
Impact des compilateurs sur les architectures CPU x86/x64
Publié le 28/02/2012 par Guillaume Louel



SSE, AVX : le problème de la vectorisationPlus tôt, nous évoquions le fait qu'AVX permette de travailler sur des opérandes (des données) d'une taille de 128 ou 256 bits. Il s'agissait d'un raccourci. En effet, la plupart du temps les programmeurs travaillent avec des nombres encodés sur 32 (entre -2,1 milliard et +2,1 milliard environ) ou 64 bits (on parle de double précision+/- 9 trillions). Il s'agit des types de données qui sont proposés par les langages de programmation comme C et C++. Si l'on met de côté quelques cas très rares, stocker et travailler sur des nombres sur 128 ou 256 bits n'a généralement pas beaucoup d'intérêt, et ce n'est d'ailleurs pas vraiment à cela que sert AVX.
L'acronyme, qui signifie Advanced Vector eXtension donne la réponse : il s'agit d'instructions vectorielles, c'est-à-dire capables de travailler sur un tableau de données. Une instruction AVX 256 bits peut ainsi travailler sur 8 données de 32 bits en simultanée, ce qui permet d'améliorer significativement la rapidité d'exécution d'un programme, pour peu que l'on ait besoin d'effectuer 8 opérations identiques en parallèle !
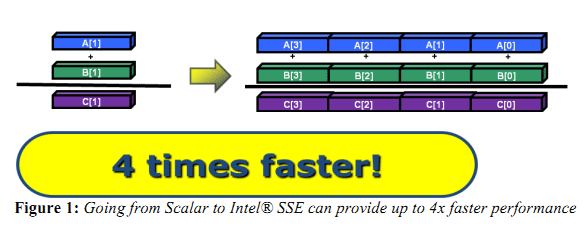
Le cas idéal de la vectorisation, travailler sur quatre données en simultanée permet de quadrupler la rapidité d'execution. Extrait d'un PDF Intel
C'est bien sûr ici que les choses deviennent complexes car les langages que sont C et C++ ne sont pas réellement adaptés à cette vision sous forme de tableaux. Les programmes utilisent des variables, qui stockent les informations en fonction de leur type (nombre entier, nombre à virgule, etc) et s'il existe bien une notion de tableaux (plusieurs données du même type), le langage ne fournit pas d'opérations qui s'appliquent directement à ceux-ci (comme ajouter le contenu d'un tableau A à un tableau B). C'est le rôle du développeur de réaliser des algorithmes qui effectueront ces opérations, dont certaines deviennent aujourd'hui accélérées par les processeurs via AVX. En pratique, l'absence de structures (dans C et C++) nativement adaptées à la manière dont fonctionnent désormais en interne les processeurs devient un vrai problème pour lequel plusieurs réponses sont apportées.
Remplacer les opérations mathématiquesDans certains cas, utiliser une instruction vectorielle avec une seule donnée peut être plus rapide qu'utiliser son équivalent classique. C'est particulièrement le cas lorsque l'on parle de calculs en virgule flottante pour des raisons historiques. En effet ces opérations que l'on appelle x87 étaient gérées dans les années 80 par des coprocesseurs arithmétiques. Même si ces dernières ont été fusionnées dans les processeurs (via les 486 DX et les Pentium), elles gardent les lourdeurs de fonctionnement de l'époque, à savoir une gestion qui s'effectue sous forme de pile. SSE, SSE2 et AVX proposent aujourd'hui des instructions qui permettent de remplacer x87, laissant tomber le concept de pile et rendant leur exécution beaucoup plus rapide. Utiliser une instruction vectorielle pour une seule donnée peut donc être plus rapide. Notez que si tous les compilateurs proposent ce genre d'optimisations, par défaut, Visual Studio continue de compiler en x87.
Vectorisation automatiqueSi l'on veut vraiment profiter de la puissance de calcul en parallèle offerte par les instructions vectorielles, on pourrait penser qu'il serait bon de demander aux compilateurs de détecter les cas où les développeurs travaillent sur des tableaux dans leurs programmes. Le compilateur pourrait alors réaliser une vectorisation automatique. Dans ce cas, le compilateur interprète le code C/C++ (il s'agit généralement de boucles qui répètent une instruction) pour générer automatiquement du code en langage machine utilisant des instructions vectorielles.
En théorie, l'idée est excellente. En pratique, le code existant n'est pas forcément écrit pour être vectorisé. En dehors des cas simples, il faudra souvent que le développeur réécrive son code pour retirer des dépendances. En effet si à l'heure du multimédia on peut penser que tous les traitements sont parallèles, le niveau de parallélisme (on parle de granularité) ne s'arrête pas forcément à une instruction dans les cas pratiques. Quand elles s'enchainent, et que les résultats d'un traitement peuvent dépendre d'un résultat précédent (ce que l'on appelle une dépendance), la vectorisation devient rapidement impossible (d'autres problèmes existent comme la gestion des sauts dans le code qui ne convient pas réellement au SIMD). Il est souvent possible de réécrire son code pour qu'il le devienne, mais le compilateur, seul, ne peut pas interpréter "l'idée" derrière un algorithme complexe pour le réécrire à la place du développeur, probablement dans une version moins lisible ou logique pour lui, mais qui le deviendrait pour le compilateur.
En pratique, nous le verrons, les résultats de la vectorisation automatique sont loin d'être au niveau des autres techniques.
L'assembleurC'est la solution la plus simple techniquement, plutôt que de demander l'impossible au compilateur, le développeur peut décider d'écrire lui-même en assembleur (une version "lisible" du langage machine) certains morceaux de son programme. Si les gains que l'on peut obtenir sont excellents (nous le verrons avec x264), en pratique très peu de développeurs choisissent cette route, car elle est tout simplement très complexe.
IntrinsèquesIl s'agit d'une option un peu plus flexible. Plutôt que de devoir écrire des morceaux d'assembleurs, les intrinsèques proposent des raccourcis en langage C vers les instructions AVX. Leur manipulation reste plus ou moins complexe et diffère d'un compilateur à un autre, ce qui peut limiter la portabilité du code. Elle n'est pas réellement employée dans les logiciels que nous avons testés (qui sont open sources et portables).
PrimitivesLes développeurs peuvent également se reposer sur des bibliothèques externes qui ont été optimisées pour tirer partie des processeurs modernes. Il s'agit souvent de bibliothèques qui implémentent des algorithmes réutilisables par les développeurs. Intel livre avec son compilateur une telle bibliothèque baptisée Performance Primitives qui propose des implémentations diverses et variées (allant de choses simples comme la manipulation de matrices à des blocs de code complexes comme le décodage et l'encodage d'images JPEG ou de vidéo H.264 !). L'utilisation de ces primitives limite bien entendu à l'utilisation du compilateur d'Intel.
Au final, l'utilisation de nouvelles instructions reste souvent un problème pour les développeurs en C/C++. Les langages étant relativement peu adaptés à la manière dont fonctionnent désormais nos processeurs, les solutions pour en tirer partie deviennent soit très complexes (réaliser soit même du code en assembleur), soit forcent à l'utilisation d'extensions propriétaires, ce qui fait perdre le côté standard du langage, et lie le développeur bon gré mal gré au fournisseur de ses outils de développements. Ce qui peut être un problème potentiel quand le fournisseur du compilateur est également un vendeur de processeur.
Sommaire
Vos réactions
Contenus relatifs
- [+] 09/05: AMD Ryzen 7 2700, Ryzen 5 2600 et I...
- [+] 04/05: Un Coffee Lake 8 coeurs en préparat...
- [+] 27/04: Le 10nm d'Intel (encore) retardé, l...
- [+] 27/04: AMD Vega 7nm en labo, Zen 2 échanti...
- [+] 26/04: Jim Keller rejoint... Intel !
- [+] 23/04: MAJ de notre test des Ryzen 7 2700X...
- [+] 19/04: AMD Ryzen 2700X et 2600X : Les même...
- [+] 19/04: 2008-2018 : tests de 62 processeurs...
- [+] 18/04: ASUS AREZ, l'effet GeForce Partner ...
- [+] 13/04: Les AMD Ryzen Pinnacle Ridge en pré...