
AMD FX-8150 et FX-6100, Bulldozer débarque sur AM3+
Publié le 12/10/2011 par Marc Prieur



 Enfin ! Après avoir été repoussée à plusieurs reprises, l'architecture AMD Bulldozer arrive sur le marché. Sa déclinaison AM3+, nom de code Zambezi, prend comme prévu la dénomination commerciale d'AMD FX, un nom qui n'est pas sans rappeler la glorieuse période du K8 durant laquelle AMD mettait à mal Intel et ses Pentium 4. L'AMD FX sera-t-il à la hauteur de son nom ?
Enfin ! Après avoir été repoussée à plusieurs reprises, l'architecture AMD Bulldozer arrive sur le marché. Sa déclinaison AM3+, nom de code Zambezi, prend comme prévu la dénomination commerciale d'AMD FX, un nom qui n'est pas sans rappeler la glorieuse période du K8 durant laquelle AMD mettait à mal Intel et ses Pentium 4. L'AMD FX sera-t-il à la hauteur de son nom ?Une architecture CMT et haute fréquenceNous avions consacré un dossier à l'architecture Bulldozer en mai dernier, toutefois il n'est pas inutile de revenir rapidement sur les principales caractéristiques de celle-ci.
La base de l'architecture Bulldozer, c'est l'utilisation de la technologie Cluster Multi-threading (MT). Un processeur 8 curs est en fait composé de 4 modules. Au sein d'un module, les deux curs se partagent un certain nombre de leurs composants :
- l'étage « front-end » qui regroupe l'unité de fetch (chargement) et de décodage des instructions, ainsi que le cache L1 d'instructions qui est alimenté par ces unités ;
- l'unité de calcul sur les nombres flottants ;
- le cache L2.
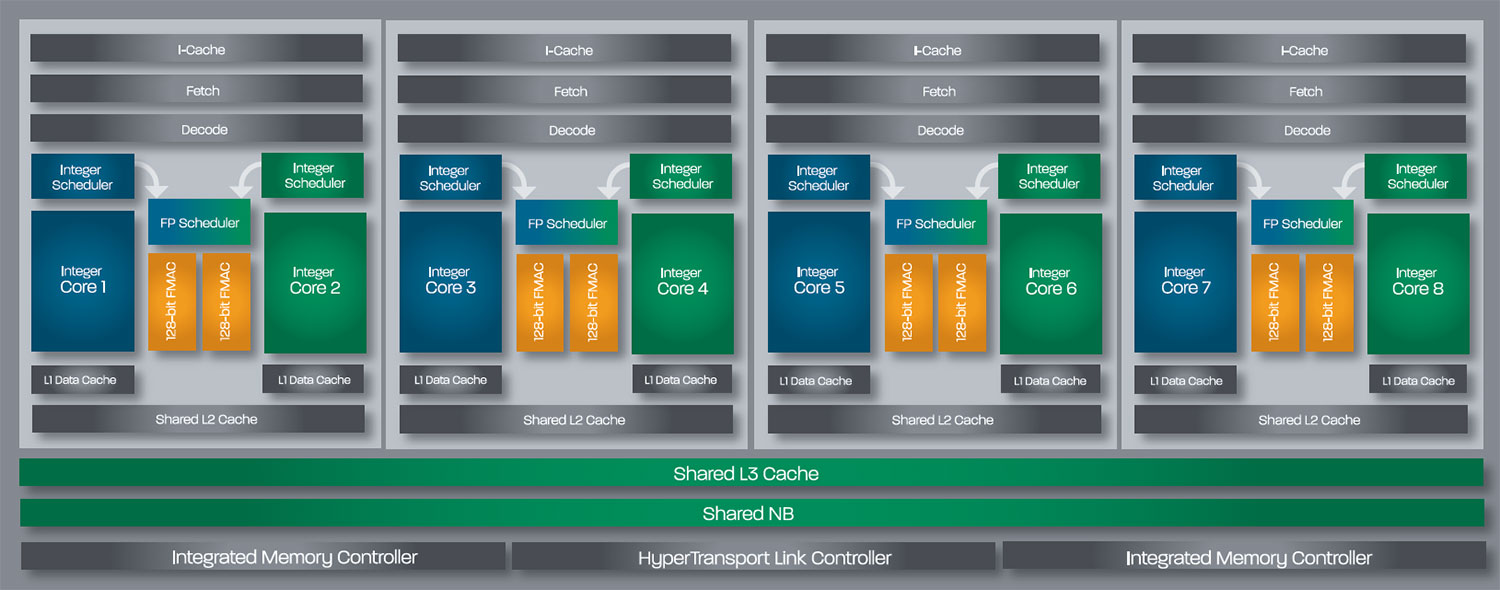
Selon AMD, les deux curs au sein d'un module obtiendraient 80% de performances de deux curs complets, pour d'importantes économies tant en terme de surface sur la puce que de consommation. Beaucoup d'autres modifications ont été apportées, tant au niveau des unités de calculs elles-mêmes que du sous-système de cache, notamment dans l'optique de permettre à l'architecture d'atteindre un haut niveau de fréquence.
Bulldozer supporte de plus 100% des jeux d'instructions x86 actuels, et il est donc compatible avec les dernières versions du SSE4 (4.1 et 4.2) et les instructions AES-NI qui permettent d'accélérer l'encryptage. L'AVX, introduit par Intel avec Sandy Bridge, et ses opérantes de 256 bits est de la partie.
On note également l'apparition de quelques instructions propres, regroupées sous le nom de XOP, FMA4 et CVT16. Ces jeux d'instructions correspondent en réalité au SSE5 (annoncé par AMD en 2007 mais jamais implémenté) adapté au format AVX. XOP opère principalement sur des opérandes entières, FMA4 sur les flottants 128-bits, et CVT16 regroupe des instructions de conversion de flottants haute précision en flottants de moyenne et basse précision. Le FMA4, qui permet de faire une multiplication et une addition en un seul cycle, devrait entre autre permettre des gains lorsqu'il sera utilisé par les logiciels, mais c'est une version différente qui sera utilisée par Intel, le FMA3. AMD suivra Intel dans cette voix et l'architecture Piledriver, évolution de Bulldozer, ce qui laisse des doutes quant à la pérennité du FMA4.
Zambezi devient AMD FX

Sommaire
1 - Une nouvelle architecture
2 - Zambezi devient AMD FX
3 - AM3+, un passage quasi obligatoire ?
4 - AMD FX-8150 et FX-6100 en test
5 - Nouveau protocole de test
6 - Les unités de calculs
7 - Performances des caches
8 - Performances mémoire
9 - Efficacité du CMT
10 - CMT, Turbo Core 2.0 et Windows 8
11 - Tests à 3.2 GHz
12 - Consommation et efficacité énergétique
2 - Zambezi devient AMD FX
3 - AM3+, un passage quasi obligatoire ?
4 - AMD FX-8150 et FX-6100 en test
5 - Nouveau protocole de test
6 - Les unités de calculs
7 - Performances des caches
8 - Performances mémoire
9 - Efficacité du CMT
10 - CMT, Turbo Core 2.0 et Windows 8
11 - Tests à 3.2 GHz
12 - Consommation et efficacité énergétique
13 - Overclocking
14 - Rendu 3D : Mental Ray et V-Ray
15 - Compilation : Visual Studio et MinGW/GCC
16 - Compression : 7-zip et WinRAR
17 - Encodage : x264 et MainConcept H.264
18 - Traitement photo : Lightroom et Bibble
19 - IA d'échecs : Houdini et Fritz
20 - Jeux 3D : Crysis 2 et Arma II : OA
21 - Jeux 3D : Rise of Flight et F1 2011
22 - Jeux 3D : Total War Shogun 2, Starcraft II et Anno 1404
23 - Moyennes
24 - Conclusion
14 - Rendu 3D : Mental Ray et V-Ray
15 - Compilation : Visual Studio et MinGW/GCC
16 - Compression : 7-zip et WinRAR
17 - Encodage : x264 et MainConcept H.264
18 - Traitement photo : Lightroom et Bibble
19 - IA d'échecs : Houdini et Fritz
20 - Jeux 3D : Crysis 2 et Arma II : OA
21 - Jeux 3D : Rise of Flight et F1 2011
22 - Jeux 3D : Total War Shogun 2, Starcraft II et Anno 1404
23 - Moyennes
24 - Conclusion
Vos réactions
Contenus relatifs
- [+] 17/03: AMD baisse ses prix AM3+/FM2+
- [+] 14/03: Bundle AMD pour les FX-6 et FX-8
- [+] 25/11: AMD dégaine ses offres de fin d'ann...
- [+] 04/10: AMD lance les Bristol Ridge Pro
- [+] 24/08: Deus Ex en bundle... avec les AMD F...
- [+] 19/05: Total War : Warhammer offert par AM...
- [+] 02/02: Excavator FM2+ et nouveaux ventirad...
- [+] 28/01: L'AM3+ a droit au M.2 et l'USB 3.1 ...
- [+] 15/12: AMD FX-6330 = FX-6300 + 100 MHz
- [+] 01/10: Perfs avec 2, 4, 6 et 8 curs : 4 j...