
Impact des compilateurs sur les architectures CPU x86/x64
Publié le 28/02/2012 par Guillaume Louel



ConclusionA l'heure de refermer ce dossier, nous espérons tout d'abord avoir pu démystifier quelque peu la problématique des compilateurs, et le rôle qu'ils jouent dans les performances de nos processeurs. Nous avions posé au cours de notre article un certain nombre de questions, il convient désormais d'y répondre.
D'abord, oui, le choix du compilateur aura un impact sur les performances. La réputation du compilateur d'Intel - toutes optimisations mises de côté - n'est pas volée. Si nous avons pu voir des contre exemples, il reste en moyenne plus rapide que celui de Microsoft avec ses options par défaut. Et même si l'on force l'utilisation des opérations mathématiques SSE2, le compilateur de Microsoft pourra accuser un déficit de 15 à 20% de performances par rapport à son rival.
Si Intel investit dans le développement d'un compilateur, c'est bien entendu pour s'en servir comme une arme de plus dans la guerre des performances. En choisissant de permettre l'optimisation automatique pour chacune de ses familles de processeurs - tout en nommant ces options par les jeux d'instructions supportées, comme
QaxAVX pour l'AVX - Intel tend à ne faire profiter des dernières optimisations qu'à ses derniers modèles de processeurs, ce qui peut enfler quelque peu la perception que l'on peut se faire des gains apportés par le jeu d'instruction. Il suffit de regarder les performances du Phenom II exécutant ces versions "AVX" dispatchées pour s'en convaincre. 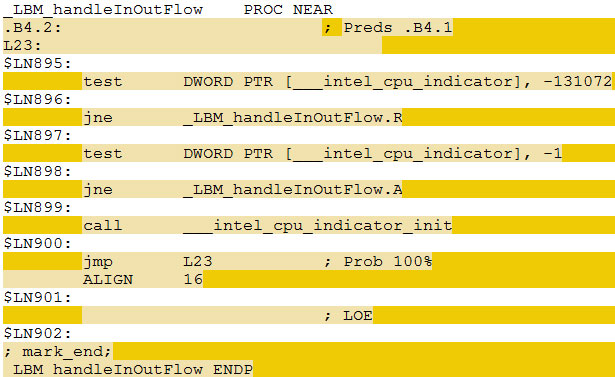
Exemple de fonction dispatchée, extraite du code assembleur de la build AVX dispatchée produite avec le compilateur Intel du test 470.lbm. En fonction de la valeur de la variable __intel_cpu_indicator, un chemin rapide (.R) ou lent (.A) sera exécuté.
Lorsque l'on supprime le dispatcher, le problème s'épaissit puisque certaines de ces couches d'optimisations - pas réellement liées aux instructions supportées par le processeur - disparaissent. Pire, certains modes sont bizarrement plus efficaces que d'autres, c'est le cas du mode SSE3 qui en moyenne est le plus rapide !
Le compilateur d'Intel laisse donc un choix complexe aux développeurs qui sont prêts à se plonger dans le manuel pour essayer de comprendre le fonctionnement des options d'optimisations. On retrouve d'un côté un mode universel, équitable dans ses optimisations, mais qui ne propose pas les meilleures performances, et ce pour des raisons qui n'ont pas grand-chose à voir avec la génération de code SSE ou AVX. De l'autre on retrouve des modes dispatchés, fourre tout, qui permettent de gagner jusque 15% de performances en plus sur un processeur Intel par rapport aux modes "équitables". Et qui ont une tendance, plus ou moins forte selon le modèle, à ne pas augmenter, ou diminuer les performances des processeurs AMD.
La question de l'implémentation exacte du dispatcher d'Intel dans son compilateur est donc ouverte. En choisissant d'executer une version différente de certaines parties des programmes en fonction de la marque du processeur, et non en fonction de ses capacités techniques, Intel n'est pas particulièrement fair play. La réponse traditionnelle du constructeur sur ce point est claire : ils proposent un logiciel qui tend - certes - à favoriser leurs propres produits, libre à son concurrent de faire de même. Le passage de la Federal Trade Commission n'a pas changé la problématique, si ce n'est par le fait qu'Intel indique désormais clairement que son compilateur optimise différemment selon la marque des processeurs (sans réellement préciser comment). Le fait cependant que nombre de ces optimisations ne soient pas vraiment liées au modèle de processeur, mais à d'autres couches d'optimisations qui se rajoutent, comme le dépliement de boucles par exemple, rendent la situation encore moins claire pour les développeurs. Notons en plus que cette détection de la marque du processeur est utilisée au cas par cas, non seulement par ICC, mais aussi par d'autres produits secondaires vendus par Intel comme par exemple la bibliothèque mathématique MKL ou celle de gestion de threads, TBB, toutes deux dispatchés, certes, mais sans que la marque du processeur n'intervienne.
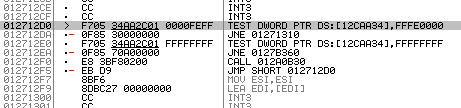
Le même code dispatché, vu à l'execution du programme via OllyDbg
Le problème s'épaissit lorsqu'Intel va ensuite démarcher les développeurs de logiciels pour leur proposer d'utiliser leur compilateur, tout en suggérant d'utiliser ces modes Qax qui, outre le fait d'être conseillés par Intel, seront détectés comme plus performants par les développeurs qui prendront le temps de vérifier les performances respectives. Sur le plan de l'équité que nous souhaitons, on peut y voir un problème. Particulièrement quand sont visés les développeurs de jeux ou de benchmarks en vogue - car utilisés dans la presse spécialisé pour mesurer les performances des processeurs.
Peut-on cependant blâmer les développeurs qui y passent ? C'est bien là le cur du problème. Si l'on propose à un développeur le choix d'utiliser un compilateur "équitable" contre un autre qui apportera 35% de performances en plus aux utilisateurs de processeurs AMD, et 54% de performances en plus aux utilisateurs de processeurs Intel, doit on le blâmer de choisir un compilateur qui accélèrera dans les deux cas ses utilisateurs, certes de façon partisane ?
Et quid de l'utilisateur de processeur AMD dans ce cas ? Préfère-t-il une version équitable et lente, ou un peu plus performante tout en sachant qu'elle avantagera plus les utilisateurs de processeurs concurrents ? En pratique, hors du monde de l'open source, il n'aura de toute façon pas à donner son avis. Les utilisateurs d'applications commerciales doivent subir les choix, bons ou mauvais, réalisés par les développeurs.
De la même manière, les mesures de performances que nous réalisons lors de nos comparatifs de processeurs restent impactées par les choix réalisés. Si nous écartons dans l'élaboration de nos protocoles les benchmarks trop partisans - ou ceux conseillés par les constructeurs - lorsqu'une application très populaire avantage un modèle de processeur plutôt qu'un autre, mesurer ces écarts n'est que refléter, au final, la réalité vécue par les utilisateurs de ces logiciels.
Le problème de l'équité est épais et les solutions maigres. L'évolution de compilateurs qui produisent du code managé, à l'image de LLVM peut être une solution, tout comme une généralisation de .NET. En gardant à l'esprit que celui qui contrôle la machine virtuelle, au final, contrôle la clef des performances sur chacune des architectures. Déplacer un problème, cela ne veut pas forcément dire le résoudre
Sommaire
A lire également




Vos réactions
Contenus relatifs
- [+] 09/05: AMD Ryzen 7 2700, Ryzen 5 2600 et I...
- [+] 04/05: Un Coffee Lake 8 coeurs en préparat...
- [+] 27/04: Le 10nm d'Intel (encore) retardé, l...
- [+] 27/04: AMD Vega 7nm en labo, Zen 2 échanti...
- [+] 26/04: Jim Keller rejoint... Intel !
- [+] 23/04: MAJ de notre test des Ryzen 7 2700X...
- [+] 19/04: AMD Ryzen 2700X et 2600X : Les même...
- [+] 19/04: 2008-2018 : tests de 62 processeurs...
- [+] 18/04: ASUS AREZ, l'effet GeForce Partner ...
- [+] 13/04: Les AMD Ryzen Pinnacle Ridge en pré...