
Les derniers contenus liés au tag ARMv8
Afficher sous forme de : Titre | Flux24 curs ARMv8 en socket chez Qualcomm
ARM annonce Cortex-A72, Mali-T880 et CCI-500
CES: Nvidia Tegra X1: Maxwell + Cortex A57/53
AMD annonce son projet Skybridge et le K12
AMD annonce les Opteron ARM Seattle
ARM annonce les Cortex-A75, A55 et Mali G72
Hot Chips : M1, SVE, Parker, InFo et Skylake !
Nouvelle extension vectorielle ARMv8-A SVE
ARM annonce le Cortex-A73 et le Mali-G71
1er tape-out 10nm ARM chez TSMC
ARM annonce les Cortex-A75, A55 et Mali G72



ARM vient d'annoncer de nouveaux blocs processeurs pour ses partenaires, sous le nom de Cortex-A75 et A55 (pour un rappel sur la stratégie d'ARM, nous vous renvoyons au début de cet article). Ces nouveaux Cortex sont des coeurs CPU clefs en main qui peuvent être utilisés par les partenaires d'ARM pour concevoir leurs SoC.
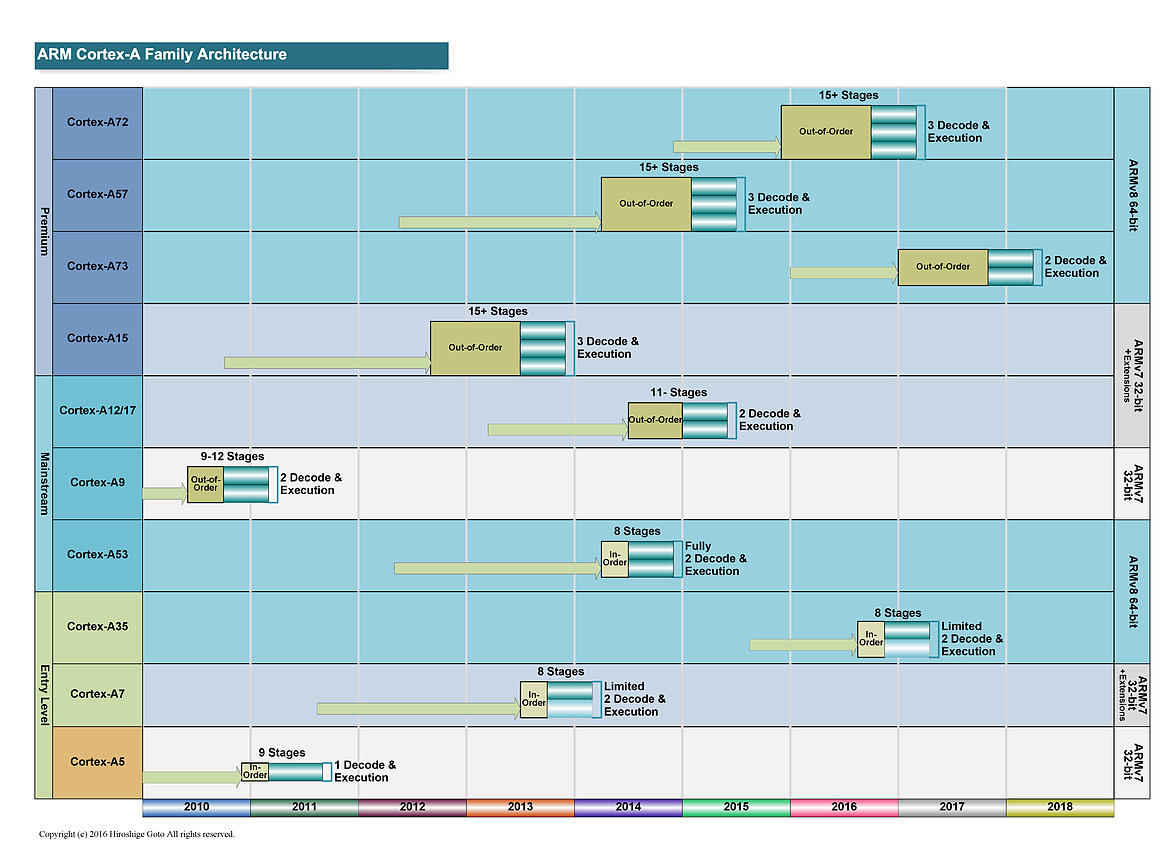
Les nomenclatures marketing d'ARM sont assez complexes à déchiffrer, la société dispose de plusieurs équipes qui font évoluer en parallèle des versions différentes de leurs architectures. Pour les "gros" coeurs, on retrouve deux familles distinctes avec d'un côté des "très gros" coeurs qui tendent à consommer significativement plus d'énergie. Ce sont les Cortex A15, A57 et A72 développés par l'équipe d'Austin. En parallèle, une autre équipe à Sophia-Antipolis développe des "gros" coeurs un peu plus efficaces comme les A12, A17 et plus récemment A73.
A l'origine, cette gamme était vue comme un intermédiaire par ARM même si la consommation élevée des "très gros" coeurs tend la société à pousser aujourd'hui les coeurs "Sophia" sur le haut de gamme mobile. Cette tendance se confirme aujourd'hui puisque l'A75 est en pratique le successeur de l'A73.
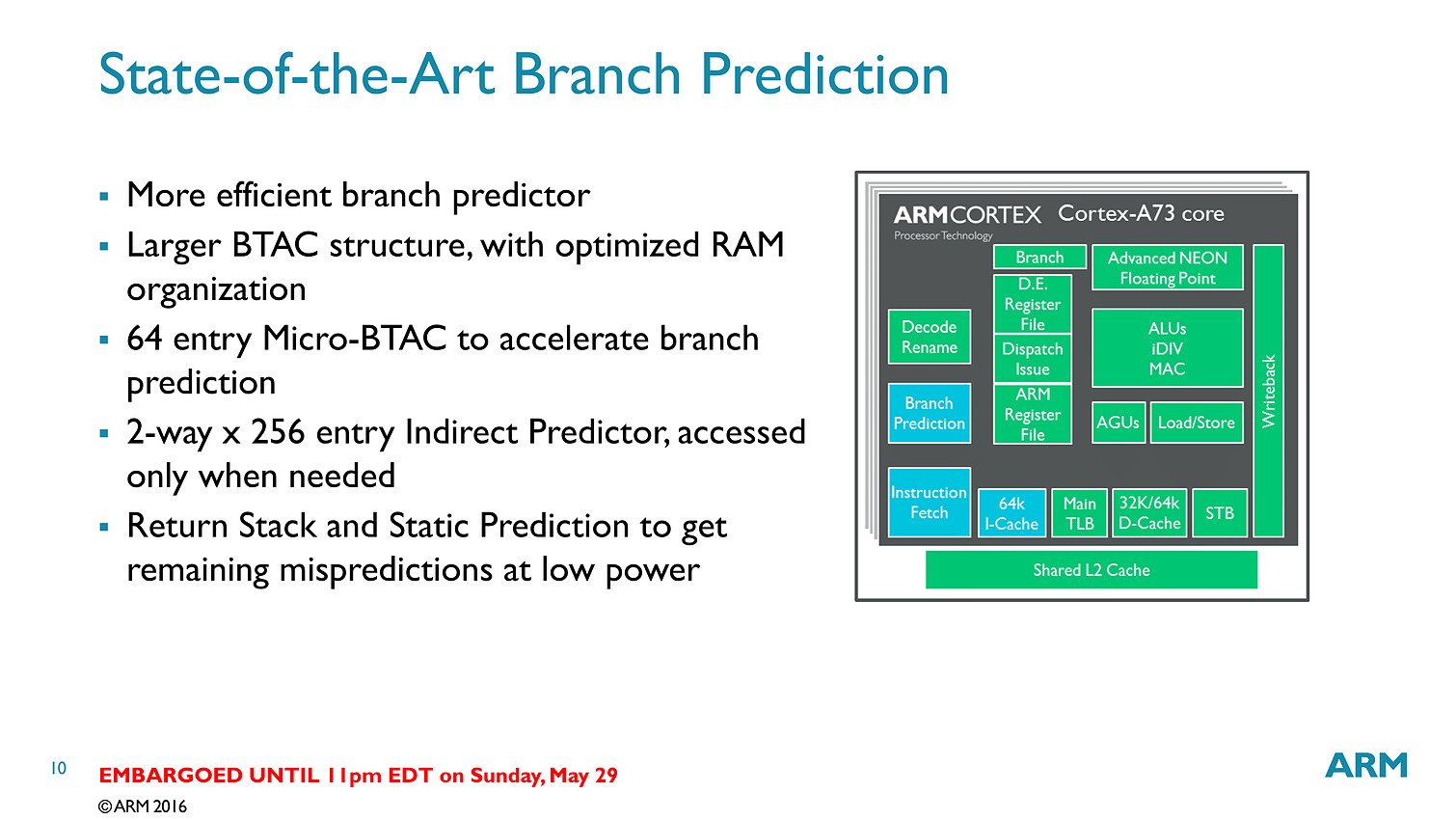
Techniquement ces puces se distinguent par un pipeline plus court, et sur ce point l'A75 ne change rien en gardant un pipeline court de 11 étapes pour les instructions entières. Le plus gros changement concerne le nombre d'instructions décodées par cycle puisque l'on passe de deux instructions décodées à trois, alignant sur cette caractéristique l'A75 avec ce qui se faisait sur les "très gros" ARM. On passe donc en pratique de 6 micro-ops par cycle à 8. Le nombre d'unités reste identique mais l'A75 ajoute des files supplémentaires pour stocker les micro-ops à traiter.
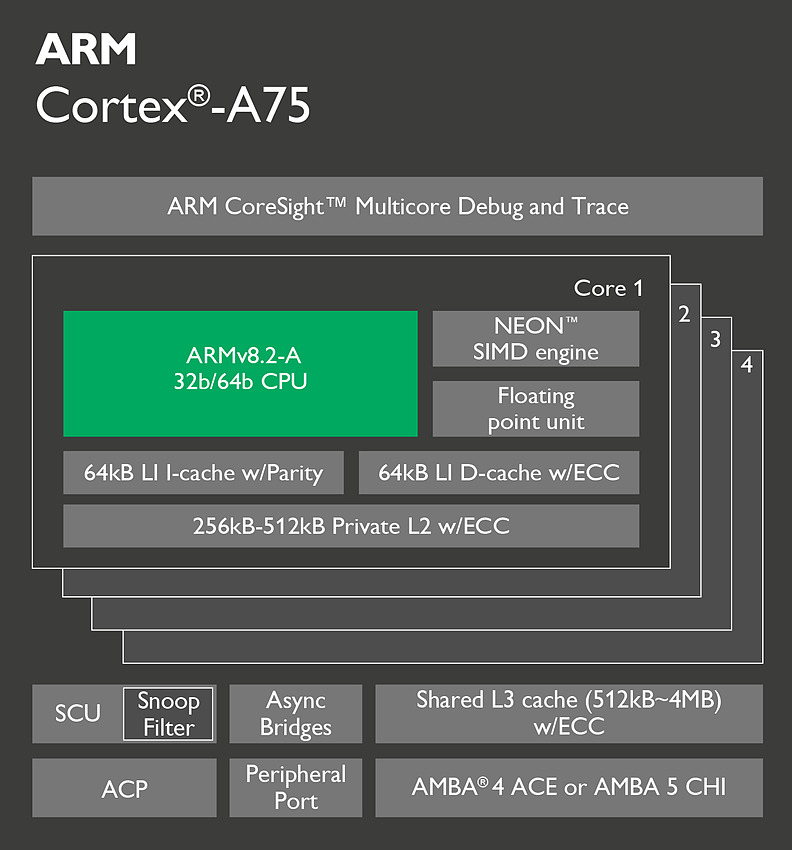
ARM applique un changement similaire pour les instructions flottantes et vectorielles (on parle de NEON dans le marketing ARM, le pendant de SSE/AVX sur x86) avec là aussi la possibilité de décoder trois instructions par cycle. Cela s'accompagne par une file supplémentaire et une troisième unité NEON spécifiquement utilisée pour les accès mémoire.
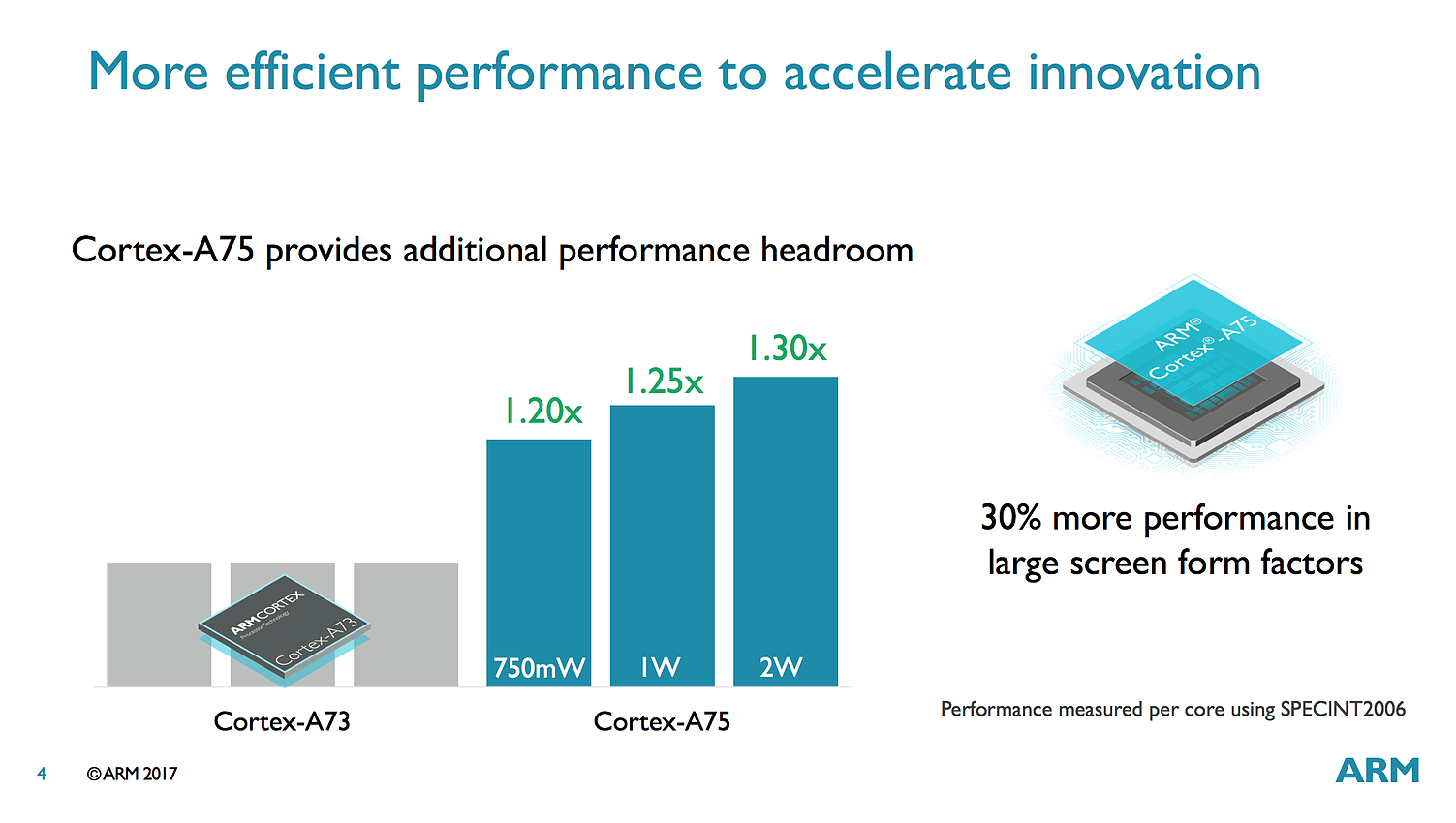
ARM annonce des gains de performance allant de 20 à 30% pour l'A75 rapport à l'A73 en fonction de la consommation autorisée, ce qui est plutôt intéressant. L'A75 est un bloc qui comme l'A73 est prévu pour le 10nm et il devrait faire son apparition en toute fin d'année ou plus probablement l'année prochaine dans des produits commerciaux.
Un nouveau coeur LITTLE
En plus des gros coeurs dont nous vous parlions au-dessus, ARM propose également des coeurs plus petits, à la consommation beaucoup plus faible et qui ont pour but d'être appairés à des gros coeurs dans ce qu'ARM appelait jusqu'ici des configurations big.LITTLE. Après avoir utilisé dans ce rôle l'A53 depuis plusieurs années (il avait été introduit en 2012 !), ARM propose enfin une nouvelle mouture de son petit coeur baptisée Cortex-A55.
Il s'agit toujours d'un coeur dit "In Order", les instructions ont exécutées dans l'ordre dans lequel elles arrivent (à l'opposé des processeurs plus gros/modernes qui utilisent des architectures "Out Of Order", les instructions sont réordonnancées pour optimiser l'exécution et améliorer le parallélisme).
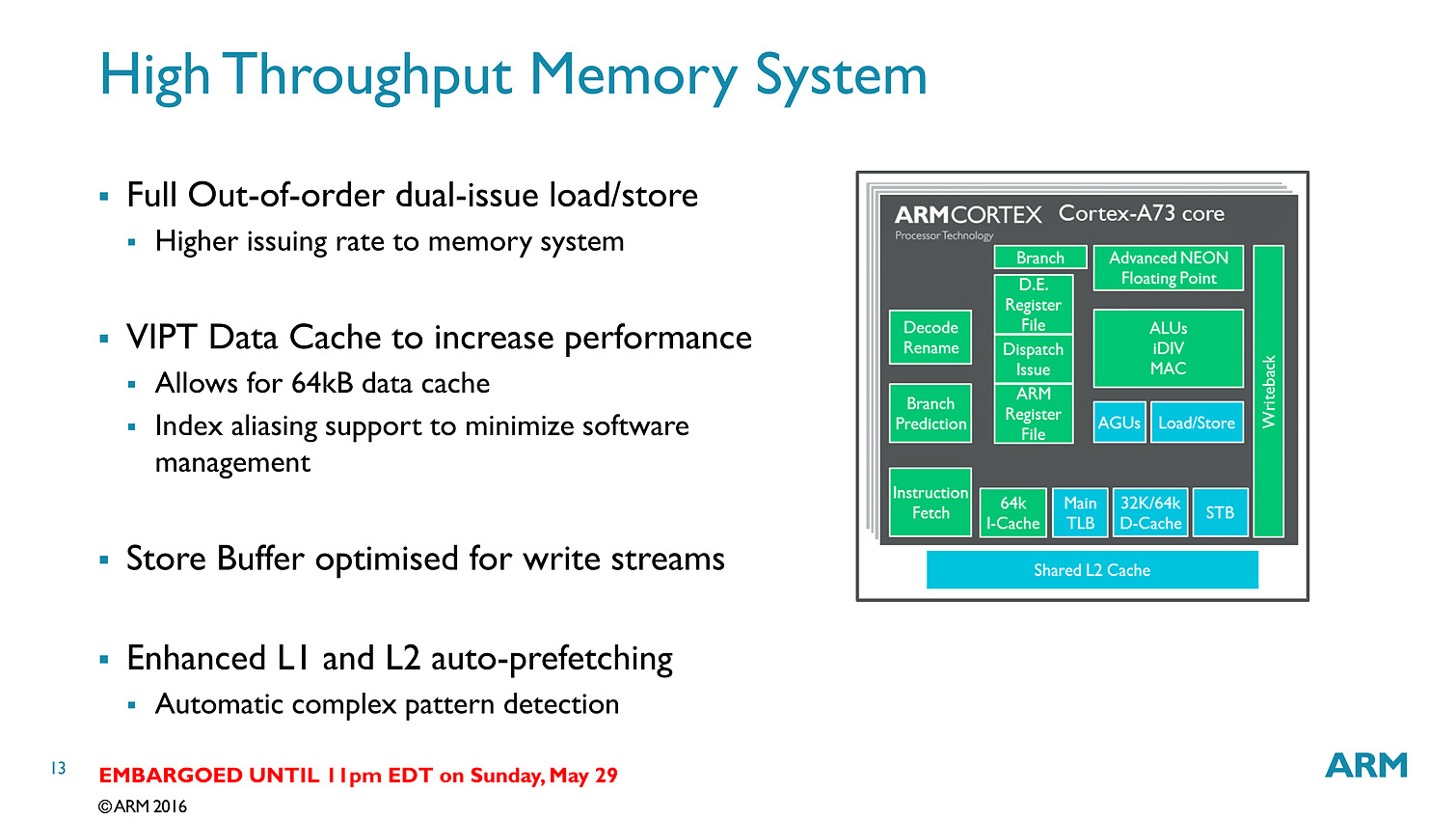
Il y a assez peu de changements sur l'A55, le plus gros concerne la séparation des unités de lecture/écriture mémoire ainsi qu'un nouveau prédicteur de branchements. Le reste des changements se situant au niveau des caches mémoires qui ont été reconfigurés.
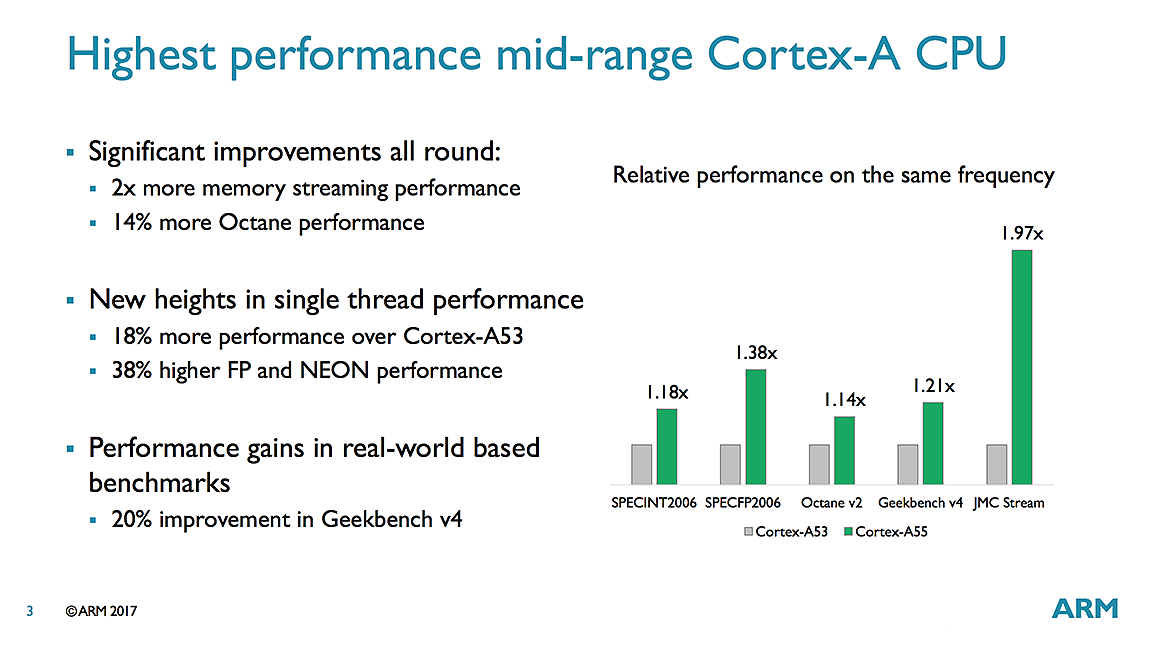
ARM annonce des gains de performances autour de 20% sur l'A55 à fréquence égale par rapport à un A53, des gains qui peuvent cependant monter beaucoup plus haut quand on prend en compte les caches. Sous SPECFP2006, la société annonce ainsi 38% de gains.
DynamIQ, big.LITTLE V2.0
Le concept du big.LITTLE évolue et prend désormais le nom de DynamIQ. ARM a repensé la manière dont il permettait de relier ses coeurs entre eux et propose un nouveau concept qui résout beaucoup de problèmes sur le papier.

L'idée principale est de remplacer big.LITTLE par des "clusters" qui peuvent regrouper jusque huit coeurs. On pourra mélanger au sein d'un cluster différents types de coeurs (par exemple quatre A75 et quatre A55) ce qui engendre un changement important au niveau de la structure des caches. Désormais, chaque coeur ARM (A55 ou A75) disposera de son propre cache L1 et de son propre cache L2. Ce changement est bienvenu et devrait éviter ces bugs embarrassants comme celui de Samsung et de son M1 qui mélangeait ses coeurs à des A53 avec des lignes de caches différentes.
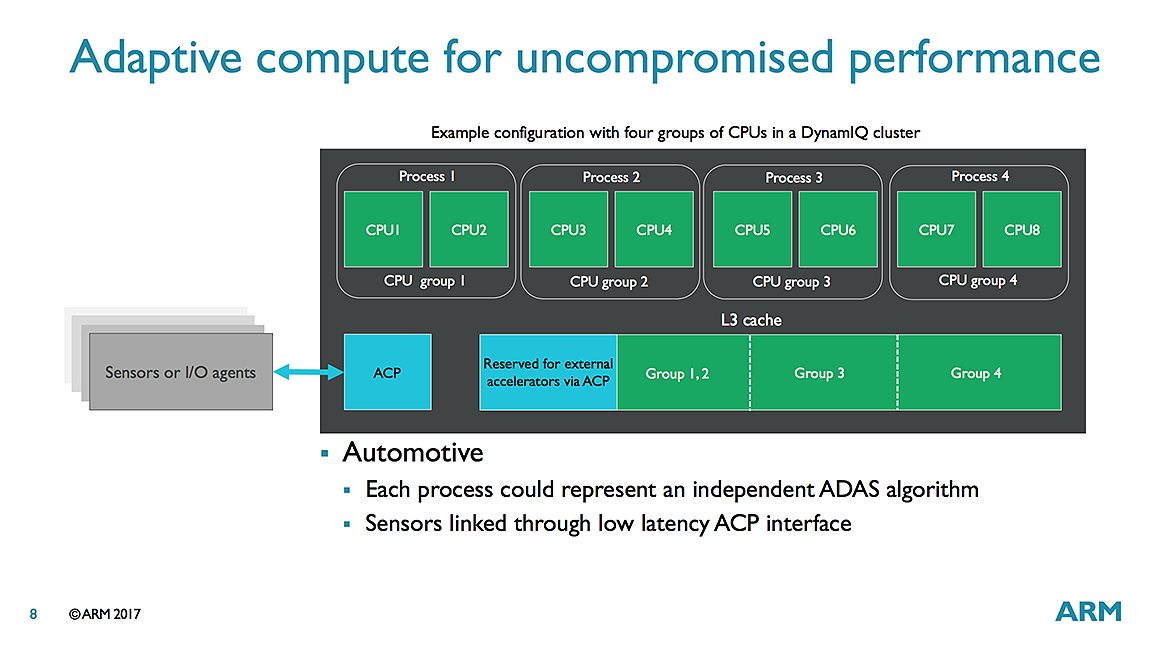
Tous les coeurs d'un cluster partageront un cache L3 commun (jusque 4 Mo) et l'on pourra disposer de plusieurs clusters - jusque 32 - au sein d'une puce (quelque chose qui devrait surtout servir pour d'éventuelles versions serveurs de ces processeurs). Une organisation qui n'est pas sans rappeler celle utilisée par AMD avec ses CCX dans Ryzen, on notera qu'ARM indique que son cache L3 peut être partitionné dynamiquement pour certains coeurs ou pour d'autres applications.
En bref
On notera également côté GPU l'arrivée une version optimisée du Mali G71, baptisé G72 pour lequel il n'y a pas de changement majeur au niveau de l'architecture Bifrost d'ARM. L'augmentation de la taille des caches permet d'augmenter l'efficacité énergétique ce qui est appréciable.
Si les modifications effectuées sur les Cortex A75 et A55 sont intéressantes, on retiendra surtout de l'annonce d'ARM l'arrivée de DynamIQ qui devrait permettre de mieux exploiter les coeurs. Car si big.LITTLE était sur le papier une bonne idée, son implémentation pratique avait montré de multiples limites. Cette nouvelle approche sous la forme de clusters contribue aussi sur les gains de performances, tout comme la réorganisation des caches.
Le sous-système mémoire des Cortex a toujours été la faiblesse de l'architecture avec des contrôleurs extrêmement optimisées pour la basse consommation, mais pas forcément pour les performances ce qui donne aux architectures ARMv8 tierces (comme celles d'Apple et même de Samsung) un avantage en général très net sur ce point.
Hot Chips : M1, SVE, Parker, InFo et Skylake !
La conférence Hot Chips qui se tenait la semaine dernière a donné lieu a d'autres annonces intéressantes que nous avons essayé de regrouper dans cette actualité !
Rajouter des tiers de mémoire côté serveur
On avait déjà noté un peu plus tôt la volonté de rajouter de la mémoire HBM à divers endroits, et même la volonté de Samsung de travailler sur une version moins onéreuse, mais l'on rajoutera ce slide issu d'une présentation d'AMD qui rappelle les objectifs de la société côté serveurs, prenant pour le coup l'exemple du big data
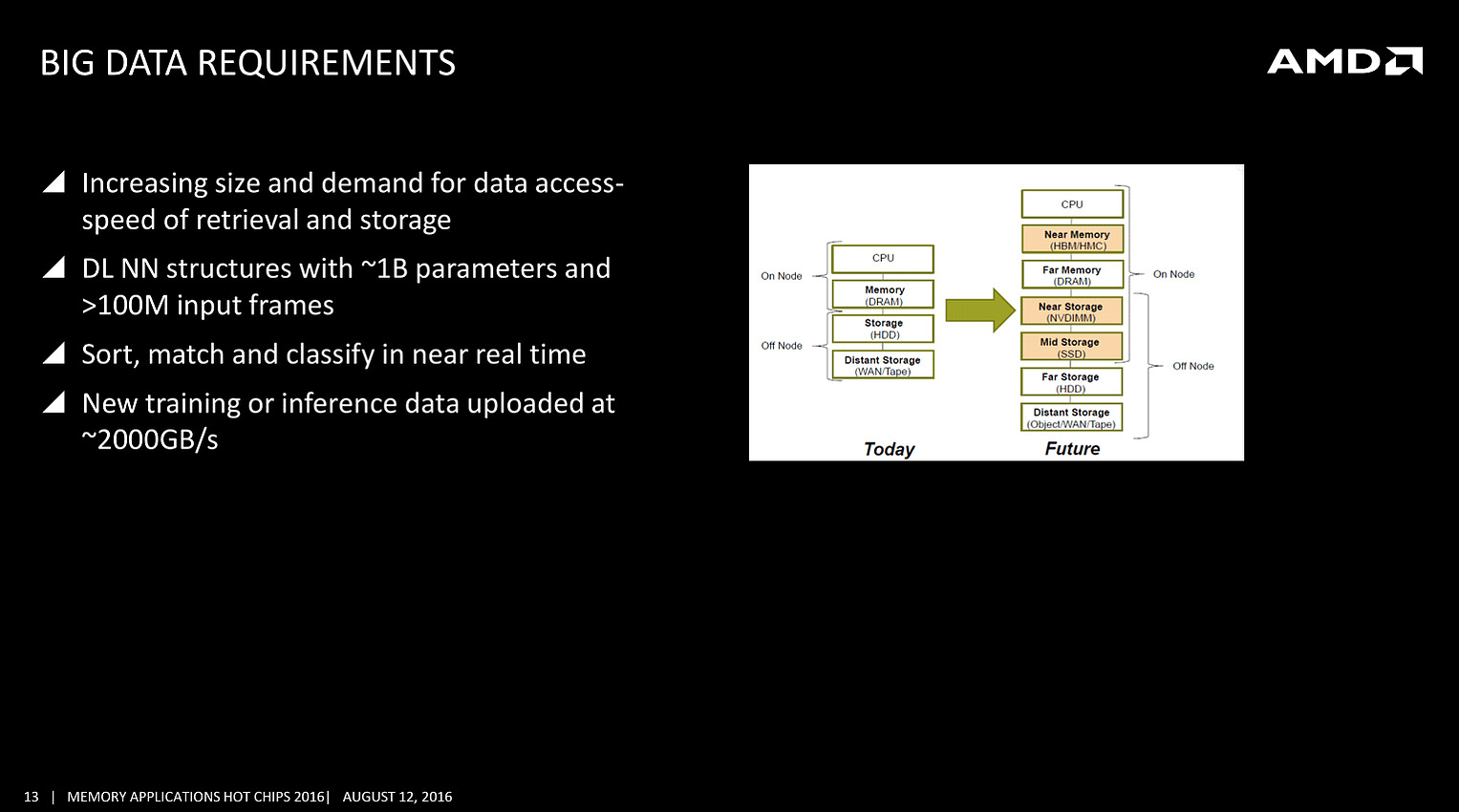
On s'attardera sur le graphique à droite qui pointe l'ajout d'une mémoire intermédiaire côté CPU, type HBM ou HMC (AMD misera plutôt sur la HBM pour les déclinaisons serveurs de Zen), et aussi l'utilisation de NVDIMM pour s'intercaler avant un SSD. Il faudra attendre encore un peu pour voir comment seront déclinées ces technologies, mais il est intéressant de noter la manière dont les avancées côté mémoire sont mises en avant, parfois un peu trop tôt comme l'a fait Intel avec 3D XPoint, dans toute l'industrie.
Quelques détails de plus sur SVE
Chez ARM, outre une présentation de Bifrost côté GPU dont on vous avait déjà parlé, l'annonce principale concernait SVE, la nouvelle extension vectorielle introduite par la société.
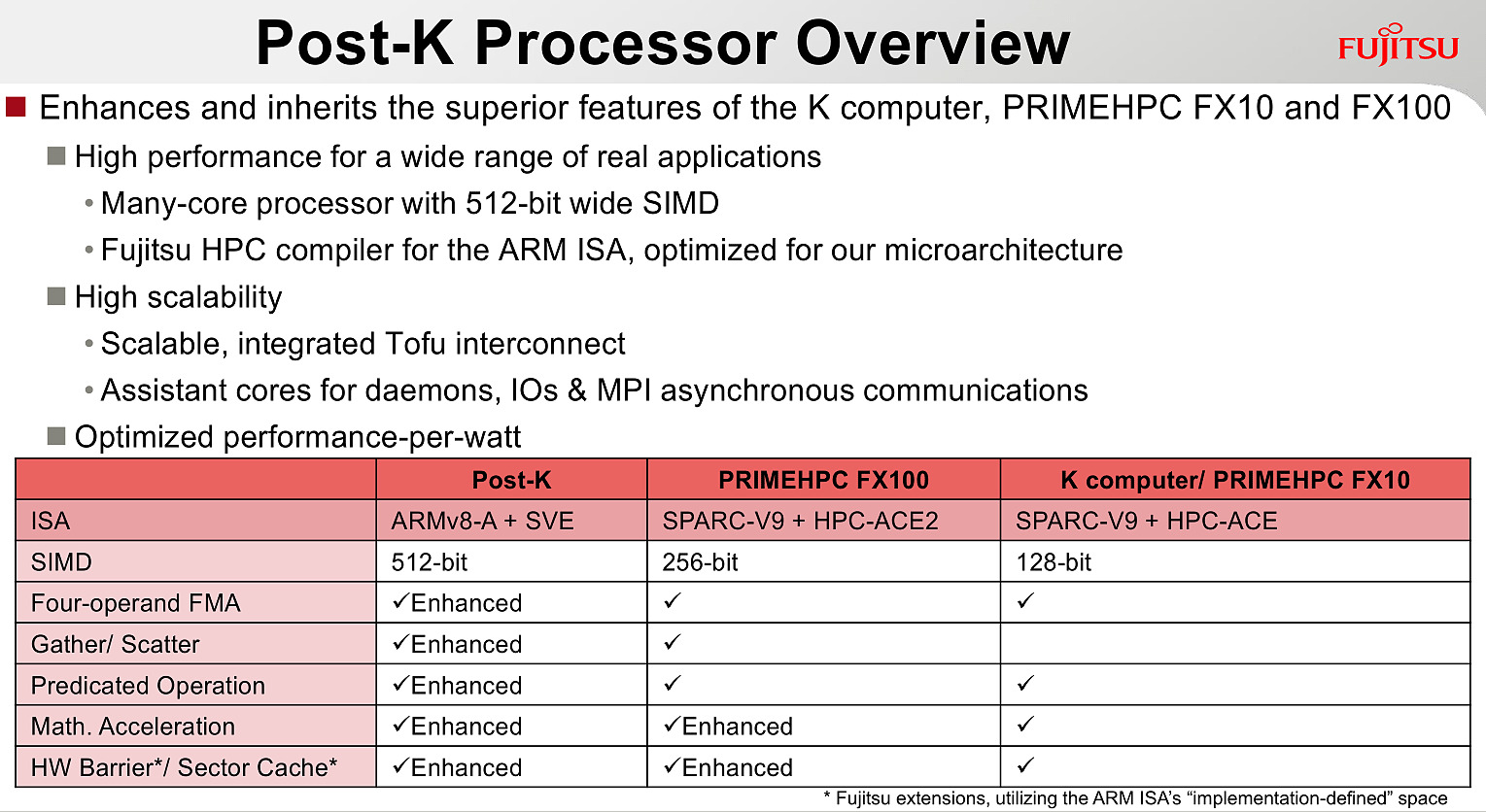
Le premier partenaire annoncé par ARM est Fujitsu, qui mettra au point des processeurs ARMv8 avec extension SVE pour le futur supercalculateur japonais Post-K. Fujitsu a donné quelques détails, indiquant par exemple que les unités vectorielles auraient une largeur de 512 bits sur ses puces.


Chez ARM, le constructeur présente plusieurs benchmarks assez théoriques, on notera surtout sur les barres grises les améliorations qui ont été effectuées côté auto-vectorisation, c'est a dire la capacité du compilateur à utiliser des instructions vectorielles pour extraire du parallélisme. ARM devrait proposer dans les semaines qui viennent des patchs pour les différents compilateurs open source, incluant LLVM et GCC.
Le Samsung M1, un timide premier pas
La particularité de l'écosystème d'ARM est que les partenaires peuvent soit utiliser des coeurs "clefs en main", développés par ARM (les gammes Cortex, comme par exemple le Cortex A57), ou créer leurs propres implémentations de l'architecture ARM (qui restent compatibles, tout en étant différentes, à l'image des processeurs d'AMD et d'Intel qui diffèrent bien que restant compatibles). Plusieurs sociétés disposent de licences "architecture" qui permettent de créer ces puces, Apple étant jusqu'ici la société la plus à la pointe sur armv8 même si de nombreuses sociétés proposent tour à tour leurs architectures.

Parmi les nouveaux venus, il y a Samsung qui s'est lancé lui aussi dans le design d'une architecture armv8 custom pour ses Exynos M1. A la tête du projet, on retrouve Brad Burgess qui était architecte chez AMD pour les Bobcat. Il aura même été rejoint un court instant par Jim Keller (K8 chez AMD, A7 chez Apple, puis Zen chez AMD), qui n'est cependant pas resté très longtemps chez Samsung et qui n'aura probablement pas eu un grand impact. Le projet aura nécessité trois années, et en soit arriver a produire quoique ce soit du premier coup en un temps si court est un exploit.
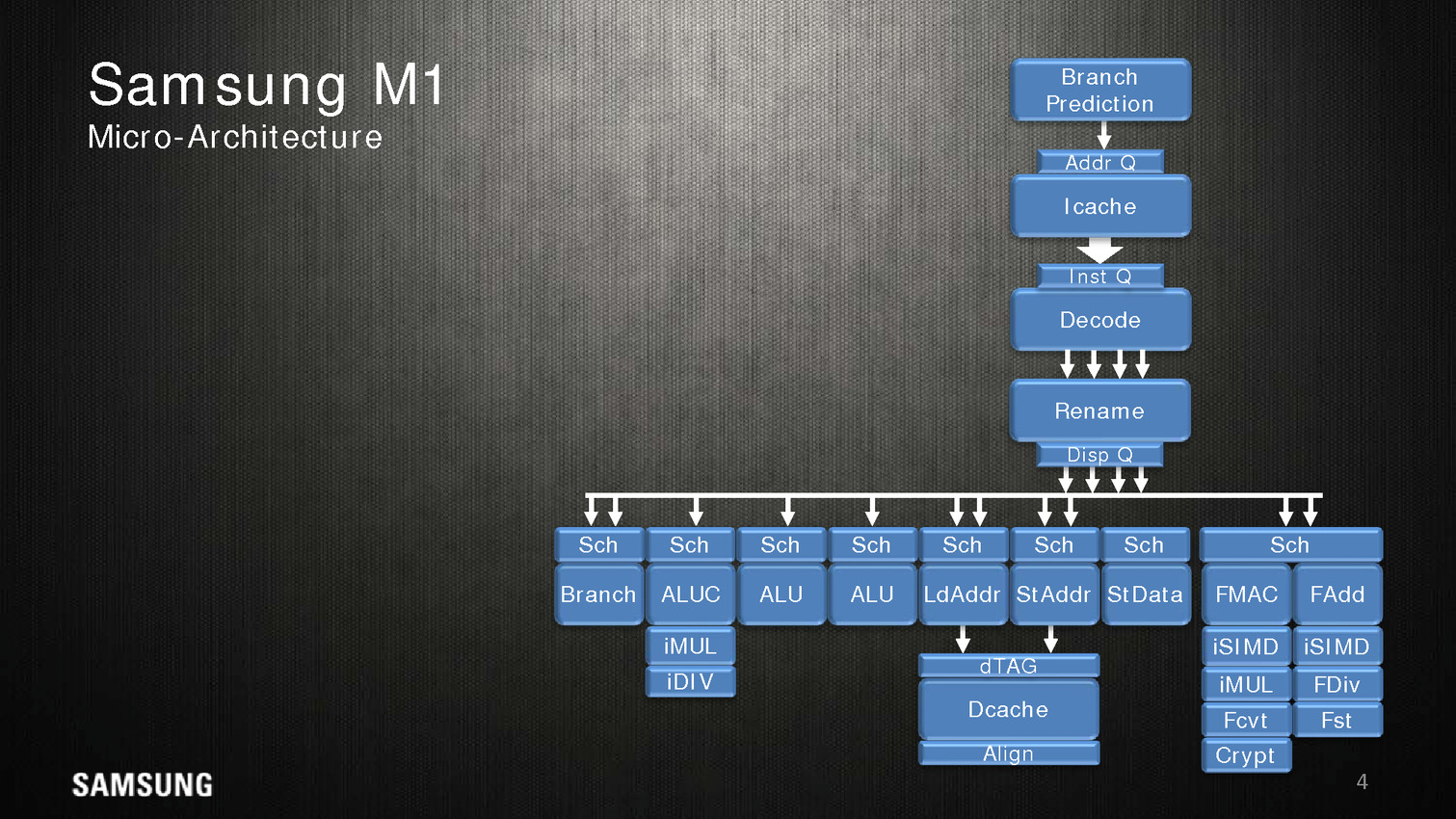
Côté architecture, Samsung indique utiliser un perceptron (un réseau de neurones simple) au niveau de ses mécanismes de prédiction de branches. Deux branches sont considérées par cycle, mais il est difficile d'estimer quoique ce soit sur l'éventuelle efficacité.
Quatre instructions peuvent être décodées/dispatchées par cycle aux unités d'exécutions qui sont regroupées sur sept files. On note deux files dédiées aux écritures mémoires, trois aux opérations mathématiques simple (avec un port sur lequel sont ajoutés les multiplications/divisions) et une aux branchements. Les opérations en virgules flottantes sont regroupées séparément avec un scheduler unique pour deux files. Samsung annonce 5 cycles pour effectuer une opération FMA.
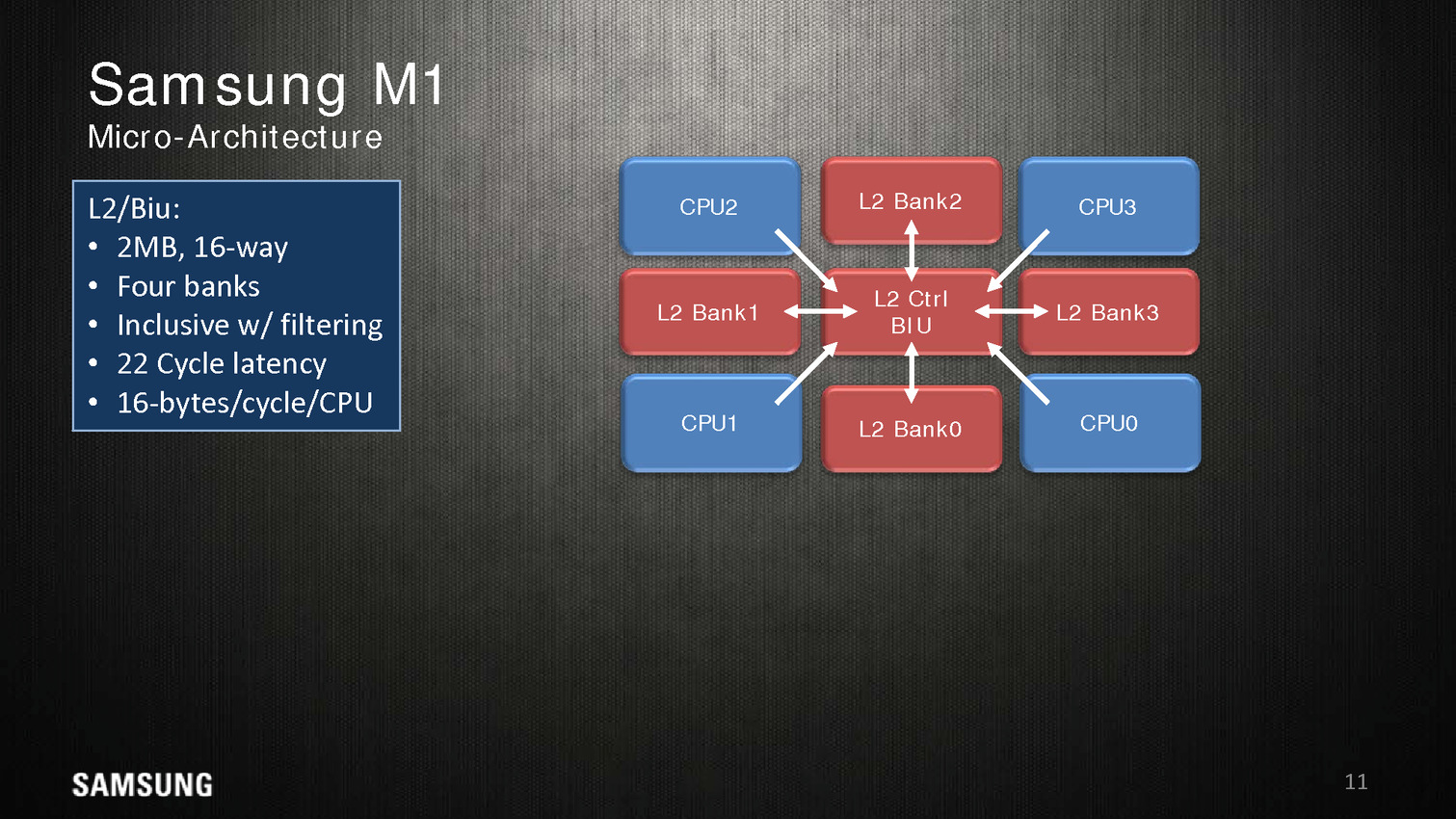
Dans une configuration quatre coeurs, le M1 dispose de 2 Mo de cache L2 coupé en quatre blocs, les coeurs accèdent au L2 via une interface commune. On appréciera aussi les schémas très spécifiques que propose Samsung, pas vraiment avare de détails techniques.

Reste qu'en pratique, les benchmarks mis en avant par Samsung ne sont pas forcément très convaincants. Avec 200 MHz de plus, sur un coeur, un M1 propose 10% de performances en plus qu'un Cortex A57 à consommation égale, ce qui est tout de même très peu. Samsung fait beaucoup mieux sur les opérations mémoires (c'est relativement facile, on l'a évoqué de nombreuses fois, les contrôleurs mémoires ARM ne sont pas particulièrement véloces/adaptés aux hautes performances), mais n'en tire pas particulièrement profit hors des benchmarks théoriques.
La présentation se termine en indiquant que ce n'est qu'un premier pas pour Samsung et que d'autres designs sont en cours d'élaboration. En soit si les performances ne vont pas révolutionner le monde des SoC ARM, Samsung a au moins une base de travail qu'ils pourront faire évoluer par la suite. A condition évidemment que Samsung continue d'investir sur le sujet dans les années à venir !
Les curieux pourront retrouver la présentation en intégralité ci dessous :














Parker/Denver 2 : design asymétrique
Nvidia était également présent à Hot Chips, donnant quelques détails sur son futur SoC baptisé Parker. Ce dernier est annoncé comme crée spécifiquement pour le marché automobile avec des fonctionnalités dédiées à ce marché. On ne sait pas si le constructeur le déclinera en d'autres versions plus génériques.

Les détails techniques ne sont pas particulièrement nombreux, on notera côté SoC que l'encodage 4K est désormais accéléré à 60 FPS, que l'on peut contrôler jusque trois écrans en simultanée, et que le contrôleur mémoire passe sur 128 bits (contre 64 précédemment). Côté GPU, Parker utilisera une version dérivée de son architecture Pascal.



C'est du côté CPU que les choses sont les plus originales, après avoir utilisé son architecture Denver sur les TK1, puis être revenu aux Cortex A57 sur les TX1, Nvidia propose une architecture asymétrique avec deux coeurs "Denver 2" (sur lesquels aucun détail n'aura été donné, à part un gain performance/watts de 30% donné sans précision sur les process comparés) et quatre coeurs Cortex A57. Ce n'est pas la première fois que l'on voit des configurations originales, durant Hot Chips, le taiwannais MediaTek présentait un SoC 10 coeurs avec quatre coeurs Cortex A53 à 1.4 GHz, quatre coeurs Cortex A53 à 2 GHz, et deux coeurs Cortex A72 à 2.5 GHz !
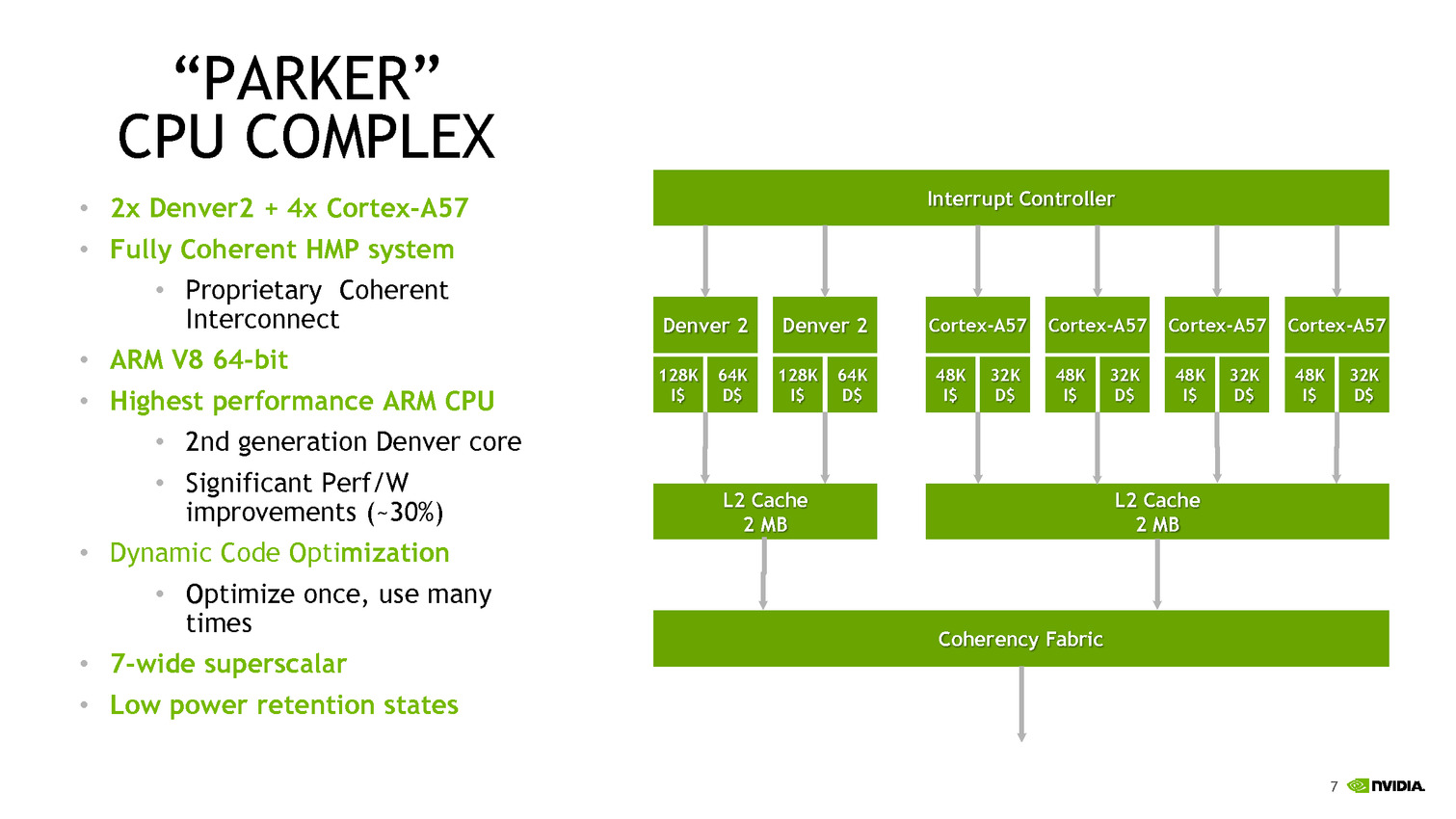
Dans le cas de MediaTek, l'idée est de proposer différentes options à différents niveaux de consommation. Pour ce qui est de Nvidia, le choix est différent, le Cortex A57 étant "haute performance" contrairement aux A53 de MediaTek. Il faut dire surtout que le marché visé, l'automobile, n'a pas les mêmes contraintes de consommation que le marché mobile. Reste que Nvidia se doit de gérer cette asymétrie avec un scheduler qui doit décider sur quel coeur placer les threads, ce qui n'est pas particulièrement simple. On notera que chaque groupe de coeurs dispose de son propre cache L2 de 2 Mo.
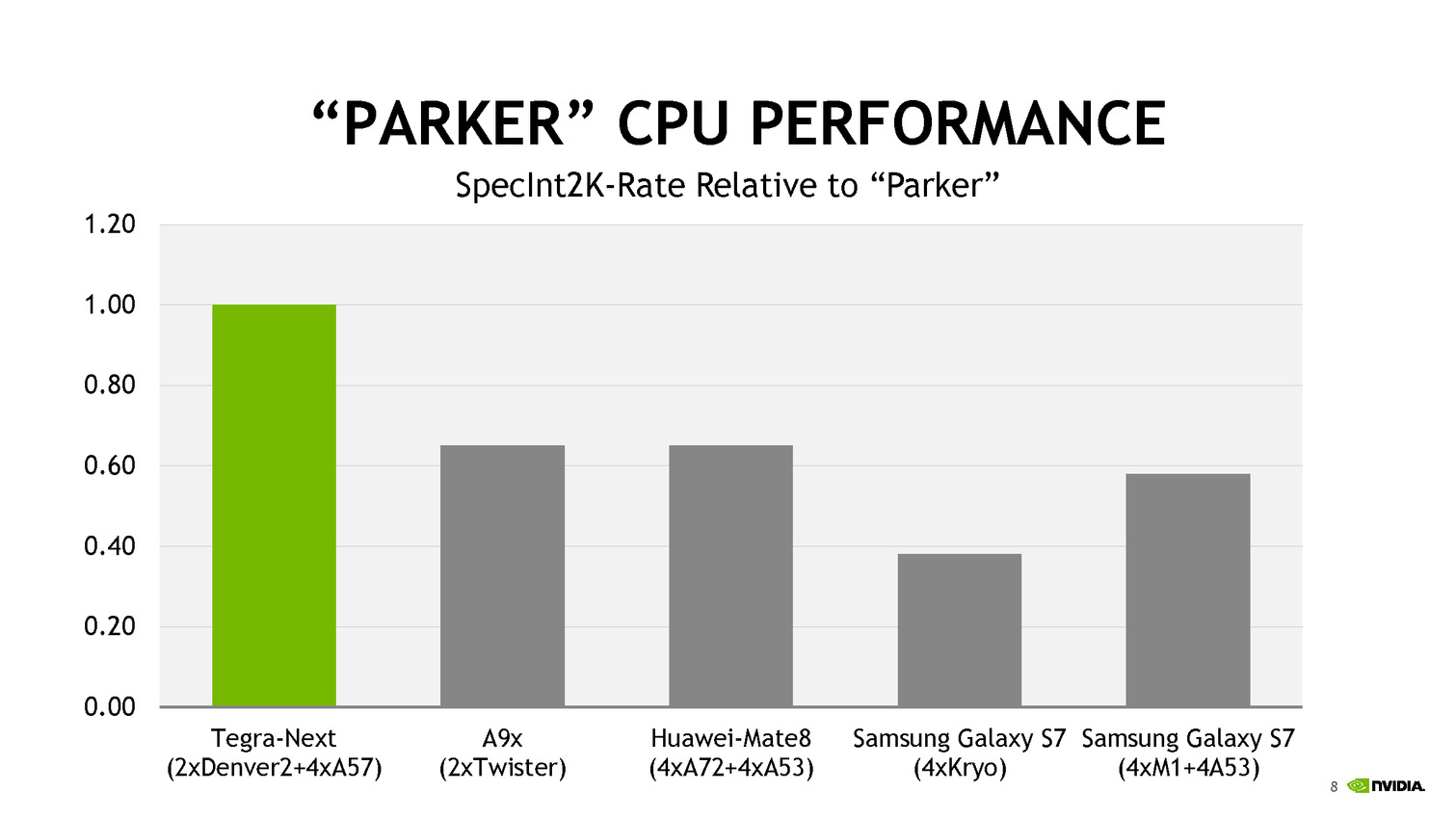
Côté performances, Nvidia avec ses 6 coeurs se présente comme moitié plus rapide qu'un A9X d'Apple en deux coeurs. Le graphique mélangeant des puces à TDP différents (on y retrouve des puces pour smartphones et pour tablettes), on admettra que la comparaison n'est pas faite à TDP identique.
TSMC parle de ses packages InFo
Une des nouveautés présentées cette année par TSMC est la disponibilité d'un nouveau type de packaging, l'InFo-WLP. L'idée est de permettre de relier plusieurs dies en les "moulant" dans un substrat commun très fin qui contient également les interconnexions entre les puces. Il s'agit d'une version à cout beaucoup plus faible que les interposer (utilisés par exemple par AMD pour Fiji).
La présentation de TSMC est dédiée aux interconnexions entre les puces, et présente une puce 16nm reliant un SOC à une puce mémoire avec une bande passante de 89.6 Go/s sur 256 bits, le tout avec une consommation très réduite.
En plus de la solution présentée qui évoque le cas simple d'une puce mémoire et d'un Soc, TSMC évoque la solution comme permettant un jour de relier également plusieurs dies de logique, par exemple des groupes de coeurs séparés, pour réduire le coût de fabrication des puces (qui augmentent exponentiellement avec la taille des dies).
































La présentation est technique mais reste intéressante, l'InFo-WLP ouvre des opportunités supplémentaires pour réaliser des produits qui mélangent processeur et mémoire. Le coût réduit et la finesse de l'interconnexion fait qu'on pourrait retrouver assez rapidement cette technique utilisée, y compris sur le marché mobile. Les prochains SoC d'Apple pourraient par exemple utiliser un tel package.
Et Skylake !
Juste avant la présentation de Zen, Intel proposait aussi une présentation de son architecture Skylake, lancée l'année dernière. Si la majorité du contenu est déjà connu, on aura noté un détail intéressant : un diagramme sur les unités d'exécution de Skylake. On rappellera que l'année dernière durant l'IDF, Intel nous avait promis plus de détails sur le sujet, sans jamais nous les donner !
Pour rappel, voici la répartition sur Haswell :
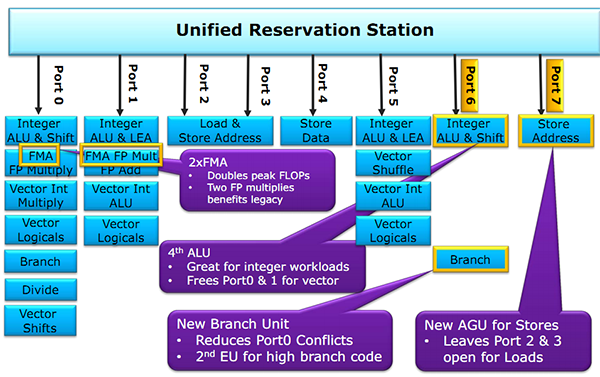
Récapitulatif des ports/unités d'exécution sur Haswell
Un an après, voici enfin un diagramme similaire pour Skylake :
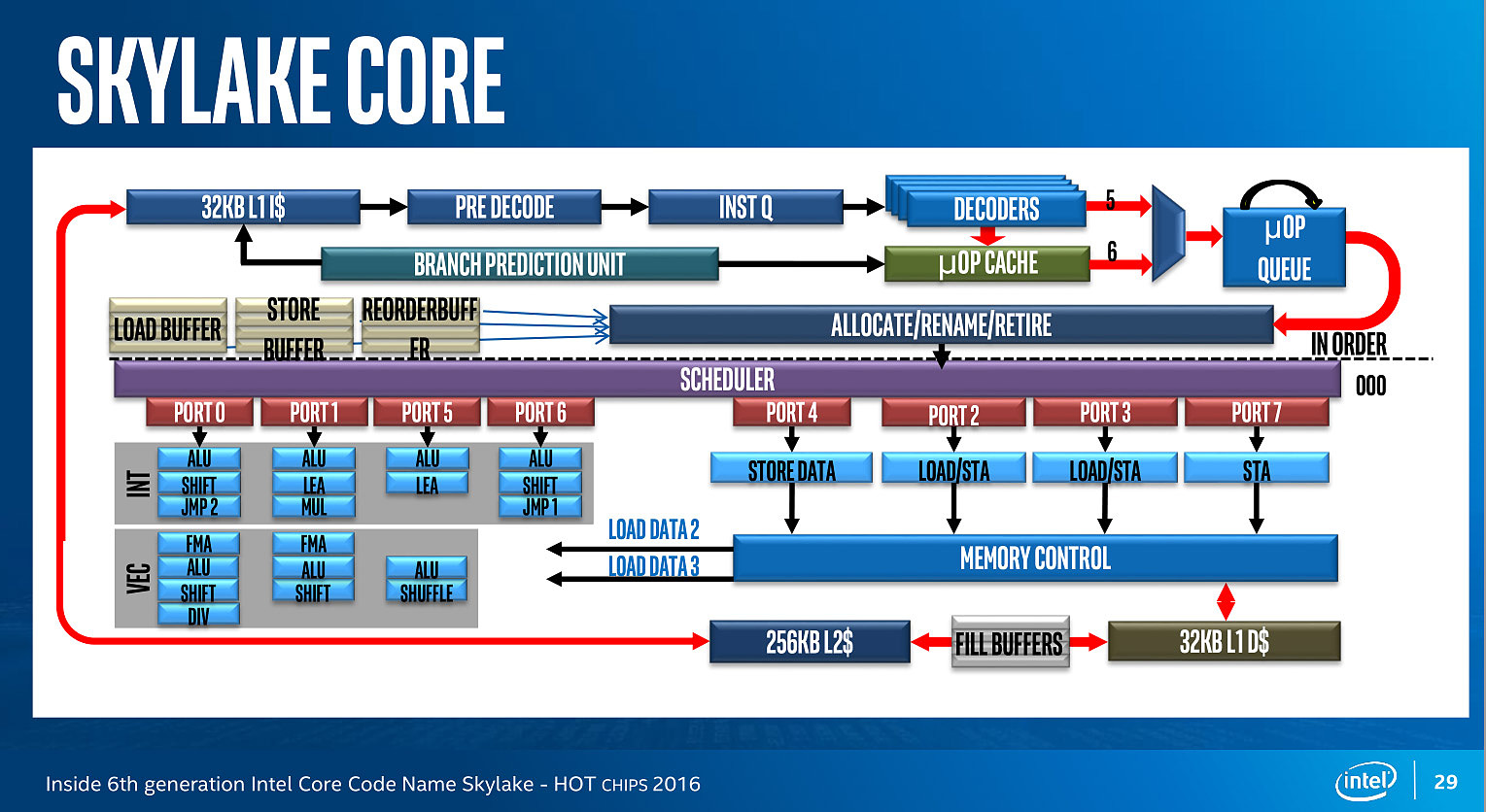
Conformément à ce que nous avaient indiqué les ingénieurs d'Intel l'année dernière, le nombre d'unité a bel et bien augmenté. Le nombre de ports reste constant, à 8, mais l'on compte... une nouvelle unité. Sur le port 1, Intel a en effet ajouté une unité de shift vectorielle. Pour le reste, la répartition reste similaire à celle d'Haswell. Un mystère enfin élucidé !
Nouvelle extension vectorielle ARMv8-A SVE
ARM profite également de la conférence Hot Chips pour présenter une nouveauté importante de son jeu d'instruction, une extension vectorielle baptisée SVE (Scalable Vector Extension).
Les instructions vectorielles permettent pour rappel d'effectuer une même opération sur plusieurs données à la fois (regroupées dans un vecteur au sens informatique , un tableau à une dimension). Dans les architectures x86, on a vu de multiples extensions se succéder. Si l'on reste chez Intel, après les différentes variantes de SSE, on aura connu plus récemment AVX dans Sandy Bridge, AVX2 dans Haswell et AVX-512 pour les Skylake serveurs uniquement.
Dans la grande tradition du x86 qui est un jeu d'instruction "large" (CISC), chaque extension rajoute de nouvelles instructions vectorielles adaptées spécifiquement aux unités matérielles présentes dans chaque génération de processeur introduite. Parmi les changements d'une version à l'autre, outre de nouvelles opérations (par exemple effectuer une multiplication et une addition en simultanée), ce qui évolue surtout est la quantité de données qu'une puce est capable de traiter. Ainsi, comme son nom l'indique, AVX-512 permet d'effectuer des opérations sur des données par groupes de 512 bits (par exemple 16 données 32 bits) à la fois, là ou les unités d'AVX2 travaillaient sur des groupes de 256 bits (dans le même exemple, 8 fois 32 bits).
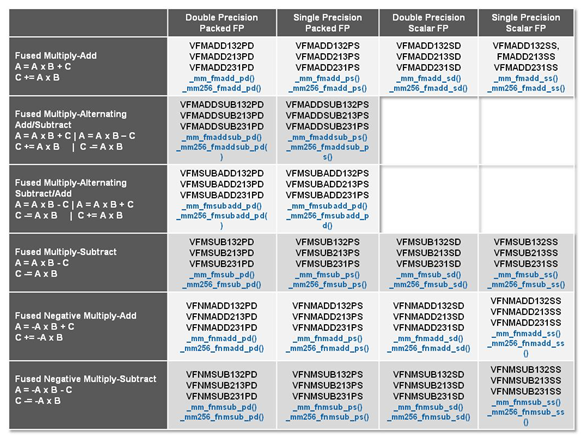
Les instructions FMA3 d'AVX2, on notera la large quantité de variantes proposées
Ce modèle d'instructions adaptées a chaque variante de matériel à l'avantage d'être simple pour les constructeurs, chaque nouveauté est géré par de nouvelles instructions, mais en pratique ce mode de fonctionnement est très problématique. Comme nous avions eu l'occasion de le voir, en général, les programmes sont compilés pour une architecture donnée, parfois deux lorsque l'on a de la chance, ce qui pousse souvent les logiciels commerciaux à ne pas forcément utiliser les dernières nouveautés matérielles par souci de compatibilité.
Cela permet aussi aux constructeurs qui disposent d'un compilateur, comme on l'avait vu avec Intel, d'augmenter artificiellement l'avantage proposé par une architecture. S'ajoute en prime le problème de la vectorisation du code source des logiciels, un problème compliqué qu'on résout soit à la main, soit en laissant faire le compilateur qui, malgré sa meilleure volonté, se retrouve assez souvent dans des situations ou il ne peut pas vectoriser automatiquement le code, par prudence.
Dans le monde ARM, la situation est beaucoup plus simple. Le jeu d'instruction ARM repose pour rappel sur le principe d'un jeu d'instruction réduit (RISC) et rajouter de nouvelles instructions à chaque nouveau processeur n'est pas une option. ARM avait tout de même introduit une extension vectorielle, NEON , qui rajoute des instructions vectorielles (VFP) sur 128 bits. Cette extension avait été conçue il y a une douzaine d'année, exploitée notamment sur l'architecture précédente (ARMv7 en 32 bits).
Pour le passage à son architecture 64 bits, ARMv8-A, ARM n'avait pas apporté de changement fondamental à NEON. C'est désormais chose faite avec l'introduction de SVE, dont les ambitions vont pour le coup beaucoup plus loin.
ARM donne quelques petits détails dans un post de blog sur le fonctionnement de sa nouvelle extension. L'idée de base de SVE se retrouve dans son nom : il s'agit d'une extension Scalable, la taille des vecteurs sur lequel les instructions s'appliquent n'est pas fixe (contrairement à AVX-512 et ses vecteurs 512 bits).

Côté matériel, la spécification d'ARM laisse le choix aux designers de processeurs qui peuvent choisir la largeur de leurs unités de calcul, entre 128 et 2048 bits (!). Cela donne un maximum de flexibilité, permettant de créer des designs orignaux et adaptés à des marchés spécifiques (ARM vise principalement avec SVE le marché des serveur et du HPC, même si le jeu d'instruction devrait se retrouver sur d'autres puces).
Le plus intéressant est ce qui se passe au niveau du jeu d'instruction : il est indépendant de la taille des vecteurs à traiter (la société parle de VLA, Vector Length Agnostic). Concrètement, plutôt que d'utiliser des instructions qui traitent (par exemple) 4 données 32 bits, les instructions VLA indiquent directement quelles instructions appliquer aux vecteurs sans s'occuper d'un quelconque découpage.
Techniquement, ARM ne détaille pas vraiment comment sera implémenté la chose côté matériel, se contentant de dire que c'est le matériel qui, en fonction de la taille de ses unités, s'occupera de découper le vecteur en autant de passes que nécessaire pour le traiter dans ses unités. ARM indique simplement que l'encodage de la taille du vecteur n'est pas nécessaire et qu'elle est déterminée par les mécanismes de prédiction des puces (qui seraient particulièrement performants y compris pour les boucles imbriquées).
Le fonctionnement exact est assez flou, et diffère d'une proposition d'extension - sur le fond assez proche - que l'on avait vu l'année dernière pour le jeu d'instruction RISC-V (PDF) . D'après ARM, un travail important a été effectué sur les instructions qui permettent de charger les données en mémoire pour les traiter, elles représenteraient la majorité des instructions ajoutées.

Extrait de la présentation de proposition vectorielle pour RISC-V, à gauche un code SIMD classique 128 bits, à droite un code vectoriel. La première instruction vsetvl indique la taille des vecteurs traités
L'approche est très différente de celle des SSE/AVX, on peut même la qualifier d'élégante, et devrait permettre de conserver un jeu d'instruction très compact tout en offrant une grande flexibilité. ARM indique que seul un seizième de l'espace d'encodage d'instruction RISC disponible est utilisé pour les nouvelles instructions VLA (les instructions AArch64 sont encodés sur 32 bits, 75% de cet espace est déjà utilisé aujourd'hui par le reste des instructions).

En prime, cela résout le problème de la compilation que nous évoquions plus haut : un programme compilé avec des instructions vectorielles VLA pourra profiter pleinement de toutes les architectures matérielles SVE existantes et à venir.

Cette extension devrait permettre de voir des puces ARM assez différentes arriver sur le marché et si le monde des serveurs et du HPC est clairement visé - ARM met en avant Fujitsu qui développera une puce ARMv8-A avec SVE pour le supercalculateur Post-K prévu pour 2020 - on s'intéressera aussi à l'arrivée de SVE dans des puces plus classiques. La publication de la version finale de la spécification est prévue pour la fin de l'année ou le tout début 2017.
ARM annonce le Cortex-A73 et le Mali-G71
ARM vient d'annoncer de nouveaux blocs disponibles pour ses partenaires. Pour rappel, ARM développe en parallèle des architectures (ARMv8-A pour la dernière version 64 bits, le pendant du x86-64 dans le monde du PC) et propose aussi ses propres implémentations de coeurs qui peuvent être utilisés par ses partenaires sous licence (l'équivalent dans le monde PC serait Intel qui autorise ses partenaires à faire des versions "custom" de Skylake).
Certains des partenaires d'ARM disposent d'une licence dite "architecture" (Apple, Qualcomm, Samsung, Nvidia...) qui leur permet de réaliser leurs propres implémentations (de la même manière qu'AMD et Intel proposent des processeurs compatibles, mais différents derrière la même architecture x86-64), même si ces derniers proposent parfois les deux. Qualcomm propose par exemple des puces utilisant les Cortex (implémentation ARM) et ses propres Snapdragon.
La nomenclature des implémentations d'ARM a toujours été compliquée à comprendre, pour ne pas dire autre chose, et autant dire qu'aujourd'hui ARM n'arrange pas son cas avec l'A73. Il fait suite sur le papier au Cortex-A72 qui avait été annoncé en février 2015 même si d'un point de vue technique les puces sont différentes.
Ce diagramme permet d'y voir un tout petit peu plus clair. Après l'époque "simple" de l'A9, ARM a proposé d'un côté des cores de grande taille, visant les hautes performances (A15, A57 et A72), également appelés big. Il s'agit de designs "Out of Order" (le processeur peut changer l'ordre des instructions pour optimiser leur exécution).
En parallèle des coeurs de plus petite tailles ont été présentés (les coeurs LITTLE comme l'A7 et l'A53). Ils utilisent un design dit "In Order" (pas de changement d'ordre) qui simplifie l'implémentation, et réduit donc la consommation de la puce. Leur niveau de performance est plus bas, mais ils disposent d'un meilleur rapport performance/watts que les coeurs big. Leur intérêt théorique est de les mélanger pour créer une architecture asymétrique (big.LITTLE, voir la présentation ici) même si en pratique, ce n'est pas toujours ce qui s'est passé.
Les deux familles sont développées par des équipes différentes (Austin pour les big et Cambridge pour les LITTLE) et au milieu de tout cela, on retrouvait les A12 et A17, mélangés sur ce graph (par une troisième équipe a Sophia-Antipolis). Il s'agissait là aussi de designs "Out of Order" mais un peu plus optimisés pour un meilleur rapport performances/watts.
Si en théorie ces puces étaient présentées comme dédiées au milieu de gamme, en pratique elles proposaient surtout une alternative aux gros coeurs ARM dont la consommation était trop élevée, obligeant de limiter fortement les fréquences pour rester dans l'enveloppe thermique d'un smartphone. On a pu voir un certain nombre de retards lors de la génération A57, particulièrement chez Qualcomm, et une surconsommation importante par rapport à ce qu'espérait ARM. Une situation qui a même poussé certains des partenaires d'ARM a proposer des puces n'utilisant que les coeurs LITTLE, un comble.
Cortex A73 : 10nm
Le Cortex A73 est présenté par ARM comme son nouveau coeur big. Il fait suite à l'A72 (16nm) et sera proposé pour les processus de fabrication 10nm. Mais contrairement à ses prédécesseurs big 64 bits (A57 et A72, c'est dur à suivre !), il s'agit sur le papier du successeur des A12/A17 (qui eux n'étaient disponibles qu'en 32 bits).
Contrairement aux A57/A72 qui pouvaient décoder trois instructions par cycle, on se limite cette fois ci à deux sur l'A73. En contrepartie, le pipeline (le nombre d'étapes par lequel les instructions passent) est significativement réduit, passant de 15 à 11 étapes. C'est au niveau du front end (récupération des instructions, décodage, changement d'ordre) que la réduction se fait. On retiendra deux changements importants, d'abord le fait que les instructions en virgules flottantes/NEON (l'équivalent des instructions vectorielles type SSE dans les architectures x86) soient traitées séparément via un décodeur distinct. La seconde est un changement au niveau des instructions arithmétiques entières avec des unités moins nombreuses mais plus performantes.



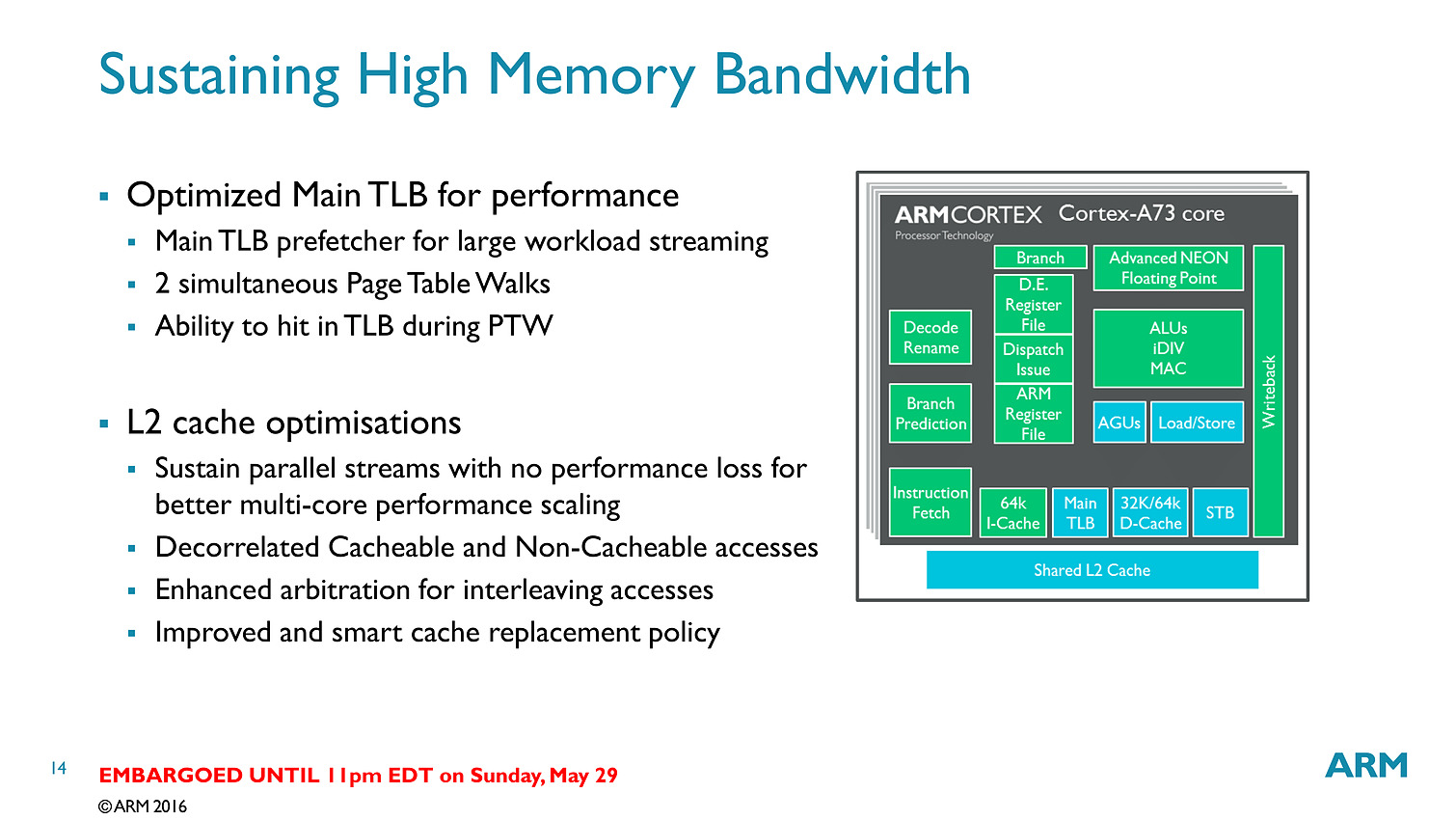
Bien que décodant une instruction par cycle en moins, l'A73 permet sur le papier au final de dispatcher 6 micro-instructions par cycle, contre 5 pour l'A72. Si l'on ajoute toutes les autres optimisations (le sous système mémoire, point faible historique des Cortex semble avoir évolué), l'A73 est annoncé comme 10% plus performant que l'A72, à fréquence/process égal.
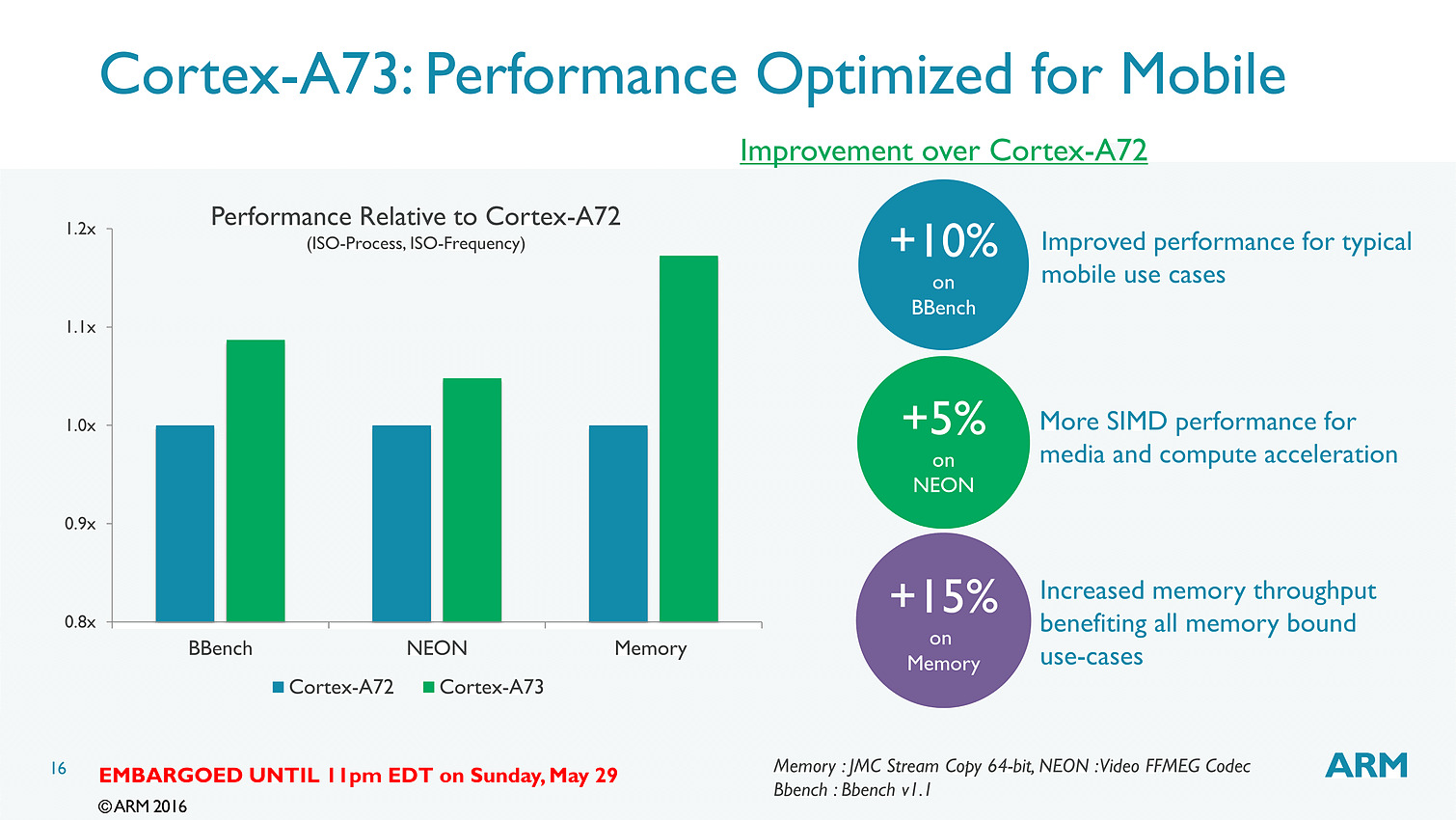
Dans le détail, ARM annonce plus spécifiquement 15% de gains sur les copies mémoire, et 5% sur un encodage FFMPEG utilisant les instructions vectorielles NEON. Notez qu'a process égal, un coeur A73 est 25% plus petit qu'un coeur A72 et consomme 20% d'énergie en moins. En 10nm, un coeur A73 ne mesure que 0.65mm2.
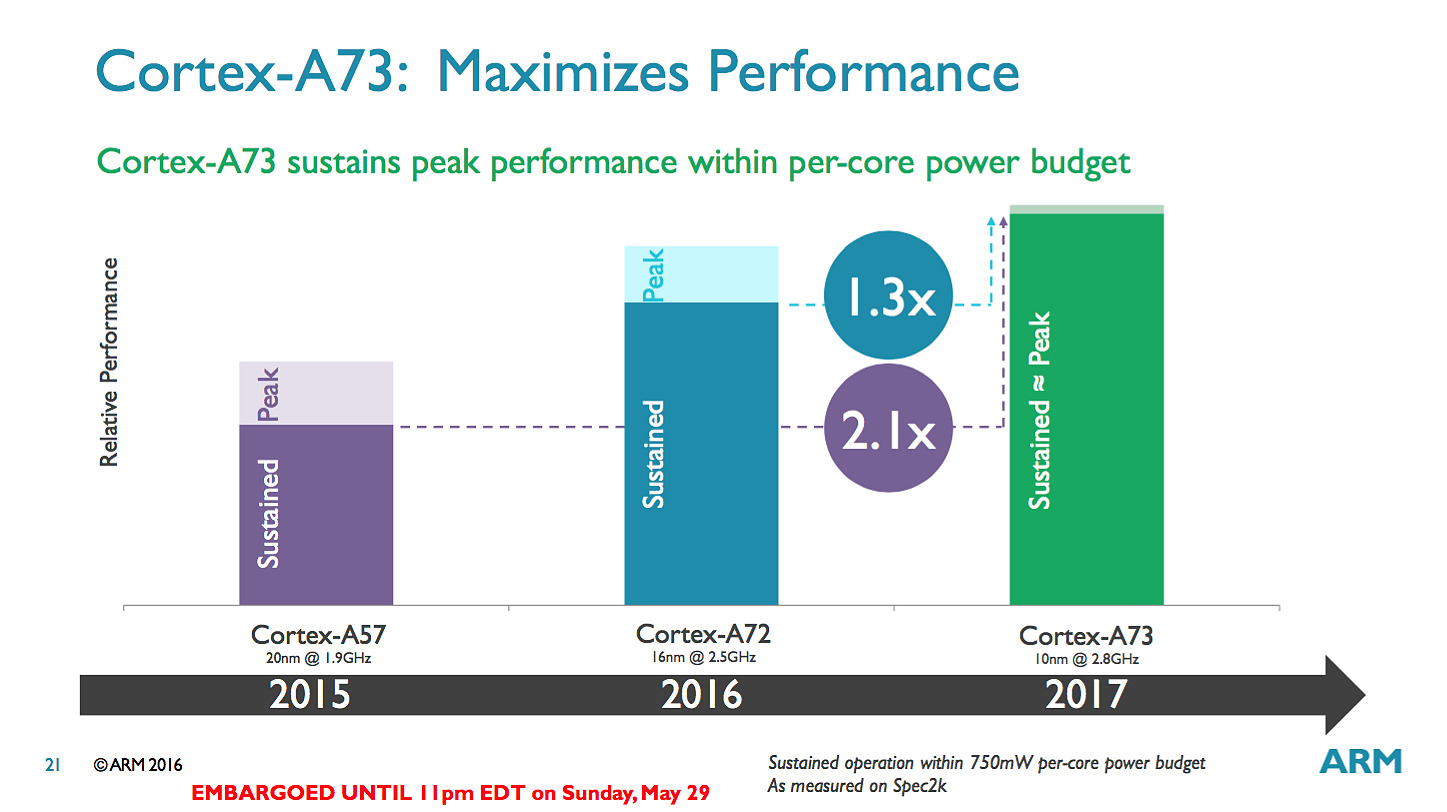
Pour les puces que l'on retrouvera dans le commerce, ARM annonce 30% de performances en plus par rapport aux A72 en profitant du 10nm et de la baisse de consommation pour augmenter la fréquence. Un autre gain significatif mis en avant par le constructeur est que ses puces ne devraient plus voir leur fréquence chuter drastiquement lorsque l'on utilise tous les coeurs en simultanée.
Sur le papier l'A73 est un meilleur compromis côté architecture que ses prédécesseurs, ce qui devrait ravir les partenaires d'ARM, assez peu heureux des A57. Si ARM vise le 10nm, en pratique il propose à ses partenaires des designs A73 en 28, 16 et 10nm. D'ici la fin de l'année, des SoC 16nm devraient faire leur apparition et c'est probablement là qu'on les trouvera en masse (le 10nm sera probablement, pour rappel, réservé au moins dans un premier temps aux gros acteurs du marché comme Qualcomm et Apple à l'image de ce que l'on avait vu avec le 20nm).
Mali-T71 et Bifrost
L'autre annonce d'ARM concerne les GPU. En plus de blocs CPU, ARM propose également à ses partenaires des blocs graphiques qu'ils peuvent utiliser ou non (d'autres sociétés comme Imagination Technologies proposent par exemple leur PowerVR) pour créer leurs SoC.
La nouvelle puce est baptisée T71 et vient faire suite aux GPU T800 dont nous vous avions parlé l'année dernière. Le changement de nomenclature annonce en réalité un changement d'architecture, on passe de l'architecture Midgard à la bien nommée Bifrost.
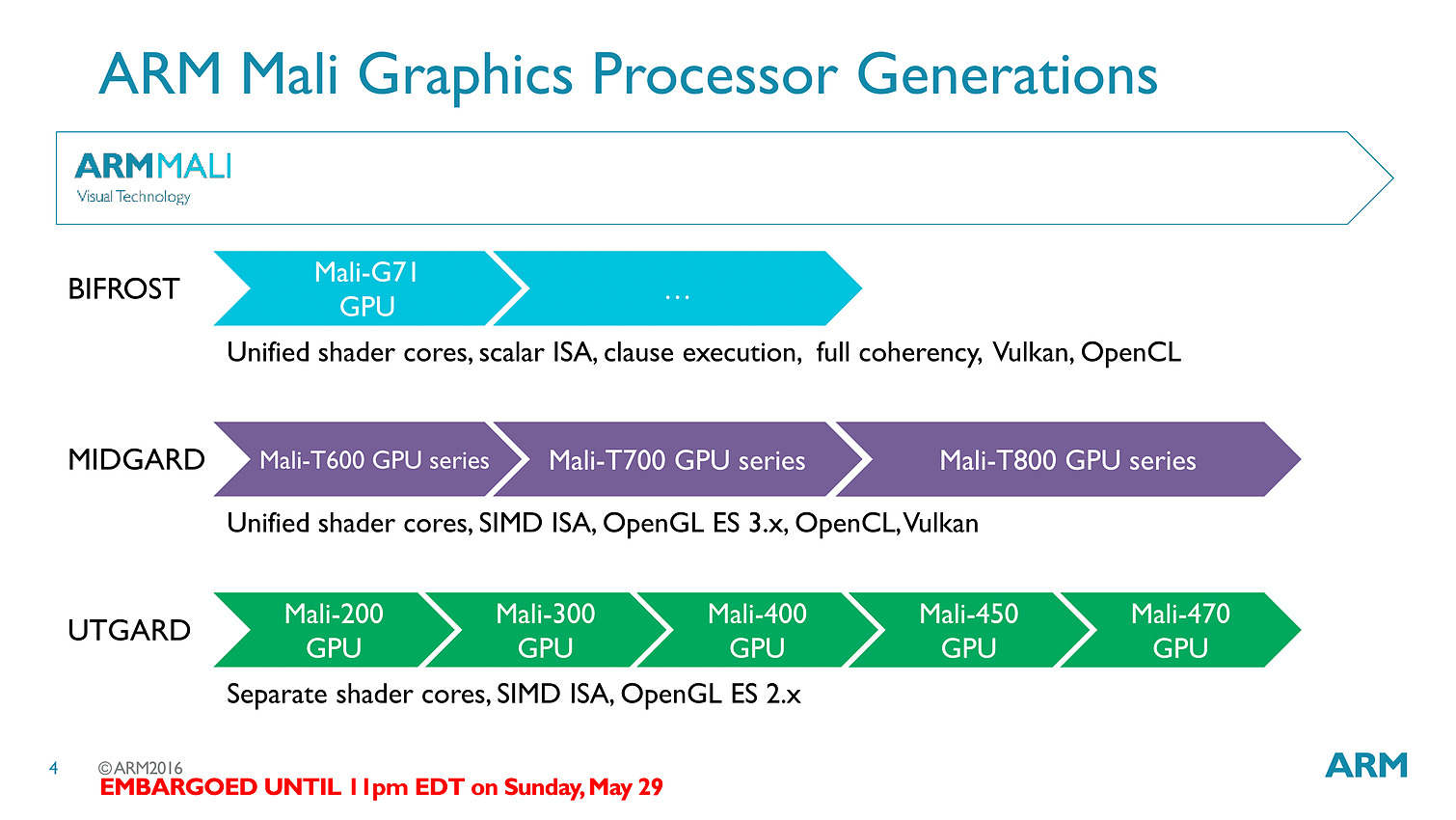
La transition est importante avec un changement complet de philosophie, passant d'un modèle VLIW (Very Long Instruction Word) à un modèle scalaire... soit exactement la transition qu'avait effectué AMD avec GCN !

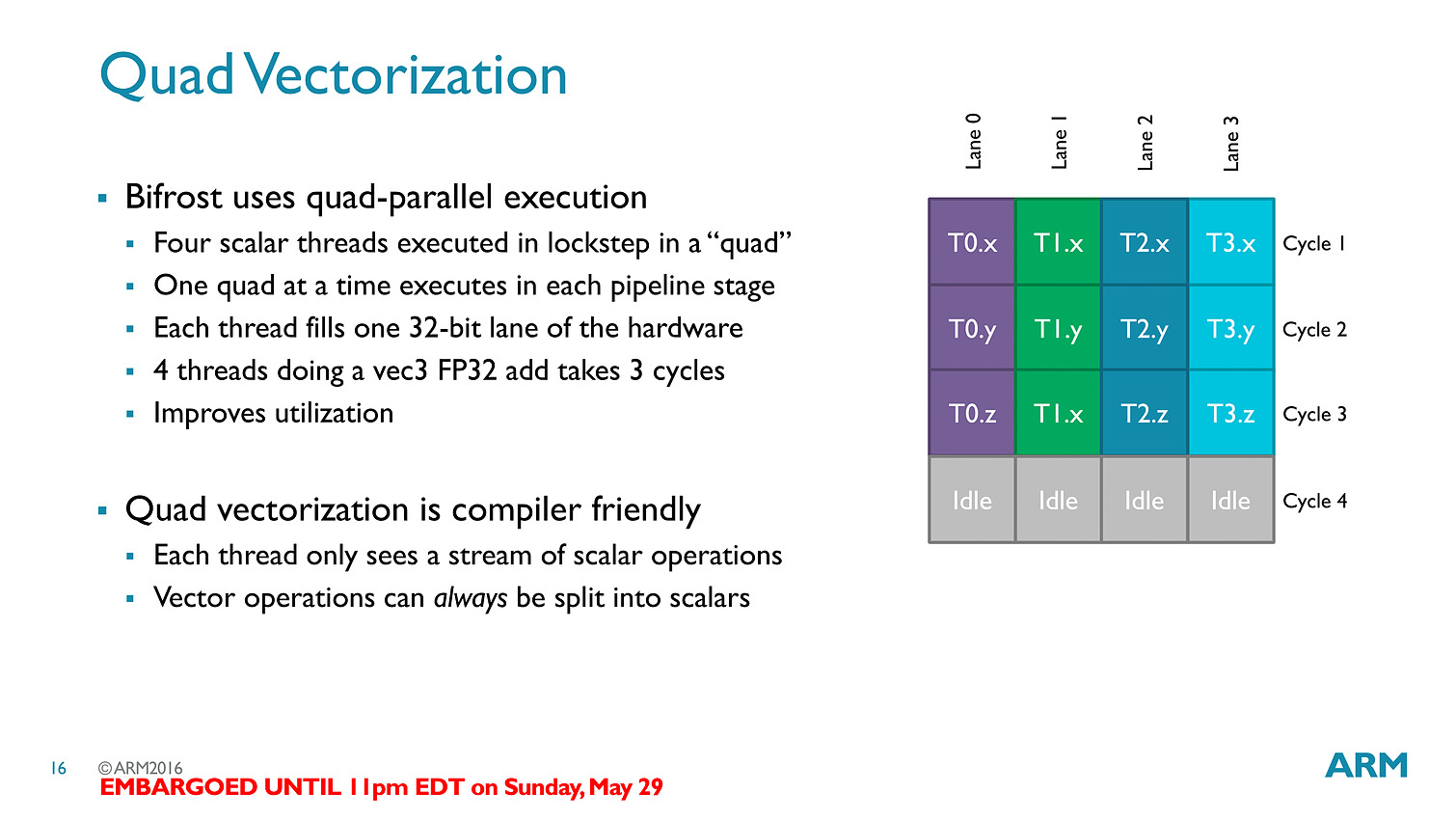
La transition aux unités scalaires change en pratique l'ordre dans lequel les données sont traitées, en simplifiant la compilation des shaders (le parallélisme étant extrait des threads, et non d'assemblage d'instructions par le compilateur).

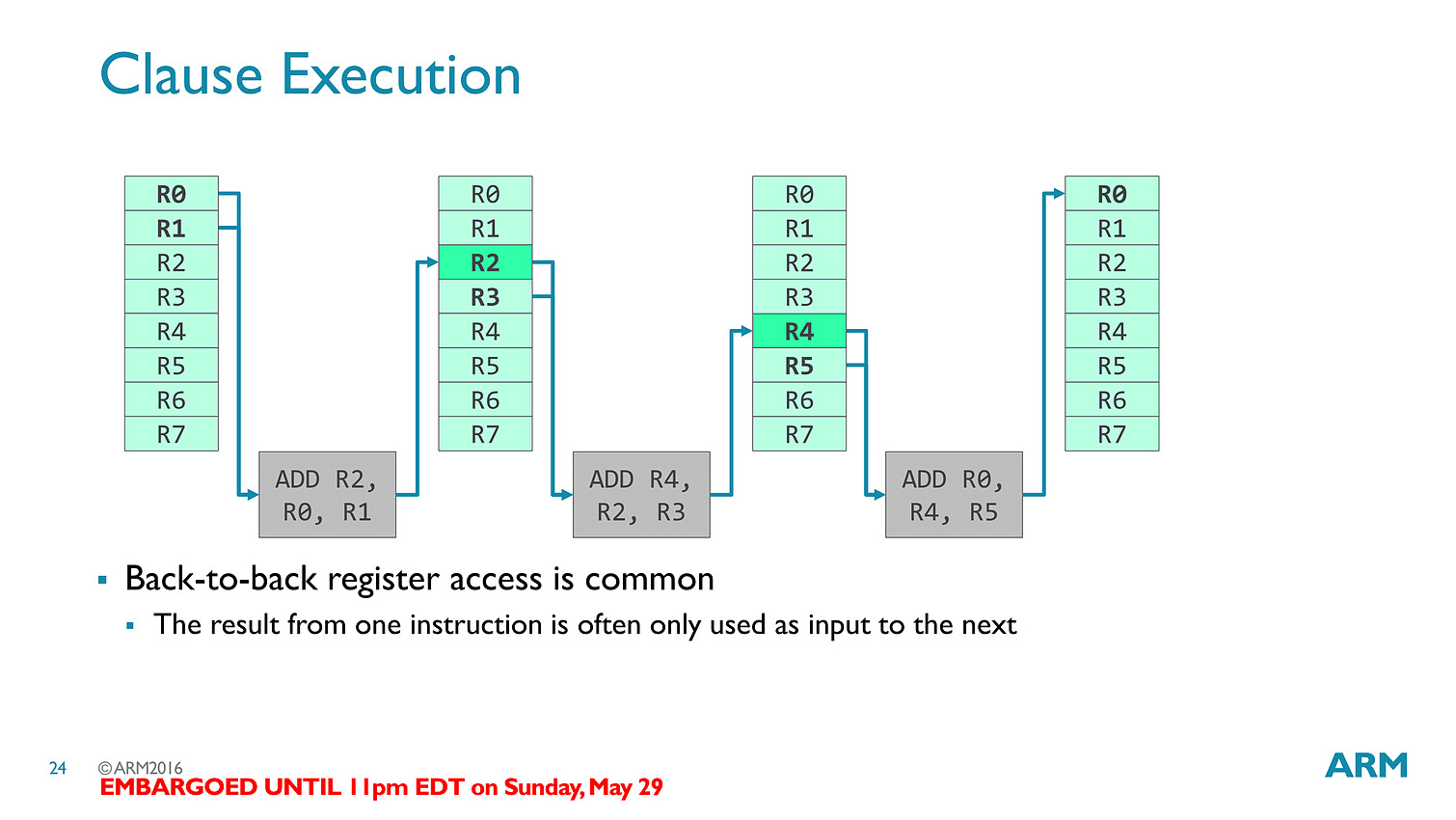
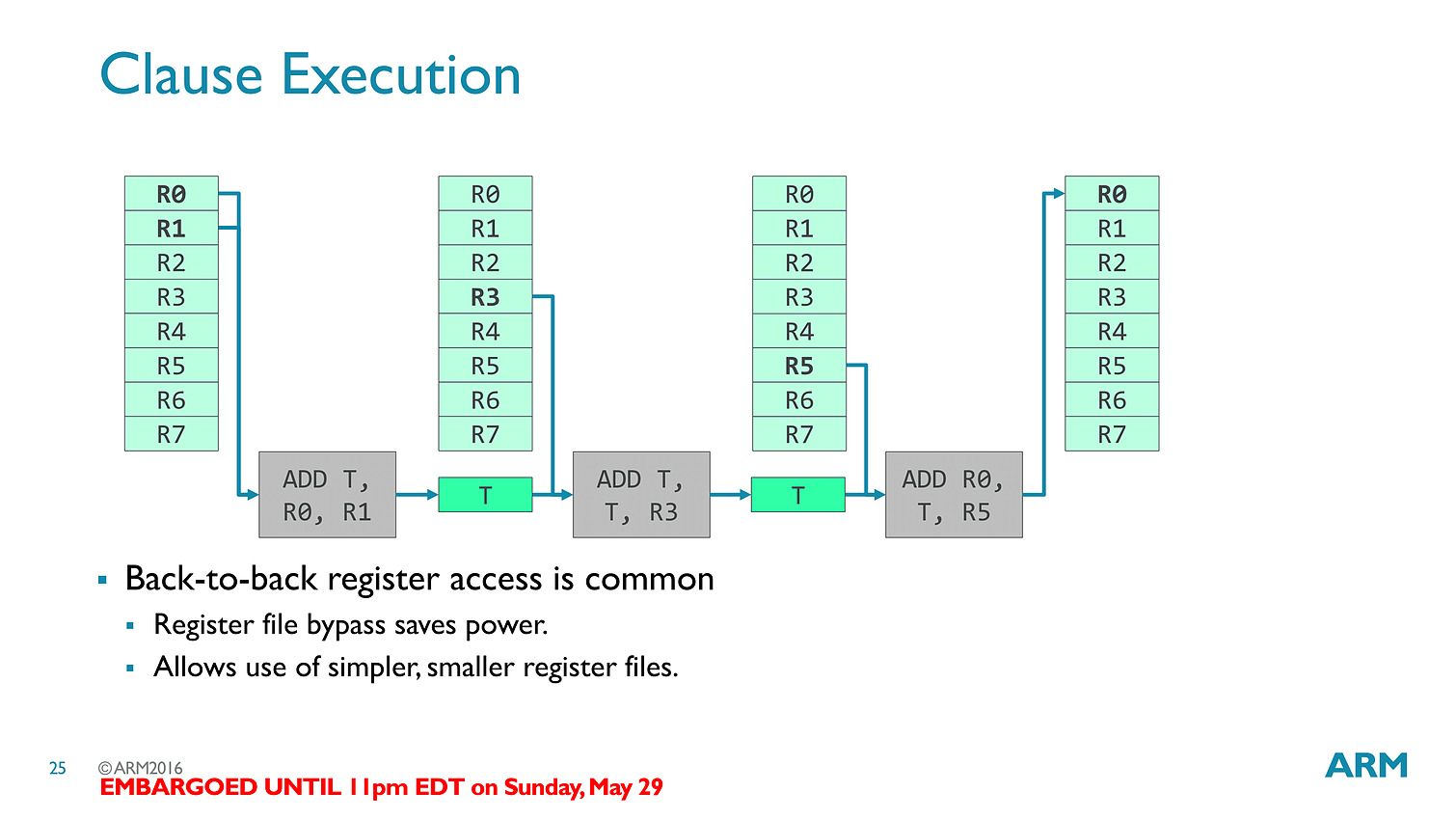

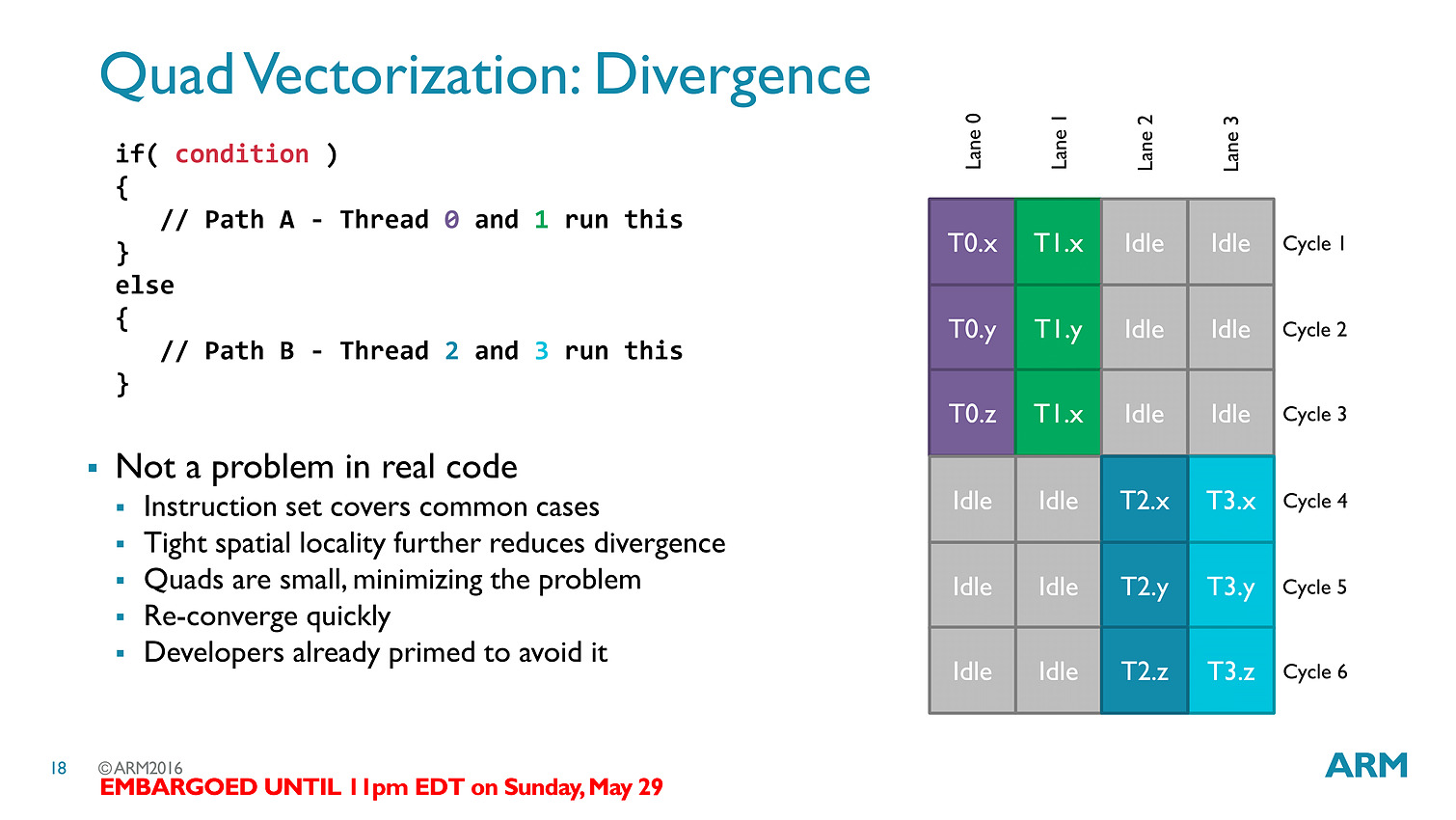
Les threads - clauses dans le langage ARM - sont particulièrement optimisées avec des caches a tous les niveaux (sous la forme de register file) pour s'assurer que les accès mémoires soient optimisés au mieux. Cumulé à tout les autres changements architecturaux (le tiler a également été modifié pour réduire sa consommation mémoire), ARM annonce 50% de gains de performances avec Bifrost.
En pratique le Mali-T71 est le premier GPU ARM utilisant Bifrost, il regroupera jusqu'à 32 shader cores (qui comptent chacun 12 unités scalaires) et reste compatible comme ses prédécesseurs avec OpenGL ES 3.x, OpenCL 2.0 et Vulkan. On rajoutera un dernier mot sur l'interconnexion puisque l'on a droit à un accès au cache fully coherent, ce qui signifie que CPU et GPU peuvent partager la même mémoire cache en opérant en parallèle sans blocage (à la manière de Kaveri chez AMD qui utilisait cependant deux bus distincts), ce qui pourra être utile pour des tâches compute ou l'on fait travailler de concert CPU et GPU (ce qui n'est pas forcément la majorité des usages sur les plateformes mobiles).
1er tape-out 10nm ARM chez TSMC
ARM vient d'annoncer qu'il avait effectué le tape-out d'un puce de test en 10nm chez TSMC. Cette puce intègre 4 coeurs Artemis, le successeur du Cortex-A72, utilisant l'architecture ARMv8-A mais un iGPU simplifié avec un seul coeur graphique. Le communiqué précise que le tape-out, c'est-à-dire l'envoi des informations chez TSMC pour graver la puce, a eu lieu au quatrième trimestre 2015.
ARM a précisé à AnandTech que le tape-out avait en fait eu lieu en décembre, mais que si la validation de la puce de test est un succès il est question d'un retour de la puce chez ARM dans les semaines à venir, soit un délai tout de même assez long.

[ 1 ] [ 2 ]
Du coup les chiffres annoncées, qui font état selon les cas de 11-12% de performances en plus pour une même consommation que le 16nm ou d'une consommation réduite de 30% pour les mêmes performances, sont en fait des simulations. Dans le même temps la densité du 10nm TSMC devrait être jusqu'à 2.1x plus importante que celle du 16nm.
Cette annonce fait suite à un partenariat datant d'octobre 2014 sur le 10nm. Pour rappel le début de la production en volume pour le 10nm chez TSMC est prévu pour 2017, mais à l'instar du 20nm une partie des clients attendront le node suivant (7nm) en 2018.