
Les derniers contenus liés aux tags AMD et ARMv8
Hot Chips : M1, SVE, Parker, InFo et Skylake !
AMD annonce son projet Skybridge et le K12
AMD annonce les Opteron ARM Seattle
AMD : Des Opteron ARM 64-bit en 2014
Hot Chips : M1, SVE, Parker, InFo et Skylake !



La conférence Hot Chips qui se tenait la semaine dernière a donné lieu a d'autres annonces intéressantes que nous avons essayé de regrouper dans cette actualité !
Rajouter des tiers de mémoire côté serveur
On avait déjà noté un peu plus tôt la volonté de rajouter de la mémoire HBM à divers endroits, et même la volonté de Samsung de travailler sur une version moins onéreuse, mais l'on rajoutera ce slide issu d'une présentation d'AMD qui rappelle les objectifs de la société côté serveurs, prenant pour le coup l'exemple du big data
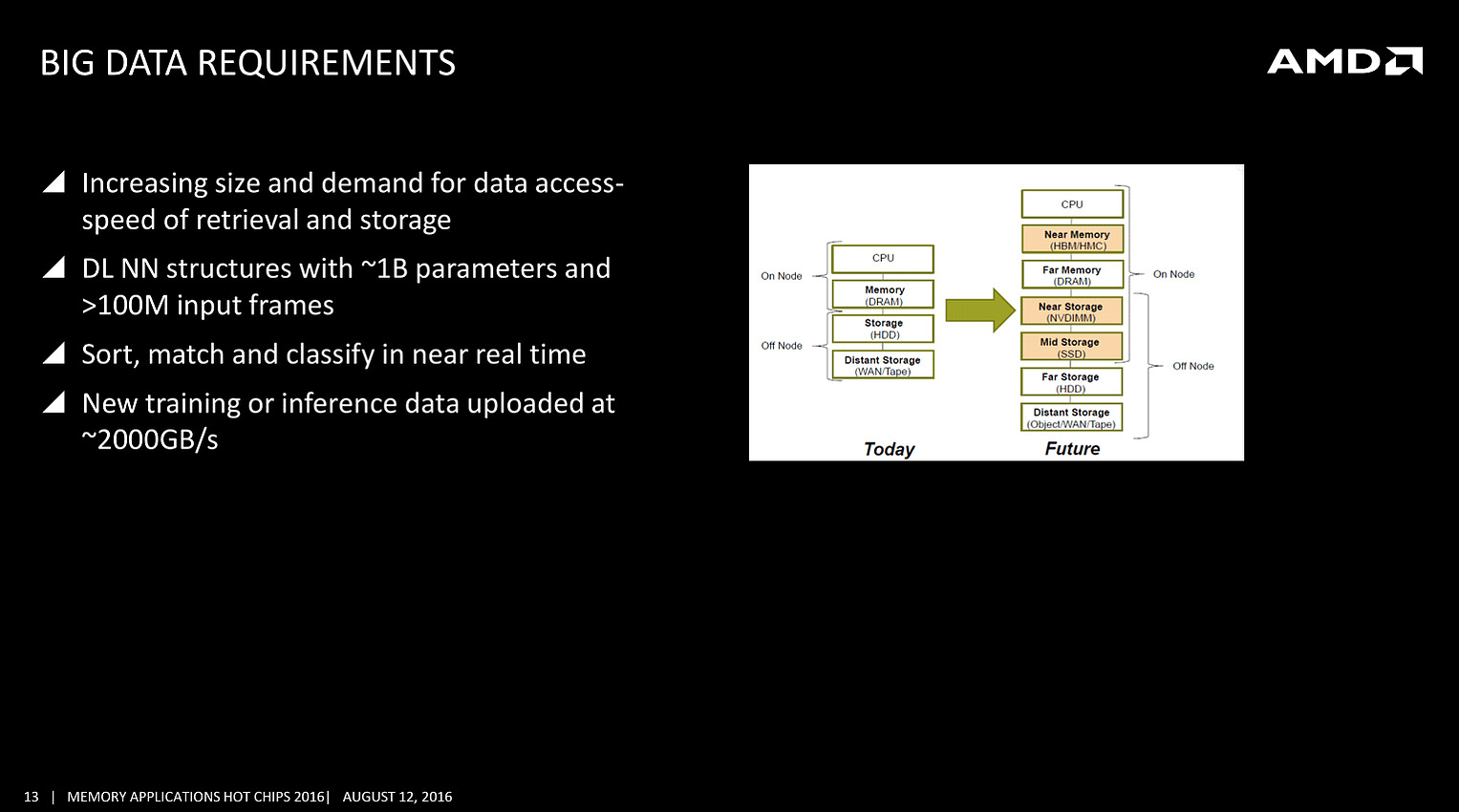
On s'attardera sur le graphique à droite qui pointe l'ajout d'une mémoire intermédiaire côté CPU, type HBM ou HMC (AMD misera plutôt sur la HBM pour les déclinaisons serveurs de Zen), et aussi l'utilisation de NVDIMM pour s'intercaler avant un SSD. Il faudra attendre encore un peu pour voir comment seront déclinées ces technologies, mais il est intéressant de noter la manière dont les avancées côté mémoire sont mises en avant, parfois un peu trop tôt comme l'a fait Intel avec 3D XPoint, dans toute l'industrie.
Quelques détails de plus sur SVE
Chez ARM, outre une présentation de Bifrost côté GPU dont on vous avait déjà parlé, l'annonce principale concernait SVE, la nouvelle extension vectorielle introduite par la société.
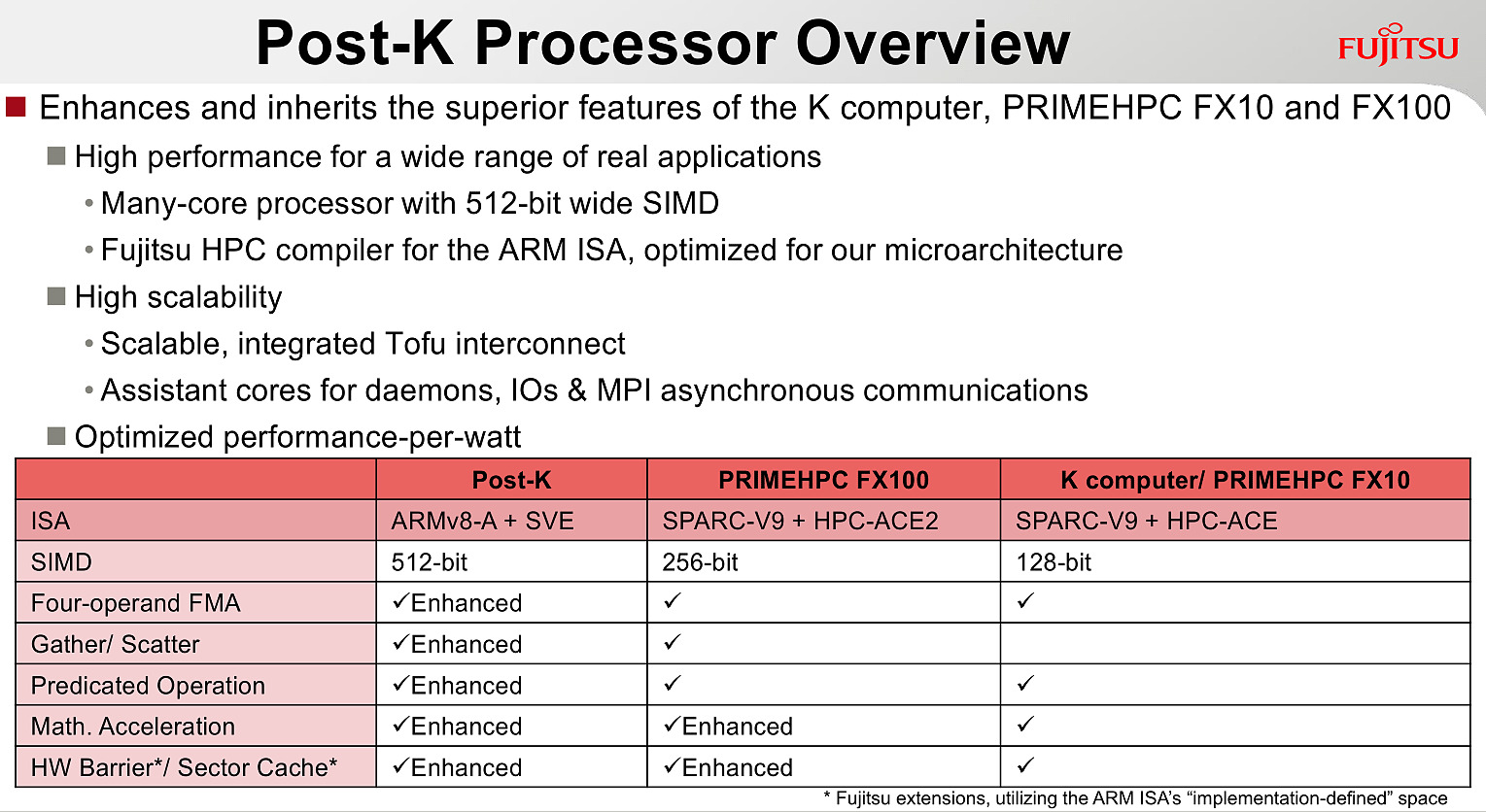
Le premier partenaire annoncé par ARM est Fujitsu, qui mettra au point des processeurs ARMv8 avec extension SVE pour le futur supercalculateur japonais Post-K. Fujitsu a donné quelques détails, indiquant par exemple que les unités vectorielles auraient une largeur de 512 bits sur ses puces.


Chez ARM, le constructeur présente plusieurs benchmarks assez théoriques, on notera surtout sur les barres grises les améliorations qui ont été effectuées côté auto-vectorisation, c'est a dire la capacité du compilateur à utiliser des instructions vectorielles pour extraire du parallélisme. ARM devrait proposer dans les semaines qui viennent des patchs pour les différents compilateurs open source, incluant LLVM et GCC.
Le Samsung M1, un timide premier pas
La particularité de l'écosystème d'ARM est que les partenaires peuvent soit utiliser des coeurs "clefs en main", développés par ARM (les gammes Cortex, comme par exemple le Cortex A57), ou créer leurs propres implémentations de l'architecture ARM (qui restent compatibles, tout en étant différentes, à l'image des processeurs d'AMD et d'Intel qui diffèrent bien que restant compatibles). Plusieurs sociétés disposent de licences "architecture" qui permettent de créer ces puces, Apple étant jusqu'ici la société la plus à la pointe sur armv8 même si de nombreuses sociétés proposent tour à tour leurs architectures.

Parmi les nouveaux venus, il y a Samsung qui s'est lancé lui aussi dans le design d'une architecture armv8 custom pour ses Exynos M1. A la tête du projet, on retrouve Brad Burgess qui était architecte chez AMD pour les Bobcat. Il aura même été rejoint un court instant par Jim Keller (K8 chez AMD, A7 chez Apple, puis Zen chez AMD), qui n'est cependant pas resté très longtemps chez Samsung et qui n'aura probablement pas eu un grand impact. Le projet aura nécessité trois années, et en soit arriver a produire quoique ce soit du premier coup en un temps si court est un exploit.
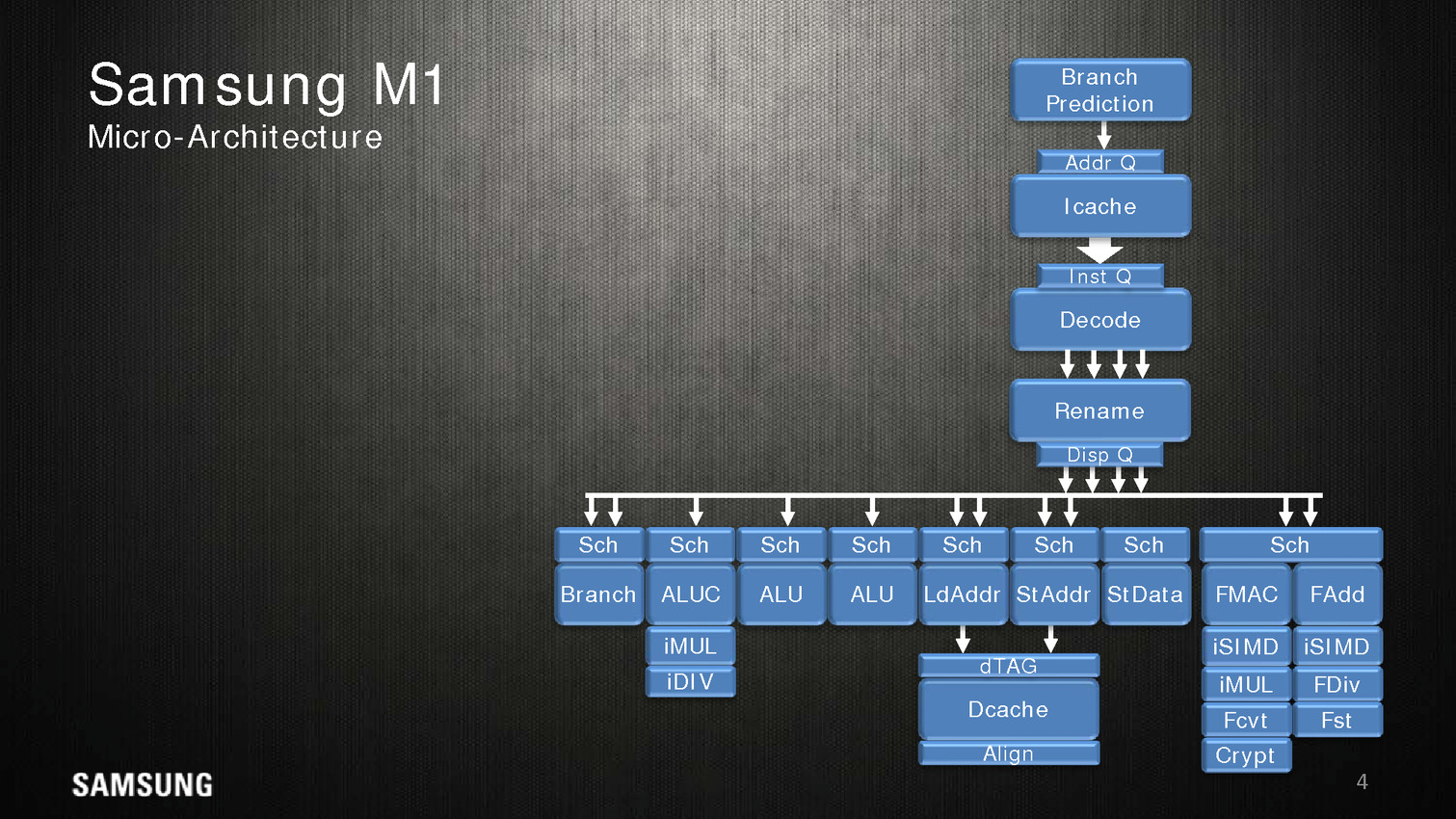
Côté architecture, Samsung indique utiliser un perceptron (un réseau de neurones simple) au niveau de ses mécanismes de prédiction de branches. Deux branches sont considérées par cycle, mais il est difficile d'estimer quoique ce soit sur l'éventuelle efficacité.
Quatre instructions peuvent être décodées/dispatchées par cycle aux unités d'exécutions qui sont regroupées sur sept files. On note deux files dédiées aux écritures mémoires, trois aux opérations mathématiques simple (avec un port sur lequel sont ajoutés les multiplications/divisions) et une aux branchements. Les opérations en virgules flottantes sont regroupées séparément avec un scheduler unique pour deux files. Samsung annonce 5 cycles pour effectuer une opération FMA.
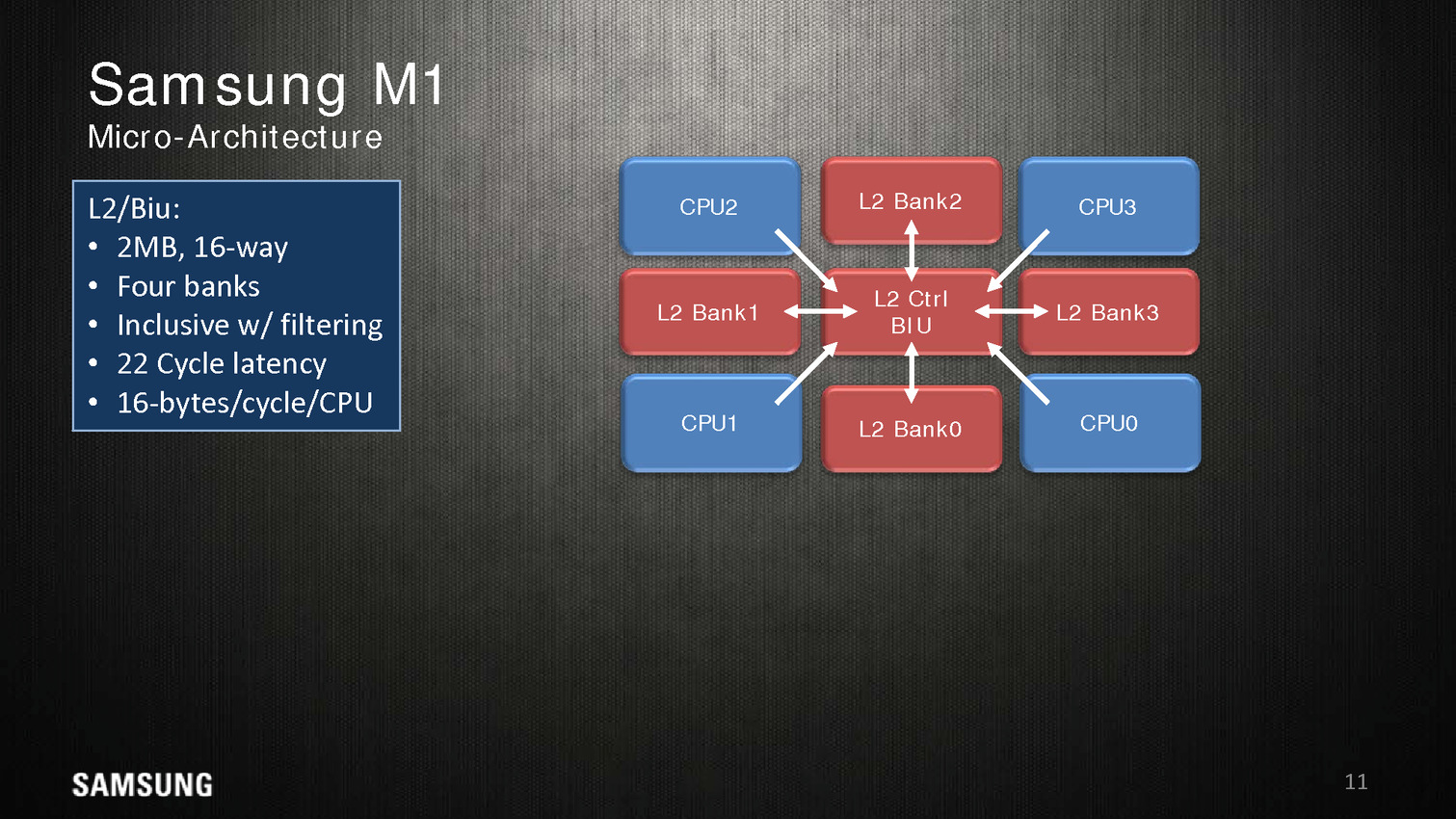
Dans une configuration quatre coeurs, le M1 dispose de 2 Mo de cache L2 coupé en quatre blocs, les coeurs accèdent au L2 via une interface commune. On appréciera aussi les schémas très spécifiques que propose Samsung, pas vraiment avare de détails techniques.

Reste qu'en pratique, les benchmarks mis en avant par Samsung ne sont pas forcément très convaincants. Avec 200 MHz de plus, sur un coeur, un M1 propose 10% de performances en plus qu'un Cortex A57 à consommation égale, ce qui est tout de même très peu. Samsung fait beaucoup mieux sur les opérations mémoires (c'est relativement facile, on l'a évoqué de nombreuses fois, les contrôleurs mémoires ARM ne sont pas particulièrement véloces/adaptés aux hautes performances), mais n'en tire pas particulièrement profit hors des benchmarks théoriques.
La présentation se termine en indiquant que ce n'est qu'un premier pas pour Samsung et que d'autres designs sont en cours d'élaboration. En soit si les performances ne vont pas révolutionner le monde des SoC ARM, Samsung a au moins une base de travail qu'ils pourront faire évoluer par la suite. A condition évidemment que Samsung continue d'investir sur le sujet dans les années à venir !
Les curieux pourront retrouver la présentation en intégralité ci dessous :














Parker/Denver 2 : design asymétrique
Nvidia était également présent à Hot Chips, donnant quelques détails sur son futur SoC baptisé Parker. Ce dernier est annoncé comme crée spécifiquement pour le marché automobile avec des fonctionnalités dédiées à ce marché. On ne sait pas si le constructeur le déclinera en d'autres versions plus génériques.

Les détails techniques ne sont pas particulièrement nombreux, on notera côté SoC que l'encodage 4K est désormais accéléré à 60 FPS, que l'on peut contrôler jusque trois écrans en simultanée, et que le contrôleur mémoire passe sur 128 bits (contre 64 précédemment). Côté GPU, Parker utilisera une version dérivée de son architecture Pascal.



C'est du côté CPU que les choses sont les plus originales, après avoir utilisé son architecture Denver sur les TK1, puis être revenu aux Cortex A57 sur les TX1, Nvidia propose une architecture asymétrique avec deux coeurs "Denver 2" (sur lesquels aucun détail n'aura été donné, à part un gain performance/watts de 30% donné sans précision sur les process comparés) et quatre coeurs Cortex A57. Ce n'est pas la première fois que l'on voit des configurations originales, durant Hot Chips, le taiwannais MediaTek présentait un SoC 10 coeurs avec quatre coeurs Cortex A53 à 1.4 GHz, quatre coeurs Cortex A53 à 2 GHz, et deux coeurs Cortex A72 à 2.5 GHz !
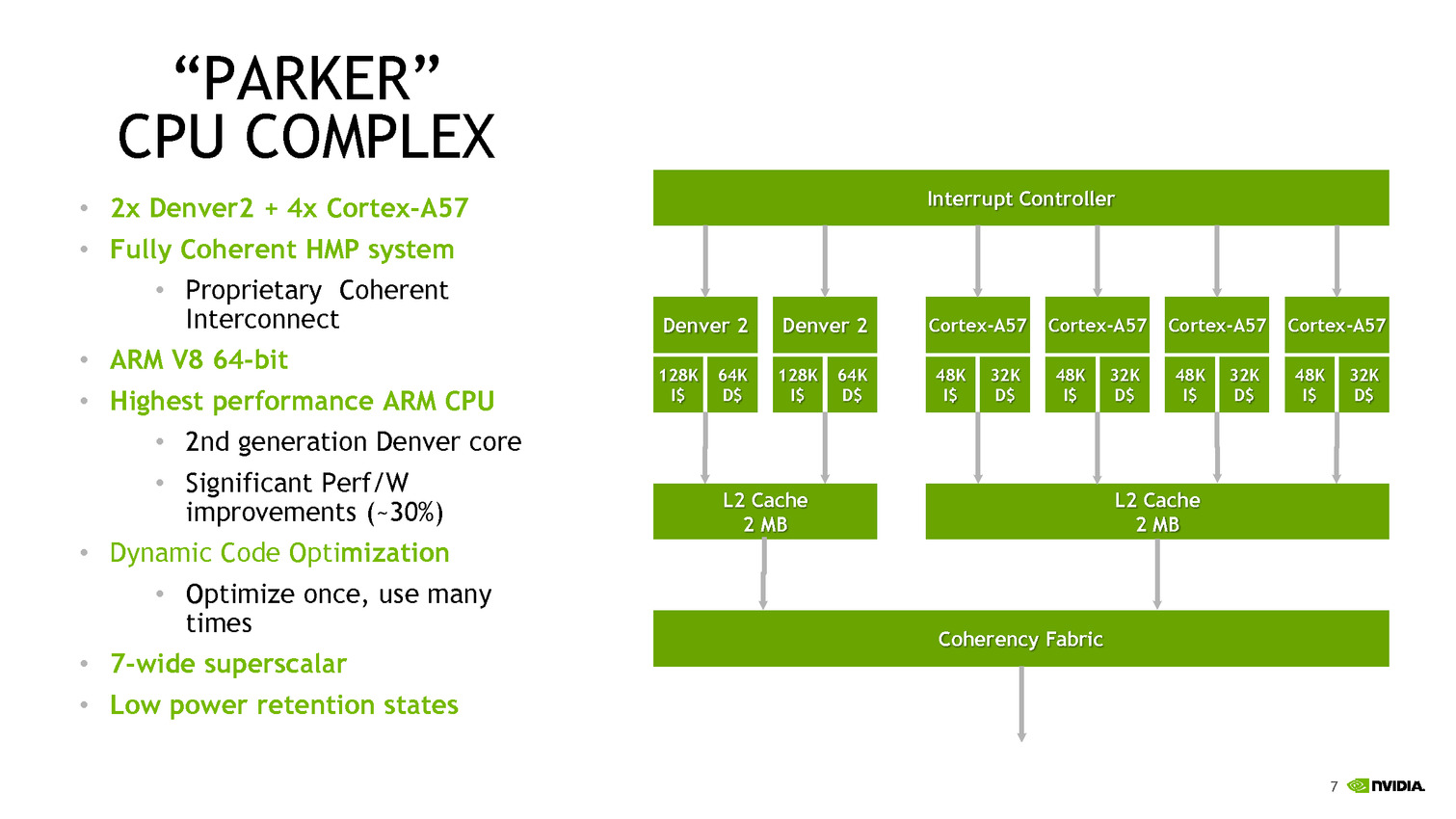
Dans le cas de MediaTek, l'idée est de proposer différentes options à différents niveaux de consommation. Pour ce qui est de Nvidia, le choix est différent, le Cortex A57 étant "haute performance" contrairement aux A53 de MediaTek. Il faut dire surtout que le marché visé, l'automobile, n'a pas les mêmes contraintes de consommation que le marché mobile. Reste que Nvidia se doit de gérer cette asymétrie avec un scheduler qui doit décider sur quel coeur placer les threads, ce qui n'est pas particulièrement simple. On notera que chaque groupe de coeurs dispose de son propre cache L2 de 2 Mo.
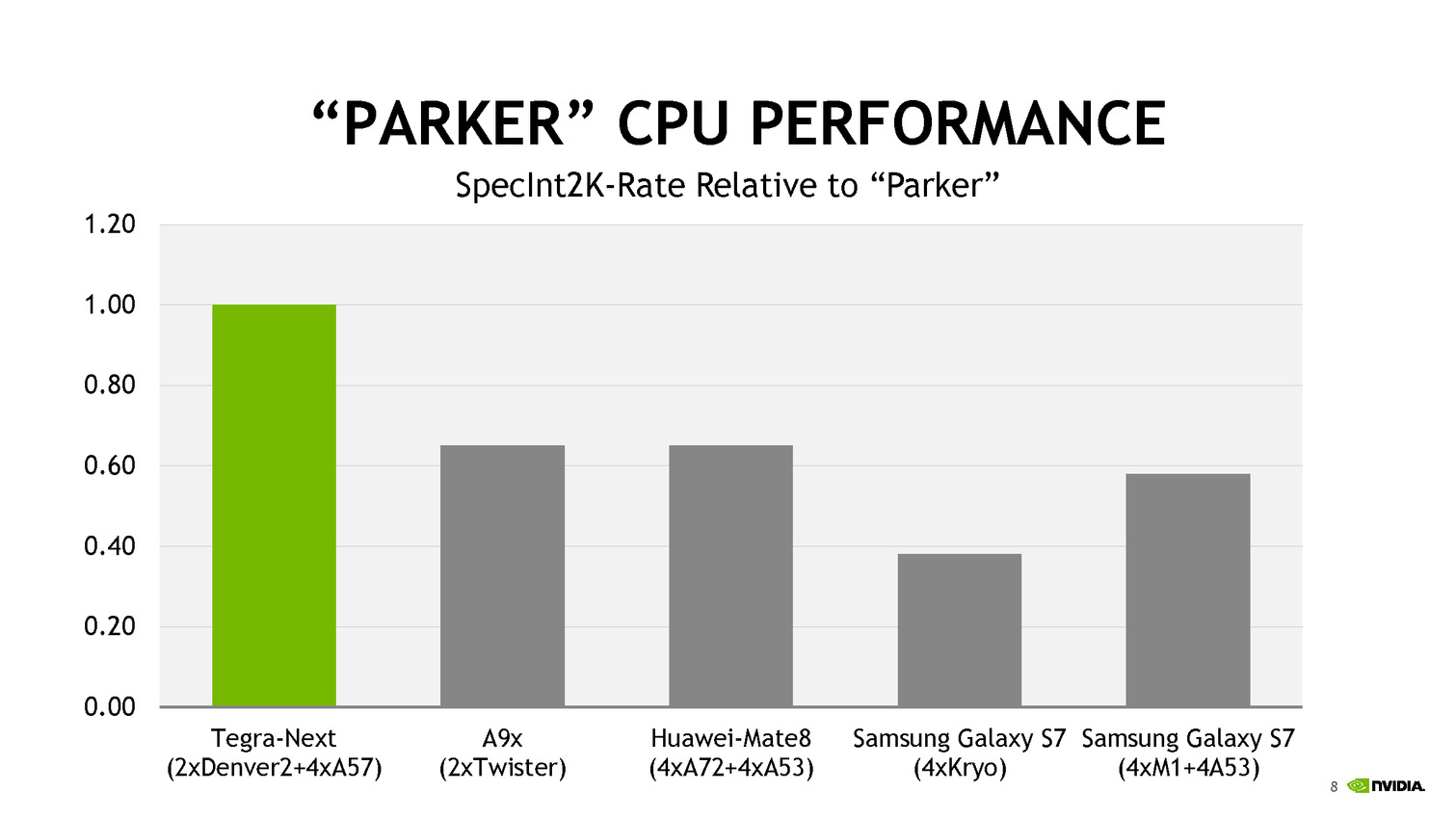
Côté performances, Nvidia avec ses 6 coeurs se présente comme moitié plus rapide qu'un A9X d'Apple en deux coeurs. Le graphique mélangeant des puces à TDP différents (on y retrouve des puces pour smartphones et pour tablettes), on admettra que la comparaison n'est pas faite à TDP identique.
TSMC parle de ses packages InFo
Une des nouveautés présentées cette année par TSMC est la disponibilité d'un nouveau type de packaging, l'InFo-WLP. L'idée est de permettre de relier plusieurs dies en les "moulant" dans un substrat commun très fin qui contient également les interconnexions entre les puces. Il s'agit d'une version à cout beaucoup plus faible que les interposer (utilisés par exemple par AMD pour Fiji).
La présentation de TSMC est dédiée aux interconnexions entre les puces, et présente une puce 16nm reliant un SOC à une puce mémoire avec une bande passante de 89.6 Go/s sur 256 bits, le tout avec une consommation très réduite.
En plus de la solution présentée qui évoque le cas simple d'une puce mémoire et d'un Soc, TSMC évoque la solution comme permettant un jour de relier également plusieurs dies de logique, par exemple des groupes de coeurs séparés, pour réduire le coût de fabrication des puces (qui augmentent exponentiellement avec la taille des dies).
































La présentation est technique mais reste intéressante, l'InFo-WLP ouvre des opportunités supplémentaires pour réaliser des produits qui mélangent processeur et mémoire. Le coût réduit et la finesse de l'interconnexion fait qu'on pourrait retrouver assez rapidement cette technique utilisée, y compris sur le marché mobile. Les prochains SoC d'Apple pourraient par exemple utiliser un tel package.
Et Skylake !
Juste avant la présentation de Zen, Intel proposait aussi une présentation de son architecture Skylake, lancée l'année dernière. Si la majorité du contenu est déjà connu, on aura noté un détail intéressant : un diagramme sur les unités d'exécution de Skylake. On rappellera que l'année dernière durant l'IDF, Intel nous avait promis plus de détails sur le sujet, sans jamais nous les donner !
Pour rappel, voici la répartition sur Haswell :
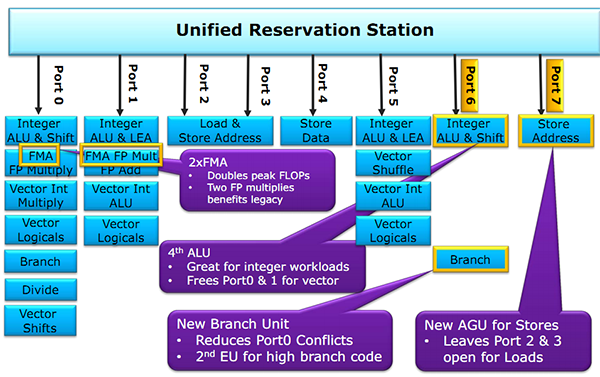
Récapitulatif des ports/unités d'exécution sur Haswell
Un an après, voici enfin un diagramme similaire pour Skylake :
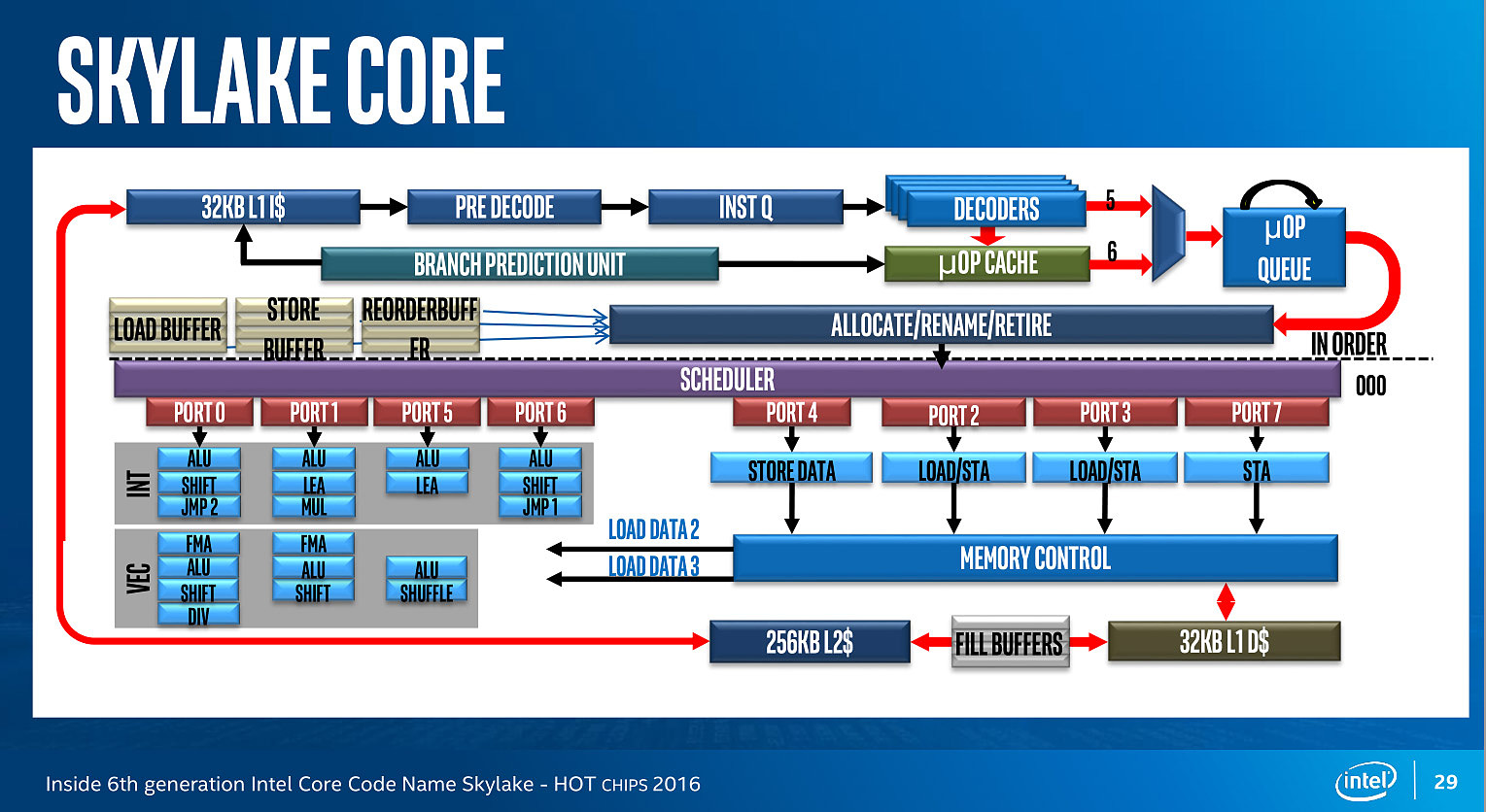
Conformément à ce que nous avaient indiqué les ingénieurs d'Intel l'année dernière, le nombre d'unité a bel et bien augmenté. Le nombre de ports reste constant, à 8, mais l'on compte... une nouvelle unité. Sur le port 1, Intel a en effet ajouté une unité de shift vectorielle. Pour le reste, la répartition reste similaire à celle d'Haswell. Un mystère enfin élucidé !
AMD annonce son projet Skybridge et le K12
Ce n'était plus vraiment un secret, AMD s'intéresse de très près a ARM depuis quelques temps. Un intérêt qui s'était concrétisé avec l'annonce de Seattle, un SoC serveur fabriqué en 28nm qui prendra place dans la gamme Opteron, basé sur des cores ARM Cortex-A57. Lors d'une conférence dédiée aux investisseurs ce soir, AMD a effectué une (longue) démonstration de sa plateforme Seattle faisant fonctionner une installation LAMP (Linux, Apache, MySQL, PHP). AMD tenant à insister quelque peu maladroitement sur le fait que l'écosystème logiciel côté serveur n'est pas marié indubitablement au x86. C'est certes vrai, mais la démo au final aurait pu fonctionner de la même manière sur un simple NAS d'entrée de gamme équipé d'un ARM 32 bits !

Les prévisions d'AMD montrent un tassement du marché x86 dans les années à venir au profit d'ARM.
La vraie raison de cette conférence aux investisseurs n'était heureusement pas cette démonstration, mais l'annonce des projets à venir. C'est pour 2015 que les choses s'échaufferont avec l'arrivée d'ARM dans la gamme AMD ailleurs que dans les serveurs. C'est à cela que correspond le projet Skybridge. Il s'agit d'une prochaine génération de SoC qui sera basée sur un process 20nm (AMD n'a pas précisé s'il s'agissait de TSMC ou de GlobalFoundries). On retrouvera une base SoC commune (une « fabric ») avec un GPU GCN, le support de HSA et au choix des cores « Puma+ » ou des cores Cortex-A57.

L'avantage de la solution est de proposer des SoC qui seront « pin compatible » permettant de créer des designs uniques (au niveau des cartes mères) qui pourront accueillir au choix des SoC ARM et x86. Une idée qui permet en théorie de donner plus de flexibilité aux développeurs de matériels pour créer par exemple un design commun de tablette x86 ou ARM. AMD n'a pas évoqué précisément de marché visé mais le sous-entendu étant de viser plus effectivement le marché des tablettes au moins en 2015. Si les smartphones ont été évoqués brièvement AMD n'a pas confirmé à partir de quand une déclinaison serait disponible, indiquant simplement ne pas chercher à viser la partie « entrée de gamme » de ce marché.

L'autre annonce concerne ce qui se passera à partir de 2016. Actuellement AMD n'utilise que des curs génériques conçus ARM, mais cela va changer. Le constructeur a annoncé disposer d'une licence « architecture » auprès d'ARM, une licence déjà utilisée par AMD pour concevoir l'architecture « K12 » qui sera une implémentation custom d'armv8 (à l'image de ce qu'a proposé Apple avec son A7).
En entrant sur le marché ARM, et plus particulièrement des designs customs, AMD arrive un peu tard sur un marché très ouvert, mais aussi très concurrentiel et ou les marges sont en général minces. Une situation renversée par rapport au marché x86 ou AMD n'a qu'un concurrent et où il profite, malgré tout, de marges historiquement plus importantes. En proposant des Cortex-A57 génériques pour 2015, AMD jouera avant tout sur son expertise graphique et son architecture GCN pour se différencier.
A sa décharge, AMD ne sera pas le seul à proposer des cores ARM génériques en 2015 suivi d'une architecture custom plus tard, c'est la stratégie qu'utilisera par exemple Qualcomm qui a annoncé des Snapdragon 808 et 810, Cortex-A57 (et A53) en 20nm fabriqués chez TSMC pour 2015 également en attendant un successeur de Krait (l'architecture custom de Qualcomm en 32 bits) pour plus tard.
AMD annonce les Opteron ARM Seattle
AMD a profité de l'Open Compute Summit (une conférence issu de l'Open Compute Project démarré par Facebook ) pour annoncer officiellement ses SoC serveurs basés sur une architecture ARM.
Ce n'est pas une surprise puisque le constructeur avait annoncé son intention dès 2012 suite au rachat de SeaMicro et l'année dernière, les roadmaps du constructeur incluaient l'arrivée d'un premier SoC baptisé Seattle pour la seconde partie de l'année 2014.

AMD annonce donc officiellement ces SoC qui porteront le nom d'Opteron A1100. Comme indiqué précédemment, AMD utilisera des cores Cortex-A57 de design ARM, et non un design custom. Ces derniers sont compatibles avec l'architecture ARMv8 qui apporte pour rappel le support du 64 bits. Ces puces sont destinées à des serveurs visant des charges légères (serveurs web, etc) à l'image des Opteron X1150 et X2150.
Ces SoCs sont fabriqués par GlobalFoundries en 28nm et intègrent huit curs Cortex-A57 et quatre Mo de cache de niveau 2, auquel AMD rajoute des blocs customs. Le tout fonctionne à une fréquence annoncée comme supérieure à 2 GHz pour un TDP de 25 watts.
Parmi les fonctionnalités custom, AMD intègre un contrôleur mémoire 128 bits compatible à la fois avec les standards DDR3 et DDR4. On retrouve également 8 lignes PCI Express 3.0 ainsi que de quoi gérer huit disques Serial ATA 6 Gb/s et deux ports 10 GbE.

AMD mettra à disposition un kit de développement en mars, mais il faudra attendre le quatrième trimestre pour voir arriver ces solutions dans le commerce. AMD dispose d'ambitions élevées avec ARM côté serveur, espérant pouvoir profiter de son expérience sur le marché de l'Opteron ainsi que celles acquises avec SeaMicro pour en capter une part importante.
AMD profite également du vide laissé par l'arrêt de Calxeda à la fin du mois de décembre dernier pour se positionner. Reste que la disponibilité annoncée seulement pour le quatrième trimestre risque d'être tardive pour ce qui reste un SoC 28nm utilisant des cores non custom, et l'on devrait voir d'ici là d'autres acteurs émerger, possiblement en 20nm.

On notera enfin avec attention qu'AMD n'hésite pas à jouer la carte de l'alternative face au x86 indiquant que les OEM, ODM et les clients souhaitent « qu'ARM gagne », ce que l'on comprend entre les lignes comme une rébellion envers Intel dont la domination du marché x86 serveur s'accompagne de marges importantes. Reste à voir si la vision d'AMD se cantonne aux serveurs, ou s'il s'agit d'une vision plus générale, AMD déclinant déjà le x86 sur de multiples marchés.
AMD : Des Opteron ARM 64-bit en 2014
Depuis près d'un an, AMD a déclaré à plusieurs reprises rester ouvert à la possibilité future de mettre au point des solutions basées sur le jeu d'instruction ARM et de ne plus se cantonner au x86. En juin dernier, le texan était déjà allé un petit peu plus loin en expliquant qu'il aurait recours à l'avenir à un core Cortex A5 dans tous ses CPU et APU x86 de manière à pouvoir profiter de l'écosystème sécurisé TrustZone d'ARM et ainsi éviter le coûteux développement d'une alternative à la Trusted Execution Technology d'Intel (TXT).
Aujourd'hui, à l'occasion d'une présentation à ses investisseurs, AMD a cette fois mis en avant un futur produit qui utilisera l'architecture ARM d'une manière directe : des Opteron ARM 64-bit. Pour cela, contrairement à Nvidia ou Qualcomm, AMD se contentera dans un premier temps d'une licence processeur pour un futur core et non d'une licence d'architecture ARMv8. En d'autres termes, AMD ne développera pas son propre core mais intégrera directement une macro fournie par ARM, qui en propose chez les fondeurs principaux tels que TSMC et GlobalFoundries. Le but est ici d'aller très vite.
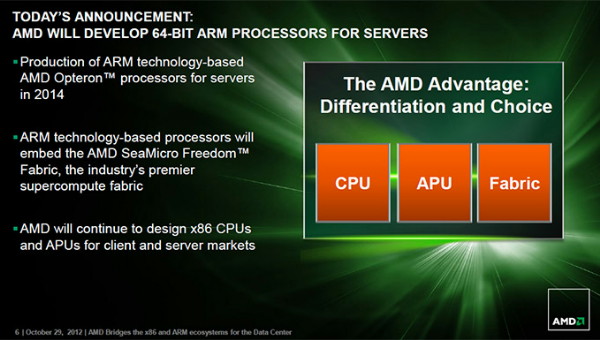
Une révolution ? Oui et non. Non parce que plus qu'un changement de stratégie, il s'agit en réalité probablement de la poursuite de la roadmap que SeaMicro, spécialiste des micro-serveurs, avait prévue avant son rachat par AMD. Mais oui parce que cette roadmap est probablement la raison pour laquelle AMD a procédé à cette acquisition.
Ce futur Opteron ARM 64-bit sera ainsi probablement destiné exclusivement à ces micro-serveurs et profitera de l'intégration dans la même puce de l'interconnexion Freedom Fabric, le tissu réseau qui fait la force de SeaMicro. AMD explique d'ailleurs qu'un CPU ARM directement connecté au réseau serait peu efficace contrairement aux CPU x86 puisque la puissance plus faible par lien réseau reviendrait à performances égales à multiplier ces liens qui ne pourraient par ailleurs pas être exploités pleinement. Or l'efficacité du réseau est primordiale pour un serveur, d'autant plus si il vise une efficacité énergétique élevée.
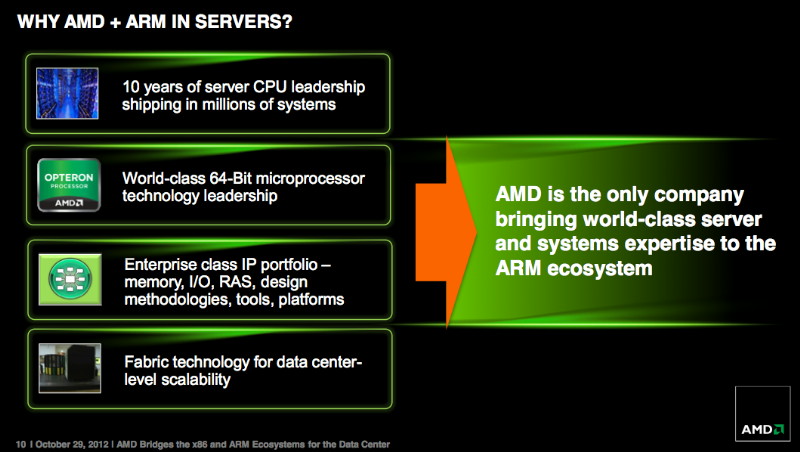

Pour AMD, ces futurs CPU ARM n'ont ainsi réellement de sens qu'une fois liés au tissu réseau de SeaMicro, qui revient en pratique à les organiser en grappes et à mettre en place les liens réseau au niveau de ces grappes. De quoi profiter pleinement de leur efficacité énergétique pour le traitement de tâches qui leur sont adaptées : principalement tout ce qui est serveur web.
La concurrence sera probablement rude, Qualcomm, Samsung et Nvidia étant également intéressés par ce créneau. AMD espère pouvoir se démarquer grâce à son expérience dans le monde des serveurs et en profitant bien entendu de l'interconnexion SeaMicro. Parallèlement à cela, AMD continuera à développer des Opteron x86 qui resteront plus puissants et mieux adaptés à d'autres marchés.

Cette stratégie sera-t-elle payante pour AMD ? Impossible de répondre à cette question tant les implications sont énormes. En sortant de l'écosystème x86, AMD s'ouvre potentiellement à d'autres marchés, mais des marchés où la concurrence pourrait être rude et qui risquent de grignoter des parts au x86, pour lequel un seul concurrent existe, certes de plus en plus difficile à battre. Difficile donc de ne pas penser qu'il aurait également pu être intéressant pour AMD de proposer un Opteron intégrant des cores Jaguar et l'interconnexion de SeaMicro.