
Actualités processeurs
MAJ de notre comparatif CPU géant
AMD Ryzen 2700X et 2600X : Les mêmes en plus petit ?
Les AMD Ryzen Pinnacle Ridge en précommande
LGA4189 pour les Xeon Ice Lake !
Pas de MAJ Microcode pour les Gulftown et Penryn !
AMD Ryzen 7 2700, Ryzen 5 2600 et Intel Core i7-8700, Core i5-8600
Un Coffee Lake 8 coeurs en préparation ?
Le 10nm d'Intel (encore) retardé, le 7nm TSMC lancé
Jim Keller rejoint... Intel !
MAJ de notre test des Ryzen 7 2700X et Ryzen 5 2600X
Dossier : AMD Ryzen 7 2700, Ryzen 5 2600 et Intel Core i7-8700, Core i5-8600



Après les Ryzen 7 2700X et les Ryzen 5 2600X, nous nous intéressons aujourd'hui au 2700 et 2600 de la nouvelle gamme d'AMD. Sans oublier les Core i7-8700 et Core i5-8600 qui s'invitent, eux aussi à 65W...
[+] Lire la suite

Un Coffee Lake 8 coeurs en préparation ?
Le fabricant de PC allemand bluechip a publié par mégarde sur Youtube une présentation intégrant ce que seraient les nouveautés AMD et Intel pour cette année.

Côté AMD tout d'abord, il est question des chipsets AMD Z490 et B450 pour juin et fin juillet. On ne sait pas encore ce qu'apporteront ces puces, le X470 offrant les mêmes fonctionnalités que le X370. C'est en août qu'on devrait voir débarquer de nouveaux Threadripper basés sur les mêmes dies que les Ryzen 2xxx qui profitent du 12nm.
Côté Intel si Cascade Lake-X LGA 2066 n'est bizarrement pas présent, bluechip annonce l'arrivée pour le dernier trimestre 2018 d'un Coffee Lake 8 coeurs. Les prototypes seraient prévus pour juin. Ce n'est pas la première fois qu'il est question de l'arrivée d'un 8 coeurs "grand public" fin 2018 chez Intel, mais il était question à l'époque de Ice Lake. Le 10nm étant en retard, l'arrivée d'une version 14nm est logique et devrait permettre à Intel de répondre pleinement à l'offensive Ryzen d'AMD.
Il faut par contre espérer que ce processeur sera bien compatible avec toutes les cartes mères LGA 1151 et non pas seulement avec celles en Z390 prévues pour le troisième trimestre avec Intel rien n'est moins sûr !
Le 10nm d'Intel (encore) retardé, le 7nm TSMC lancé
Intel vient d'annoncer lors de la présentation de ses résultats trimestriels que le 10nm sera de nouveau retardé. La production en volume ne débutera ainsi plus au second semestre 2018 mais en 2019, sans plus de précisions. Le fabricant insiste sur le fait qu'il fabrique et livre des produits (lesquels ?) 10nm en faible volume, mais le taux de rebus est encore trop élevé et nécessite des améliorations qui nécessitent encore du temps pour être implémentées et qualifiées.
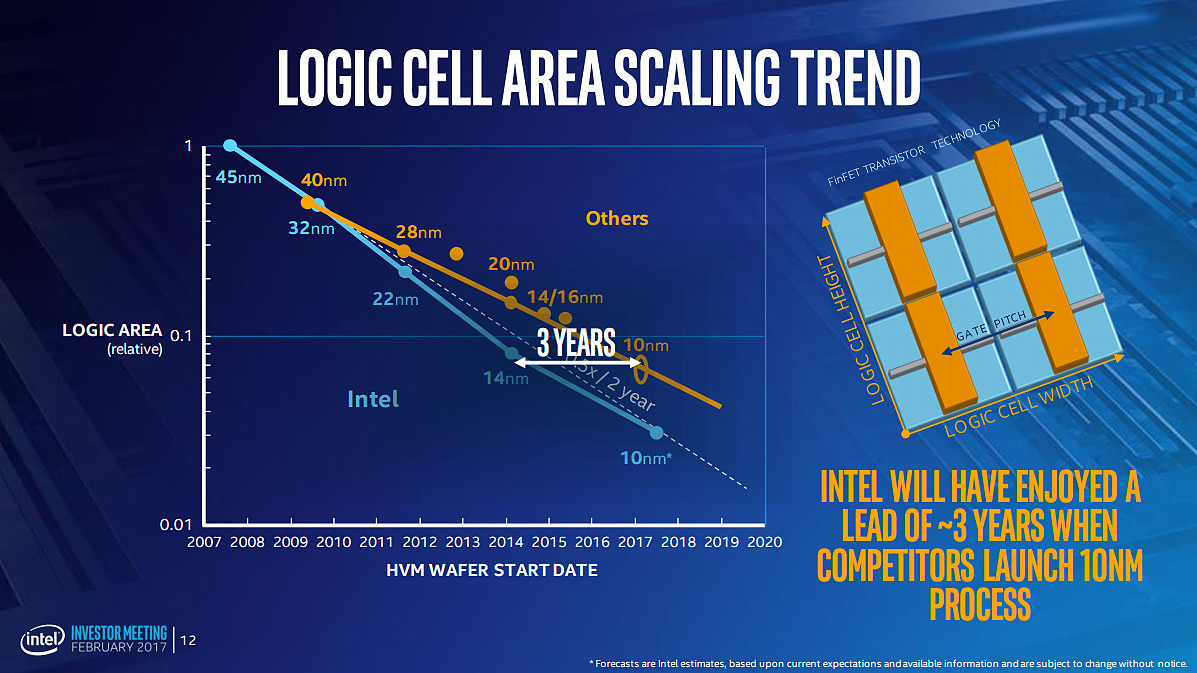
Début 2017, Intel positionnait le 10nm pour mi 2017 sur ce graphique
Le 14nm d'Intel va donc encore être appelé à la rescousse cette année, en plus de Cascade Lake pour les serveurs qui sera également décliné en version Core i7 LGA 2066, un Whiskey Lake (!) a priori destiné au marché de portable.
En quelques années Intel aura donc perdu son avance sur ses concurrents, puisque dans le même temps TSMC vient de confirmer que sa production en 7nm, dont la densité est a priori équivalente en pratique au 10nm Intel, a bien débuté ce second trimestre comme prévu.
Il s'agit d'une première étape pour le taiwanais avant le "N7+" prévu pour l'an prochain et qui intégrera un peu d'EUV et offrira une densité en hausse de 20% pour une consommation en baisse de 10%.
Jim Keller rejoint... Intel !
C'est une petite surprise, Jim Keller, ingénieur connu pour les plus gros succès d'AMD (Athlon, Athlon 64 et Zen) rejoint aujourd'hui Intel d'après nos confrères de Fortune .

Connu pour son rôle dans le design des DEC Alpha, il a également dirigé les équipes qui ont conçu les K7 (Athlon) et K8 (Athlon 64) pour AMD, avant de se retrouver suite à un rachat (de P.A. Semi) en charge de la future architecture ARM custom d'Apple. Il est retourné en 2012 chez AMD ou il s'est occupé de l'architecture de Zen.
Depuis, il avait tenu plusieurs postes, dont un passage éclair chez Samsung. Depuis deux ans, il avait rejoint Tesla en tant que Vice Président en charge du hardware custom embarqué. Suite au départ de Chris Lattner (ex-Apple), il avait également récupéré la direction d'Autopilot.
Intel n'a pas encore communiqué officiellement sur son rôle, le communiqué de Tesla indiquant simplement que "la passion principale de Jim était l'ingénierie de micoprocesseurs et qu'il rejoint une société ou il pourra de nouveau s'y consacrer exclusivement".
MAJ de notre test des Ryzen 7 2700X et Ryzen 5 2600X
Nous avons mis à jour notre test des Ryzen 7 2700X et Ryzen 5 2600X avec quelques nouvelles précisions :
- d'abord, contrairement à certaines rumeurs lancées par un de nos confrères, il n'y a pas de "surconsommation" à noter sur la Crosshair VII Hero par rapport aux autres cartes mères. Nous avons mesuré la consommation sur trois cartes pour le vérifier, vous pouvez retrouver cela sur la page overclocking.
- contrairement à ce que nous avions indiqué dans un premier temps, le XFR2 n'est pas une fonctionnalité exclusive aux cartes mères X470. Nous avons pu vérifier que les fréquences de fonctionnement étaient identiques sur une Crosshair VI Hero (X370) avec le BIOS 6004 (AGESA 1.0.0.2a) et sur la Crosshair VII Hero (X470) utilisée pour notre test.
- Nous avons confirmé également que les gains de latence, que nous avions décomposé en deux (une partie liée à l'AGESA 1.0.0.2 et l'autre à ce qu'AMD appelle une "meilleure utilisation de son silicium"), se retrouve à l'identique sur X370 avec les BIOS adéquat. La latence du 2700X est strictement identique sur X370. Vous retrouverez plus de détails sur cette page.

Au final nous confirmons qu'avec les BIOS adéquat, les performances sont identiques pour le Ryzen 7 2700X sur X370 et X470, que ce soit à 3 GHz ou à fréquence de base. La seule fonctionnalité qui semble exclusive au X470 est le Precision Boost Overdrive, un overclocking du XFR2. Vous pourrez retrouver là aussi plus de détails sur le sujet ici et là.