
Les contenus liés au tag 10nm
Afficher sous forme de : Titre | Flux1er tape-out 10nm ARM chez TSMC
Quelques nouvelles du 10 et 7nm chez TSMC
De Tick Tock à Process Architecture Optimization
L'EUV possiblement pour le 7nm ?
Accélération SHA pour Cannonlake
7nm fin 2018 pour GlobalFoundries ?



GlobalFoundries a publié un communiqué de presse annonçant officiellement son prochain process FinFet, qui sera en 7nm. On rapellera que le process 14 FinFET actuel de GlobalFoundries, le 14LPP, a été développé par Samsung suite aux problèmes de développement du 14XM (la version interne du 14nm de GlobalFoundries, abandonnée).

Comme nous vous l'avions indiqué, GlobalFoundries ne proposera pas de 10nm, son prochain process sera donc un 7nm, baptisé tout simplement 7nm FinFET. Comme souvent, le communiqué du fondeur est particulièrement flou, indiquant à la fois que ce 7nm FinFET profitera des "années d'expérience d'IBM", tout en se "construisant sur le succès du 14LPP".
Le fondeur donne deux chiffres, tout d'abord une densité double par rapport "aux process 16/14", et un gain de performances de 30%. On notera avec circonspection que chez TSMC par exemple, le 10nm est annoncé comme 2.1x plus dense que son 16nm, et que son 7nm sera 1.63x plus dense que son 10nm. Autant dire que le 2x annoncé par GlobalFoundries ne semble pas vraiment au niveau d'un "7nm".
Techniquement le fondeur confirme qu'il s'agira d'un process FinFET optique, avec éventuellement la possibilité d'utiliser de l'EUV si disponible sur quelques couches.

Côté délais, GlobalFoundries annonce une production "risque" début 2018. A titre de comparaison, le 7nm de TSMC est annoncé en production risque début 2017, avec une production volume démarrant en Q1 2018.
Sur le papier donc, ce communiqué de presse de GlobalFoundries est tout simplement inquiétant, dévoilant un 7nm dont les caractéristiques techniques semblent assez lointaines de ce que proposera un TSMC ou un Samsung. Et qui sera disponible qui plus est avec un retard d'au moins 6 mois, et possiblement plus, par rapport au planning - certes incroyablement agressif - de TSMC.
Si la CEO d'AMD, Lisa Su, se satisfait dans le communiqué des développements "à long terme" de GlobalFoundries, cette annonce assez peu flatteuse du fondeur explique probablement pourquoi il a accepté de lâcher du lest auprès d'AMD. Nous vous en parlions en détail en début de mois, AMD et GlobalFoundries ont renégocié leur Wafer Supply Agreement avec pour résultat la levée de multiples clauses d'exclusivités qui liaient les deux sociétés.
Coffee Lake en 28W et 45W pour 2018
Un extrait de roadmap d'Intel a été publié ces derniers jours sur le forum d'Anandtech . On y voit apparaître pour la première fois Coffee Lake dont nous avions appris l'existence durant l'été.
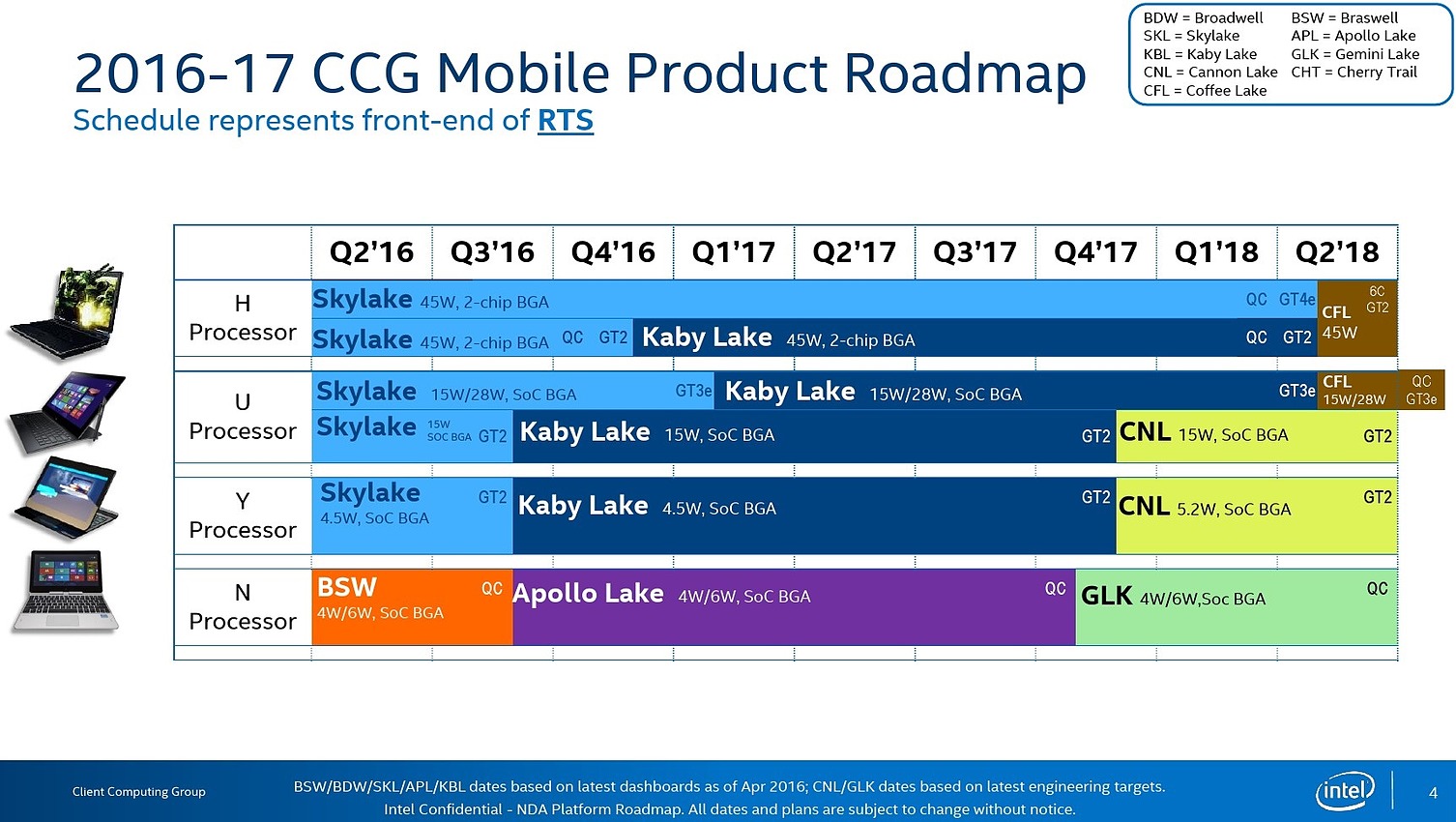
Pour rappel, Intel propose aujourd'hui Kaby Lake, sa troisième itération sur le process 14 nm, uniquement pour les modèles 15 et "4.5" watts (les gammes U et Y). Lors de l'annonce, Intel avait indiqué que les versions Desktop ainsi que les versions quad cores mobiles et équipées du cache L4 seraient annoncées en janvier. Cette roadmap d'avril semble alignée sur ce point, même si l'on note qu'une version quad core GT2 (sans mémoire L4 embarquée) en 45W (gamme H) était prévue pour le 4eme trimestre. On verra si cette version aura été repoussée également à janvier.
Cannon Lake, fabriqué en 10nm, est prévu pour la toute fin de l'année 2017, uniquement là aussi sur les gammes 15 et "5.2" watts à l'image de Kaby Lake aujourd'hui.
En ce qui concerne Coffee Lake, il s'agira d'une quatrième itération en 14nm, prévue pour le second trimestre 2018. On le retrouvera à la fois dans les gammes U et H, pour les dies 15/28W et les 45W. Plusieurs surprises de ce côté, d'abord le fait qu'Intel proposerait des puces 15/28W quad core avec Coffee Lake. Ce serait un changement majeur, les quad core étant réservés jusqu'ici au TDP supérieur côté mobile (45W).
Et comme nous l'avions entendu a l'époque, pour le plus haut de gamme (45W), Intel augmentera là aussi le nombre de coeurs passant (enfin) à 6. Il est là aussi intéressant de noter que si le GT3e est bien présent sur le segment en dessous, dans les gammes H le GT4e est aux abonnés absents, aussi bien pour Kaby Lake que Coffee Lake. Il faut dire que même côté Skylake, si les modèles Iris Pro 580/GT4e ont été annoncés, en pratique leur disponibilité dans des PC portables est proche du néant.
Après un Broadwell-H très en retard et la situation actuelle autour des Skylake-H (qui fâche parmi ses clients les plus visibles comme Apple qui avait utilisé les modèles Iris Pro Quad Core dans ses Macbook Pro), on peut se demander si Intel ne jette tout simplement pas l'éponge sur ces SKUs pour ses deux prochaines générations...
Intel Custom Foundry prend une licence ARM !
 ARM l'a confirmé par un post de blog : Intel Custom Foundry, l'activité fabrication tiers d'Intel, est désormais détentrice d'une licence ARM Artisan pour le 10nm !
ARM l'a confirmé par un post de blog : Intel Custom Foundry, l'activité fabrication tiers d'Intel, est désormais détentrice d'une licence ARM Artisan pour le 10nm !
Il faut rappeler qu'Intel est plutôt un cas à part dans le monde des semi-conducteurs, étant l'une des rares sociétés à disposer de ses propres usines, utilisées quasi uniquement pour la production de ses propres puces. La plupart des autres acteurs du marché ont migré vers la séparation de l'activité design d'un côté (on parle de sociétés fabless, c'est le cas dans le monde du GPU avec AMD et Nvidia), et de l'autre la fabrication dans des sociétés tierces spécialisées (on parle de foundry, la plus connue étant TSMC qui fabrique des puces pour de multiples clients).
Avec la difficulté de la mise au point des nouveaux process de fabrication, qui n'a fait qu'empirer ces dernières années, il est de plus en plus complexe pour une société à elle seule de justifier l'investissement nécessaire pour faire évoluer sans cesse ses usines. Qui plus est, la réduction de la taille des transistors fait que la capacité des usines augmente d'année en année, et qu'il faut disposer de très larges volumes de puces à produire, au risque de voir ses usines tourner à vide.
Un casse tête qui aura poussé plusieurs sociétés à se séparer de leurs usines (pour des raisons différentes) d'abord AMD en 2009 (créant GlobalFoundries) et plus récemment IBM (dont l'activité fabrication à été rachetée elle aussi par GlobalFoundries).
Depuis quelques années, en plus de fabriquer ses propres puces dans ses usines, Intel a décidé d'entrer très timidement, en 2010, sur le marché des fondeurs tiers en ouvrant son process à de petites sociétés qui n'étaient pas en concurrence directe avec ses produits (le premier client était Achronix, designer de FPGA en 22nm). D'autres clients ont suivi, principalement sur les FPGA, le client le plus connu d'Intel ayant été Altera... même si au final Intel aura décidé de racheter son client à la mi-2015 !
Pour Intel, la nécessité d'ouvrir ses usines est un casse tête. D'un côté, la société tente d'être présent sur tout les marchés, en déclinant le x86 - technologie "maison" sur laquelle la concurrence est limitée - à toutes les sauces et avec un soupçon de recyclage, que ce soit avec des produits serveurs spécialisés comme les Xeon Phi basés sur des Pentium pour leur première génération, ou les Quark dédiés à l'embarqué et utilisant une architecture de 486 datant d'une bonne vingtaine d'années !
Si l'envie de la société d'être présente sur tous les marchés est là, en pratique les succès ne sont pas systématiquement au rendez vous, Intel ayant par exemple massivement raté le marché des smartphones. Cumulé à la baisse continue des ventes sur le marché historique des PC, l'ouverture des usines à des clients tiers se dessine de plus en plus comme une nécessité pour Intel, même si l'avouer semble impossible à la société, qui continuait donc d'envoyer des signaux mitigés aux possibles futurs clients de son activité fabrication.
Avec l'annonce d'aujourd'hui, les choses sont - peut être - en train de changer puisque la prise de licence ARM par Intel est tout sauf anodine. Ce n'est pas la première fois qu'Intel fabriquera des SoC ARM, on l'avait vu avec Altera qui utilisait un core ARM dans un usage très spécifique.
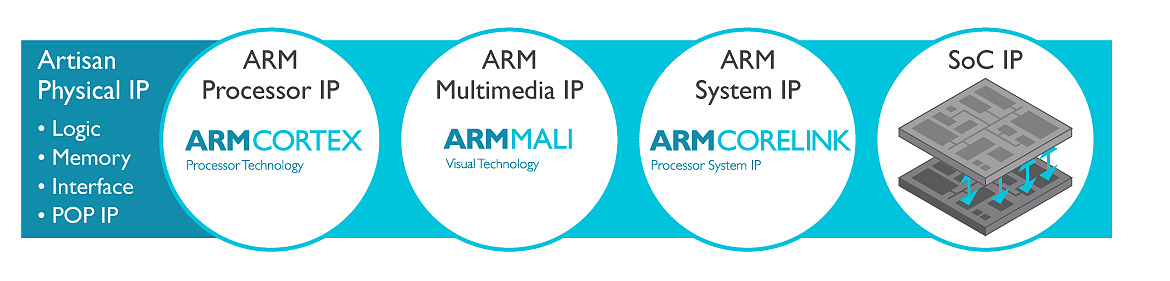
La licence Artisan Physical IP inclut en effet toutes les briques nécessaires pour la création de puces ARM de tout types. Il s'agit de tous les blocs de base avec des bibliothèques haute densité et haute performance de transistors logiques,et également tout le nécessaire pour les différents types de mémoire. La licence inclut surtout POP IP, qui est pour rappel l'idée qui fait le succès d'ARM : permettre l'utilisation de blocs interchangeables et compatibles pour créer des puces custom. Ainsi un client peut choisir d'utiliser des coeurs CPU dessinés par ARM (les gammes Cortex) ou créer ses propres coeurs (c'est le cas d'Apple et plus récemment de Nvidia), de choisir un GPU (que ce soit les Mali d'ARM, ou les populaires PowerVR d'Imagination Technologies), et également de choisir son fournisseur pour les interconnexions.
Concrètement, Intel va donc "porter" ces bibliothèques d'ARM aux particularités de son futur process 10 nm, ce qui permettra aux partenaires d'ARM de porter à leur tour - s'ils le souhaitent - leurs blocs POP IP. ARM et Intel travailleront conjointement pour le portage de deux futurs blocs CPU ARM Cortex-A (probablement un autre successeur 10nm de l'A72, voir l'annonce de l'A73 en 10nm lui aussi), la déclinaison que l'on retrouve dans les smartphones et tablettes.
Faut il y voir un virage pour Intel ? Fabriquer des puces ARM pour smartphones, ce qu'ils feront pour LG (nouveau client annoncé dans la foulée) va forcément à l'encontre des ambitions internes d'Intel d'imposer le x86 sur mobile. Car si un peu plus tôt dans l'année Intel avait décidé d'annuler sa nouvelle génération de SoC pour smartphones (Broxton et SoFIA), le constructeur continuait en interne à travailler sur les générations suivantes tout en essayant de développer dans l'intérim son activité modem (Intel aurait possiblement gagné le marché du modem du prochain iPhone). A l'heure où ARM augmente ses ambitions pour aller attaquer le marché juteux des serveurs, on peut se demander jusqu'où ira réellement l'ouverture d'Intel.

Un futur CPU ARMv8 24 coeurs de Qualcomm
En fabriquant des puces concurrentes, Intel s'ouvre à des comparaisons directes qui pourraient être assez défavorables à ses architectures x86, assez peu adaptées à la basse consommation. L'avantage supposé du process d'Intel, s'il existe, ne pourra plus jouer en la faveur de ses propres solutions pour compenser un éventuel déficit architectural. La structure de marges d'Intel, là aussi très différente de celle des fondeurs tiers, posera là aussi rapidement problème.
Qui plus est, en obtenant la licence Artisan d'ARM, Intel va devoir partager tous les détails techniques, y compris les plus secrets, de son process en ce qui concerne les règles et les dimensions exactes des transistors, ce qui va l'exposer là aussi à une comparaison directe avec les autres acteurs installés du milieu (comme TSMC et Samsung). Il faudra un peu de temps pour mesurer les conséquences concrètes de tout cela, car cet accord ne concerne que le 10nm, un process pour rappel en retard et qui n'est prévu chez Intel que pour la fin de l'année 2017 en version mobile. Les dernières nouvelles du 10nm, sur lequel Intel ne communique pas, n'étaient pour rappel pas particulièrement rassurantes avec l'arrivée possible sur sa roadmap de puces 14nm... pour 2018.
Coffee Lake : 14nm et 6 coeurs en 2018 ?
D'après PC Watch , Intel aurait ajouté une nouvelle gamme de processeur en 14nm prévue pour 2018, Coffee Lake. Après Haswell, Skylake et Kaby Lake, il s'agirait donc d'une quatrième itération sur le même process, au lieu de deux habituellement.
Cannon Lake serait toutefois maintenu pour fin 2017, mais il existerait uniquement en version 2 coeurs et associé à un iGPU de petite taille (GT2) et serait destiné plus particulièrement aux gammes mobiles les moins énergivores (U et Y). A contrario Coffee Lake viserait un niveau de performance supérieur, étant décliné avec un iGPU de type GT3e (donc associé à de l'eDRAM) et en versions 2, 4 et 6 coeurs !
Coffee Lake marquerait donc la fin du blocage à 4 coeurs pour les processeurs grand public, une bonne nouvelle qui ne doit toutefois pas faire oublier que le fait qu'il soit prévu en 14nm laisse penser qu'Intel n'est pas très optimiste sur son 10nm, reste à savoir s'il s'agit d'un choix dicté par des impératifs techniques ou financiers.
ARM annonce le Cortex-A73 et le Mali-G71
ARM vient d'annoncer de nouveaux blocs disponibles pour ses partenaires. Pour rappel, ARM développe en parallèle des architectures (ARMv8-A pour la dernière version 64 bits, le pendant du x86-64 dans le monde du PC) et propose aussi ses propres implémentations de coeurs qui peuvent être utilisés par ses partenaires sous licence (l'équivalent dans le monde PC serait Intel qui autorise ses partenaires à faire des versions "custom" de Skylake).
Certains des partenaires d'ARM disposent d'une licence dite "architecture" (Apple, Qualcomm, Samsung, Nvidia...) qui leur permet de réaliser leurs propres implémentations (de la même manière qu'AMD et Intel proposent des processeurs compatibles, mais différents derrière la même architecture x86-64), même si ces derniers proposent parfois les deux. Qualcomm propose par exemple des puces utilisant les Cortex (implémentation ARM) et ses propres Snapdragon.
La nomenclature des implémentations d'ARM a toujours été compliquée à comprendre, pour ne pas dire autre chose, et autant dire qu'aujourd'hui ARM n'arrange pas son cas avec l'A73. Il fait suite sur le papier au Cortex-A72 qui avait été annoncé en février 2015 même si d'un point de vue technique les puces sont différentes.
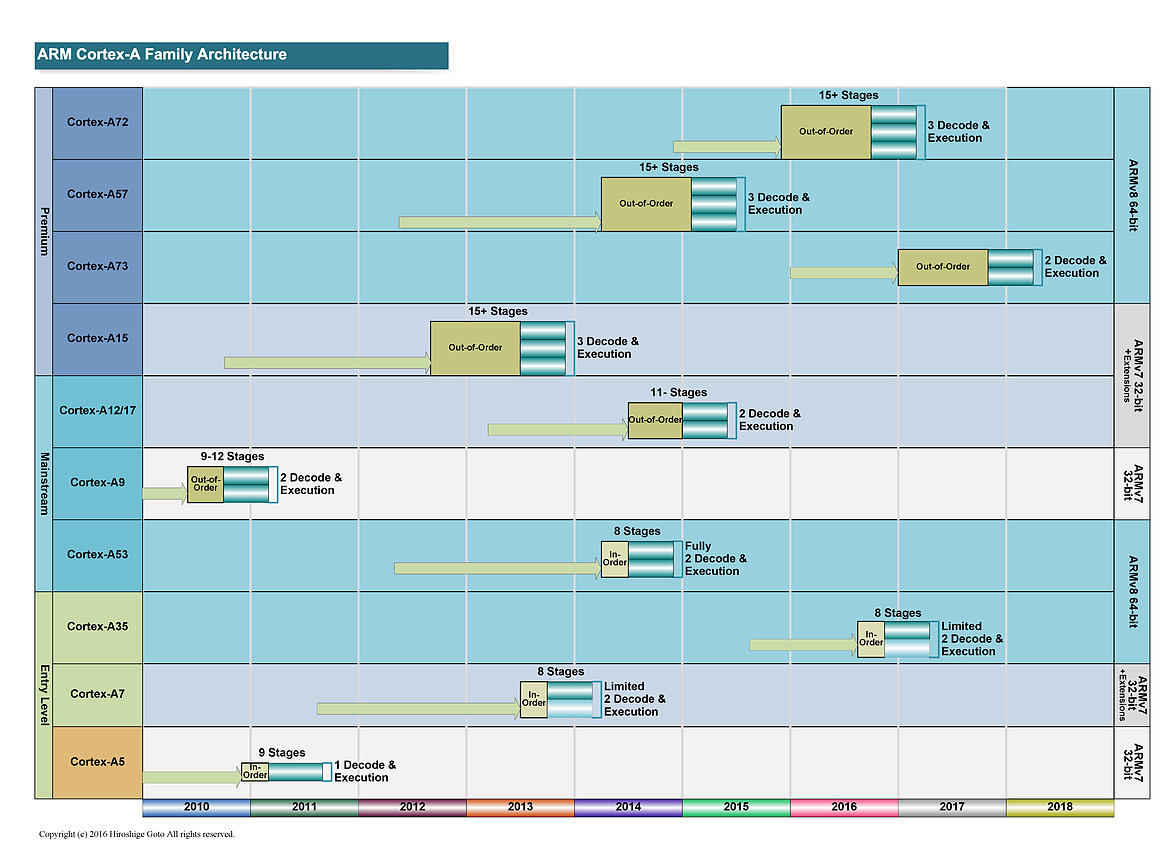
Ce diagramme permet d'y voir un tout petit peu plus clair. Après l'époque "simple" de l'A9, ARM a proposé d'un côté des cores de grande taille, visant les hautes performances (A15, A57 et A72), également appelés big. Il s'agit de designs "Out of Order" (le processeur peut changer l'ordre des instructions pour optimiser leur exécution).
En parallèle des coeurs de plus petite tailles ont été présentés (les coeurs LITTLE comme l'A7 et l'A53). Ils utilisent un design dit "In Order" (pas de changement d'ordre) qui simplifie l'implémentation, et réduit donc la consommation de la puce. Leur niveau de performance est plus bas, mais ils disposent d'un meilleur rapport performance/watts que les coeurs big. Leur intérêt théorique est de les mélanger pour créer une architecture asymétrique (big.LITTLE, voir la présentation ici) même si en pratique, ce n'est pas toujours ce qui s'est passé.
Les deux familles sont développées par des équipes différentes (Austin pour les big et Cambridge pour les LITTLE) et au milieu de tout cela, on retrouvait les A12 et A17, mélangés sur ce graph (par une troisième équipe a Sophia-Antipolis). Il s'agissait là aussi de designs "Out of Order" mais un peu plus optimisés pour un meilleur rapport performances/watts.
Si en théorie ces puces étaient présentées comme dédiées au milieu de gamme, en pratique elles proposaient surtout une alternative aux gros coeurs ARM dont la consommation était trop élevée, obligeant de limiter fortement les fréquences pour rester dans l'enveloppe thermique d'un smartphone. On a pu voir un certain nombre de retards lors de la génération A57, particulièrement chez Qualcomm, et une surconsommation importante par rapport à ce qu'espérait ARM. Une situation qui a même poussé certains des partenaires d'ARM a proposer des puces n'utilisant que les coeurs LITTLE, un comble.
Cortex A73 : 10nm
Le Cortex A73 est présenté par ARM comme son nouveau coeur big. Il fait suite à l'A72 (16nm) et sera proposé pour les processus de fabrication 10nm. Mais contrairement à ses prédécesseurs big 64 bits (A57 et A72, c'est dur à suivre !), il s'agit sur le papier du successeur des A12/A17 (qui eux n'étaient disponibles qu'en 32 bits).
Contrairement aux A57/A72 qui pouvaient décoder trois instructions par cycle, on se limite cette fois ci à deux sur l'A73. En contrepartie, le pipeline (le nombre d'étapes par lequel les instructions passent) est significativement réduit, passant de 15 à 11 étapes. C'est au niveau du front end (récupération des instructions, décodage, changement d'ordre) que la réduction se fait. On retiendra deux changements importants, d'abord le fait que les instructions en virgules flottantes/NEON (l'équivalent des instructions vectorielles type SSE dans les architectures x86) soient traitées séparément via un décodeur distinct. La seconde est un changement au niveau des instructions arithmétiques entières avec des unités moins nombreuses mais plus performantes.

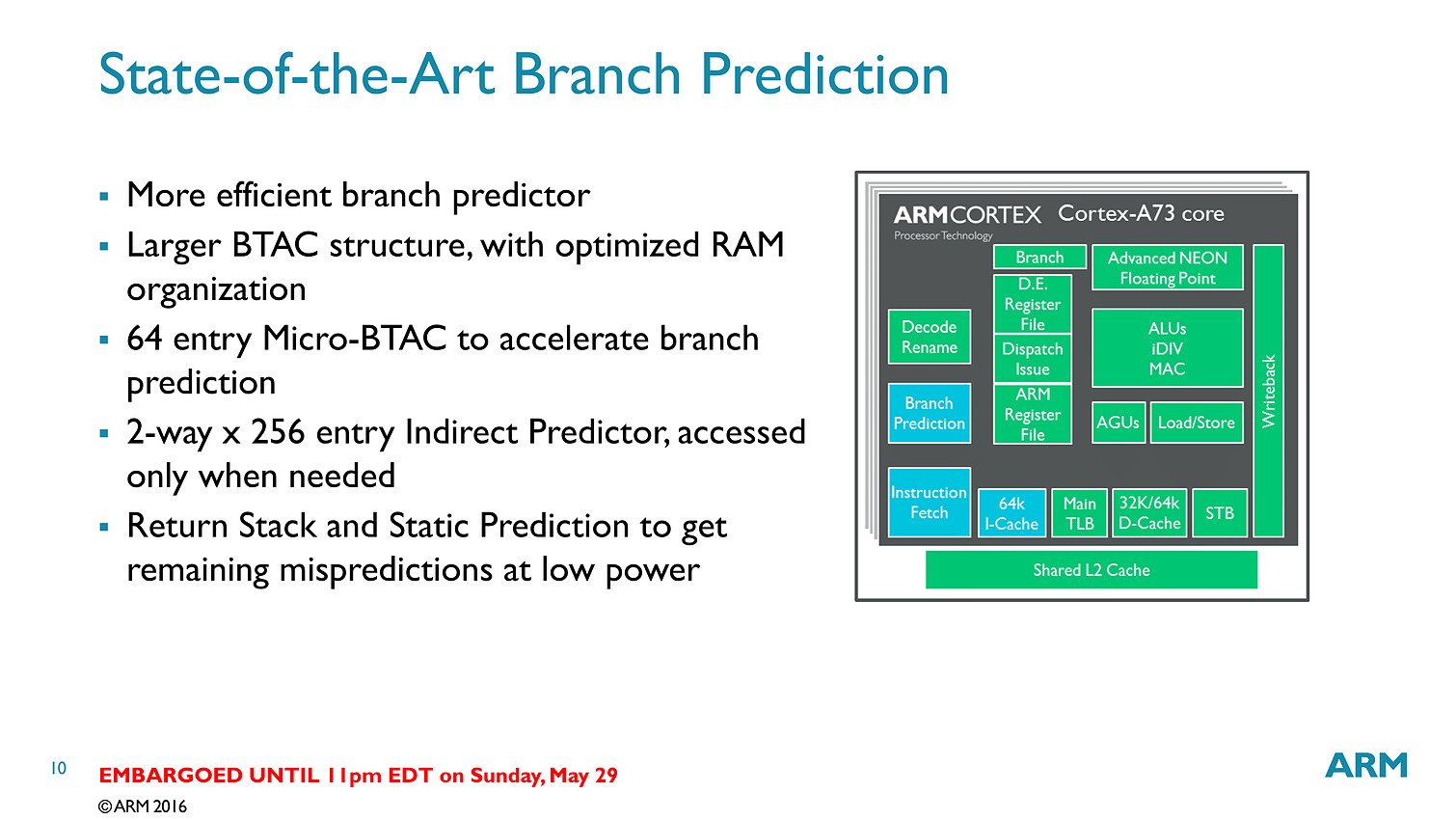


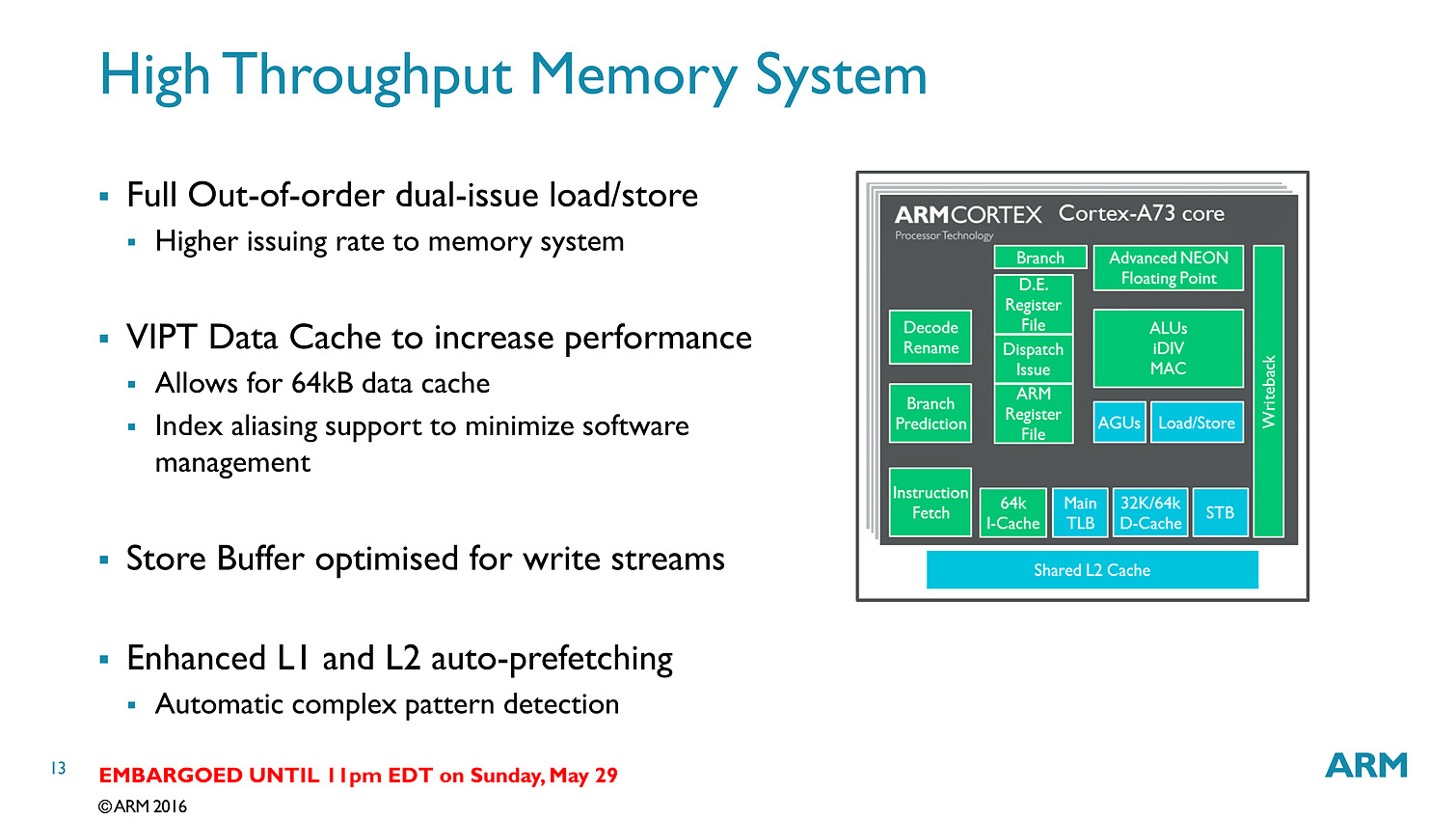
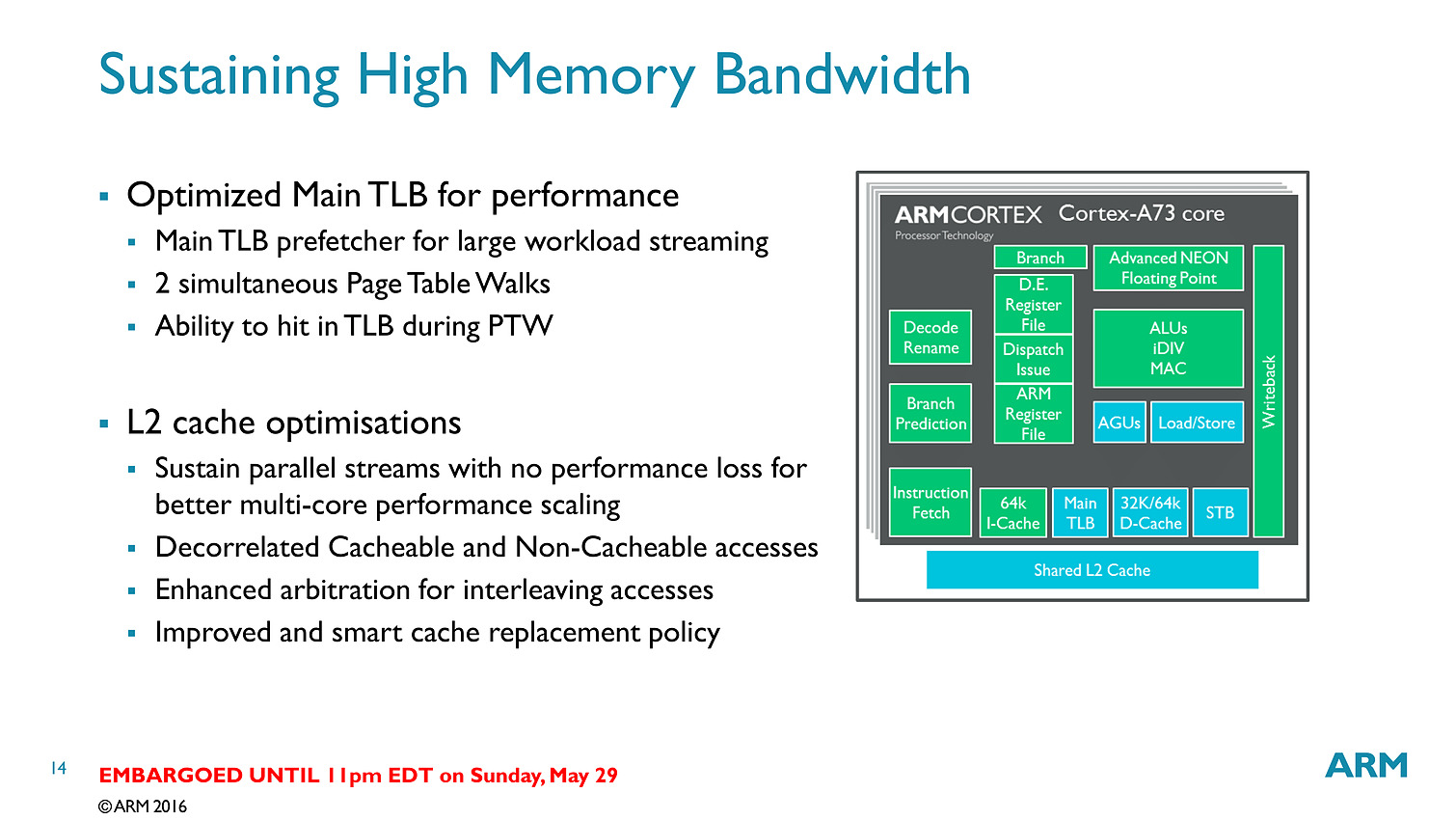
Bien que décodant une instruction par cycle en moins, l'A73 permet sur le papier au final de dispatcher 6 micro-instructions par cycle, contre 5 pour l'A72. Si l'on ajoute toutes les autres optimisations (le sous système mémoire, point faible historique des Cortex semble avoir évolué), l'A73 est annoncé comme 10% plus performant que l'A72, à fréquence/process égal.
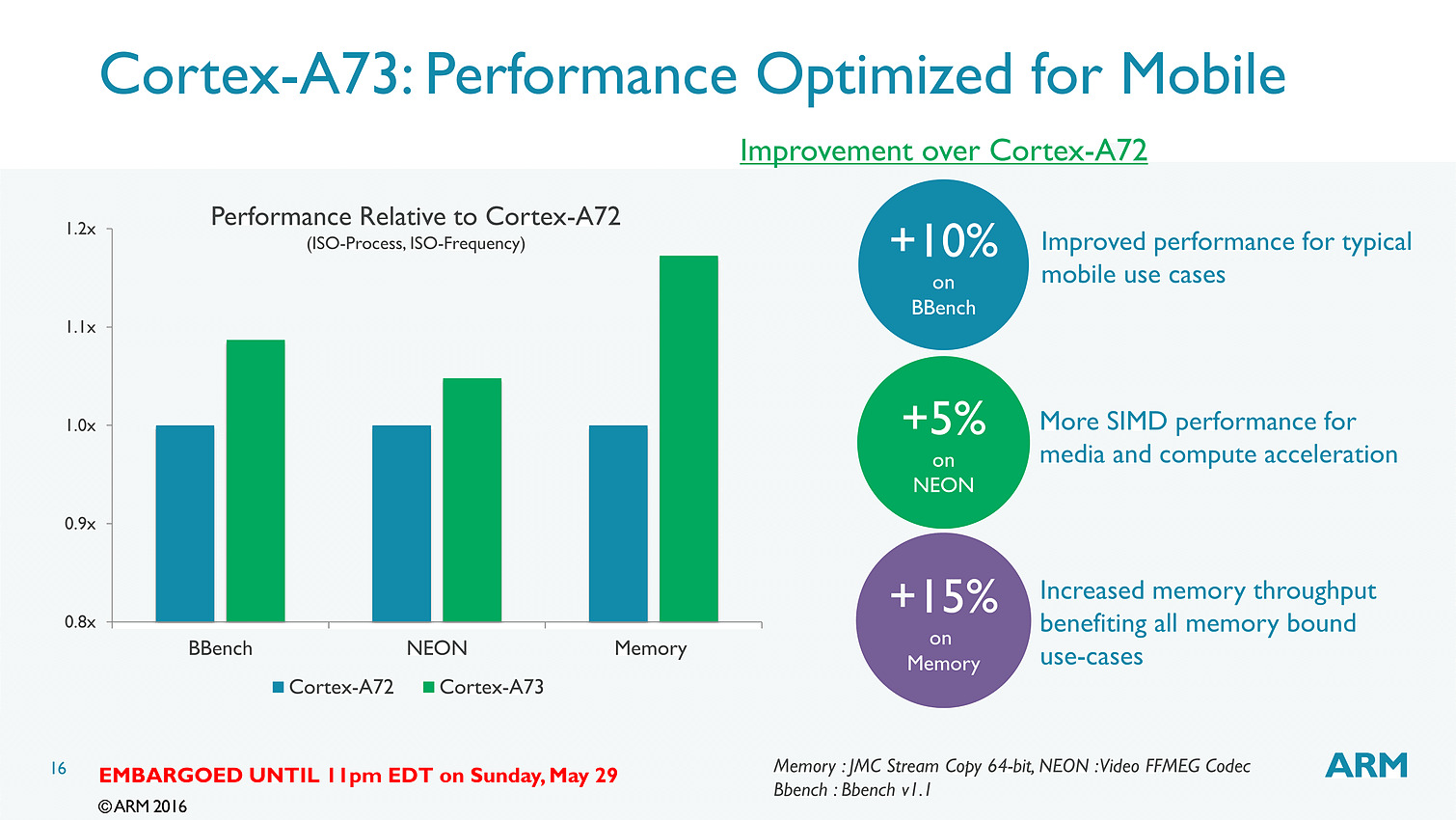
Dans le détail, ARM annonce plus spécifiquement 15% de gains sur les copies mémoire, et 5% sur un encodage FFMPEG utilisant les instructions vectorielles NEON. Notez qu'a process égal, un coeur A73 est 25% plus petit qu'un coeur A72 et consomme 20% d'énergie en moins. En 10nm, un coeur A73 ne mesure que 0.65mm2.
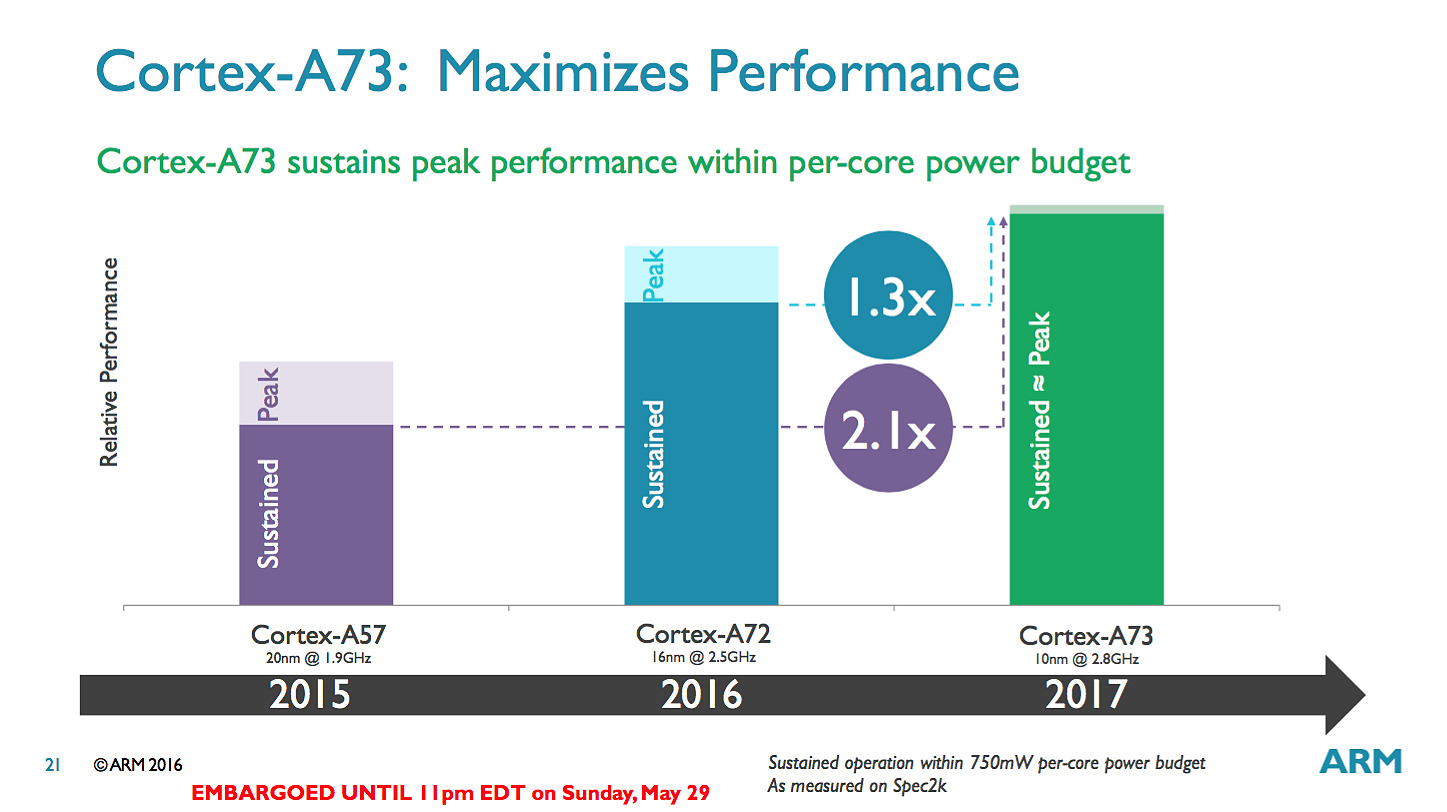
Pour les puces que l'on retrouvera dans le commerce, ARM annonce 30% de performances en plus par rapport aux A72 en profitant du 10nm et de la baisse de consommation pour augmenter la fréquence. Un autre gain significatif mis en avant par le constructeur est que ses puces ne devraient plus voir leur fréquence chuter drastiquement lorsque l'on utilise tous les coeurs en simultanée.
Sur le papier l'A73 est un meilleur compromis côté architecture que ses prédécesseurs, ce qui devrait ravir les partenaires d'ARM, assez peu heureux des A57. Si ARM vise le 10nm, en pratique il propose à ses partenaires des designs A73 en 28, 16 et 10nm. D'ici la fin de l'année, des SoC 16nm devraient faire leur apparition et c'est probablement là qu'on les trouvera en masse (le 10nm sera probablement, pour rappel, réservé au moins dans un premier temps aux gros acteurs du marché comme Qualcomm et Apple à l'image de ce que l'on avait vu avec le 20nm).
Mali-T71 et Bifrost
L'autre annonce d'ARM concerne les GPU. En plus de blocs CPU, ARM propose également à ses partenaires des blocs graphiques qu'ils peuvent utiliser ou non (d'autres sociétés comme Imagination Technologies proposent par exemple leur PowerVR) pour créer leurs SoC.
La nouvelle puce est baptisée T71 et vient faire suite aux GPU T800 dont nous vous avions parlé l'année dernière. Le changement de nomenclature annonce en réalité un changement d'architecture, on passe de l'architecture Midgard à la bien nommée Bifrost.
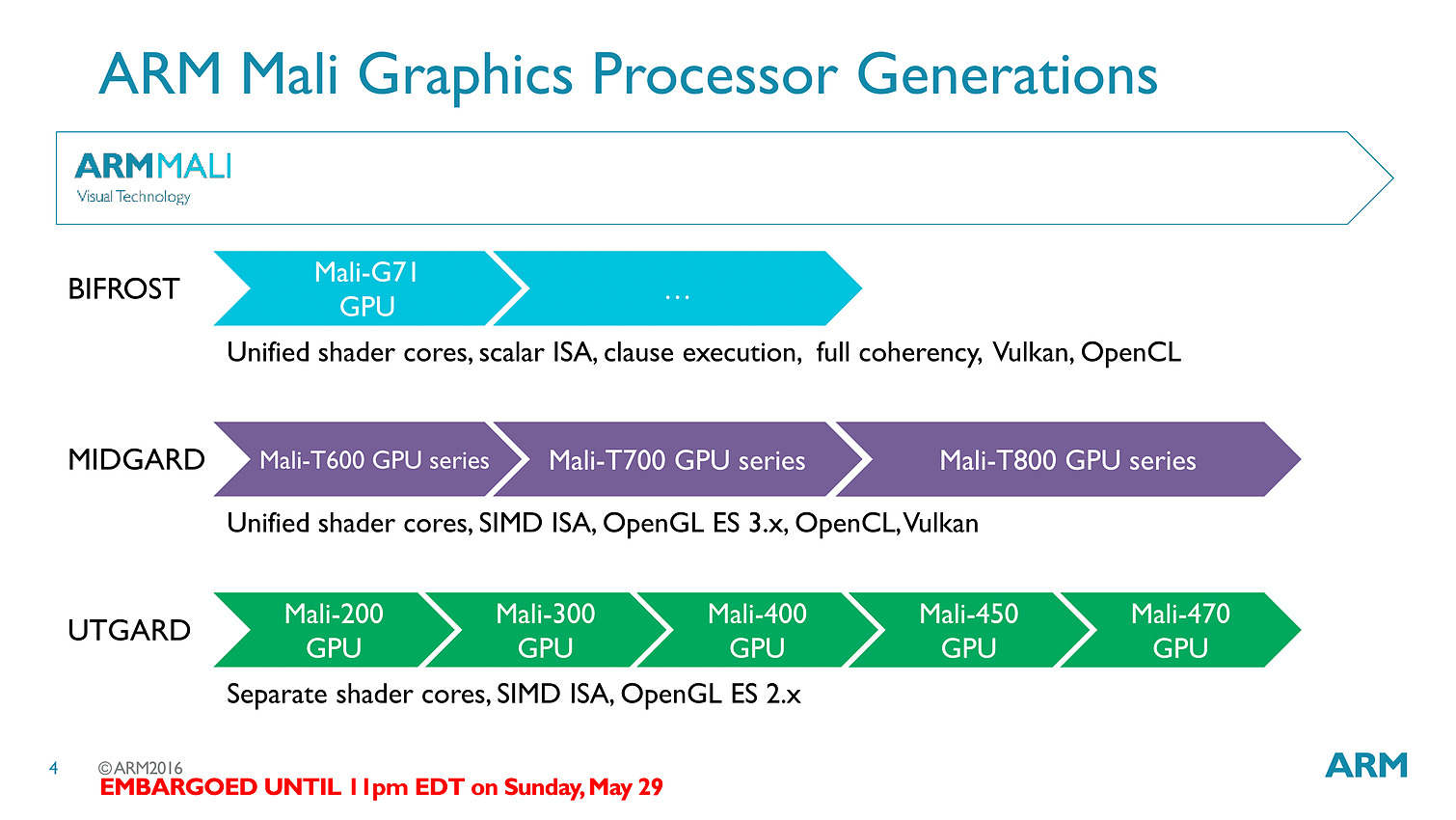
La transition est importante avec un changement complet de philosophie, passant d'un modèle VLIW (Very Long Instruction Word) à un modèle scalaire... soit exactement la transition qu'avait effectué AMD avec GCN !

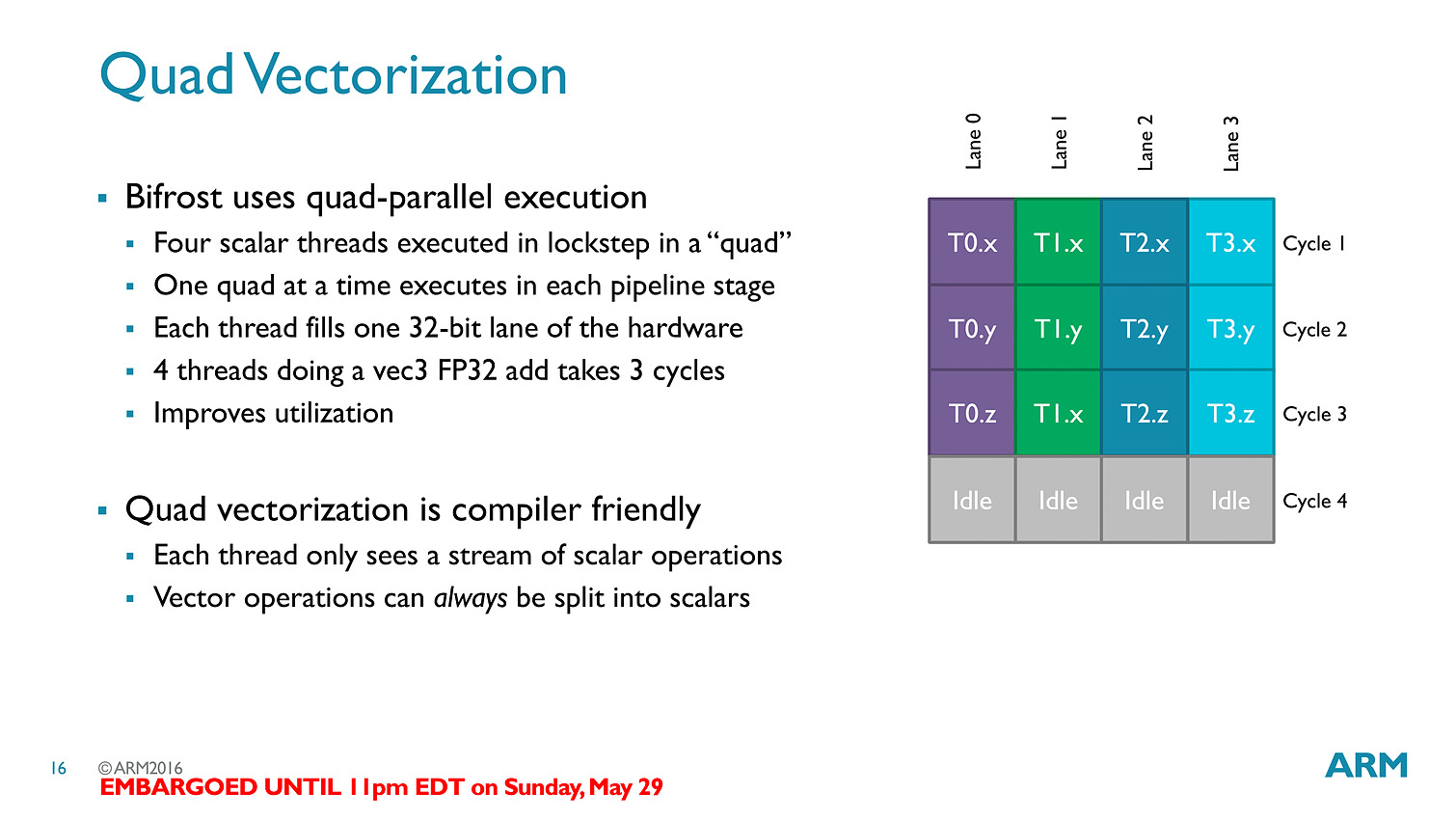
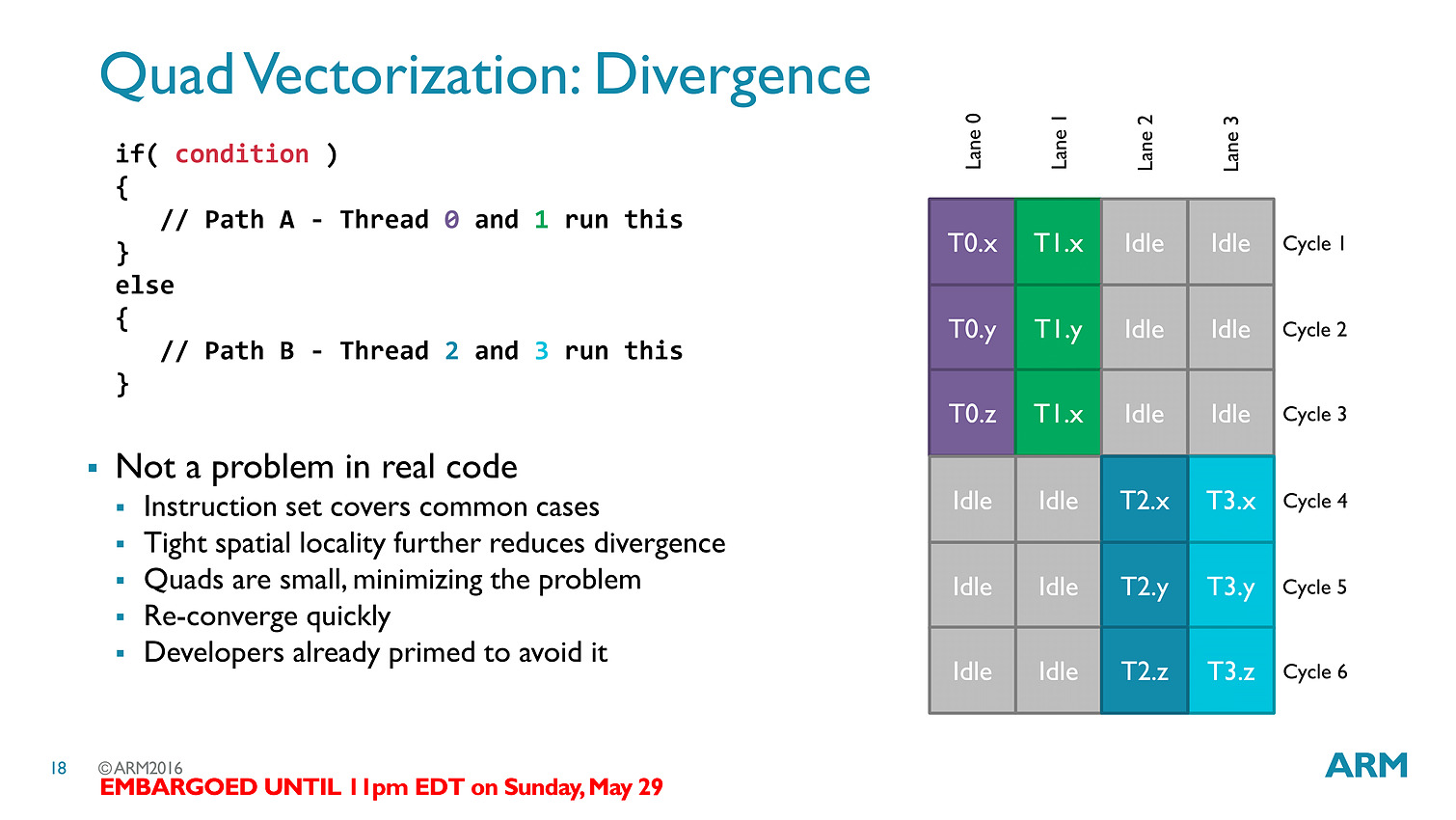
La transition aux unités scalaires change en pratique l'ordre dans lequel les données sont traitées, en simplifiant la compilation des shaders (le parallélisme étant extrait des threads, et non d'assemblage d'instructions par le compilateur).

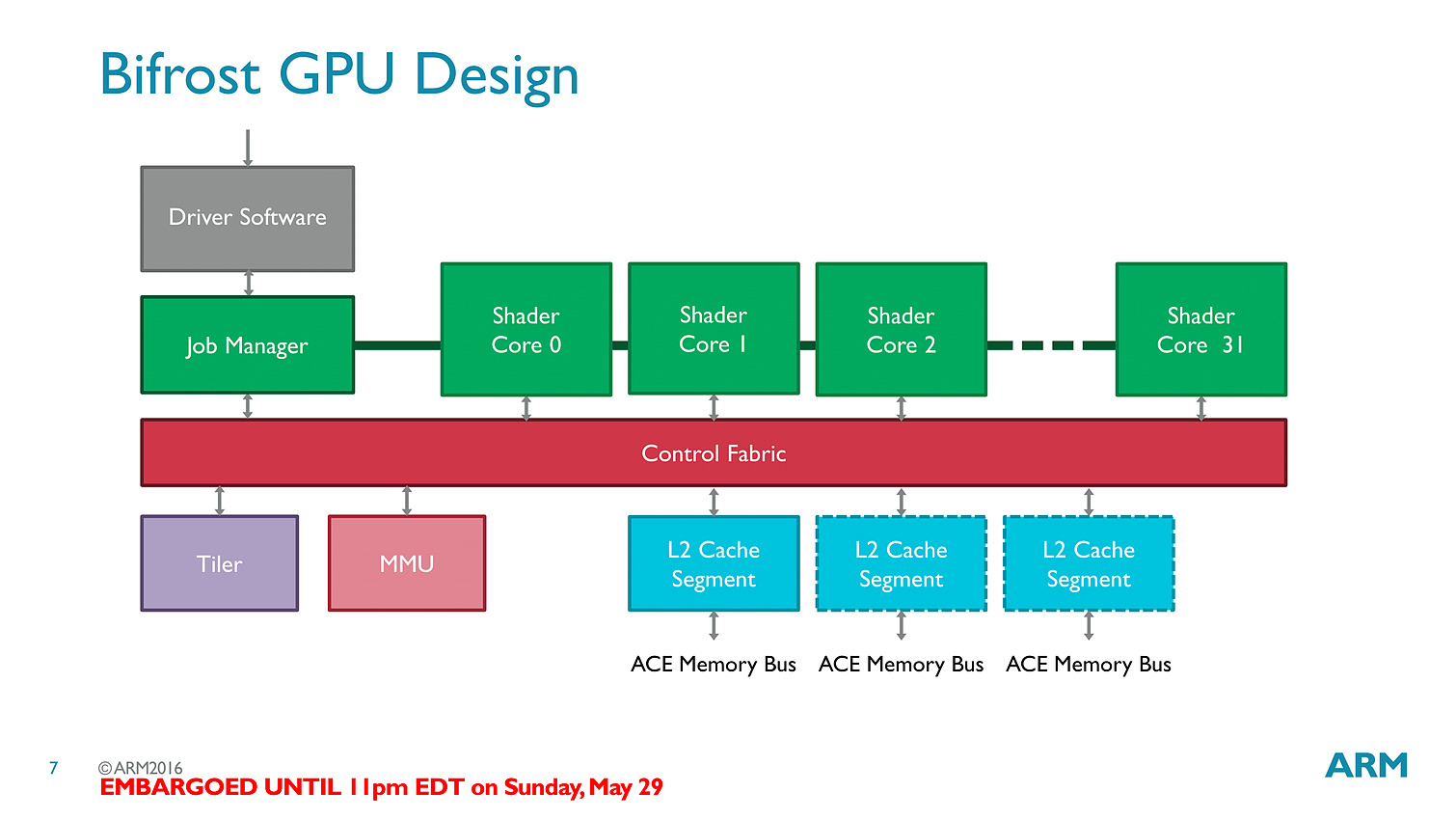
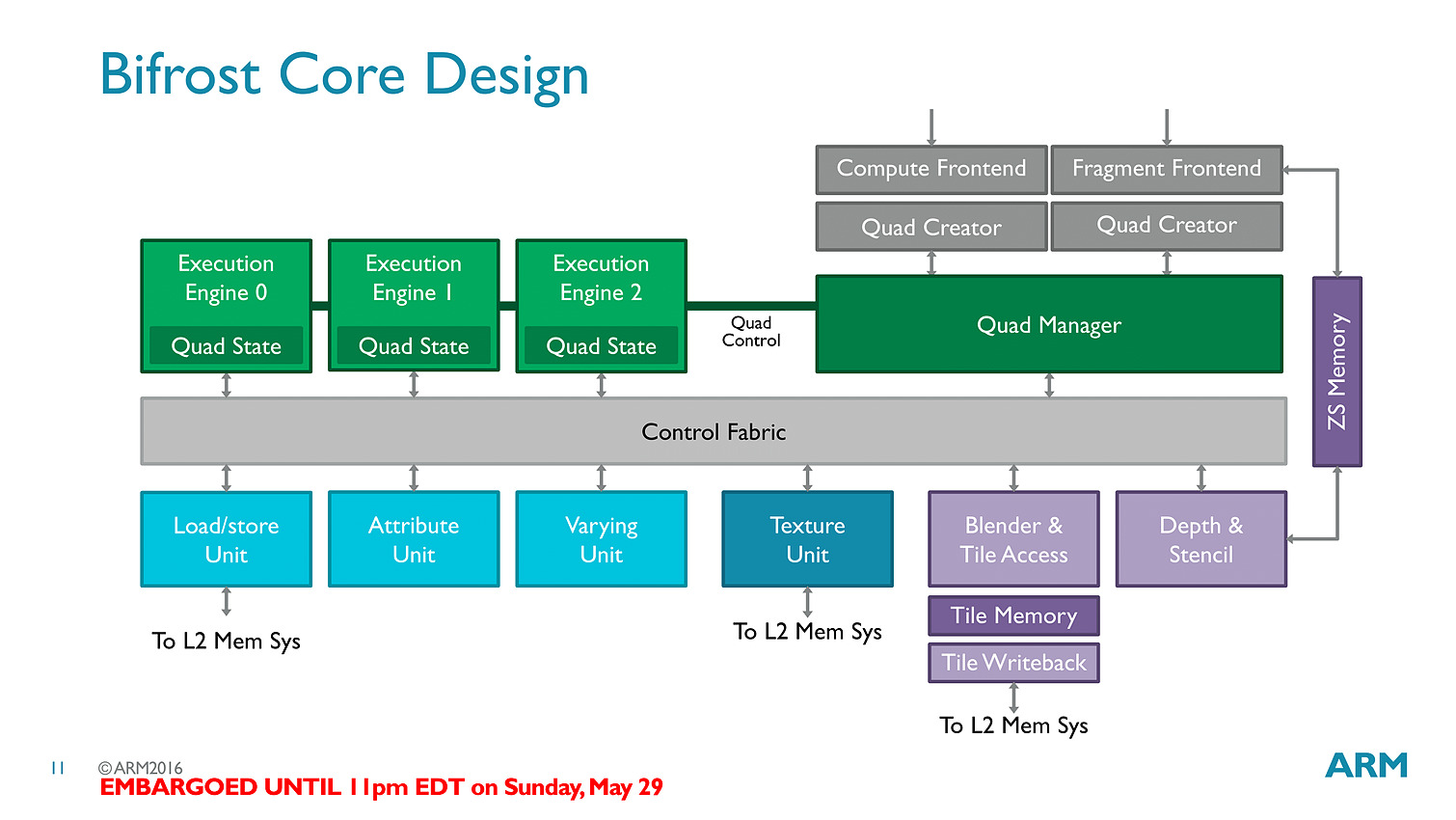
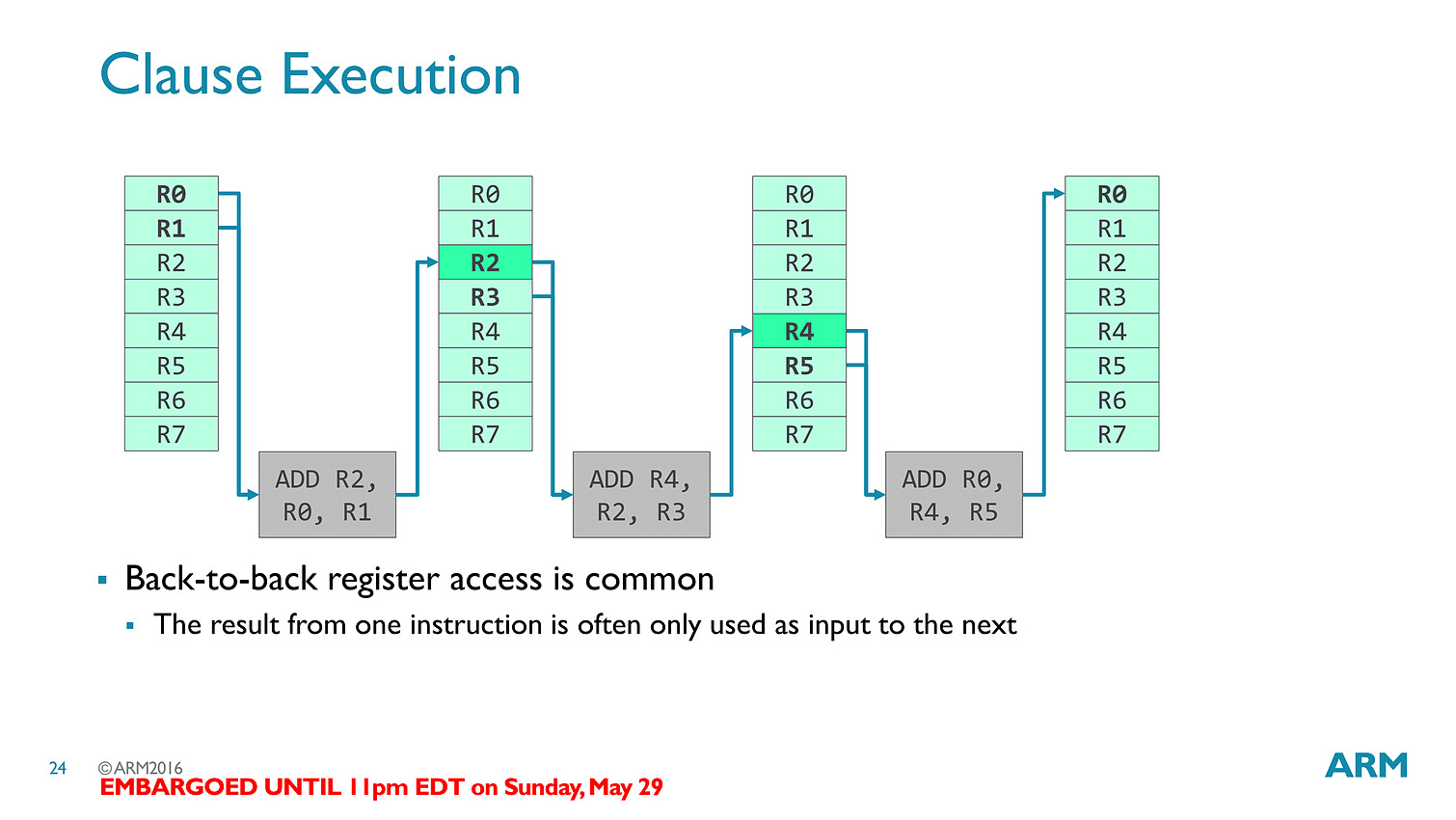
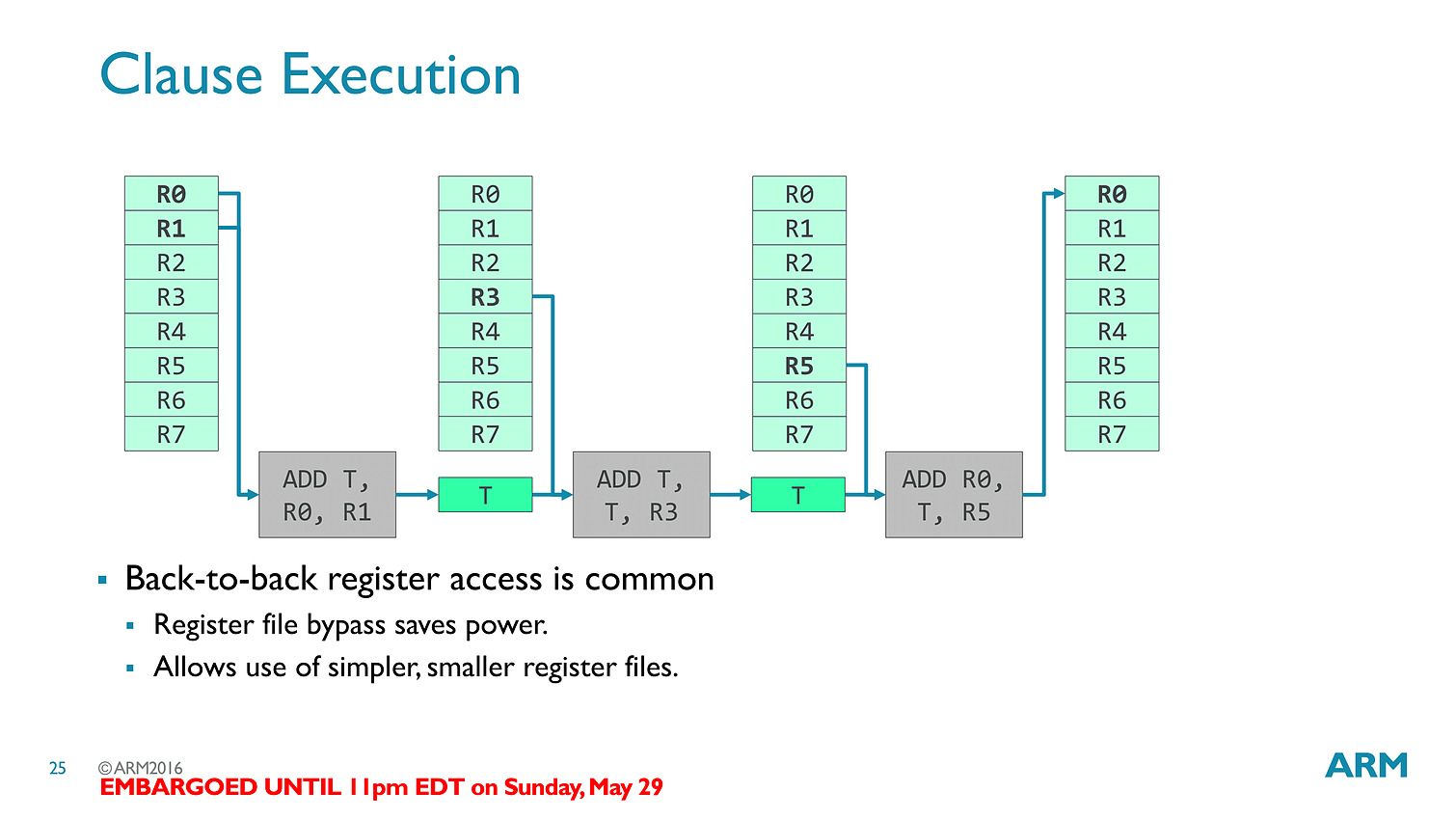

Les threads - clauses dans le langage ARM - sont particulièrement optimisées avec des caches a tous les niveaux (sous la forme de register file) pour s'assurer que les accès mémoires soient optimisés au mieux. Cumulé à tout les autres changements architecturaux (le tiler a également été modifié pour réduire sa consommation mémoire), ARM annonce 50% de gains de performances avec Bifrost.
En pratique le Mali-T71 est le premier GPU ARM utilisant Bifrost, il regroupera jusqu'à 32 shader cores (qui comptent chacun 12 unités scalaires) et reste compatible comme ses prédécesseurs avec OpenGL ES 3.x, OpenCL 2.0 et Vulkan. On rajoutera un dernier mot sur l'interconnexion puisque l'on a droit à un accès au cache fully coherent, ce qui signifie que CPU et GPU peuvent partager la même mémoire cache en opérant en parallèle sans blocage (à la manière de Kaveri chez AMD qui utilisait cependant deux bus distincts), ce qui pourra être utile pour des tâches compute ou l'on fait travailler de concert CPU et GPU (ce qui n'est pas forcément la majorité des usages sur les plateformes mobiles).