
Actualités cartes graphiques
Intel présente un prototype de (mini) dGPU
Résultats records pour Nvidia
Pilotes GeForce 390.77 pour Metal Gear Survive
Sapphire lance la Vega 56 Pulse, sans prix
AMD annonce la restructuration de RTG
Pilotes GeForce 391.24 pour Sea of Thieves



 Nvidia propose également aujourd'hui une nouvelle version de ses pilotes GeForce, les 391.24. La nouveauté principale de ces pilotes est un support optimisé pour Sea of Thieves.
Nvidia propose également aujourd'hui une nouvelle version de ses pilotes GeForce, les 391.24. La nouveauté principale de ces pilotes est un support optimisé pour Sea of Thieves.
Côté bugs, le constructeur dit avoir résolu des problèmes avec les casques VR (Rift et Vive) qui ne fonctionnaient pas après plusieurs lancements à la suite, ou au retour d'une hibernation système. Un problème de stuttering au lancement des vidéo avec MPC-HC est également résolu, ainsi qu'un problème sous Firefox. Un crash à l'installation à également été résolu pour les possesseurs de Surface Laptop.
Côté jeux, un problème de clignotements/corruptions de texture est également résolu pour les GTX 1060 sous Rise of the Tomb Raider.
Vous pourrez télécharger ces pilotes comme toujours sur le site du constructeur, ici pour Windows 7 et là pour Windows 10 .
Microsoft annonce DirectX Raytracing
Microsoft a profité de l'ouverture de la GDC pour annoncer une nouvelle API, DirectX Raytracing (DXR) . Comme son nom l'indique, il s'agit d'une nouvelle API qui vient s'ajouter aux autres API DirectX pour standardiser l'utilisation de certaines techniques dites de raytracing. Le raytracing tente pour rappel de représenter de manière plus exacte le parcours de la lumière pour proposer des rendus réalistes. L'inconvénient de la technique étant son coût généralement prohibitif, même si des approximations existent.
A l'inverse, le rendu 3D dans les jeux actuel est basé sur la rasterisation, la projection d'une scène 3D en 2D avant d'y appliquer les traitements pour obtenir la couleur des pixels, avec des techniques plus ou moins avancées de gestion de lumière (les premiers jeux 3D se contentant d'imiter les effets de lumière en les dessinant directement dans les textures, tandis qu'aujourd'hui les pixel shaders s'appliquent sur l'image 2D ce qui limite les possibilités même si les développeurs sont extrêmement créatifs). Comme le rappelle le sous titre de l'annonce de Microsoft, "3D Graphics is a lie" (le rendu 3D est un mensonge) !
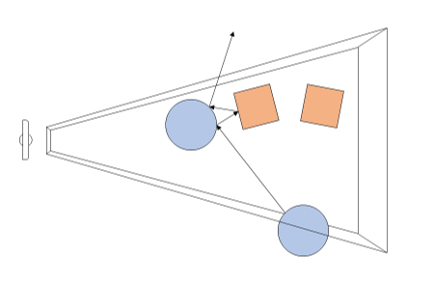
Avec DXR, Microsoft souhaite donc ajouter un peu de "réalisme" avec une petite dose de raytracing. Dans le détail, il s'agit d'une API complémentaire qui ajoute de nouvelles possibilités pour utiliser le raytracing par dessus les pipelines actuels de rasterisation. En pratique, DXR s'appuie sur une représentation de la géométrie pour lancer des rayons. Par dessus cette représentation, chaque objet ou groupe d'objet pourra définir des "raytracing shaders" et des textures spécifiques à utiliser. Une fois ceci crée, le lancé de rayons est appliqué, l'API définie les cas d'intersection, de non intersection, et de "presque" intersection (near miss), en gérant les cas ou les rayons rebondissent sur plusieurs surfaces (multi bounce).
Techniquement, le lancer de rayon est effectué a partir de la "caméra" dans la variante utilisée par DirectX, et peut se faire pour une sélection de pixels de l'écran ou la totalité (Microsoft prend l'exemple de ne le faire uniquement que pour les objets dont la surface est réfléchissante).

Un exemple de rendu DXR avec le moteur SEED d'EA, Project PICA
D'un point de vue compatibilité avec le matériel existant, Microsoft renvoi simplement vers les constructeurs pour les détails. Certains matériels sur le marché disposeraient déjà d'un support de DXR (on ne sait pas lesquels), et Microsoft semble proposer un mode de rendu alternatif s'appuyant sur Direct Compute pour fonctionner sur tout le matériel existant aujourd'hui (avec un niveau de performances on l'imagine réduit).
AMD nous a indiqué qu'ils collaboraient "étroitement" avec Microsoft "pour les aider à définir, améliorer et prendre en charge l'avenir de DirectX 12 et du ray tracing", un propos qui évite soigneusement de prononcer l'acronyme DXR. AMD dispose déjà d'une API de ce type utilisable sur de multiples plateformes avec Radeon Rays . Interrogé sur la question spécifique de l'accélération matérielle, AMD nous a indiqué qu'ils proposeraient, à un moment non défini, un pilote qui proposera une accélération DXR (au delà du mode "fallback" utilisant Direct Compute et qui lui marche sur tous les GPU, mais probablement en étant peu utilisable). Ce qui sera accéléré, et quelles cartes seront concernées n'est pas encore défini non plus selon le constructeur. On semble sentir une certaine précaution pour ne pas dire frilosité de la part de la société sur sa communication, il nous est difficile de savoir s'il s'agit d'un manque de préparation sur le sujet, d'un désaccord avec Microsoft sur certains choix effectués, ou d'autre chose.
Nvidia de son côté a évoqué son implémentation sous le nom de RTX, cette dernière ne s'appliquera qu'à compter des GPU Volta et ultérieurs (soit uniquement la Titan V dans les GPU "joueurs" actuels de la gamme du constructeur). Nvidia présente la technologie là aussi de manière assez vague, sous entendant que leur implémentation sera utilisable "via" DXR, mettant son API en avant sans que l'on sache si c'est simplement dans un but de démarcation compétitive ou autre chose. Là encore à l'image d'AMD, la communication des deux principaux constructeurs ne va pas exactement dans le même sens que celle de Microsoft (les relations entre Microsoft et les responsables GPU ont toujours été particulières, chacun tentant de tirer la couverture de son côté et de créer un avantage compétitif, que ce soit les constructeurs de GPU l'un face à l'autre, ou Microsoft à proposer une API et des fonctionnalités qui ne soient pas cross-platform).
Du côté des développeurs, Microsoft annonce que les moteurs Frostbite, SEED (plus haut), Unity et Unreal Engine proposeront une forme de support de DXR. Futuremark devrait également proposer un test de ce type pour une version de 3D Mark.
Radeon Software 18.3.3 beta avec Vulkan 1.1
AMD a mis en ligne ces dernières heures une nouvelle version beta de ses pilotes graphiques. On retrouve comme souvent un support "optimisé" pour de nouveaux titres, cette fois ci il s'agit de Sea of Thieves et A Way Out.
Côté bugs, un problème de stuttering intermittent sous Forza Motorsport 7 à été corrigé. Pour Final Fantasy XV, ce sont des clignotements et objets disparaissant qui ont été résolus pour les configurations Multi GPU. Enfin pour Battlefront 2, c'est un plantage au lancement du titre, là encore sur des configurations Multi GPU, qui a été corrigé.
L'autre nouveauté de ces pilotes est qu'ils apportent un support de la version 1.1 de Vulkan, l'API "bas niveau" de Khronos Group. Cette nouvelle version avait été annoncée il y a quinze jours de cela apporte plusieurs nouveautés dont les "Subgroup Operations" pour partager des données entre plusieurs tâches sur un GPU et une nouvelle version du langage intermédiaire de shaders, SPIR-V 1.3 (et de ses outils). Nvidia avait de son côté proposé un pilote beta spécifique pour Vulkan 1.1 au moment de l'annonce .
L'autre objectif pour Khronos Group est un support multi plateforme universel. Quelques jours avant l'annonce de cette version 1.1, la "Khronos Vulkan Portability Initiative" avait été annoncée avec pour but de créer des couches de compatibilités fines s'appuyant sur les API bas niveau natives des plateformes, comme DirectX 12 pour Windows ou Metal chez Apple.
Pour rappel, Apple gère le déploiement (et le co développement) des pilotes graphiques pour sa plateforme contrairement à ce que l'on voit sous Windows, et il n'y a pas de support natif dans l'OS pour Vulkan. Microsoft n'en propose pas non plus pour Windows, le support y étant assuré par les pilotes directement (cf cette actualité), comme cela était le cas pour OpenGL dans les dernières versions de Windows.
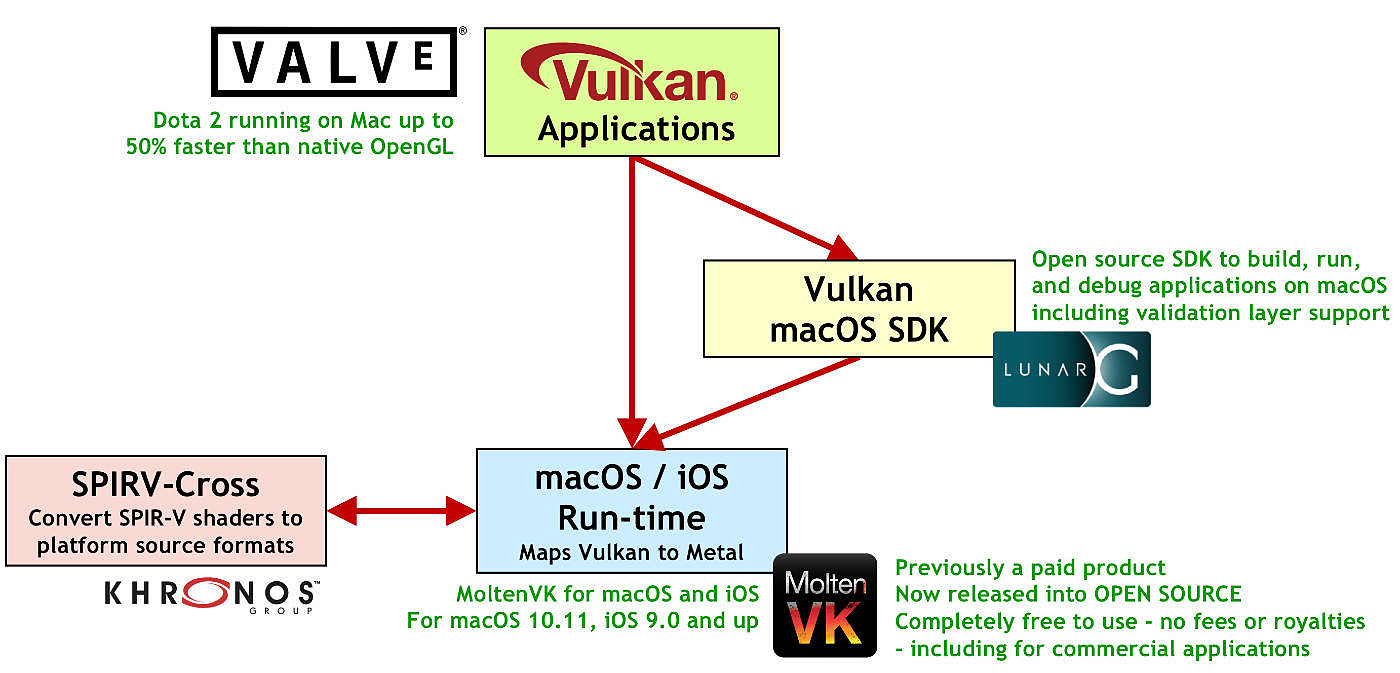
Avec LunarG et MoltenVK, Valve annonce 50% de performances en plus sous Dota 2 par rapport à l'implémentation OpenGL sur Mac
Proposer des couches intermédiaires est donc une solution assez pragmatique, car si en général ces couches sont assez coûteuses, toutes ces API bas niveau sont excessivement proches dans leurs caractéristiques (elles sont après tout de bas niveau et "très proches du métal" avec des similarités larges) ce qui limite grandement l'impact sur les performances. Valve et Brenwill Workshop ont rendu open source LunarG (un SDK MacOS Vulkan spécifique développé par Valve) et MoltenVK (une couche de traduction Vulkan vers Metal pour MacOS et iOS) en partenariat avec Khronos. Vous pouvez retrouver une présentation de cette initiative sur cette page qui évalue également la portabilité pour DirectX 12. Une autre initiative est celle de Mozilla dans le cadre du développement de son API cross plateforme bas niveau gfx-rs .
Le téléchargement de ces pilotes AMD s'effectue sur cette page du site du constructeur .
3 millions de GPU vendus pour le minage
Jon Peddie Research a publié ses estimations de ventes de GPU pour le quatrième trimestre 2017. Si les ventes n'ont pas été bonnes sur le dernier trimestre, cela reste assez relatif car les cartes graphiques ont vu leur ventes augmenter de 9.7% sur l'année, là ou le marché GPU complet (qui inclut également les IGP/portables) baisse sur l'année de 4.8%.
Les bonnes ventes de GPU en 2017 sont bien entendu à mettre à l'actif du minage des diverses crypto monnaies qui ont fortement fait parler d'elles l'année dernière. Si toutes ne sont pas adaptées au GPU, cela n'a pas été sans impact sur les ventes tout le long de l'année avec des pénuries et des hausses de prix.
Selon JPR, trois millions de cartes graphiques auraient été vendues pour cet usage précis (une estimation probablement assez incertaine) en 2017, profitant principalement à AMD. On ne connaît pas le nombre d'unités vendues en 2017, mais le marché de la carte graphique oscille au dessus des 40 millions d'unités par an. 3 millions représenterait 13% environ de ces ventes totales ce qui n'est pas anecdotique quand l'on considère qu'en général les cartes milieu/haut de gamme représentent un part modeste des ventes.
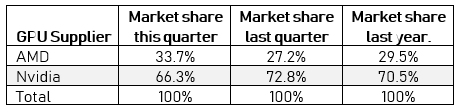
Sur ce dernier trimestre, les cartes dites haut de gamme ont vu leur part de marché monter de 11.5 à 16% par rapport au précédent. Tout ceci pousse vers le haut la part de marché d'AMD qui passe en un trimestre de 27.2 à 33.7%, Nvidia restant à une confortable part de marché de 66.3%. Pour AMD cette augmentation est assez significative, puisque le constructeur n'avait pas atteint une telle part depuis 2014 et l'époque des Radeon R9 2X0.
AMD n'avait pas pour rappel donné de détails sur les ventes de ses GPU sur l'année 2017, regroupant les ventes CPU et GPU dans une seule activité "Computing & Graphics" dans ses résultats financiers. Lisa Su estimait cependant qu'un tiers de la croissance sur l'année était due au minage.
Radeon Software 18.3.1 optimisé pour PUBG et DOTA 2
AMD a rendu disponible plus tôt dans la semaine une nouvelle version beta de ses pilotes graphiques, les Radeon Software 18.3.1. Le constructeur annonce un support optimisé pour Final Fantasy XV ainsi que pour Warhammer: Vermintide II.
Le constructeur annonce aussi des gains de performances sous DOTA 2, jusque 6% sur une Radeon RX580 en 4K. Ce changement fait partie d'une série d'améliorations et d'optimisations entreprises par la société pour certains jeux en ligne populaires du moment. La société dit avoir collaboré avec les développeurs pour améliorer les performances et réduire la latence (des gains de 2 à 4 ms sont évoqués sur Overwatch et Dota 2).
Des bugs ont également été corrigés pour Sea of Thieves (crash en cours de jeu), Middle Earth : Shadow of War (corruptions de textures en multi GPU) et World of Tanks (corruptions de couleurs en multi GPU).
Le téléchargement des pilotes s'effectue comme toujours sur le site du constructeur .