
Les contenus liés aux tags Intel et TSMC
Afficher sous forme de : Titre | Flux46% de parts de marché pour TSMC
Le 20nm en production chez TSMC
L'EUV prêt chez ASML pour 2015 ?
TSMC aurait signé Apple pour le 20nm
Impact de l'EUV et du 450mm selon Intel
L'ITRS prépare l'après loi de Moore



C'est la section actualité de la très sérieuse revue scientifique Nature qui l'affirme : la loi de Moore est arrivée à son terme. Énoncée en 1965 par Gordon Moore, l'un des cofondateurs d'Intel, il s'agit d'une observation par laquelle la quantité de transistors dans les circuits intégrés doublait à peu près tous les ans. Une observation transformée en loi pour prédire que cette cadence pouvait être extrapolée pour les années à venir.
En 1975, la loi avait été révisée pour prendre la forme que l'on connaît actuellement, à savoir un doublement des transistors tous les deux ans. L'importance de la loi de Moore allait cependant au-delà de la simple prédiction puisqu'elle prenait en compte les coûts de fabrication : l'observation se fait sur les puces ayant le coût par transistor le plus faible (tentant donc de prendre en compte les questions de yields et de défauts en fonction de la taille des puces).
Plus qu'une prédiction, la loi de Moore a servie, particulièrement chez Intel, de guide au fil des années, prédisant à l'avance les budgets en nombre de transistors alloués aux ingénieurs, et poussant vers l'avant la nécessité d'investir dans de nouveaux process de fabrications, la fameuse stratégie du Tick-Tock poussée d'abord en interne par Pat Gelsinger au début des années 2000 avant d'être utilisée publiquement pour décrire les générations à venir.
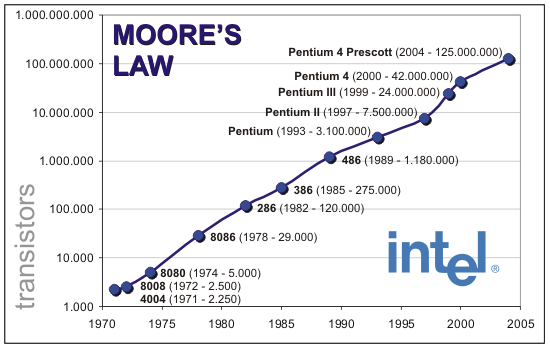
De manière intéressante, au-delà d'Intel, c'est toute l'industrie du semi-conducteur qui s'est mise d'accord autour de la loi de Moore, à savoir non seulement les fondeurs, mais aussi et surtout les fournisseurs d'outils. Le besoin de coordination entre tous les acteurs aura conduit à l'élaboration d'une roadmap, d'abord appelée National Technology Roadmap for Semiconductors dès 1993, avant d'être renommée sous sa forme actuelle, l'International Technology Roadmap for Semiconductors (ITRS).
Le rôle joué par cette roadmap, dont la dernière version a été publiée en 2013 aura été particulièrement important ces dernières années où, passé le 90nm, les challenges techniques ont contraint à des changements d'approches importants. L'augmentation des performances par la fréquence, méthode classique aura atteint un plateau à cause de l'augmentation de la consommation, poussant dans le commerce les stratégies de multiplication des coeurs que l'on connaît. Le rôle de la roadmap, au-delà de la concertation, est de s'assurer de trouver des pistes pour continuer la cadence de réduction des coûts/augmentation des transistors de la loi de Moore.
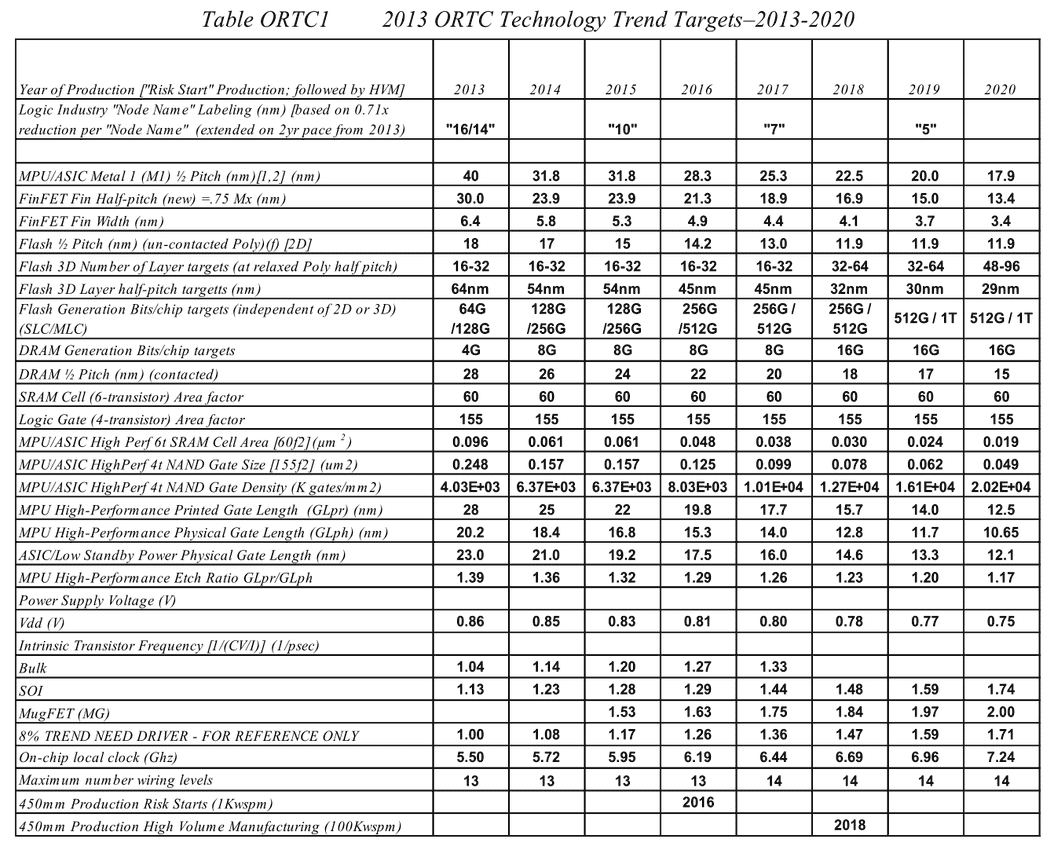
La dernière roadmap ci-dessus donnait des grandes lignes sur la manière de mettre à l'échelle les différents composants des transistors. Après les difficultés autour du 90nm, l'industrie est passé progressivement de la règle dite de la mise à l'échelle géométrique (on réduit tout dans des proportions identiques, le nom du node indiquant en général la taille de la porte) à celle de la mise à échelle par équivalence (equivalent scaling).
Etant donné que différentes parties composant les puces posent des problèmes différents, des règles d'équivalences ont été mises au point pour permettre de continuer a atteindre les buts de réduction des coûts/augmentation de densité imposé par la loi de Moore (on peut voir sur le tableau la couche d'interconnexion M1 et l'écart minimal entre deux transistors FinFET, en passant par des estimations des tailles de blocs fondamentaux comme la SRAM).
Pour 2016, la roadmap annonçait par exemple de la SRAM 6 transistors (6T) haute performance en 10nm autour de 0.048 µm2, ce qui n'est pas très éloigné de ce que présentait Samsung il y a une dizaine de jours de cela. En pratique cependant, on notera qu'on est globalement assez en retard sur la roadmap qui prévoyait des débuts de production à petite échelle en 10nm en 2015 (Risk Start dans la roadmap, suivi de HVM, fabrication en volume). Chez TSMC par exemple, la production risque est prévue pour la fin 2016 avec une production en volume pour 2017. Intel prévoit ses puces en volume pour 2017 également.
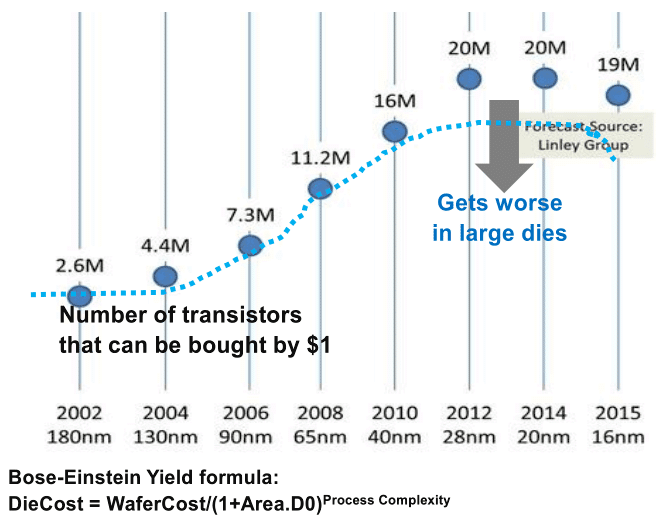
Évidemment depuis 2013 les choses se sont un peu plus compliquées et l'absence de roadmap en provenance de l'ITRS n'a pas forcément aidé. En pratique, la réduction des coûts s'est arrêtée, avec même un retour en arrière à 16nm signant de facto la fin de la loi de Moore, comme on peut le voir sur cette estimation ci-dessus tirée d'une présentation de l'ITRS en février 2015.
L'absence de nouvelle roadmap en provenance de l'ITRS aura même donné lieu à des divergences d'interprétations fortes, Intel titillant ses concurrents sur la question de la densité théorique. TSMC et Samsung ont fait pour rappel le choix de conserver un BEOL (Back End of Line, la partie basse d'une puce qui sert à l'interconnexion des transistors) commun entre le 20 et le 16nm pour accélérer la cadence de mise en production. En pratique chez TSMC, malgré le BEOL commun, le half pitch M1 reste tout de même dans les clous à 32nm (entre 40 et 31.8 sur la roadmap).
La densité pratique reste de toute manière très différente de ce que peuvent proposer des formules grossières comme celle utilisée par Intel (qui multipliait le pitch M1 par le pitch entre deux portes), qui pour exploiter les FinFET aura fait le choix d'utiliser pour certains de ses transistors critiques des structures plus larges composées de plusieurs fins (dans des proportions non négligeables même si la proportion exacte est rarement évoquée de manière précise par Intel).
Cumulé a de multiples autres détails (différents types de blocs sont présents avec des densités différentes, de la SRAM aux blocs plus ou moins critiques) il est impossible de tirer grand-chose de la théorie. L'écart entre un Core M Broadwell 14nm fabriqué par Intel (82mm2 pour 1.3 milliards de transistors) et un A8 fabriqué par TSMC en 20nm (89 mm2 pour 2 milliards de transistors) montre qu'il est difficile de comparer quoique ce soit à moins de prendre deux puces strictement identiques. Cela aura été possible pour l'A9 d'Apple, dont la superficie atteint 96mm2 chez Samsung contre 104.5mm2 chez TSMC.

Le mois prochain, l'ITRS devrait donc enfin communiquer une nouvelle roadmap qui d'après Nature tirera définitivement un trait sur la question de la loi de Moore comme moteur d'évolution unique. D'après Nature, la prochaine roadmap se concentrera sur les applications pratiques, allant du smartphones aux puces serveurs et regardera les applications pratiques, que ce soit au niveau circuits d'alimentations, des capteurs nécessaires, ou d'autres blocs de siliciums répondant à des besoins particuliers.
La véritable question est de savoir ce que comportera réellement cette roadmap qui serait rebaptisée d'après Nature International Roadmap for Devices and Systems, abandonnant même le mot transistor !
Ce que l'on sait, c'est que la réorganisation de l'ITRS en 2014 s'est faite autour de groupes de travaux, avec notamment un groupe baptisé « More Moore » pour évoquer les pistes techniques pour les prochains nodes, dont vous pouvez retrouver ci-dessous la dernière présentation datant de février 2015.



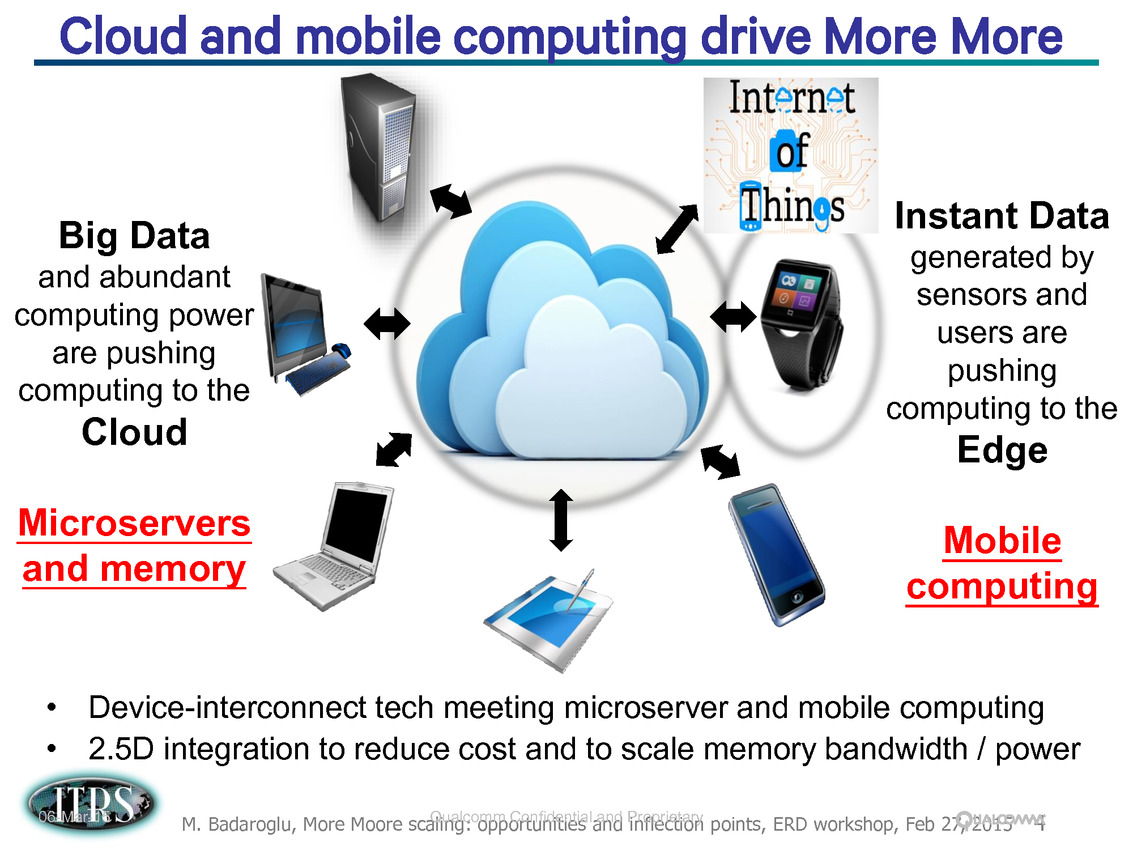
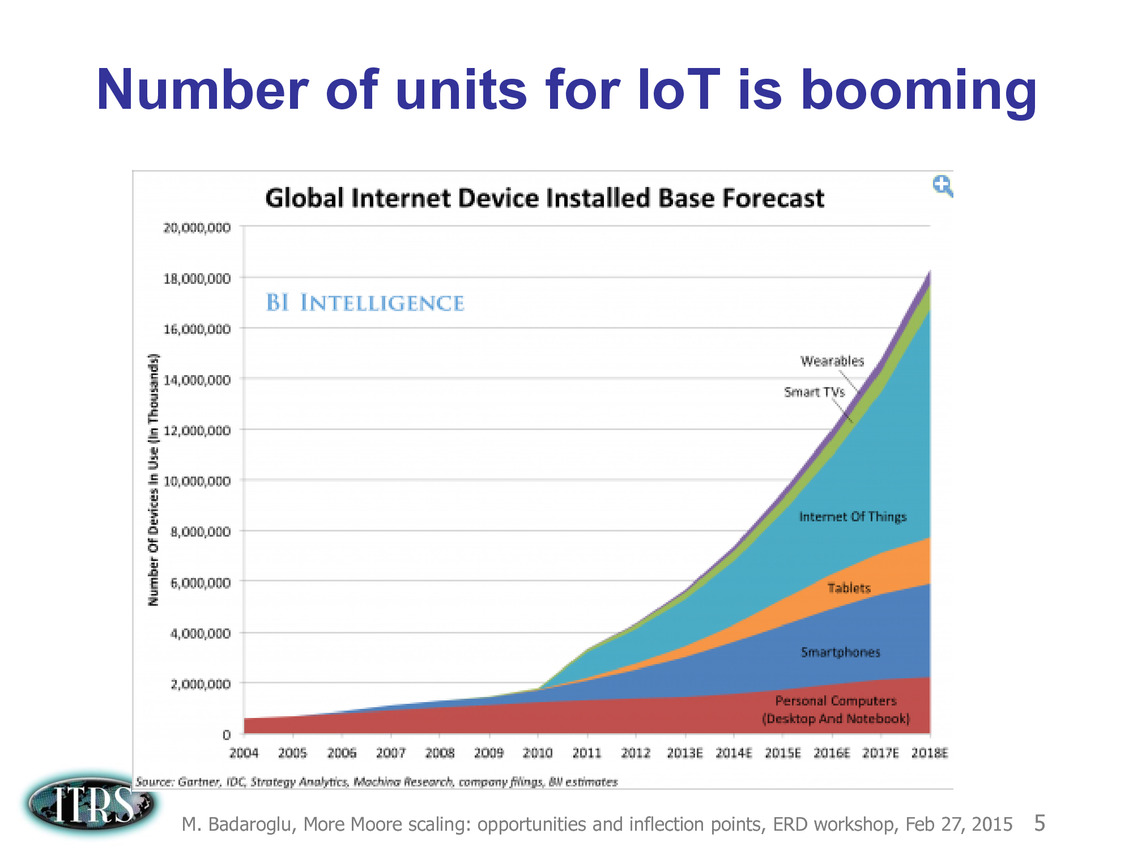

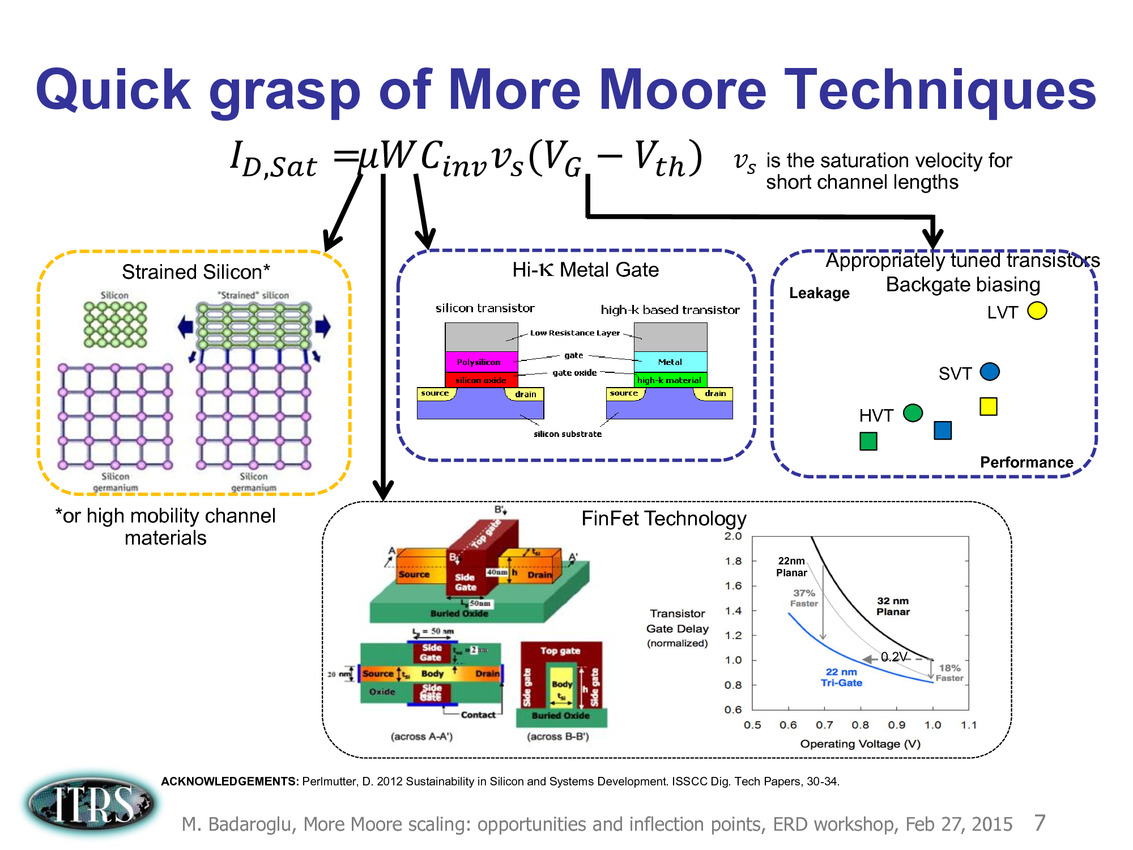
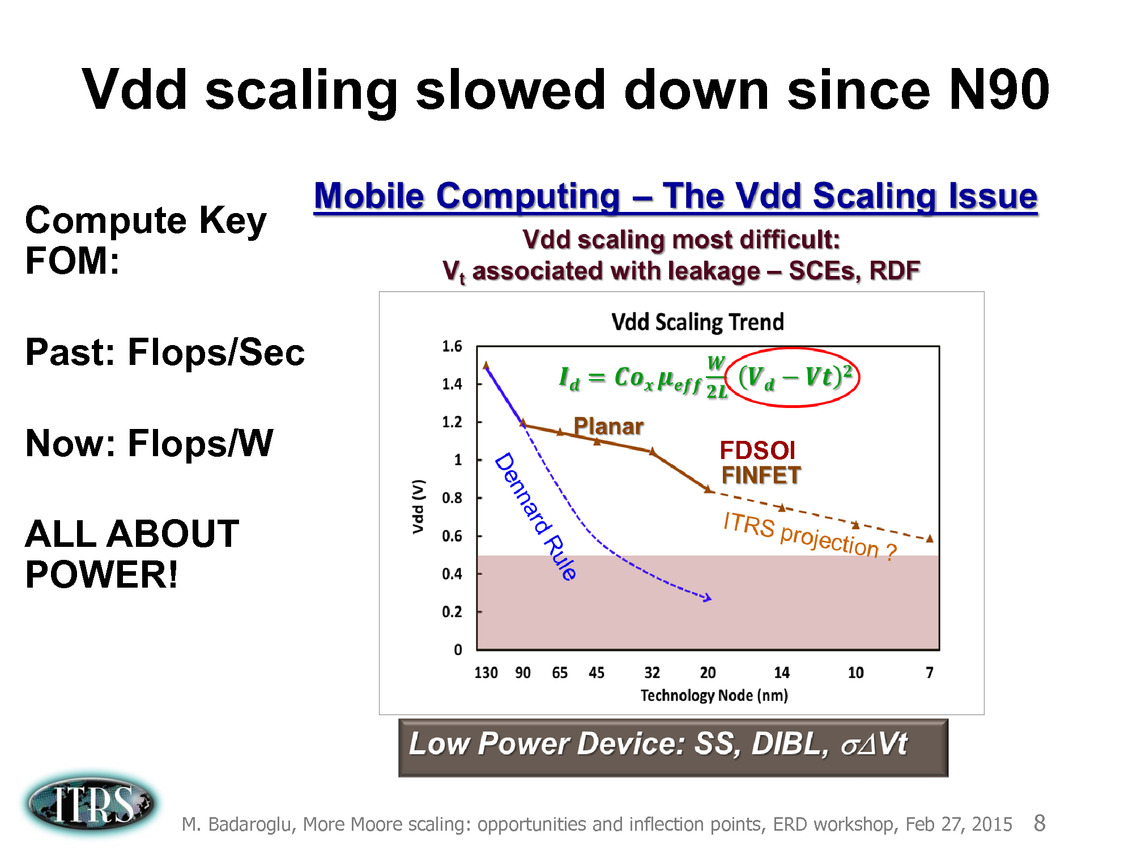
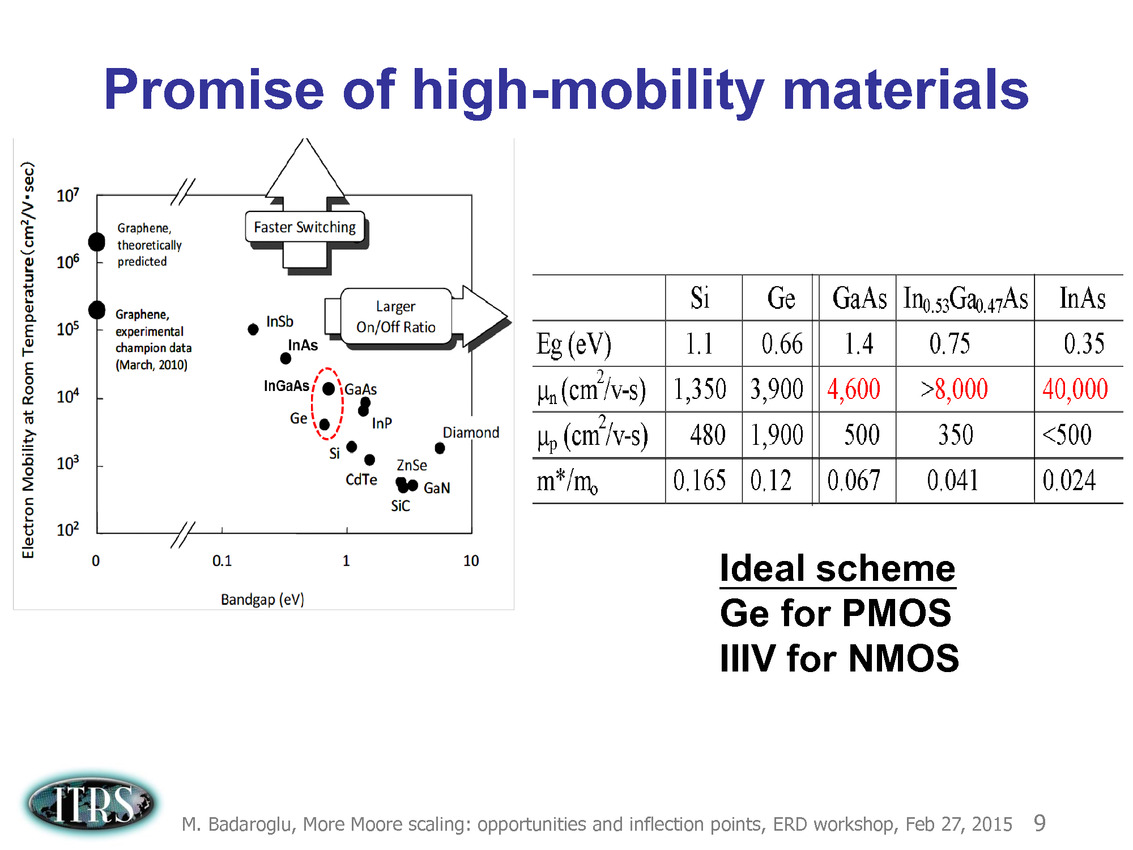
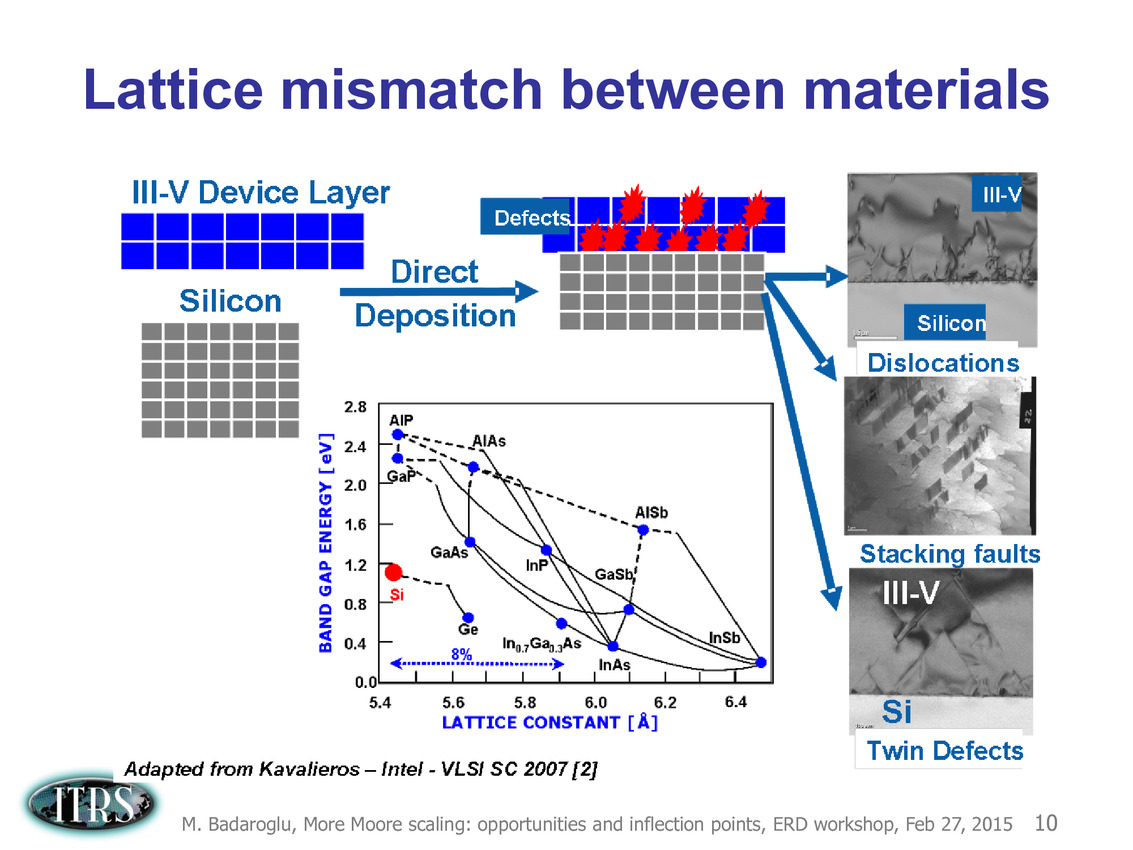
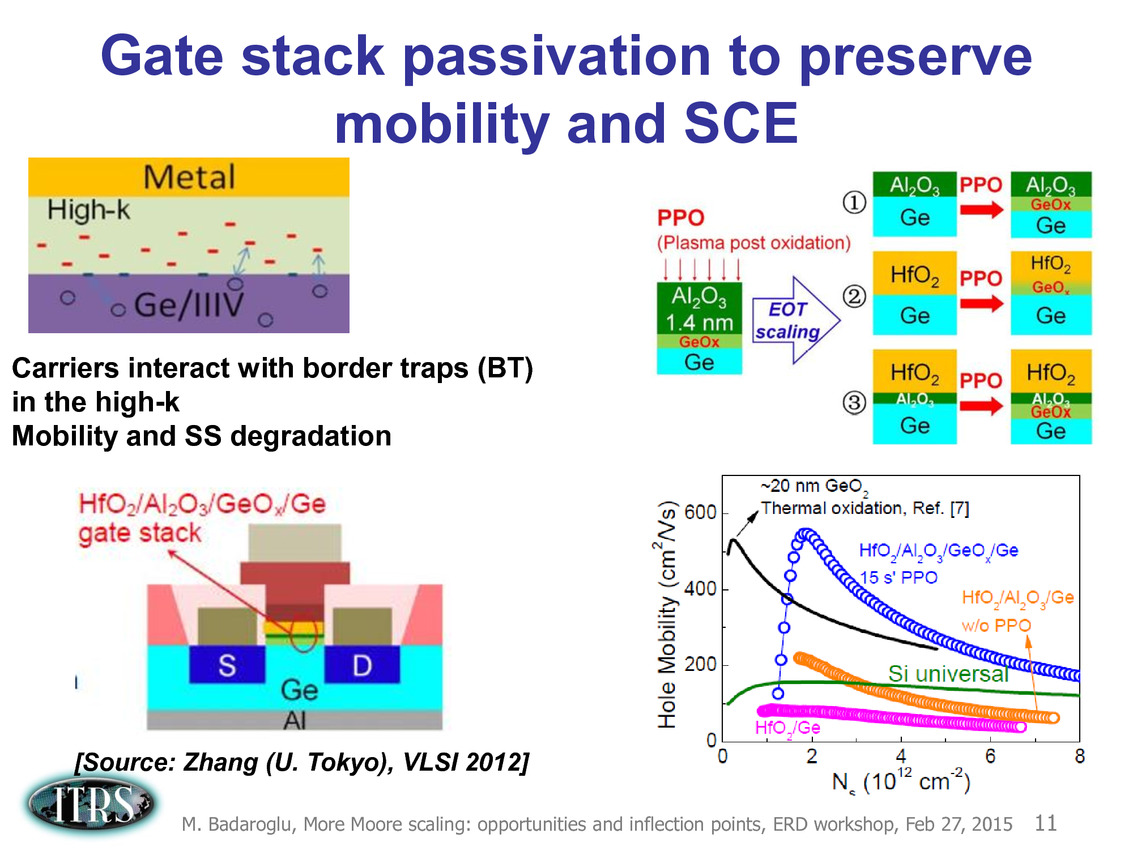
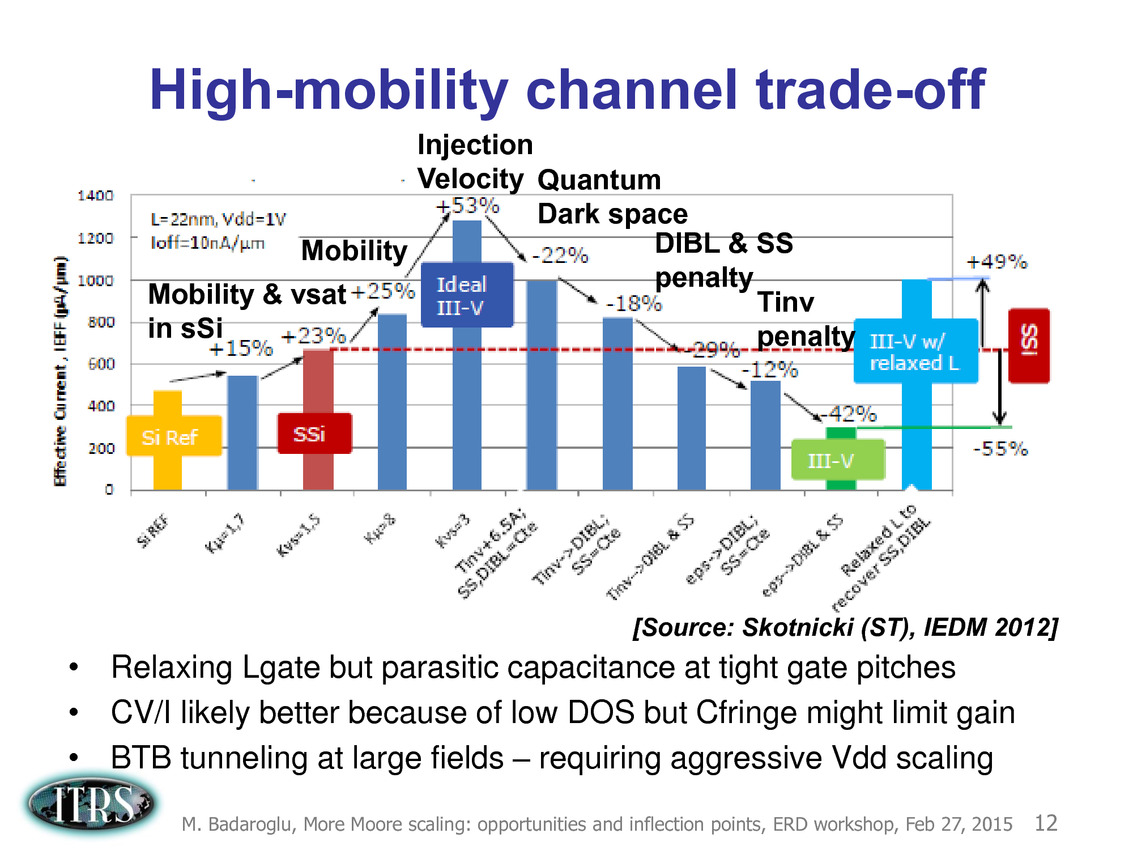
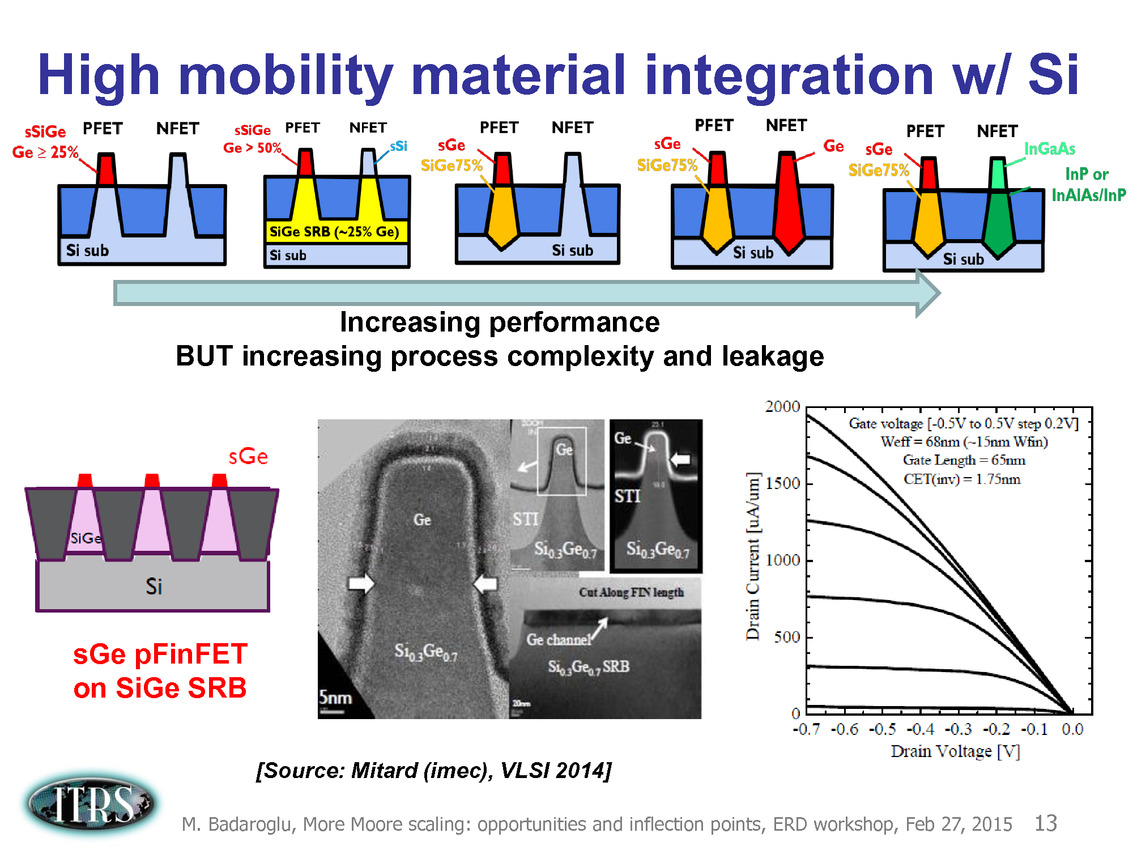

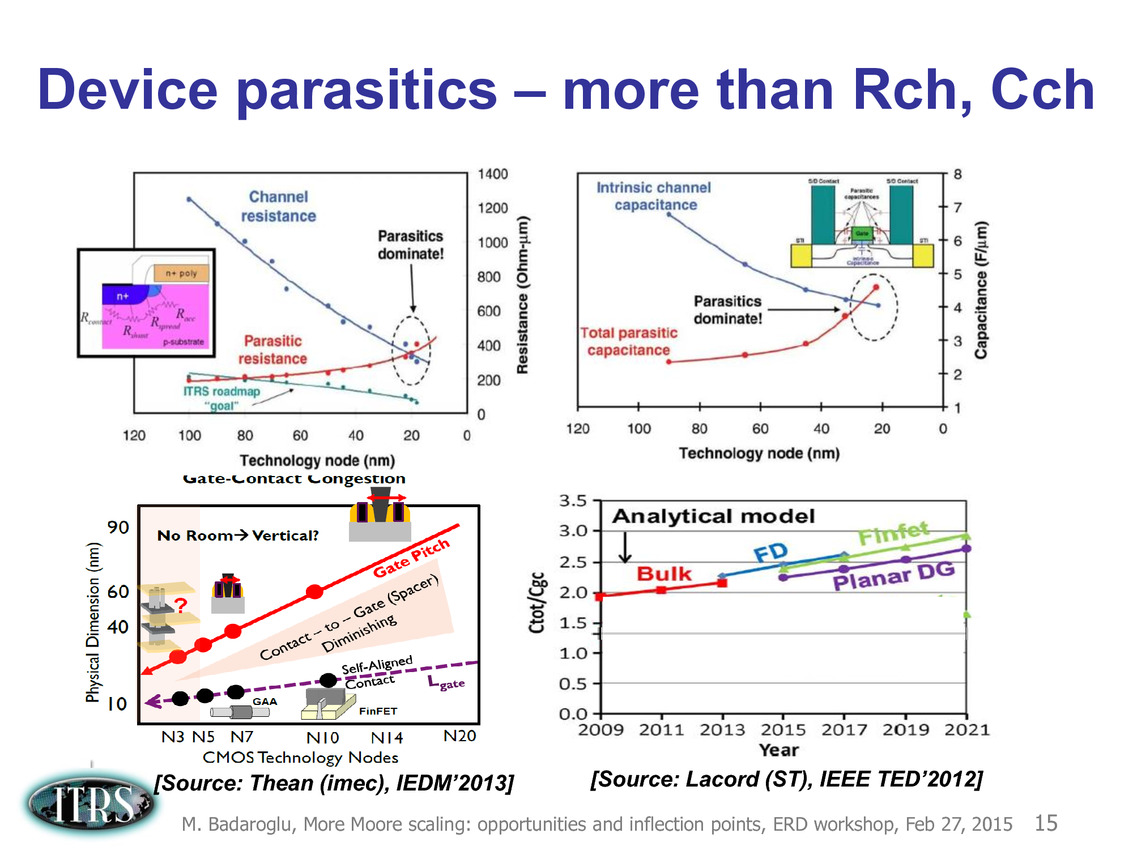
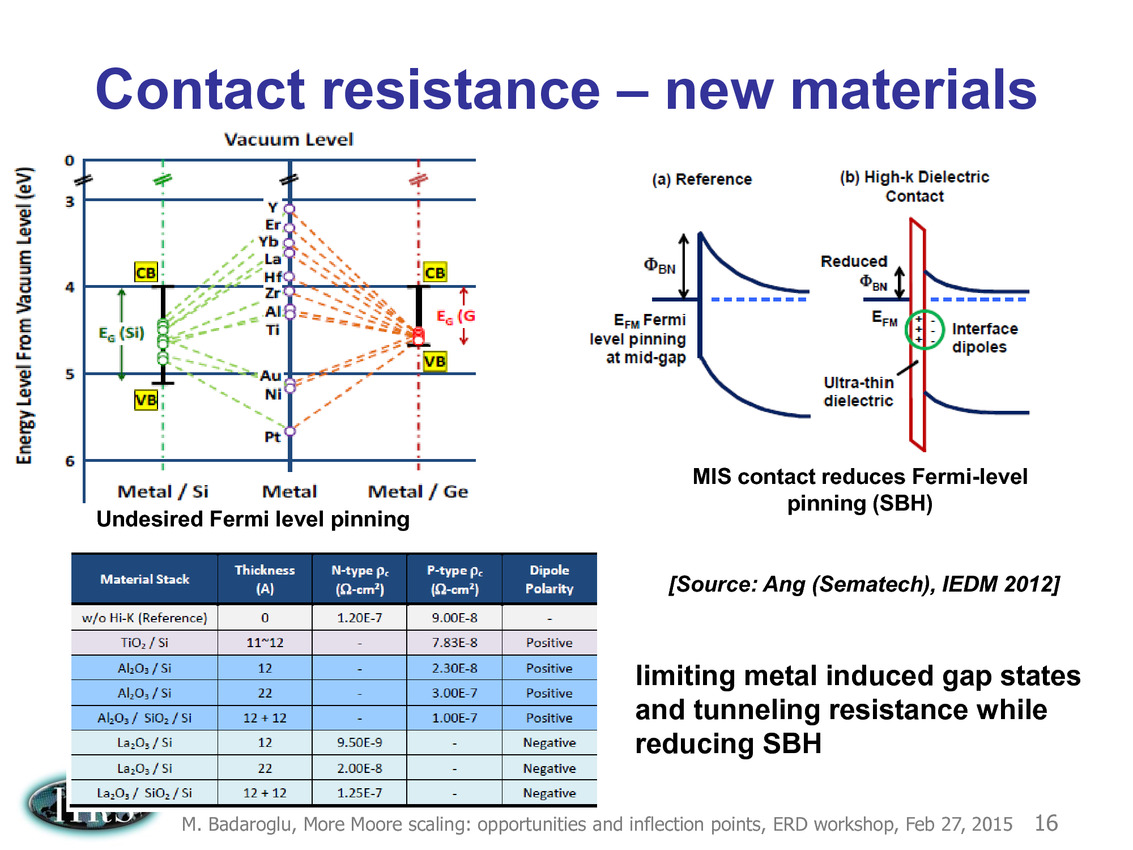
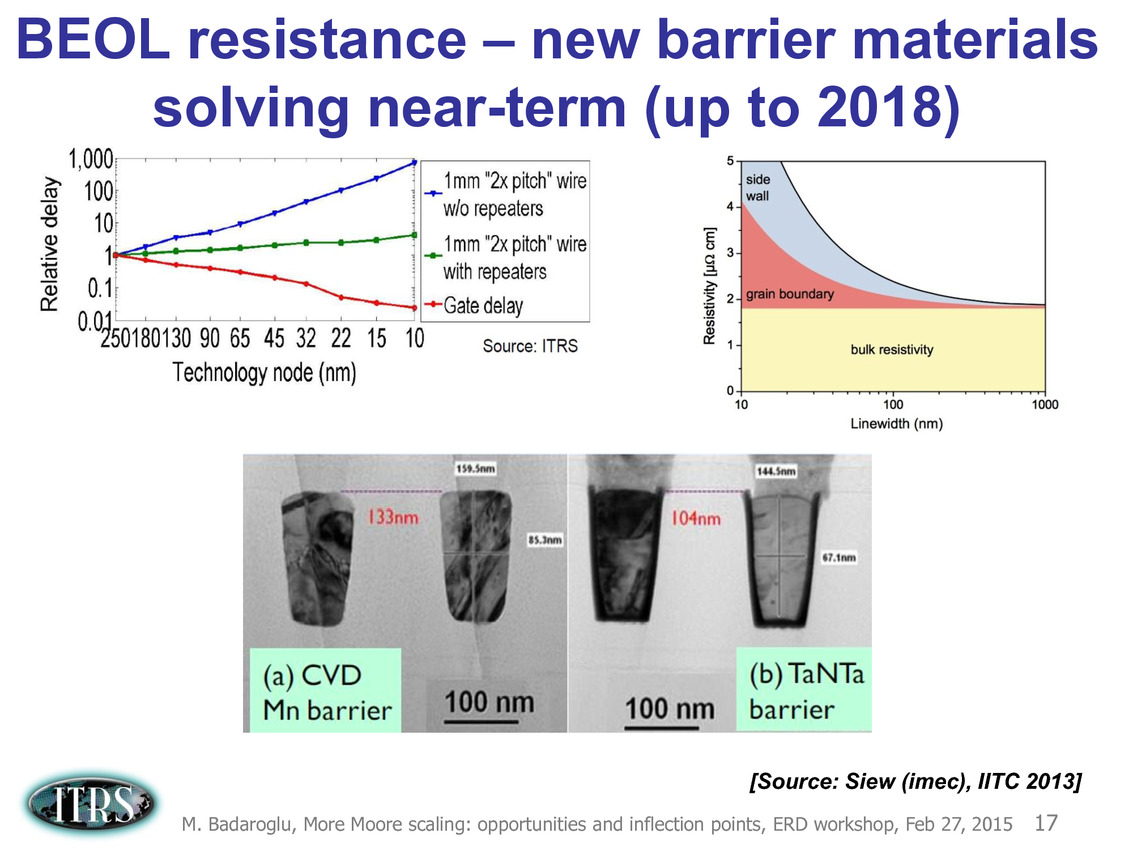
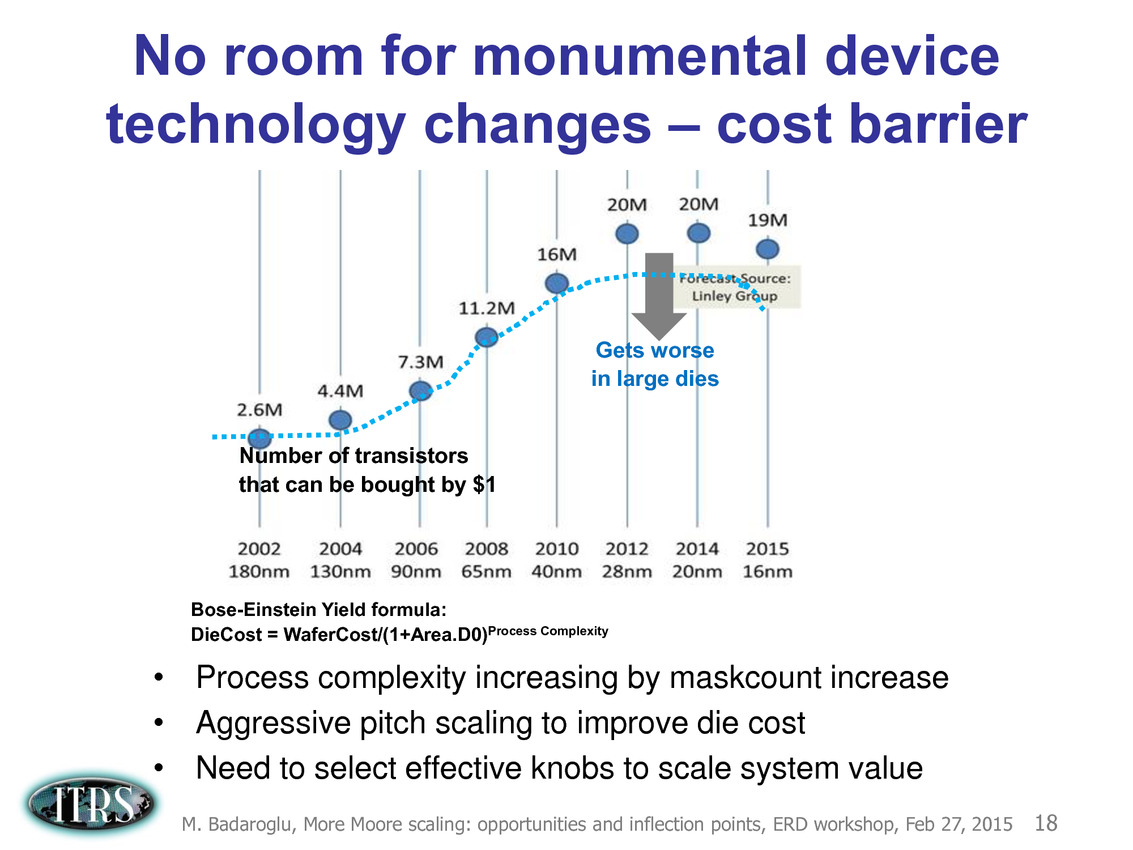
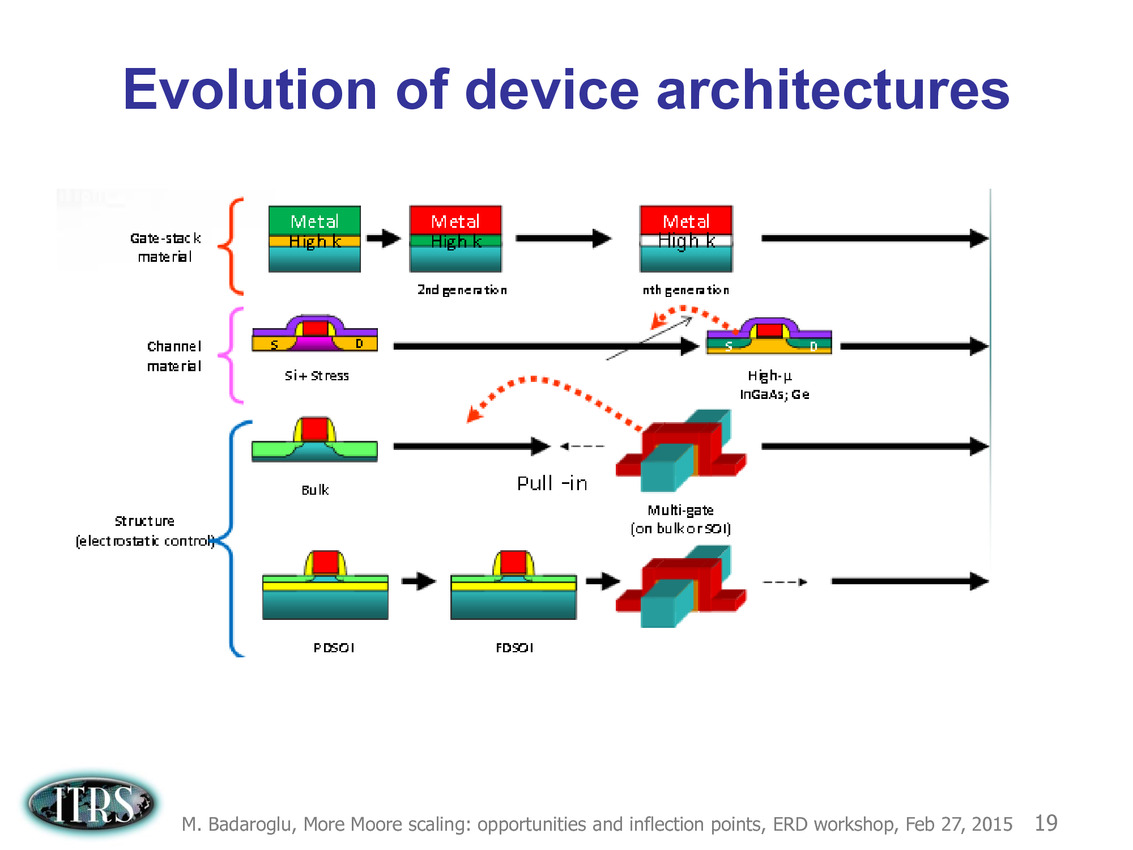
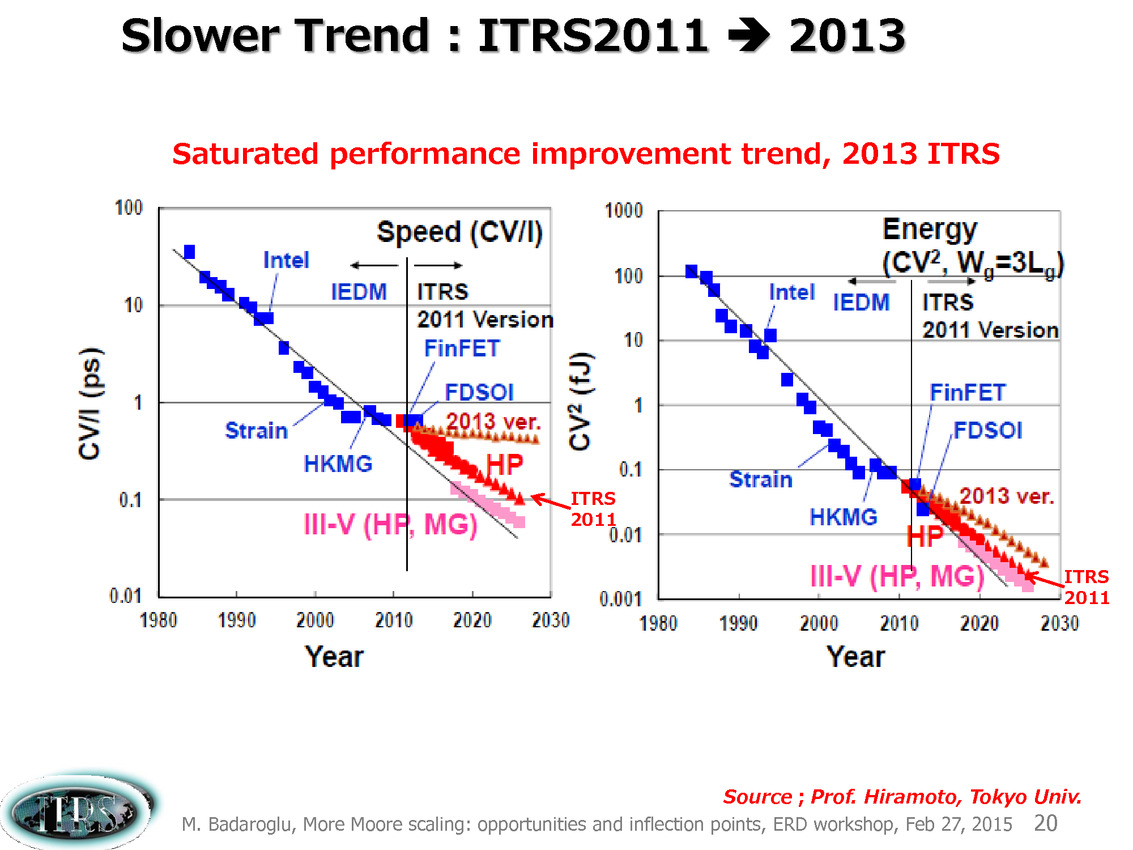
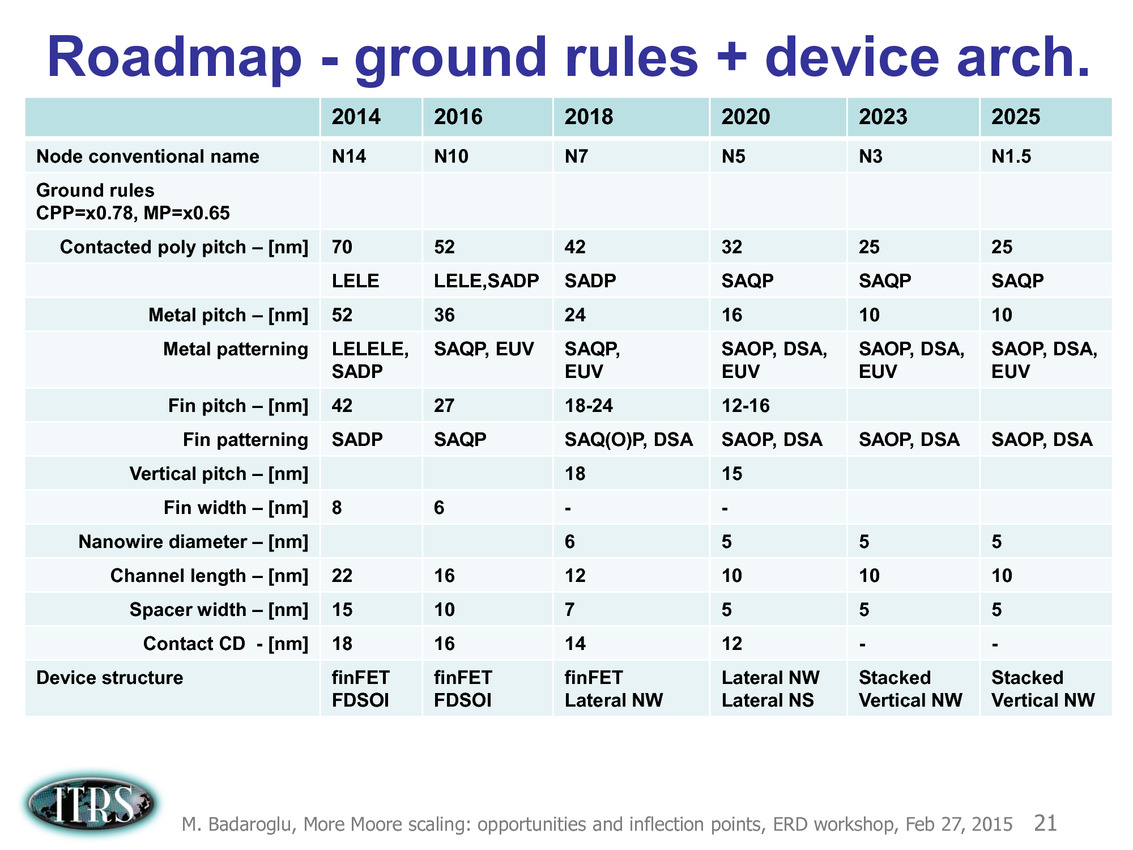
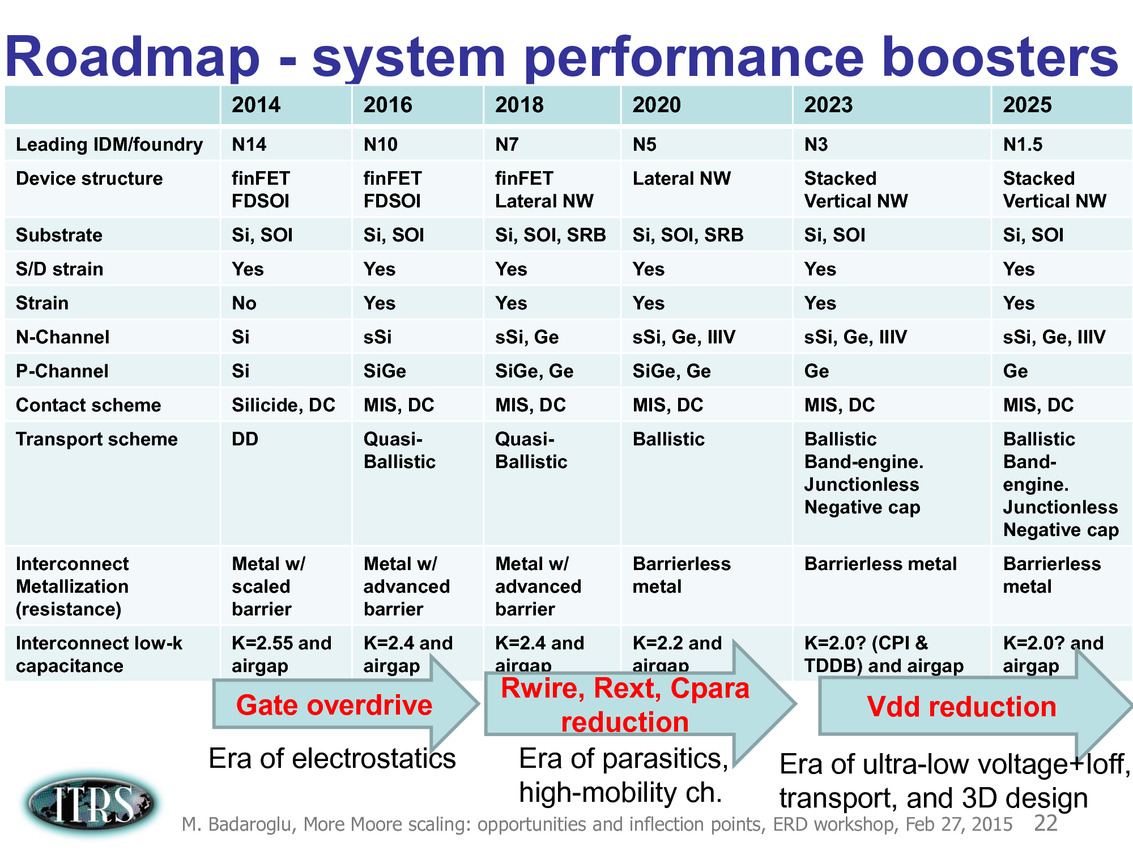
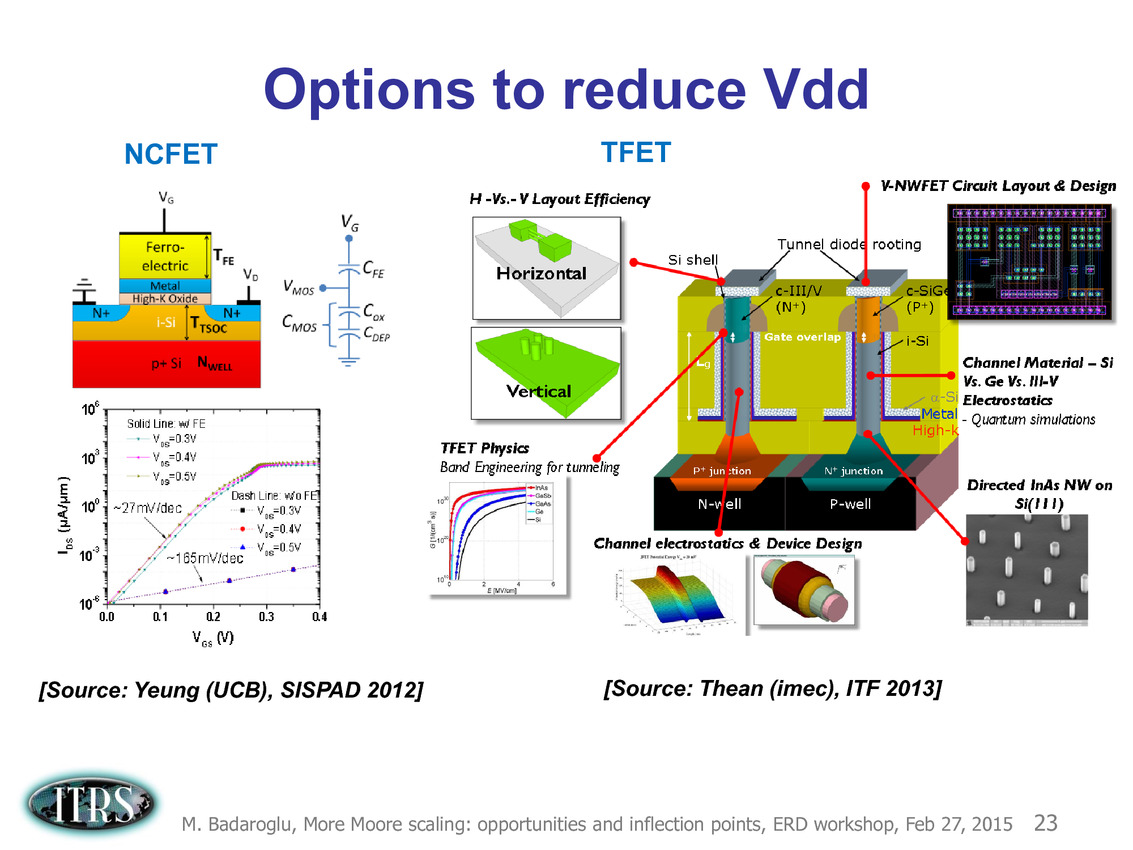
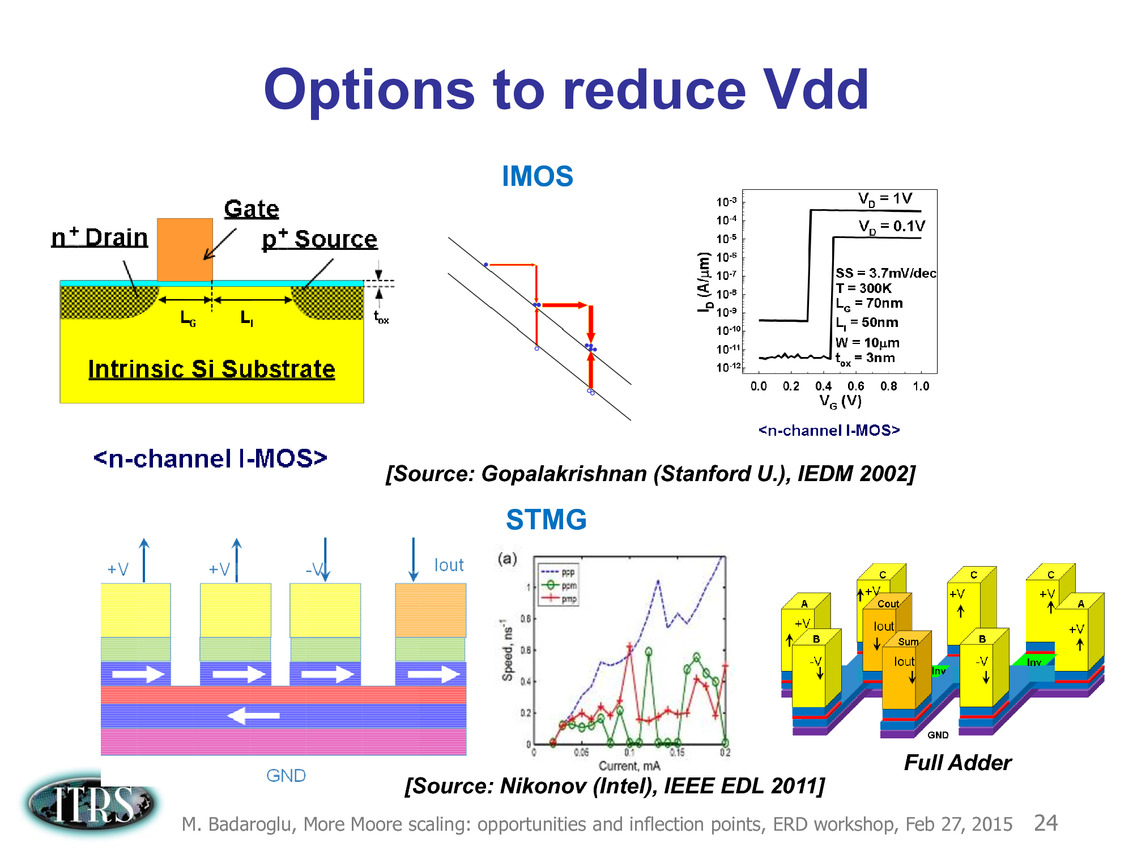
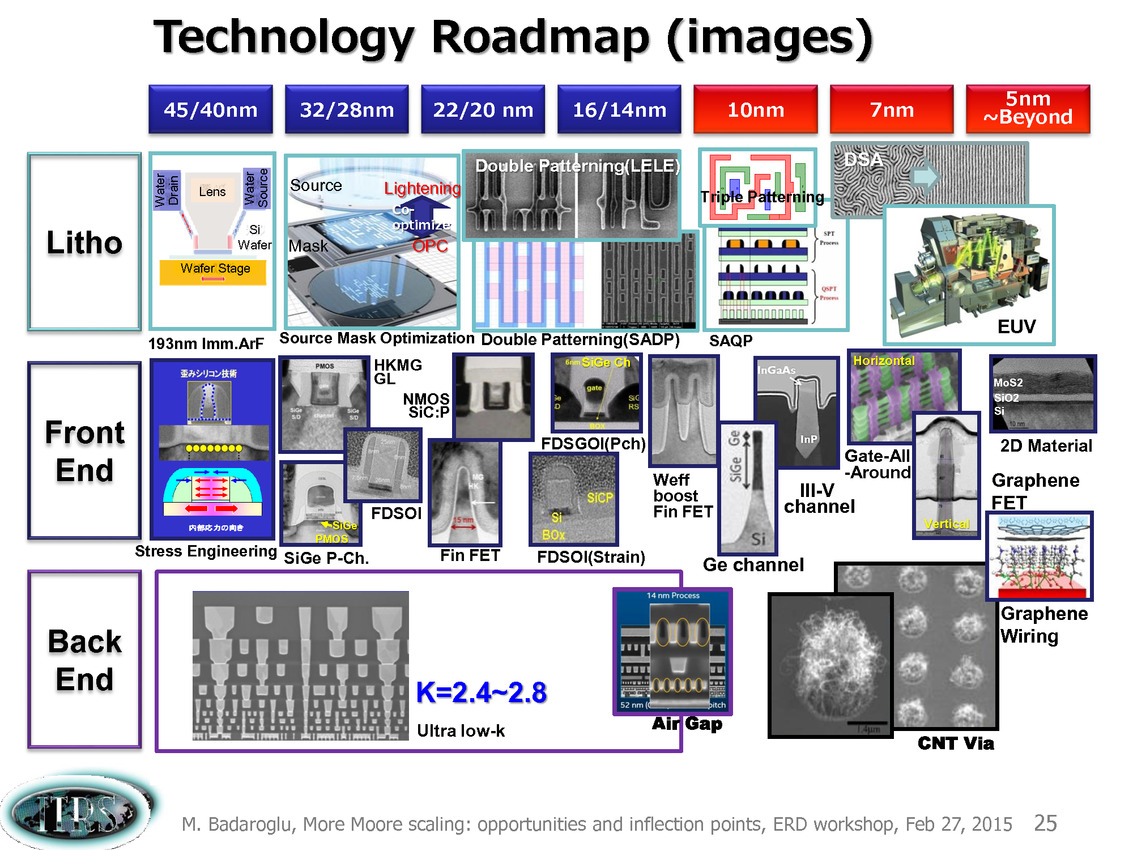

Une présentation intéressante qui évoque de multiples pistes et où l'on trouve un début de roadmap que nous avons remis ci-dessous :
En pratique, après l'ère de la mise à l'échelle géométrique, et l'ère des équivalences, l'ITRS évoque l'ère du "3D Power Scaling" dont les meilleurs représentants sont la NAND 3D ou des technologies comme la mémoire HBM. Des techniques complexes à appliquer aux puces logiques même si la présentation évoque quelques pistes et alternatives.
On attendra donc le mois prochain pour en savoir un peu plus !
3 architectures 10nm pour Intel ?
Alors qu'Intel a indiqué lors de ses résultats trimestriels avoir pour objectif de revenir au rythme habituel de 2 ans entre deux process de fabrication, il ne semble que ce retour à la normale ne soit pas prévu pour le passage à 7nm.

A l'instar de ce qui se passe sur le 14nm qui va voir passer successivement Broadwell, Skylake et Kaby Lake, ce sont ainsi trois architectures qui seraient prévues en 10nm selon Fool.com : Cannonlake pour le second trimestre 2017, Icelake un an plus tard et finalement Tigerlake au second semestre 2019. L'arrivée des produits en 7nm ne se ferait ainsi pas avant 2020, soit par rapport au planning annoncé en 2010 1 an de retard pour le 14nm, 2 ans pour le 10nm et 3 ans pour le 7nm.
Si Intel aime annoncer une densité supérieure de son 14nm par rapport aux process 14/16nm concurrents, ce que contredisent bien entendu ces derniers, l'arrivée de produits 7nm en 2020 mettrait tout le monde d'accord puisque côté TSMC on devrait voir des puces 7nm sortir des chaines de fabrication avant la fin 2018.
Un tel décalage peut paraître étonnant puisque c'est ASML qui équipe principalement toutes les fonderies, il est très probable qu'il découle en fait de choix différent entre d'un côté attendre l'EUV, ce que fera peut-être Intel pour le 7nm, ou faire appel à de plus en plus de multiple patterning et de parties de process communes avec le node précédent afin de repousser l'EUV au 5nm, ce qui est l'option prise par TSMC. L'avenir nous dira quels choix vont être faits et lequel sera le bon !
ASML confirme les retards sur l'EUV
Après Intel, c'est ASML qui dévoile à son tour ses résultats sur le troisième trimestre. L'occasion pour les dirigeants de la société de revenir sur la question de la lithographie EUV, technologie importante pour la fabrication des semi-conducteurs dans les prochaines années, et sur laquelle ASML a massivement misé.
En début d'année l'optimisme était de mise, évoquant un déploiement de l'EUV en cours de vie du node 10nm, et un déploiement complet à 7nm. ASML s'était même félicité d'avoir vendu 15 machines à Intel. Cependant en juillet TSMC avait refroidit les espoirs, indiquant que l'EUV était exclu à 10nm, et n'arriverait peut être qu'en cours de process 7nm.
Nous notions hier qu'Intel avait repoussé la livraison de certaines machines-outils de deux trimestres et il était facile de lire entre les lignes que l'EUV était en cause. Dans leur présentation aux analystes, ASML a indiqué qu'effectivement la livraison de plusieurs machines avait été repoussée, et que seulement 4 machines EUV seraient livrées en 2016 contre sept annoncées. Le choix de repousser l'insertion a 7 et 5nm fait que les commandes ont été repoussées, modifiées vers de nouvelles machines. Derrière la raison des reports, ASML évoque « l'incertitude de ses clients » sur le timing de leurs nodes à venir, ainsi que sur « leurs priorités à court terme ». On y verrait presque un petit tacle envers Intel dont la priorité principale est effectivement les yields en 14nm qui ont été confirmés comme en dessous des attentes hier par le constructeur.
ASML indique que cinq clients sont concernés par les livraisons de machines EUV dans les années à venir pour un total de 11 machines sur les générations 10 et 7nm. Un chiffre plus bas que le nombre de machines supposément vendues à Intel, il s'agissait cependant d'un contrat à long terme basé sur un certain nombre de critères de performances. Une partie de la commande d'Intel sera donc vraisemblablement repoussée sur le 5nm. Au milieu des questions/réponses, le CEO Peter Wennink a confirmé qu'ASML avait misé sur le fait que le 10nm serait un node EUV, ce qui ne sera pas le cas et décale de 6 à 12 mois les demandes de ses clients. Etant donné que l'écart entre deux nodes est plus proche de 24 mois en moyenne, on doutera un peu de cette assertion. En pratique Peter Wennink à confirmé que le déploiement de l'EUV se ferait à partir de 2018/2019 avec des livraisons pour les machines de production courant 2017.
En ce qui concerne les avancées sur les points bloquants derrière l'introduction de l'EUV, ASML est resté relativement muet. La question principale reste la vitesse d'exposition, qui était de 1000 wafers sur une période de 24h (il faut de nombreuses expositions pour réaliser une puce, dont la fabrication prend plusieurs semaines, la vitesse d'exposition est donc un point critique !), un peu en dessous du seuil minimal acceptable (50 à 100 exposition par heure, les machines « classiques » en font 250/h à titre de comparaison). Si ces chiffres semblent proche, l'autre problème est le taux de disponibilité des machines, nous notions la dernière fois que le générateur de goutes d'étain devait être changé tous les quatre jours et que sur une période de 8 semaines, le taux de disponibilité mesuré n'était que de 55%.
Côté rendement, les choses n'ont visiblement pas évolué puisque le même chiffre de 1000 sur une journée a été de nouveau évoqué. ASML indique cependant que sur des périodes de quatre semaines, plusieurs de ses clients ont atteint une disponibilité de plus de 70%. Si l'on pourrait y voir un progrès, le CEO d'ASML a noté qu'il s'agissait de meilleures situations et que la moyenne totale reste plus basse. Peter Wennink a également évoqué que les dernières générations de laser ont posé problème même si ces problèmes seraient résolus.
Le CEO s'est également félicité du fait que deux clients avaient indiqué la « nécessité » de l'EUV à 7nm, même si l'on notera que toutes les annonces que ce soit chez TSMC ou Intel étaient empruntes de prudence, quelque chose de compréhensible vu que des annonces identiques avaient été faites pour le 10nm ! On notera sur la question du 10nm qu'ASML a confirmé que Samsung, TSMC et Intel seront « proches » avec des livraisons à partir du second trimestre. Il a cependant été confirmé que le passage au 10nm serait « complexe » de par le fait que le multiple patterning était généralisé pour de nombreuses couches critiques et qu'il ne faudrait pas sous-estimer le temps nécessaire avant de voir en production ces puces sur le marché.
ASML vend 15 machines EUV à Intel
La société ASML s'est fendu hier d'un communiqué de presse pour indiquer avoir signé un accord important pour la vente de machines de lithographie EUV. Nous étions revenus sur le sujet à la fin du mois dernier, après de long et multiples retards, cette technologie de lithographie nouvelle génération avait effectué quelques progrès substantiels, notamment chez TSMC, qui avait commandé deux machines NXE:3350B livrables cette année, des machines dédiées au 10nm.
Le communiqué d'ASML indique que la firme néerlandaise a trouvé un accord avec un de ses « gros client américain » pour livrer, dans un délai non précisé, 15 machines EUV. Deux de ces machines au moins seront de type NXE:3350B (10nm) et seront livrées cette année.
Il ne faut pas trop d'imagination pour deviner que le client en question est Intel. La société avait investi de manière importante dans ASML en 2012 même si elle restait prudente sur l'utilisation à venir de la technologie. Cet accord semble montrer un regain d'intérêt autour de l'EUV, même si à l'image de TSMC on s'attend probablement à un déploiement initial autour du 7nm.
La cadence de production des machines sera en effet étalée dans le temps. Six (à huit) machines NXE:3350 devraient être vendues cette année (deux à Intel, deux à TSMC et possiblement deux à Samsung qui était le troisième à avoir investi dans ASML en 2012). La production devrait s'intensifier progressivement puisque ASML table sur la production de douze machines en 2016, vingt-quatre en 2017 et 48 en 2018.
On notera enfin que si l'intérêt autour de l'EUV se porte aujourd'hui pour la fabrication de circuits logiques (processeurs), ASML compte également déployer l'EUV auprès des fabricants de mémoire DRAM dans un second temps. La production de mémoire flash NAND en EUV pourrait suivre avec un décalage de deux à trois ans selon le CEO d'ASML.
Intel précise son process 14nm
En marge de son annonce sur Broadwell-Y, Intel a partagé quelques détails sur son process 14nm. Comme vous le savez, le process 14nm d'Intel souffre de retards. Le constructeur avait annoncé qu'il décalerait la mise en production d'un trimestre en novembre dernier, tout en publiant des indications autour de ses yields qui laissaient entendre un retard de 6 mois.
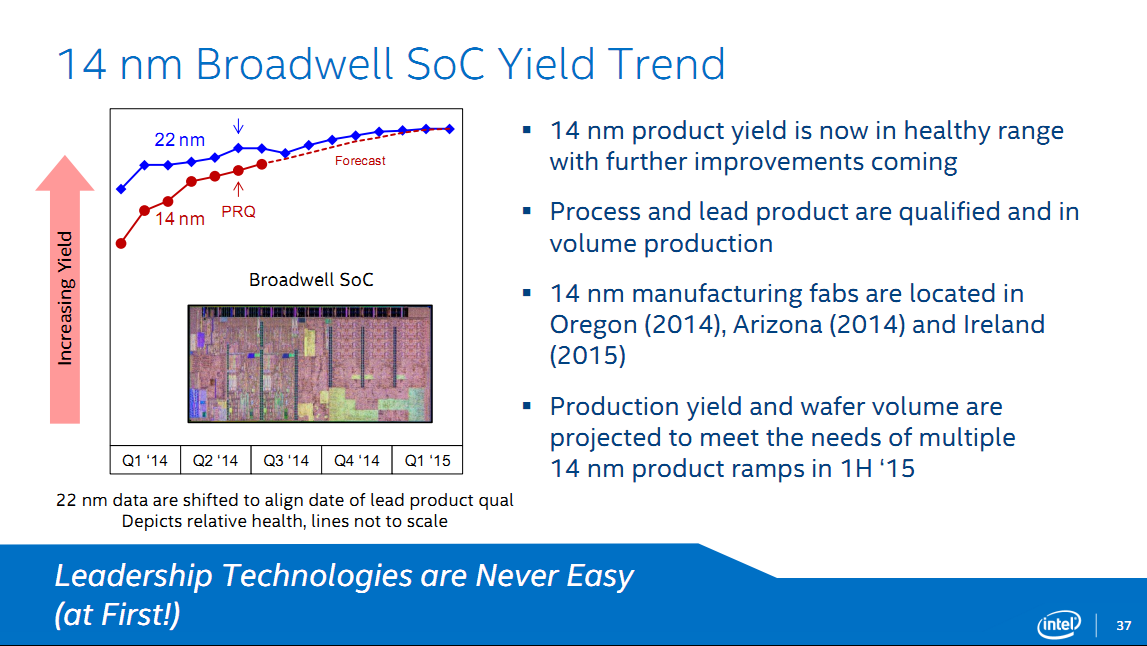
En pratique, il est difficile de mesurer réellement le retard du process même si Intel a partagé ce nouveau graphique de yields :
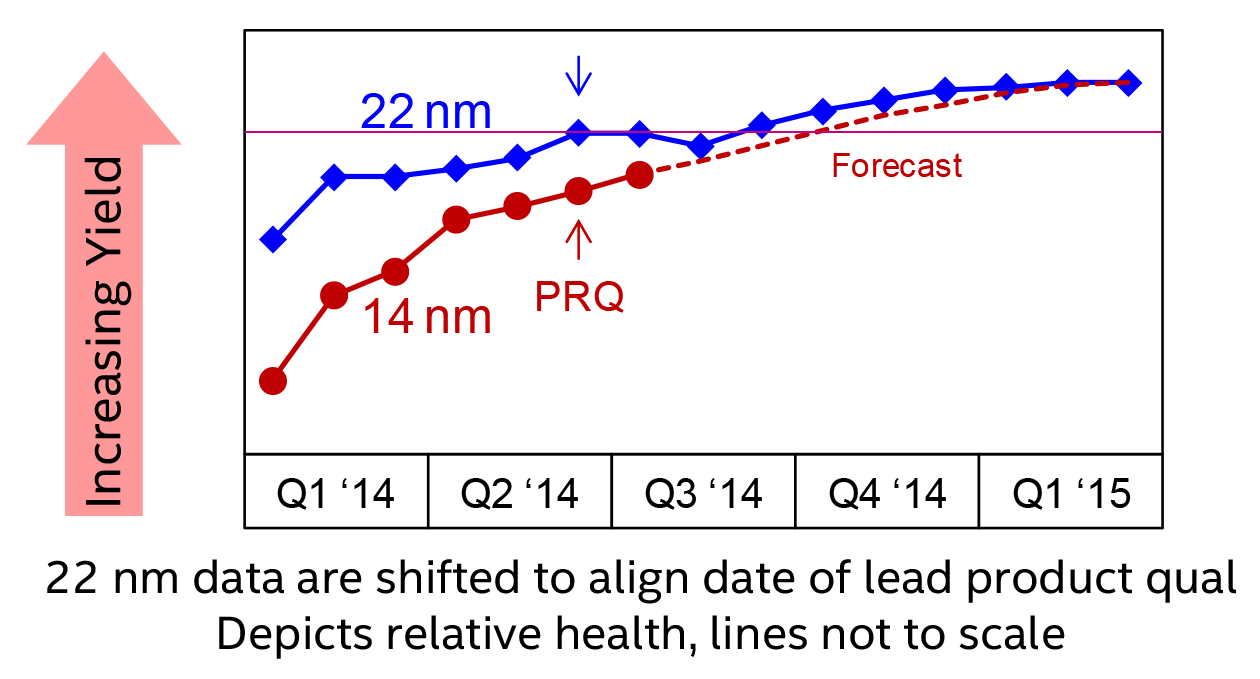
Plusieurs choses à voir sur ce graph, d'abord, si vous vous souvenez du dernier graphique de yields présenté par Intel, celui-ci diffère fortement. Là où le premier était aligné par rapport au début du développement du process, les graphiques sont désormais alignés sur la qualification du premier produit (Ivy Bridge en 22nm, Broadwell-Y en 14nm), étape préalable à la mise en production. Intel indique sur ce graphique que la qualification de Broadwell-Y a eu lieu en fin de second trimestre et qu'il est actuellement en production en volume. Si l'on ne connait pas la date précise de qualification d'Ivy Bridge, on sait que la production en volume avait débuté au troisième trimestre 2011, ce qui met donc au minimum deux ans et neuf mois entre la mise en production en volume du 22nm et celle du 14nm.
L'autre point le plus important concerne (on passera sur l'échelle absente une fois de plus) l'écart de yields entre la mise en production d'Ivy Bridge et celle de Broadwell-Y. Le constructeur a choisi, comme nous le supposions en novembre dernier, de lancer la production avec des niveaux de yields inférieurs. En pratique, le décalage de yields pour la mise en production, si l'on prend en compte la prédiction pour les prochains mois est de quatre mois (voir la ligne violette que nous avons rajouté au graphique). Ce qui ne signifie pas quatre mois de retard pour ce process rappelez-vous que les graphiques ne sont plus alignés ! mais qu'Intel a anticipé la mise en production de quatre mois par rapport à celle d'Ivy Bridge. Il est probable que, plus que le niveau de yields, ce soit une date butoir qui ait été utilisée pour déterminer la mise en production afin de s'assurer qu'un produit soit « livré » cette année.
En soit, ce choix est logique : le constructeur peut ainsi proposer un peu plus tôt des produits quitte à sacrifier sur ses marges, tout en honorant - on l'imagine - des contrats auprès de ses partenaires et en pouvant montrer aux investisseurs qu'un produit en 14nm a bel et bien été lancé en 2014. En pratique, si Intel pourra effectivement « lancer » un premier produit cette année, le gros du volume en 14nm devra attendre. Le constructeur ne le cache pas en indiquant que ses yields devraient être acceptables au premier semestre 2015 pour la production en volume de produits vendus en plus larges quantités que les Broadwell-Y.
Intel est également revenu sur la compétition en proposant une nouvelle version de son graphique à propos de la densité qui avait largement fait débat :

Cette fois ci, le constructeur mélange IBM et TSMC parmi ses concurrents, et met de côté Samsung (pour rappel, Samsung et GlobalFoundries ont annoncé un partenariat sur le 14nm autour du process 14nm développé par Samsung, hors de la Common Platform l'alliance qui liait Samsung et GlobalFoundries à IBM). Le constructeur a le mérite d'indiquer la formule qu'il utilise pour mesurer la densité ce qui n'était pas le cas auparavant.
La densité des puces est un sujet pour le moins complexe et si la formule annoncée par Intel (gate pitch l'écart entre deux transistors multiplié par metal pitch l'écart de la couche métallique la plus basse qui sert à l'interconnexion des transistors) est correcte, elle ne prend en compte qu'en partie la question de la densité.
Intel a par exemple toujours été en retard sur ses concurrents sur la question du metal pitch. Le 22nm d'Intel disposait d'un metal pitch de 90nm tout comme le 28nm de TSMC. En pratique, pour le 14/16nm, voici les chiffres qui sont annoncés :
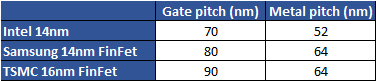
C'est sur cette formule (90x64 comparé à 70x52) qu'Intel annonçait un gain de 35% par rapport à TSMC. Bien sur, la densité finale d'une puce ne dépend pas que de cette formule, les règles de design, la taille des SRAM, et d'autres facteurs jouent de manière importante sur la densité « réelle » de transistors obtenus au mm2 sur une puce, la formule metal pitch x gate pitch n'indiquant que le cas « idéal ». C'est sur ces autres facteurs que TSMC estime gagner 15% de densité « réelle » au total entre son process 20 et 16nm. Si l'on ne peut pas reprocher à Intel de choisir la formule qui l'arrange le plus pour mettre ses produits en avant, on peut apprécier que cette fois ci, la formule choisie soit au moins précisée !
On notera par contre qu'Intel continue d'ignorer Samsung qui devrait pourtant être son plus sérieux concurrent sur le 14nm. Samsung pour rappel avait annoncé une production en volume de son process 14nm pour la fin de l'année 2014.
Sur le papier et comme indiqué plus tôt, le process d'Intel semble être supérieur aux autres process 16/14nm de première génération annoncés (on se souviendra que et TSMC, et Samsung ont annoncés une seconde version de leurs process), en partie par le choix fait d'obtenir une réduction forte sur la taille des interconnections atteignant un metal pitch de 52nm qui sera en avance pour la première fois depuis plusieurs process sur ce que proposeront ses concurrents.
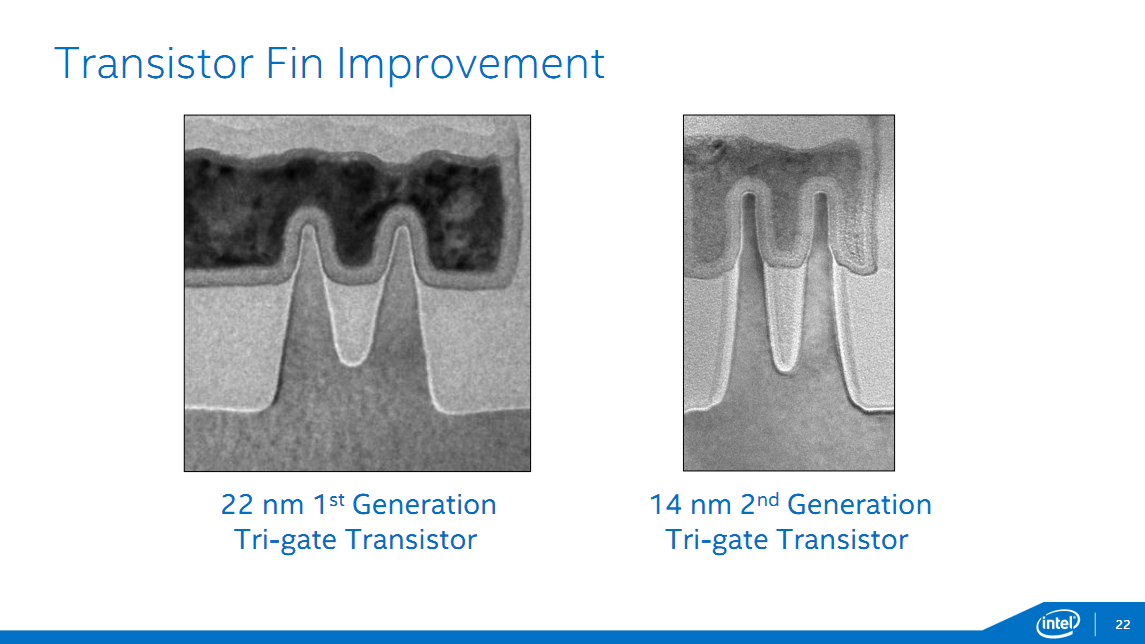
Il s'agira également de la seconde génération de FinFet pour Intel. Outre l'apprentissage effectué par le premier, on peut noter sur les photos fournies par le constructeur quelques changements dans la forme des Fin. Là ou en 22nm les gates avaient une forme trapézoidale, les fins ont désormais une forme rectangulaire plus proche de la forme idéale attendue. On se souviendra qu'IBM et la Common Platform avaient soulevés les questions de forme et de variabilité du process d'Intel :
Il sera intéressant de voir si Samsung (et TSMC) aura comme le laissait entendre IBM à l'époque appris de la première version du process d'Intel.
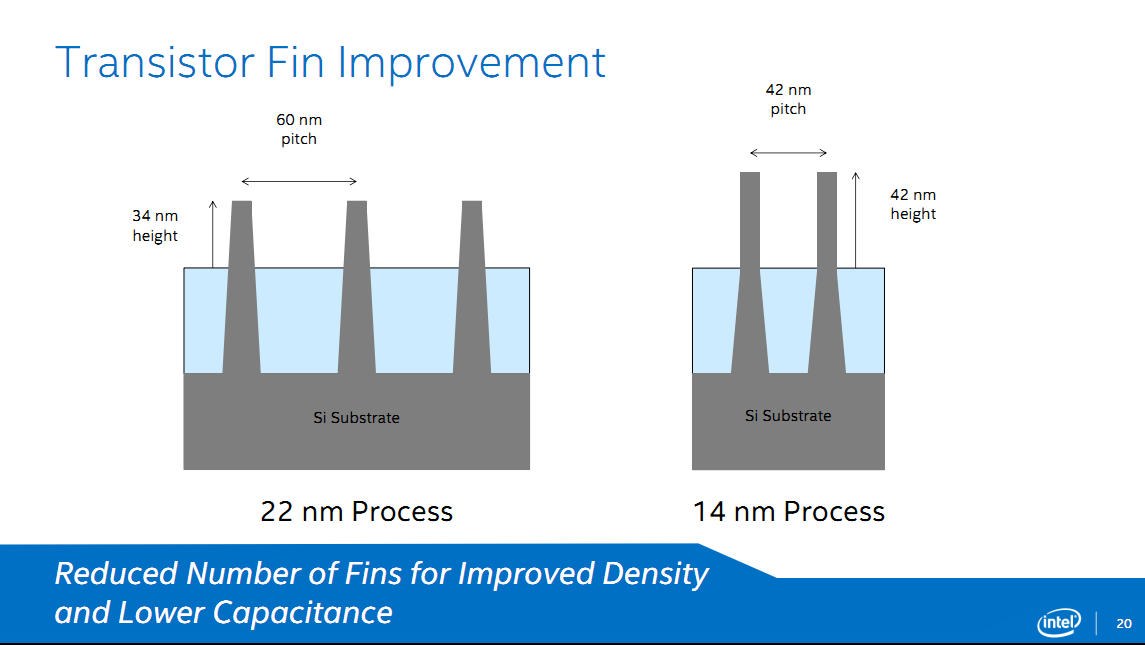
On notera également une augmentation de la hauteur des fins (de 34nm à 42nm) qui devrait permettre une amélioration des performances, quelque chose qui devrait être très utile notamment sur les usages SoC pour limiter la consommation. Si Intel ne donne pas de chiffre de performances concernant les transistors, le constructeur donne quelques chiffres concernant Broadwell-Y. Sur cette puce, et par rapport à son équivalent Haswell, les courants de fuites seraient réduits par deux, avec un rapport performance par watt de 2x.
Pour résumer, Intel semble avoir fortement optimisé son process pour les usages mobiles qui sont aujourd'hui les marchés les plus porteurs (qu'il s'agisse des PC portables ou des tablettes/smartphones) et il sera intéressant de voir comment les gains (forts) annoncés sur Broadwell-Y se traduiront sur le reste des produits 14nm du constructeur. Si le retard d'Intel dans la mise au point de son process est conséquent, et que le lancement de Broadwell-Y se fait dans des conditions non optimales (yields plus faibles qu'attendus, et produits à fort volumes repoussés en 2015), le constructeur semble disposer sur le papier d'un process solide et ambitieux, qui semble corriger les problèmes de sa première génération FinFet. Reste que les délais dans sa mise au point ont permis à la concurrence de se rapprocher - au moins dans les annonces avec un Samsung qui devrait être particulièrement agressif. L'avantage technique apporté par ses process de fabrication reste toujours réel et important pour Intel, et sur le papier son 14nm devrait permettre à Broadwell-Y des avancées notables. Mais la domination d'Intel sur le sujet des process ne semble plus - si l'on s'en tient aux annonces respectives des uns des autres - aussi hégémonique qu'elle le fut ces dernières années.