
Actualités processeurs
Intel lance la 2ème vague de sa 8ème génération
AMD va patcher les failles pointées par CTS-Labs
Microcode final pour Spectre chez Intel
Des failles de sécurité spécifiques aux Ryzen ?
GlobalFoundries : 12nm, 7nm et EUV
MAJ de notre comparatif CPU géant



Suite au lancement des Ryzen Pinnacle Ridge, nous avons mis à jour notre comparatif CPU géant qui regroupe désormais pas moins de 62 processeurs !

Nous avons ajouté six processeurs AMD pour cette mise à jour : - Ryzen 7 2700X - Ryzen 5 2600X - Ryzen 5 2400G - Ryzen 3 2200G - A10-7870K - A10-7800
Nous avons également mis à jour nos graphiques de rapport performances prix, ainsi que les commentaires qui vont avec en dernière page.
2008-2018 : tests de 62 processeurs et 16 archis Intel et AMD !
Dossier : AMD Ryzen 2700X et 2600X : Les mêmes en plus petit ?
Un an après le retour aux affaires d'AMD avec Ryzen dans le monde des CPU, le constructeur lance une deuxième fournée en 12nm. De quoi changer l'ordre établi ?
[+] Lire la suite

Les AMD Ryzen Pinnacle Ridge en précommande
Ca devient une mauvaise habitude, AMD vient d'ouvrir les précommandes de ces Ryzen "Pinnacle Ridge", leur disponibilité effective ainsi que les tests étant attendus pour le 19 avril.
Toujours au format AM4 et utilisant toujours l'architecture Zen, ces Ryzen ont notamment pour particularité de faire appel au 12nm de GlobalFoundries ce qui leur permet de bénéficier de quelques gains en fréquence. Trois modèles sont lancés :
- Ryzen 7 2700X, 8C/16T, 3.7/4.3 GHz, 105W, 329$
- Ryzen 7 2700, 8C/16T, 3.2/4.1 GHz, 65W, 299$
- Ryzen 5 2600X, 6C/12T, 3.6/4.2 GHz, 95W, 229$
- Ryzen 5 2600, 6C/12T, 3.4/3.9 GHz, 65W, 199$
Le Ryzen 7 2700X, vient se positionner entre les prix des 1700X et 1800X (309 et 349$), il offre par contre des fréquences de 100 à 300 MHz supérieures et est désormais livré avec un ventirad Wraith Prism. Le surplus de fréquence ne se fait toutefois pas sans concessions, le 12nm ne faisant a priori pas de miracle : AMD a du pousser le TDP de 95 à 105W, même si il faut bien dire que sur le 1800X les 95W n'étaient déjà pas vraiment respectés.
Le R7 2700 est au même prix et TDP que son prédécesseur, il dispose de fréquences 200 à 400 MHz supérieures. Les R5 2600X et 2600 sont 10$ plus onéreux que les 1600X et 1600. Sur le X seule la fréquence Turbo est en hausse (+200 MHz), mais il bénéficie désormais d'un ventirad Wraith Spire. Le 2600 bénéficie de 200 à 300 MHz de plus par rapport au 1600.
De nouvelles cartes mères supportant nativement ces processeurs sont prévues, elles utiliseront notamment le chipset X470 qui ne se distingue finalement pas du X370 par la gestion du PCIe Gen3 : il semble s'agir d'un simple renommage. Il est toutefois possible de faire fonctionner ces Pinnacle Ridge sur les cartes mères AM4 existantes, à condition que leur bios soit à jour sans peine de quoi il ne sera pas possible de démarrer comme c'est également le cas avec les Raven Ridge !
LGA4189 pour les Xeon Ice Lake !
Le Socket LGA3647 des Xeon actuels, qui accueillera prochainement une nouvelle génération de processeurs 14nm dénommée Cascade Lake, sera ensuite remplacé pour les Icelake 10nm par un LGA4189 d'après les documents de la Power Stamp Alliance.
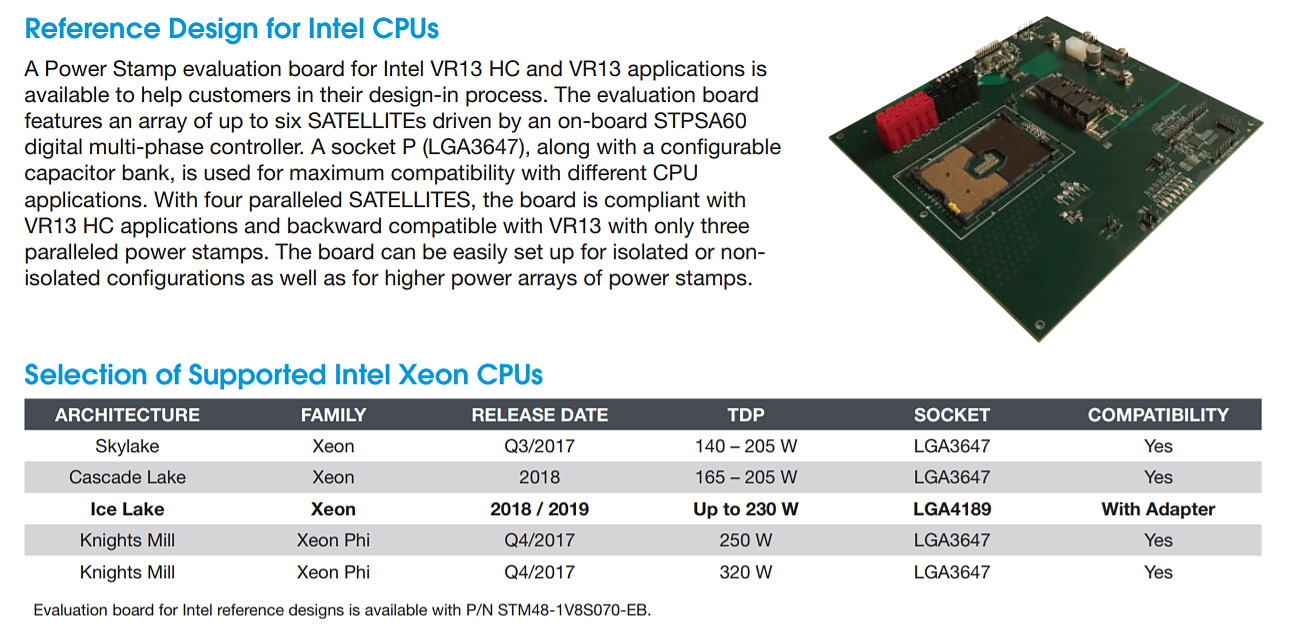
Ces Xeon sont indiqués pour 2018/2019 sur le document (on penche fortement vers 2019), et il est question d'un TDP pouvant attendre 230W contre 205W pour les Xeon actuels. Ils seraient a priori capables de supporter la DDR4 sur 8 canaux, ce qui explique entre-autres l'augmentation du nombre de contacts sur le Socket.
Pas de MAJ Microcode pour les Gulftown et Penryn !
Intel a publié une nouvelle roadmap indiquant l'état du développement de ses patchs de microcode pour les failles Spectre/Meltdown. Après avoir proposé des versions finales pour les processeurs Sandy Bridge et supérieurs, le constructeur évaluait des solutions pour ses plateformes plus anciennes.
En pratique, la dernière communication indique que des patchs sont désormais disponibles (chez Intel, il est peu probable que les constructeurs de cartes mères les proposent via un BIOS et il faudra probablement attendre qu'ils soient rendus disponibles par les mécanismes de mise à jour des OS) pour quelques nouvelles architectures.
Côté desktop "grand public", les Lynnfield (2009, 45nm, LGA 1156, par exemple les Core i7-870) et les Clarkdale (2010, 32nm, LGA1156, par exemple les Core i5-670) disposent désormais d'un microcode indiqué en production par Intel.
Pour les générations antérieures (on arrive a l'époque des Core 2 en LGA775, les plus récents étant les familles Penryn/Yorkfield à partir de 2007 comme le Core 2 Quad Q9400), Intel annonce avoir stoppé le développement.
Du côté des plateformes HEDT (desktop haut de gamme) on va noter une certaine déception. Car si Intel propose des patchs pour ses Xeon Nehalem, la version HEDT de Nehalem connue sous les noms de Bloomfield et Gulftown (2008/2010, 45/32nm, LGA 1366, par exemple les Core i7-990X de 2011) n'aura pas droit au patch.
En pratique côté Xeon, les Westmere (WS, EP, EX, les Xeon Nehalem 32nm, par exemple Xeon X5670) disposent d'un patch, et les Nehalem (WS, EP, EX, les Xeon Nehalem 45nm DP et +) sont patchés. Par contre, les Nehalem "Bloomfield" (les Xeon W35XX) ne seront pas patchés. Les Xeon Core 2 (Wolfdale, etc) ne seront pas non plus patchés.
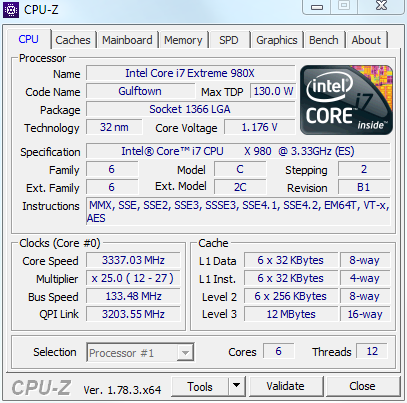
Ce sont donc surtout les (derniers) possesseurs de Gulftown/Bloomfield qui se sentiront les plus lésés par ce changement, les derniers Gulftown étant assez récents même si la plateforme en elle même est assez ancienne (le X58 qui les accompagne n'ayant pas très bien vieilli !). Vous pouvez retrouver l'intégralité des détails de cette mise à jour sur le site d'Intel (PDF) .