
Les contenus liés aux tags Intel et Process
Afficher sous forme de : Titre | Flux14 nm pour tous chez Intel en 2014
Tri-Gate/FinFET : TSMC et Global Foundries
Focus: Le 22nm dIntel sera Tri-Gate !
MLC 20nm chez Intel / Micron
14nm en 300mm pour Intel
TSMC et InFo PoP pour l'A10 de l'iPhone 7



Ce week end, la société Chipworks a procédé à son traditionnel "teardown" des puces incluses dans l'iPhone 7 , en se concentrant particulièrement sur le SoC A10 d'Apple.
Rappel sur l'A9
Avant de regarder l'A10, revenons un instant sur l'A9 inclus l'année dernière dans l'iPhone 6S. Il avait la particularité d'être sourcé en parallèle chez Samsung et TSMC, quelque chose de quasi unique pour des puces haut de gamme sur des process de dernière génération, ce qui nous avait permis d'effectuer quelques comparaisons.
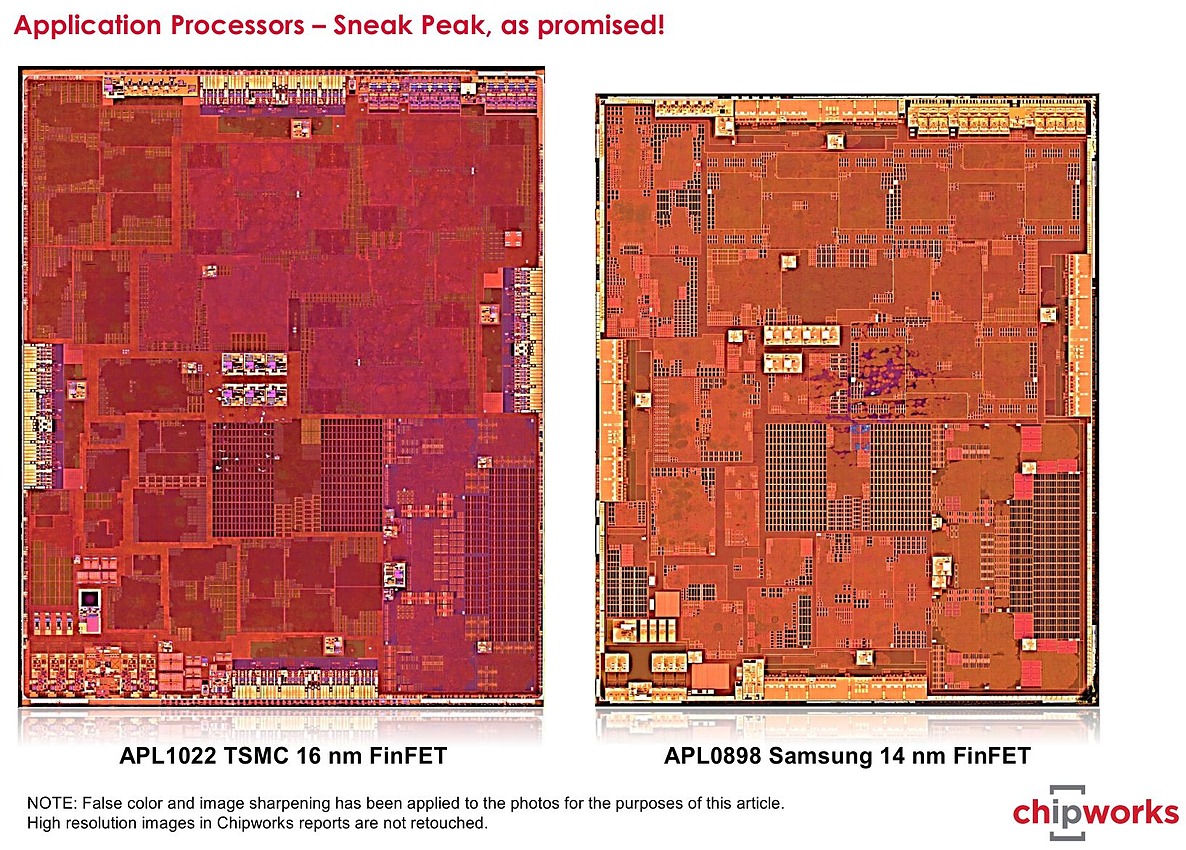
Les deux A9 de l'iPhone 6S (2015)
La différence la plus visible était la densité des deux process : l'A9 "Samsung" mesurant 96mm2, contre 104.5mm2 pour la version TSMC. A l'époque nous n'avions pas de certitudes sur les variantes exactes des process utilisées. Depuis, Chipworks a confirmé qu'il s'agissait bien du 14LPE chez Samsung. Le cas de TSMC est plus compliqué, Chipworks ne répondant pas (gratuitement) à la question. Les rumeurs laissent penser qu'il ne s'agissait pas d'un simple 16FF, mais d'une version "custom" empruntant en partie au process 16FF+.
Outre la densité, les tests pratiques avaient suggéré une différence de consommation à pleine charge avec un avantage pour la puce de TSMC. De quoi laisser penser que son process avait besoin de tensions inférieures à celui de Samsung pour obtenir les mêmes performances.
Depuis, Chipworks a la aussi répondu partiellement à la question suggérant que le problème se situerait pour le process de Samsung sur le rapport puissance/performances de ses NMOS . On ne sait pas si le problème persiste sur la version 14LPP qui a remplacé le 14LPE.
L'A10 : 16FFC TSMC
Première différence par rapport à l'année dernière, l'A10 semble produit cette année exclusivement par TSMC. Il est plus large que l'A9, mesurant 125mm2 pour 3.3 milliards de transistors annoncés. Côté process il s'agit du 16FFC (ou d'une variante) de TSMC, la troisième version "optimisée" du 16nm de TSMC. Annoncée en janvier dernier, le C signifie "Compact" et ce process vise avant tout les usages basses consommation tout en réduisant de manière significative les coûts de fabrication.

D'après Chipworks, l'utilisation des bibliothèques optimisées permet une bien meilleure utilisation du die, avec une compacité équivalente à celle des process TSMC précédents. Chipworks estime que la même puce aurait demandé 150mm2 en 16FF. Etant donné que 70 tapeouts de clients de TSMC sont attendus sur ce process cette année, les progrès de densité du 16FFC devraient profiter assez largement, on attendra de voir les constructeurs qui annonceront des puces l'utilisant.


Chipworks note également que l'A10 est beaucoup moins haut que les générations précédentes. Comme beaucoup de SoC, il est de type PoP et embarque la mémoire au dessus du die logique. Cependant plutôt que d'empiler les quatre dies de mémoire (2 Go de LPDDR4 Samsung sur l'A10 de l'iPhone 7), ils sont placés côte à côte.
Qui plus est, comme nous le supposions la puce utilise le nouveau packaging InFo de TSMC (dans sa version InFo-PoP) pour relier les dies entre eux.
big.LITTLE et performances
Côté performances les premiers benchmarks synthétiques évoquent 40% de gains pour le CPU ARM par rapport à l'année dernière, tout en restant en 16nm.
Pour arriver à ce gain, Apple augmente d'abord significativement la fréquence, passant de 1.85 GHz sur l'A9 à 2.35 GHz sur l'A10. Sur ce point, la marque exploite à la fois la marge notée de son process l'année dernière (on peut supposer facilement que l'A9 aurait eu une fréquence plus élevée s'il avait été sourcé uniquement chez TSMC) et les gains apportés par le 16FFC.

Ce gain de 27% de fréquence est accompagné de changements au niveau de l'architecture. Ceux ci ne sont pas encore connus, au delà du nom Hurricane, mais Chipworks note que le cluster CPU prend une place plus importante sur le die, 16mm2 face à 13mm2 sur l'A9, malgré l'utilisation d'un process plus compact.
Il est cependant difficile de se baser sur cette différence de taille étant donné que l'A10 est en réalité un quad core big.LITTLE dans la nomenclature ARM. En plus des deux coeurs hautes performances à 2.35 GHz (big), deux coeurs basse consommation à 1.05 GHz (LITTLE) sont également présents sur le die (leur emplacement exact est pour l'instant inconnu, ce qui vaut les points d'interrogation sur le diagramme au dessus).
Contrairement à d'autres implémentations dans l'écosystème ARM, les applications ne peuvent pas utiliser en simultanée les deux blocs de coeurs, le passage de l'un à l'autre étant transparent pour elles (géré par la puce et l'OS). L'intérêt de cet arrangement est bien entendu d'augmenter l'autonomie en ne sollicitant les coeurs haute performances que lorsque nécessaire.
Déjà largement en avance côté performances sur le reste de l'écosystème ARM, l'A10 commence à devenir embarrassant même pour Intel, dépassant un Core M Skylake en monothread sous Geekbench 4 (voir ici et là ), avec un "TDP" au moins deux fois inférieur (et sans mécanisme Turbo).
Intel se consolera tout de même de sa présence dans une partie des iPhone 7 car c'est l'autre information de Chipworks, la société confirme qu'une partie des modèles utilise un modem Intel XMM 7360 (certains modèles intègrent un modem Qualcomm X12). Très en retard, le XMM 7360 est un modem LTE 450 Mb/s Cat 10 certes dessiné par Intel, mais fabriqué selon toutes vraisemblances comme ses prédécesseurs... par TSMC.
Intel Custom Foundry prend une licence ARM !
 ARM l'a confirmé par un post de blog : Intel Custom Foundry, l'activité fabrication tiers d'Intel, est désormais détentrice d'une licence ARM Artisan pour le 10nm !
ARM l'a confirmé par un post de blog : Intel Custom Foundry, l'activité fabrication tiers d'Intel, est désormais détentrice d'une licence ARM Artisan pour le 10nm !
Il faut rappeler qu'Intel est plutôt un cas à part dans le monde des semi-conducteurs, étant l'une des rares sociétés à disposer de ses propres usines, utilisées quasi uniquement pour la production de ses propres puces. La plupart des autres acteurs du marché ont migré vers la séparation de l'activité design d'un côté (on parle de sociétés fabless, c'est le cas dans le monde du GPU avec AMD et Nvidia), et de l'autre la fabrication dans des sociétés tierces spécialisées (on parle de foundry, la plus connue étant TSMC qui fabrique des puces pour de multiples clients).
Avec la difficulté de la mise au point des nouveaux process de fabrication, qui n'a fait qu'empirer ces dernières années, il est de plus en plus complexe pour une société à elle seule de justifier l'investissement nécessaire pour faire évoluer sans cesse ses usines. Qui plus est, la réduction de la taille des transistors fait que la capacité des usines augmente d'année en année, et qu'il faut disposer de très larges volumes de puces à produire, au risque de voir ses usines tourner à vide.
Un casse tête qui aura poussé plusieurs sociétés à se séparer de leurs usines (pour des raisons différentes) d'abord AMD en 2009 (créant GlobalFoundries) et plus récemment IBM (dont l'activité fabrication à été rachetée elle aussi par GlobalFoundries).
Depuis quelques années, en plus de fabriquer ses propres puces dans ses usines, Intel a décidé d'entrer très timidement, en 2010, sur le marché des fondeurs tiers en ouvrant son process à de petites sociétés qui n'étaient pas en concurrence directe avec ses produits (le premier client était Achronix, designer de FPGA en 22nm). D'autres clients ont suivi, principalement sur les FPGA, le client le plus connu d'Intel ayant été Altera... même si au final Intel aura décidé de racheter son client à la mi-2015 !
Pour Intel, la nécessité d'ouvrir ses usines est un casse tête. D'un côté, la société tente d'être présent sur tout les marchés, en déclinant le x86 - technologie "maison" sur laquelle la concurrence est limitée - à toutes les sauces et avec un soupçon de recyclage, que ce soit avec des produits serveurs spécialisés comme les Xeon Phi basés sur des Pentium pour leur première génération, ou les Quark dédiés à l'embarqué et utilisant une architecture de 486 datant d'une bonne vingtaine d'années !
Si l'envie de la société d'être présente sur tous les marchés est là, en pratique les succès ne sont pas systématiquement au rendez vous, Intel ayant par exemple massivement raté le marché des smartphones. Cumulé à la baisse continue des ventes sur le marché historique des PC, l'ouverture des usines à des clients tiers se dessine de plus en plus comme une nécessité pour Intel, même si l'avouer semble impossible à la société, qui continuait donc d'envoyer des signaux mitigés aux possibles futurs clients de son activité fabrication.
Avec l'annonce d'aujourd'hui, les choses sont - peut être - en train de changer puisque la prise de licence ARM par Intel est tout sauf anodine. Ce n'est pas la première fois qu'Intel fabriquera des SoC ARM, on l'avait vu avec Altera qui utilisait un core ARM dans un usage très spécifique.
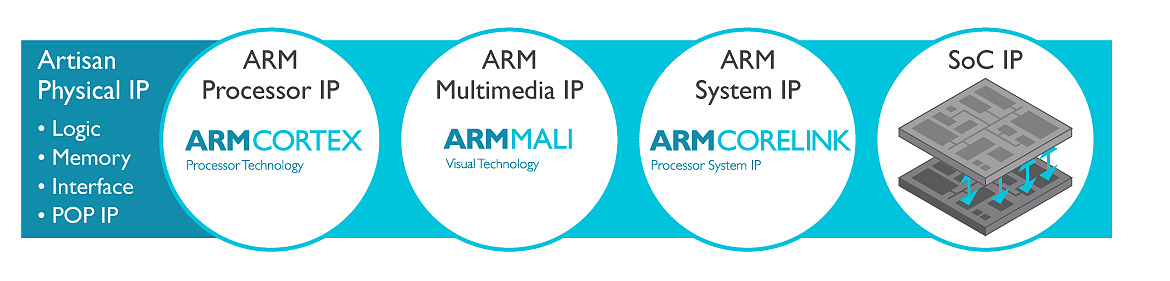
La licence Artisan Physical IP inclut en effet toutes les briques nécessaires pour la création de puces ARM de tout types. Il s'agit de tous les blocs de base avec des bibliothèques haute densité et haute performance de transistors logiques,et également tout le nécessaire pour les différents types de mémoire. La licence inclut surtout POP IP, qui est pour rappel l'idée qui fait le succès d'ARM : permettre l'utilisation de blocs interchangeables et compatibles pour créer des puces custom. Ainsi un client peut choisir d'utiliser des coeurs CPU dessinés par ARM (les gammes Cortex) ou créer ses propres coeurs (c'est le cas d'Apple et plus récemment de Nvidia), de choisir un GPU (que ce soit les Mali d'ARM, ou les populaires PowerVR d'Imagination Technologies), et également de choisir son fournisseur pour les interconnexions.
Concrètement, Intel va donc "porter" ces bibliothèques d'ARM aux particularités de son futur process 10 nm, ce qui permettra aux partenaires d'ARM de porter à leur tour - s'ils le souhaitent - leurs blocs POP IP. ARM et Intel travailleront conjointement pour le portage de deux futurs blocs CPU ARM Cortex-A (probablement un autre successeur 10nm de l'A72, voir l'annonce de l'A73 en 10nm lui aussi), la déclinaison que l'on retrouve dans les smartphones et tablettes.
Faut il y voir un virage pour Intel ? Fabriquer des puces ARM pour smartphones, ce qu'ils feront pour LG (nouveau client annoncé dans la foulée) va forcément à l'encontre des ambitions internes d'Intel d'imposer le x86 sur mobile. Car si un peu plus tôt dans l'année Intel avait décidé d'annuler sa nouvelle génération de SoC pour smartphones (Broxton et SoFIA), le constructeur continuait en interne à travailler sur les générations suivantes tout en essayant de développer dans l'intérim son activité modem (Intel aurait possiblement gagné le marché du modem du prochain iPhone). A l'heure où ARM augmente ses ambitions pour aller attaquer le marché juteux des serveurs, on peut se demander jusqu'où ira réellement l'ouverture d'Intel.

Un futur CPU ARMv8 24 coeurs de Qualcomm
En fabriquant des puces concurrentes, Intel s'ouvre à des comparaisons directes qui pourraient être assez défavorables à ses architectures x86, assez peu adaptées à la basse consommation. L'avantage supposé du process d'Intel, s'il existe, ne pourra plus jouer en la faveur de ses propres solutions pour compenser un éventuel déficit architectural. La structure de marges d'Intel, là aussi très différente de celle des fondeurs tiers, posera là aussi rapidement problème.
Qui plus est, en obtenant la licence Artisan d'ARM, Intel va devoir partager tous les détails techniques, y compris les plus secrets, de son process en ce qui concerne les règles et les dimensions exactes des transistors, ce qui va l'exposer là aussi à une comparaison directe avec les autres acteurs installés du milieu (comme TSMC et Samsung). Il faudra un peu de temps pour mesurer les conséquences concrètes de tout cela, car cet accord ne concerne que le 10nm, un process pour rappel en retard et qui n'est prévu chez Intel que pour la fin de l'année 2017 en version mobile. Les dernières nouvelles du 10nm, sur lequel Intel ne communique pas, n'étaient pour rappel pas particulièrement rassurantes avec l'arrivée possible sur sa roadmap de puces 14nm... pour 2018.
L'ITRS prépare l'après loi de Moore
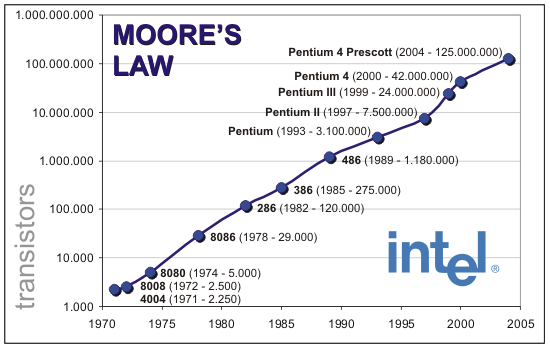
C'est la section actualité de la très sérieuse revue scientifique Nature qui l'affirme : la loi de Moore est arrivée à son terme. Énoncée en 1965 par Gordon Moore, l'un des cofondateurs d'Intel, il s'agit d'une observation par laquelle la quantité de transistors dans les circuits intégrés doublait à peu près tous les ans. Une observation transformée en loi pour prédire que cette cadence pouvait être extrapolée pour les années à venir.
En 1975, la loi avait été révisée pour prendre la forme que l'on connaît actuellement, à savoir un doublement des transistors tous les deux ans. L'importance de la loi de Moore allait cependant au-delà de la simple prédiction puisqu'elle prenait en compte les coûts de fabrication : l'observation se fait sur les puces ayant le coût par transistor le plus faible (tentant donc de prendre en compte les questions de yields et de défauts en fonction de la taille des puces).
Plus qu'une prédiction, la loi de Moore a servie, particulièrement chez Intel, de guide au fil des années, prédisant à l'avance les budgets en nombre de transistors alloués aux ingénieurs, et poussant vers l'avant la nécessité d'investir dans de nouveaux process de fabrications, la fameuse stratégie du Tick-Tock poussée d'abord en interne par Pat Gelsinger au début des années 2000 avant d'être utilisée publiquement pour décrire les générations à venir.
De manière intéressante, au-delà d'Intel, c'est toute l'industrie du semi-conducteur qui s'est mise d'accord autour de la loi de Moore, à savoir non seulement les fondeurs, mais aussi et surtout les fournisseurs d'outils. Le besoin de coordination entre tous les acteurs aura conduit à l'élaboration d'une roadmap, d'abord appelée National Technology Roadmap for Semiconductors dès 1993, avant d'être renommée sous sa forme actuelle, l'International Technology Roadmap for Semiconductors (ITRS).
Le rôle joué par cette roadmap, dont la dernière version a été publiée en 2013 aura été particulièrement important ces dernières années où, passé le 90nm, les challenges techniques ont contraint à des changements d'approches importants. L'augmentation des performances par la fréquence, méthode classique aura atteint un plateau à cause de l'augmentation de la consommation, poussant dans le commerce les stratégies de multiplication des coeurs que l'on connaît. Le rôle de la roadmap, au-delà de la concertation, est de s'assurer de trouver des pistes pour continuer la cadence de réduction des coûts/augmentation des transistors de la loi de Moore.
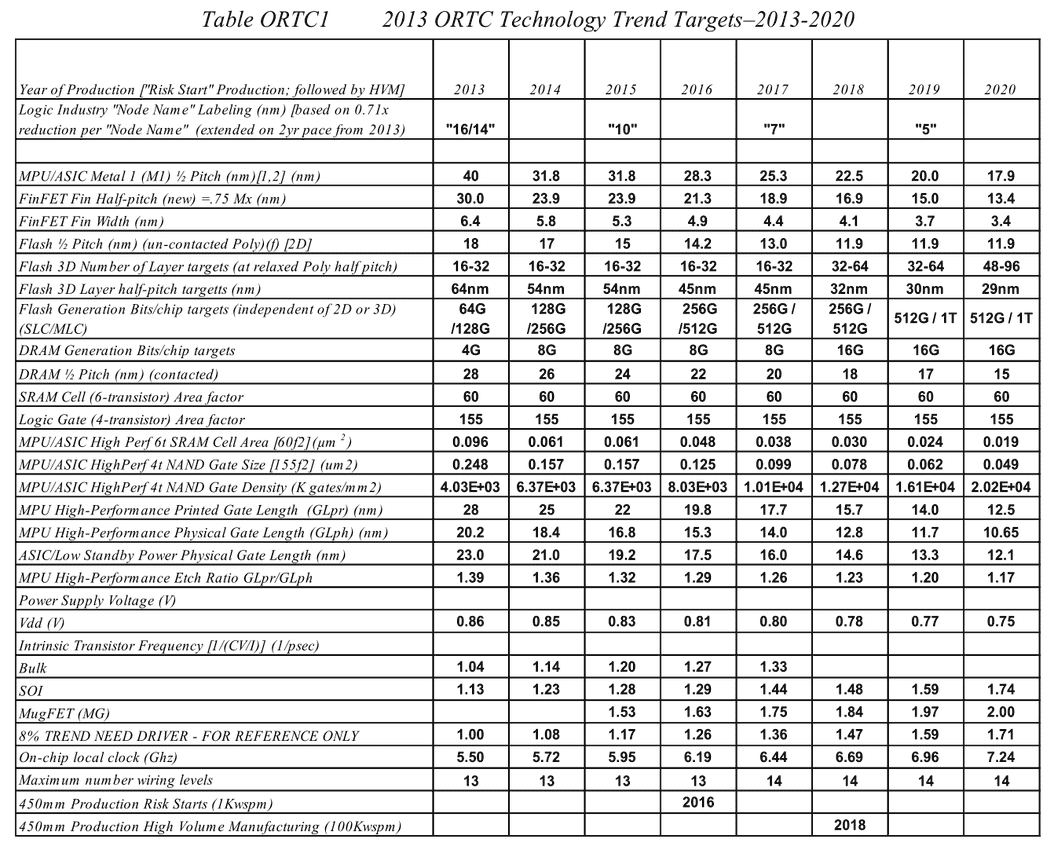
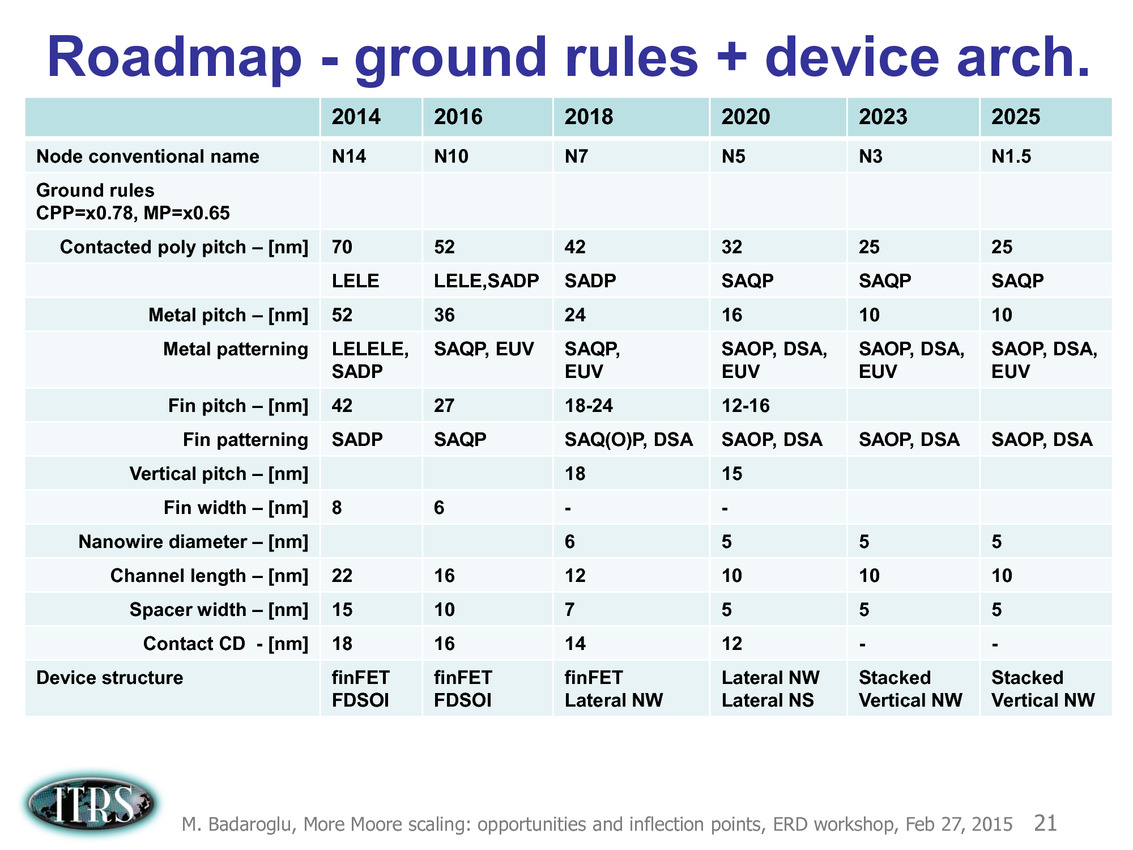
La dernière roadmap ci-dessus donnait des grandes lignes sur la manière de mettre à l'échelle les différents composants des transistors. Après les difficultés autour du 90nm, l'industrie est passé progressivement de la règle dite de la mise à l'échelle géométrique (on réduit tout dans des proportions identiques, le nom du node indiquant en général la taille de la porte) à celle de la mise à échelle par équivalence (equivalent scaling).
Etant donné que différentes parties composant les puces posent des problèmes différents, des règles d'équivalences ont été mises au point pour permettre de continuer a atteindre les buts de réduction des coûts/augmentation de densité imposé par la loi de Moore (on peut voir sur le tableau la couche d'interconnexion M1 et l'écart minimal entre deux transistors FinFET, en passant par des estimations des tailles de blocs fondamentaux comme la SRAM).
Pour 2016, la roadmap annonçait par exemple de la SRAM 6 transistors (6T) haute performance en 10nm autour de 0.048 µm2, ce qui n'est pas très éloigné de ce que présentait Samsung il y a une dizaine de jours de cela. En pratique cependant, on notera qu'on est globalement assez en retard sur la roadmap qui prévoyait des débuts de production à petite échelle en 10nm en 2015 (Risk Start dans la roadmap, suivi de HVM, fabrication en volume). Chez TSMC par exemple, la production risque est prévue pour la fin 2016 avec une production en volume pour 2017. Intel prévoit ses puces en volume pour 2017 également.
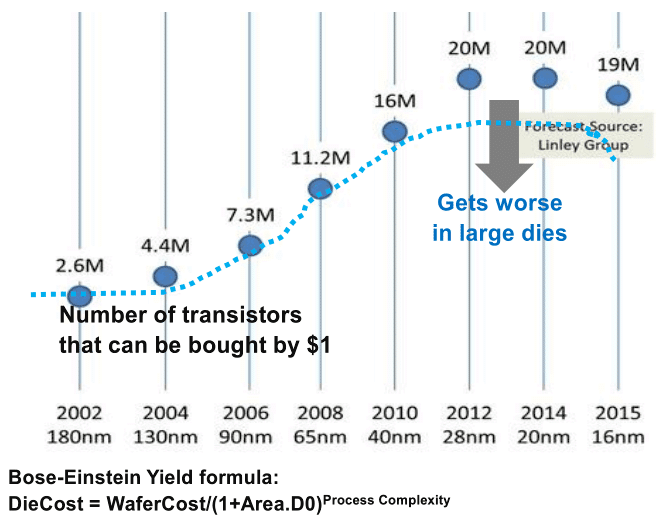
Évidemment depuis 2013 les choses se sont un peu plus compliquées et l'absence de roadmap en provenance de l'ITRS n'a pas forcément aidé. En pratique, la réduction des coûts s'est arrêtée, avec même un retour en arrière à 16nm signant de facto la fin de la loi de Moore, comme on peut le voir sur cette estimation ci-dessus tirée d'une présentation de l'ITRS en février 2015.
L'absence de nouvelle roadmap en provenance de l'ITRS aura même donné lieu à des divergences d'interprétations fortes, Intel titillant ses concurrents sur la question de la densité théorique. TSMC et Samsung ont fait pour rappel le choix de conserver un BEOL (Back End of Line, la partie basse d'une puce qui sert à l'interconnexion des transistors) commun entre le 20 et le 16nm pour accélérer la cadence de mise en production. En pratique chez TSMC, malgré le BEOL commun, le half pitch M1 reste tout de même dans les clous à 32nm (entre 40 et 31.8 sur la roadmap).
La densité pratique reste de toute manière très différente de ce que peuvent proposer des formules grossières comme celle utilisée par Intel (qui multipliait le pitch M1 par le pitch entre deux portes), qui pour exploiter les FinFET aura fait le choix d'utiliser pour certains de ses transistors critiques des structures plus larges composées de plusieurs fins (dans des proportions non négligeables même si la proportion exacte est rarement évoquée de manière précise par Intel).
Cumulé a de multiples autres détails (différents types de blocs sont présents avec des densités différentes, de la SRAM aux blocs plus ou moins critiques) il est impossible de tirer grand-chose de la théorie. L'écart entre un Core M Broadwell 14nm fabriqué par Intel (82mm2 pour 1.3 milliards de transistors) et un A8 fabriqué par TSMC en 20nm (89 mm2 pour 2 milliards de transistors) montre qu'il est difficile de comparer quoique ce soit à moins de prendre deux puces strictement identiques. Cela aura été possible pour l'A9 d'Apple, dont la superficie atteint 96mm2 chez Samsung contre 104.5mm2 chez TSMC.

Le mois prochain, l'ITRS devrait donc enfin communiquer une nouvelle roadmap qui d'après Nature tirera définitivement un trait sur la question de la loi de Moore comme moteur d'évolution unique. D'après Nature, la prochaine roadmap se concentrera sur les applications pratiques, allant du smartphones aux puces serveurs et regardera les applications pratiques, que ce soit au niveau circuits d'alimentations, des capteurs nécessaires, ou d'autres blocs de siliciums répondant à des besoins particuliers.
La véritable question est de savoir ce que comportera réellement cette roadmap qui serait rebaptisée d'après Nature International Roadmap for Devices and Systems, abandonnant même le mot transistor !
Ce que l'on sait, c'est que la réorganisation de l'ITRS en 2014 s'est faite autour de groupes de travaux, avec notamment un groupe baptisé « More Moore » pour évoquer les pistes techniques pour les prochains nodes, dont vous pouvez retrouver ci-dessous la dernière présentation datant de février 2015.



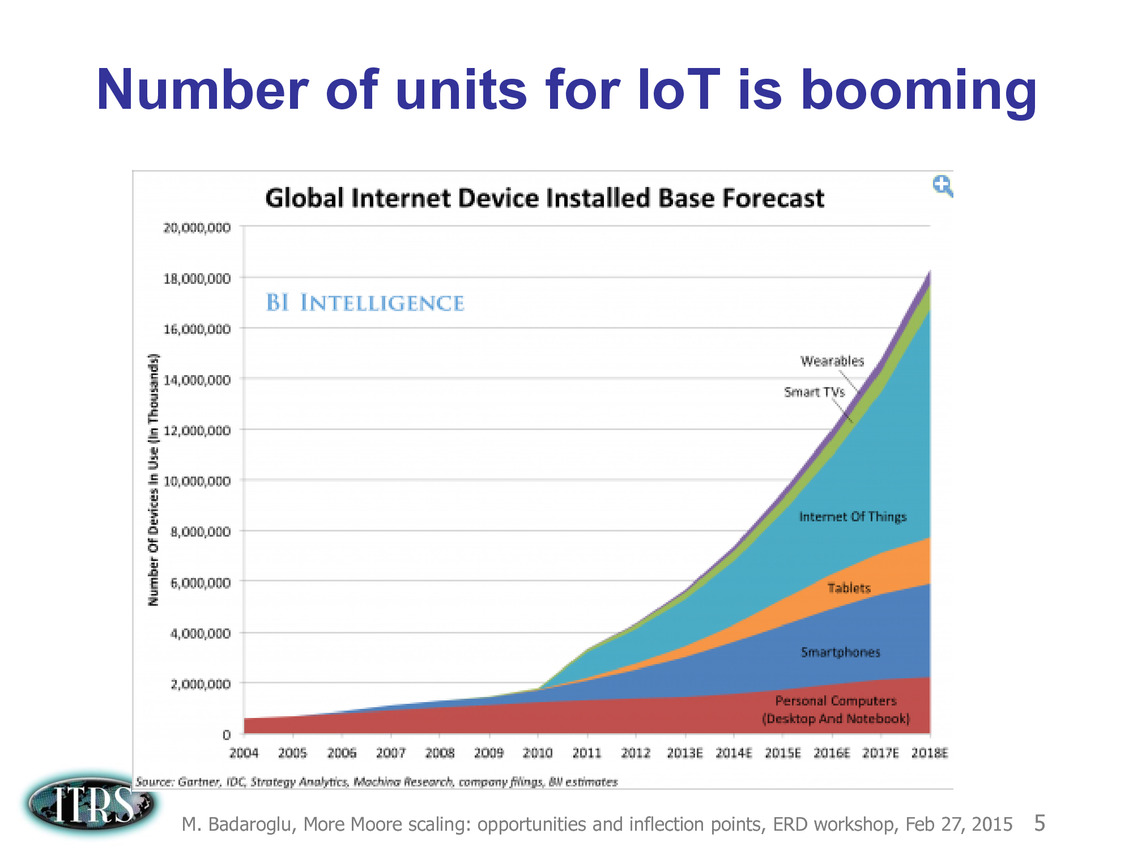

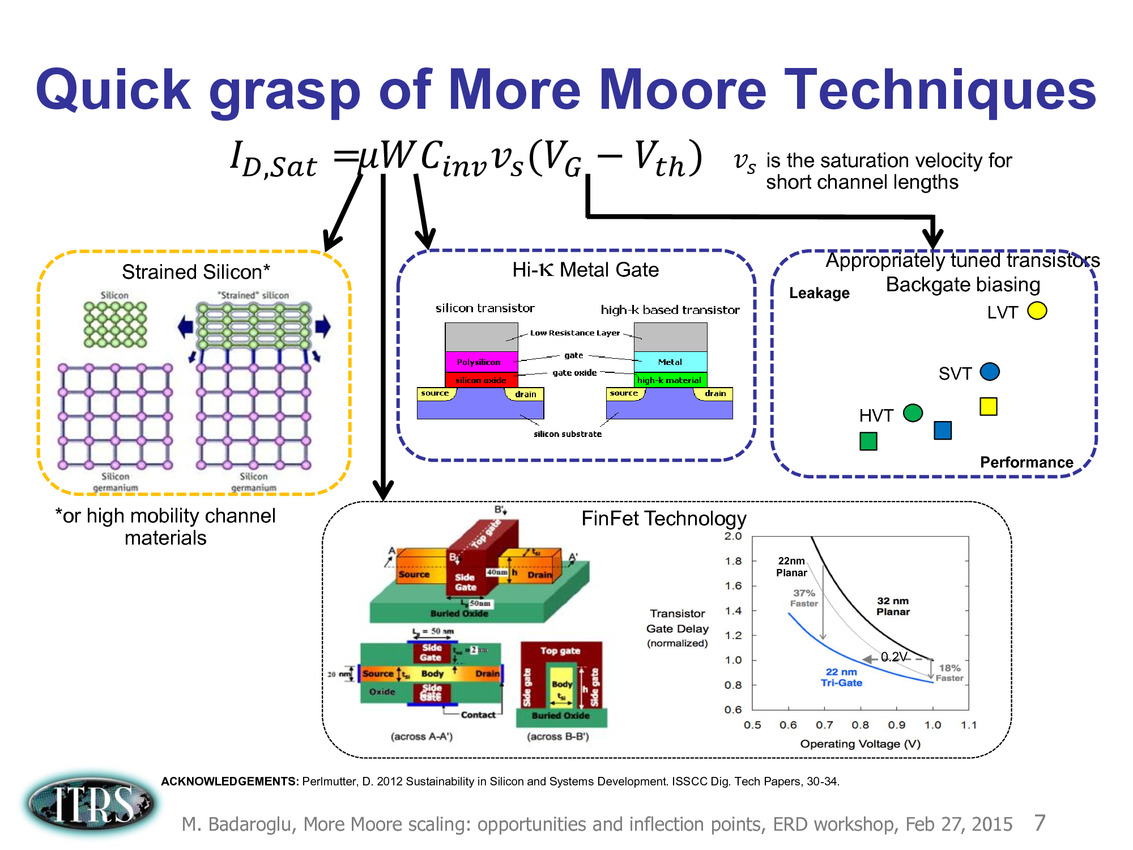
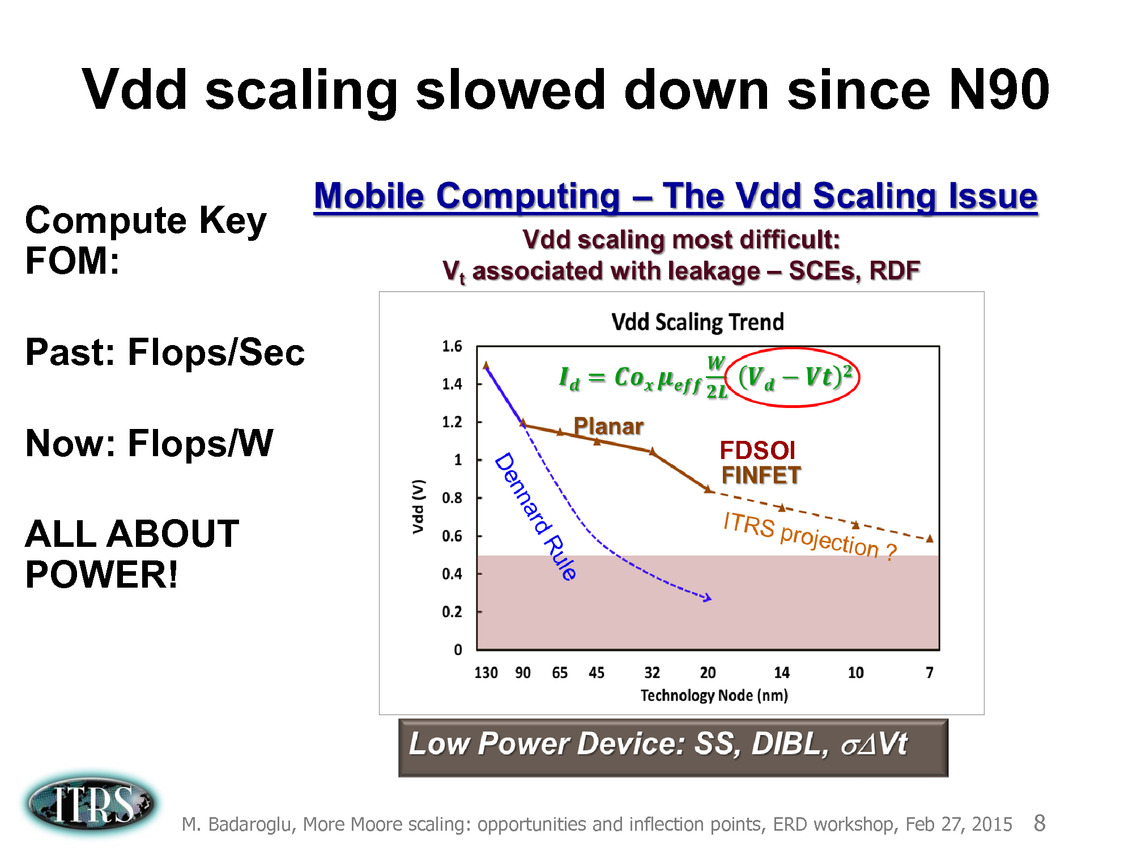
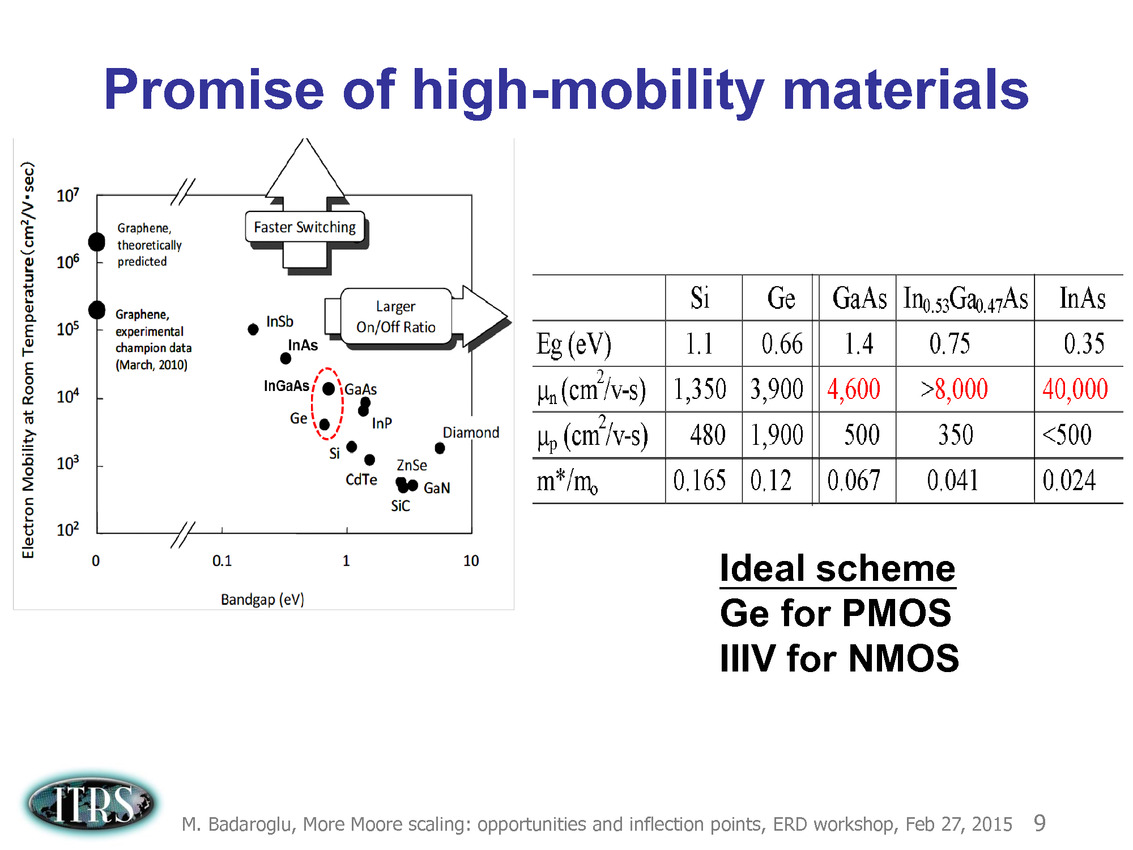
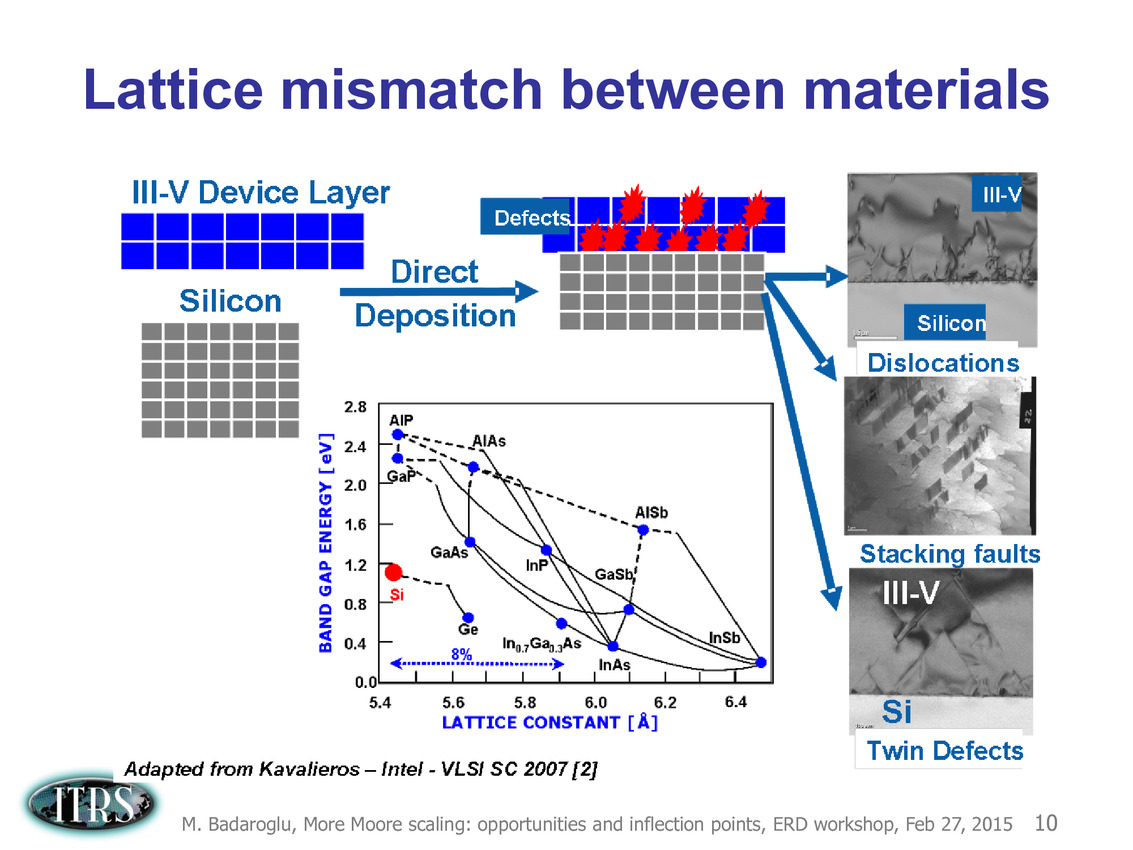
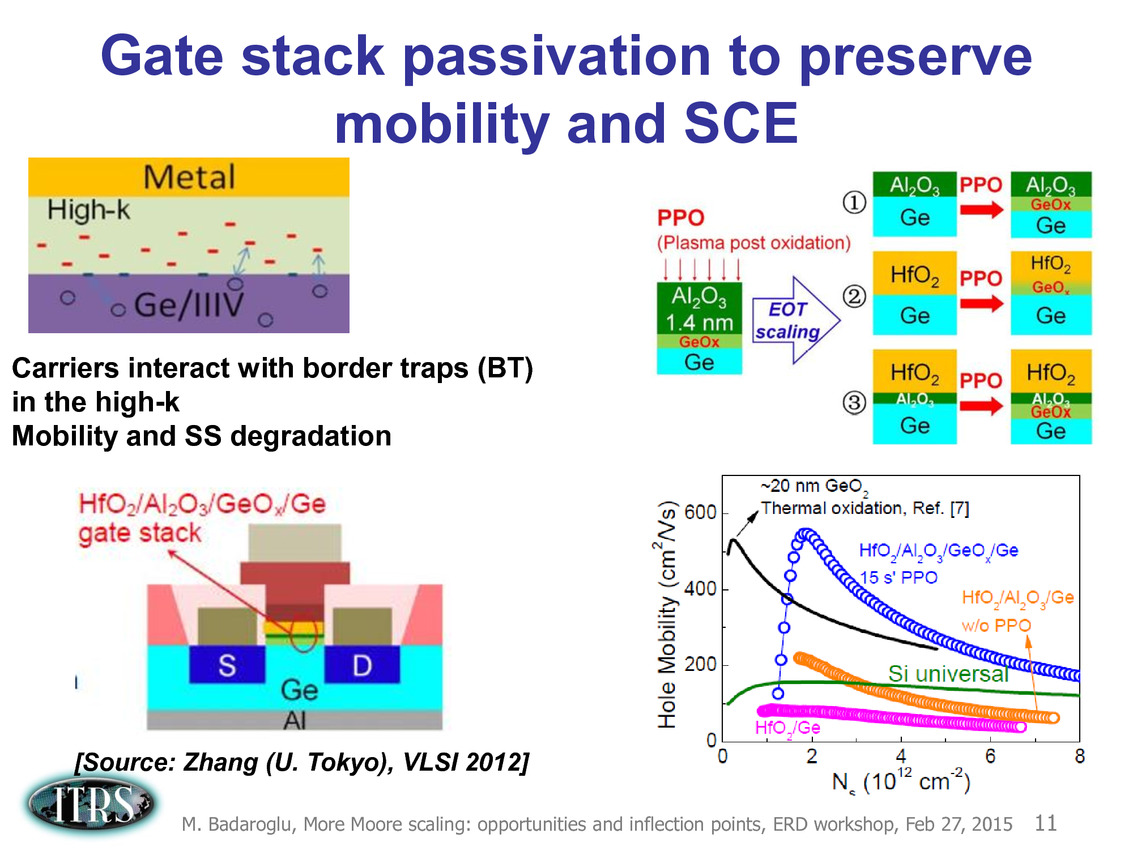
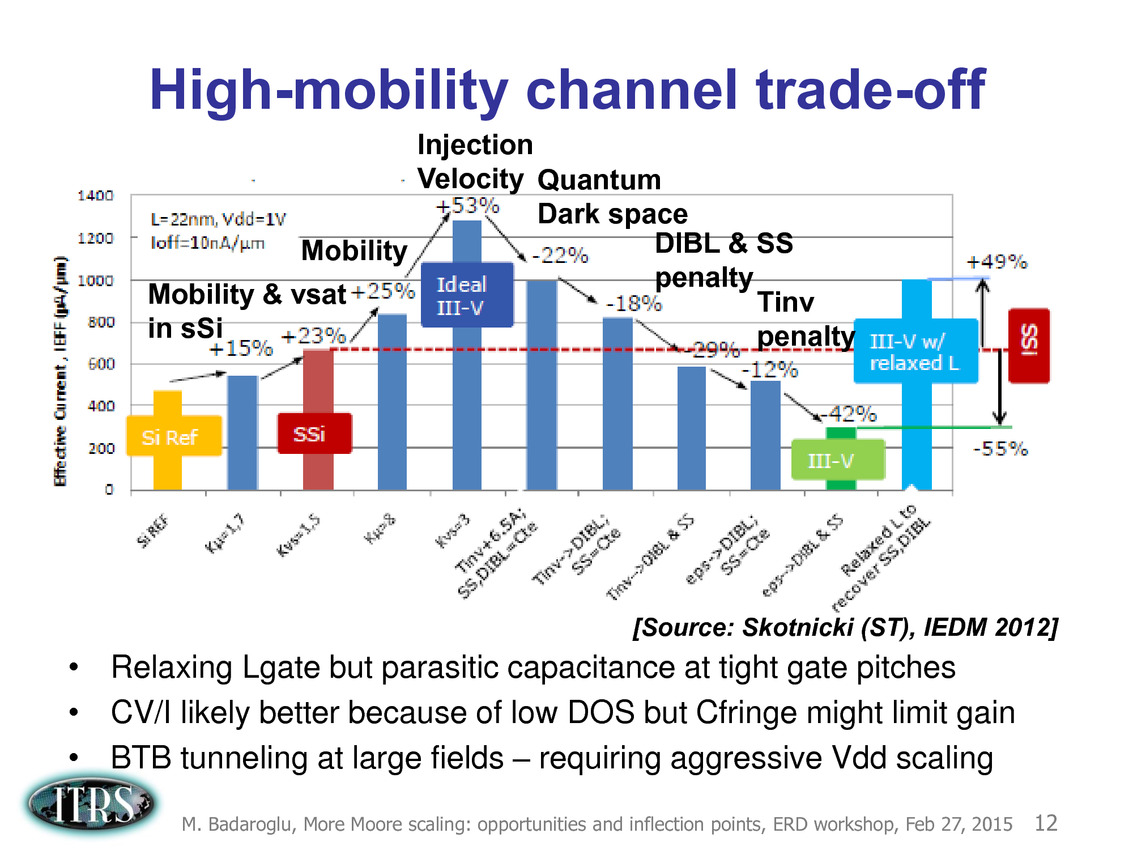
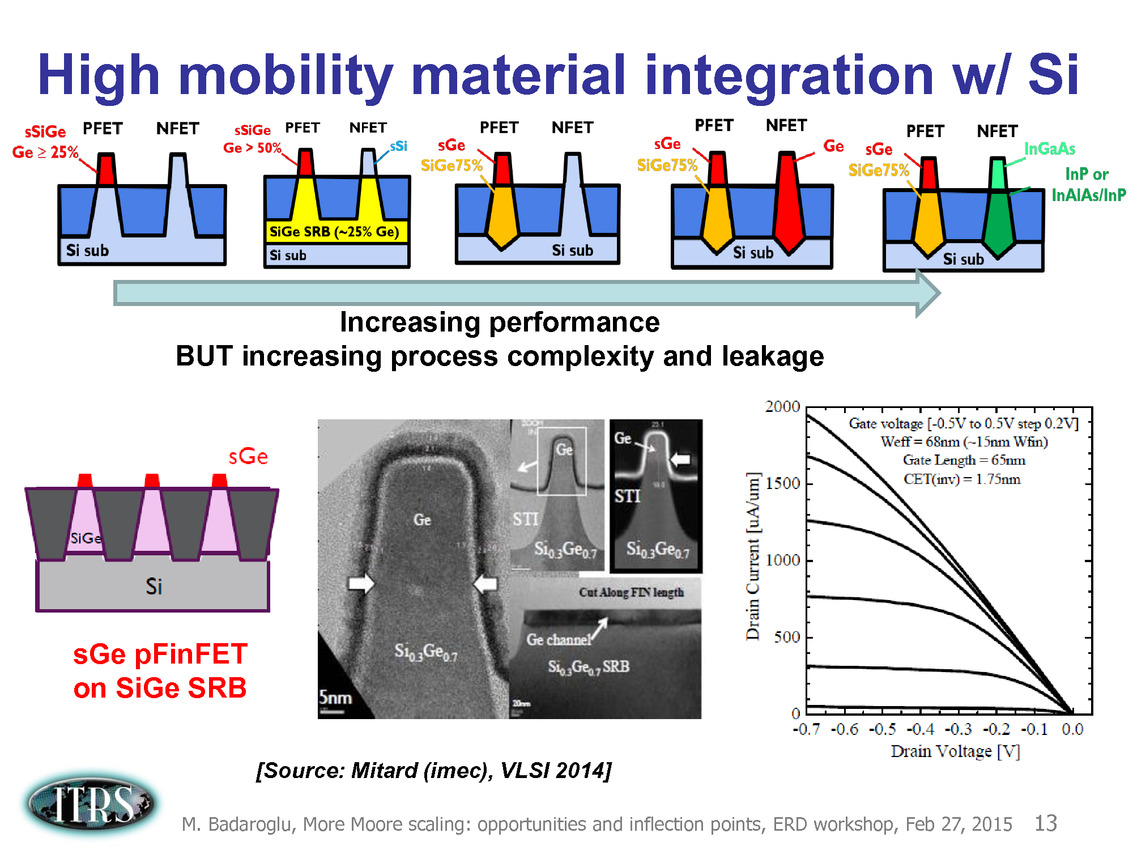

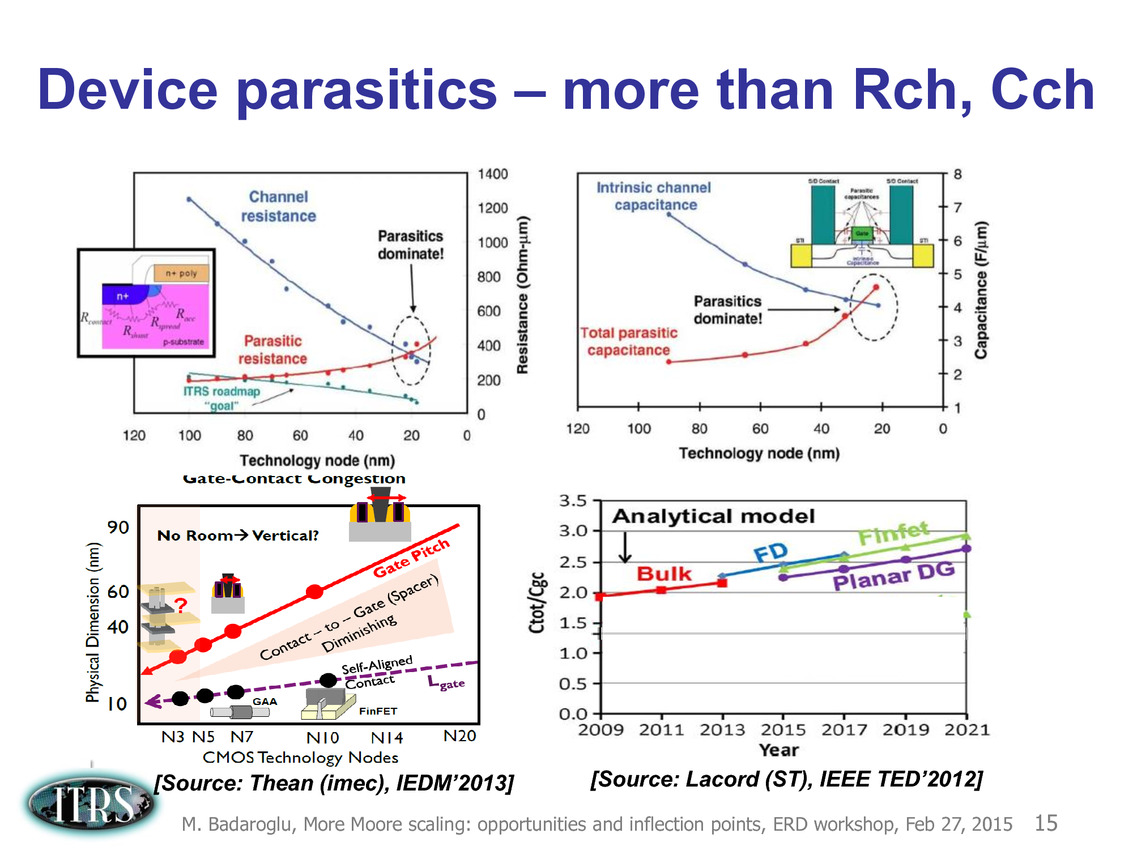
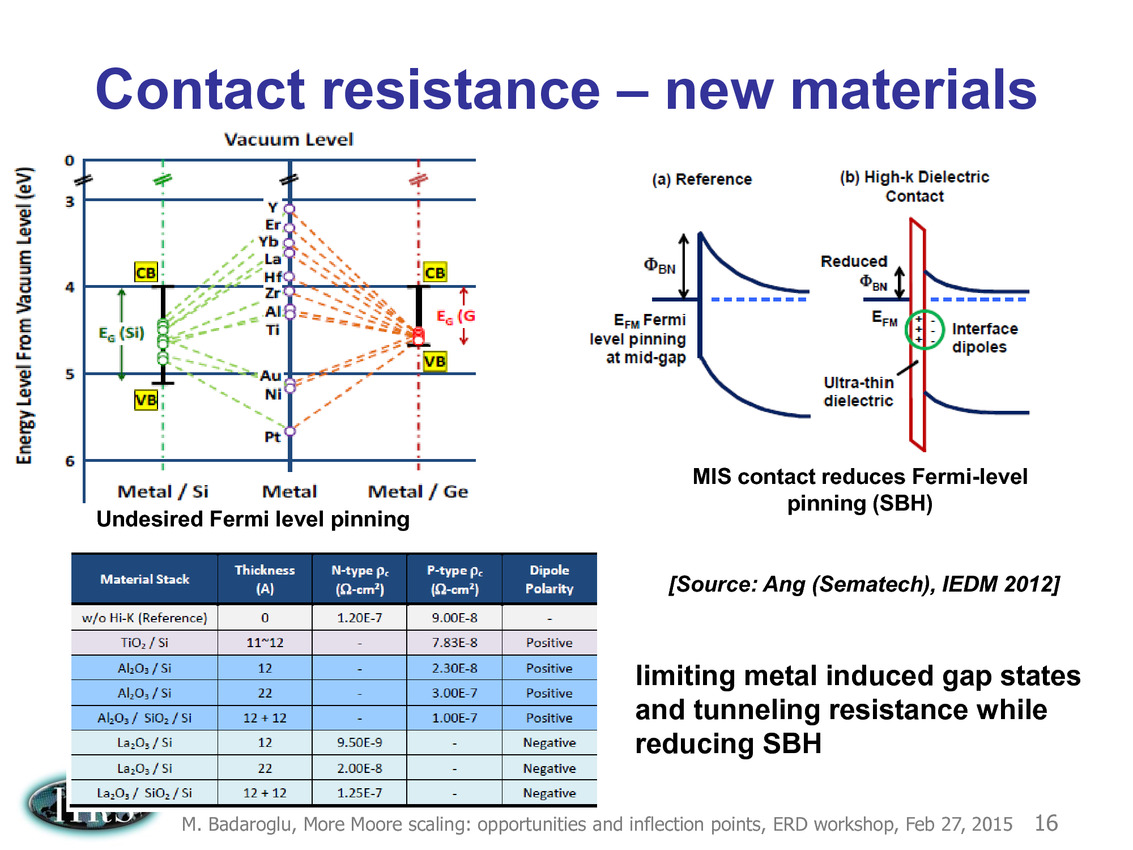
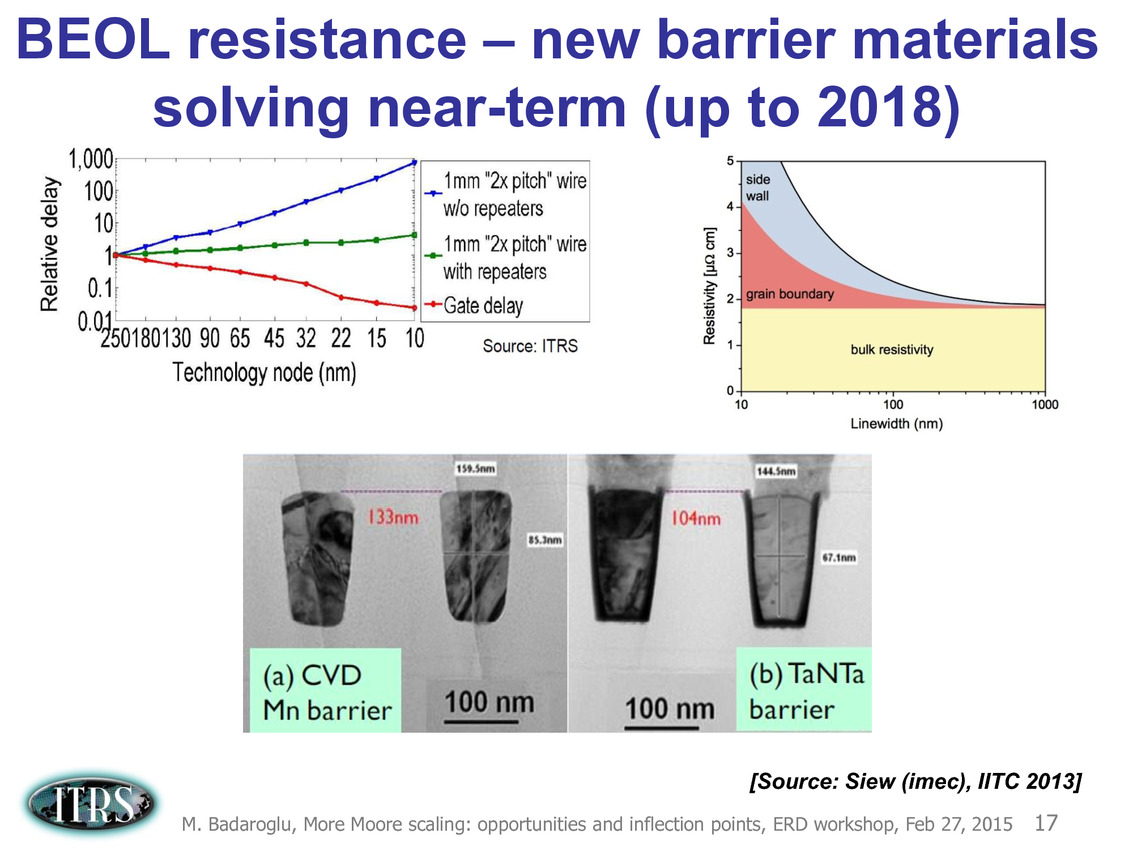
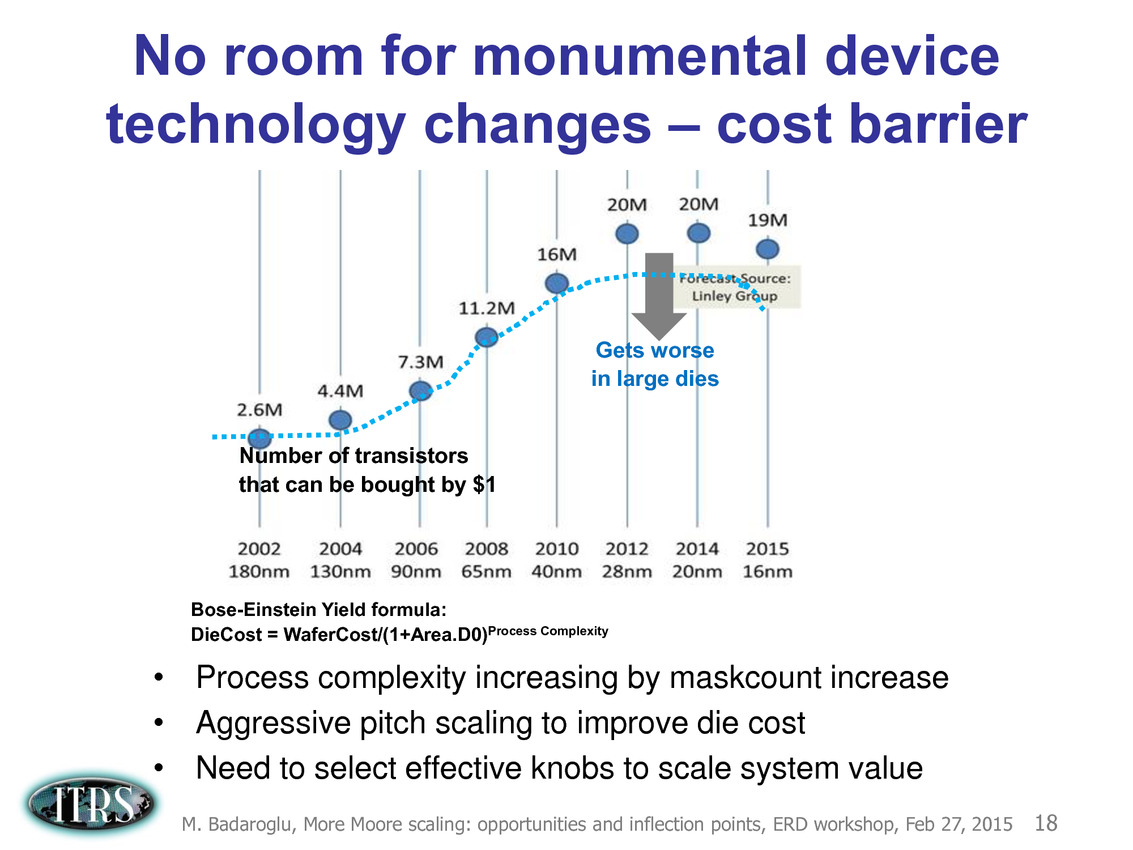
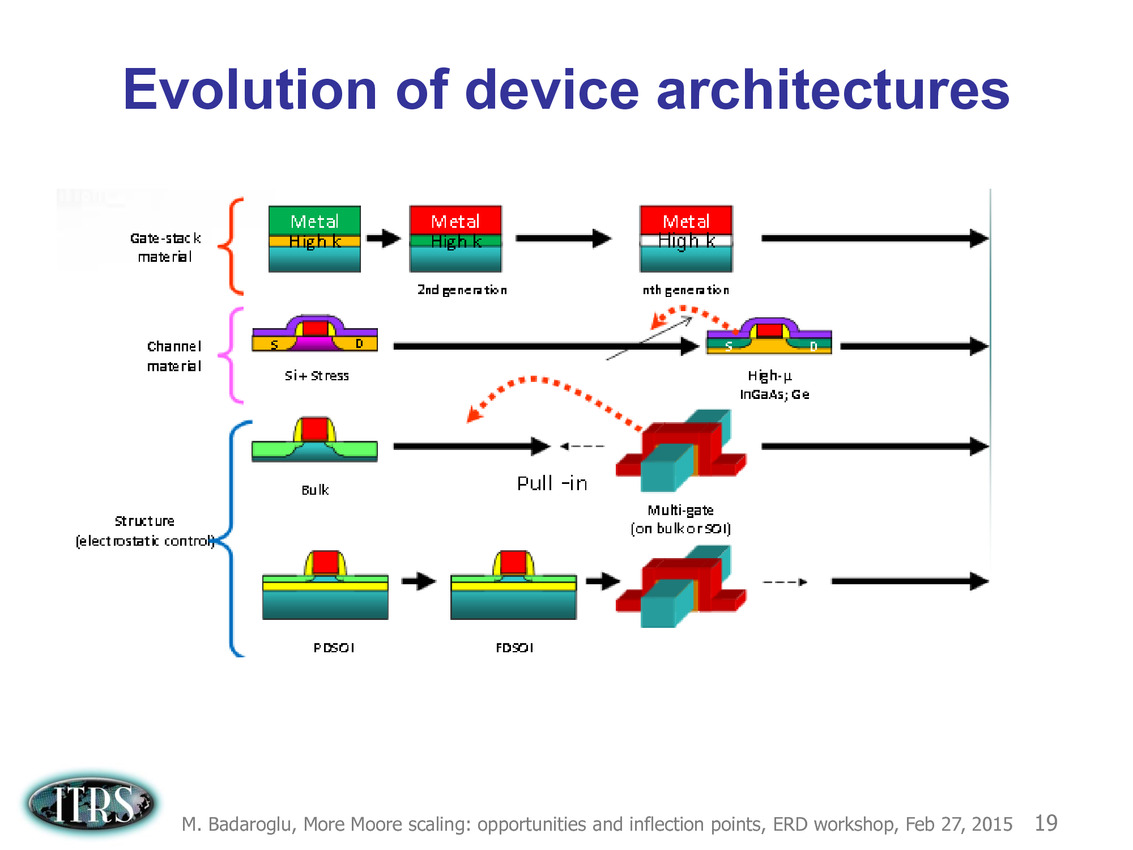
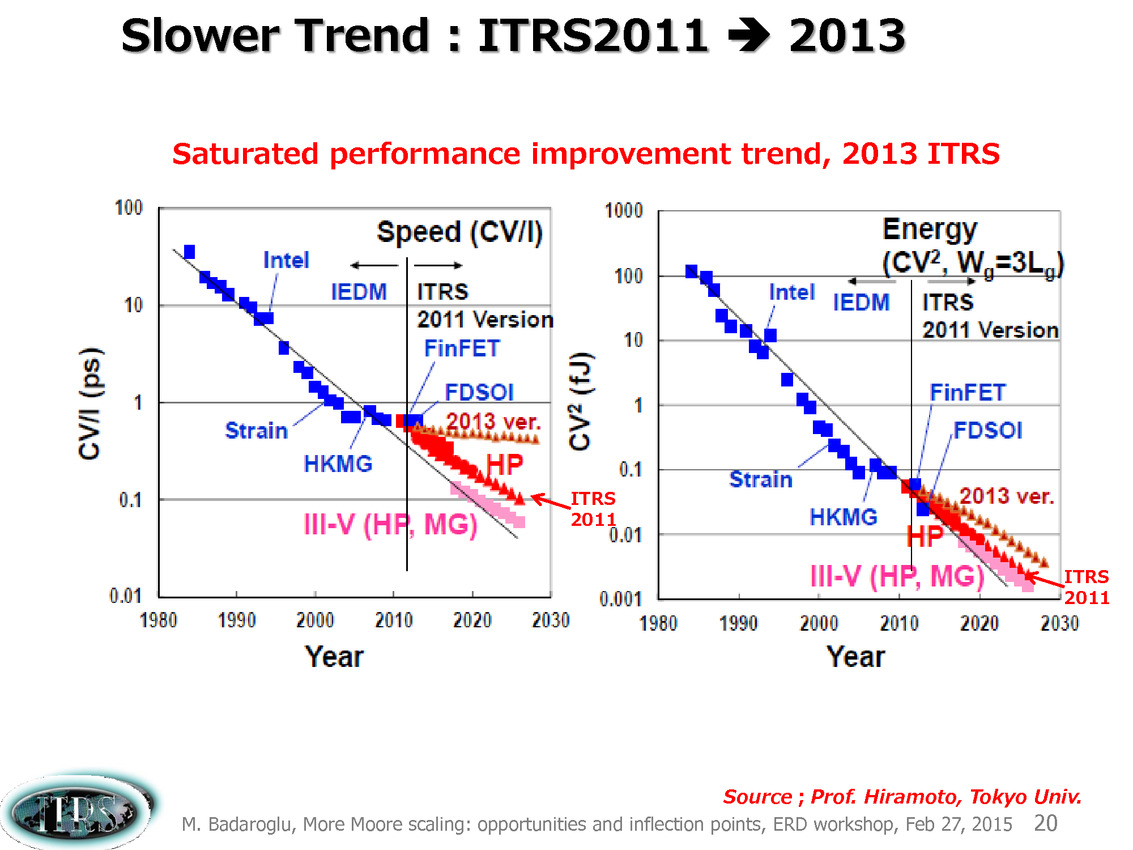
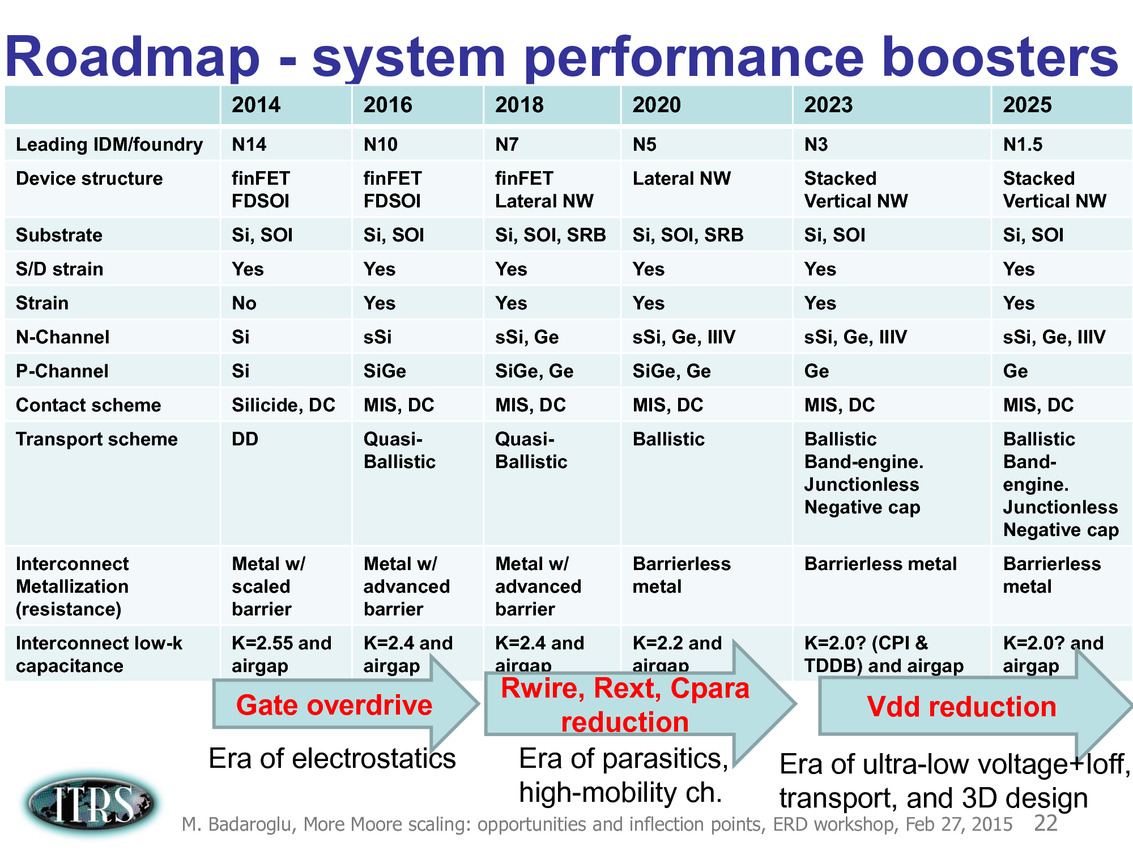
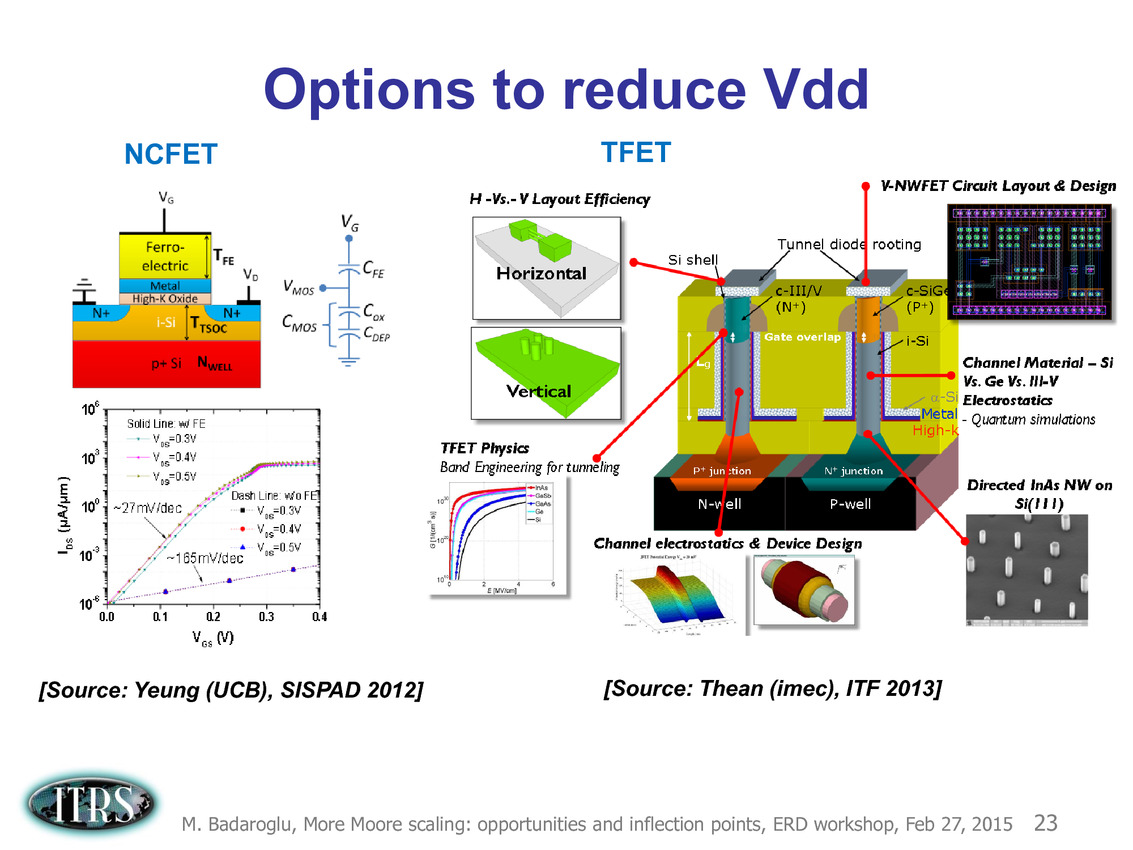
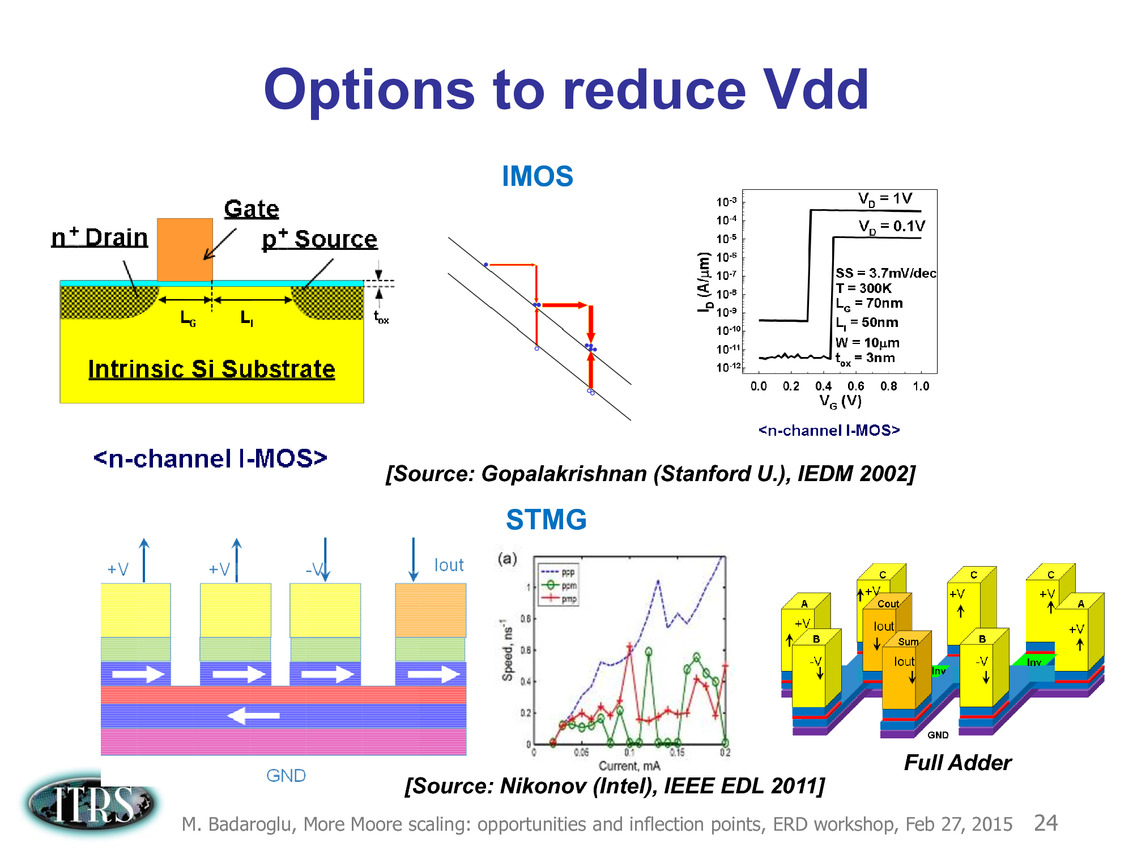
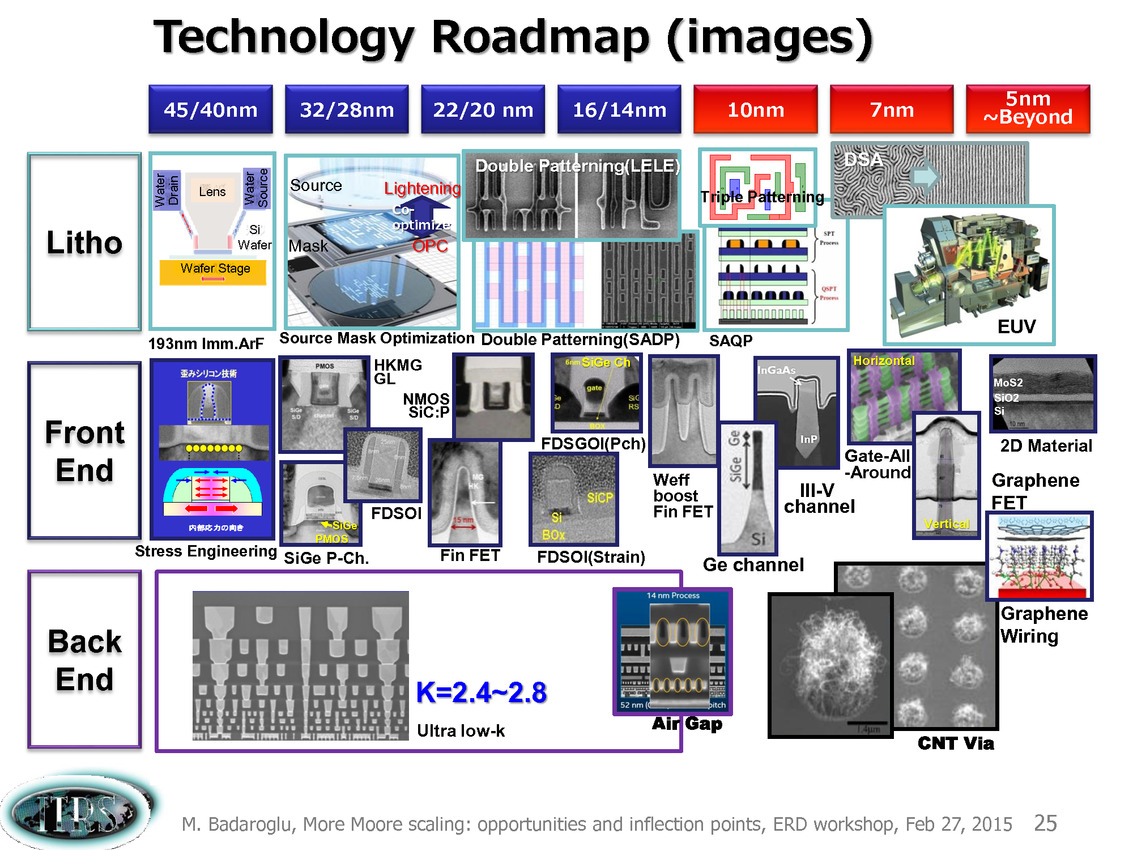

Une présentation intéressante qui évoque de multiples pistes et où l'on trouve un début de roadmap que nous avons remis ci-dessous :
En pratique, après l'ère de la mise à l'échelle géométrique, et l'ère des équivalences, l'ITRS évoque l'ère du "3D Power Scaling" dont les meilleurs représentants sont la NAND 3D ou des technologies comme la mémoire HBM. Des techniques complexes à appliquer aux puces logiques même si la présentation évoque quelques pistes et alternatives.
On attendra donc le mois prochain pour en savoir un peu plus !
128 Gb de Flash en 20nm chez IMFT
Intel et Micron viennent d'annoncer une nouvelle puce Flash MLC de 128 Gb gravée en 20nm. En combinant 8 de ces puces au sein d'un même packaging il est possible d'atteindre une capacité de 128 Go, une première. Les échantillons de la puce sont prévus pour le mois de janvier, la production en volume devant débuter au cours du premier semestre 2012.

Cette mémoire devrait de plus être nettement plus rapide lors d'accès séquentiel puisqu'elle utilise interface ONFI 3.0 à 333 MT/s soit le double des puces actuelles en 25nm. Les accès aléatoires 4K seront par contre le parent pauvre puisque la taille des pages sera désormais de 16 Ko contre 8 Ko pour les die 64 Gb et 4 Ko pour les die 32 Gb. Ces modifications devraient retarder l'intégration de ses puces dans les SSD et il ne faut pas l'attendre avant 2013.
IMFT annonce au passage que la puce 64 Gb (8 Go) 20nm annoncée en avril dernier est pour sa part désormais produite en volume. Elle mesure pour rappel 118mm², contre 167²mm pour son équivalent 25nm, et offre les mêmes caractéristiques en termes d'endurance ou de performances. Son arrivée devrait permettre de faire baisser le prix au Go des SSD, mais il faudra attendre la mi-2012 pour la voir débarquer dans nos boutiques.
Résultats d'Intel, 14nm et 7nm, Ultrabook
Intel annonce un cinquième trimestre record de suite avec un chiffre d'affaires de 13,1 milliards de $, soit 2% de mieux séquentiellement et 22% de mieux qu'il y a un an. Le résultat net ressort pour sa part à 3 milliards, respectivement en baisse de 7% et en hausse de 2%, du fait notamment du rachat de ses propres actions pour 2 milliards de $. La marge brute s'établit pour sa part à 61% comme au premier trimestre, loin du taux record de 67,6% d'il y a un an que les consommateurs ne regretterons pas. Il faut noter que McAfee et Infineon Wireless Solutions (désormais Intel Mobile Communications) ont contribué au chiffre d'affaires à hauteur de 1 milliard de $.
Côté divisions, par rapport à l'an passé on note une hausse de 11% des ventes de la division PC Client (desktop/mobile, 8,3 milliards), contre 15% pour la division Data Center (serveurs, 2,4 milliards) et 85% pour la division Other Intel Architecture (solutions embarquées, 1389 millions). Les chiffres de l'Atom sont par contre assez décevants avec 15% de baisse, pour des revenus de 352 millions.
Intel annonce par ailleurs une hausse de 500 millions de $ des investissements prévus cette années en R&D (pour un total de 16,2 milliards). Une partie de ses dépenses provient d'une accélération du développement du 14nm dont l'arrivée est prévue pour 2014, les futures usines 14nm comme celle de Chandler étant d'ailleurs désormais prévues pour accueillir également à terme des gravures en 10 et 7nm. Une autre partie est destinée au développement des Ultrabook, format dans lequel Intel a beaucoup d'espoirs.