
Impact des compilateurs sur les architectures CPU x86/x64
Publié le 28/02/2012 par Guillaume Louel



Nous avons également utilisé plusieurs logiciels open source pour tenter de mesurer les performances relatives des compilateurs.
[ Core i7 2600k ] [ FX-8150 ] [ Phenom II X4 975 ]
Passez la souris sur un modèle de processeur pour afficher ses résultats
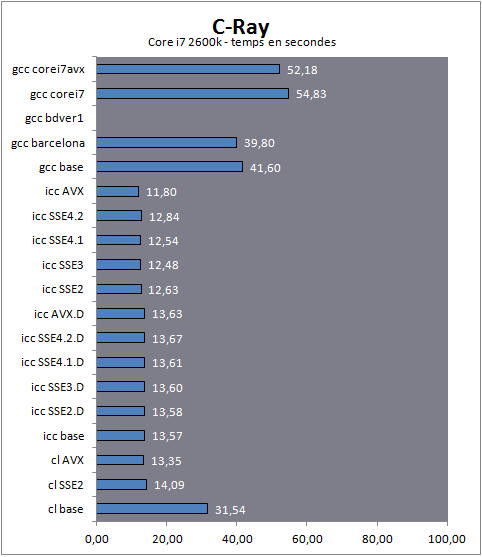
Les résultats obtenus montrent tout d'abord la différence que peut faire l'utilisation d'opérations mathématiques SSE2 ou AVX. Sur les trois plateformes, passer du x87 au SSE2 avec le compilateur de Microsoft fait plus que doubler les performances (le Phenom II étant celui qui, de loin, en profite le plus !). Le mode AVX du compilateur de Microsoft se paye même le luxe d'être plus plus rapide que le compilateur d'Intel sur un Core i7. Ironiquement une fois de plus, c'est le compilateur d'Intel qui est le plus efficace sur les plateformes AMD. Les différentes optimisations du compilateur d'Intel ne changent pas grand-chose avec le dispatcher, même si une fois celui-ci désactivé, on est obligé de noter un petit décrochement sur le FX des modes SSE 4.2 et AVX. On notera enfin que les optimisations Core i7 sont très contreproductives sous GCC, ce qui n'est pas le cas des optimisations AMD.
[ Core i7 2600k ] [ FX-8150 ] [ Phenom II X4 975 ]
Passez la souris sur un modèle de processeur pour afficher ses résultats
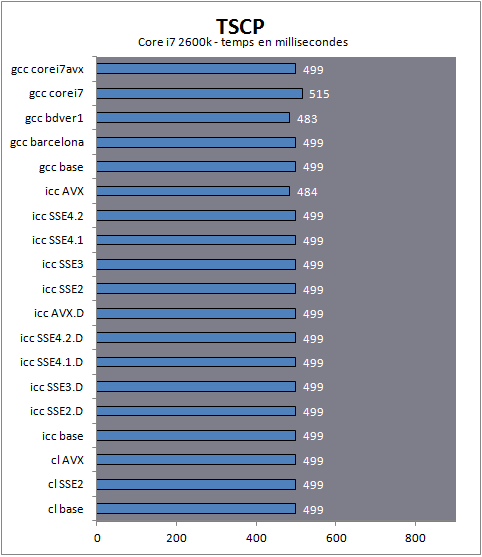
Une fois n'est pas coutume, les différentes optimisations du compilateur Intel ne servent ici à rien sans dispatcher. Avec, on note un petit avantage du mode AVX. C'est surtout GCC qui tire son épingle du jeu avec les meilleurs résultats sur les trois plateformes, parfois ex-equo avec le compilateur d'AMD qui s'en sort aussi très bien.
[ Core i7 2600k ] [ FX-8150 ] [ Phenom II X4 975 ]
Passez la souris sur un modèle de processeur pour afficher ses résultats
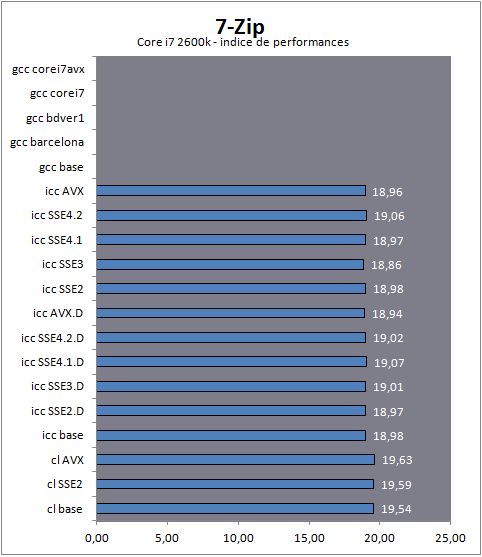
Attention, contrairement à tous nos autres graphiques, 7-Zip rapporte un indice de performance et non un temps. Une barre plus longue indique donc de meilleures performances. Le code de 7-Zip n'est pas compilable directement avec GCC. Un portage unix/posix existe bel et bien (p7zip ) mais comparer le temps d'exécutions de code sources différents ne ferait ici pas sens.
On notera surtout ici le fait que le compilateur de Microsoft se distingue en étant plus rapide sur Core i7 et FX. L'Intel n'est devant que sur Phenom II, décidément le constructeur aime beaucoup ce processeur ! Notons enfin pour l'anecdote que la version optimisée pour la taille du code était très légèrement plus rapide dans ce test, sous Visual Studio (
 Performances SPEC : namd, lbm, sphinx3
Impact de l'assembleur : x264
Performances SPEC : namd, lbm, sphinx3
Impact de l'assembleur : x264

C-RayC-Ray est une implémentation d'un raytracer en C. Particulièrement concise, cette implémentation stresse très fortement les capacités flottantes des processeurs modernes et à été transformée en benchmark pour ce but (vous pouvez retrouver le code source ici).
Langage : C
Type de charge : Flottants
Multithreadé : Oui
[ Core i7 2600k ] [ FX-8150 ] [ Phenom II X4 975 ]
Passez la souris sur un modèle de processeur pour afficher ses résultats
Les résultats obtenus montrent tout d'abord la différence que peut faire l'utilisation d'opérations mathématiques SSE2 ou AVX. Sur les trois plateformes, passer du x87 au SSE2 avec le compilateur de Microsoft fait plus que doubler les performances (le Phenom II étant celui qui, de loin, en profite le plus !). Le mode AVX du compilateur de Microsoft se paye même le luxe d'être plus plus rapide que le compilateur d'Intel sur un Core i7. Ironiquement une fois de plus, c'est le compilateur d'Intel qui est le plus efficace sur les plateformes AMD. Les différentes optimisations du compilateur d'Intel ne changent pas grand-chose avec le dispatcher, même si une fois celui-ci désactivé, on est obligé de noter un petit décrochement sur le FX des modes SSE 4.2 et AVX. On notera enfin que les optimisations Core i7 sont très contreproductives sous GCC, ce qui n'est pas le cas des optimisations AMD.
TSCPTSCP est une implémentation d'une intelligence artificielle d'échecs par Tom Kerrigan (que nous remercions pour nous avoir laissé utiliser son bench).
Langage : C
Type de charge : Entiers
Multithreadé : Non
[ Core i7 2600k ] [ FX-8150 ] [ Phenom II X4 975 ]
Passez la souris sur un modèle de processeur pour afficher ses résultats
Une fois n'est pas coutume, les différentes optimisations du compilateur Intel ne servent ici à rien sans dispatcher. Avec, on note un petit avantage du mode AVX. C'est surtout GCC qui tire son épingle du jeu avec les meilleurs résultats sur les trois plateformes, parfois ex-equo avec le compilateur d'AMD qui s'en sort aussi très bien.
7-ZipNous utilisons ici le bench intégré à 7-Zip 9.20 , ce dernier mesure les performances de la compression LZMA2, cette dernière s'effectue exclusivement en mémoire à l'image de ce que nous avions vu pour SPEC et bzip2.
Langage : C
Type de charge : Entiers
Multithreadé : Oui
[ Core i7 2600k ] [ FX-8150 ] [ Phenom II X4 975 ]
Passez la souris sur un modèle de processeur pour afficher ses résultats
Attention, contrairement à tous nos autres graphiques, 7-Zip rapporte un indice de performance et non un temps. Une barre plus longue indique donc de meilleures performances. Le code de 7-Zip n'est pas compilable directement avec GCC. Un portage unix/posix existe bel et bien (p7zip ) mais comparer le temps d'exécutions de code sources différents ne ferait ici pas sens.
On notera surtout ici le fait que le compilateur de Microsoft se distingue en étant plus rapide sur Core i7 et FX. L'Intel n'est devant que sur Phenom II, décidément le constructeur aime beaucoup ce processeur ! Notons enfin pour l'anecdote que la version optimisée pour la taille du code était très légèrement plus rapide dans ce test, sous Visual Studio (
-O1). Un choix d'ailleurs effectué par le développeur pour les versions qu'il distribue.
Sommaire
Vos réactions
Contenus relatifs
- [+] 09/05: AMD Ryzen 7 2700, Ryzen 5 2600 et I...
- [+] 04/05: Un Coffee Lake 8 coeurs en préparat...
- [+] 27/04: Le 10nm d'Intel (encore) retardé, l...
- [+] 27/04: AMD Vega 7nm en labo, Zen 2 échanti...
- [+] 26/04: Jim Keller rejoint... Intel !
- [+] 23/04: MAJ de notre test des Ryzen 7 2700X...
- [+] 19/04: AMD Ryzen 2700X et 2600X : Les même...
- [+] 19/04: 2008-2018 : tests de 62 processeurs...
- [+] 18/04: ASUS AREZ, l'effet GeForce Partner ...
- [+] 13/04: Les AMD Ryzen Pinnacle Ridge en pré...