
Impact des compilateurs sur les architectures CPU x86/x64
Publié le 28/02/2012 par Guillaume Louel



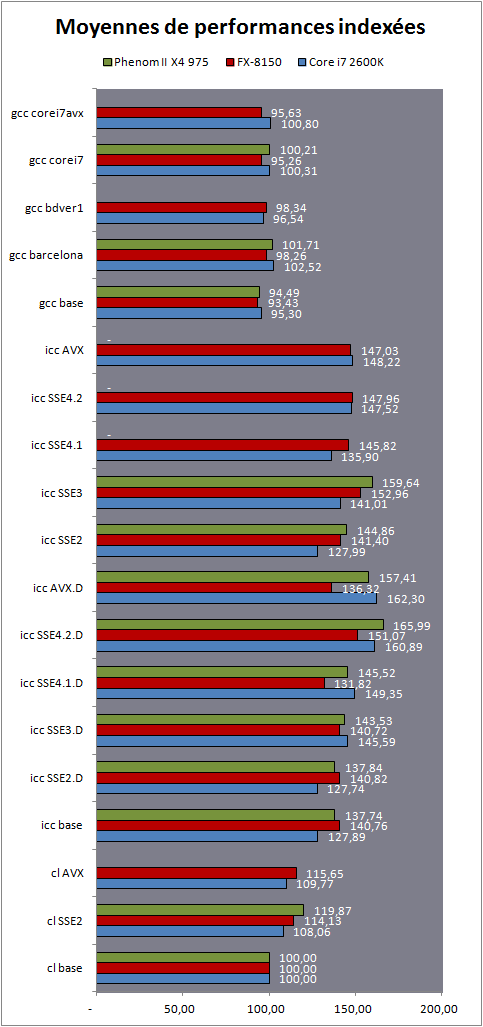
MoyennesPour illustrer les performances relatives des compilateurs, nous avons calculé des moyennes en ramenant à un indice 100 la performance du compilateur de Microsoft sur chacune des plateformes. 7-Zip et x264 sont bien entendu exclus de ces moyennes.
Pour être très précis, nous avons également effectué deux autres moyennes en ramenant à 100 les scores du compilateur Microsoft en version SSE2, et Intel en version de base.
[ cl base ] [ cl SSE2 ] [ icc base ]
Passez la souris sur un compilateur pour centrer les moyennes
Bien entendu, les performances des ces trois processeurs ne sont pas identiques mais en ramenant chacun à un indice équivalent, nous pouvons voir plus précisément de quelle manière les performances évoluent en fonction du compilateur ou des options utilisées.
Si vous avez suivi notre article depuis le début, les résultats présentés ici ne vous surprendront pas. Le compilateur d'Intel arrive, sans surprise, à se placer devant. Si gcc ne démérite pas, en pratique les options de tuning ont souvent été contreproductives, mitigeant les gains qu'elles apportent. Visual Studio de son côté est significativement plus lent dans sa version classique, et pour cause, il génère encore du code x87 par défaut pour les opérations en virgule flottante. Passer au SSE2 pour les opérations mathématiques augmente les performances, particulièrement sur les processeurs AMD dont le mode x87 a été quelque peu délaissé au profit des nouveaux jeux d'instructions comme SSE2 qui sont censés les remplacer.
Si l'on compare ce mode à celui par défaut d'Intel (qui compile également pour SSE2), on notera que ce dernier se détache, et c'est même le FX-8150 qui en profite le plus avec 24% de performances en plus obtenues contre 20% seulement pour le Core i7.
En centrant les performances sur ce mode, on peut voir plusieurs points intéressants. D'abord, la manière très progressive dont chaque mode
Qax profite aux processeurs d'Intel. Des gains graduels, un peu trop parfaits pour être liés simplement à l'utilisation d'un jeu d'instruction. Pour se convaincre de ce fait, il suffit de regarder l'écart que l'on retrouve entre la version AVX avec et sans dispatcher sur un Core i7 2600k. Les modes "équitables" ne sont pas optimisés avec la même vigueur par Intel que les autres modes d'optimisations. Intel ne s'en cache d'ailleurs pas. Les modes
Qax sont des modes d'optimisations fourre tout ou nombre des optimisations ne sont pas du tout liées au niveau de support du processeur. Le fait que ces autres optimisations, dont l'on a vu parfois en pratique les effets bénéfiques sur les processeurs AMD, ne soient pas rendues disponibles dans les modes censés être largement compatibles (sans dispatcher) est particulièrement gênant. Si ces modes sont effectivement plus "justes", ils sont en pratique moins rapides pour tout le monde, y compris les processeurs Intel. Alors, quelles sont ces autres optimisations ? En analysant le code assembleur généré par le compilateur d'Intel nous avons pu remarquer un certain nombre de choses.
D'abord, il y a des optimisations qui ne concernent pas le code des développeurs. Que ce soit l'utilisation d'une version ou d'une autre des fonctions d'allocations et de copie mémoire, les résultats peuvent être très changeants. Tout ce code annexe généré par le compilateur pour les fonctionnalités standard de C/C++ est important, et si le dispatcher en affecte certaines, d'autres ne sont pas affectées. C'est d'ailleurs à cela que l'on doit cette si grande variété dans les résultats que l'on retrouve. Pour le test lbm, le code assembleur généré dans la section critique du programme est identique dans les versions SSE 4.1 et 4.2. Pire, le code généré n'est pas dispatché (il l'est en mode AVX, avec un gain très modeste), mais l'on note une différence de traitement significative entre un Core i7 et un FX en SSE 4.1. Parce que certains blocs de code annexes, sont, eux, dispatchés.
Ensuite, il ne faut surtout pas surestimer la quantité de code SSE/AVX généré. Si le compilateur est souvent capable d'en utiliser, nous avons remarqués dans nombre de tests que le code produit dans les sections critiques (les parties de code les plus gourmandes) n'utilise pas toujours de code AVX. Les instructions SSE2 sont souvent préférées, et ce à juste escient.
Enfin, il y a les optimisations opaques. Nous avons pu remarquer par exemple que les modes Qax influent sur le dépliement de boucle. Cette optimisation consiste à remplacer des boucles (des morceaux de codes que l'on demande de répéter de multiples fois) par ce code répété plusieurs fois. Cela rallonge la taille du code généré, mais en pratique le fait d'éviter des sauts conditionnels (très couteux sur l'architecture x86) peut apporter de bons gains de performances. Nous avons pu remarquer, dans le cas du test lbm, que le compilateur d'Intel ne déplie pas le code en mode QaxSSE2, et qu'il le déplie avec plus ou moins de vigueur dans les autres modes, alors même que l'option de dépliement est activée par défaut dans le compilateur.
Sommaire
Vos réactions
Contenus relatifs
- [+] 09/05: AMD Ryzen 7 2700, Ryzen 5 2600 et I...
- [+] 04/05: Un Coffee Lake 8 coeurs en préparat...
- [+] 27/04: Le 10nm d'Intel (encore) retardé, l...
- [+] 27/04: AMD Vega 7nm en labo, Zen 2 échanti...
- [+] 26/04: Jim Keller rejoint... Intel !
- [+] 23/04: MAJ de notre test des Ryzen 7 2700X...
- [+] 19/04: AMD Ryzen 2700X et 2600X : Les même...
- [+] 19/04: 2008-2018 : tests de 62 processeurs...
- [+] 18/04: ASUS AREZ, l'effet GeForce Partner ...
- [+] 13/04: Les AMD Ryzen Pinnacle Ridge en pré...