
Les contenus liés aux tags Intel et TSMC
Afficher sous forme de : Titre | FluxL'ITRS prépare l'après loi de Moore
3 architectures 10nm pour Intel ?
ASML confirme les retards sur l'EUV
ASML vend 15 machines EUV à Intel
Intel précise son process 14nm
10/7nm en avance pour TSMC, EUV pour le 5nm



TSMC vient de publier ses résultats financiers pour le troisième trimestre. Le fondeur taiwannais enregistre une hausse séquentielle de 17% (+22% par rapport à la même période sur 2015), au dessus de ses prévisions. Des bons chiffres qui s'expliquent selon TSMC par une forte demande sur le marché des smartphones.

Ramenés par process, le 16/20nm représente 31% des revenus de la société (contre 23% le trimestre précédent). Le 28nm voit sa part baisser à 24% des revenus, mais TSMC confirme que ses usines restent "pleinement utilisées".
En ce qui concerne les prochains nodes, TSMC a confirmé les informations publiées un peu plus tôt, à savoir l'avance prise par les process 10 et 7nm.
Le 10nm entre en production ce trimestre et les premiers produits finaux seront livrés au premier trimestre 2017. Ce node ne sera pour rappel utilisé que par les très gros clients de TSMC, à savoir Apple et possiblement Qualcomm. Les autres clients attendront le 7nm. La montée des yields est décrite comme "similaire" à celle du 16nm même si "techniquement plus difficile".
Le 7nm entrera en production "risque" au premier trimestre 2017 et TSMC s'empresse d'indiquer qu'il sera utilisé non seulement pour les smartphones, mais aussi pour des GPU, des puces serveurs, et des "PC et tablettes". TSMC décrit des tapeout aggressifs qui commenceront au début du second trimestre. 15 produits devraient être qualifiés en 2017.

La fondeur a également évoqué le 5nm, qui a quitté le stade de la recherche pure pour entrer dans une phase de développement. Et TSMC confirme qu'ils utiliseront de manière "extensive" la lithographie EUV. Cette dernière aurait fait des progrès sur tous les plans, que ce soit en fiabilité, ou sur les problèmes techniques complexes (masques, photo resist, etc). La production "risque" reste prévue pour la première moitié de 2019 (la production volume suit en général de 3 à 4 trimestres).
Lors de la présentation des résultats aux analystes financiers, le CEO de TSMC, Mark Liu, a réitéré une fois de plus voir "l'informatique haute performance" comme un marché sur lequel TSMC espère voir une progression de ses ventes. Les serveurs et les PC clients sont mis en avant, et on a du mal a ne pas y voir un lien avec les annonces d'AMD sur sa renégociation du contrat WSA qui les lie à GlobalFoundries.
Dans la séance de questions/réponses posées, on notera qu'a la question de savoir si la prise de licence ARM par Intel est un risque, Mark Liu estime surtout que cela renforce le rôle d'ARM, tout en ne négligeant pas le rôle qu'Intel pourrait jouer. Reste que sur ce trimestre, la part de marché de TSMC chez les fondeurs (hors activité propre comme Intel pour ses propres puces donc) était de 55%.
TSMC et InFo PoP pour l'A10 de l'iPhone 7
Ce week end, la société Chipworks a procédé à son traditionnel "teardown" des puces incluses dans l'iPhone 7 , en se concentrant particulièrement sur le SoC A10 d'Apple.
Rappel sur l'A9
Avant de regarder l'A10, revenons un instant sur l'A9 inclus l'année dernière dans l'iPhone 6S. Il avait la particularité d'être sourcé en parallèle chez Samsung et TSMC, quelque chose de quasi unique pour des puces haut de gamme sur des process de dernière génération, ce qui nous avait permis d'effectuer quelques comparaisons.
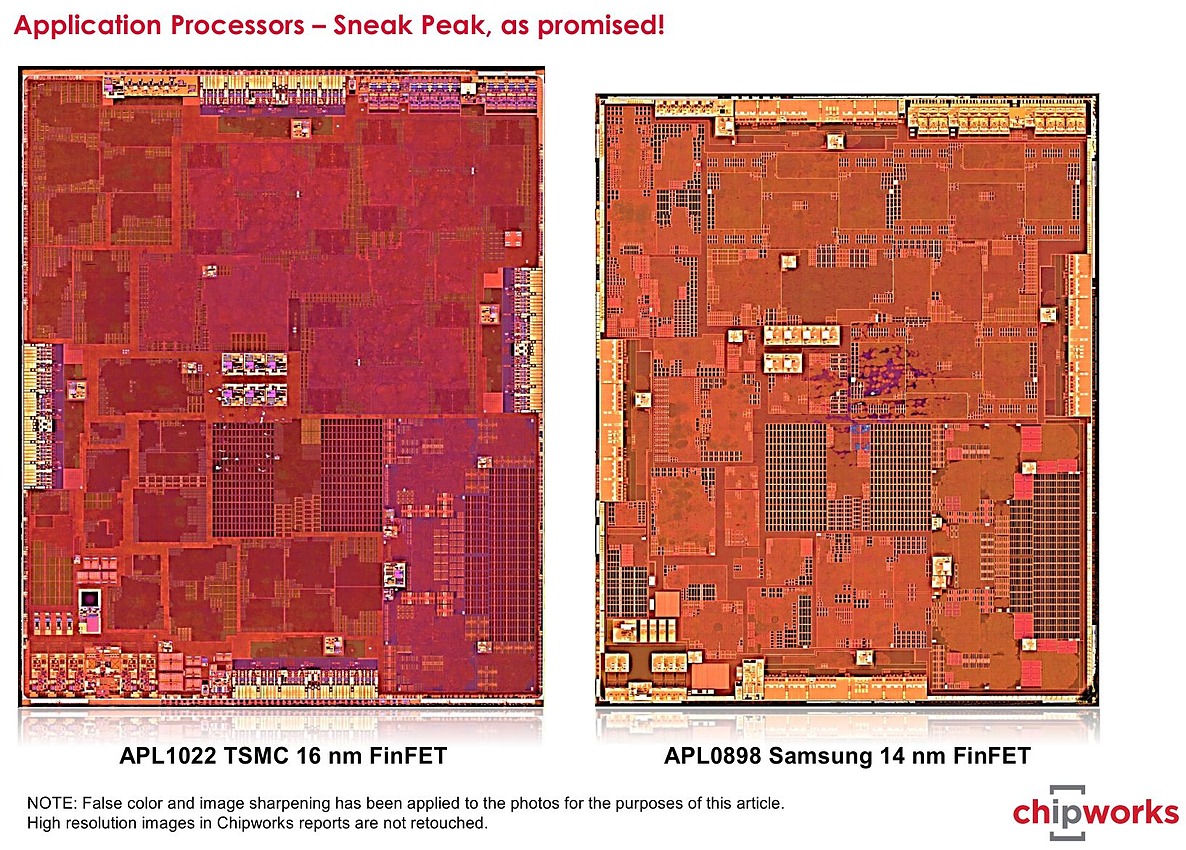
Les deux A9 de l'iPhone 6S (2015)
La différence la plus visible était la densité des deux process : l'A9 "Samsung" mesurant 96mm2, contre 104.5mm2 pour la version TSMC. A l'époque nous n'avions pas de certitudes sur les variantes exactes des process utilisées. Depuis, Chipworks a confirmé qu'il s'agissait bien du 14LPE chez Samsung. Le cas de TSMC est plus compliqué, Chipworks ne répondant pas (gratuitement) à la question. Les rumeurs laissent penser qu'il ne s'agissait pas d'un simple 16FF, mais d'une version "custom" empruntant en partie au process 16FF+.
Outre la densité, les tests pratiques avaient suggéré une différence de consommation à pleine charge avec un avantage pour la puce de TSMC. De quoi laisser penser que son process avait besoin de tensions inférieures à celui de Samsung pour obtenir les mêmes performances.
Depuis, Chipworks a la aussi répondu partiellement à la question suggérant que le problème se situerait pour le process de Samsung sur le rapport puissance/performances de ses NMOS . On ne sait pas si le problème persiste sur la version 14LPP qui a remplacé le 14LPE.
L'A10 : 16FFC TSMC
Première différence par rapport à l'année dernière, l'A10 semble produit cette année exclusivement par TSMC. Il est plus large que l'A9, mesurant 125mm2 pour 3.3 milliards de transistors annoncés. Côté process il s'agit du 16FFC (ou d'une variante) de TSMC, la troisième version "optimisée" du 16nm de TSMC. Annoncée en janvier dernier, le C signifie "Compact" et ce process vise avant tout les usages basses consommation tout en réduisant de manière significative les coûts de fabrication.

D'après Chipworks, l'utilisation des bibliothèques optimisées permet une bien meilleure utilisation du die, avec une compacité équivalente à celle des process TSMC précédents. Chipworks estime que la même puce aurait demandé 150mm2 en 16FF. Etant donné que 70 tapeouts de clients de TSMC sont attendus sur ce process cette année, les progrès de densité du 16FFC devraient profiter assez largement, on attendra de voir les constructeurs qui annonceront des puces l'utilisant.


Chipworks note également que l'A10 est beaucoup moins haut que les générations précédentes. Comme beaucoup de SoC, il est de type PoP et embarque la mémoire au dessus du die logique. Cependant plutôt que d'empiler les quatre dies de mémoire (2 Go de LPDDR4 Samsung sur l'A10 de l'iPhone 7), ils sont placés côte à côte.
Qui plus est, comme nous le supposions la puce utilise le nouveau packaging InFo de TSMC (dans sa version InFo-PoP) pour relier les dies entre eux.
big.LITTLE et performances
Côté performances les premiers benchmarks synthétiques évoquent 40% de gains pour le CPU ARM par rapport à l'année dernière, tout en restant en 16nm.
Pour arriver à ce gain, Apple augmente d'abord significativement la fréquence, passant de 1.85 GHz sur l'A9 à 2.35 GHz sur l'A10. Sur ce point, la marque exploite à la fois la marge notée de son process l'année dernière (on peut supposer facilement que l'A9 aurait eu une fréquence plus élevée s'il avait été sourcé uniquement chez TSMC) et les gains apportés par le 16FFC.

Ce gain de 27% de fréquence est accompagné de changements au niveau de l'architecture. Ceux ci ne sont pas encore connus, au delà du nom Hurricane, mais Chipworks note que le cluster CPU prend une place plus importante sur le die, 16mm2 face à 13mm2 sur l'A9, malgré l'utilisation d'un process plus compact.
Il est cependant difficile de se baser sur cette différence de taille étant donné que l'A10 est en réalité un quad core big.LITTLE dans la nomenclature ARM. En plus des deux coeurs hautes performances à 2.35 GHz (big), deux coeurs basse consommation à 1.05 GHz (LITTLE) sont également présents sur le die (leur emplacement exact est pour l'instant inconnu, ce qui vaut les points d'interrogation sur le diagramme au dessus).
Contrairement à d'autres implémentations dans l'écosystème ARM, les applications ne peuvent pas utiliser en simultanée les deux blocs de coeurs, le passage de l'un à l'autre étant transparent pour elles (géré par la puce et l'OS). L'intérêt de cet arrangement est bien entendu d'augmenter l'autonomie en ne sollicitant les coeurs haute performances que lorsque nécessaire.
Déjà largement en avance côté performances sur le reste de l'écosystème ARM, l'A10 commence à devenir embarrassant même pour Intel, dépassant un Core M Skylake en monothread sous Geekbench 4 (voir ici et là ), avec un "TDP" au moins deux fois inférieur (et sans mécanisme Turbo).
Intel se consolera tout de même de sa présence dans une partie des iPhone 7 car c'est l'autre information de Chipworks, la société confirme qu'une partie des modèles utilise un modem Intel XMM 7360 (certains modèles intègrent un modem Qualcomm X12). Très en retard, le XMM 7360 est un modem LTE 450 Mb/s Cat 10 certes dessiné par Intel, mais fabriqué selon toutes vraisemblances comme ses prédécesseurs... par TSMC.
Hot Chips : M1, SVE, Parker, InFo et Skylake !
La conférence Hot Chips qui se tenait la semaine dernière a donné lieu a d'autres annonces intéressantes que nous avons essayé de regrouper dans cette actualité !
Rajouter des tiers de mémoire côté serveur
On avait déjà noté un peu plus tôt la volonté de rajouter de la mémoire HBM à divers endroits, et même la volonté de Samsung de travailler sur une version moins onéreuse, mais l'on rajoutera ce slide issu d'une présentation d'AMD qui rappelle les objectifs de la société côté serveurs, prenant pour le coup l'exemple du big data
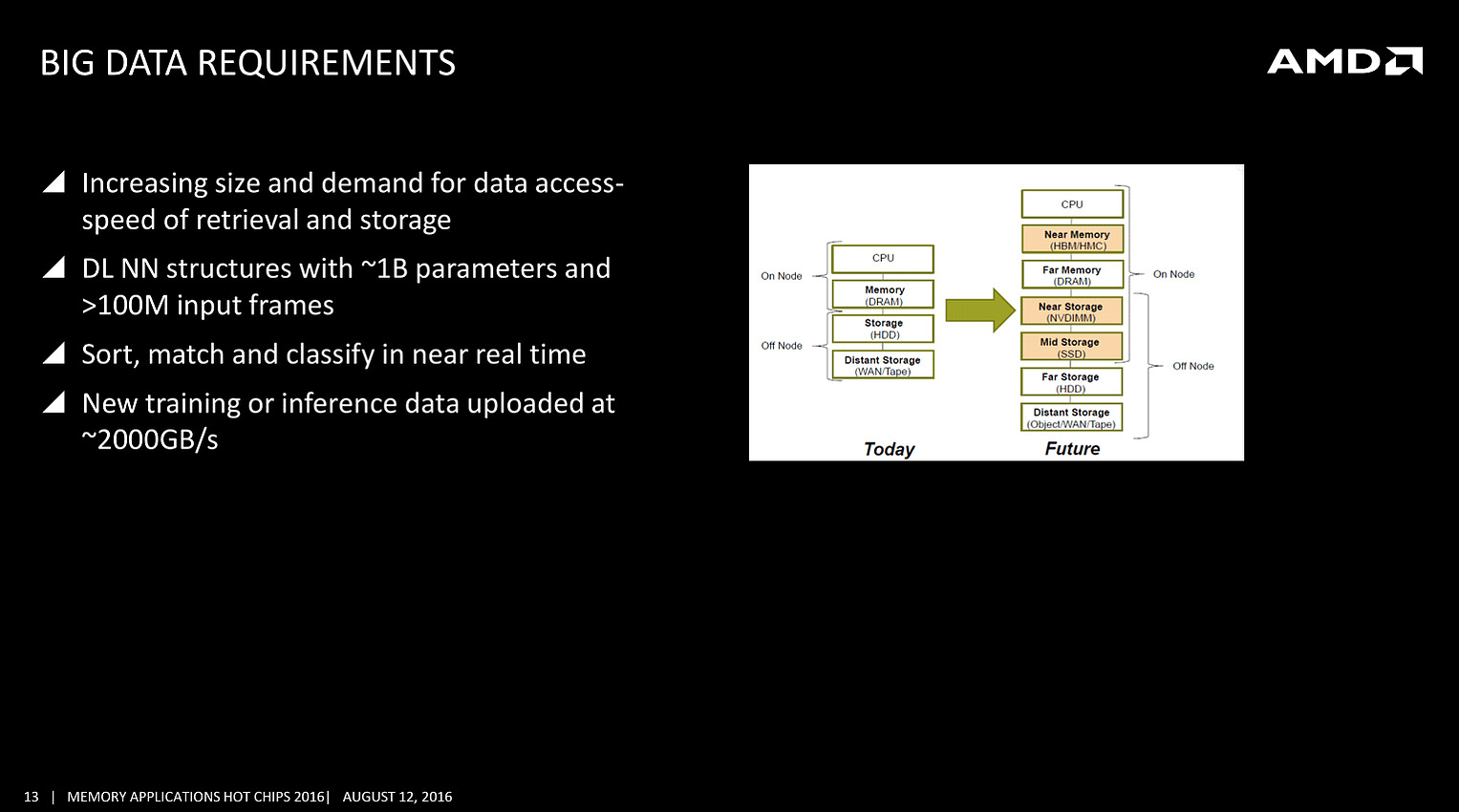
On s'attardera sur le graphique à droite qui pointe l'ajout d'une mémoire intermédiaire côté CPU, type HBM ou HMC (AMD misera plutôt sur la HBM pour les déclinaisons serveurs de Zen), et aussi l'utilisation de NVDIMM pour s'intercaler avant un SSD. Il faudra attendre encore un peu pour voir comment seront déclinées ces technologies, mais il est intéressant de noter la manière dont les avancées côté mémoire sont mises en avant, parfois un peu trop tôt comme l'a fait Intel avec 3D XPoint, dans toute l'industrie.
Quelques détails de plus sur SVE
Chez ARM, outre une présentation de Bifrost côté GPU dont on vous avait déjà parlé, l'annonce principale concernait SVE, la nouvelle extension vectorielle introduite par la société.
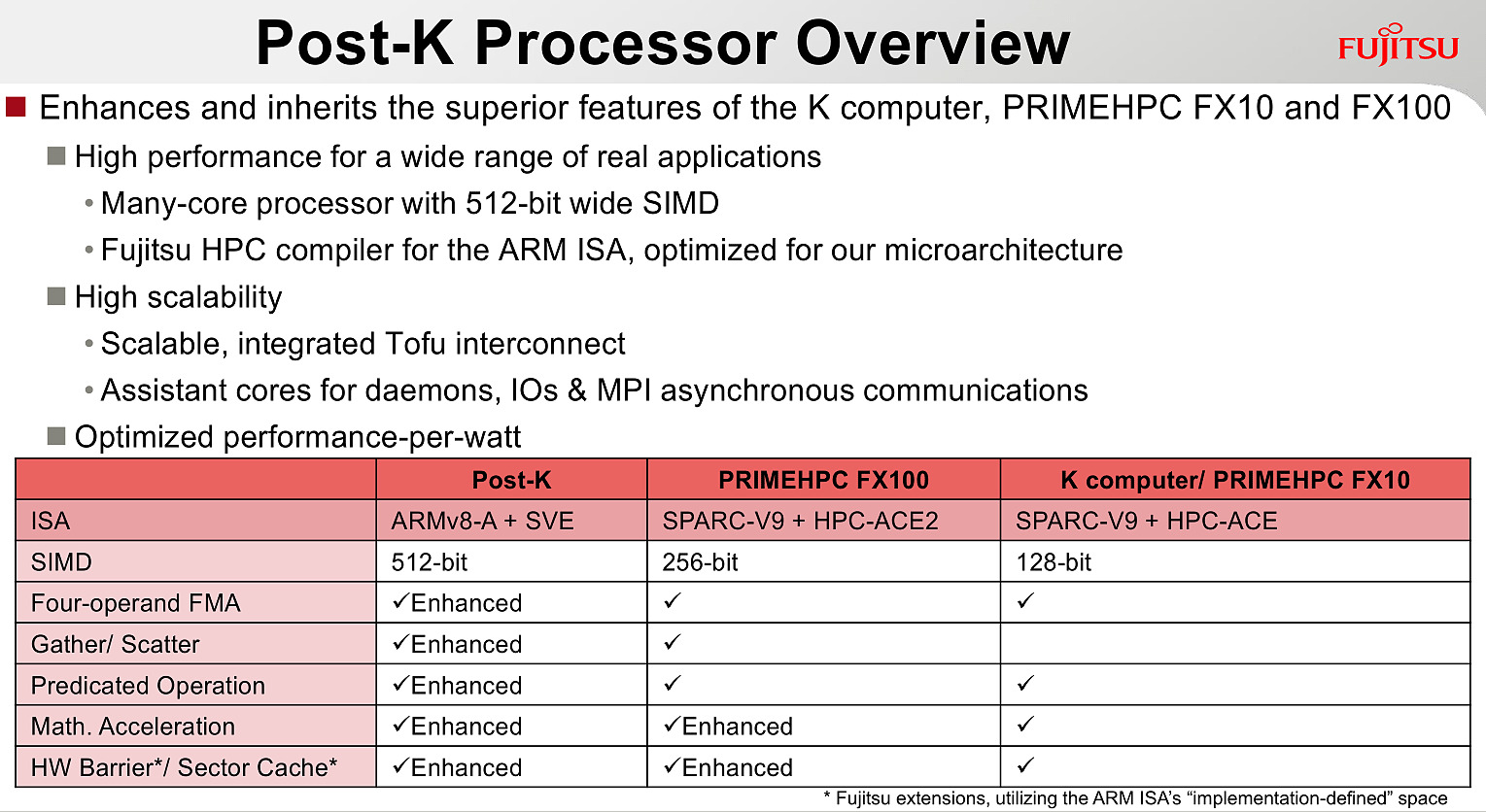
Le premier partenaire annoncé par ARM est Fujitsu, qui mettra au point des processeurs ARMv8 avec extension SVE pour le futur supercalculateur japonais Post-K. Fujitsu a donné quelques détails, indiquant par exemple que les unités vectorielles auraient une largeur de 512 bits sur ses puces.


Chez ARM, le constructeur présente plusieurs benchmarks assez théoriques, on notera surtout sur les barres grises les améliorations qui ont été effectuées côté auto-vectorisation, c'est a dire la capacité du compilateur à utiliser des instructions vectorielles pour extraire du parallélisme. ARM devrait proposer dans les semaines qui viennent des patchs pour les différents compilateurs open source, incluant LLVM et GCC.
Le Samsung M1, un timide premier pas
La particularité de l'écosystème d'ARM est que les partenaires peuvent soit utiliser des coeurs "clefs en main", développés par ARM (les gammes Cortex, comme par exemple le Cortex A57), ou créer leurs propres implémentations de l'architecture ARM (qui restent compatibles, tout en étant différentes, à l'image des processeurs d'AMD et d'Intel qui diffèrent bien que restant compatibles). Plusieurs sociétés disposent de licences "architecture" qui permettent de créer ces puces, Apple étant jusqu'ici la société la plus à la pointe sur armv8 même si de nombreuses sociétés proposent tour à tour leurs architectures.

Parmi les nouveaux venus, il y a Samsung qui s'est lancé lui aussi dans le design d'une architecture armv8 custom pour ses Exynos M1. A la tête du projet, on retrouve Brad Burgess qui était architecte chez AMD pour les Bobcat. Il aura même été rejoint un court instant par Jim Keller (K8 chez AMD, A7 chez Apple, puis Zen chez AMD), qui n'est cependant pas resté très longtemps chez Samsung et qui n'aura probablement pas eu un grand impact. Le projet aura nécessité trois années, et en soit arriver a produire quoique ce soit du premier coup en un temps si court est un exploit.
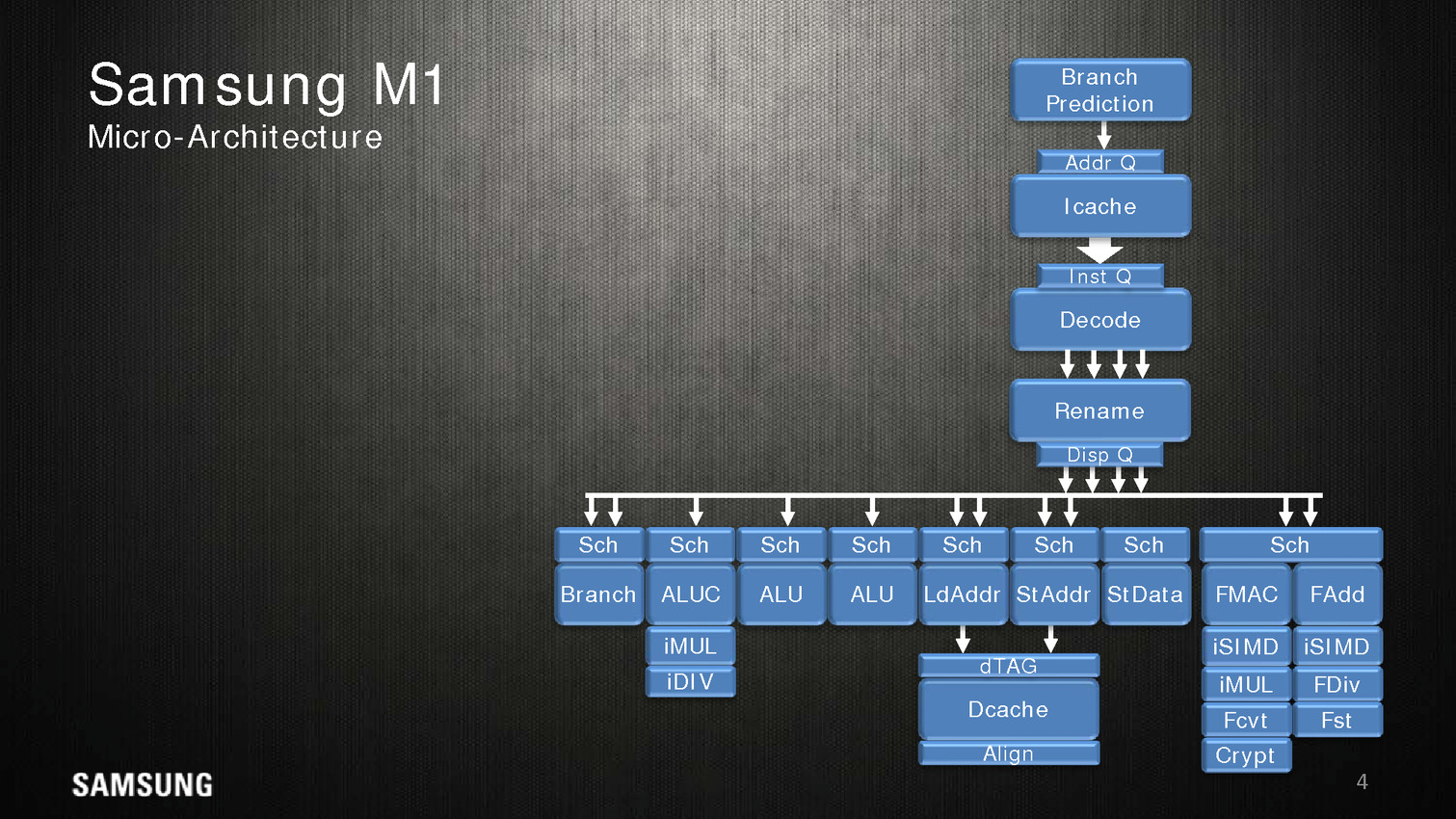
Côté architecture, Samsung indique utiliser un perceptron (un réseau de neurones simple) au niveau de ses mécanismes de prédiction de branches. Deux branches sont considérées par cycle, mais il est difficile d'estimer quoique ce soit sur l'éventuelle efficacité.
Quatre instructions peuvent être décodées/dispatchées par cycle aux unités d'exécutions qui sont regroupées sur sept files. On note deux files dédiées aux écritures mémoires, trois aux opérations mathématiques simple (avec un port sur lequel sont ajoutés les multiplications/divisions) et une aux branchements. Les opérations en virgules flottantes sont regroupées séparément avec un scheduler unique pour deux files. Samsung annonce 5 cycles pour effectuer une opération FMA.
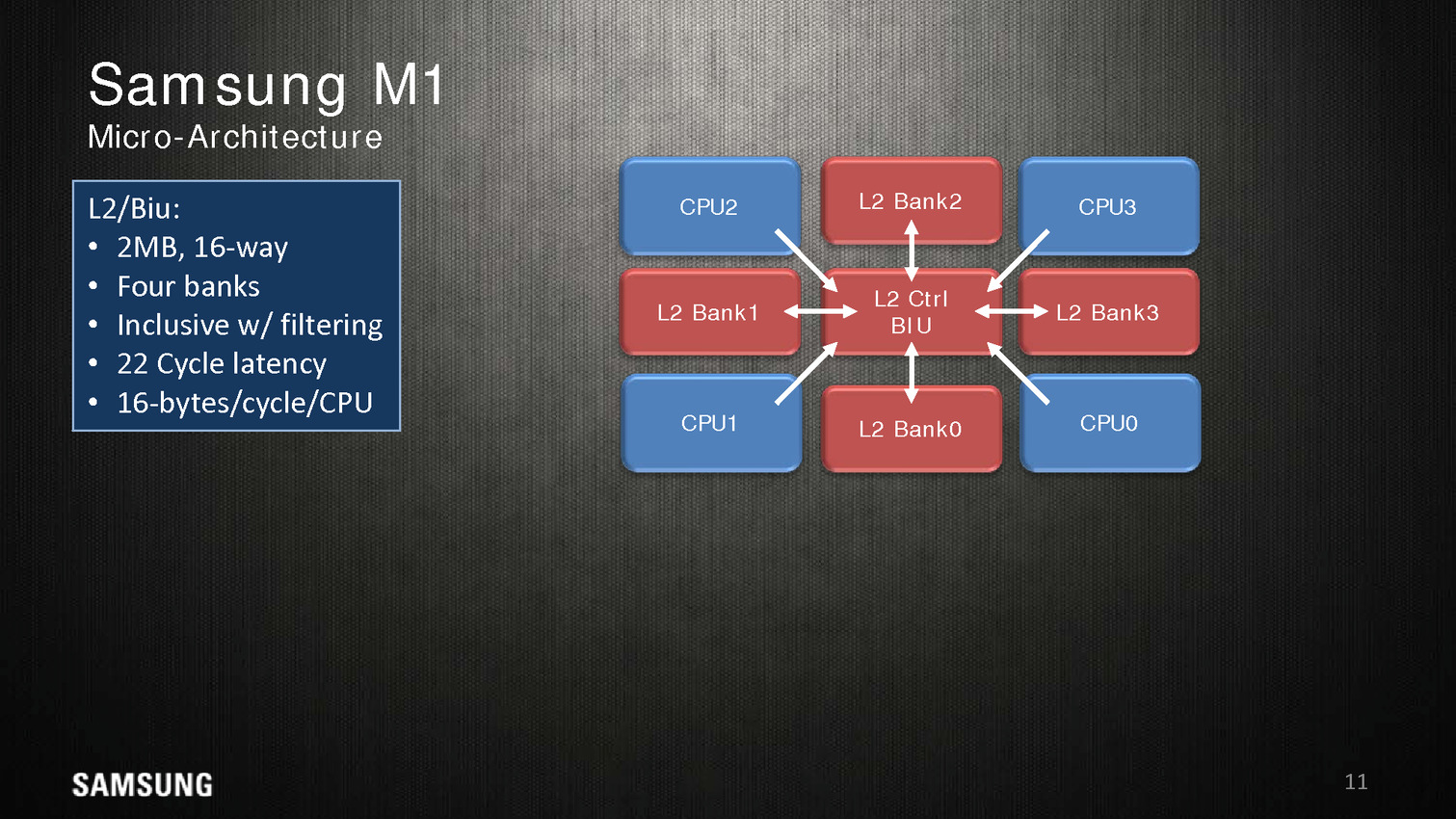
Dans une configuration quatre coeurs, le M1 dispose de 2 Mo de cache L2 coupé en quatre blocs, les coeurs accèdent au L2 via une interface commune. On appréciera aussi les schémas très spécifiques que propose Samsung, pas vraiment avare de détails techniques.

Reste qu'en pratique, les benchmarks mis en avant par Samsung ne sont pas forcément très convaincants. Avec 200 MHz de plus, sur un coeur, un M1 propose 10% de performances en plus qu'un Cortex A57 à consommation égale, ce qui est tout de même très peu. Samsung fait beaucoup mieux sur les opérations mémoires (c'est relativement facile, on l'a évoqué de nombreuses fois, les contrôleurs mémoires ARM ne sont pas particulièrement véloces/adaptés aux hautes performances), mais n'en tire pas particulièrement profit hors des benchmarks théoriques.
La présentation se termine en indiquant que ce n'est qu'un premier pas pour Samsung et que d'autres designs sont en cours d'élaboration. En soit si les performances ne vont pas révolutionner le monde des SoC ARM, Samsung a au moins une base de travail qu'ils pourront faire évoluer par la suite. A condition évidemment que Samsung continue d'investir sur le sujet dans les années à venir !
Les curieux pourront retrouver la présentation en intégralité ci dessous :














Parker/Denver 2 : design asymétrique
Nvidia était également présent à Hot Chips, donnant quelques détails sur son futur SoC baptisé Parker. Ce dernier est annoncé comme crée spécifiquement pour le marché automobile avec des fonctionnalités dédiées à ce marché. On ne sait pas si le constructeur le déclinera en d'autres versions plus génériques.

Les détails techniques ne sont pas particulièrement nombreux, on notera côté SoC que l'encodage 4K est désormais accéléré à 60 FPS, que l'on peut contrôler jusque trois écrans en simultanée, et que le contrôleur mémoire passe sur 128 bits (contre 64 précédemment). Côté GPU, Parker utilisera une version dérivée de son architecture Pascal.



C'est du côté CPU que les choses sont les plus originales, après avoir utilisé son architecture Denver sur les TK1, puis être revenu aux Cortex A57 sur les TX1, Nvidia propose une architecture asymétrique avec deux coeurs "Denver 2" (sur lesquels aucun détail n'aura été donné, à part un gain performance/watts de 30% donné sans précision sur les process comparés) et quatre coeurs Cortex A57. Ce n'est pas la première fois que l'on voit des configurations originales, durant Hot Chips, le taiwannais MediaTek présentait un SoC 10 coeurs avec quatre coeurs Cortex A53 à 1.4 GHz, quatre coeurs Cortex A53 à 2 GHz, et deux coeurs Cortex A72 à 2.5 GHz !
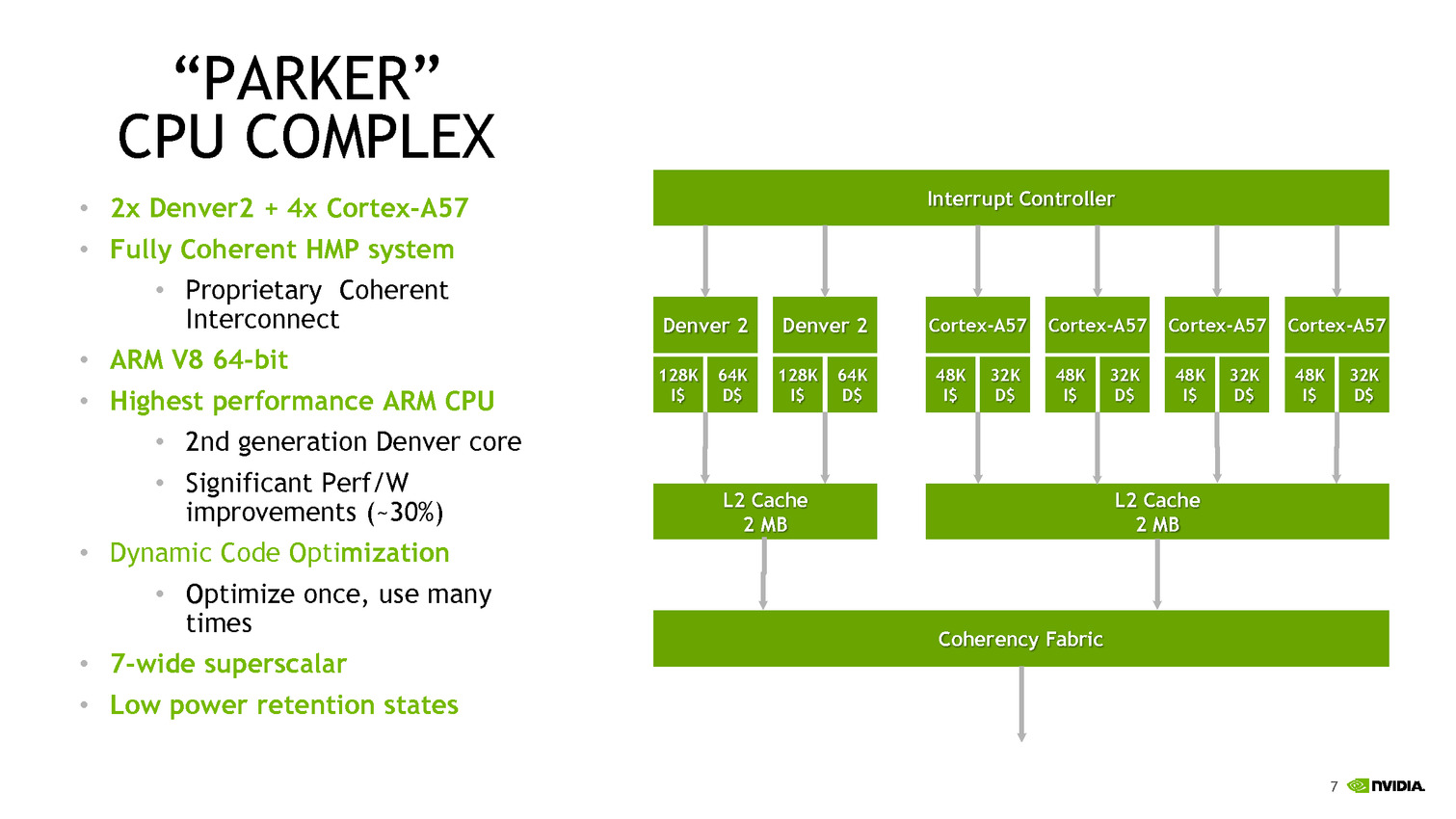
Dans le cas de MediaTek, l'idée est de proposer différentes options à différents niveaux de consommation. Pour ce qui est de Nvidia, le choix est différent, le Cortex A57 étant "haute performance" contrairement aux A53 de MediaTek. Il faut dire surtout que le marché visé, l'automobile, n'a pas les mêmes contraintes de consommation que le marché mobile. Reste que Nvidia se doit de gérer cette asymétrie avec un scheduler qui doit décider sur quel coeur placer les threads, ce qui n'est pas particulièrement simple. On notera que chaque groupe de coeurs dispose de son propre cache L2 de 2 Mo.
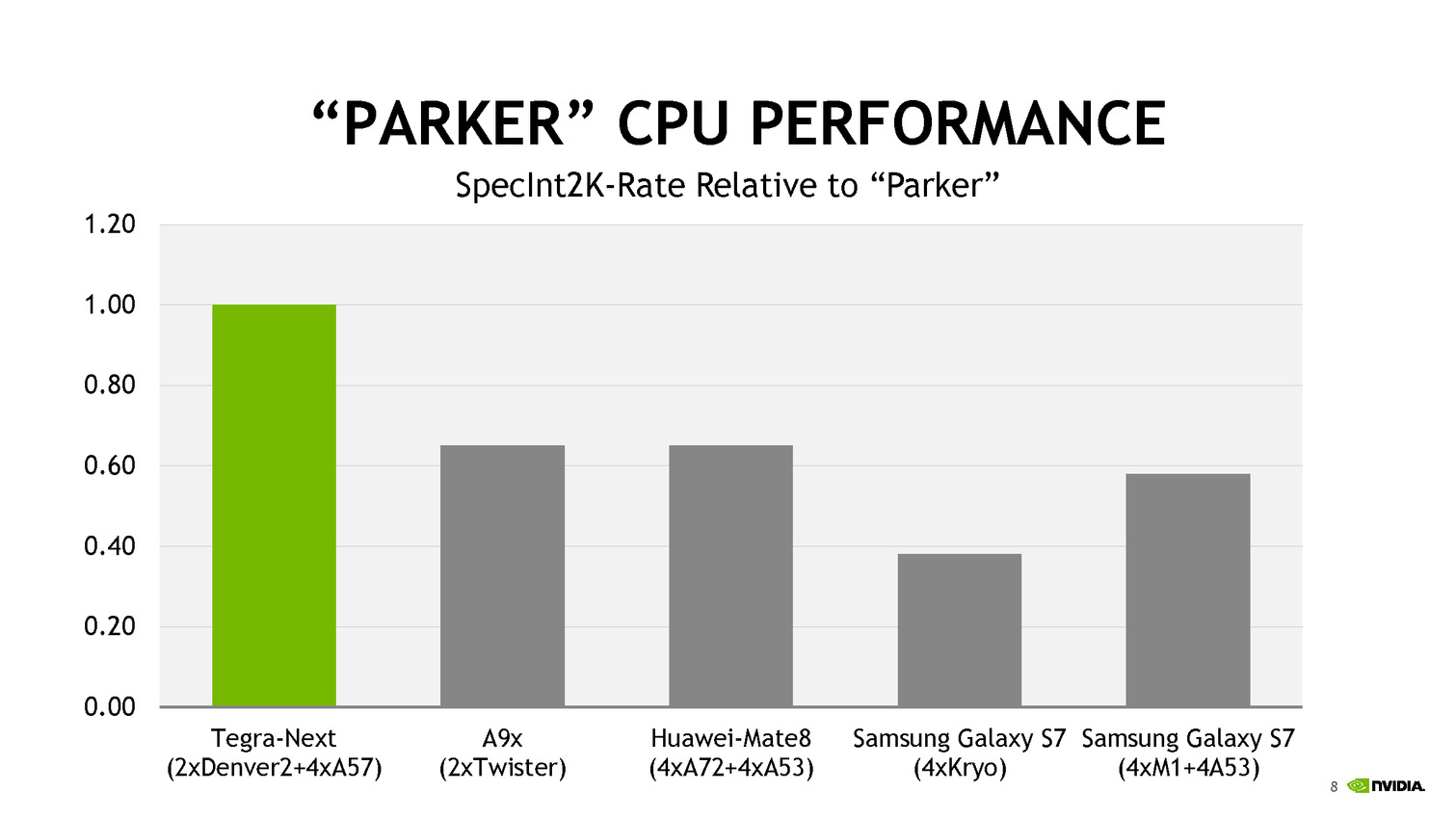
Côté performances, Nvidia avec ses 6 coeurs se présente comme moitié plus rapide qu'un A9X d'Apple en deux coeurs. Le graphique mélangeant des puces à TDP différents (on y retrouve des puces pour smartphones et pour tablettes), on admettra que la comparaison n'est pas faite à TDP identique.
TSMC parle de ses packages InFo
Une des nouveautés présentées cette année par TSMC est la disponibilité d'un nouveau type de packaging, l'InFo-WLP. L'idée est de permettre de relier plusieurs dies en les "moulant" dans un substrat commun très fin qui contient également les interconnexions entre les puces. Il s'agit d'une version à cout beaucoup plus faible que les interposer (utilisés par exemple par AMD pour Fiji).
La présentation de TSMC est dédiée aux interconnexions entre les puces, et présente une puce 16nm reliant un SOC à une puce mémoire avec une bande passante de 89.6 Go/s sur 256 bits, le tout avec une consommation très réduite.
En plus de la solution présentée qui évoque le cas simple d'une puce mémoire et d'un Soc, TSMC évoque la solution comme permettant un jour de relier également plusieurs dies de logique, par exemple des groupes de coeurs séparés, pour réduire le coût de fabrication des puces (qui augmentent exponentiellement avec la taille des dies).
































La présentation est technique mais reste intéressante, l'InFo-WLP ouvre des opportunités supplémentaires pour réaliser des produits qui mélangent processeur et mémoire. Le coût réduit et la finesse de l'interconnexion fait qu'on pourrait retrouver assez rapidement cette technique utilisée, y compris sur le marché mobile. Les prochains SoC d'Apple pourraient par exemple utiliser un tel package.
Et Skylake !
Juste avant la présentation de Zen, Intel proposait aussi une présentation de son architecture Skylake, lancée l'année dernière. Si la majorité du contenu est déjà connu, on aura noté un détail intéressant : un diagramme sur les unités d'exécution de Skylake. On rappellera que l'année dernière durant l'IDF, Intel nous avait promis plus de détails sur le sujet, sans jamais nous les donner !
Pour rappel, voici la répartition sur Haswell :
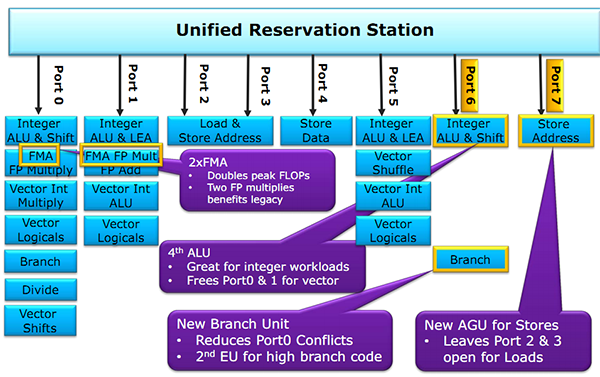
Récapitulatif des ports/unités d'exécution sur Haswell
Un an après, voici enfin un diagramme similaire pour Skylake :
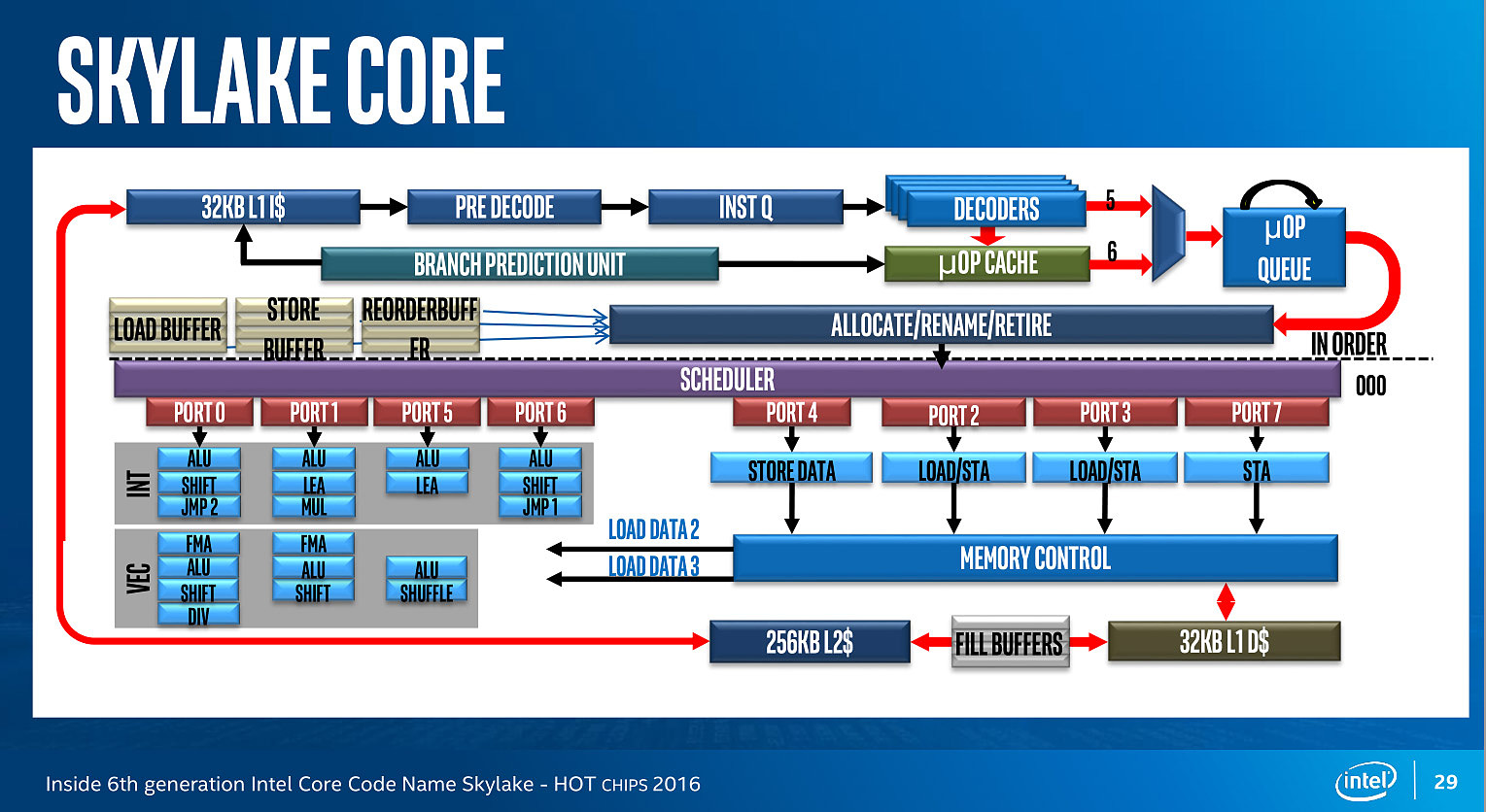
Conformément à ce que nous avaient indiqué les ingénieurs d'Intel l'année dernière, le nombre d'unité a bel et bien augmenté. Le nombre de ports reste constant, à 8, mais l'on compte... une nouvelle unité. Sur le port 1, Intel a en effet ajouté une unité de shift vectorielle. Pour le reste, la répartition reste similaire à celle d'Haswell. Un mystère enfin élucidé !
Intel Custom Foundry prend une licence ARM !
 ARM l'a confirmé par un post de blog : Intel Custom Foundry, l'activité fabrication tiers d'Intel, est désormais détentrice d'une licence ARM Artisan pour le 10nm !
ARM l'a confirmé par un post de blog : Intel Custom Foundry, l'activité fabrication tiers d'Intel, est désormais détentrice d'une licence ARM Artisan pour le 10nm !
Il faut rappeler qu'Intel est plutôt un cas à part dans le monde des semi-conducteurs, étant l'une des rares sociétés à disposer de ses propres usines, utilisées quasi uniquement pour la production de ses propres puces. La plupart des autres acteurs du marché ont migré vers la séparation de l'activité design d'un côté (on parle de sociétés fabless, c'est le cas dans le monde du GPU avec AMD et Nvidia), et de l'autre la fabrication dans des sociétés tierces spécialisées (on parle de foundry, la plus connue étant TSMC qui fabrique des puces pour de multiples clients).
Avec la difficulté de la mise au point des nouveaux process de fabrication, qui n'a fait qu'empirer ces dernières années, il est de plus en plus complexe pour une société à elle seule de justifier l'investissement nécessaire pour faire évoluer sans cesse ses usines. Qui plus est, la réduction de la taille des transistors fait que la capacité des usines augmente d'année en année, et qu'il faut disposer de très larges volumes de puces à produire, au risque de voir ses usines tourner à vide.
Un casse tête qui aura poussé plusieurs sociétés à se séparer de leurs usines (pour des raisons différentes) d'abord AMD en 2009 (créant GlobalFoundries) et plus récemment IBM (dont l'activité fabrication à été rachetée elle aussi par GlobalFoundries).
Depuis quelques années, en plus de fabriquer ses propres puces dans ses usines, Intel a décidé d'entrer très timidement, en 2010, sur le marché des fondeurs tiers en ouvrant son process à de petites sociétés qui n'étaient pas en concurrence directe avec ses produits (le premier client était Achronix, designer de FPGA en 22nm). D'autres clients ont suivi, principalement sur les FPGA, le client le plus connu d'Intel ayant été Altera... même si au final Intel aura décidé de racheter son client à la mi-2015 !
Pour Intel, la nécessité d'ouvrir ses usines est un casse tête. D'un côté, la société tente d'être présent sur tout les marchés, en déclinant le x86 - technologie "maison" sur laquelle la concurrence est limitée - à toutes les sauces et avec un soupçon de recyclage, que ce soit avec des produits serveurs spécialisés comme les Xeon Phi basés sur des Pentium pour leur première génération, ou les Quark dédiés à l'embarqué et utilisant une architecture de 486 datant d'une bonne vingtaine d'années !
Si l'envie de la société d'être présente sur tous les marchés est là, en pratique les succès ne sont pas systématiquement au rendez vous, Intel ayant par exemple massivement raté le marché des smartphones. Cumulé à la baisse continue des ventes sur le marché historique des PC, l'ouverture des usines à des clients tiers se dessine de plus en plus comme une nécessité pour Intel, même si l'avouer semble impossible à la société, qui continuait donc d'envoyer des signaux mitigés aux possibles futurs clients de son activité fabrication.
Avec l'annonce d'aujourd'hui, les choses sont - peut être - en train de changer puisque la prise de licence ARM par Intel est tout sauf anodine. Ce n'est pas la première fois qu'Intel fabriquera des SoC ARM, on l'avait vu avec Altera qui utilisait un core ARM dans un usage très spécifique.
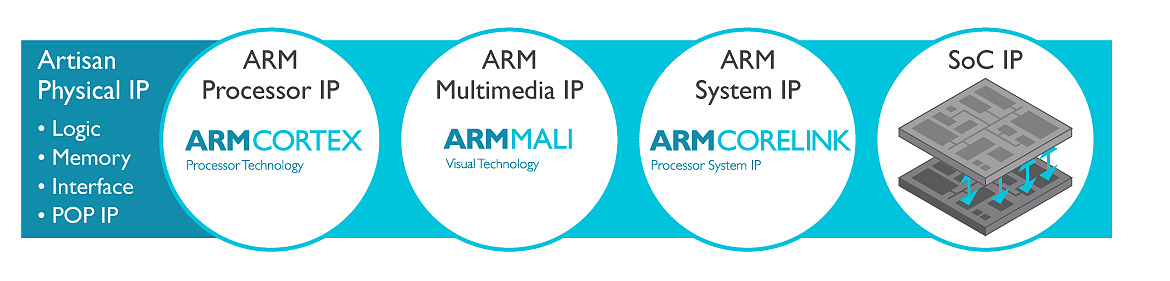
La licence Artisan Physical IP inclut en effet toutes les briques nécessaires pour la création de puces ARM de tout types. Il s'agit de tous les blocs de base avec des bibliothèques haute densité et haute performance de transistors logiques,et également tout le nécessaire pour les différents types de mémoire. La licence inclut surtout POP IP, qui est pour rappel l'idée qui fait le succès d'ARM : permettre l'utilisation de blocs interchangeables et compatibles pour créer des puces custom. Ainsi un client peut choisir d'utiliser des coeurs CPU dessinés par ARM (les gammes Cortex) ou créer ses propres coeurs (c'est le cas d'Apple et plus récemment de Nvidia), de choisir un GPU (que ce soit les Mali d'ARM, ou les populaires PowerVR d'Imagination Technologies), et également de choisir son fournisseur pour les interconnexions.
Concrètement, Intel va donc "porter" ces bibliothèques d'ARM aux particularités de son futur process 10 nm, ce qui permettra aux partenaires d'ARM de porter à leur tour - s'ils le souhaitent - leurs blocs POP IP. ARM et Intel travailleront conjointement pour le portage de deux futurs blocs CPU ARM Cortex-A (probablement un autre successeur 10nm de l'A72, voir l'annonce de l'A73 en 10nm lui aussi), la déclinaison que l'on retrouve dans les smartphones et tablettes.
Faut il y voir un virage pour Intel ? Fabriquer des puces ARM pour smartphones, ce qu'ils feront pour LG (nouveau client annoncé dans la foulée) va forcément à l'encontre des ambitions internes d'Intel d'imposer le x86 sur mobile. Car si un peu plus tôt dans l'année Intel avait décidé d'annuler sa nouvelle génération de SoC pour smartphones (Broxton et SoFIA), le constructeur continuait en interne à travailler sur les générations suivantes tout en essayant de développer dans l'intérim son activité modem (Intel aurait possiblement gagné le marché du modem du prochain iPhone). A l'heure où ARM augmente ses ambitions pour aller attaquer le marché juteux des serveurs, on peut se demander jusqu'où ira réellement l'ouverture d'Intel.

Un futur CPU ARMv8 24 coeurs de Qualcomm
En fabriquant des puces concurrentes, Intel s'ouvre à des comparaisons directes qui pourraient être assez défavorables à ses architectures x86, assez peu adaptées à la basse consommation. L'avantage supposé du process d'Intel, s'il existe, ne pourra plus jouer en la faveur de ses propres solutions pour compenser un éventuel déficit architectural. La structure de marges d'Intel, là aussi très différente de celle des fondeurs tiers, posera là aussi rapidement problème.
Qui plus est, en obtenant la licence Artisan d'ARM, Intel va devoir partager tous les détails techniques, y compris les plus secrets, de son process en ce qui concerne les règles et les dimensions exactes des transistors, ce qui va l'exposer là aussi à une comparaison directe avec les autres acteurs installés du milieu (comme TSMC et Samsung). Il faudra un peu de temps pour mesurer les conséquences concrètes de tout cela, car cet accord ne concerne que le 10nm, un process pour rappel en retard et qui n'est prévu chez Intel que pour la fin de l'année 2017 en version mobile. Les dernières nouvelles du 10nm, sur lequel Intel ne communique pas, n'étaient pour rappel pas particulièrement rassurantes avec l'arrivée possible sur sa roadmap de puces 14nm... pour 2018.
L'EUV possiblement pour le 7nm ?
Le site SemiWiki nous rapporte quelques informations sur l'état de la fabrication EUV, en provenance de la conférence SPIE Advanced Lithography qui se tient actuellement à San José.
Lors de la même conférence l'année dernière, les nouvelles étaient pour rappel plutôt bonnes (voir le lien pour un rappel complet sur la fabrication des processeurs et l'importance capitale de l'EUV !) et l'on espérait une introduction en cours de process pour le 10nm, et une introduction complète à 7nm. Malheureusement, on le rappelait en janvier, TSMC avait calmé les ardeurs en indiquant qu'il faudrait attendre le 5nm pour une éventuelle introduction de cette technologie.
SemiWiki confirme certains chiffres donnés lors de la dernière conférence aux investisseurs de TSMC, à savoir que la machine avait atteint sur une période de quatre semaines une production de 518 wafers/jour, un niveau encore largement insuffisant. Intel a partagé également quelques chiffres, un peu inférieurs à ceux de TSMC, à savoir entre 2000 et 3000 wafers par semaine (285-428 par jour).
On notera quand même que le taux de disponibilité des scanners de la société ASML a augmenté, passant de 55 à 70% chez TSMC (Intel rapportant une disponibilité identique) ! On notera que s'il est question d'une introduction en début de node à 5nm, TSMC laisse la porte ouverte pour le 7nm si jamais des progrès étaient effectués. Intel de son côté n'a pas donné d'information. Samsung envisagerait l'introduction à 7nm selon les présentations, sans plus de précisions.
Si la question de la disponibilité est importante, celle de la puissance de la source lumineuse l'est encore plus. Après avoir été limité à 40 watts l'année dernière, les machines actuellement en évaluation chez TSMC disposent désormais de sources 80 watts. C'est mieux, mais cela reste loin des 250 watts promis par ASML pour fin 2015. Les dernières prédictions sont désormais de 250 watts en 2016-2017, et au delà en 2018-2019, des plages particulièrement larges.
Atteindre les 250 watts de puissance permettrait d'augmenter significativement la cadence de production, atteignant 170 wafers/heure en théorie. ASML a effectué des démonstrations que TSMC et Intel semblent juger prometteuses de 185 et 200 watts. Reste à les voir en production, bien évidemment. Les challenges de cette technologie restent complexes et ne se limitent pas à ces deux points cruciaux, la question des défauts dans les masques est elle aussi importante même si là aussi TSMC et Intel ont visiblement noté quelques progrès. Vous pouvez retrouver plus de détails sur ces points dans l'article de SemiWiki .