
Les contenus liés au tag TSMC
Afficher sous forme de : Titre | FluxASML confirme les retards sur l'EUV
L'A9 d'Apple produit par Samsung et TSMC
Pascal sera produit en 16nm chez TSMC
16nm à l'heure, EUV en retard pour TSMC
Prévisions AMD en baisse
L'ITRS prépare l'après loi de Moore



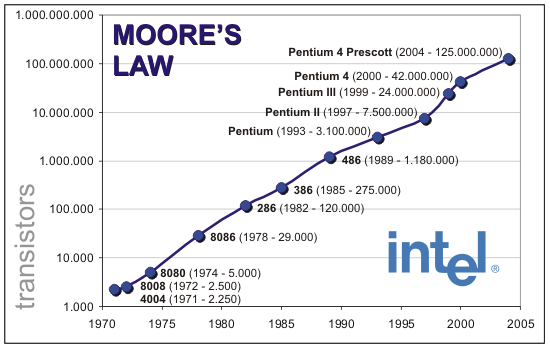
C'est la section actualité de la très sérieuse revue scientifique Nature qui l'affirme : la loi de Moore est arrivée à son terme. Énoncée en 1965 par Gordon Moore, l'un des cofondateurs d'Intel, il s'agit d'une observation par laquelle la quantité de transistors dans les circuits intégrés doublait à peu près tous les ans. Une observation transformée en loi pour prédire que cette cadence pouvait être extrapolée pour les années à venir.
En 1975, la loi avait été révisée pour prendre la forme que l'on connaît actuellement, à savoir un doublement des transistors tous les deux ans. L'importance de la loi de Moore allait cependant au-delà de la simple prédiction puisqu'elle prenait en compte les coûts de fabrication : l'observation se fait sur les puces ayant le coût par transistor le plus faible (tentant donc de prendre en compte les questions de yields et de défauts en fonction de la taille des puces).
Plus qu'une prédiction, la loi de Moore a servie, particulièrement chez Intel, de guide au fil des années, prédisant à l'avance les budgets en nombre de transistors alloués aux ingénieurs, et poussant vers l'avant la nécessité d'investir dans de nouveaux process de fabrications, la fameuse stratégie du Tick-Tock poussée d'abord en interne par Pat Gelsinger au début des années 2000 avant d'être utilisée publiquement pour décrire les générations à venir.
De manière intéressante, au-delà d'Intel, c'est toute l'industrie du semi-conducteur qui s'est mise d'accord autour de la loi de Moore, à savoir non seulement les fondeurs, mais aussi et surtout les fournisseurs d'outils. Le besoin de coordination entre tous les acteurs aura conduit à l'élaboration d'une roadmap, d'abord appelée National Technology Roadmap for Semiconductors dès 1993, avant d'être renommée sous sa forme actuelle, l'International Technology Roadmap for Semiconductors (ITRS).
Le rôle joué par cette roadmap, dont la dernière version a été publiée en 2013 aura été particulièrement important ces dernières années où, passé le 90nm, les challenges techniques ont contraint à des changements d'approches importants. L'augmentation des performances par la fréquence, méthode classique aura atteint un plateau à cause de l'augmentation de la consommation, poussant dans le commerce les stratégies de multiplication des coeurs que l'on connaît. Le rôle de la roadmap, au-delà de la concertation, est de s'assurer de trouver des pistes pour continuer la cadence de réduction des coûts/augmentation des transistors de la loi de Moore.
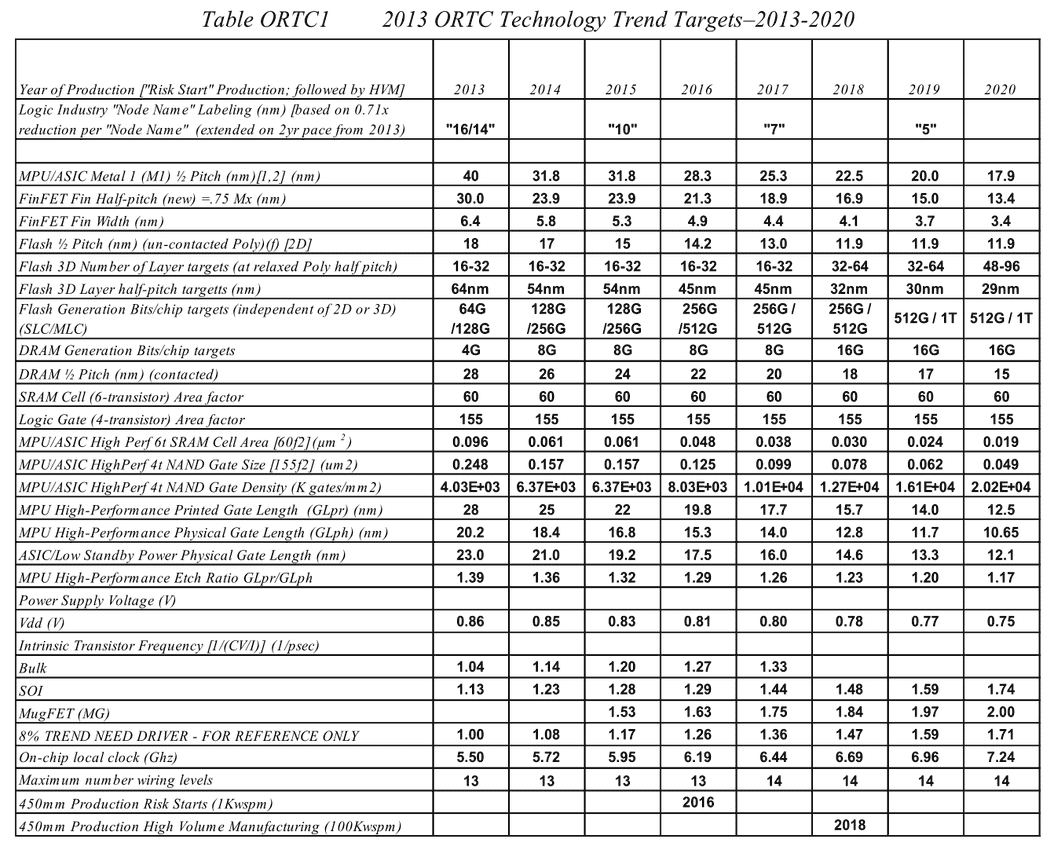
La dernière roadmap ci-dessus donnait des grandes lignes sur la manière de mettre à l'échelle les différents composants des transistors. Après les difficultés autour du 90nm, l'industrie est passé progressivement de la règle dite de la mise à l'échelle géométrique (on réduit tout dans des proportions identiques, le nom du node indiquant en général la taille de la porte) à celle de la mise à échelle par équivalence (equivalent scaling).
Etant donné que différentes parties composant les puces posent des problèmes différents, des règles d'équivalences ont été mises au point pour permettre de continuer a atteindre les buts de réduction des coûts/augmentation de densité imposé par la loi de Moore (on peut voir sur le tableau la couche d'interconnexion M1 et l'écart minimal entre deux transistors FinFET, en passant par des estimations des tailles de blocs fondamentaux comme la SRAM).
Pour 2016, la roadmap annonçait par exemple de la SRAM 6 transistors (6T) haute performance en 10nm autour de 0.048 µm2, ce qui n'est pas très éloigné de ce que présentait Samsung il y a une dizaine de jours de cela. En pratique cependant, on notera qu'on est globalement assez en retard sur la roadmap qui prévoyait des débuts de production à petite échelle en 10nm en 2015 (Risk Start dans la roadmap, suivi de HVM, fabrication en volume). Chez TSMC par exemple, la production risque est prévue pour la fin 2016 avec une production en volume pour 2017. Intel prévoit ses puces en volume pour 2017 également.
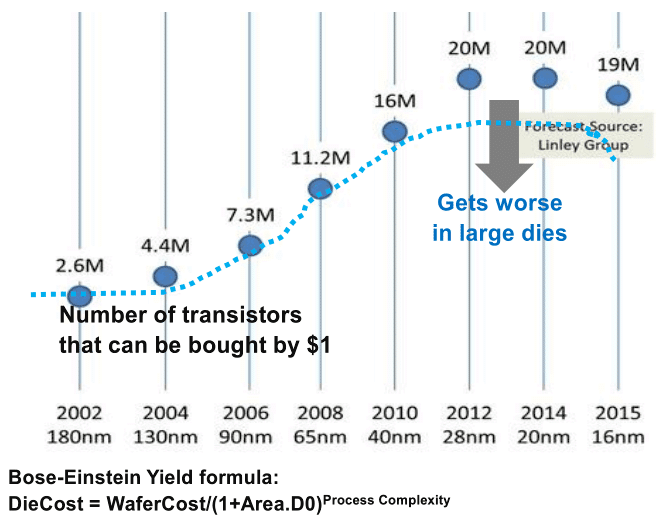
Évidemment depuis 2013 les choses se sont un peu plus compliquées et l'absence de roadmap en provenance de l'ITRS n'a pas forcément aidé. En pratique, la réduction des coûts s'est arrêtée, avec même un retour en arrière à 16nm signant de facto la fin de la loi de Moore, comme on peut le voir sur cette estimation ci-dessus tirée d'une présentation de l'ITRS en février 2015.
L'absence de nouvelle roadmap en provenance de l'ITRS aura même donné lieu à des divergences d'interprétations fortes, Intel titillant ses concurrents sur la question de la densité théorique. TSMC et Samsung ont fait pour rappel le choix de conserver un BEOL (Back End of Line, la partie basse d'une puce qui sert à l'interconnexion des transistors) commun entre le 20 et le 16nm pour accélérer la cadence de mise en production. En pratique chez TSMC, malgré le BEOL commun, le half pitch M1 reste tout de même dans les clous à 32nm (entre 40 et 31.8 sur la roadmap).
La densité pratique reste de toute manière très différente de ce que peuvent proposer des formules grossières comme celle utilisée par Intel (qui multipliait le pitch M1 par le pitch entre deux portes), qui pour exploiter les FinFET aura fait le choix d'utiliser pour certains de ses transistors critiques des structures plus larges composées de plusieurs fins (dans des proportions non négligeables même si la proportion exacte est rarement évoquée de manière précise par Intel).
Cumulé a de multiples autres détails (différents types de blocs sont présents avec des densités différentes, de la SRAM aux blocs plus ou moins critiques) il est impossible de tirer grand-chose de la théorie. L'écart entre un Core M Broadwell 14nm fabriqué par Intel (82mm2 pour 1.3 milliards de transistors) et un A8 fabriqué par TSMC en 20nm (89 mm2 pour 2 milliards de transistors) montre qu'il est difficile de comparer quoique ce soit à moins de prendre deux puces strictement identiques. Cela aura été possible pour l'A9 d'Apple, dont la superficie atteint 96mm2 chez Samsung contre 104.5mm2 chez TSMC.

Le mois prochain, l'ITRS devrait donc enfin communiquer une nouvelle roadmap qui d'après Nature tirera définitivement un trait sur la question de la loi de Moore comme moteur d'évolution unique. D'après Nature, la prochaine roadmap se concentrera sur les applications pratiques, allant du smartphones aux puces serveurs et regardera les applications pratiques, que ce soit au niveau circuits d'alimentations, des capteurs nécessaires, ou d'autres blocs de siliciums répondant à des besoins particuliers.
La véritable question est de savoir ce que comportera réellement cette roadmap qui serait rebaptisée d'après Nature International Roadmap for Devices and Systems, abandonnant même le mot transistor !
Ce que l'on sait, c'est que la réorganisation de l'ITRS en 2014 s'est faite autour de groupes de travaux, avec notamment un groupe baptisé « More Moore » pour évoquer les pistes techniques pour les prochains nodes, dont vous pouvez retrouver ci-dessous la dernière présentation datant de février 2015.



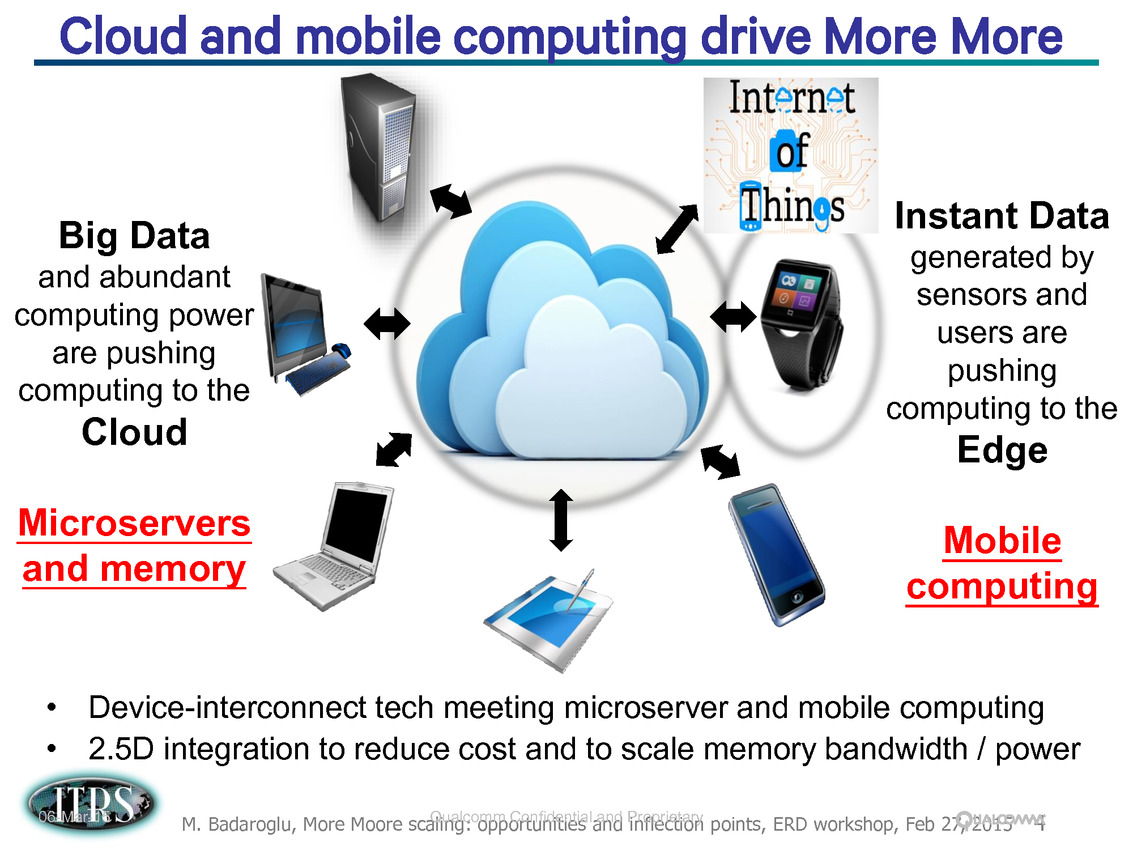
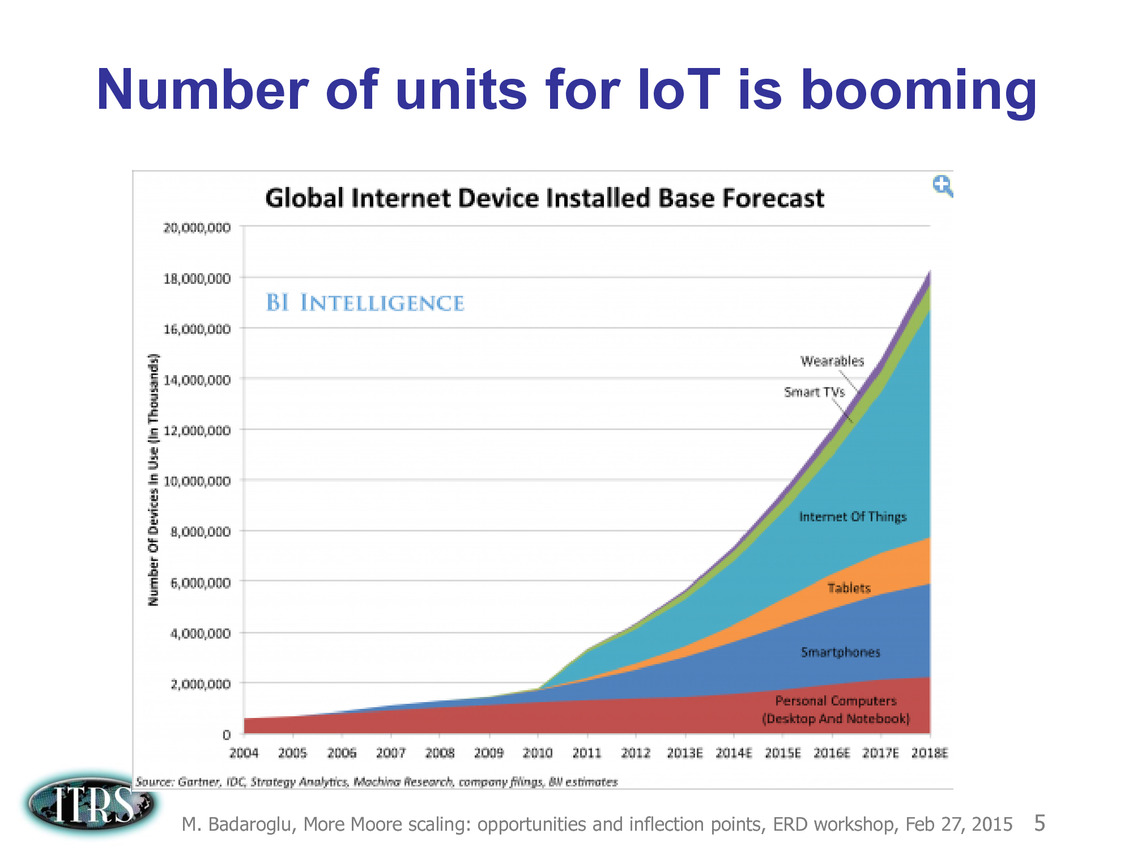

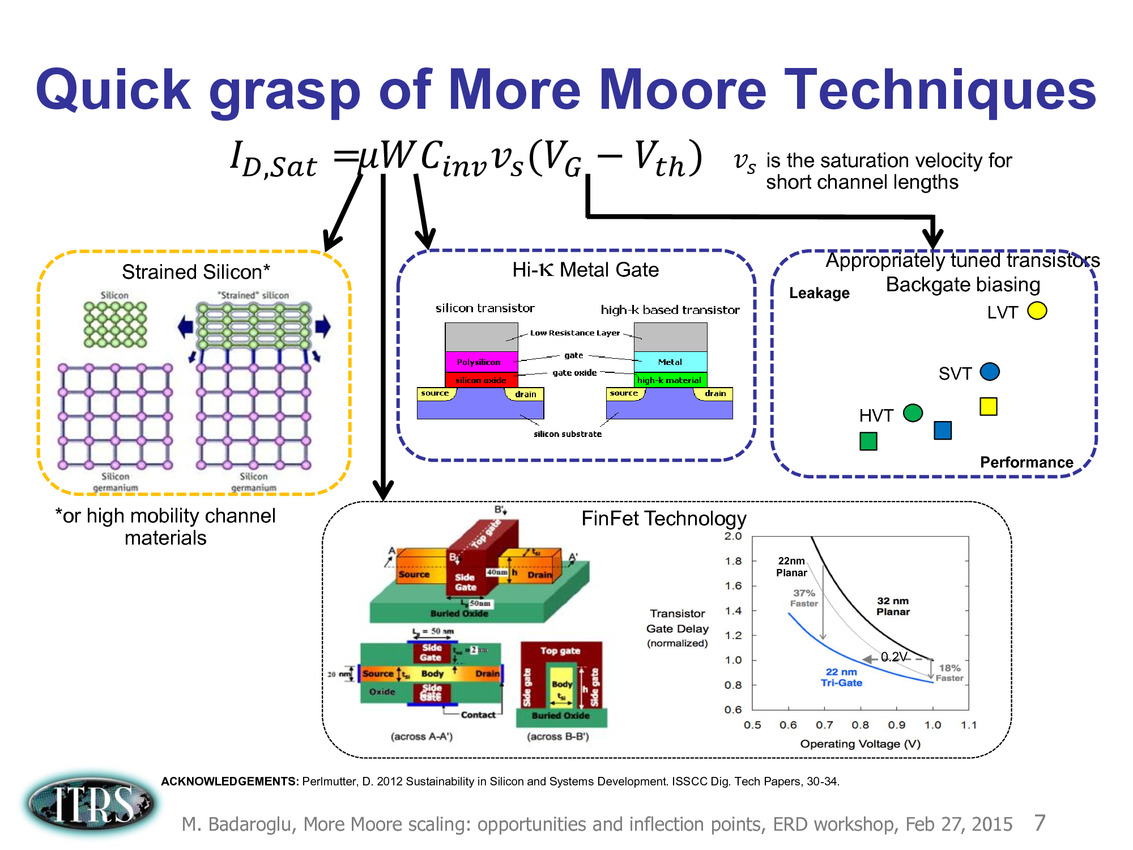
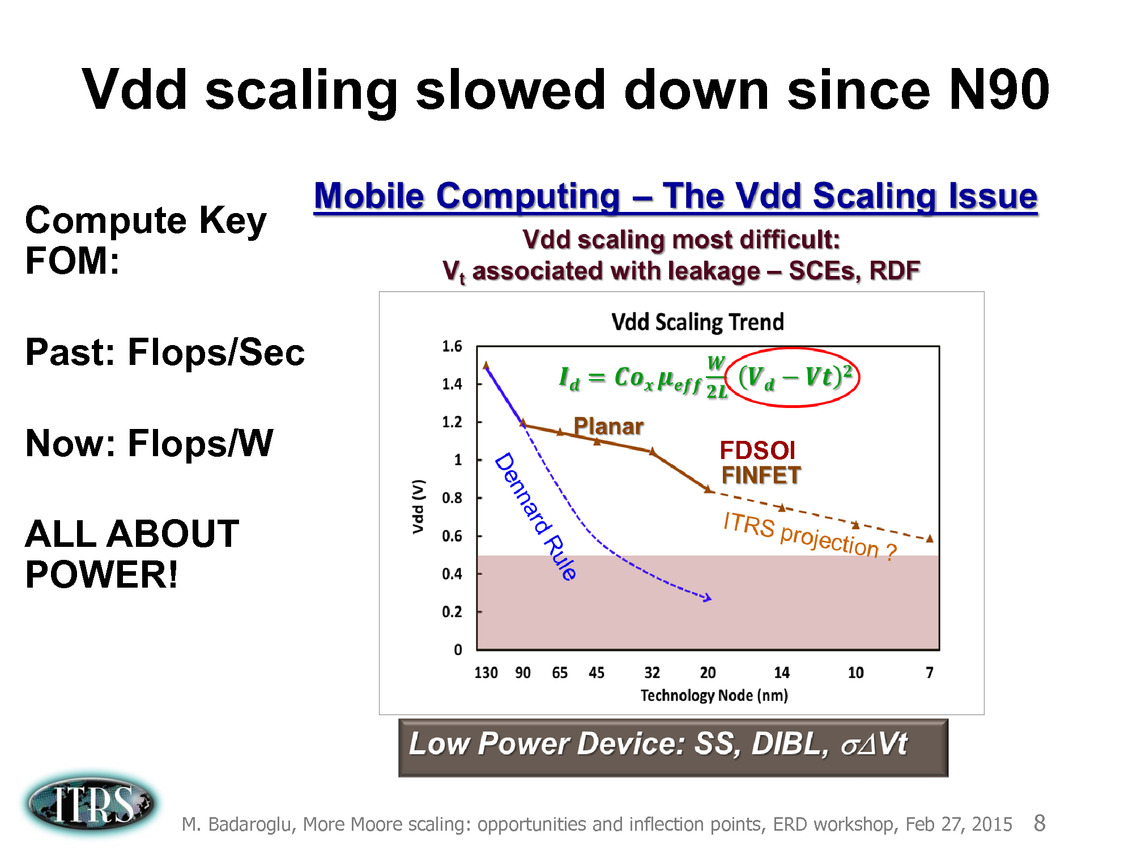
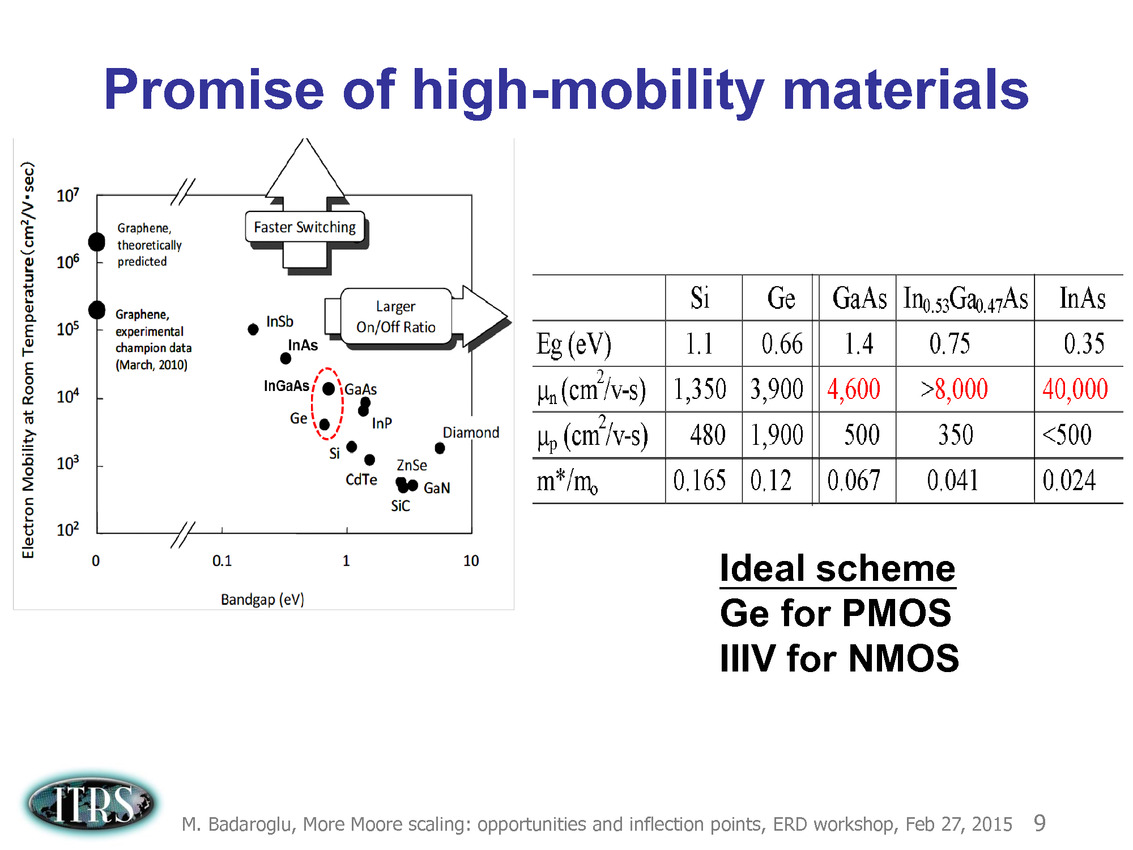
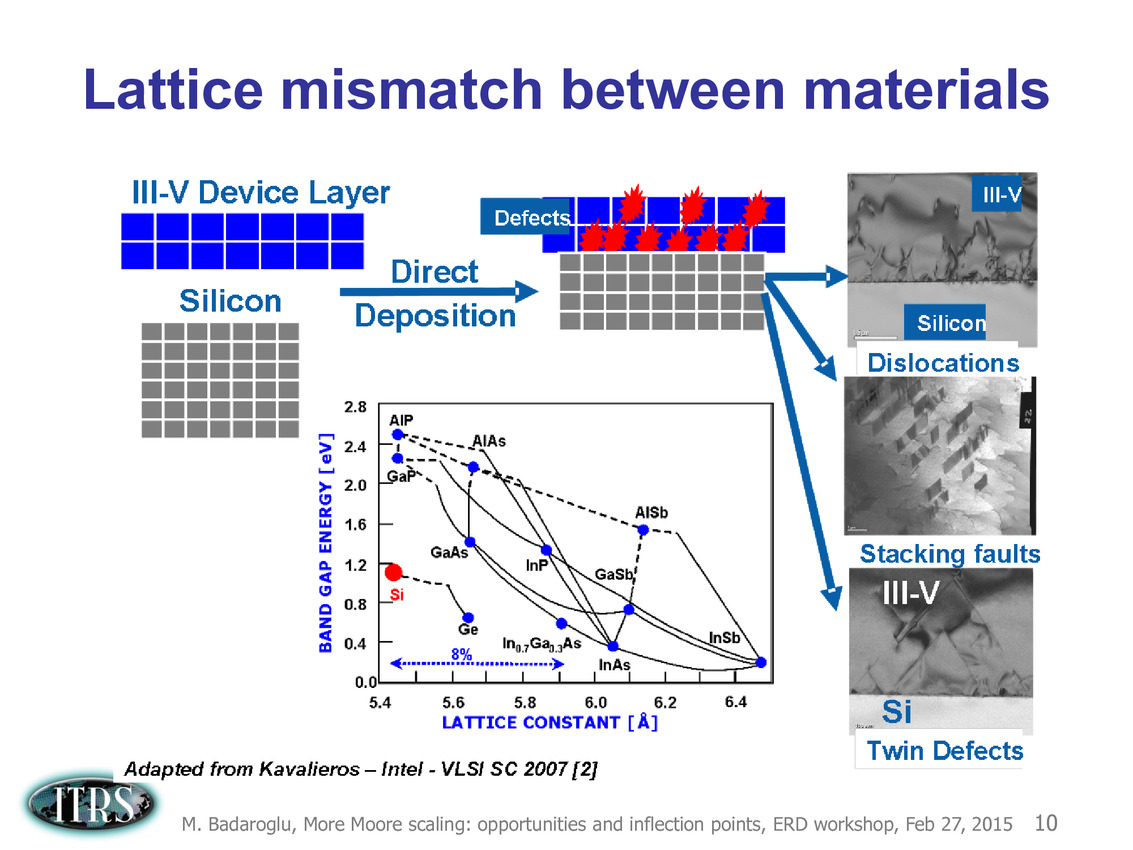
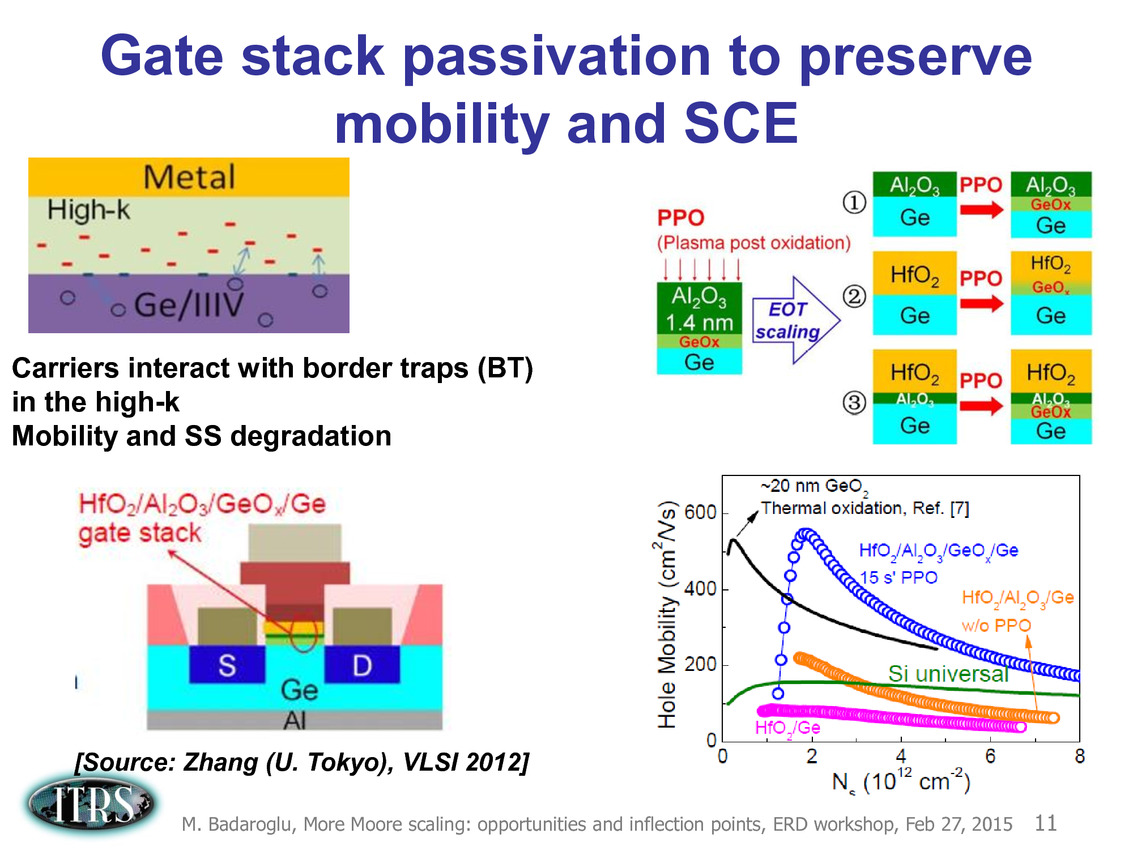
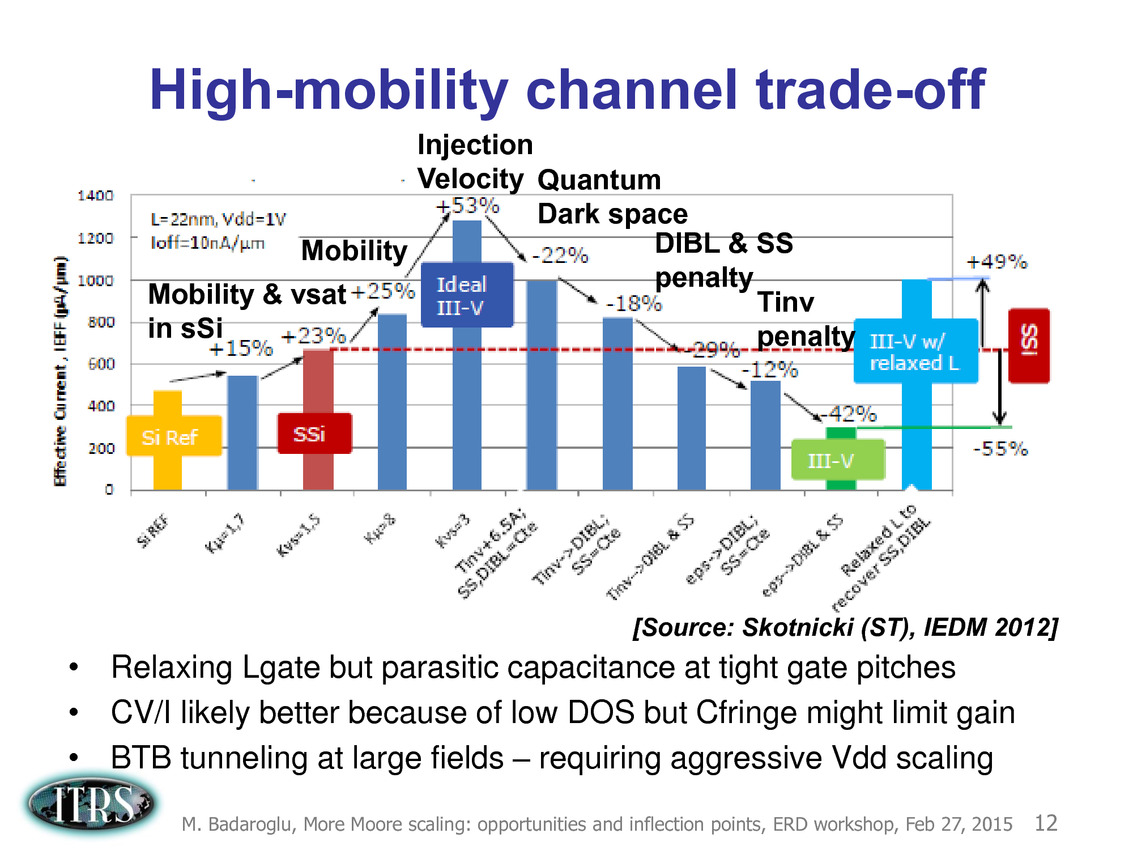
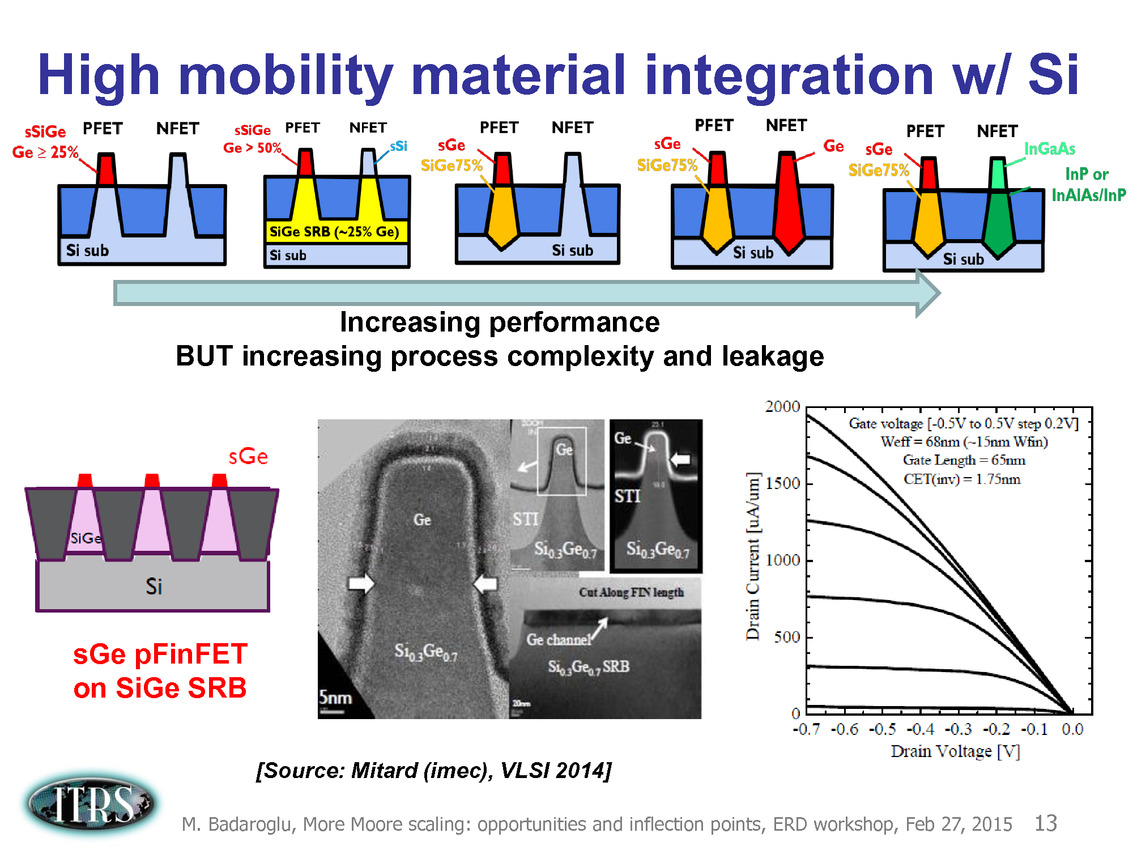

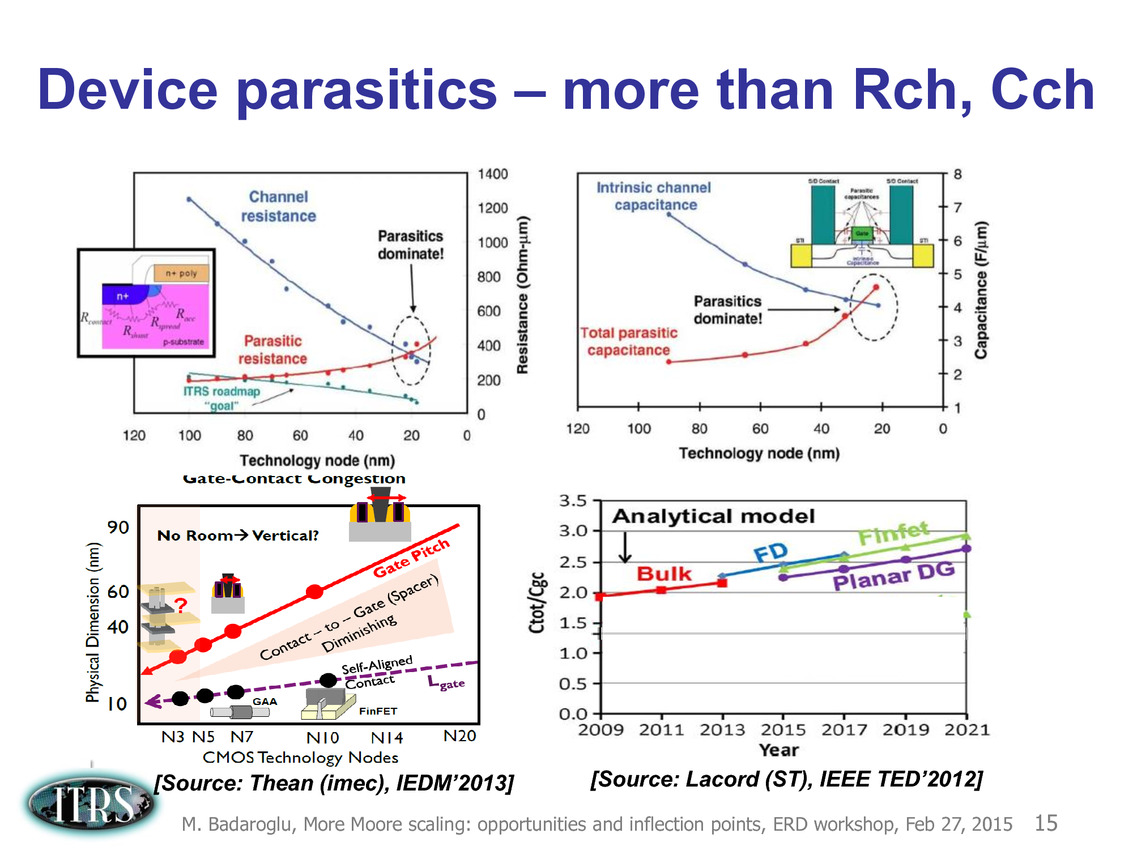
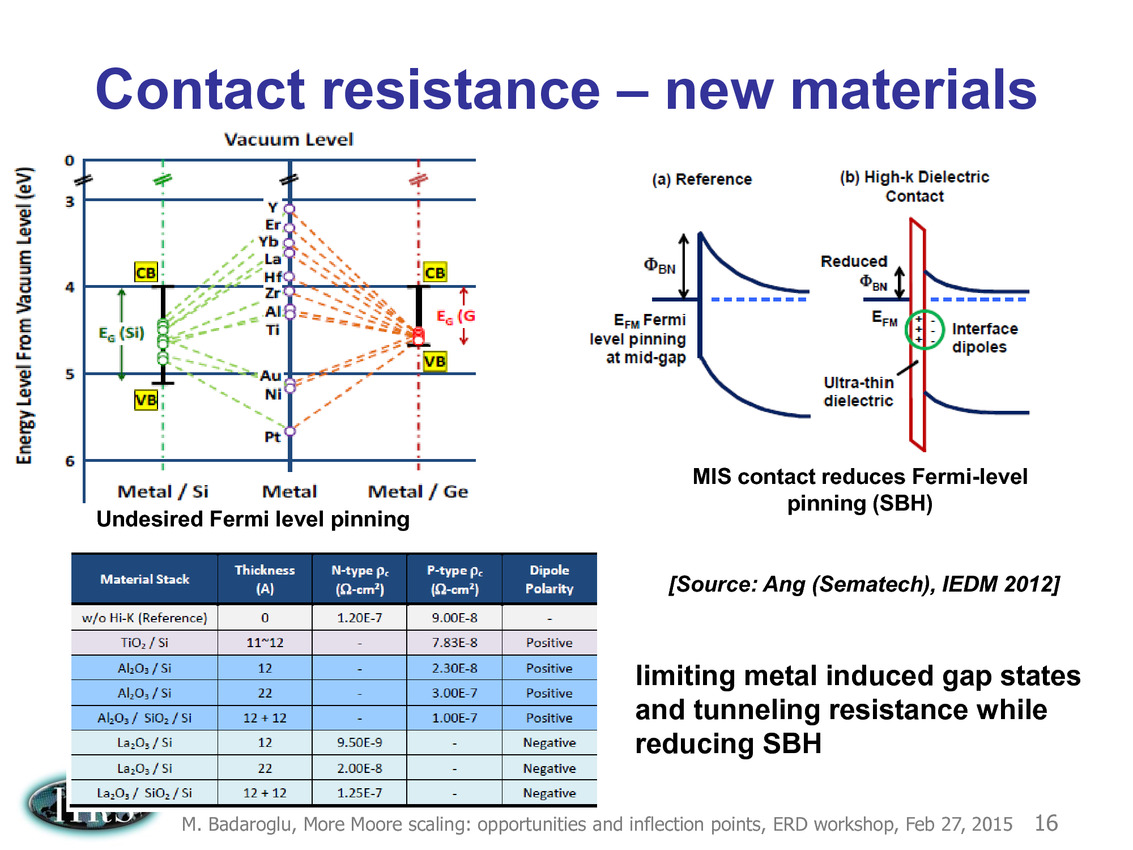
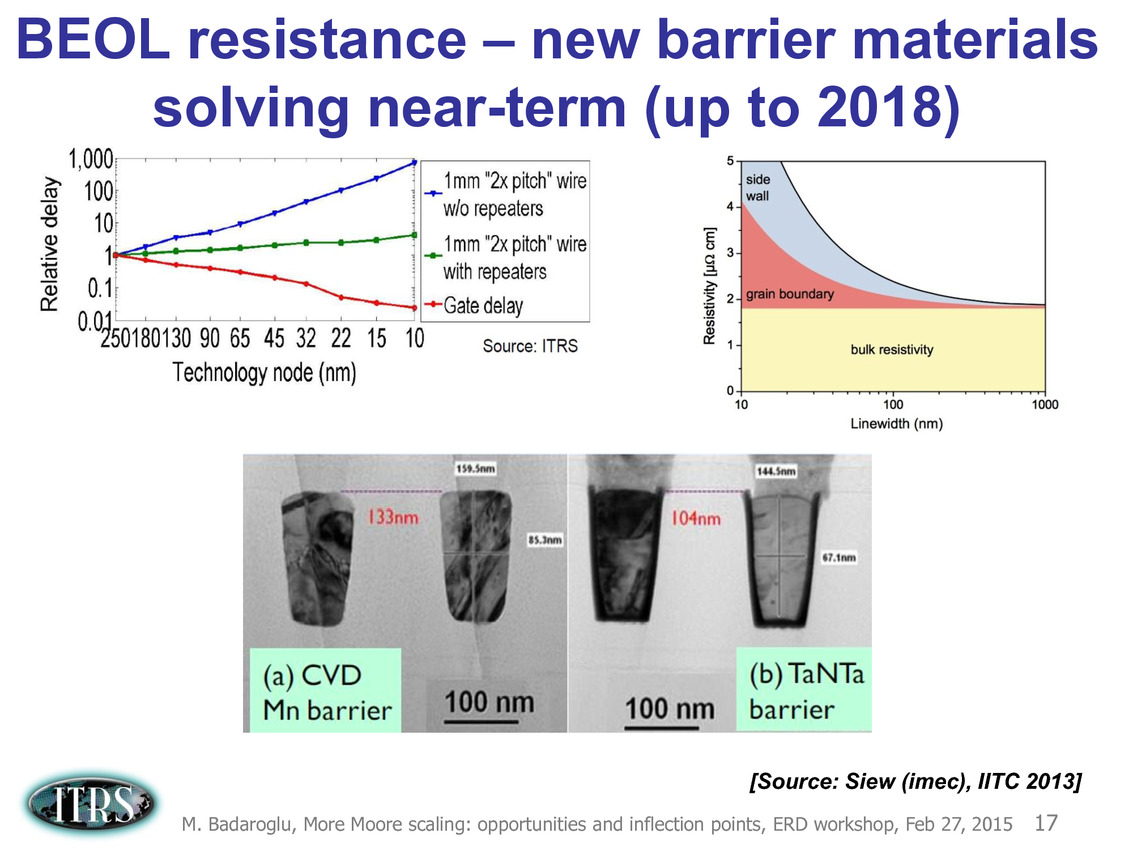
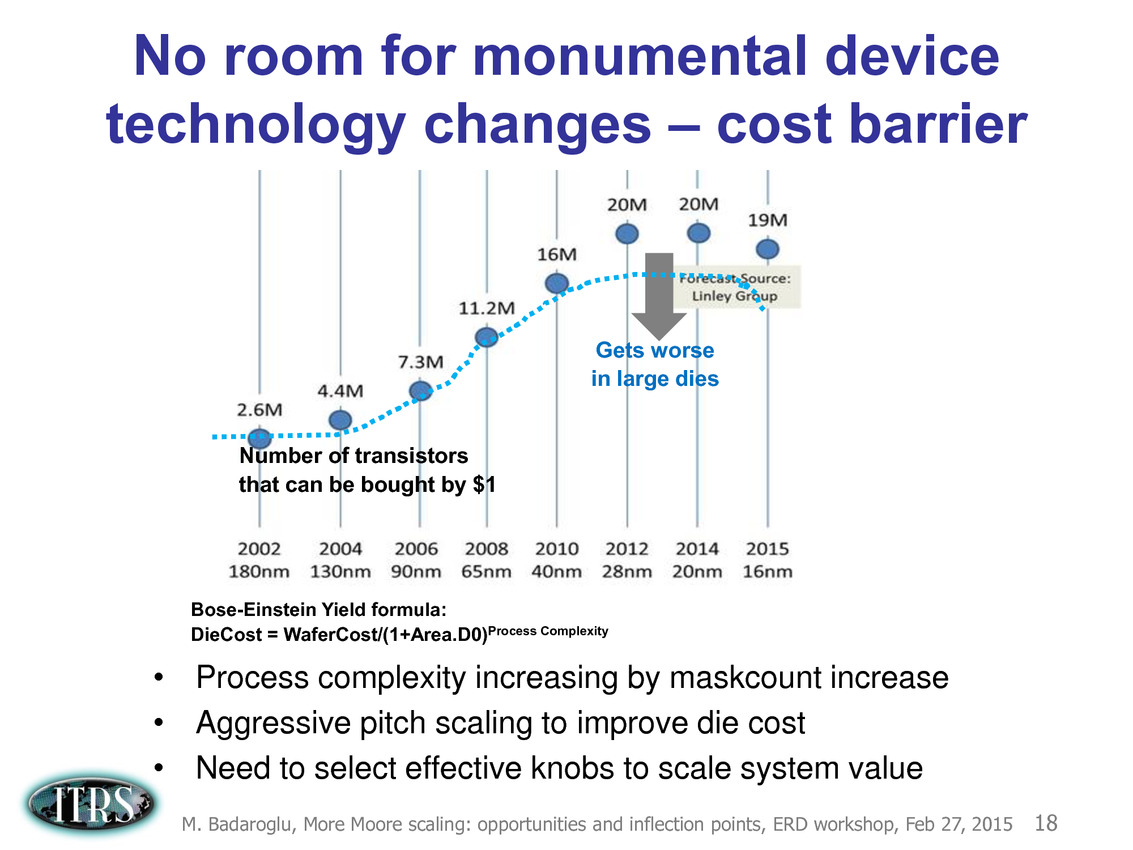
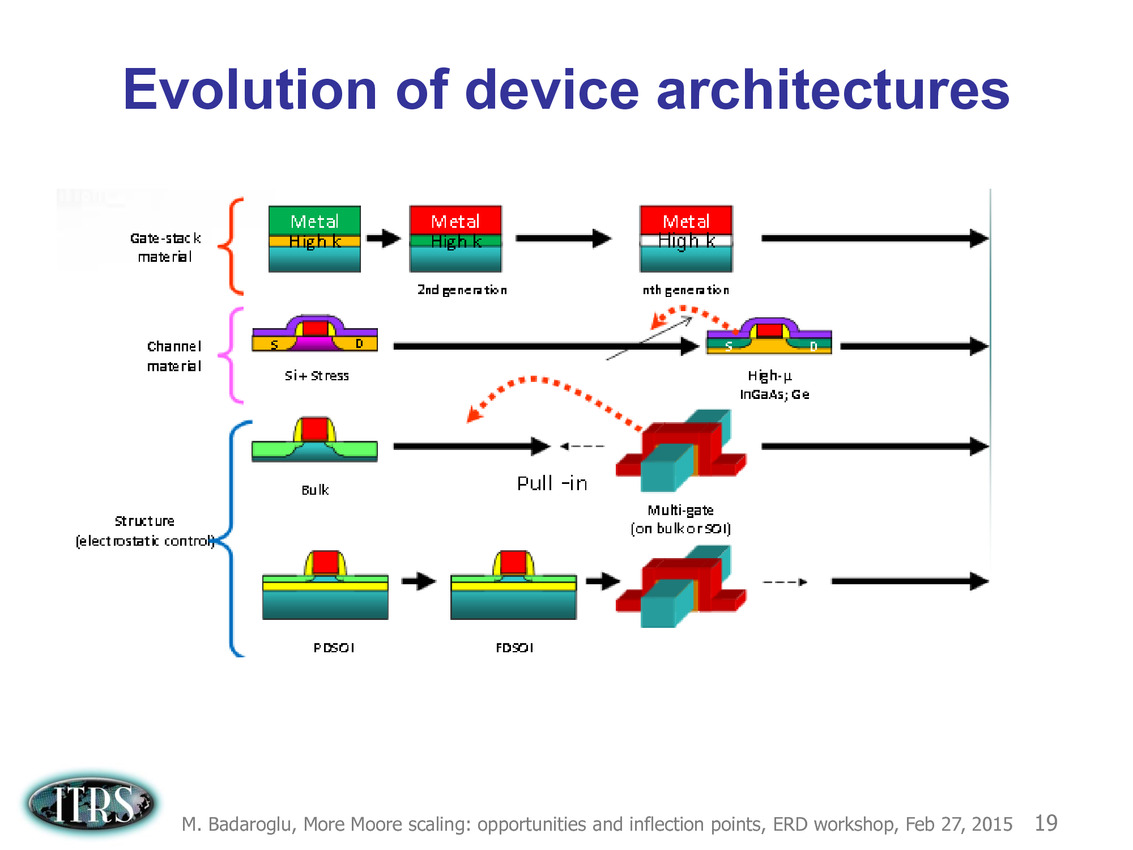
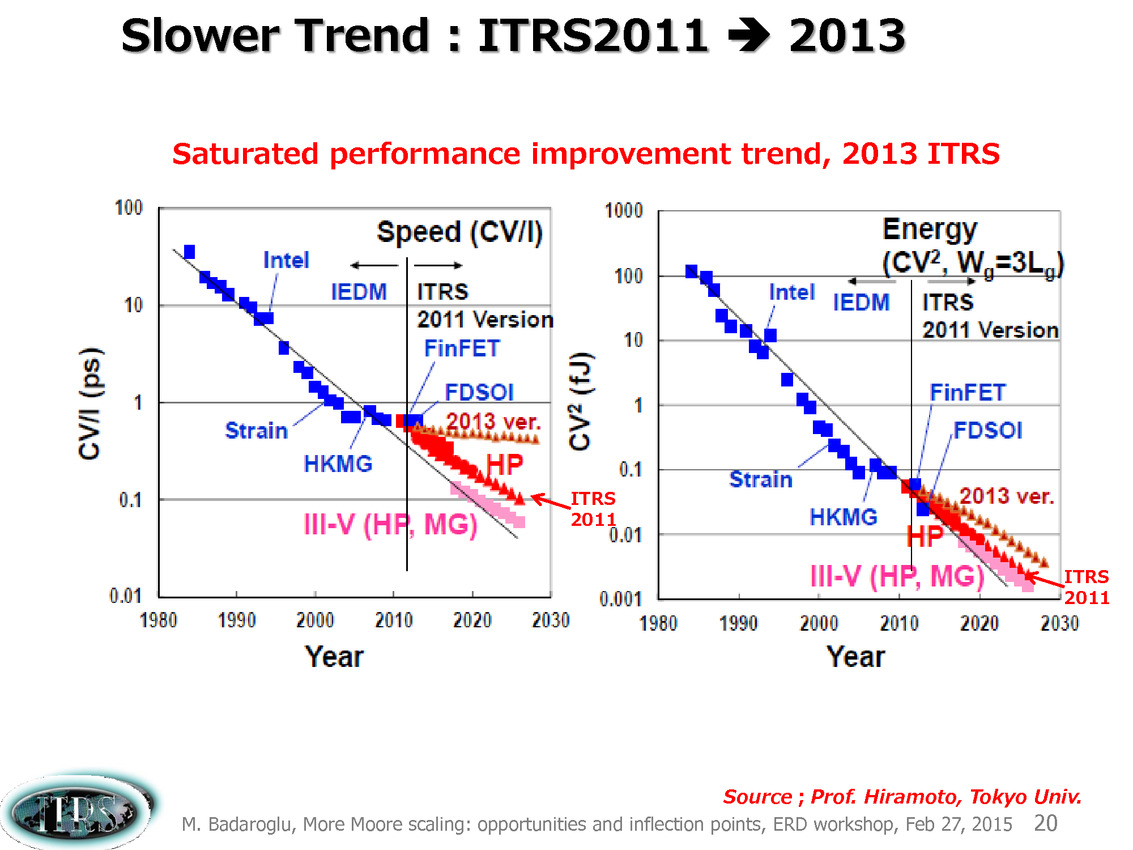
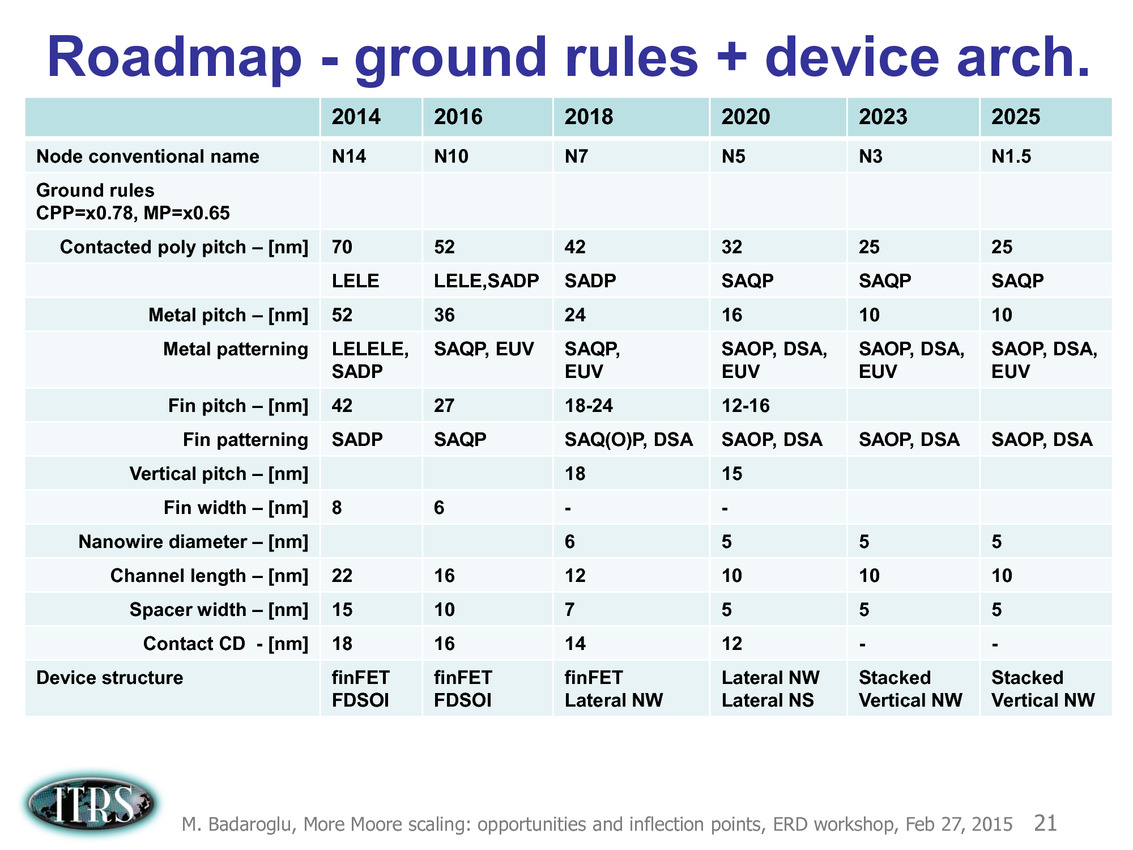
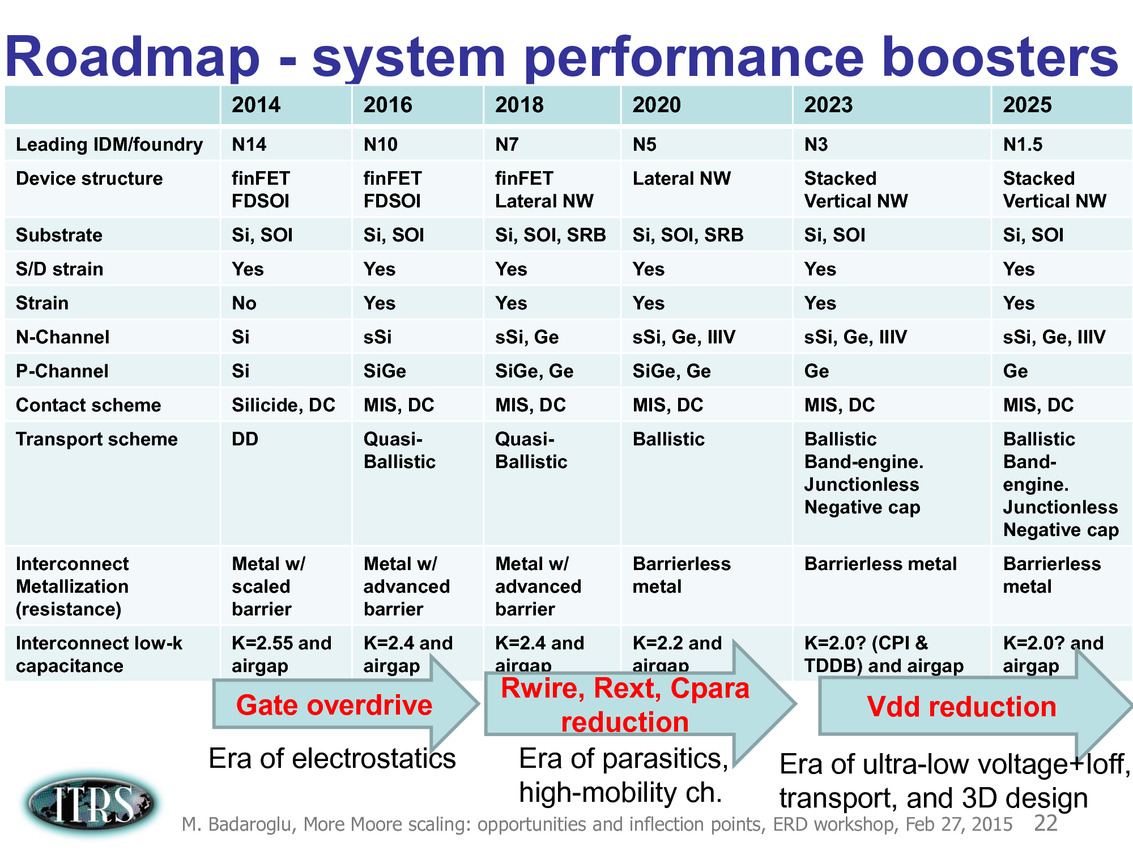
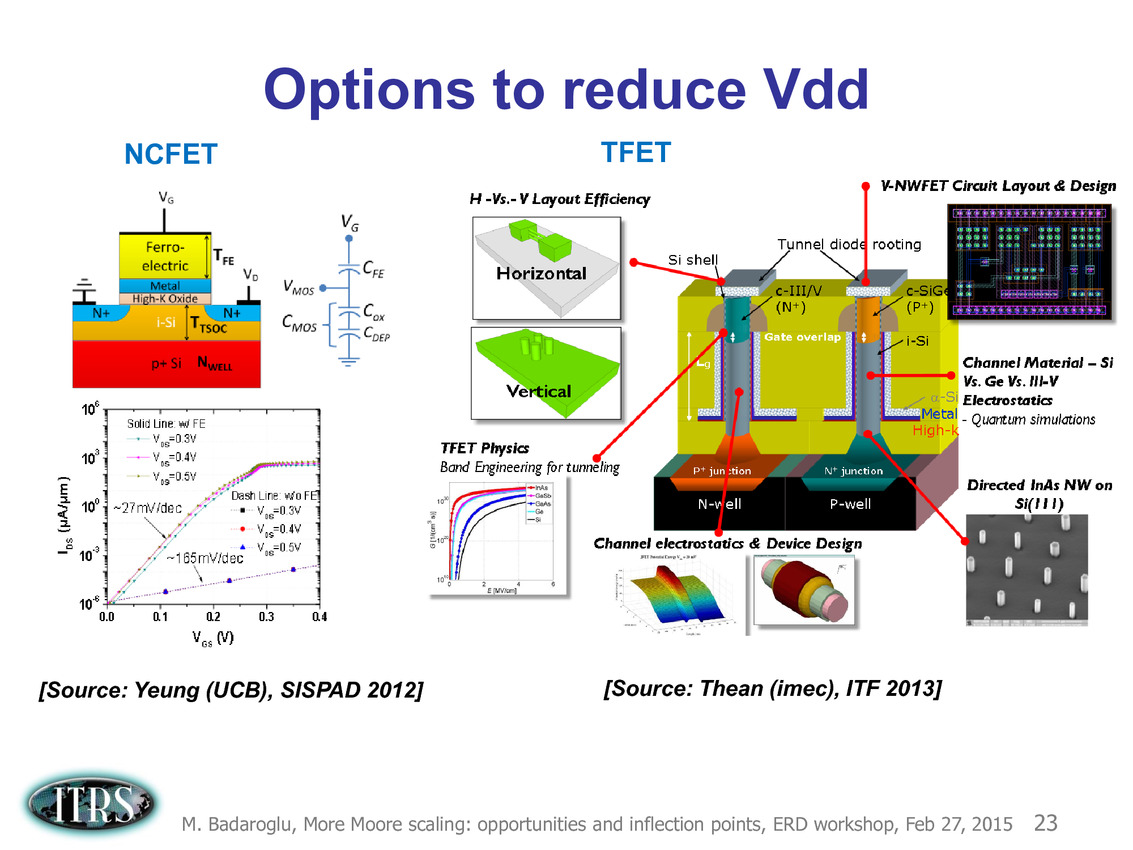
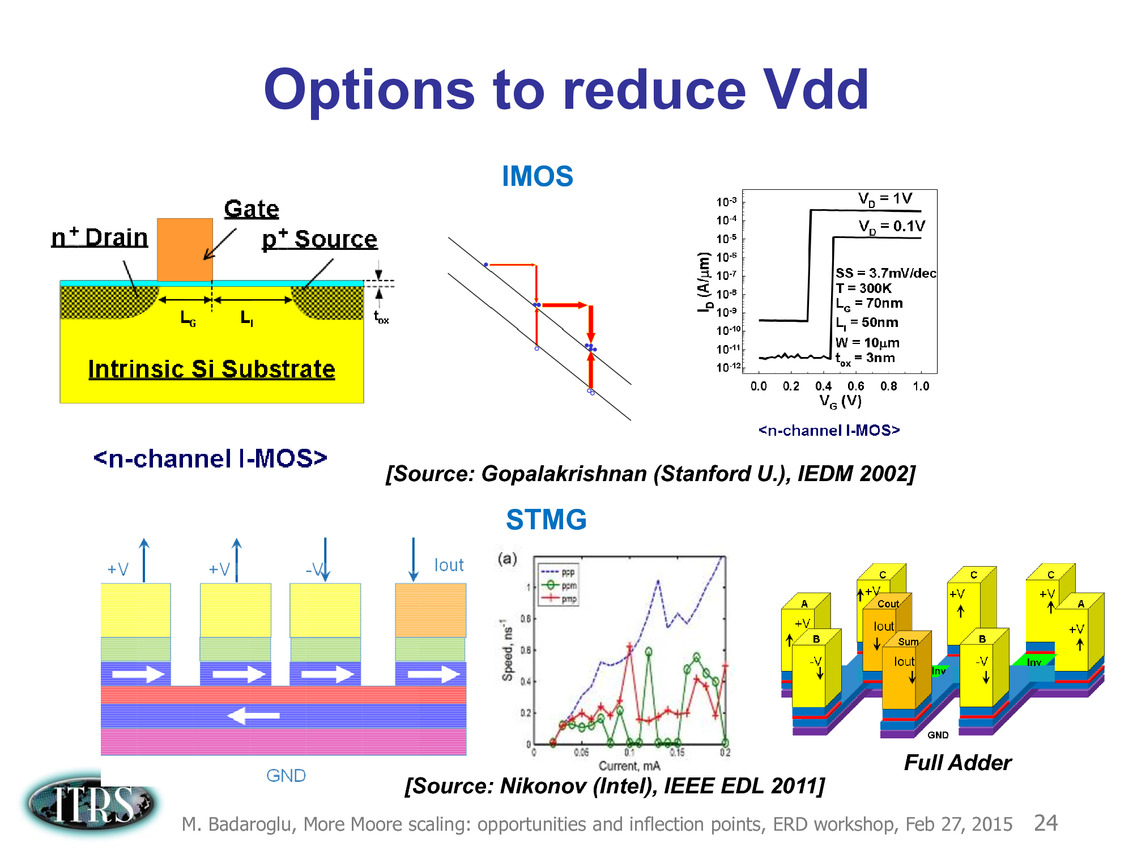
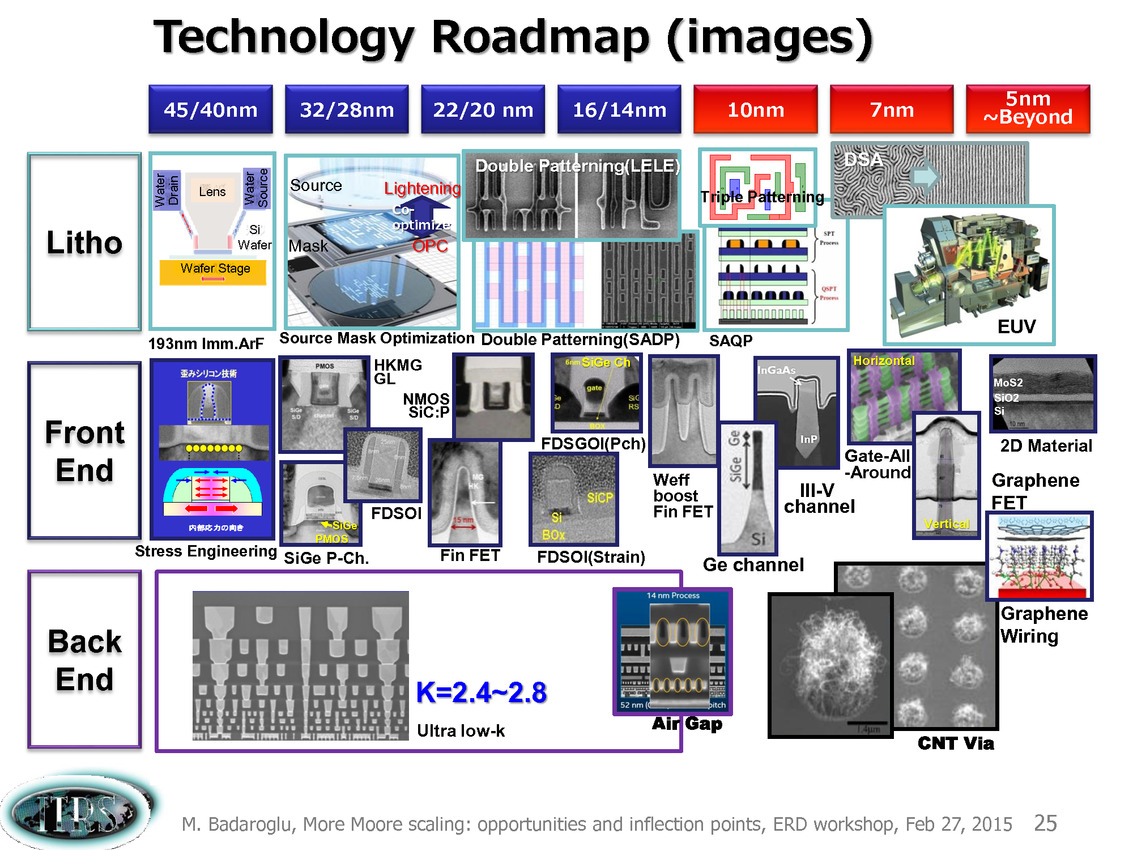

Une présentation intéressante qui évoque de multiples pistes et où l'on trouve un début de roadmap que nous avons remis ci-dessous :
En pratique, après l'ère de la mise à l'échelle géométrique, et l'ère des équivalences, l'ITRS évoque l'ère du "3D Power Scaling" dont les meilleurs représentants sont la NAND 3D ou des technologies comme la mémoire HBM. Des techniques complexes à appliquer aux puces logiques même si la présentation évoque quelques pistes et alternatives.
On attendra donc le mois prochain pour en savoir un peu plus !
3 architectures 10nm pour Intel ?
Alors qu'Intel a indiqué lors de ses résultats trimestriels avoir pour objectif de revenir au rythme habituel de 2 ans entre deux process de fabrication, il ne semble que ce retour à la normale ne soit pas prévu pour le passage à 7nm.

A l'instar de ce qui se passe sur le 14nm qui va voir passer successivement Broadwell, Skylake et Kaby Lake, ce sont ainsi trois architectures qui seraient prévues en 10nm selon Fool.com : Cannonlake pour le second trimestre 2017, Icelake un an plus tard et finalement Tigerlake au second semestre 2019. L'arrivée des produits en 7nm ne se ferait ainsi pas avant 2020, soit par rapport au planning annoncé en 2010 1 an de retard pour le 14nm, 2 ans pour le 10nm et 3 ans pour le 7nm.
Si Intel aime annoncer une densité supérieure de son 14nm par rapport aux process 14/16nm concurrents, ce que contredisent bien entendu ces derniers, l'arrivée de produits 7nm en 2020 mettrait tout le monde d'accord puisque côté TSMC on devrait voir des puces 7nm sortir des chaines de fabrication avant la fin 2018.
Un tel décalage peut paraître étonnant puisque c'est ASML qui équipe principalement toutes les fonderies, il est très probable qu'il découle en fait de choix différent entre d'un côté attendre l'EUV, ce que fera peut-être Intel pour le 7nm, ou faire appel à de plus en plus de multiple patterning et de parties de process communes avec le node précédent afin de repousser l'EUV au 5nm, ce qui est l'option prise par TSMC. L'avenir nous dira quels choix vont être faits et lequel sera le bon !
TSMC vise 2020 pour le 5nm via l'EUV
TSMC a présenté ses résultats pour le dernier trimestre 2015, pour une fois ils sont en baisse avec des ventes et un bénéfice qui baissent respectivement de 8.5 et 8.9%. La part du 16/20nm dans les revenus est en hausse, passant sur trois mois de 21 à 24%, ce qui se fait surtout au dépend du 28nm qui passe de 27 à 25%.
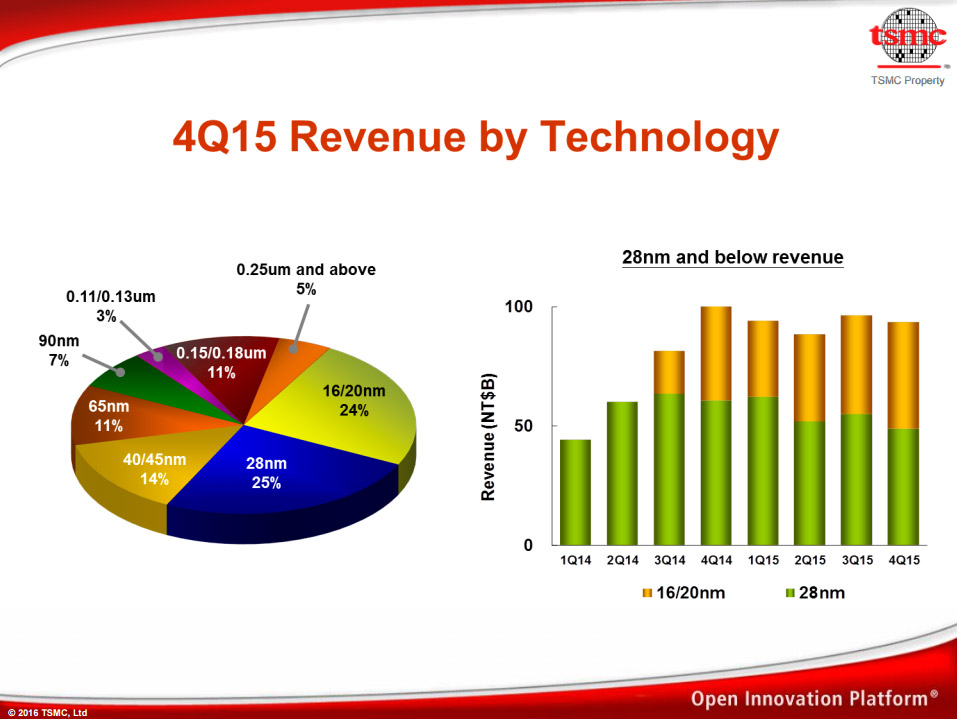
Le fondeur se montre confiant pour l'année à venir, indiquant qu'il devrait passer de 40% de parts de marché sur les process 16/14nm à plus de 70% en 2016. Cela se fera via 16FF+ (FinFet+) destiné aux produits les plus performants mais aussi nouveau 16FFC (FinFet Compact) pour le moyen de gamme et la basse consommation.
Pour le reste TSMC a confirmé le 10nm pour 2017, sans donner de date précise. Il y a trois mois il était question d'un début de la production en volume au dernier trimestre 2016 et de premiers revenus au premier trimestre 2017. La production en volume en 7nm a été annoncée pour le premier semestre 2018, et il faudra attendre 2 années supplémentaires avant de voir débarquer le 5nm. Le 5nm devrait finalement être le premier à utiliser l'EUV, mais TSMC travaille encore avec ASML à fiabiliser les machines : il a ainsi pu atteindre sur une période de 4 mois une moyenne de 500 wafer exposés par jour on est assez loin des 1000 wafer qu'elle peut atteindre en pointe.
AMD valide le 14nm LPP de GloFo
GlobalFoundries vient d'annoncer dans un communiqué qu'il avait livré à AMD des puces fonctionnelles gravées avec le process 14nm LPP (Low Power Plus), la version la plus avancée du procédé de fabrication Samsung 14nm FinFet (l'Apple A9 utilisant le 14nm LPE Low Power Early) qui est pour rappel également déployé chez GF.

Le fondeur précise qu'AMD a "taped out" plusieurs produit chez GF en 14nm LPP et qu'il est actuellement en train de valider les échantillons produit. Il semble donc qu'un premier produit ai été validé, GF parlant de "silicon success". AMD indique au passage qu'il compte utiliser le process 14nm LPP sur des produits CPU, APU mais aussi GPU. Jusqu'alors les GPU AMD étaient comme ceux de Nvidia fabriqués par TSMC, mais sachant qu'AMD a toujours des engagements contractuels sur des volumes avec GF qu'il peine à remplir il est logique qu'il favorise ce dernier si le process est à la hauteur. On devrait donc avoir droit en 2016 à une bataille d'architecture entre AMD et Nvidia combinée à une bataille de fondeurs avec d'un côté le 16nm FinFET+ de TSMC et de l'autre le 14nm LPP de Samsung/GlobalFoundries !
GlobalFoundries indique que le 14nm LPP a été qualifié au cours du troisième trimestre pour la production, cette dernière va débuter au cours de ce quatrième trimestre et arrivera à plein débit en 2016, sans plus de précision. Difficile pour le moment de savoir quand les premières puces AMD produites en 14nm LPP seront lancées en 2016, mais il serait étonnant que ce soit avant le second trimestre côté GPU et le dernier trimestre côté CPU. Vivement !
Résultats TSMC, 16 FinFET+ dans l'iPhone 6s
TSMC présentait cette nuit également ses résultats qui, sans trop de surprises, sont bons et au-dessus des estimations. Une des raisons se trouve derrière le fait que TSMC est, contrairement aux spéculations, le fournisseur majoritaire de SoC d'Apple pour l'iPhone 6s. TSMC a également glissé au passage que ces SoC livrés par TSMC étaient bel et bien 16 FinFET+ (la version avancée du process 16nm de TSMC), ce qui explique peut-être l'avantage de consommation en charge lourde que l'on voit dans les versions TSMC des iPhones face aux versions Samsung, comme noté par nos confrères d'Ars Technica .
On aura noté quelques sourires lorsque la question de la différence a été posée clairement à TSMC, le fondeur se contentant de rapporter les propos d'Apple (qui indique 2 à 3% de variations selon les puces en usage normal) et qu'ils étaient « très confiants » sur leur technologie. Dans tous les cas, cela confirme qu'effectivement le 16 FinFET+ de TSMC est déjà prêt, ce qui est une bonne nouvelle pour tous les clients du fondeur !
Par rapport au troisième trimestre 2013 les revenus du fondeur sont en hausse de 1.7%. La marge brute est en baisse cependant, principalement suite à la vente de l'activité solaire du groupe. La société mélange les revenus 16 et 20nm dans ses résultats, les deux nodes représentent 21% des revenus de TSMC. La proportion du 16nm devrait augmenter significativement au quatrième trimestre même si la société n'a pas donné de détails. Au second trimestre, le 20nm, utilisé quasi exclusivement par Apple et Qualcomm représentait 20% des revenus de TSMC.
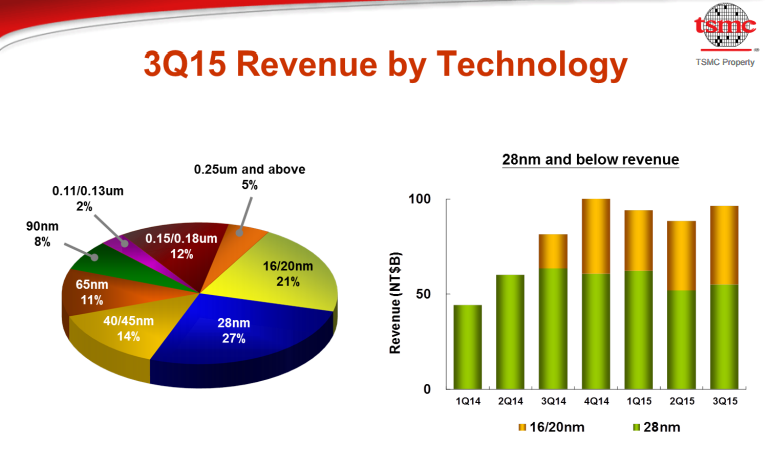
TSMC s'attend à voir ses revenus progresser sur l'année 2015 de 11%, porté par le marché des smartphones qui globalement profiterait d'une hausse de 10% sur l'année quand tous les autres secteurs sont en baisse. La société se félicite de sa place sur le marché haut de gamme qui, s'il n'évolue pas massivement en volume, contient de plus en plus desilicium TSMC.
L'un des co-CEO de TSMC Mark Liu insiste sur le rôle à venir de TSMC sur le marché du « computing » en général, quelque chose qui fait écho aux propos de Morris Chang, le chairman qui au trimestre dernier voyait TSMC jouer un rôle plus important sur les PC portables et les serveurs, mais aussi l'arrivée de SoC dans de nouveaux marchés qui n'existent pas encore. TSMC a indiqué travailler avec certains de ses partenaires sur les automobiles autonomes, nécessitant beaucoup de silicium pour des puces spécialisées dans les traitements d'images pour simuler la vision.
Sur le 10nm, TSMC dit être en bon chemin sur le développement indiquant que le process apportera un gain de densité de 2.1x par rapport au 16 FinFET+, 20% de performances supplémentaires ou 40% d'économie d'énergie à performances égales. Des chiffres qui ont légèrement évolué, plutôt dans le bon sens par rapport à ce qui était indiqué le trimestre dernier (2.2x, +15% et -35% respectivement). TSMC compte freezer la phase de développement ce trimestre et commencer les phases de qualifications avec des premiers tapeout clients attendus au printemps prochain. Des délais agressifs qui correspondent à ce que la société avait promis jusqu'ici.
Pour le 7nm, TSMC sous-entend que le process profitera de l'apprentissage des yields du 10nm. Nous continuons de penser, même si TSMC ne le dit pas clairement, que le BEOL (la partie interconnexion de la puce) du 10 et du 7nm seront communs à l'image de ce qui s'est passé entre le 20 et le 16nm, même si des gains de densités ont été évoqués (mais non quantifiés !). Le développement est lui aussi « en bonne voie » et devrait apporter des gains substantiels de performances face au 10 même s'ils n'ont pas été précisés non plus. Le 7nm sera en tout cas le prochain node « long » (après le 16 FinFET+) ce qui laisse penser qu'effectivement la situation 20/16 se réitèrera en 10/7. Mark Liu a en prime indiqué avoir déjà produit de la SRAM fonctionnelle en 7nm.
L'autre co-CEO de TSMC, C.C. Wei, a indiqué que la demande sur le 20nm était plus faible qu'attendue, en partie du fait de la disponibilité un peu plus tôt que prévue du 16nm. Le fondeur s'attend tout de même à produire deux fois plus de puces 20nm en 2015 qu'en 2014. Cependant la conversion des usines 20nm en 16nm va continuer, le 20nm étant voué à disparaitre. 100 produits de 40 clients sont attendus en 2016. Sur le packaging type InFO (Intergrated Fan-Out Wafer Level Packaging) le fondeur s'attend à ce qu'il soit disponible en 2016 pour ses clients sur son process 16nm.
Les yields 16 FinFET+ continuent en tout cas de battre tous les records internes d'après le constructeur, confirmant que le choix d'avoir utilisé un BEOL commun, même si cela n'apporte pas un gain de densité massif, permet d'être plus rapidement présent sur le marché avec un process performant.
MAJ : A la toute fin du (long !) webcast, TSMC est revenu sur l'EUV, indiquant que durant ces trois derniers mois, les progrès de l'EUV ont été très bon et qu'à compter de janvier, de nouvelles machines devraient être livrées pour préparer le travail sur le 5nm !