, les cartes mères sont limitées à 4 canaux mémoires mais il est tout à fait possible de ne pas utiliser les lignes PCI Express additionnelles de ces dies ou leurs canaux mémoires et n'en exploiter que les coeurs, au travers de l'Infinity Fabric. Une possibilité qu'AMD pourrait utiliser pour s'attaquer au futur 18 coeurs d'Intel, même si d'autres problèmes pratiques se poseraient en termes de fréquences (nous y reviendrons !) ce qui n'en ferait probablement pas une grande idée.
2 - Threadripper en détail
3 - Threadripper 1950X et 1920X, les cartes mères
4 - UMA, NUMA, Game mode
5 - Overclocking en pratique
6 - Consommation, efficacité énergétique
7 - Protocole de test
8 - Compression : 7-Zip et WinRAR
9 - Compilation : Visual Studio et MinGW-w64/GCC
10 - Encodage vidéo : x264 et x265
12 - Traitement photos : Lightroom et DxO Optics Pro
13 - Rendu 3D : Mental Ray et V-Ray
14 - Jeux 3D : Project Cars et F1 2016
15 - Jeux 3D : Civilization VI et Total War : Warhammer
16 - Jeux 3D : GTA V et Watch Dogs 2
17 - Jeux 3D : Battlefield 1 et The Witcher 3
18 - Indices de performance
19 - Un retour en forme Epyc ?
Contenus relatifs
- [+] 09/05: AMD Ryzen 7 2700, Ryzen 5 2600 et I...
- [+] 23/04: MAJ de notre test des Ryzen 7 2700X...
- [+] 19/04: AMD Ryzen 2700X et 2600X : Les même...
- [+] 13/04: Les AMD Ryzen Pinnacle Ridge en pré...
- [+] 14/03: Des failles de sécurité spécifiques...
- [+] 08/03: Quatre Ryzen+ Pinnacle Ridge pour a...
- [+] 21/02: AMD Ryzen 5 2400G et Ryzen 3 2200G ...
- [+] 12/02: AMD lance les APU Ryzen 5 2400G et ...
- [+] 09/02: AMD Ryzen 3 2200G et 5 2400G : MAJ ...
- [+] 07/02: Windows 10, Meltdown et Spectre : q...