
Impact des compilateurs sur les architectures CPU x86/x64
Publié le 28/02/2012 par Guillaume Louel



Générer un code optimisé pour une architecture CPUVous l'aurez deviné, s'il y a des différences fortes dans la manière dont les processeurs traitent les instructions, il est possible pour les développeurs de compilateurs d'optimiser le code qu'ils génèrent afin de prendre en compte les particularités de chacun.
Avec l'arrivée du Pentium et des processeurs super-scalaires, l'ordre dans lequel le compilateur aura placé les instructions est devenu excessivement important. Placées correctement, deux additions pouvaient avoir lieu en simultanée sur cette architecture, un doublement de performances gratuit qu'il fallait obtenir à la main : à l'époque les compilateurs n'étaient pas aussi évolués et ne savaient pas prendre en compte cette différence pour générer un code optimisé. Cela a poussé Intel à proposer ensuite avec les Pentium Pro un nouveau type d'architecture, on parle alors de "Out Of Order" ou OOO. Derrière l'acronyme se cache un concept simple, permettre au processeur de changer l'ordre des instructions pour utiliser au mieux les unités super-scalaires. Si à l'époque il s'agissait surtout de maximiser l'utilisation de toutes les unités, aujourd'hui les moteurs d'ordonnancements continuent d'évoluer pour compenser les évolutions des processeurs modernes : aujourd'hui, cacher au maximum la latence des accès mémoires (en traitant le plus tôt possible les opérations de lectures mémoire pour qu'elles soient là lorsque le processeur en aura besoin) est devenu la nouvelle préoccupation, la rapidité des accès mémoire n'évoluant pas aussi rapidement que l'augmentation des performances arithmétiques des processeurs.
Depuis l'arrivée du Pentium Pro en 1995 la tendance aura toujours été la même : intégrer au niveau hardware un maximum de nouveautés (super scalaire, OOO, caches, MMU, prefetchers, etc) pour permettre de tirer une efficacité maximale d'architectures qui deviennent de plus en plus complexes. En disant cela, on pourrait penser que le rôle du compilateur diminue tant les processeurs modernes sont capables de gommer par eux même certaines lourdeurs du code que l'on leur demande de traiter. En pratique, il existe toujours cependant des cas ou les choix réalisés par le compilateur sera d'importance.
Le choix des instructions par exemple reste crucial. Pour prendre un exemple qui nous ramène au 21eme siècle, les instructions AVX sont disponibles pour la plupart dans deux variantes : 128 bits et 256 bits (le nombre de bits indique la taille des opérandes, les données sur lesquelles les instructions travaillent) et il est généralement possible de remplacer une instruction 256 bits par deux instructions 128 bits.
Comme nous l'avions vu à l'époque en évoquant son architecture, un module bulldozer consiste en une fusion de deux curs au sein d'un module ou un certain nombre de ressources sont partagées. Parmi celles-ci, il y a le cas de l'unité virgule flottante, en charge de l'exécution des instructions SSE (128 bits) et AVX (128 ou 256). Elle est particulière car découpée en deux morceaux pouvant travailler indépendamment en mode 128 bits. Cependant s'il faut réaliser une instruction 256 bits, les deux blocs devront se synchroniser et travailler ensemble, ce qui peut avoir un cout. Ainsi mélanger des instructions 128 et 256 bits peut nuire à l'efficacité. Pour prendre en compte cette particularité, le compilateur GCC tentera, si l'on lui demande d'optimiser pour un processeur Bulldozer (architecture bdver1) de favoriser l'utilisation d'instructions AVX128.
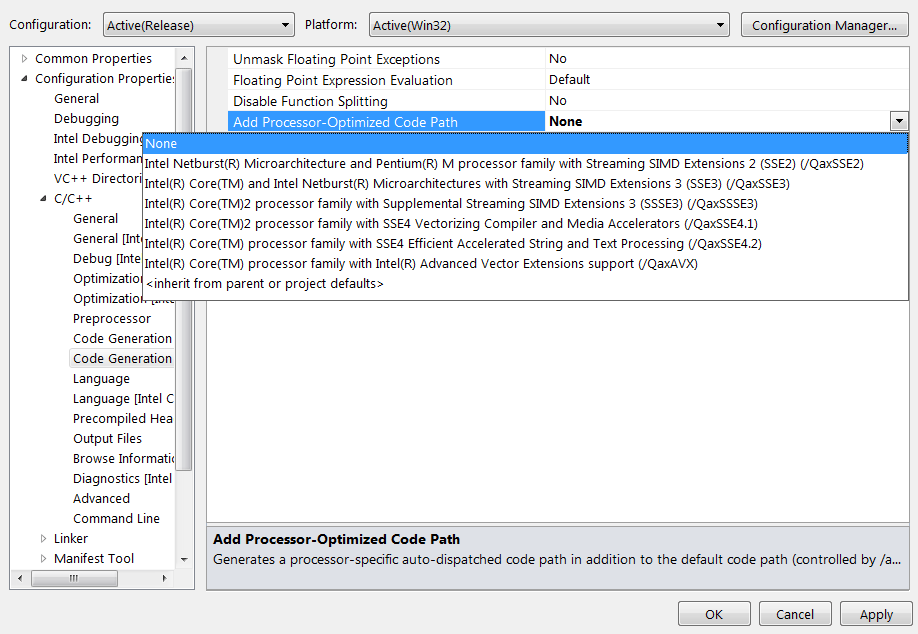
Plutôt que d'optimiser pour une architecture, le compilateur d'Intel permet d'optimiser pour un modèle donné de processeur de marque Intel.
Le problème s'épaissit lorsque l'on prend en compte certaines instructions spécifiques du langage C/C++. Si les opérations mathématiques classiques peuvent se traduire simplement en langage machine, pour d'autres tâches, le langage offre des fonctions qui simplifient la tâche des programmeurs. C'est par exemple le cas de la manipulation de chaines de caractères (des suites de lettres ou de chiffres) ou encore la manipulation de blocs mémoire (en pratique, la manipulation de chaines repose sur la manipulation de mémoire). Le langage C/C++ propose des fonctions qui vont être traduites, par le compilateur, par des morceaux de langage machine relativement longs. Et donc optimisables ! La latence dans l'accès aux données, la taille des caches, le fonctionnement interne des prefetchers et de la MMU peuvent être pris en compte par des développeurs zélés au moment de la compilation, tout comme les instructions disponibles sur le processeur. Ainsi, comme nous le verrons plus tard, le compilateur d'Intel dispose d'implémentations spécifiques de ces fonctions pour chacun de ses processeurs.
L'optimisation pour une architecture n'est donc définitivement pas enterrée et l'empiètement du hardware sur le terrain du compilateur se compense par une complexification des optimisations. Et puis, il y a la vectorisation
Sommaire
Vos réactions
Contenus relatifs
- [+] 09/05: AMD Ryzen 7 2700, Ryzen 5 2600 et I...
- [+] 04/05: Un Coffee Lake 8 coeurs en préparat...
- [+] 27/04: Le 10nm d'Intel (encore) retardé, l...
- [+] 27/04: AMD Vega 7nm en labo, Zen 2 échanti...
- [+] 26/04: Jim Keller rejoint... Intel !
- [+] 23/04: MAJ de notre test des Ryzen 7 2700X...
- [+] 19/04: AMD Ryzen 2700X et 2600X : Les même...
- [+] 19/04: 2008-2018 : tests de 62 processeurs...
- [+] 18/04: ASUS AREZ, l'effet GeForce Partner ...
- [+] 13/04: Les AMD Ryzen Pinnacle Ridge en pré...