
Actualités cartes graphiques
Pilotes GeForce 391.24 pour Sea of Thieves
Microsoft annonce DirectX Raytracing
Radeon Software 18.3.3 beta avec Vulkan 1.1
3 millions de GPU vendus pour le minage
Radeon Software 18.3.1 optimisé pour PUBG et DOTA 2
Nvidia abandonne son GeForce Partner Program
AMD Vega 7nm en labo, Zen 2 échantillonné en 2018
ASUS AREZ, l'effet GeForce Partner Program
Nvidia : fin du support Fermi et 32-bit
Pilotes Radeon et GeForce pour Far Cry 5
Nvidia abandonne son GeForce Partner Program



 C'est via un billet de blog que Nvidia annonce qu'il met fin à son GeForce Partner Program. Evoqué au sein de cette actualité, ce programme permettait aux partenaires de Nvidia proposant une marque de carte graphique exclusivement basées sur les GeForce de disposer d'avantages, ce qui avait poussé ASUS par exemple à sortir les Radeon des gammes actuelles pour une nouvelle dénommée AREZ.
C'est via un billet de blog que Nvidia annonce qu'il met fin à son GeForce Partner Program. Evoqué au sein de cette actualité, ce programme permettait aux partenaires de Nvidia proposant une marque de carte graphique exclusivement basées sur les GeForce de disposer d'avantages, ce qui avait poussé ASUS par exemple à sortir les Radeon des gammes actuelles pour une nouvelle dénommée AREZ.
Le constructeur met en avant une mauvaise compréhension d'un programme destiné à s'assurer que les joueurs voulant du Nvidia ont du Nvidia même si on a du mal à comprendre en quoi c'est un problème à l'heure actuelle et en quoi GPP le résolvait.
Voilà donc une bonne nouvelle à notre sens, reste à savoir quel sera le comportement des fabricants qui avaient déjà enclenchés des changements afin de se plier au GPP.
AMD Vega 7nm en labo, Zen 2 échantillonné en 2018
Déjà évoqué par AMD lors du CES par exemple, la version 7nm de Vega tourne actuellement sous forme de prototype dans les laboratoires d'AMD. C'est Lisa Su, CEO d'AMD, qui vient de l'indiquer lors de l'annonce des résultats.

Il ne s'agit pas d'une avance sur le planning, le constructeur se limitant à évoquer un échantillonnage en version "Instinct" (gamme destinée aux calculs type AI) "plus tard dans l'année", sans parler de production en volume et encore moins de version Radeon. AMD précise au passage que c'est TSMC qui grave ce GPU.
Concernant Zen 2 en 7nm, AMD précise que les déclinaisons serveurs devraient également être échantillonnées cette année, pour une arrivée qui reste prévue en 2019, sans plus de précision, côté desktop également.
ASUS AREZ, l'effet GeForce Partner Program
Le 1er mars dernier, Nvidia présentait brièvement via un billet de blog son GeForce Partner Program (GPP). Présenté pour aider les joueurs, et bien entendu pas Nvidia (sic), ce programme permet aux fabricants de PC et de cartes graphiques y adhérant d'avoir un temps d'avance sur les autres en terme d'informations sur les nouveautés et d'accès aux équipes d'ingénieurs Nvidia. L'une des contraintes pour y adhérer est que le fabricant ne peut plus avoir que des produits Nvidia sous une même marque.
Plus précisément, et ce n'est pas précisé dans le billet, le partenaire aurait l'obligation d'avoir sa « Gaming Brand Aligned Exclusively With GeForce » selon HardOCP , un point qui mériterait d'être éclaircis : lui est-il possible d'avoir une marque Gaming, regroupant autre chose des cartes graphiques, avec des GPU autres que les Nvidia ? Dans la négative on peut avoir des doutes sur la légalité d'une telle clause.
Pour les fabricants de cartes graphiques exclusifs (EVGA, Inno3D, KFA2 ou Zotac par exemple) ce n'est pas un problème, mais cela a donc quelques conséquences pour ceux qui ne le sont pas (ASUS, Gigabyte ou MSI par exemple) puisqu'en état de leurs gammes ils ne sont pas éligibles.
S'il souhaite adhérer à ce programme et ne pas avoir un temps de retard, ASUS par exemple ne peut plus vendre sous sa marque Republic of Gamers (ROG), sur laquelle il a déjà beaucoup investi côté marketing, des GPU de marques AMD et Nvidia.

C'est pour cette raison qu'ASUS vient d'annoncer la gamme ASUS AREZ destinée exclusivement aux cartes graphiques dotées de GPU AMD, les cartes Nvidia restant pour leur part sur les gammes existantes et étant donc les seules à profiter du marketing passé sur ces dénominations. Disponibles à partir de mai, les ASUS AREZ couvriront toute la gamme : RX 550, RX 560, RX 570, RX 580, RX Vega 56 et RX Vega 64.
AMD de son côté indique que d'autres partenaires devrait lancer de nouvelles marques "s'appuyant sur AMD Radeon" dans les semaines à venir, preuve s'il le fallait que tout le monde ou presque va passer au GPP, et a publié un billet de blog mettant en avant des valeurs d'ouverture et de transparence qui n'est pas sans faire écho aux choix de Nvidia.
Sans aller jusqu'à accuser l'actuel leader du marché du GPU de pratiques monopolistiques et anti-concurrentielles à ce stade, il est clair que Nvidia essaie via son programme GPP de sécuriser sa position par des manoeuvres assez douteuses, que ce soit vis-à-vis d'AMD ou l'arrivée dans quelques années d'Intel côté GPU. Vu la situation actuelle, était-ce bien nécessaire ?
Nvidia : fin du support Fermi et 32-bit
Nvidia a indiqué que les GeForce Fermi, soit les séries 400 et 500, ne seront plus supportés par les pilotes classiques "Game Ready" qui se limiteront donc aux Kepler, Maxwell et Pascal. Ces cartes recevront toutefois les mises à jour de sécurités critique jusqu'en janvier 2019.
Pour rappel Fermi a fait son apparition en mars 2010, cf. notre test des GeForce GTX 480 & 470, avant l'arrivée de la GTX 580 en novembre de la même année.
L'arrêt du support des OS 32-bit débute également ce mois , avec là encore des mises à jour critiques disponible jusqu'en janvier 2019. A noter que GeForce Experience ne sera de son côté plus maintenu en 32-bit, même en cas de découverte d'une faille critique.
Pilotes Radeon et GeForce pour Far Cry 5
A l'occasion du lancement de Far Cry 5, AMD et Nvidia proposent coup sur coup de nouveaux pilotes optimisés pour ce titre. Chez AMD tout d'abord, outre le support optimisé de ce titre (AMD note malgré tout que ces pilotes peuvent causer des clignotements dans ce jeu en multi GPU après avoir utilisé Alt+TAB), on retrouve également quelques correctifs.
Pour Final Fantasy XV, certains effets de lumières sur les arbres à certains endroits de la carte ont été corrigés, tout comme un bug qui pouvait causer un crash à l'arrivée du second chapitre. Dans la liste des "problèmes corrigés", le constructeur parle aussi d'une baisse de performances sur certaines charges "blockchain" comparé aux pilotes précédents, ce qui nous rend assez circonspects, on ne sait pas si la chose est corrigée ou si c'est ce pilote qui est plus lent. On notera également dans les problèmes connus que ces pilotes peuvent causer un crash système après une utilisation prolongée et simultanée de 12 GPU (!) pour des tâches compute. Ces pilotes 18.3.4 sont téléchargeables sur le site du constructeur .
Chez Nvidia, il s'agit des pilotes 391.35 qui apportent un support pour ce titre. Quelques bugs ont été corrigés, un problème d'Alt-TAB sous Diablo III en SLI avec V-Sync actif qui pouvait planter le jeu, et une fuite mémoire de GeForce Experience lorsque l'on utilise la fonction "freestyle". Plus important, le pilote apporte des correctifs de sécurité pour ses pilotes. 7 CVE sont pointés par Nvidia, plusieurs s'attaquant au pilote "noyau" (nvlddmkm.sys) avec des risques importants d'escalade de privilèges.
Contrairement aux autres périphériques sous Windows dont les pilotes fonctionnent dans l'espace mémoire utilisateur (une restriction imposée par Microsoft pour réduire les plantages), les GPU disposent encore d'un petit pilote niveau "noyau", ce qui permet théoriquement aux pilotes GPU de planter complètement votre système (ou d'être un vecteur de failles) contrairement à un pilote USB par exemple, quelque chose dont Microsoft se plaint souvent même s'ils sont responsables de cette situation !
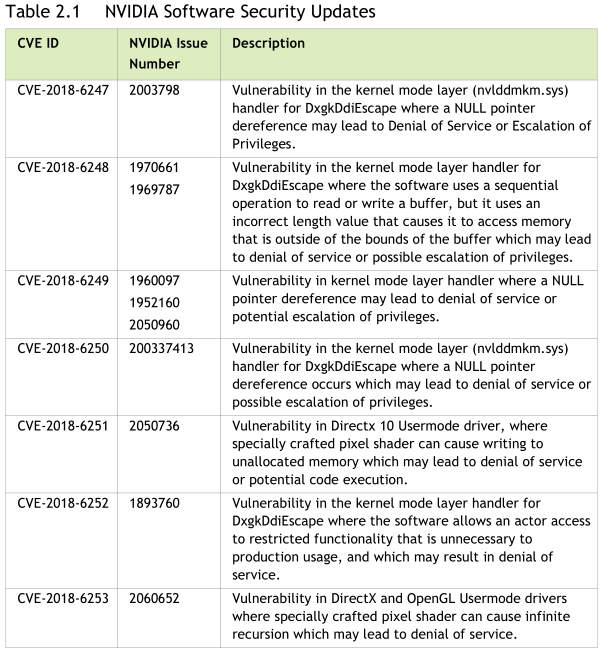
Certaines failles concernent également le pilote en espace mémoire "utilisateur". Nous ne pouvons que vous conseiller de mettre à jour vos pilotes qui sont téléchargeables ici pour Windows 7 , et là pour Windows 10 .