
Les derniers contenus liés aux tags ARM et 10nm
ARM annonce les Cortex-A75, A55 et Mali G72
Le 10nm de TSMC est bien à l'heure
10/7nm en avance pour TSMC, EUV pour le 5nm
Intel Custom Foundry prend une licence ARM !
ARM annonce le Cortex-A73 et le Mali-G71
ARM annonce les Cortex-A75, A55 et Mali G72



ARM vient d'annoncer de nouveaux blocs processeurs pour ses partenaires, sous le nom de Cortex-A75 et A55 (pour un rappel sur la stratégie d'ARM, nous vous renvoyons au début de cet article). Ces nouveaux Cortex sont des coeurs CPU clefs en main qui peuvent être utilisés par les partenaires d'ARM pour concevoir leurs SoC.
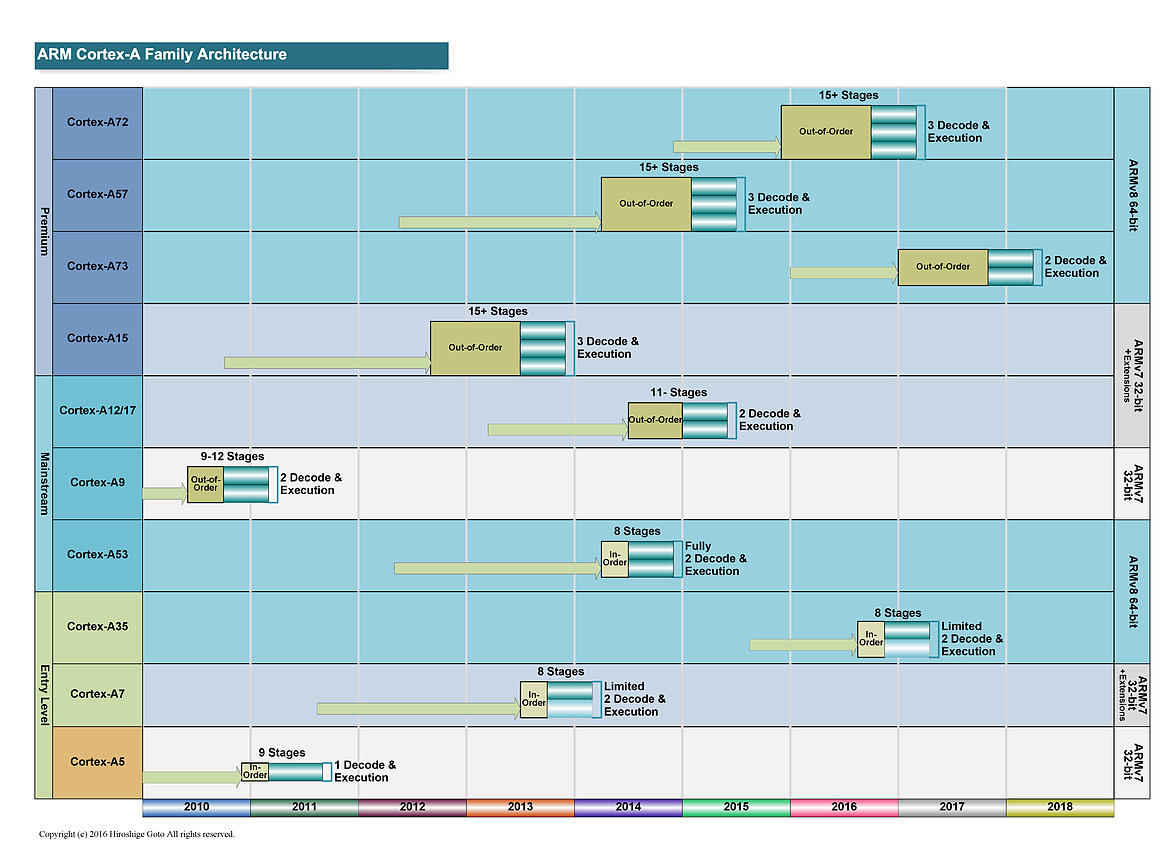
Les nomenclatures marketing d'ARM sont assez complexes à déchiffrer, la société dispose de plusieurs équipes qui font évoluer en parallèle des versions différentes de leurs architectures. Pour les "gros" coeurs, on retrouve deux familles distinctes avec d'un côté des "très gros" coeurs qui tendent à consommer significativement plus d'énergie. Ce sont les Cortex A15, A57 et A72 développés par l'équipe d'Austin. En parallèle, une autre équipe à Sophia-Antipolis développe des "gros" coeurs un peu plus efficaces comme les A12, A17 et plus récemment A73.
A l'origine, cette gamme était vue comme un intermédiaire par ARM même si la consommation élevée des "très gros" coeurs tend la société à pousser aujourd'hui les coeurs "Sophia" sur le haut de gamme mobile. Cette tendance se confirme aujourd'hui puisque l'A75 est en pratique le successeur de l'A73.
Techniquement ces puces se distinguent par un pipeline plus court, et sur ce point l'A75 ne change rien en gardant un pipeline court de 11 étapes pour les instructions entières. Le plus gros changement concerne le nombre d'instructions décodées par cycle puisque l'on passe de deux instructions décodées à trois, alignant sur cette caractéristique l'A75 avec ce qui se faisait sur les "très gros" ARM. On passe donc en pratique de 6 micro-ops par cycle à 8. Le nombre d'unités reste identique mais l'A75 ajoute des files supplémentaires pour stocker les micro-ops à traiter.
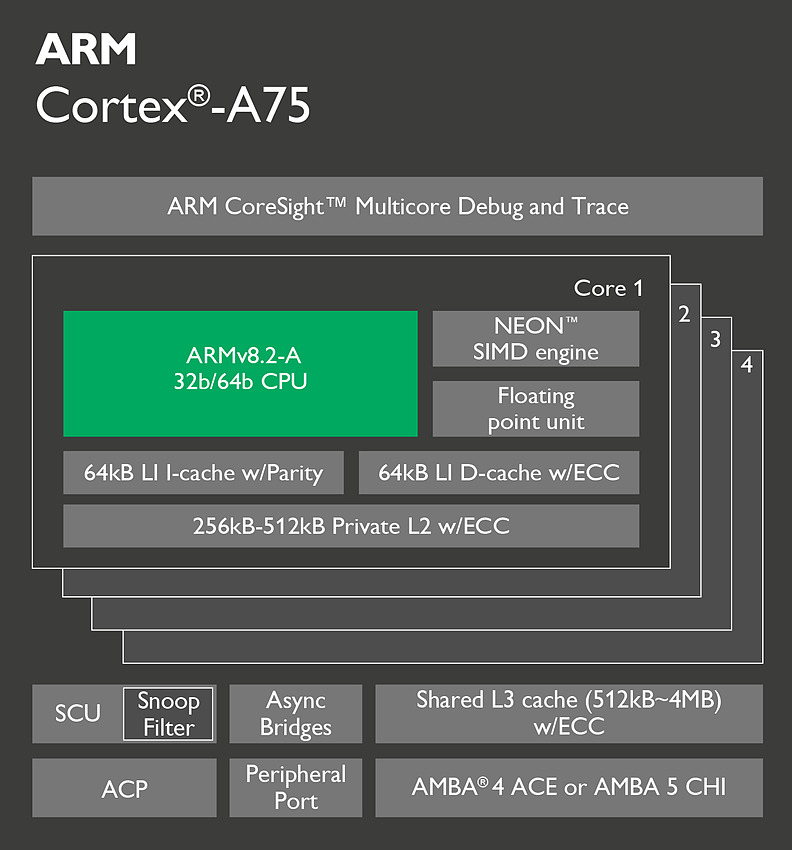
ARM applique un changement similaire pour les instructions flottantes et vectorielles (on parle de NEON dans le marketing ARM, le pendant de SSE/AVX sur x86) avec là aussi la possibilité de décoder trois instructions par cycle. Cela s'accompagne par une file supplémentaire et une troisième unité NEON spécifiquement utilisée pour les accès mémoire.
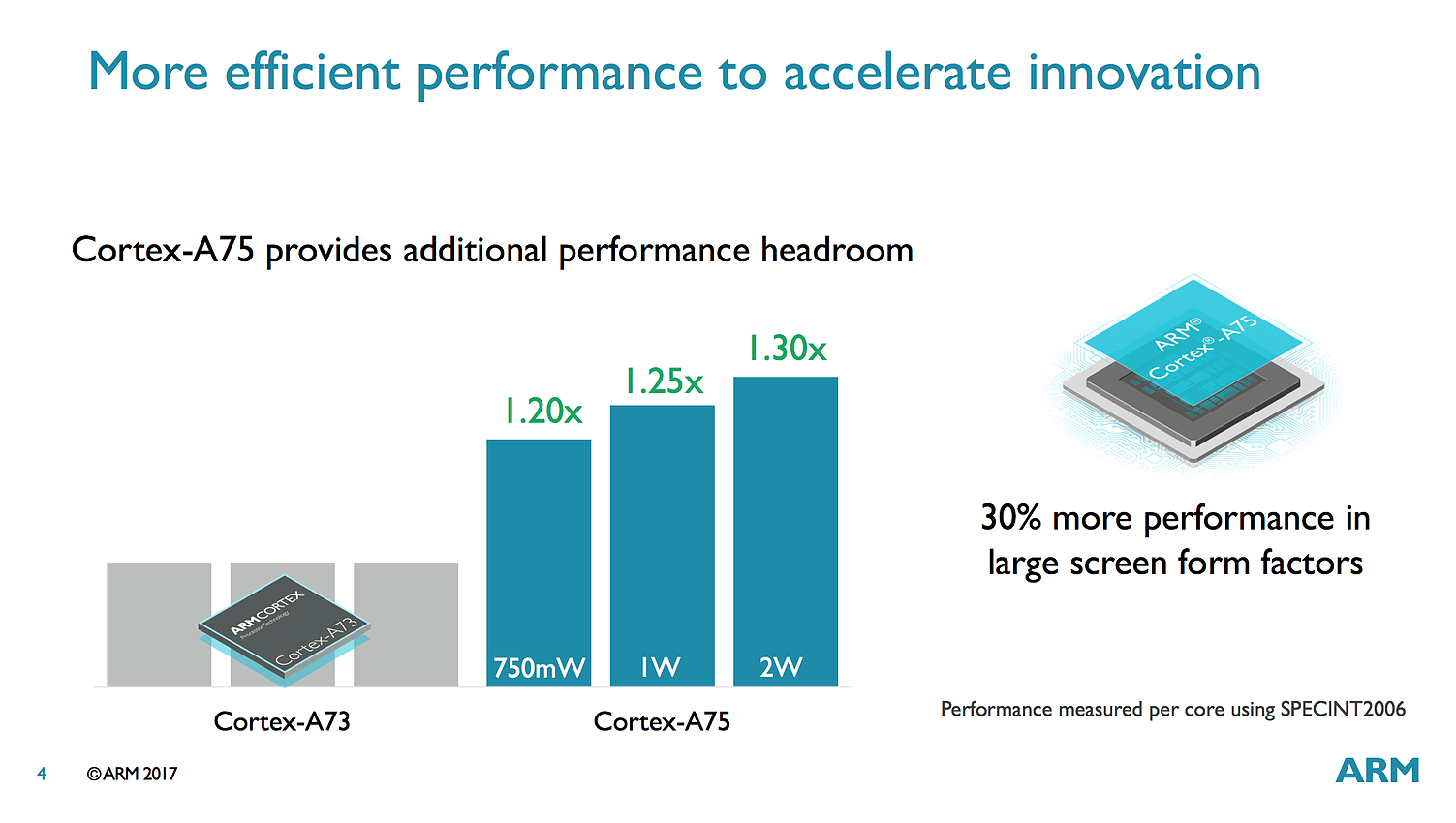
ARM annonce des gains de performance allant de 20 à 30% pour l'A75 rapport à l'A73 en fonction de la consommation autorisée, ce qui est plutôt intéressant. L'A75 est un bloc qui comme l'A73 est prévu pour le 10nm et il devrait faire son apparition en toute fin d'année ou plus probablement l'année prochaine dans des produits commerciaux.
Un nouveau coeur LITTLE
En plus des gros coeurs dont nous vous parlions au-dessus, ARM propose également des coeurs plus petits, à la consommation beaucoup plus faible et qui ont pour but d'être appairés à des gros coeurs dans ce qu'ARM appelait jusqu'ici des configurations big.LITTLE. Après avoir utilisé dans ce rôle l'A53 depuis plusieurs années (il avait été introduit en 2012 !), ARM propose enfin une nouvelle mouture de son petit coeur baptisée Cortex-A55.
Il s'agit toujours d'un coeur dit "In Order", les instructions ont exécutées dans l'ordre dans lequel elles arrivent (à l'opposé des processeurs plus gros/modernes qui utilisent des architectures "Out Of Order", les instructions sont réordonnancées pour optimiser l'exécution et améliorer le parallélisme).
Il y a assez peu de changements sur l'A55, le plus gros concerne la séparation des unités de lecture/écriture mémoire ainsi qu'un nouveau prédicteur de branchements. Le reste des changements se situant au niveau des caches mémoires qui ont été reconfigurés.
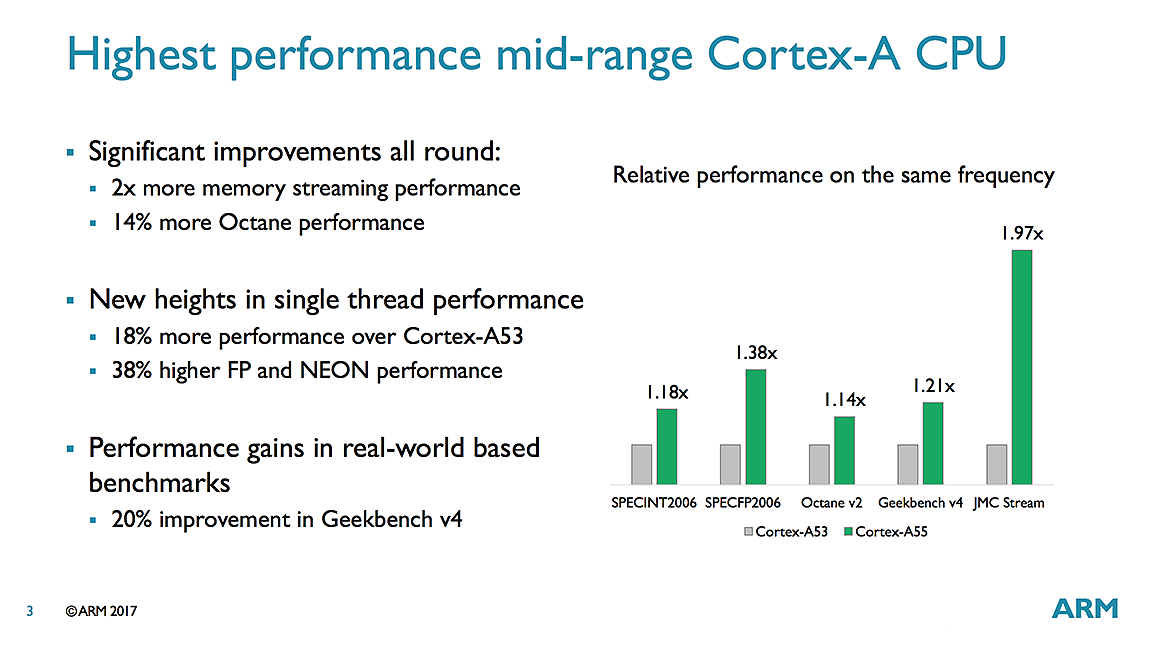
ARM annonce des gains de performances autour de 20% sur l'A55 à fréquence égale par rapport à un A53, des gains qui peuvent cependant monter beaucoup plus haut quand on prend en compte les caches. Sous SPECFP2006, la société annonce ainsi 38% de gains.
DynamIQ, big.LITTLE V2.0
Le concept du big.LITTLE évolue et prend désormais le nom de DynamIQ. ARM a repensé la manière dont il permettait de relier ses coeurs entre eux et propose un nouveau concept qui résout beaucoup de problèmes sur le papier.

L'idée principale est de remplacer big.LITTLE par des "clusters" qui peuvent regrouper jusque huit coeurs. On pourra mélanger au sein d'un cluster différents types de coeurs (par exemple quatre A75 et quatre A55) ce qui engendre un changement important au niveau de la structure des caches. Désormais, chaque coeur ARM (A55 ou A75) disposera de son propre cache L1 et de son propre cache L2. Ce changement est bienvenu et devrait éviter ces bugs embarrassants comme celui de Samsung et de son M1 qui mélangeait ses coeurs à des A53 avec des lignes de caches différentes.
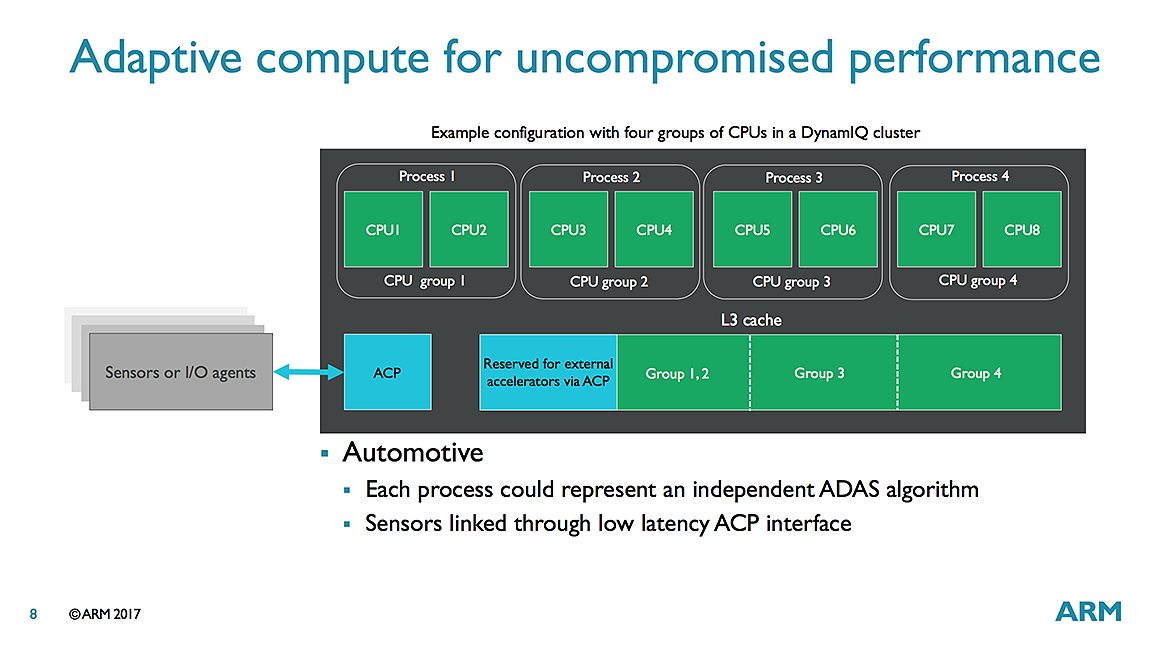
Tous les coeurs d'un cluster partageront un cache L3 commun (jusque 4 Mo) et l'on pourra disposer de plusieurs clusters - jusque 32 - au sein d'une puce (quelque chose qui devrait surtout servir pour d'éventuelles versions serveurs de ces processeurs). Une organisation qui n'est pas sans rappeler celle utilisée par AMD avec ses CCX dans Ryzen, on notera qu'ARM indique que son cache L3 peut être partitionné dynamiquement pour certains coeurs ou pour d'autres applications.
En bref
On notera également côté GPU l'arrivée une version optimisée du Mali G71, baptisé G72 pour lequel il n'y a pas de changement majeur au niveau de l'architecture Bifrost d'ARM. L'augmentation de la taille des caches permet d'augmenter l'efficacité énergétique ce qui est appréciable.
Si les modifications effectuées sur les Cortex A75 et A55 sont intéressantes, on retiendra surtout de l'annonce d'ARM l'arrivée de DynamIQ qui devrait permettre de mieux exploiter les coeurs. Car si big.LITTLE était sur le papier une bonne idée, son implémentation pratique avait montré de multiples limites. Cette nouvelle approche sous la forme de clusters contribue aussi sur les gains de performances, tout comme la réorganisation des caches.
Le sous-système mémoire des Cortex a toujours été la faiblesse de l'architecture avec des contrôleurs extrêmement optimisées pour la basse consommation, mais pas forcément pour les performances ce qui donne aux architectures ARMv8 tierces (comme celles d'Apple et même de Samsung) un avantage en général très net sur ce point.
Le 10nm de TSMC est bien à l'heure
Il y a quelques jours de cela, le site Digitimes avait fait circuler une rumeur par laquelle TSMC et Samsung disposeraient de yields trop bas pour leur production 10nm. De quoi lancer multiples spéculations sur des retards de production.

Pour rappel, TSMC et Samsung ont annoncé avoir commencé la production en volume (des puces qui se retrouveront donc dans des produits commerciaux) de leurs nouveaux process 10nm au quatrième trimestre.
Pour tenter de couper l'herbe sous le pied des rumeurs, TSMC a confirmé une fois de plus au Taipei Times que non seulement la production avait bien commencé au quatrième trimestre, mais que le 10nm générerait des revenus pour TSMC dès le mois prochain - ce qui signifie en pratique que TSMC aura livré des puces à ses clients.
Sur la question des clients, Digitimes avait spéculé qu'en plus d'Apple (client traditionnel en début de disponibilité de node pour TSMC), MediaTek et HiSilicon seraient parmi les premiers clients 10nm de TSMC. Des informations plutôt surprenantes pour les deux sociétés qui produisent (en grand volume) des SoC ARM à prix réduit, utilisant les blocs d'IP génériques (les "Cortex-A") dessinés par ARM.
 Qualcomm, l'autre client habituel des débuts de nodes chez TSMC aurait cette fois ci misé sur Samsung pour le 10nm. Samsung n'a pas réagit aux rumeurs lancées par Digitimes. On notera cependant qu'il y a quelques semaines de cela, Samsung avait évoqué l'idée de mieux séparer ses activités. En effet, la marque coréenne entre assez régulièrement en conflit d'intérêts avec les éventuels clients de son activité "fabrication". Une situation que l'on a vue à de nombreuses reprises avec Apple par exemple.
Qualcomm, l'autre client habituel des débuts de nodes chez TSMC aurait cette fois ci misé sur Samsung pour le 10nm. Samsung n'a pas réagit aux rumeurs lancées par Digitimes. On notera cependant qu'il y a quelques semaines de cela, Samsung avait évoqué l'idée de mieux séparer ses activités. En effet, la marque coréenne entre assez régulièrement en conflit d'intérêts avec les éventuels clients de son activité "fabrication". Une situation que l'on a vue à de nombreuses reprises avec Apple par exemple.
Une restructuration qui séparerait les équipes de design de puces utilisées par Samsung (LSI et SoC) de l'activité "fab" serait donc envisagée selon nos confrères de Business Korea . Une séparation qui servirait surtout à rassurer d'éventuels clients car en pratique Samsung ne compte pas se séparer de son activité "fab".
10/7nm en avance pour TSMC, EUV pour le 5nm
TSMC vient de publier ses résultats financiers pour le troisième trimestre. Le fondeur taiwannais enregistre une hausse séquentielle de 17% (+22% par rapport à la même période sur 2015), au dessus de ses prévisions. Des bons chiffres qui s'expliquent selon TSMC par une forte demande sur le marché des smartphones.
Ramenés par process, le 16/20nm représente 31% des revenus de la société (contre 23% le trimestre précédent). Le 28nm voit sa part baisser à 24% des revenus, mais TSMC confirme que ses usines restent "pleinement utilisées".
En ce qui concerne les prochains nodes, TSMC a confirmé les informations publiées un peu plus tôt, à savoir l'avance prise par les process 10 et 7nm.
Le 10nm entre en production ce trimestre et les premiers produits finaux seront livrés au premier trimestre 2017. Ce node ne sera pour rappel utilisé que par les très gros clients de TSMC, à savoir Apple et possiblement Qualcomm. Les autres clients attendront le 7nm. La montée des yields est décrite comme "similaire" à celle du 16nm même si "techniquement plus difficile".
Le 7nm entrera en production "risque" au premier trimestre 2017 et TSMC s'empresse d'indiquer qu'il sera utilisé non seulement pour les smartphones, mais aussi pour des GPU, des puces serveurs, et des "PC et tablettes". TSMC décrit des tapeout aggressifs qui commenceront au début du second trimestre. 15 produits devraient être qualifiés en 2017.

La fondeur a également évoqué le 5nm, qui a quitté le stade de la recherche pure pour entrer dans une phase de développement. Et TSMC confirme qu'ils utiliseront de manière "extensive" la lithographie EUV. Cette dernière aurait fait des progrès sur tous les plans, que ce soit en fiabilité, ou sur les problèmes techniques complexes (masques, photo resist, etc). La production "risque" reste prévue pour la première moitié de 2019 (la production volume suit en général de 3 à 4 trimestres).
Lors de la présentation des résultats aux analystes financiers, le CEO de TSMC, Mark Liu, a réitéré une fois de plus voir "l'informatique haute performance" comme un marché sur lequel TSMC espère voir une progression de ses ventes. Les serveurs et les PC clients sont mis en avant, et on a du mal a ne pas y voir un lien avec les annonces d'AMD sur sa renégociation du contrat WSA qui les lie à GlobalFoundries.
Dans la séance de questions/réponses posées, on notera qu'a la question de savoir si la prise de licence ARM par Intel est un risque, Mark Liu estime surtout que cela renforce le rôle d'ARM, tout en ne négligeant pas le rôle qu'Intel pourrait jouer. Reste que sur ce trimestre, la part de marché de TSMC chez les fondeurs (hors activité propre comme Intel pour ses propres puces donc) était de 55%.
Intel Custom Foundry prend une licence ARM !
 ARM l'a confirmé par un post de blog : Intel Custom Foundry, l'activité fabrication tiers d'Intel, est désormais détentrice d'une licence ARM Artisan pour le 10nm !
ARM l'a confirmé par un post de blog : Intel Custom Foundry, l'activité fabrication tiers d'Intel, est désormais détentrice d'une licence ARM Artisan pour le 10nm !
Il faut rappeler qu'Intel est plutôt un cas à part dans le monde des semi-conducteurs, étant l'une des rares sociétés à disposer de ses propres usines, utilisées quasi uniquement pour la production de ses propres puces. La plupart des autres acteurs du marché ont migré vers la séparation de l'activité design d'un côté (on parle de sociétés fabless, c'est le cas dans le monde du GPU avec AMD et Nvidia), et de l'autre la fabrication dans des sociétés tierces spécialisées (on parle de foundry, la plus connue étant TSMC qui fabrique des puces pour de multiples clients).
Avec la difficulté de la mise au point des nouveaux process de fabrication, qui n'a fait qu'empirer ces dernières années, il est de plus en plus complexe pour une société à elle seule de justifier l'investissement nécessaire pour faire évoluer sans cesse ses usines. Qui plus est, la réduction de la taille des transistors fait que la capacité des usines augmente d'année en année, et qu'il faut disposer de très larges volumes de puces à produire, au risque de voir ses usines tourner à vide.
Un casse tête qui aura poussé plusieurs sociétés à se séparer de leurs usines (pour des raisons différentes) d'abord AMD en 2009 (créant GlobalFoundries) et plus récemment IBM (dont l'activité fabrication à été rachetée elle aussi par GlobalFoundries).
Depuis quelques années, en plus de fabriquer ses propres puces dans ses usines, Intel a décidé d'entrer très timidement, en 2010, sur le marché des fondeurs tiers en ouvrant son process à de petites sociétés qui n'étaient pas en concurrence directe avec ses produits (le premier client était Achronix, designer de FPGA en 22nm). D'autres clients ont suivi, principalement sur les FPGA, le client le plus connu d'Intel ayant été Altera... même si au final Intel aura décidé de racheter son client à la mi-2015 !
Pour Intel, la nécessité d'ouvrir ses usines est un casse tête. D'un côté, la société tente d'être présent sur tout les marchés, en déclinant le x86 - technologie "maison" sur laquelle la concurrence est limitée - à toutes les sauces et avec un soupçon de recyclage, que ce soit avec des produits serveurs spécialisés comme les Xeon Phi basés sur des Pentium pour leur première génération, ou les Quark dédiés à l'embarqué et utilisant une architecture de 486 datant d'une bonne vingtaine d'années !
Si l'envie de la société d'être présente sur tous les marchés est là, en pratique les succès ne sont pas systématiquement au rendez vous, Intel ayant par exemple massivement raté le marché des smartphones. Cumulé à la baisse continue des ventes sur le marché historique des PC, l'ouverture des usines à des clients tiers se dessine de plus en plus comme une nécessité pour Intel, même si l'avouer semble impossible à la société, qui continuait donc d'envoyer des signaux mitigés aux possibles futurs clients de son activité fabrication.
Avec l'annonce d'aujourd'hui, les choses sont - peut être - en train de changer puisque la prise de licence ARM par Intel est tout sauf anodine. Ce n'est pas la première fois qu'Intel fabriquera des SoC ARM, on l'avait vu avec Altera qui utilisait un core ARM dans un usage très spécifique.
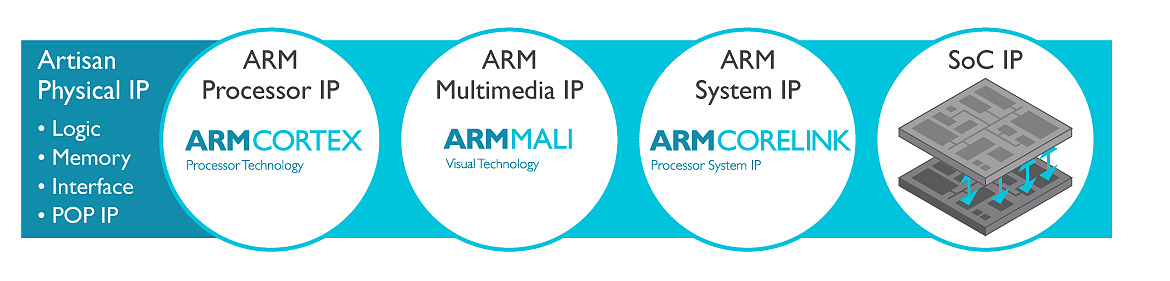
La licence Artisan Physical IP inclut en effet toutes les briques nécessaires pour la création de puces ARM de tout types. Il s'agit de tous les blocs de base avec des bibliothèques haute densité et haute performance de transistors logiques,et également tout le nécessaire pour les différents types de mémoire. La licence inclut surtout POP IP, qui est pour rappel l'idée qui fait le succès d'ARM : permettre l'utilisation de blocs interchangeables et compatibles pour créer des puces custom. Ainsi un client peut choisir d'utiliser des coeurs CPU dessinés par ARM (les gammes Cortex) ou créer ses propres coeurs (c'est le cas d'Apple et plus récemment de Nvidia), de choisir un GPU (que ce soit les Mali d'ARM, ou les populaires PowerVR d'Imagination Technologies), et également de choisir son fournisseur pour les interconnexions.
Concrètement, Intel va donc "porter" ces bibliothèques d'ARM aux particularités de son futur process 10 nm, ce qui permettra aux partenaires d'ARM de porter à leur tour - s'ils le souhaitent - leurs blocs POP IP. ARM et Intel travailleront conjointement pour le portage de deux futurs blocs CPU ARM Cortex-A (probablement un autre successeur 10nm de l'A72, voir l'annonce de l'A73 en 10nm lui aussi), la déclinaison que l'on retrouve dans les smartphones et tablettes.
Faut il y voir un virage pour Intel ? Fabriquer des puces ARM pour smartphones, ce qu'ils feront pour LG (nouveau client annoncé dans la foulée) va forcément à l'encontre des ambitions internes d'Intel d'imposer le x86 sur mobile. Car si un peu plus tôt dans l'année Intel avait décidé d'annuler sa nouvelle génération de SoC pour smartphones (Broxton et SoFIA), le constructeur continuait en interne à travailler sur les générations suivantes tout en essayant de développer dans l'intérim son activité modem (Intel aurait possiblement gagné le marché du modem du prochain iPhone). A l'heure où ARM augmente ses ambitions pour aller attaquer le marché juteux des serveurs, on peut se demander jusqu'où ira réellement l'ouverture d'Intel.

Un futur CPU ARMv8 24 coeurs de Qualcomm
En fabriquant des puces concurrentes, Intel s'ouvre à des comparaisons directes qui pourraient être assez défavorables à ses architectures x86, assez peu adaptées à la basse consommation. L'avantage supposé du process d'Intel, s'il existe, ne pourra plus jouer en la faveur de ses propres solutions pour compenser un éventuel déficit architectural. La structure de marges d'Intel, là aussi très différente de celle des fondeurs tiers, posera là aussi rapidement problème.
Qui plus est, en obtenant la licence Artisan d'ARM, Intel va devoir partager tous les détails techniques, y compris les plus secrets, de son process en ce qui concerne les règles et les dimensions exactes des transistors, ce qui va l'exposer là aussi à une comparaison directe avec les autres acteurs installés du milieu (comme TSMC et Samsung). Il faudra un peu de temps pour mesurer les conséquences concrètes de tout cela, car cet accord ne concerne que le 10nm, un process pour rappel en retard et qui n'est prévu chez Intel que pour la fin de l'année 2017 en version mobile. Les dernières nouvelles du 10nm, sur lequel Intel ne communique pas, n'étaient pour rappel pas particulièrement rassurantes avec l'arrivée possible sur sa roadmap de puces 14nm... pour 2018.
ARM annonce le Cortex-A73 et le Mali-G71
ARM vient d'annoncer de nouveaux blocs disponibles pour ses partenaires. Pour rappel, ARM développe en parallèle des architectures (ARMv8-A pour la dernière version 64 bits, le pendant du x86-64 dans le monde du PC) et propose aussi ses propres implémentations de coeurs qui peuvent être utilisés par ses partenaires sous licence (l'équivalent dans le monde PC serait Intel qui autorise ses partenaires à faire des versions "custom" de Skylake).
Certains des partenaires d'ARM disposent d'une licence dite "architecture" (Apple, Qualcomm, Samsung, Nvidia...) qui leur permet de réaliser leurs propres implémentations (de la même manière qu'AMD et Intel proposent des processeurs compatibles, mais différents derrière la même architecture x86-64), même si ces derniers proposent parfois les deux. Qualcomm propose par exemple des puces utilisant les Cortex (implémentation ARM) et ses propres Snapdragon.
La nomenclature des implémentations d'ARM a toujours été compliquée à comprendre, pour ne pas dire autre chose, et autant dire qu'aujourd'hui ARM n'arrange pas son cas avec l'A73. Il fait suite sur le papier au Cortex-A72 qui avait été annoncé en février 2015 même si d'un point de vue technique les puces sont différentes.
Ce diagramme permet d'y voir un tout petit peu plus clair. Après l'époque "simple" de l'A9, ARM a proposé d'un côté des cores de grande taille, visant les hautes performances (A15, A57 et A72), également appelés big. Il s'agit de designs "Out of Order" (le processeur peut changer l'ordre des instructions pour optimiser leur exécution).
En parallèle des coeurs de plus petite tailles ont été présentés (les coeurs LITTLE comme l'A7 et l'A53). Ils utilisent un design dit "In Order" (pas de changement d'ordre) qui simplifie l'implémentation, et réduit donc la consommation de la puce. Leur niveau de performance est plus bas, mais ils disposent d'un meilleur rapport performance/watts que les coeurs big. Leur intérêt théorique est de les mélanger pour créer une architecture asymétrique (big.LITTLE, voir la présentation ici) même si en pratique, ce n'est pas toujours ce qui s'est passé.
Les deux familles sont développées par des équipes différentes (Austin pour les big et Cambridge pour les LITTLE) et au milieu de tout cela, on retrouvait les A12 et A17, mélangés sur ce graph (par une troisième équipe a Sophia-Antipolis). Il s'agissait là aussi de designs "Out of Order" mais un peu plus optimisés pour un meilleur rapport performances/watts.
Si en théorie ces puces étaient présentées comme dédiées au milieu de gamme, en pratique elles proposaient surtout une alternative aux gros coeurs ARM dont la consommation était trop élevée, obligeant de limiter fortement les fréquences pour rester dans l'enveloppe thermique d'un smartphone. On a pu voir un certain nombre de retards lors de la génération A57, particulièrement chez Qualcomm, et une surconsommation importante par rapport à ce qu'espérait ARM. Une situation qui a même poussé certains des partenaires d'ARM a proposer des puces n'utilisant que les coeurs LITTLE, un comble.
Cortex A73 : 10nm
Le Cortex A73 est présenté par ARM comme son nouveau coeur big. Il fait suite à l'A72 (16nm) et sera proposé pour les processus de fabrication 10nm. Mais contrairement à ses prédécesseurs big 64 bits (A57 et A72, c'est dur à suivre !), il s'agit sur le papier du successeur des A12/A17 (qui eux n'étaient disponibles qu'en 32 bits).
Contrairement aux A57/A72 qui pouvaient décoder trois instructions par cycle, on se limite cette fois ci à deux sur l'A73. En contrepartie, le pipeline (le nombre d'étapes par lequel les instructions passent) est significativement réduit, passant de 15 à 11 étapes. C'est au niveau du front end (récupération des instructions, décodage, changement d'ordre) que la réduction se fait. On retiendra deux changements importants, d'abord le fait que les instructions en virgules flottantes/NEON (l'équivalent des instructions vectorielles type SSE dans les architectures x86) soient traitées séparément via un décodeur distinct. La seconde est un changement au niveau des instructions arithmétiques entières avec des unités moins nombreuses mais plus performantes.



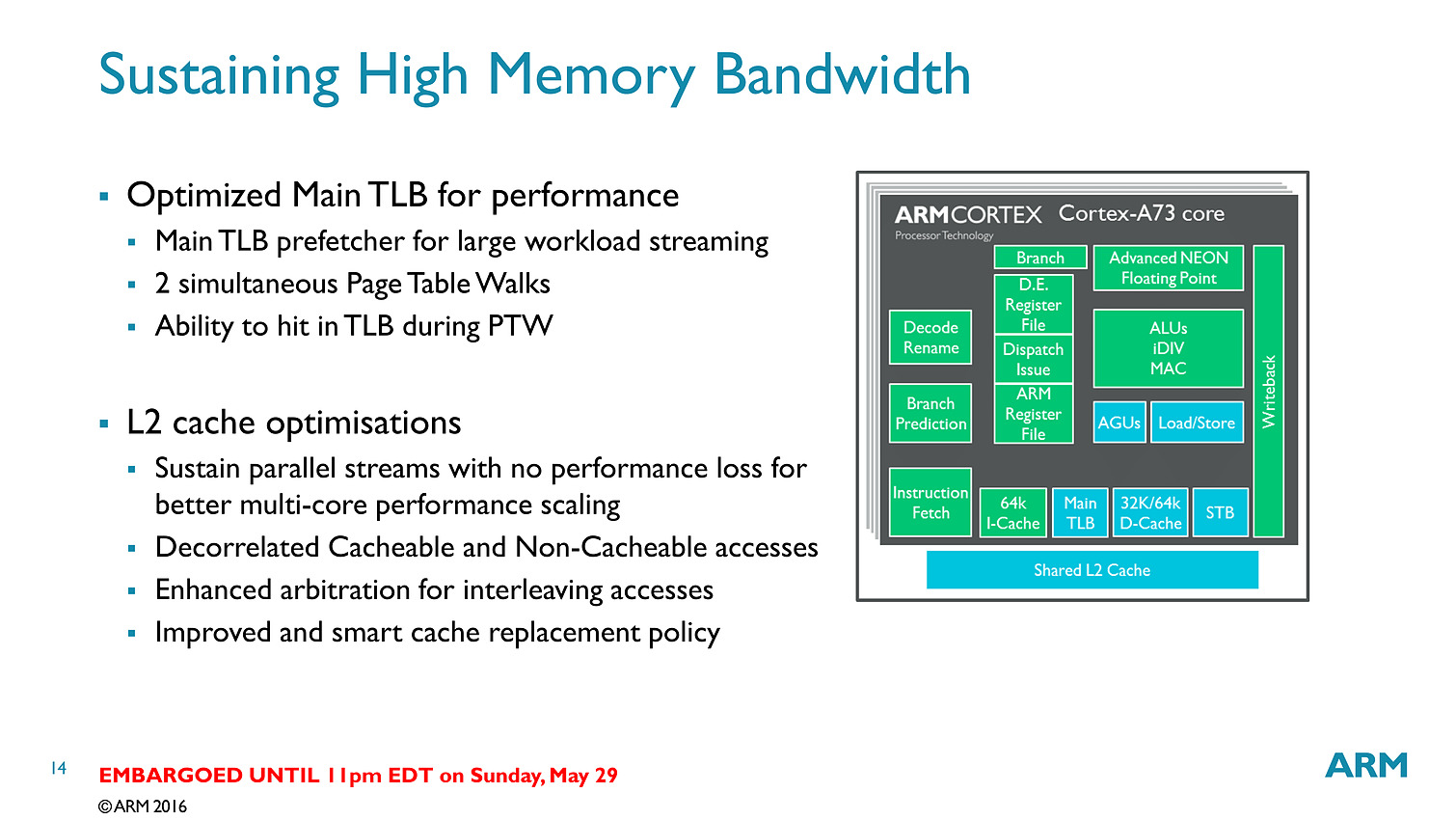
Bien que décodant une instruction par cycle en moins, l'A73 permet sur le papier au final de dispatcher 6 micro-instructions par cycle, contre 5 pour l'A72. Si l'on ajoute toutes les autres optimisations (le sous système mémoire, point faible historique des Cortex semble avoir évolué), l'A73 est annoncé comme 10% plus performant que l'A72, à fréquence/process égal.
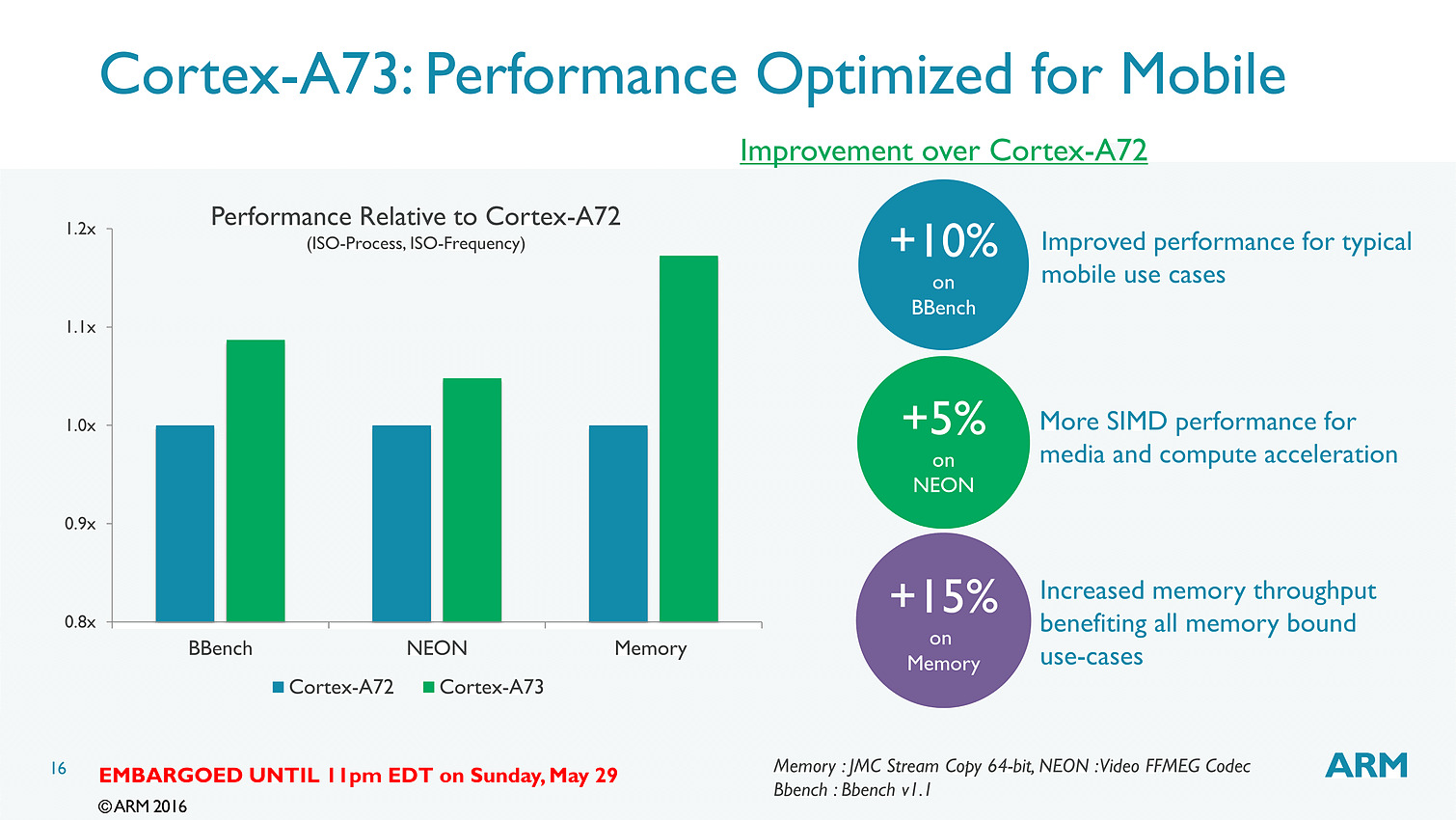
Dans le détail, ARM annonce plus spécifiquement 15% de gains sur les copies mémoire, et 5% sur un encodage FFMPEG utilisant les instructions vectorielles NEON. Notez qu'a process égal, un coeur A73 est 25% plus petit qu'un coeur A72 et consomme 20% d'énergie en moins. En 10nm, un coeur A73 ne mesure que 0.65mm2.
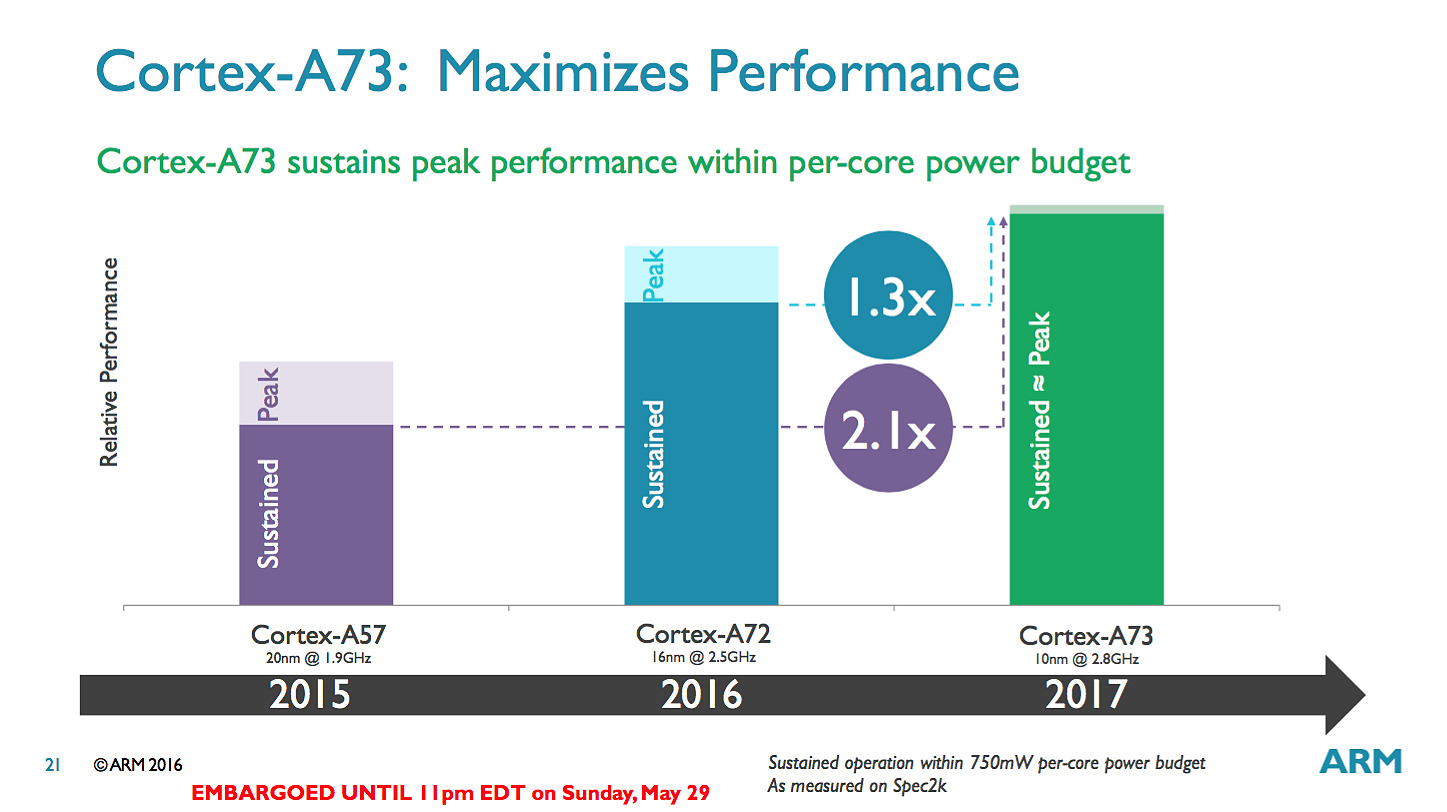
Pour les puces que l'on retrouvera dans le commerce, ARM annonce 30% de performances en plus par rapport aux A72 en profitant du 10nm et de la baisse de consommation pour augmenter la fréquence. Un autre gain significatif mis en avant par le constructeur est que ses puces ne devraient plus voir leur fréquence chuter drastiquement lorsque l'on utilise tous les coeurs en simultanée.
Sur le papier l'A73 est un meilleur compromis côté architecture que ses prédécesseurs, ce qui devrait ravir les partenaires d'ARM, assez peu heureux des A57. Si ARM vise le 10nm, en pratique il propose à ses partenaires des designs A73 en 28, 16 et 10nm. D'ici la fin de l'année, des SoC 16nm devraient faire leur apparition et c'est probablement là qu'on les trouvera en masse (le 10nm sera probablement, pour rappel, réservé au moins dans un premier temps aux gros acteurs du marché comme Qualcomm et Apple à l'image de ce que l'on avait vu avec le 20nm).
Mali-T71 et Bifrost
L'autre annonce d'ARM concerne les GPU. En plus de blocs CPU, ARM propose également à ses partenaires des blocs graphiques qu'ils peuvent utiliser ou non (d'autres sociétés comme Imagination Technologies proposent par exemple leur PowerVR) pour créer leurs SoC.
La nouvelle puce est baptisée T71 et vient faire suite aux GPU T800 dont nous vous avions parlé l'année dernière. Le changement de nomenclature annonce en réalité un changement d'architecture, on passe de l'architecture Midgard à la bien nommée Bifrost.
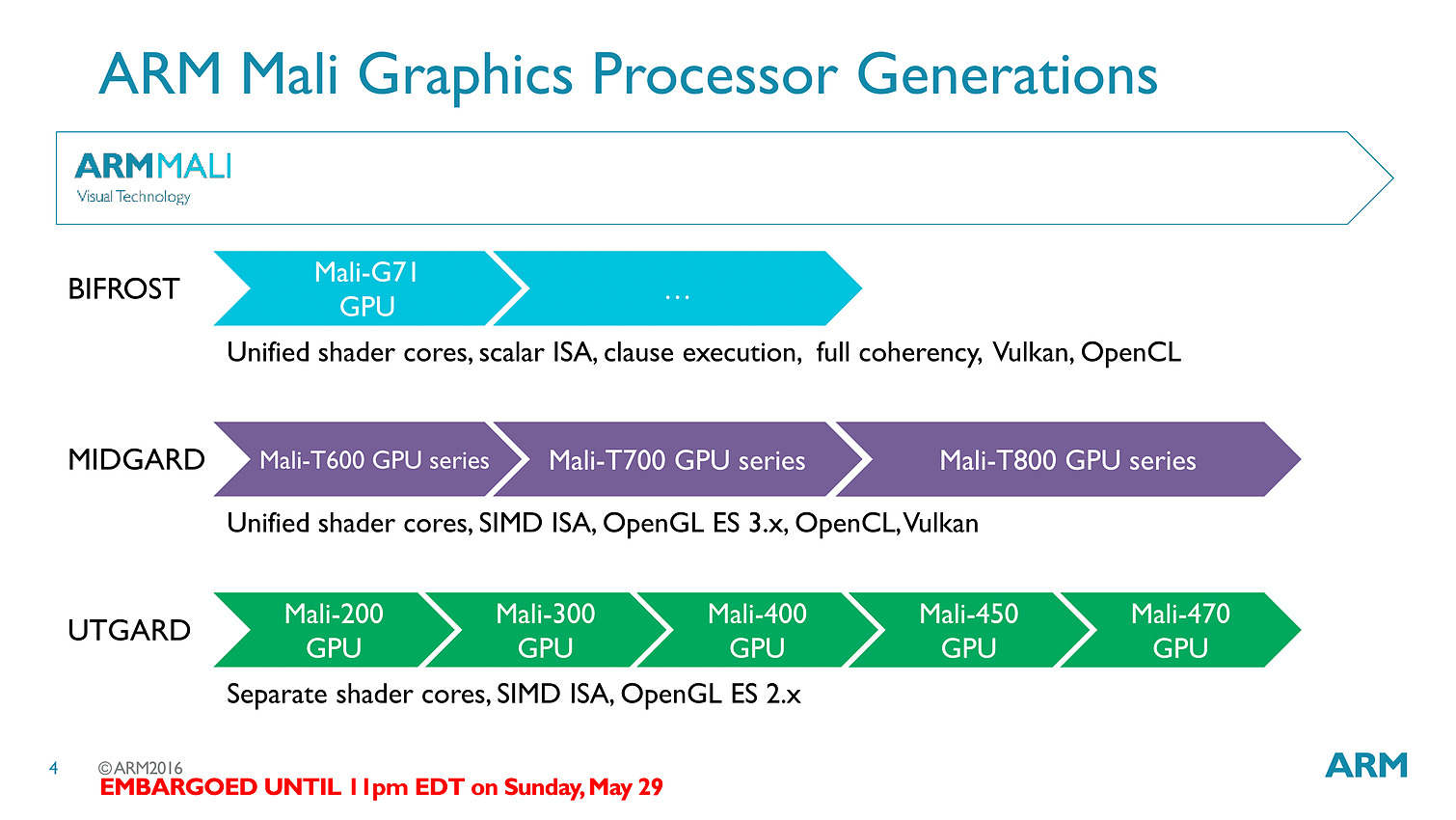
La transition est importante avec un changement complet de philosophie, passant d'un modèle VLIW (Very Long Instruction Word) à un modèle scalaire... soit exactement la transition qu'avait effectué AMD avec GCN !

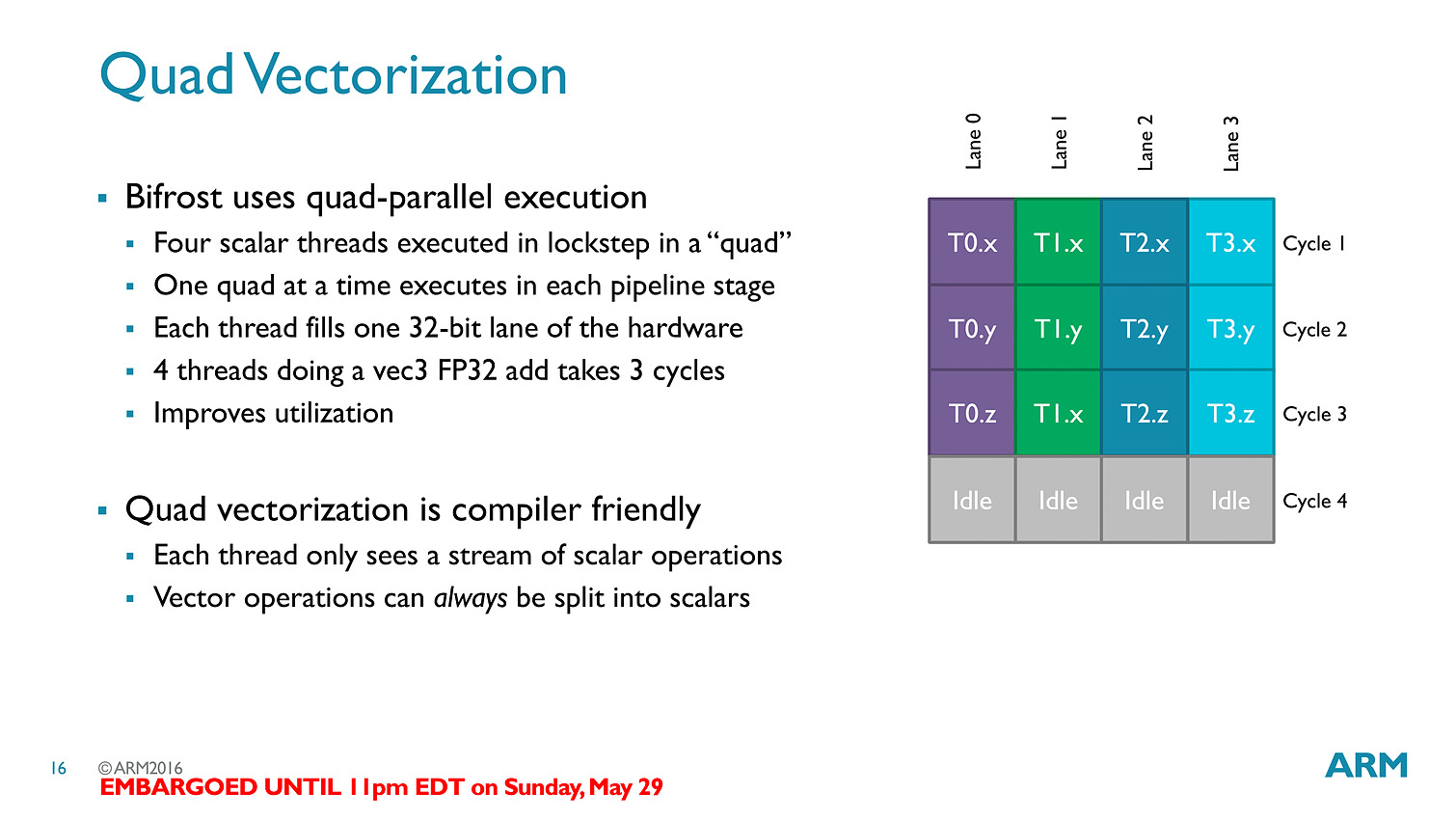
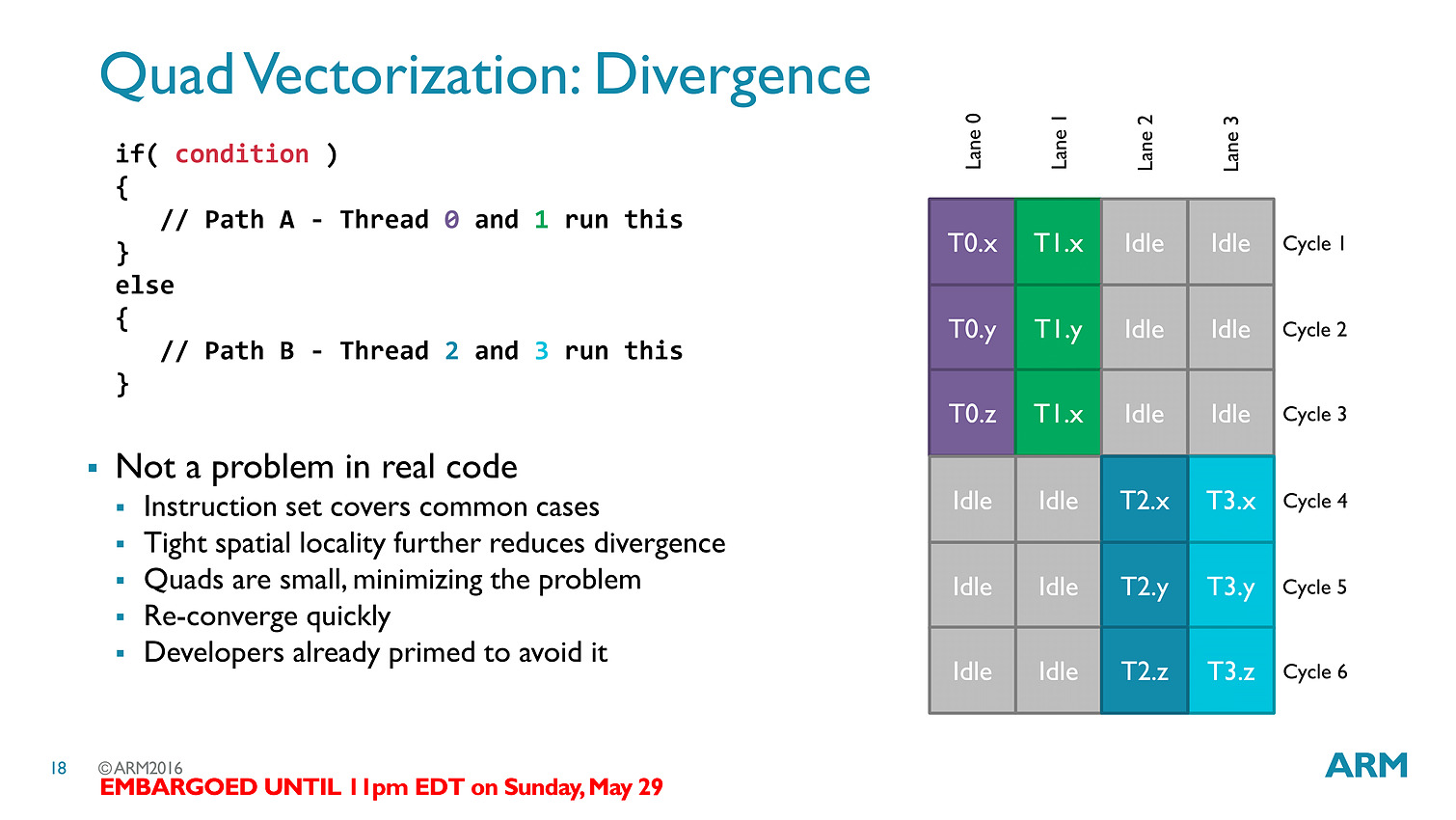
La transition aux unités scalaires change en pratique l'ordre dans lequel les données sont traitées, en simplifiant la compilation des shaders (le parallélisme étant extrait des threads, et non d'assemblage d'instructions par le compilateur).

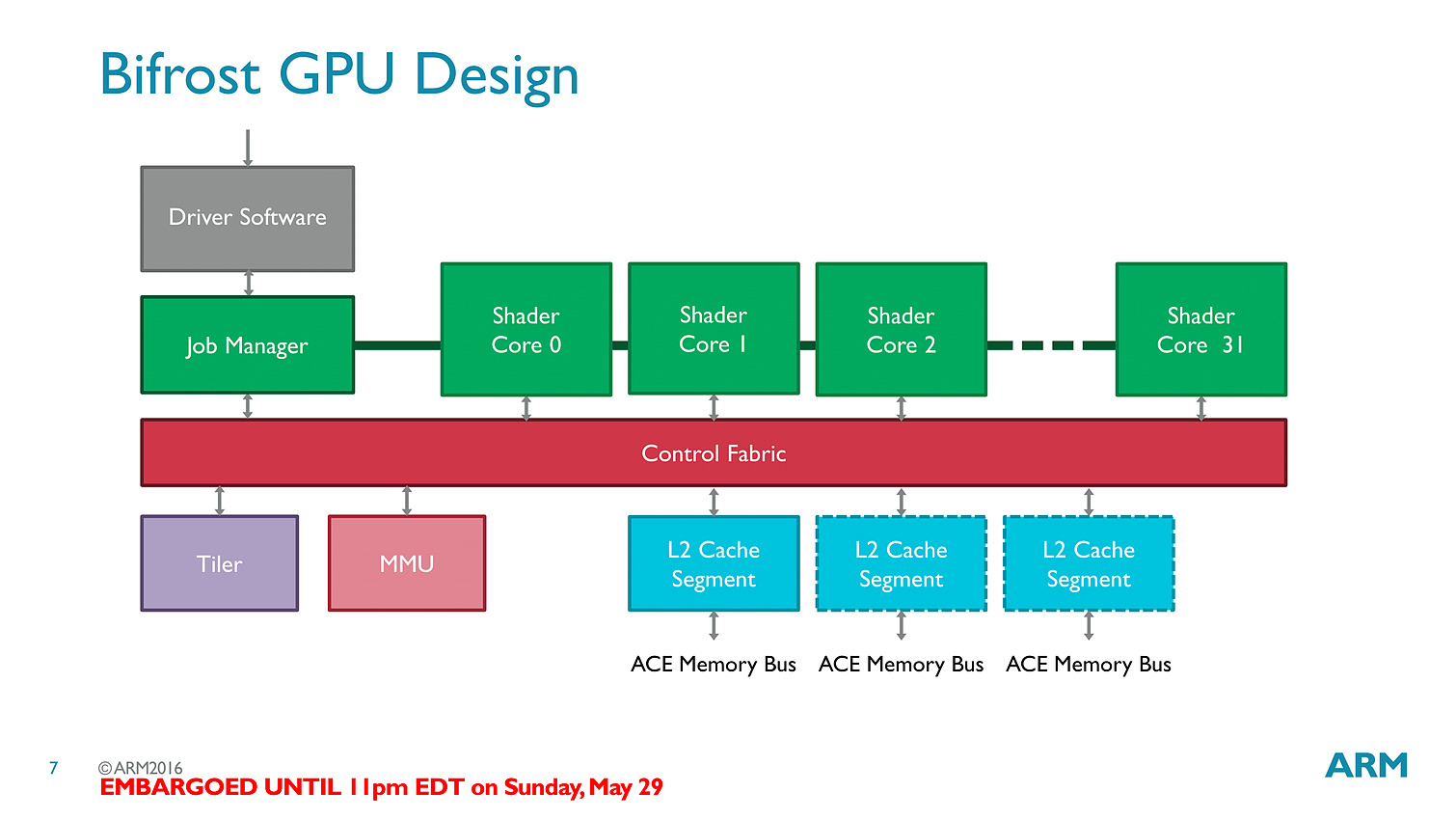
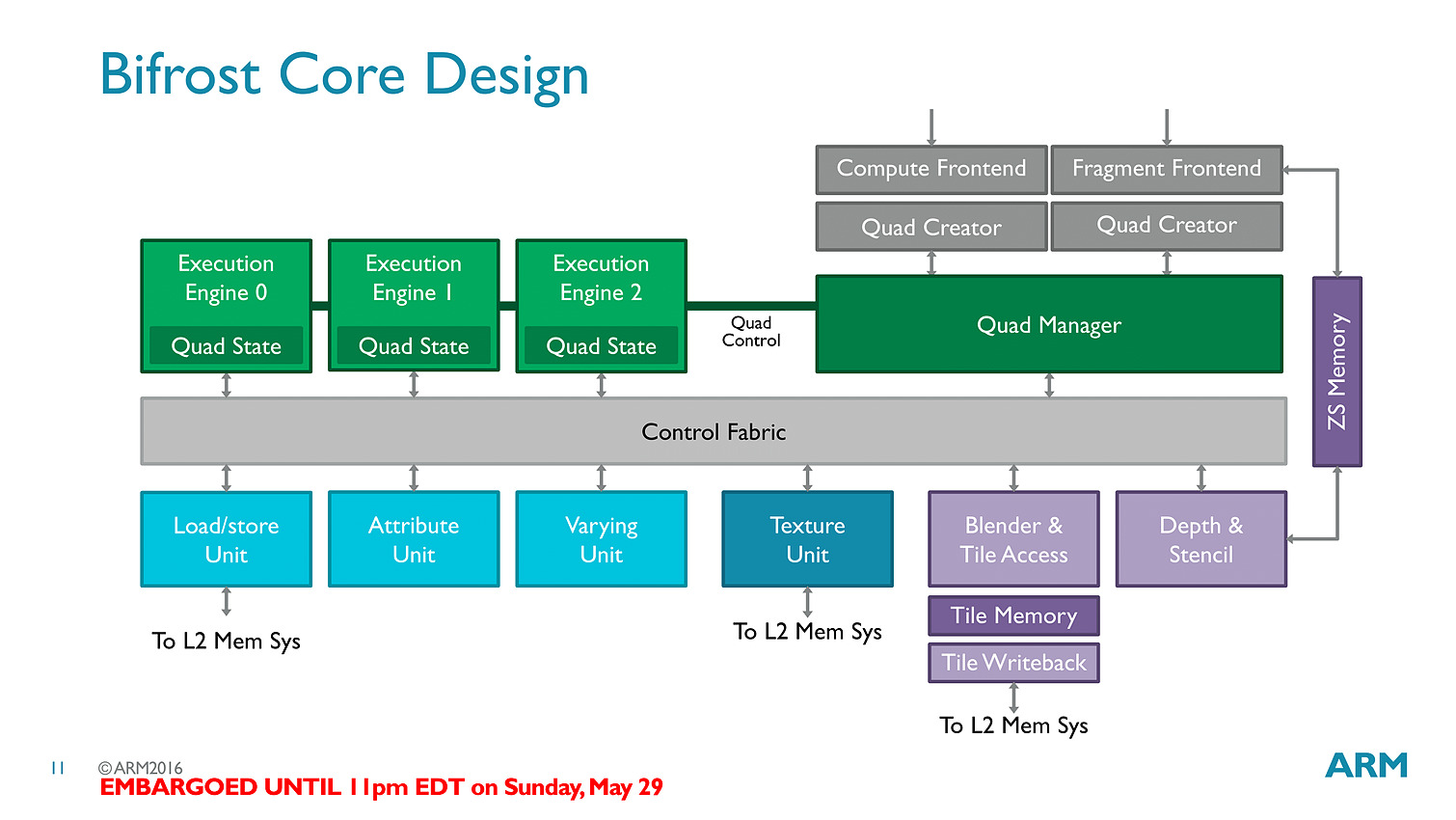
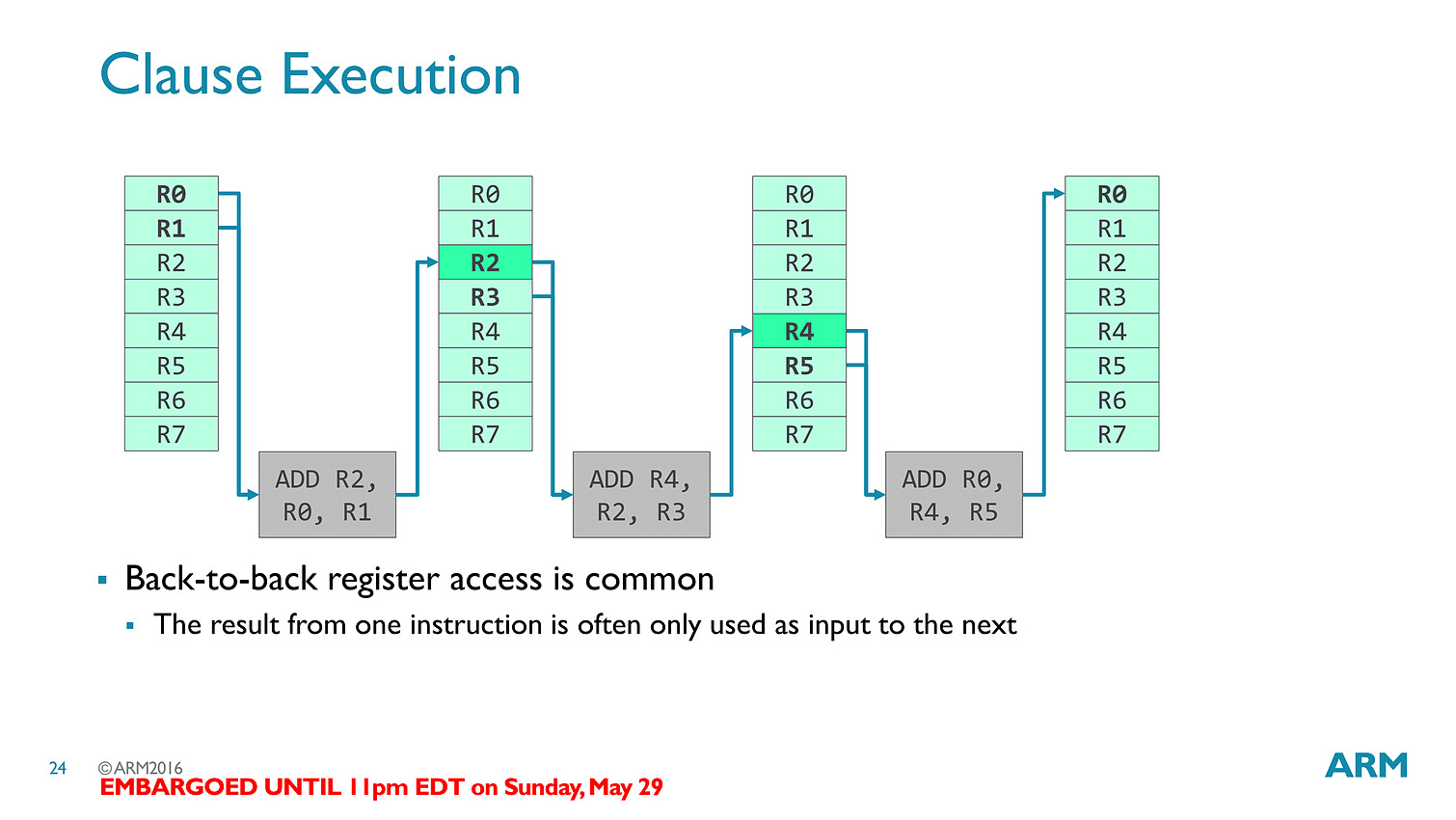
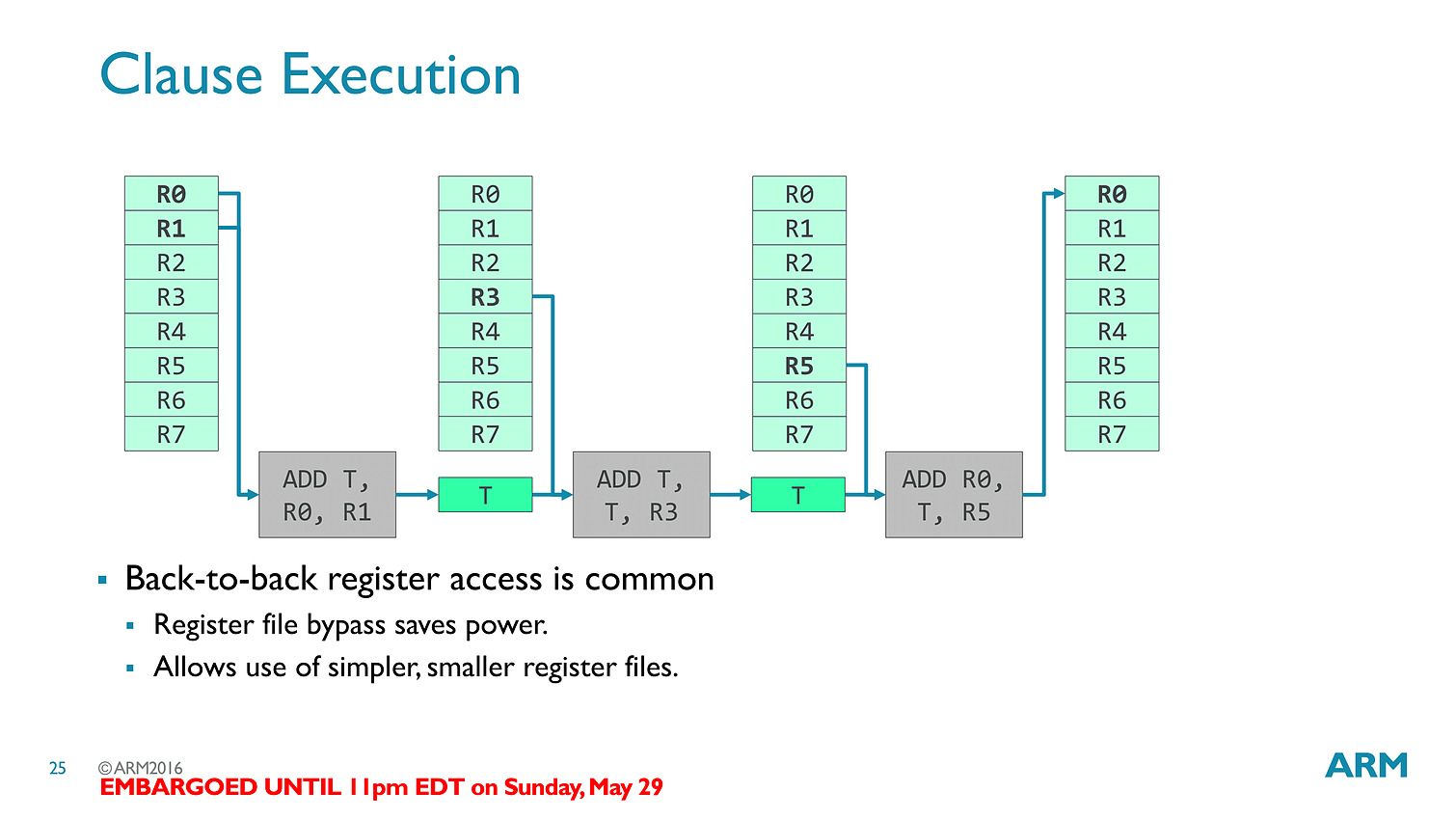

Les threads - clauses dans le langage ARM - sont particulièrement optimisées avec des caches a tous les niveaux (sous la forme de register file) pour s'assurer que les accès mémoires soient optimisés au mieux. Cumulé à tout les autres changements architecturaux (le tiler a également été modifié pour réduire sa consommation mémoire), ARM annonce 50% de gains de performances avec Bifrost.
En pratique le Mali-T71 est le premier GPU ARM utilisant Bifrost, il regroupera jusqu'à 32 shader cores (qui comptent chacun 12 unités scalaires) et reste compatible comme ses prédécesseurs avec OpenGL ES 3.x, OpenCL 2.0 et Vulkan. On rajoutera un dernier mot sur l'interconnexion puisque l'on a droit à un accès au cache fully coherent, ce qui signifie que CPU et GPU peuvent partager la même mémoire cache en opérant en parallèle sans blocage (à la manière de Kaveri chez AMD qui utilisait cependant deux bus distincts), ce qui pourra être utile pour des tâches compute ou l'on fait travailler de concert CPU et GPU (ce qui n'est pas forcément la majorité des usages sur les plateformes mobiles).