| |
| |
| Nouvelle extension vectorielle ARMv8-A SVE Processeurs Publié le Mardi 23 Août 2016 par Guillaume Louel URL: /news/14756/nouvelle-extension-vectorielle-armv8-a-sve.html ARM profite également de la conférence Hot Chips pour présenter une nouveauté importante de son jeu d'instruction, une extension vectorielle baptisée SVE (Scalable Vector Extension). Les instructions vectorielles permettent pour rappel d'effectuer une même opération sur plusieurs données à la fois (regroupées dans un vecteur au sens informatique , un tableau à une dimension). Dans les architectures x86, on a vu de multiples extensions se succéder. Si l'on reste chez Intel, après les différentes variantes de SSE, on aura connu plus récemment AVX dans Sandy Bridge, AVX2 dans Haswell et AVX-512 pour les Skylake serveurs uniquement. Dans la grande tradition du x86 qui est un jeu d'instruction "large" (CISC), chaque extension rajoute de nouvelles instructions vectorielles adaptées spécifiquement aux unités matérielles présentes dans chaque génération de processeur introduite. Parmi les changements d'une version à l'autre, outre de nouvelles opérations (par exemple effectuer une multiplication et une addition en simultanée), ce qui évolue surtout est la quantité de données qu'une puce est capable de traiter. Ainsi, comme son nom l'indique, AVX-512 permet d'effectuer des opérations sur des données par groupes de 512 bits (par exemple 16 données 32 bits) à la fois, là ou les unités d'AVX2 travaillaient sur des groupes de 256 bits (dans le même exemple, 8 fois 32 bits). 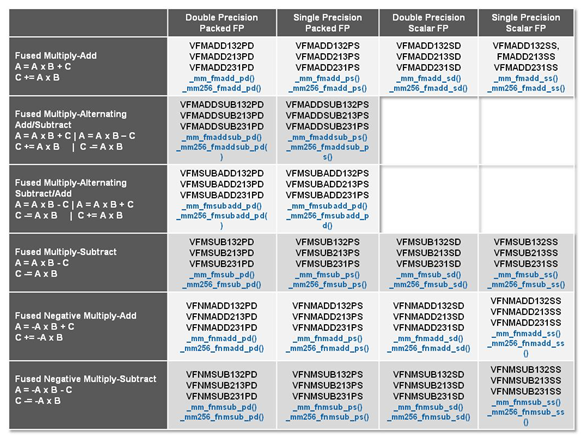 Les instructions FMA3 d'AVX2, on notera la large quantité de variantes proposées Ce modèle d'instructions adaptées a chaque variante de matériel à l'avantage d'être simple pour les constructeurs, chaque nouveauté est géré par de nouvelles instructions, mais en pratique ce mode de fonctionnement est très problématique. Comme nous avions eu l'occasion de le voir, en général, les programmes sont compilés pour une architecture donnée, parfois deux lorsque l'on a de la chance, ce qui pousse souvent les logiciels commerciaux à ne pas forcément utiliser les dernières nouveautés matérielles par souci de compatibilité. Cela permet aussi aux constructeurs qui disposent d'un compilateur, comme on l'avait vu avec Intel, d'augmenter artificiellement l'avantage proposé par une architecture. S'ajoute en prime le problème de la vectorisation du code source des logiciels, un problème compliqué qu'on résout soit à la main, soit en laissant faire le compilateur qui, malgré sa meilleure volonté, se retrouve assez souvent dans des situations ou il ne peut pas vectoriser automatiquement le code, par prudence. Dans le monde ARM, la situation est beaucoup plus simple. Le jeu d'instruction ARM repose pour rappel sur le principe d'un jeu d'instruction réduit (RISC) et rajouter de nouvelles instructions à chaque nouveau processeur n'est pas une option. ARM avait tout de même introduit une extension vectorielle, NEON , qui rajoute des instructions vectorielles (VFP) sur 128 bits. Cette extension avait été conçue il y a une douzaine d'année, exploitée notamment sur l'architecture précédente (ARMv7 en 32 bits). Pour le passage à son architecture 64 bits, ARMv8-A, ARM n'avait pas apporté de changement fondamental à NEON. C'est désormais chose faite avec l'introduction de SVE, dont les ambitions vont pour le coup beaucoup plus loin. ARM donne quelques petits détails dans un post de blog sur le fonctionnement de sa nouvelle extension. L'idée de base de SVE se retrouve dans son nom : il s'agit d'une extension Scalable, la taille des vecteurs sur lequel les instructions s'appliquent n'est pas fixe (contrairement à AVX-512 et ses vecteurs 512 bits).  Côté matériel, la spécification d'ARM laisse le choix aux designers de processeurs qui peuvent choisir la largeur de leurs unités de calcul, entre 128 et 2048 bits (!). Cela donne un maximum de flexibilité, permettant de créer des designs orignaux et adaptés à des marchés spécifiques (ARM vise principalement avec SVE le marché des serveur et du HPC, même si le jeu d'instruction devrait se retrouver sur d'autres puces). Le plus intéressant est ce qui se passe au niveau du jeu d'instruction : il est indépendant de la taille des vecteurs à traiter (la société parle de VLA, Vector Length Agnostic). Concrètement, plutôt que d'utiliser des instructions qui traitent (par exemple) 4 données 32 bits, les instructions VLA indiquent directement quelles instructions appliquer aux vecteurs sans s'occuper d'un quelconque découpage. Techniquement, ARM ne détaille pas vraiment comment sera implémenté la chose côté matériel, se contentant de dire que c'est le matériel qui, en fonction de la taille de ses unités, s'occupera de découper le vecteur en autant de passes que nécessaire pour le traiter dans ses unités. ARM indique simplement que l'encodage de la taille du vecteur n'est pas nécessaire et qu'elle est déterminée par les mécanismes de prédiction des puces (qui seraient particulièrement performants y compris pour les boucles imbriquées). Le fonctionnement exact est assez flou, et diffère d'une proposition d'extension - sur le fond assez proche - que l'on avait vu l'année dernière pour le jeu d'instruction RISC-V (PDF) . D'après ARM, un travail important a été effectué sur les instructions qui permettent de charger les données en mémoire pour les traiter, elles représenteraient la majorité des instructions ajoutées.  Extrait de la présentation de proposition vectorielle pour RISC-V, à gauche un code SIMD classique 128 bits, à droite un code vectoriel. La première instruction vsetvl indique la taille des vecteurs traités L'approche est très différente de celle des SSE/AVX, on peut même la qualifier d'élégante, et devrait permettre de conserver un jeu d'instruction très compact tout en offrant une grande flexibilité. ARM indique que seul un seizième de l'espace d'encodage d'instruction RISC disponible est utilisé pour les nouvelles instructions VLA (les instructions AArch64 sont encodés sur 32 bits, 75% de cet espace est déjà utilisé aujourd'hui par le reste des instructions).  En prime, cela résout le problème de la compilation que nous évoquions plus haut : un programme compilé avec des instructions vectorielles VLA pourra profiter pleinement de toutes les architectures matérielles SVE existantes et à venir.  Cette extension devrait permettre de voir des puces ARM assez différentes arriver sur le marché et si le monde des serveurs et du HPC est clairement visé - ARM met en avant Fujitsu qui développera une puce ARMv8-A avec SVE pour le supercalculateur Post-K prévu pour 2020 - on s'intéressera aussi à l'arrivée de SVE dans des puces plus classiques. La publication de la version finale de la spécification est prévue pour la fin de l'année ou le tout début 2017. Copyright © 1997-2026 HardWare.fr. Tous droits réservés. |