
Les derniers contenus liés aux tags Nvidia et ARM
Afficher sous forme de : Titre | FluxGTC: CUDA on ARM: Tegra 3 + Tesla K20
GTC: CUDA on ARM: Kayla, Tegra 3 et GK208
GTC: Le futur de Tegra: CUDA, Logan, Parker
Focus: Nvidia Tegra 4 et 4i : tout savoir de leur architecture
Focus: Nvidia Tegra 3: plus de cores, moins de watts ?

Hot Chips : M1, SVE, Parker, InFo et Skylake !



La conférence Hot Chips qui se tenait la semaine dernière a donné lieu a d'autres annonces intéressantes que nous avons essayé de regrouper dans cette actualité !
Rajouter des tiers de mémoire côté serveur
On avait déjà noté un peu plus tôt la volonté de rajouter de la mémoire HBM à divers endroits, et même la volonté de Samsung de travailler sur une version moins onéreuse, mais l'on rajoutera ce slide issu d'une présentation d'AMD qui rappelle les objectifs de la société côté serveurs, prenant pour le coup l'exemple du big data
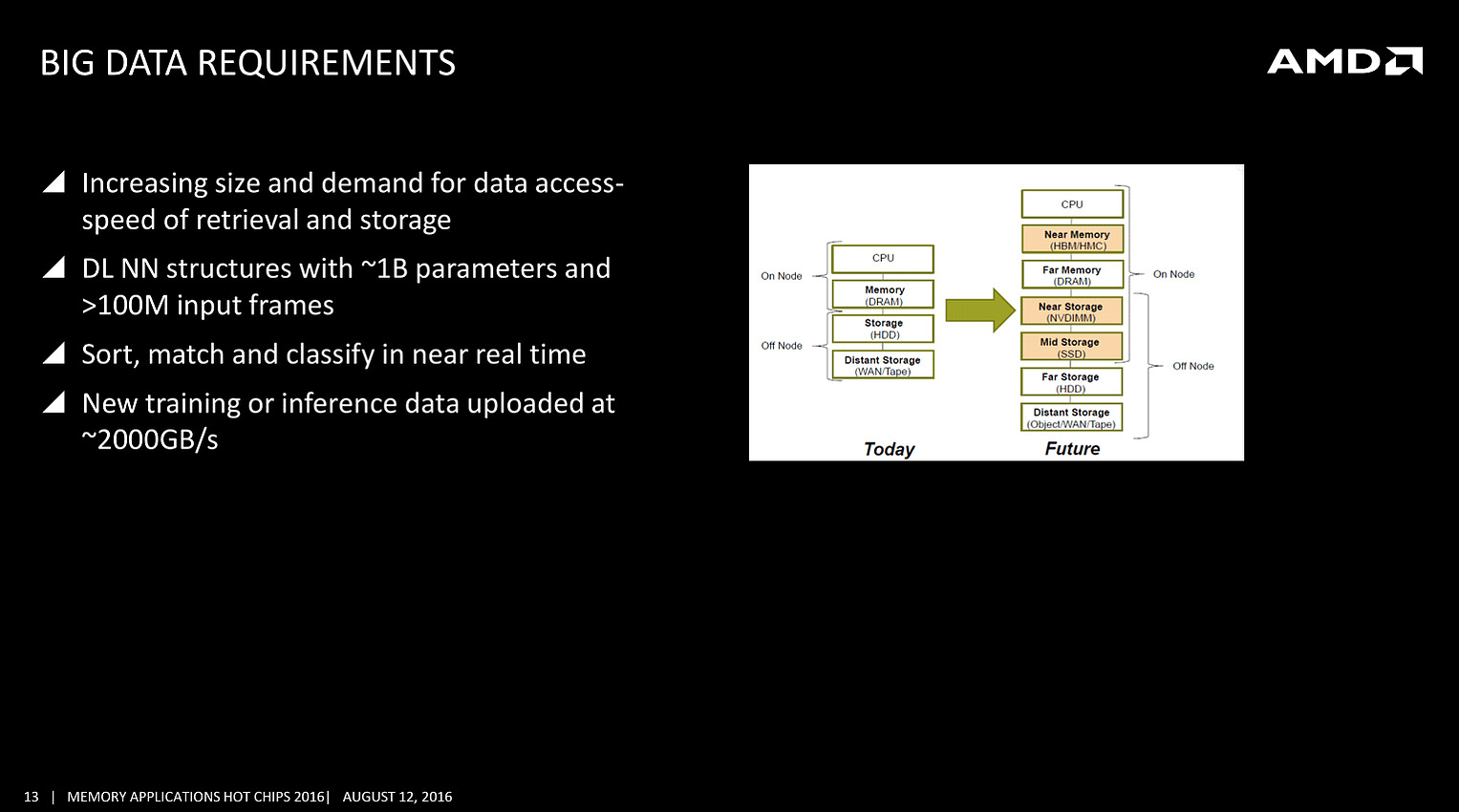
On s'attardera sur le graphique à droite qui pointe l'ajout d'une mémoire intermédiaire côté CPU, type HBM ou HMC (AMD misera plutôt sur la HBM pour les déclinaisons serveurs de Zen), et aussi l'utilisation de NVDIMM pour s'intercaler avant un SSD. Il faudra attendre encore un peu pour voir comment seront déclinées ces technologies, mais il est intéressant de noter la manière dont les avancées côté mémoire sont mises en avant, parfois un peu trop tôt comme l'a fait Intel avec 3D XPoint, dans toute l'industrie.
Quelques détails de plus sur SVE
Chez ARM, outre une présentation de Bifrost côté GPU dont on vous avait déjà parlé, l'annonce principale concernait SVE, la nouvelle extension vectorielle introduite par la société.
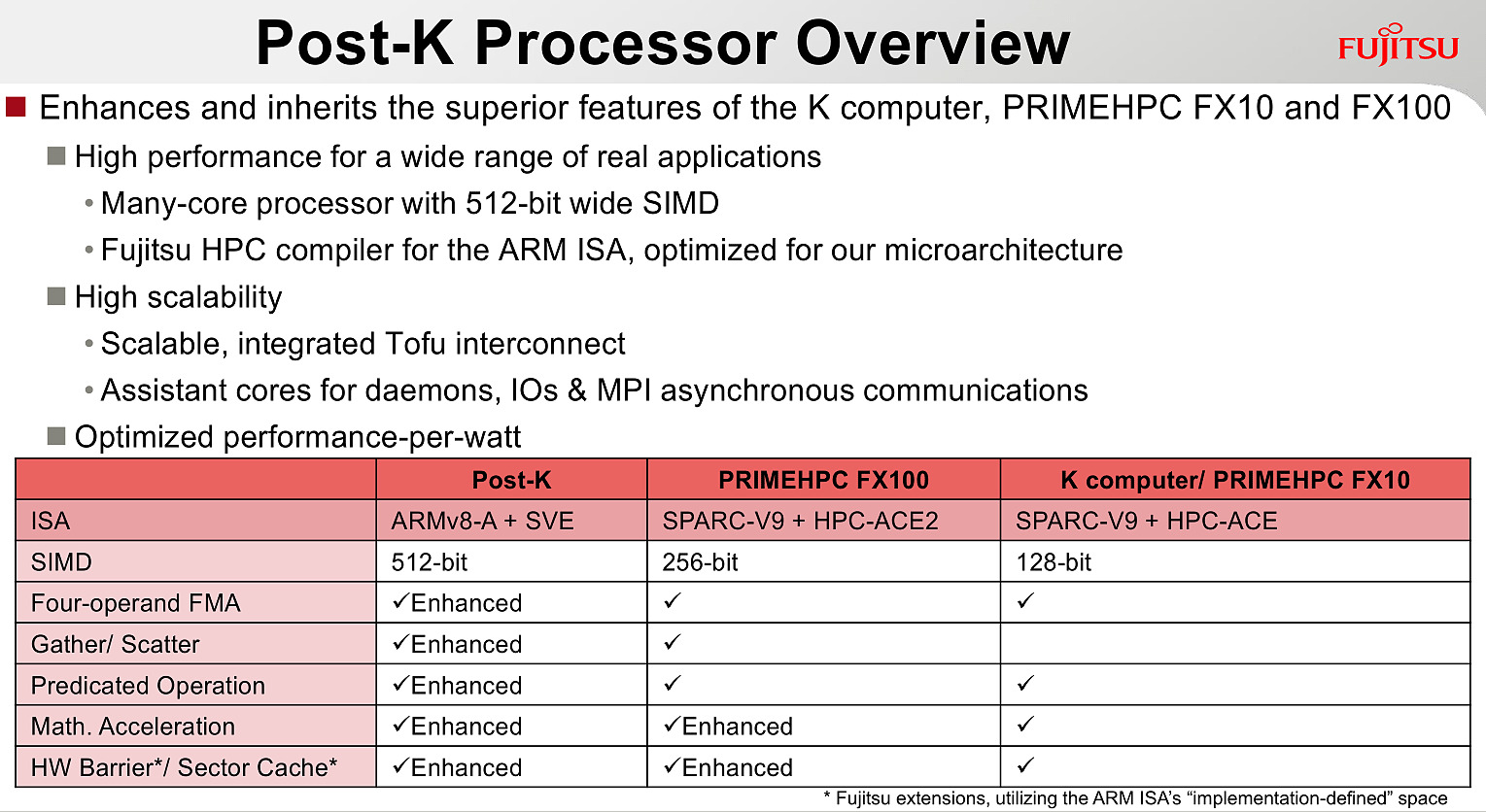
Le premier partenaire annoncé par ARM est Fujitsu, qui mettra au point des processeurs ARMv8 avec extension SVE pour le futur supercalculateur japonais Post-K. Fujitsu a donné quelques détails, indiquant par exemple que les unités vectorielles auraient une largeur de 512 bits sur ses puces.


Chez ARM, le constructeur présente plusieurs benchmarks assez théoriques, on notera surtout sur les barres grises les améliorations qui ont été effectuées côté auto-vectorisation, c'est a dire la capacité du compilateur à utiliser des instructions vectorielles pour extraire du parallélisme. ARM devrait proposer dans les semaines qui viennent des patchs pour les différents compilateurs open source, incluant LLVM et GCC.
Le Samsung M1, un timide premier pas
La particularité de l'écosystème d'ARM est que les partenaires peuvent soit utiliser des coeurs "clefs en main", développés par ARM (les gammes Cortex, comme par exemple le Cortex A57), ou créer leurs propres implémentations de l'architecture ARM (qui restent compatibles, tout en étant différentes, à l'image des processeurs d'AMD et d'Intel qui diffèrent bien que restant compatibles). Plusieurs sociétés disposent de licences "architecture" qui permettent de créer ces puces, Apple étant jusqu'ici la société la plus à la pointe sur armv8 même si de nombreuses sociétés proposent tour à tour leurs architectures.

Parmi les nouveaux venus, il y a Samsung qui s'est lancé lui aussi dans le design d'une architecture armv8 custom pour ses Exynos M1. A la tête du projet, on retrouve Brad Burgess qui était architecte chez AMD pour les Bobcat. Il aura même été rejoint un court instant par Jim Keller (K8 chez AMD, A7 chez Apple, puis Zen chez AMD), qui n'est cependant pas resté très longtemps chez Samsung et qui n'aura probablement pas eu un grand impact. Le projet aura nécessité trois années, et en soit arriver a produire quoique ce soit du premier coup en un temps si court est un exploit.
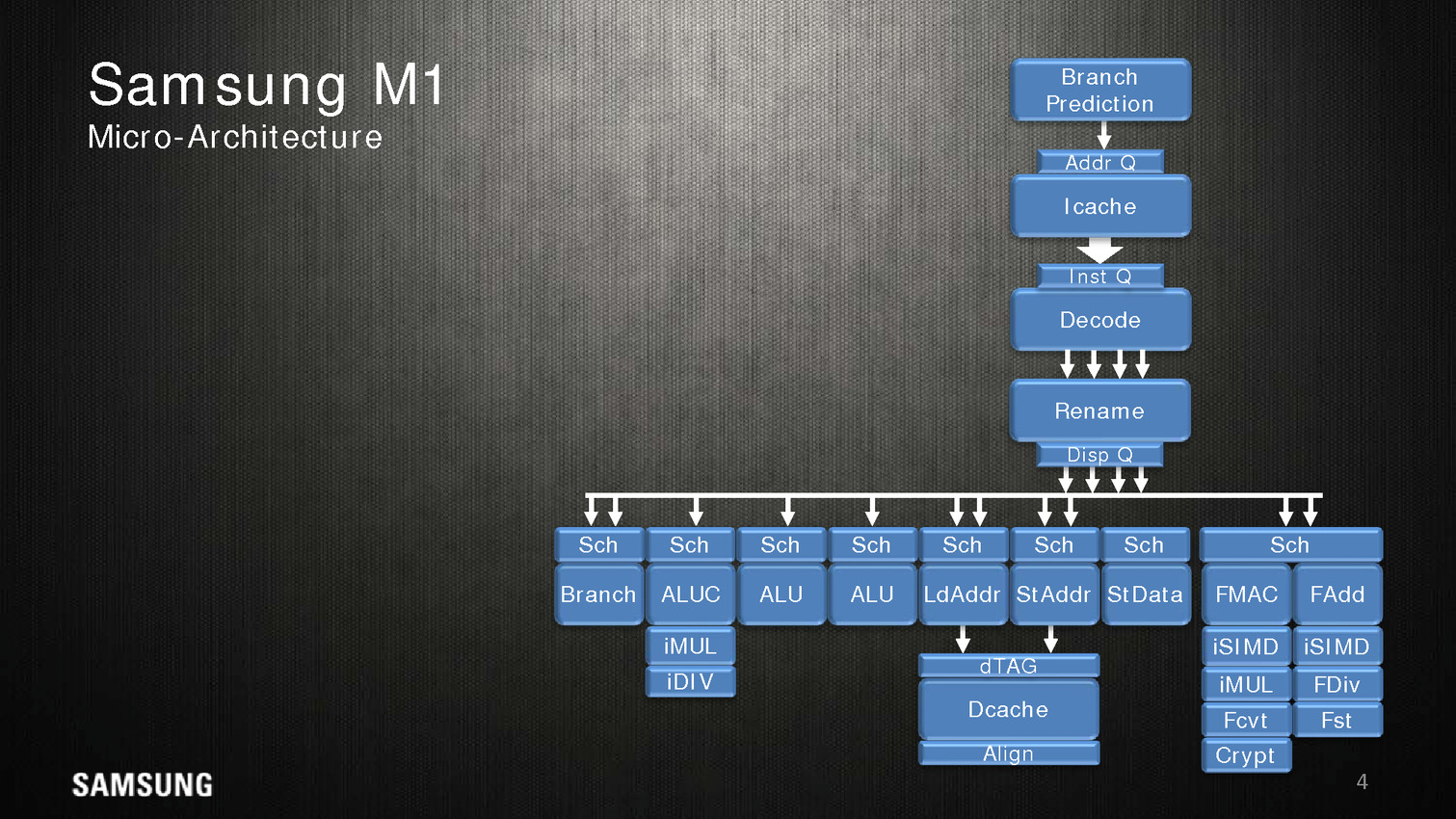
Côté architecture, Samsung indique utiliser un perceptron (un réseau de neurones simple) au niveau de ses mécanismes de prédiction de branches. Deux branches sont considérées par cycle, mais il est difficile d'estimer quoique ce soit sur l'éventuelle efficacité.
Quatre instructions peuvent être décodées/dispatchées par cycle aux unités d'exécutions qui sont regroupées sur sept files. On note deux files dédiées aux écritures mémoires, trois aux opérations mathématiques simple (avec un port sur lequel sont ajoutés les multiplications/divisions) et une aux branchements. Les opérations en virgules flottantes sont regroupées séparément avec un scheduler unique pour deux files. Samsung annonce 5 cycles pour effectuer une opération FMA.
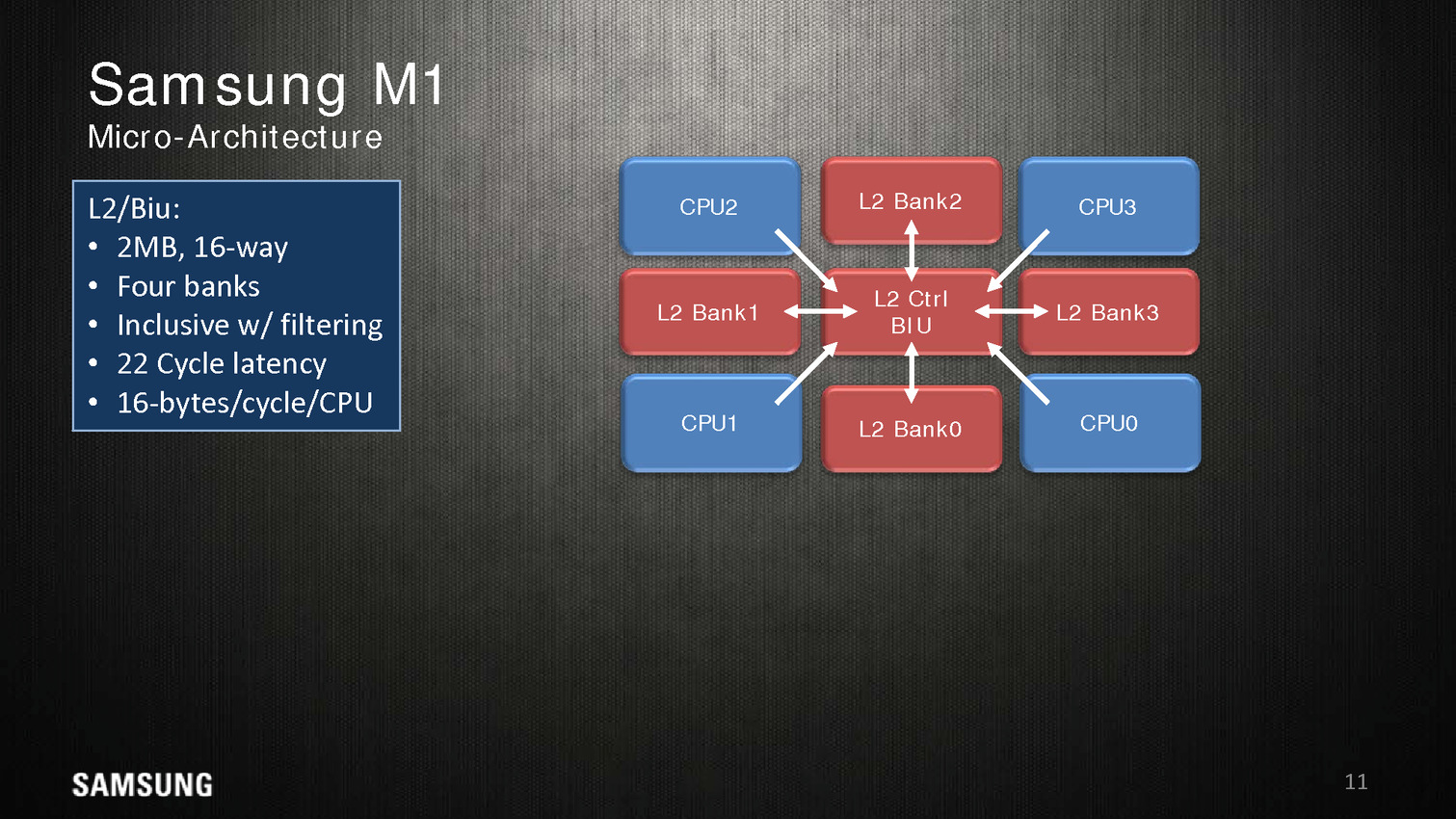
Dans une configuration quatre coeurs, le M1 dispose de 2 Mo de cache L2 coupé en quatre blocs, les coeurs accèdent au L2 via une interface commune. On appréciera aussi les schémas très spécifiques que propose Samsung, pas vraiment avare de détails techniques.

Reste qu'en pratique, les benchmarks mis en avant par Samsung ne sont pas forcément très convaincants. Avec 200 MHz de plus, sur un coeur, un M1 propose 10% de performances en plus qu'un Cortex A57 à consommation égale, ce qui est tout de même très peu. Samsung fait beaucoup mieux sur les opérations mémoires (c'est relativement facile, on l'a évoqué de nombreuses fois, les contrôleurs mémoires ARM ne sont pas particulièrement véloces/adaptés aux hautes performances), mais n'en tire pas particulièrement profit hors des benchmarks théoriques.
La présentation se termine en indiquant que ce n'est qu'un premier pas pour Samsung et que d'autres designs sont en cours d'élaboration. En soit si les performances ne vont pas révolutionner le monde des SoC ARM, Samsung a au moins une base de travail qu'ils pourront faire évoluer par la suite. A condition évidemment que Samsung continue d'investir sur le sujet dans les années à venir !
Les curieux pourront retrouver la présentation en intégralité ci dessous :














Parker/Denver 2 : design asymétrique
Nvidia était également présent à Hot Chips, donnant quelques détails sur son futur SoC baptisé Parker. Ce dernier est annoncé comme crée spécifiquement pour le marché automobile avec des fonctionnalités dédiées à ce marché. On ne sait pas si le constructeur le déclinera en d'autres versions plus génériques.

Les détails techniques ne sont pas particulièrement nombreux, on notera côté SoC que l'encodage 4K est désormais accéléré à 60 FPS, que l'on peut contrôler jusque trois écrans en simultanée, et que le contrôleur mémoire passe sur 128 bits (contre 64 précédemment). Côté GPU, Parker utilisera une version dérivée de son architecture Pascal.



C'est du côté CPU que les choses sont les plus originales, après avoir utilisé son architecture Denver sur les TK1, puis être revenu aux Cortex A57 sur les TX1, Nvidia propose une architecture asymétrique avec deux coeurs "Denver 2" (sur lesquels aucun détail n'aura été donné, à part un gain performance/watts de 30% donné sans précision sur les process comparés) et quatre coeurs Cortex A57. Ce n'est pas la première fois que l'on voit des configurations originales, durant Hot Chips, le taiwannais MediaTek présentait un SoC 10 coeurs avec quatre coeurs Cortex A53 à 1.4 GHz, quatre coeurs Cortex A53 à 2 GHz, et deux coeurs Cortex A72 à 2.5 GHz !
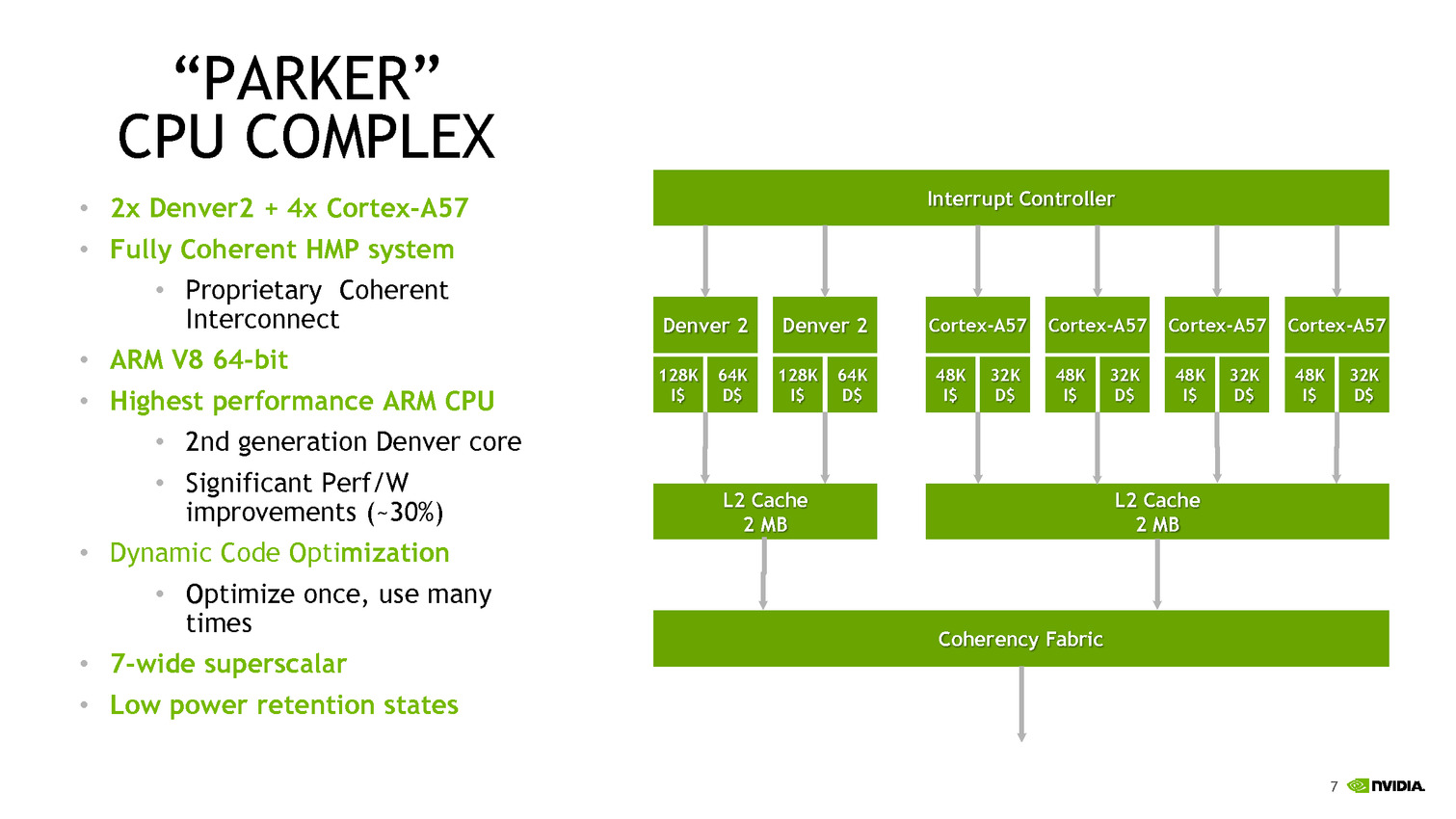
Dans le cas de MediaTek, l'idée est de proposer différentes options à différents niveaux de consommation. Pour ce qui est de Nvidia, le choix est différent, le Cortex A57 étant "haute performance" contrairement aux A53 de MediaTek. Il faut dire surtout que le marché visé, l'automobile, n'a pas les mêmes contraintes de consommation que le marché mobile. Reste que Nvidia se doit de gérer cette asymétrie avec un scheduler qui doit décider sur quel coeur placer les threads, ce qui n'est pas particulièrement simple. On notera que chaque groupe de coeurs dispose de son propre cache L2 de 2 Mo.
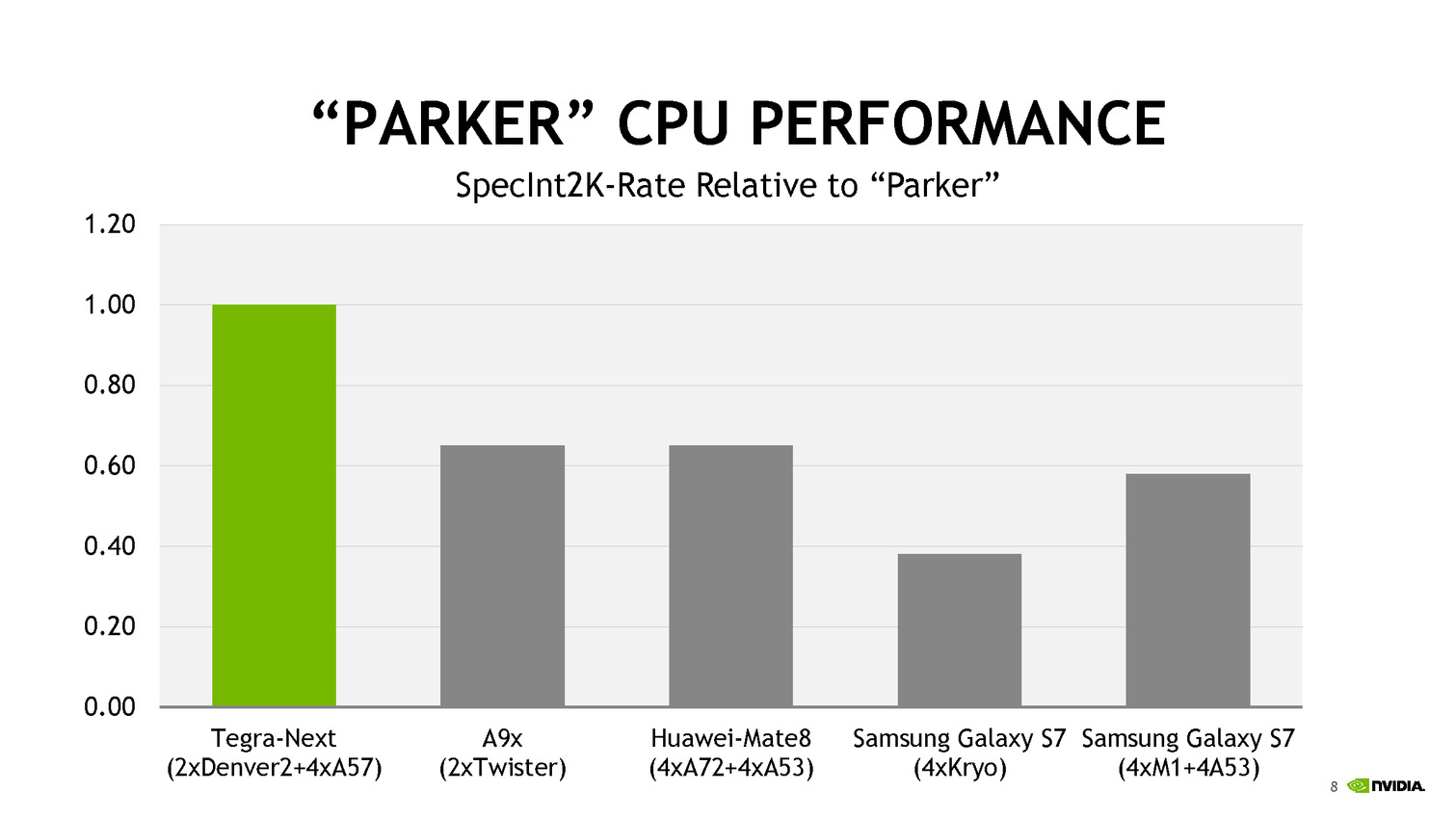
Côté performances, Nvidia avec ses 6 coeurs se présente comme moitié plus rapide qu'un A9X d'Apple en deux coeurs. Le graphique mélangeant des puces à TDP différents (on y retrouve des puces pour smartphones et pour tablettes), on admettra que la comparaison n'est pas faite à TDP identique.
TSMC parle de ses packages InFo
Une des nouveautés présentées cette année par TSMC est la disponibilité d'un nouveau type de packaging, l'InFo-WLP. L'idée est de permettre de relier plusieurs dies en les "moulant" dans un substrat commun très fin qui contient également les interconnexions entre les puces. Il s'agit d'une version à cout beaucoup plus faible que les interposer (utilisés par exemple par AMD pour Fiji).
La présentation de TSMC est dédiée aux interconnexions entre les puces, et présente une puce 16nm reliant un SOC à une puce mémoire avec une bande passante de 89.6 Go/s sur 256 bits, le tout avec une consommation très réduite.
En plus de la solution présentée qui évoque le cas simple d'une puce mémoire et d'un Soc, TSMC évoque la solution comme permettant un jour de relier également plusieurs dies de logique, par exemple des groupes de coeurs séparés, pour réduire le coût de fabrication des puces (qui augmentent exponentiellement avec la taille des dies).
































La présentation est technique mais reste intéressante, l'InFo-WLP ouvre des opportunités supplémentaires pour réaliser des produits qui mélangent processeur et mémoire. Le coût réduit et la finesse de l'interconnexion fait qu'on pourrait retrouver assez rapidement cette technique utilisée, y compris sur le marché mobile. Les prochains SoC d'Apple pourraient par exemple utiliser un tel package.
Et Skylake !
Juste avant la présentation de Zen, Intel proposait aussi une présentation de son architecture Skylake, lancée l'année dernière. Si la majorité du contenu est déjà connu, on aura noté un détail intéressant : un diagramme sur les unités d'exécution de Skylake. On rappellera que l'année dernière durant l'IDF, Intel nous avait promis plus de détails sur le sujet, sans jamais nous les donner !
Pour rappel, voici la répartition sur Haswell :
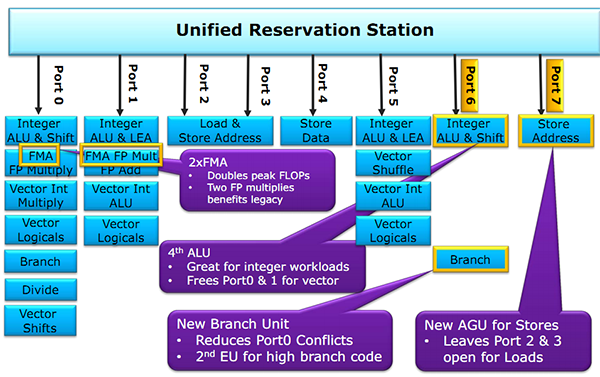
Récapitulatif des ports/unités d'exécution sur Haswell
Un an après, voici enfin un diagramme similaire pour Skylake :
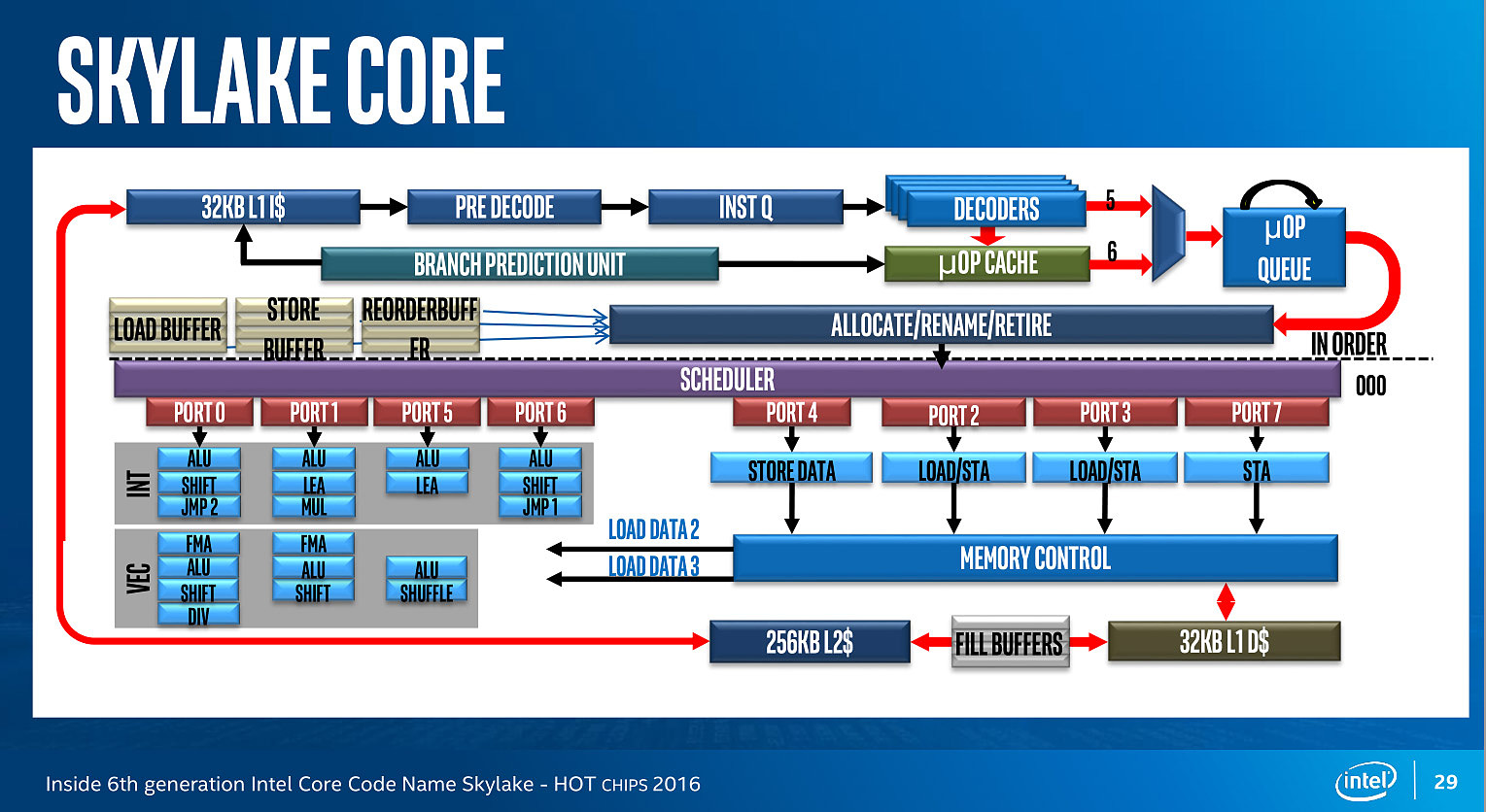
Conformément à ce que nous avaient indiqué les ingénieurs d'Intel l'année dernière, le nombre d'unité a bel et bien augmenté. Le nombre de ports reste constant, à 8, mais l'on compte... une nouvelle unité. Sur le port 1, Intel a en effet ajouté une unité de shift vectorielle. Pour le reste, la répartition reste similaire à celle d'Haswell. Un mystère enfin élucidé !
Accord de licence Nvidia-Samsung
 En 2013, Nvidia avait commencé à parler de proposer des licences pour ses technologies. Quelque chose que nous avions interprété, logiquement, en la volonté pour Nvidia de proposer des blocs d'IP pour les autres fabricants de SoC ARM. L'écosystème ARM fonctionne pour rappel sur un modèle ouvert, un designer de SoC comme Mediatek piochant dans le catalogue des différents acteurs, ARM proposant par exemple de nombreux cores CPU - les Cortex - mais aussi des GPU - les Mali - des interconnexions et des contrôleurs mémoires, tandis que d'autres comme Imagination Technologies proposent plus spécifiquement des GPU (les PowerVR). Le designer de SoC assemble ces blocs (payant les licences nécessaires), parfois avec des blocs d'IP propres pour terminer son design de puce, qui sera fabriqué chez un fondeur tiers comme TSMC par exemple.
En 2013, Nvidia avait commencé à parler de proposer des licences pour ses technologies. Quelque chose que nous avions interprété, logiquement, en la volonté pour Nvidia de proposer des blocs d'IP pour les autres fabricants de SoC ARM. L'écosystème ARM fonctionne pour rappel sur un modèle ouvert, un designer de SoC comme Mediatek piochant dans le catalogue des différents acteurs, ARM proposant par exemple de nombreux cores CPU - les Cortex - mais aussi des GPU - les Mali - des interconnexions et des contrôleurs mémoires, tandis que d'autres comme Imagination Technologies proposent plus spécifiquement des GPU (les PowerVR). Le designer de SoC assemble ces blocs (payant les licences nécessaires), parfois avec des blocs d'IP propres pour terminer son design de puce, qui sera fabriqué chez un fondeur tiers comme TSMC par exemple.
Nvidia proposait à l'époque ses SoC Tegra en accolant des blocs CPU développés par ARM à ses propres blocs GPU GeForce. Les dernières générations avaient cependant reçu un accueil frileux auprès des constructeurs de smartphones et de tablettes, le marché des SoC étant excessivement compétitif (Depuis, Nvidia s'est recentré en fabricant ses propres produits et en visant le marché automobile ou les contraintes de puissance, souvent pointés comme problématiques, sont moins importantes). Le nom officieux de la licence (« licence kepler ») semblait confirmer la volonté de Nvidia.
En coulisse cependant, Nvidia tentait de négocier un tout autre type d'accord auprès des constructeurs de SoC, souhaitant obtenir des royalties pour des brevets qu'ils jugeaient essentiels à la création de GPU, et qu'ils pensaient enfreints par leurs concurrents. Une stratégie lucrative dans le mobile lorsqu'elle réussit, on sait par exemple que Microsoft obtient de chaque constructeur de smartphone Android des royalties (un montant variable estimé à 3.41 dollars pour Samsung en 2013, et 5 dollars pour HTC ) pour certaines de ses technologies (comme le système de fichiers FAT32, plus de 310 brevets sont concernés d'après une liste ayant fuité en 2014 ).
Dans le cas de Nvidia, les négociations ont été infructueuses (et coûteuses, on notera par exemple qu'à compter de cette période, les GPU Nvidia ont complètement disparus des gammes Apple) qui ont culminé en septembre 2014 par un dépôt de plainte de Nvidia auprès de l'ITC (U.S. International Trade Commission). Cette plainte envers Samsung et Qualcomm demandait le retrait du marché américain de produits qui enfreignaient, selon Nvidia, leurs brevets.
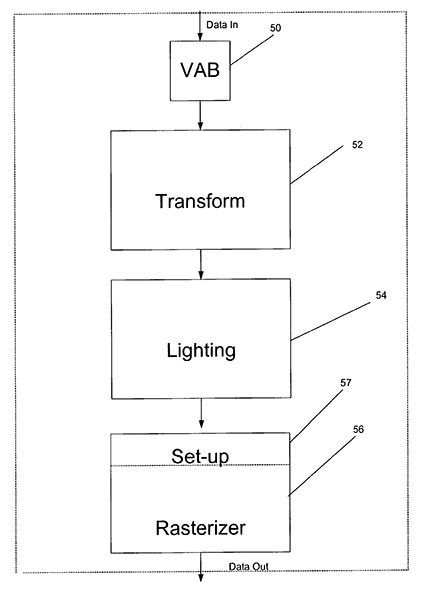
Un des brevets "essentiels" de Nvidia concernait le Transform&Lighting, une technologie ayant disparue des GPU modernes
En octobre 2015, l'ITC avait statué de manière défavorable sur la plainte de Nvidia, un jugement que nous vous avions relaté en détail dans cet article. Le résultat de ce jugement avait été entériné définitivement en décembre : ni Samsung, ni Qualcomm, n'enfreignaient les brevets de Nvidia.
Bien que Samsung et Qualcomm étaient directement visés (parce qu'ils produisent les SoC et que ces derniers étaient visés par l'interdiction d'importation), techniquement ce sont les GPU ARM (Mali), Imagination Technologies (PowerVR) et Adreno (Qualcomm) qui enfreignaient potentiellement les brevets. Ce jugement empêche donc toute procédure du type de la part de Nvidia contre d'autres fabricants de SoC qui utiliseraient ces mêmes coeurs graphiques.
Conséquences coûteuses
En parallèle, Samsung avait bien évidemment contre attaqué Nvidia (et l'un de ses clients, Velocity Micro) auprès de l'ITC (la plainte est ici ). En décembre dernier, nos confrères de Bloomberg rapportaient que l'ITC avait jugé en première instance que trois brevets de Samsung avaient été enfreints par Nvidia.
Un jugement définitif était attendu hier, pouvant entraîner dans la foulée une interdiction d'importation aux états unis de produits Nvidia. Cependant, comme le relate une fois de plus Bloomberg , quelques heures avant l'annonce définitive de l'ITC, Nvidia et Samsung ont annoncé un accord croisé de licence mettant un terme à leurs différentes procédures. Le communiqué est particulièrement avare en détails, indiquant simplement qu'il se limite à quelques brevets (il ne s'agit pas d'un accord de licence croisé « large ») et qu'il n'y aurait pas eu de compensation additionnelle (comprendre financière) en contrepartie. Etant donné la position de faiblesse de Nvidia au moment de la négociation, on imagine que d'autres concessions ont été faites, mais ces dernières resteront, d'après le communiqué, secrètes.
Il était bien évidemment dans l'intérêt de Nvidia d'éviter un retrait du marché de ses produits. La plainte originale visait spécifiquement les tablettes Nvidia Shield, même si Samsung avait étendu le cadre de sa plainte à Biostar et ECS (on ne sait pas exactement pour quels produits). Nvidia va également pouvoir tourner la page de cette stratégie de « licence kepler » mal pensée dès l'origine.
Pour Samsung, dont le département légal est rôdé, la normalisation des relations entre les deux sociétés sera une bonne chose, d'autant que Nvidia semble travailler avec Samsung Foundries pour produire certaines de ses puces, quelque chose qui avait été noté dans un document administratif l'année dernière. Bien évidemment, Samsung Foundries a longtemps produit des puces pour Apple tout en entretenant des relations légales hautement conflictuelles, même si là aussi, ces deux dernières années, les deux sociétés ont progressivement normalisé leurs relations .
CES: Nvidia Tegra X1: Maxwell + Cortex A57/53
Comme chaque année, Nvidia profite du CES de Las Vegas pour dévoiler un nouveau SoC. Pour cette édition 2015, c'est le Tegra X1 qui est mis en avant. Au menu, le passage au 20nm, un GPU Maxwell de seconde génération optimisé pour le monde mobile et un ensemble de curs Cortex-A57 et A53 pour former le CPU.

Après les Tegra K1 32-bits et 64-bits, Nvidia passera dans le courant de 2015 au Tegra X1, connu précédemment sous le nom de code Erista. Une évolution qui était attendue mais qui réserve quelques surprises, notamment au niveau de sa partie CPU qui ne fait pas appel aux curs ARMv8 maison (nom de code Denver) exploités dans le Tegra K1 64-bits. A la place, Nvidia reprend, comme Qualcomm et Samsung, les curs ARM 64-bits "standards", des Cortex-A57 et des Cortex-A53.
Des curs ARM 64-bits standards en 20nmNvidia explique ce choix par le fait que le développement du Tegra K1 64-bits et du Tegra X1 s'est fait en parallèle en visant des procédés de fabrication différents. Il n'aurait ainsi pas été possible de profiter de l'expérience du développement du premier avec les curs Denver pour mettre au point le second. Dans ce sens il faut voir le Tegra X1 comme le successeur du Tegra K1 32-bits alors qu'une variante équipée des curs Denver sera dévoilée plus tard (Parker ?).
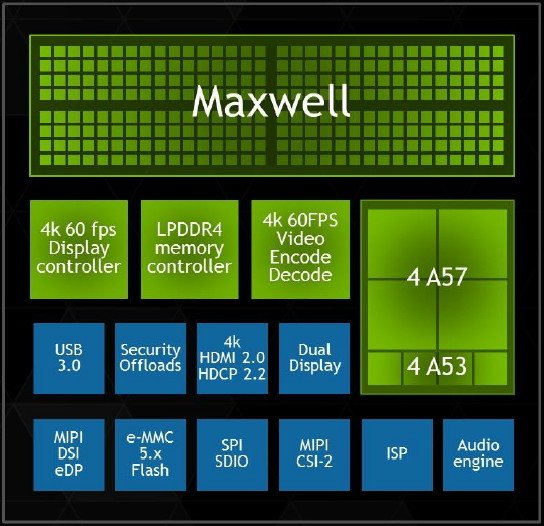
Cette approche permet à Nvidia de réduire les risques lors du passage au 20 nanomètres puisque, en amont, ARM s'est assuré de proposer un design adapté à cette technologie du fondeur TSMC. Pour son implémentation, Nvidia a d'ailleurs abandonné l'approche 4+1 des précédents Tegra qui consistait à associer un unique cur optimisé basse consommation à un ensemble de 4 curs similaires mais orientés performances. L'an passé, Nvidia nous expliquait que ce mode 4+1 était beaucoup plus efficace que ce que faisait la concurrence qui avait opté pour une approche 4+4 mais avec 2 types de curs différents.
Changement de discours cette année, probablement parce que Nvidia n'a pas eu le choix, l'implémentation proposée par ARM a été optimisée pour du 4+4. Nvidia a donc opté pour 4 Cortex-A57 (en version cache L1 I/D de 48/32 Ko) associés à 4 Cortex-A53 (avec cache L1 I/D de 32/32 Ko). Contrairement à ce que le marketing essayera de vous vendre, cela n'en fait cependant pas un SoC octocore. Le Tegra X1 reste un SoC quadcore puisque ces 2 groupes de curs ne peuvent en aucun cas être exploités simultanément. Au repos ou à très faible charge CPU, les Cortex-A53 sont exploités et dès qu'une charge CPU plus lourde est initiée, ils passent au repos et les Cortex-A57 entrent en action.
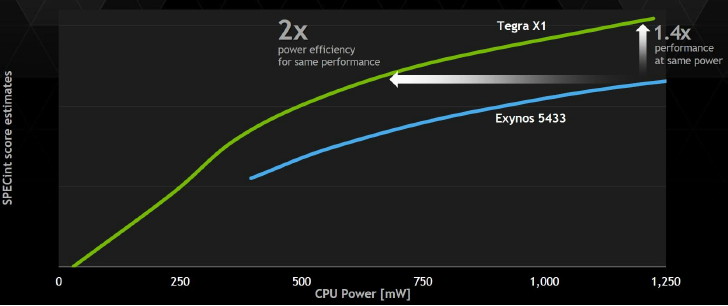
Nvidia indique que son implémentation est cependant plus efficace sur le plan énergétique que celle d'autres fabricants, notamment Samsung, qui ont fait un choix similaire. Il est question d'une réduction de moitié de la consommation à performances égales et d'un gain de performances de 40% à consommation égale. Nvidia explique cela d'une part par l'expérience acquise lors du design de puces 4+1 qui lui a donné une bonne maîtrise de l'exploitation des possibilités des process de TSMC pour intégrer sur une même puce deux ensembles de curs CPU au profil énergétique très différent. D'autre part, Nvidia exploite sa propre interconnexion, moins gourmande que celle proposée par ARM (CCI-400).
Au niveau du sous-système mémoire, l'ensemble de Cortex-A57 profite d'un cache L2 de 2 Mo, comme les précédents Tegra, alors que les Cortex-A53 se contentent de 512 Ko. Le bus mémoire reste large de 64-bit mais passe de la LPDDR3-1866 (au départ il était question de LPDDR3-2133 mais Nvidia n'en parle plus) à la LPDDR4-3200 (jusqu'à 4 Go) pour offrir un gain de bande passante de 70%. De quoi permettre notamment d'alimenter le GPU plus musclé.
Un GPU Maxwell de seconde génération avec support du FP16Rappelons que là où Kepler avait été portée dans le monde Tegra alors que Nvidia était déjà très avancé dans le développement de cette architecture, Maxwell est la première qui a été pensée dès le départ pour le monde mobile. Ce qui participe au fait que Nvidia ait fait un effort supplémentaire au niveau de son efficacité énergétique. Alors que de nombreux fabricants de SoC ont opté pour les mêmes curs CPU que ceux exploités par le Tegra X1, le GPU est bien entendu l'élément principal qui permet à Nvidia de se démarquer.
Le Tegra X1 fait ainsi appel à un GPU Maxwell de seconde génération, le GM20B, similaire au GM204 qui équipe les GeForce GTX 980 et GTX 970, mais bien entendu équipé de moins d'unités de calcul. Vous pourrez retrouver les détails à son sujet dans le dossier que nous avions consacré à ces cartes graphiques et à l'architecture Maxwell.
Là où le GM204 desktop embarque 16 blocs de 128 unités de calculs, appelés SMM, le GM20A s'en contente de 2. Le nombre d'unités de calcul principal passe donc de 2048 à 256, soit 1/8ème de la puissance de calcul du GPU le plus performant du moment, ce qui reste impressionnant pour un petit SoC. A noter que les Tegra K1 se contentaient d'un seul SMX, mais de 192 unités de calcul. Cependant sur cet ensemble, seules 128 unités était exploitables efficacement et les 64 supplémentaires n'offraient qu'un gain minime. En passant à 2 SMM avec le Tegra X1 et à une fréquence légèrement supérieure, Nvidia n'est pas loin de doubler la puissance de calcul pratique de son GPU.
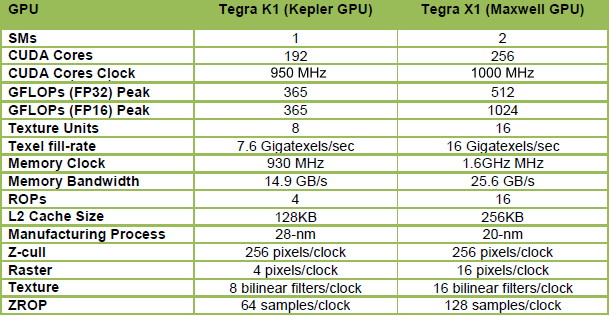
Mais ce n'est pas tout. Les 256 unités de calcul du Tegra X1 évoluent pour supporter de nouvelles instructions qui vont pouvoir doubler la puissance de calcul dans certains cas. Ces instructions sont des opérations FP16 vectorielles pour les FMA, les multiplications et les additions. De plus faible précision, le format de calcul FP16 est suffisant pour bien des usages, notamment pour les jeux mobiles, et alors que la concurrence y a massivement recours pour booster les performances et l'efficacité énergétique, il était devenu inévitable pour Nvidia d'en profiter également.
Pour les GPU Nvidia précédents, aucune précision inférieure au FP32 n'est supportée directement par les unités de calcul. Si celles-ci doivent traiter une opération basse précision en FP16, elles doivent donc les traiter comme des opérations FP32 avec un débit identique et uniquement quelques petites optimisations mineures.
Pour le Tegra X1, l'ajout d'instructions vec2 permet à chaque unité de calcul FP32 de traiter deux opérations FP16 simultanément et donc de doubler le débit. Ces unités restent alimentées par des registres 32-bits classiques dans lesquels sont placées deux valeurs 16-bits. Une implémentation basique qui implique une modification mineure de l'architecture mais qui transpose tout le travail de l'exploitation du FP16 au compilateur qui devra faire en sorte de trouver des opérations vec2 dans le code et parvenir à optimiser l'utilisation du fichier registres entre les valeurs FP32 et FP16.
Cela permet de doubler la puissance de calcul théorique, qui atteint 1 TFlops à 1 GHz, mais en pratique le taux d'utilisation sera rarement optimal. Ceci étant dit il s'agit dans tous les cas d'un gain performances appréciable qui profitera notamment aux jeux mobiles friands de FP16.
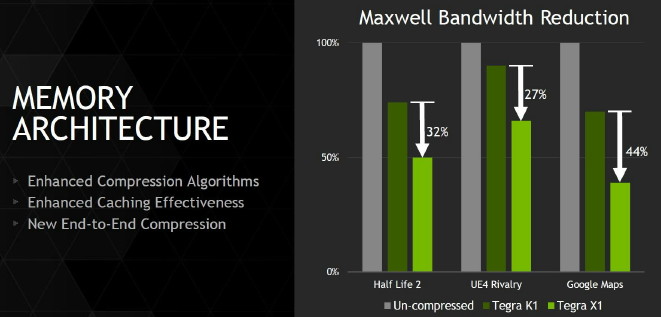
Nvidia a également implémenté la dernière itération de sa technologie de compression des couleurs, et plus spécifiquement du codage différentiel. Son principe de base consiste à ne pas enregistrer directement les couleurs mais leur différence par rapport à une autre qui fait office de repère. Suivant les spécificités de chaque scène, cette technique de compression sans perte permet d'économiser une part significative de la bande passante mémoire, ce qui profite aux performances.
L'ensemble de la chaine d'affichage supporte ces méthodes de compression, ce qui permet de réduire la bande passante à tous les niveaux, jusqu'au moteur d'affichage qui ne décompresse qu'au moment de l'envoi vers l'interface de l'écran. Le cache L2 passe par ailleurs de 128 à 256 Ko, de quoi également d'éviter certains accès à la mémoire centrale. Au final, les techniques de cache et de compressions sans perte permettent par exemple de réduire la bande passante nécessaire de moitié dans Half-Life avec un gain de 30% par rapport au Tegra K1 qui était pourtant déjà plutôt efficace de ce côté.
Pour le reste, toutes les technologies supportées par les gros GPU de bureau le sont par le Tegra X1 : Direct3D 12, OpenGL ES 3.1, AEP, OpenGL 4.5, CUDA 6.0, MFAA, VXGI
4K et 60 HzLe moteur vidéo, cette fois spécifique au SoC Tegra, a été lui aussi revu pour le X1. Nvidia s'est particulièrement penché sur le support de la 4K, qui lui permettra de se différencier par rapport à la concurrence sur un autre plan que la 3D. Tout le pipeline vidéo a ainsi été optimisé pour la lecture du contenu 4K à 60 fps, qui devrait être proposé notamment par le service de streaming de Netflix même s'il faut bien avouer que cela ne concernera qu'une minorité de vidéos et d'utilisateurs.
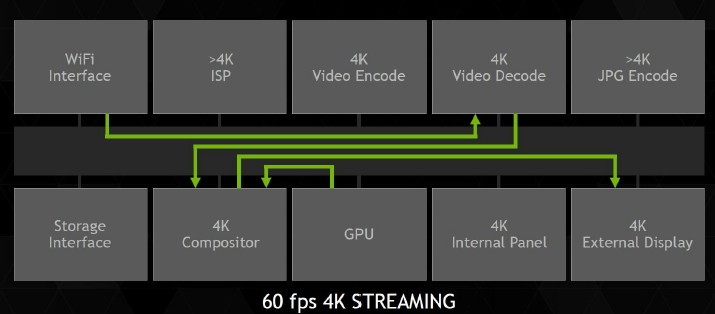
Cela passe bien entendu par un moteur de décodage 100% matériel. Il supporte la 4K à 60 fps en H.264, en H.265 (HEVC) ainsi qu'en VP9, avec un débit maximal non précisé. La profondeur des couleurs de 10-bit est également supportée en H.265 en 4K et 60 fps. Au niveau de l'encodage, Nvidia se "contente" par contre de la 4K à 30 fps en H.264 et H.265 et du 1080 à 60 Hz en VP8.
Deux écrans peuvent être supportés par le moteur d'affichage, compatible HDMI 2.0 et HDCP 2.2. Il supporte par ailleurs la technologie DSC de VESA qui permet de transmettre une image compressée à l'écran.
Le support de l'Adaptive Sync qui permettrait d'améliorer la fluidité dans le monde mobile de manière standardisée n'est par contre pas au menu. A cette question, Nvidia répond par son attachement à G-Sync accompagné d'un traditionnel "wait & see", de quoi nous laisser penser que cette technique d'affichage, ou un dérivé, pourrait être supporté sur le Tegra X1.
L'efficacité énergétique en démoPour mettre en avant les capacités de son SoC, Nvidia avait préparé quelques démos basées sur une plateforme de développement. Celle-ci est relativement compacte et se contente d'un dissipateur en aluminium relativement fin, censé représenter les capacités de refroidissement d'une tablette.


Quel est le TDP de ce SoC Tegra X1 ? Question délicate à laquelle il est toujours difficile d'obtenir une réponse directe. Pour ses démos, Nvidia parle d'environ 5W, mais lors de la présentation globale réalisée par son CEO, il était plutôt mentionné 10W.





Comme à son habitude, Nvidia exploite des comparaisons "isoperf" (à performances égales) pour mettre en avant l'efficacité énergétique de ses futurs SoC face aux solutions actuelles déjà sur le marché. Des données qui ont selon nous un intérêt limité puisque cette approche consiste à réduire drastiquement les fréquences et tensions du SoC le plus performant. Un calcul du rendement énergétique sur base des conditions d'utilisation réelles des puces est plus pertinent, mais cela ne permet pas d'aller chercher le fameux 2x, un must pour mettre en avant les nouveautés.
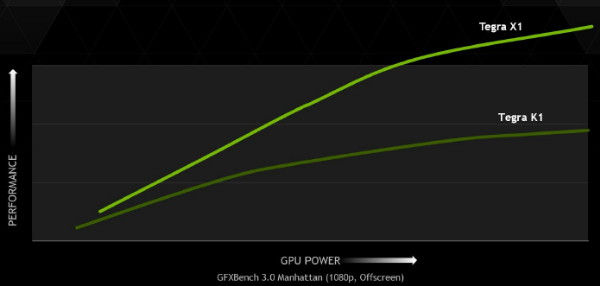
L'exemple le plus parlant est le test Manhattan, dans lequel le Tegra X1 se comporte très bien en doublant les performances par rapport au Tegra K1 et à l'A8x d'Apple. En réduisant les fréquences du Tegra X1, Nvidia observe un rendement énergétique supérieur de 77% (1.51W pour le GPU du Tegra X1, 2.68W pour celui de l'A8x). Nvidia nous indique par contre qu'à pleines performances (64 contre 33 fps), la consommation du GM20B se situe plutôt à environ 3.5W. Un petit calcul montre cette fois un gain du rendement énergétique de 48%. Un chiffre plus réaliste, mais qui reste un excellent résultat.
Le Tegra X1 face à la Xbox One ?Souvenez-vous, lors de l'introduction du Tegra K1, il avait été comparé à la Xbox 360. Nvidia poursuit dans cette voie et pour terminer la présentation du Tegra X1, nous avons eu droit à la démo de l'Unreal Engine qui avait été utilisée pour mettre en avant les consoles de "nouvelle génération", la PS4 et la Xbox One.

Il est sans aucun doute quelque peu exagéré de dire qu'un SoC Tegra X1 dispose de capacité CPU et GPU identique à celles de ces consoles, mais le fait que cette démo (ou même une version allégée) tourne correctement sur une telle puce, montre bien les progrès qui ont été accomplis.
Si Nvidia annonce donc une fois de plus un SoC prometteur au CES, la question du timing de sa disponibilité n'a pas été abordée. Ce sera plus tard dans l'année et la concurrence proposera probablement des évolutions d'ici-là. Nvidia estime cependant que son nouveau bébé gardera la tête au niveau des capacités et des performances de son GPU. De quoi proposer une évolution de sa tablette Shield dans le courant de l'été ? Avec fonction G-Sync ?
Restera ensuite à voir quand une variante à base de curs Denver pourra être proposée mais l'absence totale d'information ou de démos à son niveau laisse penser qu'elle n'arrivera pas avant fin 2015 ou 2016.
GTC: Performances GPU de Logan = GT 640M ?
Durant la GTC 2013, nous avons pu nous entretenir avec Ian Buck qui est à l'origine de la première version de CUDA et actuellement General Manager chez Nvidia pour les technologies du GPU Computing. Interrogé au sujet de Kayla, la plateforme de développement CUDA on ARM équipée d'un GPU GK208, Ian Buck nous a indiqué que les performances GPU, au niveau de CUDA, étaient bel et bien représentatives de celles de Logan, sans vouloir en dire plus.

Bien que ce niveau de performances représente le bas de gamme sur PC, il s'agit d'une évolution énorme pour un SoC Tegra. Si le passage au 20nm et sans aucun doute plusieurs évolutions de l'architecture (avec probablement une réduction du nombre d'unités de texturing), faciliteront l'arrivée de l'architecture Kepler et de CUDA dans le monde ultra-mobile, il est difficile d'imaginer que ces 384 cores (ou équivalents) flexibles ne consommeront pas plus que les 72 cores avec pipeline fixe de Tegra 4.
De quoi nous laisser spéculer qu'avec Logan, Nvidia devra se contenter de versions bridées (en termes d'unités actives ou de fréquences) pour les "petites" tablettes et les superphones, mais compte par contre revoir ses prétentions à la hausse avec un SoC capable de monter en gamme pour viser les "grosses" tablettes voire des ultra-portables et bien entendu le successeur de Shield.
Parallèlement à cela, Ian Buck nous a indiqué que CUDA devrait progressivement devenir "power aware" et devenir capable de prendre en compte l'aspect consommation ou tout du moins de permettre aux développeurs de le faire. Cela se fera tout d'abord au niveau des outils tels que Nsight (et sa version Tegra) qui d'ici quelques temps reporteront des informations liées à la consommation.
Il est possible qu'à terme, les compilateurs CUDA, permettent optionnellement d'améliorer le rendement énergétique, mais cela est encore à l'état de recherche et prendra encore plusieurs années avant d'éventuellement se concrétiser. Globalement, la meilleure stratégie reste d'exécuter le plus rapidement une tâche pour retourner au repos dès que possible mais ce n'est pas toujours vrai, d'autant plus dans le cas d'une tâche continue telle que le rendu 3D sur GPU. Par exemple, calculer une valeur au lieu de la lire en mémoire peut avoir un léger impact sur les performances mais augmenter le rendement énergétique.
En plus de préparer le futur avec CUDA, dans l'immédiat, le plus important pour Nvidia est probablement d'arriver à convaincre un maximum de développeurs que faire l'effort nécessaire pour arriver à utiliser 2 threads ou plus à fréquence modérée offre un meilleur rendement que se contenter d'un seul thread mais des performances de la fréquence CPU maximale.
Correction du 01/07/2013: le nom du GPU que nous pensions être GK117 est en réalité GK208.
GTC: 5W Pour Tegra 4 et 1W pour Tegra 4i ?
Lorsque nous avions rencontré Nvidia pour parler de l'architecture des Tegra 4 et 4i, il y a un point que le concepteur de ces SoC a catégoriquement refusé d'aborder : la consommation en charge et le TDP. Des chiffres délicats à avancer et à assumer puisque de toute évidence, la consommation maximale de Tegra 4 sera supérieure à celle de Tegra 3. Ceci n'étant bien entendu pas incompatible avec un rendement énergétique supérieur et avec une consommation en baisse lors de scénarios de types charge faible.

Lors d'une présentation dédiée aux investisseurs qui a suivi la keynote principale de la GTC, Jen-Hsun Huang, CEO de Nvidia, a avancé des chiffres concernant les TDP des futurs SoC : 5W pour Tegra 4 et 1W pour Tegra 4i. Deux chiffres relativement faibles, voire très faibles dans le cas du Tegra 4i qui intègre pour rappel 4 Cortex-A9 r4, un GPU relativement véloce et un modem 4G/LTE.
Pour comprendre ces chiffres, il faut cependant savoir que la définition du TDP est à géométrie variable, comme nous l'avions expliqué en nous intéressant de plus près au SDP d'Intel. Globalement le TDP représente la capacité de refroidissement nécessaire pour garantir le bon fonctionnement du composant. Historiquement cela représentait sa limite haute de consommation, mais progressivement, le fait de pouvoir fonctionner à une fréquence réduite pour éviter une surchauffe a été intégré à la définition même de "bon fonctionnement". Ajoutez-y les modes turbo et la prise en compte de l'inertie thermique et vous comprendrez qu'il devient difficile d'interpréter l'impact exact du TDP sur la consommation et sur les performances.
Les chiffres de 5W et de 1W avancés par Nvidia représentent ainsi probablement la capacité de dissipation nécessaire pour les variantes les moins gourmandes de Tegra 4 et de Tegra 4i. Des chiffres qui permettent de se faire une idée des types de designs et de formats qui pourront accueillir ces composants. De quoi confirmer que Tegra 4 est plutôt adapté à une tablette alors que Tegra 4i pourra être intégré facilement dans des smartphones compacts.
Difficile de dire par contre quel sera le niveau de performances soutenu autorisé par ces TDP puisqu'il est probable, comme c'est le cas pour la plupart des SoC actuels, que les Tegra 4 et 4i soient autorisés à consommer plus que cette valeur, jusqu'à atteindre une certaine température et voir leurs fréquences réduites. En plus de ces TDP, soit de la capacité de dissipation requise, il serait ainsi intéressant de connaître la capacité de dissipation conseillée par Nvidia pour pouvoir tirer le meilleur de ces SoC en termes de performances, notamment en ce qui concerne le jeu qui représente l'une des tâches les plus gourmandes qu'ils auront à exécuter.

Enfin, notez que le CEO de Nvidia a précisé le timing de l'entrée en production des périphériques qui intégreront ces futurs SoC : Q2 2013 pour Shield, les tablettes et les superphones Tegra 4, Q4 2013 pour les tablettes Tegra 4 + modem i500 et enfin Q1 2014 pour les smartphones Tegra 4i (i500 intégré).