
Les contenus liés au tag ARM
Afficher sous forme de : Titre | FluxRésultats en baisse pour AMD
24 curs ARMv8 en socket chez Qualcomm
Intel pourrait racheter Altera
La spécification HSA 1.0 disponible
ARM annonce Cortex-A72, Mali-T880 et CCI-500
Nouveau contrôleur NVMe pour Marvell



Marvell profite lui aussi du Flash Memory Summit pour lancer un nouveau contrôleur pour SSD NVMe compacts (par exemple au format M.2 ou directement intégré dans un SSD BGA), le 88NV1160. Il vient faire suite aux 88NV1120 et 88NV1140 lancés fin 2014. Comme les deux autres références, le contrôleur est toujours fabriqué en 28nm.

Les ressemblances ne s'arrêtent pas là puisque l'on retrouve à l'intérieur les mêmes deux coeurs ARM Cortex R5. On retrouve les mêmes particularité à savoir la présence de SRAM à l'intérieur du contrôleur pour remplacer l'utilisation d'une puce DRAM externe, et le support additionnel du Host Memory Buffer pour utiliser si on le souhaite la mémoire système comme cache.
Contrairement au 1140 qui gérait le NVMe sur une seule ligne PCIe Gen3, le 1160 supporte désormais deux lignes, ce qui permet de doubler les débits théoriques pour atteindre les 1600 Mo/s en lecture annoncés. De la même manière, on passe de deux à quatre canaux NAND pour le 1160.
La puce est actuellement en cours d'échantillonnage par Marvell auprès de ses partenaires.
ARM annonce le Cortex-A73 et le Mali-G71
ARM vient d'annoncer de nouveaux blocs disponibles pour ses partenaires. Pour rappel, ARM développe en parallèle des architectures (ARMv8-A pour la dernière version 64 bits, le pendant du x86-64 dans le monde du PC) et propose aussi ses propres implémentations de coeurs qui peuvent être utilisés par ses partenaires sous licence (l'équivalent dans le monde PC serait Intel qui autorise ses partenaires à faire des versions "custom" de Skylake).
Certains des partenaires d'ARM disposent d'une licence dite "architecture" (Apple, Qualcomm, Samsung, Nvidia...) qui leur permet de réaliser leurs propres implémentations (de la même manière qu'AMD et Intel proposent des processeurs compatibles, mais différents derrière la même architecture x86-64), même si ces derniers proposent parfois les deux. Qualcomm propose par exemple des puces utilisant les Cortex (implémentation ARM) et ses propres Snapdragon.
La nomenclature des implémentations d'ARM a toujours été compliquée à comprendre, pour ne pas dire autre chose, et autant dire qu'aujourd'hui ARM n'arrange pas son cas avec l'A73. Il fait suite sur le papier au Cortex-A72 qui avait été annoncé en février 2015 même si d'un point de vue technique les puces sont différentes.
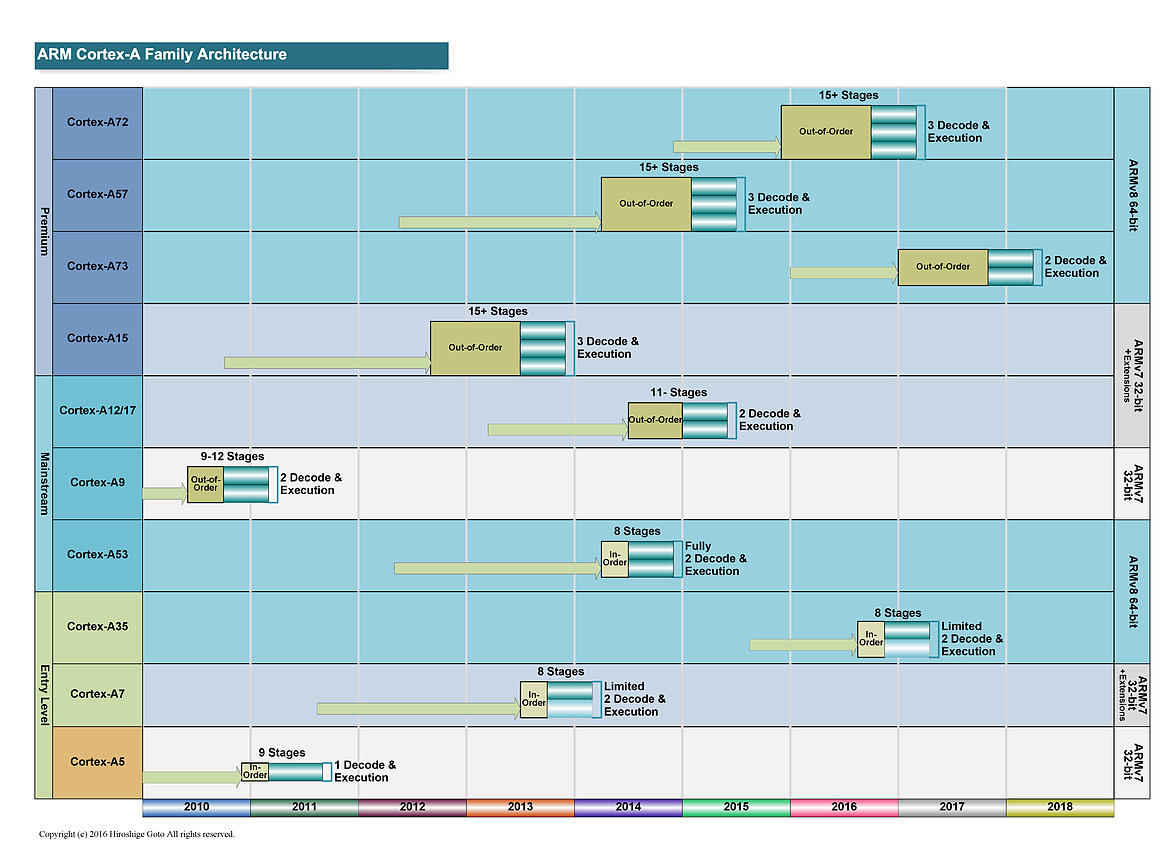
Ce diagramme permet d'y voir un tout petit peu plus clair. Après l'époque "simple" de l'A9, ARM a proposé d'un côté des cores de grande taille, visant les hautes performances (A15, A57 et A72), également appelés big. Il s'agit de designs "Out of Order" (le processeur peut changer l'ordre des instructions pour optimiser leur exécution).
En parallèle des coeurs de plus petite tailles ont été présentés (les coeurs LITTLE comme l'A7 et l'A53). Ils utilisent un design dit "In Order" (pas de changement d'ordre) qui simplifie l'implémentation, et réduit donc la consommation de la puce. Leur niveau de performance est plus bas, mais ils disposent d'un meilleur rapport performance/watts que les coeurs big. Leur intérêt théorique est de les mélanger pour créer une architecture asymétrique (big.LITTLE, voir la présentation ici) même si en pratique, ce n'est pas toujours ce qui s'est passé.
Les deux familles sont développées par des équipes différentes (Austin pour les big et Cambridge pour les LITTLE) et au milieu de tout cela, on retrouvait les A12 et A17, mélangés sur ce graph (par une troisième équipe a Sophia-Antipolis). Il s'agissait là aussi de designs "Out of Order" mais un peu plus optimisés pour un meilleur rapport performances/watts.
Si en théorie ces puces étaient présentées comme dédiées au milieu de gamme, en pratique elles proposaient surtout une alternative aux gros coeurs ARM dont la consommation était trop élevée, obligeant de limiter fortement les fréquences pour rester dans l'enveloppe thermique d'un smartphone. On a pu voir un certain nombre de retards lors de la génération A57, particulièrement chez Qualcomm, et une surconsommation importante par rapport à ce qu'espérait ARM. Une situation qui a même poussé certains des partenaires d'ARM a proposer des puces n'utilisant que les coeurs LITTLE, un comble.
Cortex A73 : 10nm
Le Cortex A73 est présenté par ARM comme son nouveau coeur big. Il fait suite à l'A72 (16nm) et sera proposé pour les processus de fabrication 10nm. Mais contrairement à ses prédécesseurs big 64 bits (A57 et A72, c'est dur à suivre !), il s'agit sur le papier du successeur des A12/A17 (qui eux n'étaient disponibles qu'en 32 bits).
Contrairement aux A57/A72 qui pouvaient décoder trois instructions par cycle, on se limite cette fois ci à deux sur l'A73. En contrepartie, le pipeline (le nombre d'étapes par lequel les instructions passent) est significativement réduit, passant de 15 à 11 étapes. C'est au niveau du front end (récupération des instructions, décodage, changement d'ordre) que la réduction se fait. On retiendra deux changements importants, d'abord le fait que les instructions en virgules flottantes/NEON (l'équivalent des instructions vectorielles type SSE dans les architectures x86) soient traitées séparément via un décodeur distinct. La seconde est un changement au niveau des instructions arithmétiques entières avec des unités moins nombreuses mais plus performantes.

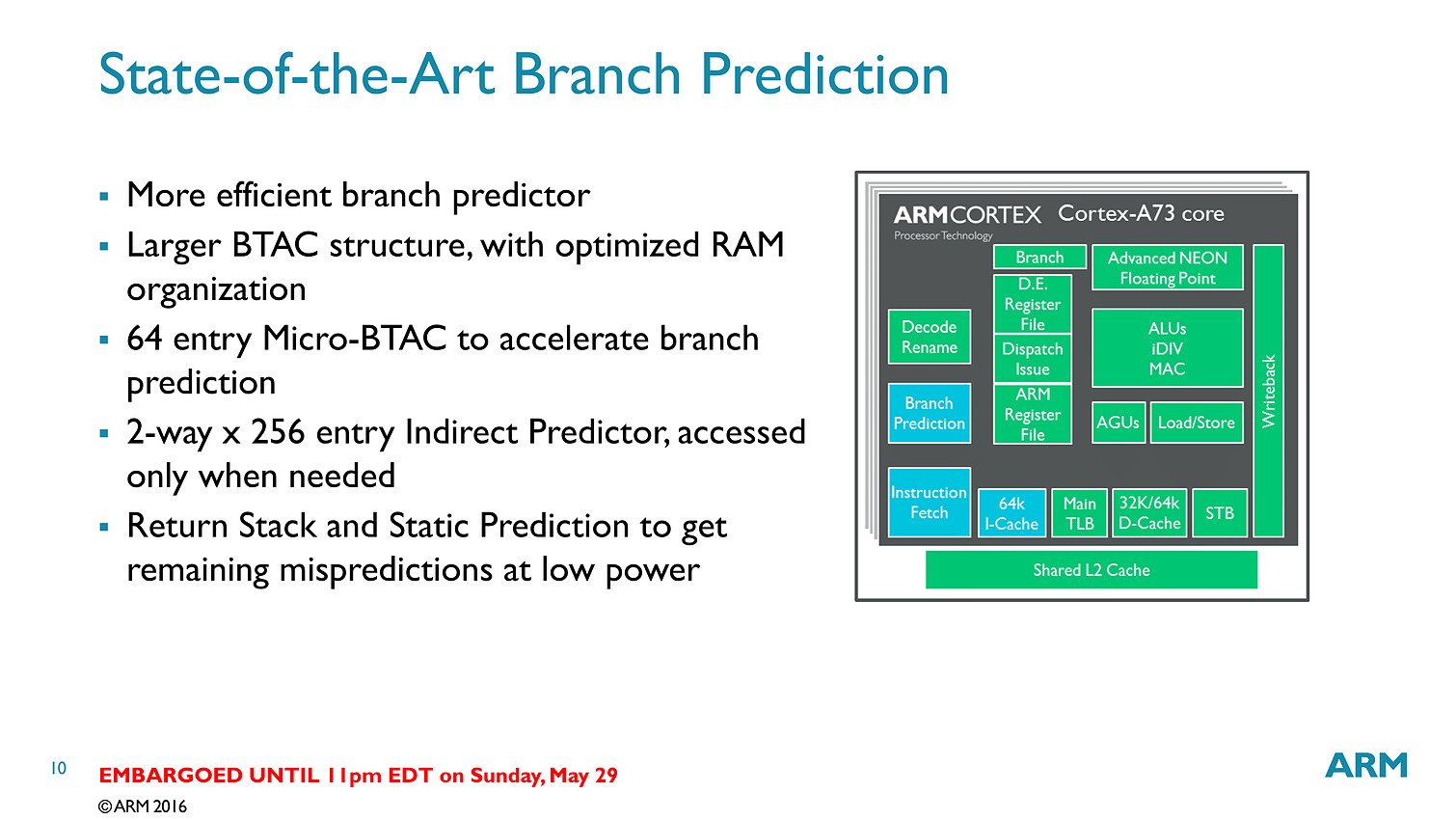


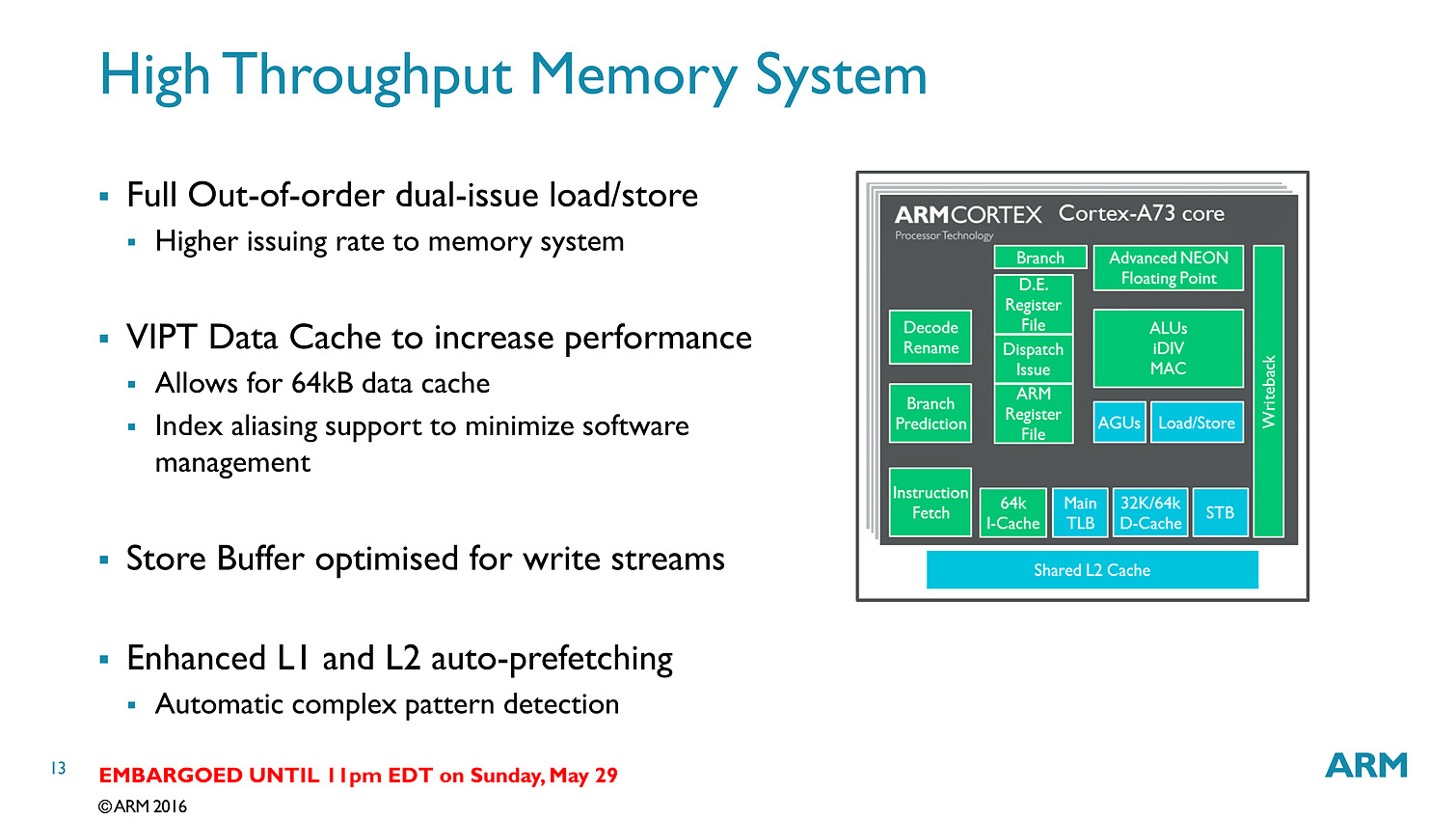
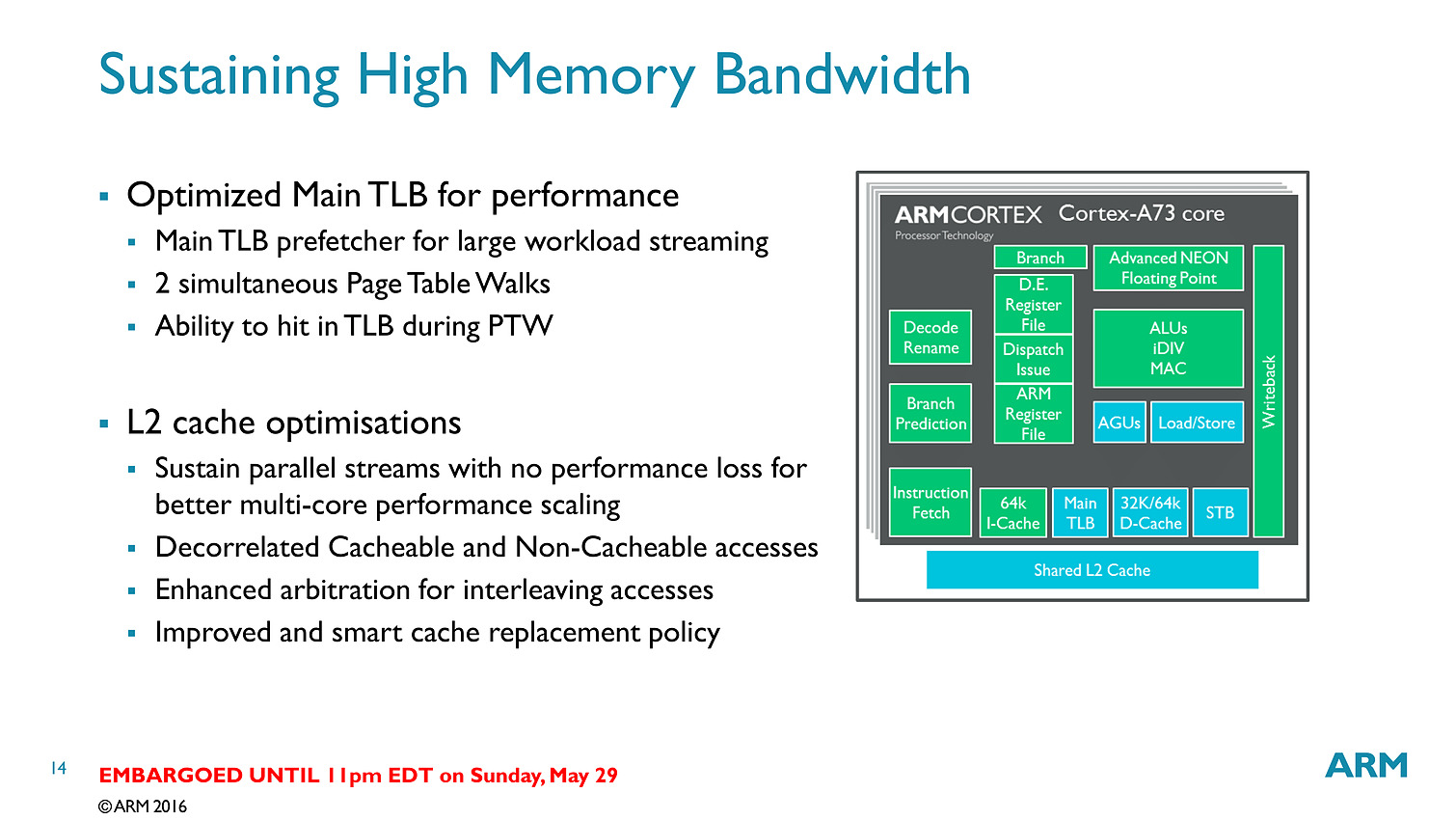
Bien que décodant une instruction par cycle en moins, l'A73 permet sur le papier au final de dispatcher 6 micro-instructions par cycle, contre 5 pour l'A72. Si l'on ajoute toutes les autres optimisations (le sous système mémoire, point faible historique des Cortex semble avoir évolué), l'A73 est annoncé comme 10% plus performant que l'A72, à fréquence/process égal.
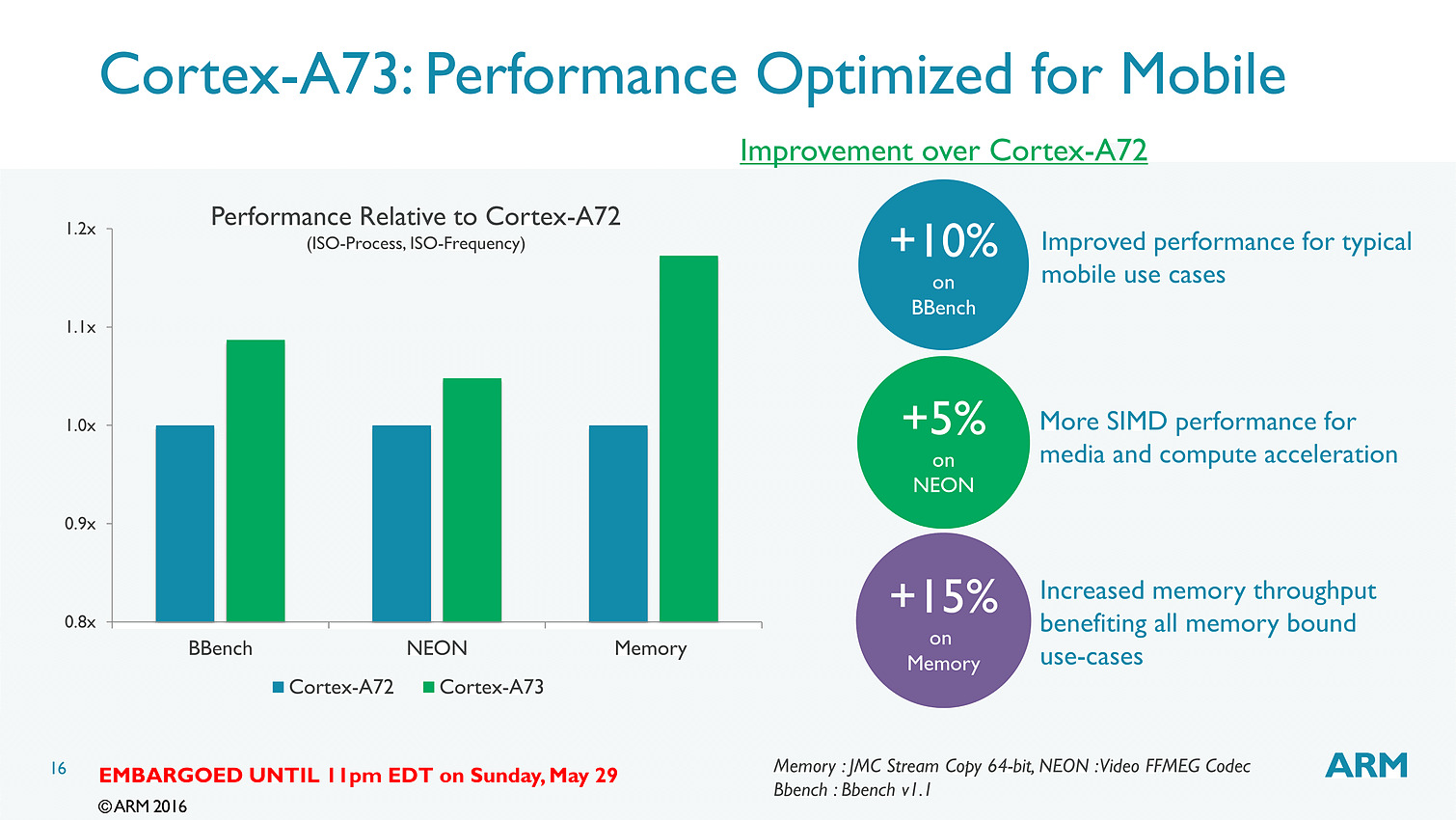
Dans le détail, ARM annonce plus spécifiquement 15% de gains sur les copies mémoire, et 5% sur un encodage FFMPEG utilisant les instructions vectorielles NEON. Notez qu'a process égal, un coeur A73 est 25% plus petit qu'un coeur A72 et consomme 20% d'énergie en moins. En 10nm, un coeur A73 ne mesure que 0.65mm2.
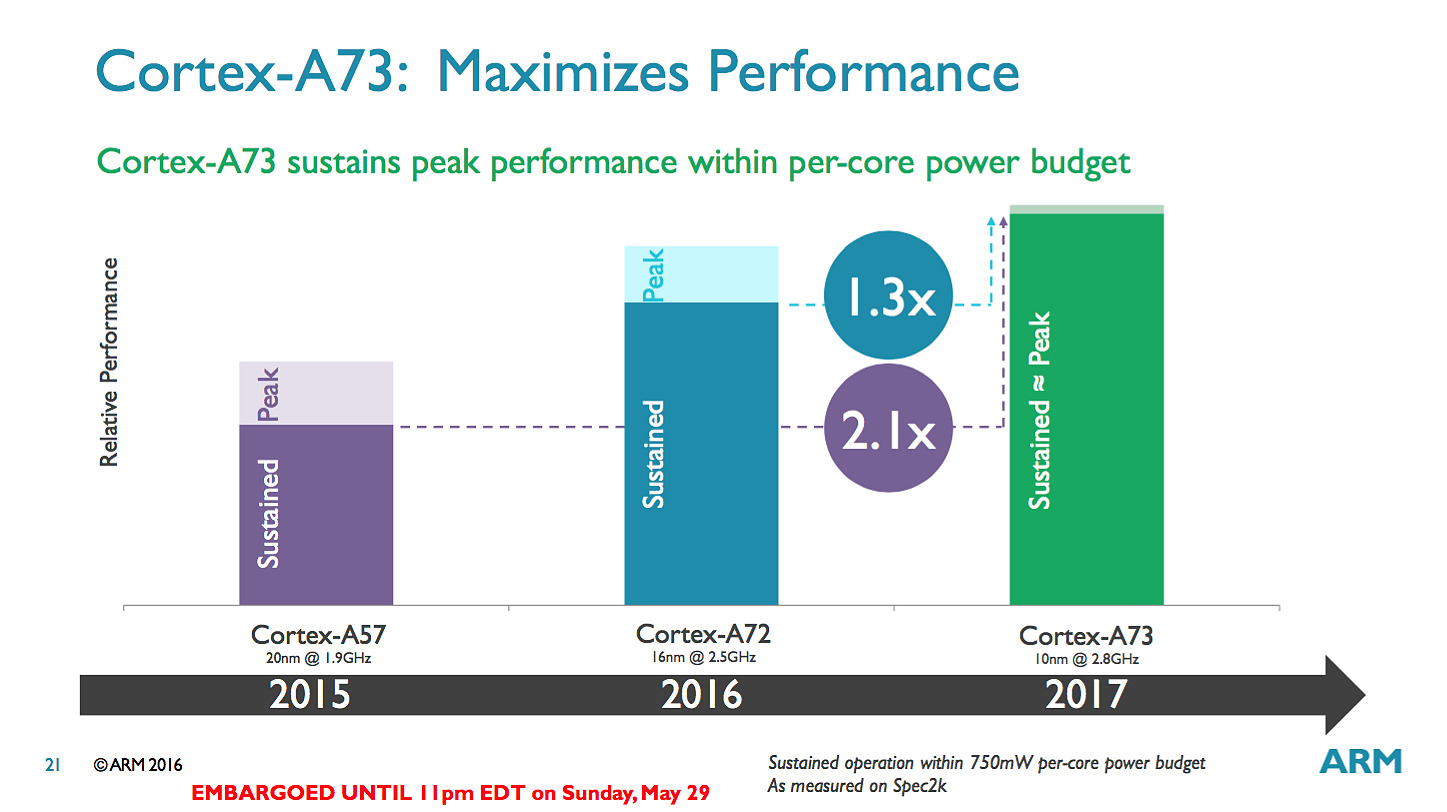
Pour les puces que l'on retrouvera dans le commerce, ARM annonce 30% de performances en plus par rapport aux A72 en profitant du 10nm et de la baisse de consommation pour augmenter la fréquence. Un autre gain significatif mis en avant par le constructeur est que ses puces ne devraient plus voir leur fréquence chuter drastiquement lorsque l'on utilise tous les coeurs en simultanée.
Sur le papier l'A73 est un meilleur compromis côté architecture que ses prédécesseurs, ce qui devrait ravir les partenaires d'ARM, assez peu heureux des A57. Si ARM vise le 10nm, en pratique il propose à ses partenaires des designs A73 en 28, 16 et 10nm. D'ici la fin de l'année, des SoC 16nm devraient faire leur apparition et c'est probablement là qu'on les trouvera en masse (le 10nm sera probablement, pour rappel, réservé au moins dans un premier temps aux gros acteurs du marché comme Qualcomm et Apple à l'image de ce que l'on avait vu avec le 20nm).
Mali-T71 et Bifrost
L'autre annonce d'ARM concerne les GPU. En plus de blocs CPU, ARM propose également à ses partenaires des blocs graphiques qu'ils peuvent utiliser ou non (d'autres sociétés comme Imagination Technologies proposent par exemple leur PowerVR) pour créer leurs SoC.
La nouvelle puce est baptisée T71 et vient faire suite aux GPU T800 dont nous vous avions parlé l'année dernière. Le changement de nomenclature annonce en réalité un changement d'architecture, on passe de l'architecture Midgard à la bien nommée Bifrost.
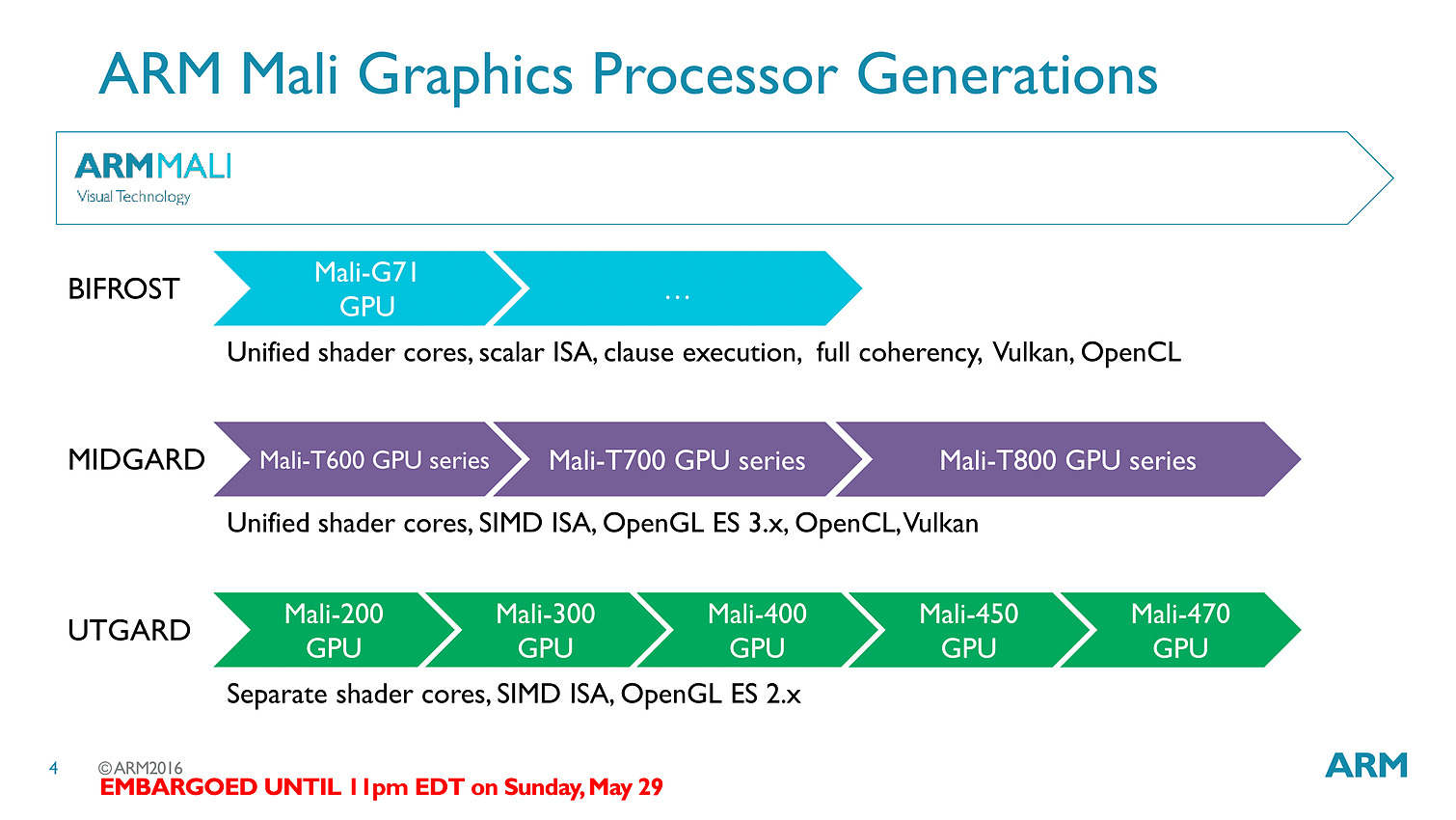
La transition est importante avec un changement complet de philosophie, passant d'un modèle VLIW (Very Long Instruction Word) à un modèle scalaire... soit exactement la transition qu'avait effectué AMD avec GCN !

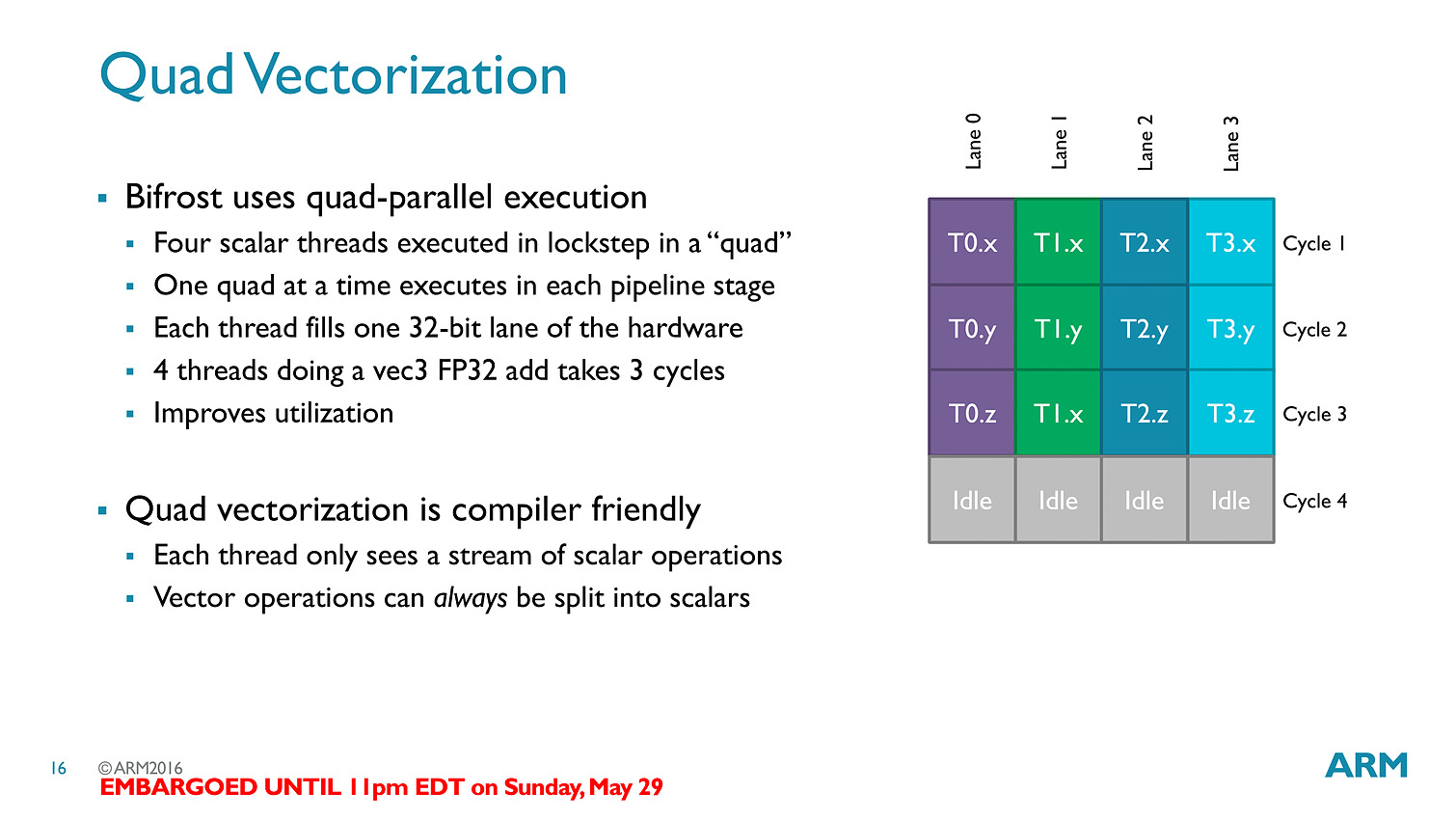
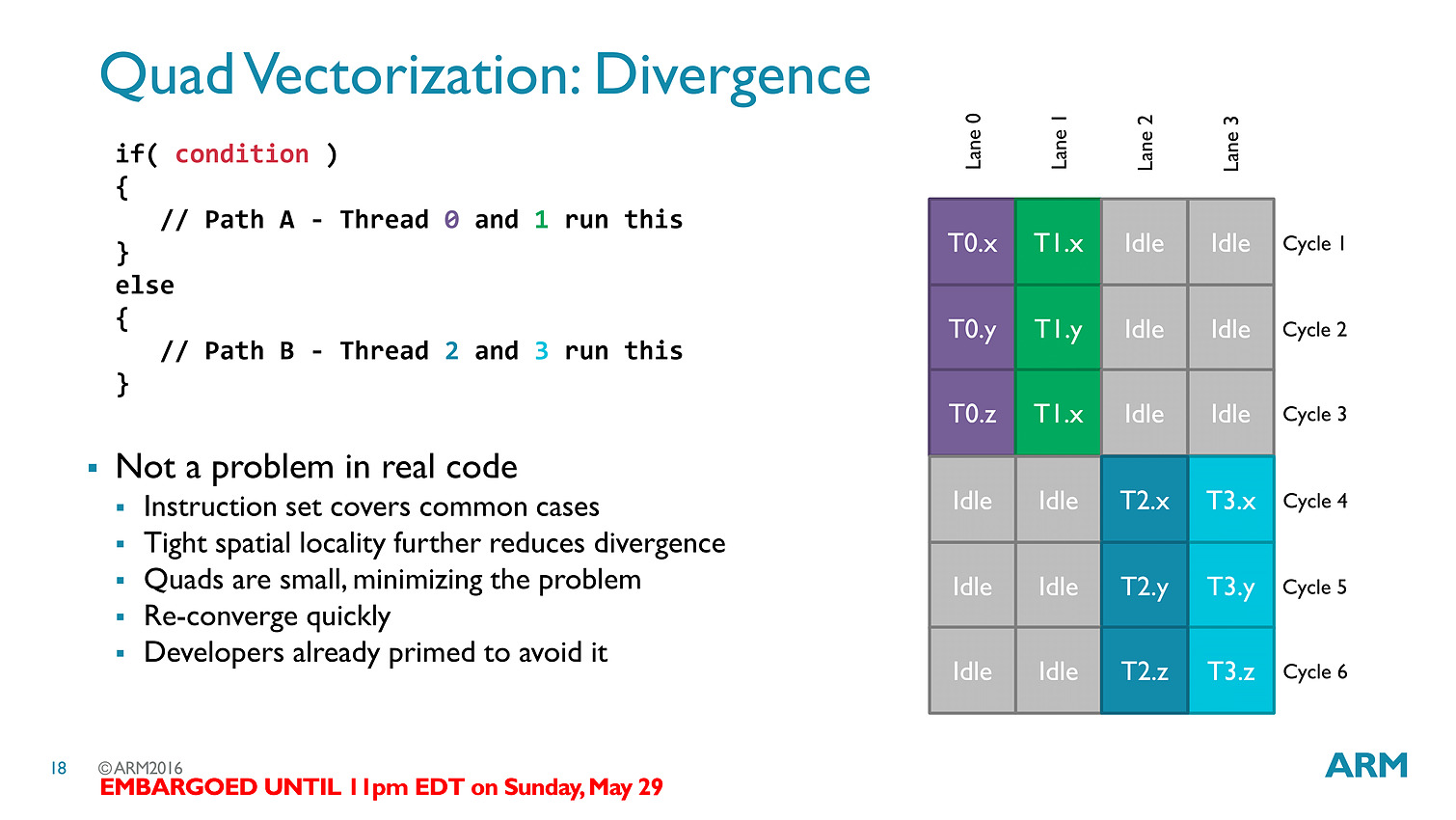
La transition aux unités scalaires change en pratique l'ordre dans lequel les données sont traitées, en simplifiant la compilation des shaders (le parallélisme étant extrait des threads, et non d'assemblage d'instructions par le compilateur).

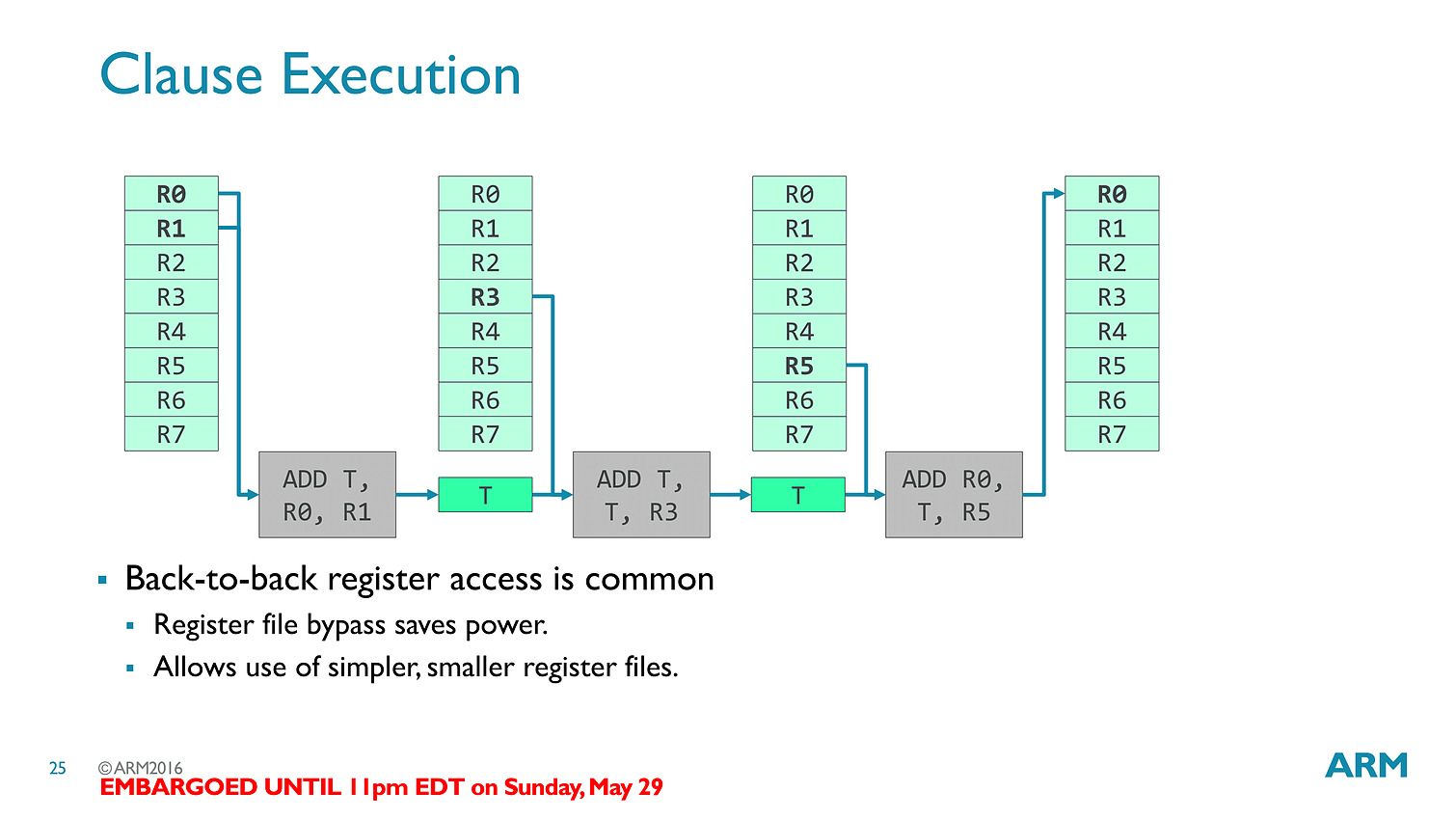

Les threads - clauses dans le langage ARM - sont particulièrement optimisées avec des caches a tous les niveaux (sous la forme de register file) pour s'assurer que les accès mémoires soient optimisés au mieux. Cumulé à tout les autres changements architecturaux (le tiler a également été modifié pour réduire sa consommation mémoire), ARM annonce 50% de gains de performances avec Bifrost.
En pratique le Mali-T71 est le premier GPU ARM utilisant Bifrost, il regroupera jusqu'à 32 shader cores (qui comptent chacun 12 unités scalaires) et reste compatible comme ses prédécesseurs avec OpenGL ES 3.x, OpenCL 2.0 et Vulkan. On rajoutera un dernier mot sur l'interconnexion puisque l'on a droit à un accès au cache fully coherent, ce qui signifie que CPU et GPU peuvent partager la même mémoire cache en opérant en parallèle sans blocage (à la manière de Kaveri chez AMD qui utilisait cependant deux bus distincts), ce qui pourra être utile pour des tâches compute ou l'on fait travailler de concert CPU et GPU (ce qui n'est pas forcément la majorité des usages sur les plateformes mobiles).
1er tape-out 10nm ARM chez TSMC
ARM vient d'annoncer qu'il avait effectué le tape-out d'un puce de test en 10nm chez TSMC. Cette puce intègre 4 coeurs Artemis, le successeur du Cortex-A72, utilisant l'architecture ARMv8-A mais un iGPU simplifié avec un seul coeur graphique. Le communiqué précise que le tape-out, c'est-à-dire l'envoi des informations chez TSMC pour graver la puce, a eu lieu au quatrième trimestre 2015.
ARM a précisé à AnandTech que le tape-out avait en fait eu lieu en décembre, mais que si la validation de la puce de test est un succès il est question d'un retour de la puce chez ARM dans les semaines à venir, soit un délai tout de même assez long.

[ 1 ] [ 2 ]
Du coup les chiffres annoncées, qui font état selon les cas de 11-12% de performances en plus pour une même consommation que le 16nm ou d'une consommation réduite de 30% pour les mêmes performances, sont en fait des simulations. Dans le même temps la densité du 10nm TSMC devrait être jusqu'à 2.1x plus importante que celle du 16nm.
Cette annonce fait suite à un partenariat datant d'octobre 2014 sur le 10nm. Pour rappel le début de la production en volume pour le 10nm chez TSMC est prévu pour 2017, mais à l'instar du 20nm une partie des clients attendront le node suivant (7nm) en 2018.
Accord de licence Nvidia-Samsung
 En 2013, Nvidia avait commencé à parler de proposer des licences pour ses technologies. Quelque chose que nous avions interprété, logiquement, en la volonté pour Nvidia de proposer des blocs d'IP pour les autres fabricants de SoC ARM. L'écosystème ARM fonctionne pour rappel sur un modèle ouvert, un designer de SoC comme Mediatek piochant dans le catalogue des différents acteurs, ARM proposant par exemple de nombreux cores CPU - les Cortex - mais aussi des GPU - les Mali - des interconnexions et des contrôleurs mémoires, tandis que d'autres comme Imagination Technologies proposent plus spécifiquement des GPU (les PowerVR). Le designer de SoC assemble ces blocs (payant les licences nécessaires), parfois avec des blocs d'IP propres pour terminer son design de puce, qui sera fabriqué chez un fondeur tiers comme TSMC par exemple.
En 2013, Nvidia avait commencé à parler de proposer des licences pour ses technologies. Quelque chose que nous avions interprété, logiquement, en la volonté pour Nvidia de proposer des blocs d'IP pour les autres fabricants de SoC ARM. L'écosystème ARM fonctionne pour rappel sur un modèle ouvert, un designer de SoC comme Mediatek piochant dans le catalogue des différents acteurs, ARM proposant par exemple de nombreux cores CPU - les Cortex - mais aussi des GPU - les Mali - des interconnexions et des contrôleurs mémoires, tandis que d'autres comme Imagination Technologies proposent plus spécifiquement des GPU (les PowerVR). Le designer de SoC assemble ces blocs (payant les licences nécessaires), parfois avec des blocs d'IP propres pour terminer son design de puce, qui sera fabriqué chez un fondeur tiers comme TSMC par exemple.
Nvidia proposait à l'époque ses SoC Tegra en accolant des blocs CPU développés par ARM à ses propres blocs GPU GeForce. Les dernières générations avaient cependant reçu un accueil frileux auprès des constructeurs de smartphones et de tablettes, le marché des SoC étant excessivement compétitif (Depuis, Nvidia s'est recentré en fabricant ses propres produits et en visant le marché automobile ou les contraintes de puissance, souvent pointés comme problématiques, sont moins importantes). Le nom officieux de la licence (« licence kepler ») semblait confirmer la volonté de Nvidia.
En coulisse cependant, Nvidia tentait de négocier un tout autre type d'accord auprès des constructeurs de SoC, souhaitant obtenir des royalties pour des brevets qu'ils jugeaient essentiels à la création de GPU, et qu'ils pensaient enfreints par leurs concurrents. Une stratégie lucrative dans le mobile lorsqu'elle réussit, on sait par exemple que Microsoft obtient de chaque constructeur de smartphone Android des royalties (un montant variable estimé à 3.41 dollars pour Samsung en 2013, et 5 dollars pour HTC ) pour certaines de ses technologies (comme le système de fichiers FAT32, plus de 310 brevets sont concernés d'après une liste ayant fuité en 2014 ).
Dans le cas de Nvidia, les négociations ont été infructueuses (et coûteuses, on notera par exemple qu'à compter de cette période, les GPU Nvidia ont complètement disparus des gammes Apple) qui ont culminé en septembre 2014 par un dépôt de plainte de Nvidia auprès de l'ITC (U.S. International Trade Commission). Cette plainte envers Samsung et Qualcomm demandait le retrait du marché américain de produits qui enfreignaient, selon Nvidia, leurs brevets.
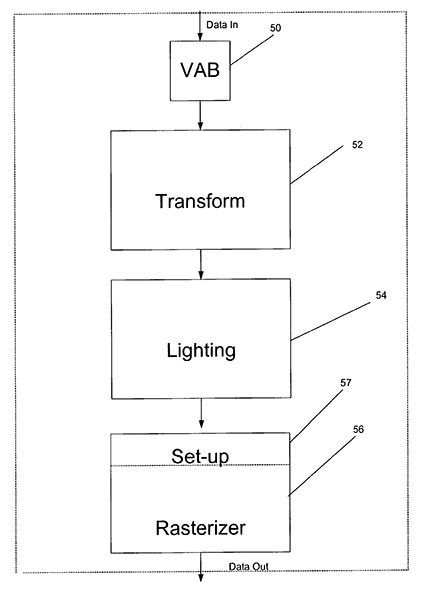
Un des brevets "essentiels" de Nvidia concernait le Transform&Lighting, une technologie ayant disparue des GPU modernes
En octobre 2015, l'ITC avait statué de manière défavorable sur la plainte de Nvidia, un jugement que nous vous avions relaté en détail dans cet article. Le résultat de ce jugement avait été entériné définitivement en décembre : ni Samsung, ni Qualcomm, n'enfreignaient les brevets de Nvidia.
Bien que Samsung et Qualcomm étaient directement visés (parce qu'ils produisent les SoC et que ces derniers étaient visés par l'interdiction d'importation), techniquement ce sont les GPU ARM (Mali), Imagination Technologies (PowerVR) et Adreno (Qualcomm) qui enfreignaient potentiellement les brevets. Ce jugement empêche donc toute procédure du type de la part de Nvidia contre d'autres fabricants de SoC qui utiliseraient ces mêmes coeurs graphiques.
Conséquences coûteuses
En parallèle, Samsung avait bien évidemment contre attaqué Nvidia (et l'un de ses clients, Velocity Micro) auprès de l'ITC (la plainte est ici ). En décembre dernier, nos confrères de Bloomberg rapportaient que l'ITC avait jugé en première instance que trois brevets de Samsung avaient été enfreints par Nvidia.
Un jugement définitif était attendu hier, pouvant entraîner dans la foulée une interdiction d'importation aux états unis de produits Nvidia. Cependant, comme le relate une fois de plus Bloomberg , quelques heures avant l'annonce définitive de l'ITC, Nvidia et Samsung ont annoncé un accord croisé de licence mettant un terme à leurs différentes procédures. Le communiqué est particulièrement avare en détails, indiquant simplement qu'il se limite à quelques brevets (il ne s'agit pas d'un accord de licence croisé « large ») et qu'il n'y aurait pas eu de compensation additionnelle (comprendre financière) en contrepartie. Etant donné la position de faiblesse de Nvidia au moment de la négociation, on imagine que d'autres concessions ont été faites, mais ces dernières resteront, d'après le communiqué, secrètes.
Il était bien évidemment dans l'intérêt de Nvidia d'éviter un retrait du marché de ses produits. La plainte originale visait spécifiquement les tablettes Nvidia Shield, même si Samsung avait étendu le cadre de sa plainte à Biostar et ECS (on ne sait pas exactement pour quels produits). Nvidia va également pouvoir tourner la page de cette stratégie de « licence kepler » mal pensée dès l'origine.
Pour Samsung, dont le département légal est rôdé, la normalisation des relations entre les deux sociétés sera une bonne chose, d'autant que Nvidia semble travailler avec Samsung Foundries pour produire certaines de ses puces, quelque chose qui avait été noté dans un document administratif l'année dernière. Bien évidemment, Samsung Foundries a longtemps produit des puces pour Apple tout en entretenant des relations légales hautement conflictuelles, même si là aussi, ces deux dernières années, les deux sociétés ont progressivement normalisé leurs relations .
AMD lance ses Opteron A1100 en ARM
Annoncé en octobre 2012, l'arrivée d'Opteron à base d'ARM chez AMD devait se faire en 2014. Après le lancement d'un kit de développement début 2014, ce n'est finalement qu'en ce mois de janvier 2016 qu'AMD lance les Opteron A1100 dans leur version définitive.
Trois références de ces SoC gravés en 28nm sont annoncées :
-A1170, 8 curs à 2.0 GHz, 4 Mo L2 + 8 Mo L3, DDR3-1600/DDR4-1866, 32w
-A1150, 8 curs à 1.7 GHz, 4 Mo L2 + 8 Mo L3, DDR3-1600/DDR4-1866, 32w
-A1120, 4 curs à 1.7 GHz, 2 Mo L2 + 8 Mo L3, DDR3-1600/DDR4-1866, 25w
Les curs ARM sont pour rappel de type Cortex-A57 64-bit. Côté fonctionnalité le contrôleur mémoire dispose de deux canaux et peut gérer jusqu'à 32 Go (4x8 Go) de DDR3 avec des dies de 4 Gb, 64 Go (8x8 Go) en DDR4 avec des die de 8 Gb et même 128 Go (4x32 Go) si on passe en RDIMM. Le SoC gère en sus 8 lignes PCIe Gen3, pas moins de 14 ports SATA 3.0 et deux réseaux 10 Gigabit. L'USB n'est pas de la partie et devra être confié à une puce externe.
Il est question d'environ 150$ pour l'A1170, soit un tarif proche de l'Atom C2730 d'Intel et ses 8 curs x86 Silvermont à 1.7-2.4 GHz qui devrait a priori avoir des performances assez proches mais dont le TDP est de 12w. L'intérêt de ces Opteron ARM ne se situera donc a priori pas du côté du rapport performance/prix ou performance/watt mais plutôt côté fonctionnalité, l'Atom étant limité officiellement à 32 Go (a priori 64 Go en pratique), ne disposant que d'une interface Gigabit et que de 6 SATA dont 2 SATA 3.0.
Pour gérer 128 Go de mémoire et deux interfaces 10 Gigabit il faut chez Intel passer au Pentium D1517 (4C/8T 1.6-2.2 GHz, 25W et 194$) ou au Xeon D1520 (4C/8T 2.2-2.6 GHz, 45W et 199$) qui sont autrement plus performants en calcul puisque basés sur Broadwell, gèrent 32 lignes PCIe (24 en 3.0 et 8 en 2.0) mais restent limité comme l'Atom à 6 SATA (tous 3.0 cette fois).
C'est donc avec pas mal de retard et un positionnement assez complexe que les premiers Opteron ARM arrivent. Il faut dire que la mise en place de l'écosystème ARM côté serveur a mis du temps, avec notamment le support logiciel de l'APCI ou du PCIe. Pas de quoi faire trembler Intel et son x86 pour le moment mais ça ne saurait tarder ! Gageons en effet que tout ce qu'AMD a appris et mis en place lui servira pour le lancement de la prochaine génération d'Opteron ARM utilisant des curs K12 (intégration "custom" d'ARMv8). Initialement prévu pour 2016, ce lancement ne devrait se faire qu'en 2017 et il faut espérer que cette-fois AMD n'aura pas de retard puisqu'en sus de la concurrence d'Intel il ne devrait plus être seul sur le marché serveur en ARM, puisque d'autres puces notamment chez Qualcomm sont prévues.












