
Les derniers contenus liés au tag GM20B
CES: Nvidia Tegra X1: Maxwell + Cortex A57/53
Publié le 05/01/2015 à 09:30 par Damien Triolet



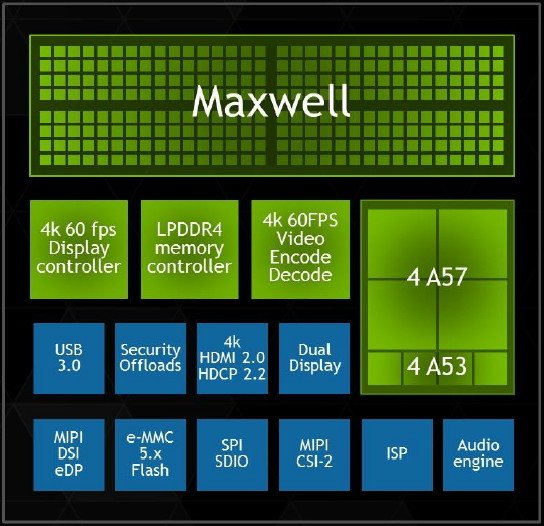
Comme chaque année, Nvidia profite du CES de Las Vegas pour dévoiler un nouveau SoC. Pour cette édition 2015, c'est le Tegra X1 qui est mis en avant. Au menu, le passage au 20nm, un GPU Maxwell de seconde génération optimisé pour le monde mobile et un ensemble de curs Cortex-A57 et A53 pour former le CPU.

Après les Tegra K1 32-bits et 64-bits, Nvidia passera dans le courant de 2015 au Tegra X1, connu précédemment sous le nom de code Erista. Une évolution qui était attendue mais qui réserve quelques surprises, notamment au niveau de sa partie CPU qui ne fait pas appel aux curs ARMv8 maison (nom de code Denver) exploités dans le Tegra K1 64-bits. A la place, Nvidia reprend, comme Qualcomm et Samsung, les curs ARM 64-bits "standards", des Cortex-A57 et des Cortex-A53.
Des curs ARM 64-bits standards en 20nmNvidia explique ce choix par le fait que le développement du Tegra K1 64-bits et du Tegra X1 s'est fait en parallèle en visant des procédés de fabrication différents. Il n'aurait ainsi pas été possible de profiter de l'expérience du développement du premier avec les curs Denver pour mettre au point le second. Dans ce sens il faut voir le Tegra X1 comme le successeur du Tegra K1 32-bits alors qu'une variante équipée des curs Denver sera dévoilée plus tard (Parker ?).
Cette approche permet à Nvidia de réduire les risques lors du passage au 20 nanomètres puisque, en amont, ARM s'est assuré de proposer un design adapté à cette technologie du fondeur TSMC. Pour son implémentation, Nvidia a d'ailleurs abandonné l'approche 4+1 des précédents Tegra qui consistait à associer un unique cur optimisé basse consommation à un ensemble de 4 curs similaires mais orientés performances. L'an passé, Nvidia nous expliquait que ce mode 4+1 était beaucoup plus efficace que ce que faisait la concurrence qui avait opté pour une approche 4+4 mais avec 2 types de curs différents.
Changement de discours cette année, probablement parce que Nvidia n'a pas eu le choix, l'implémentation proposée par ARM a été optimisée pour du 4+4. Nvidia a donc opté pour 4 Cortex-A57 (en version cache L1 I/D de 48/32 Ko) associés à 4 Cortex-A53 (avec cache L1 I/D de 32/32 Ko). Contrairement à ce que le marketing essayera de vous vendre, cela n'en fait cependant pas un SoC octocore. Le Tegra X1 reste un SoC quadcore puisque ces 2 groupes de curs ne peuvent en aucun cas être exploités simultanément. Au repos ou à très faible charge CPU, les Cortex-A53 sont exploités et dès qu'une charge CPU plus lourde est initiée, ils passent au repos et les Cortex-A57 entrent en action.
Nvidia indique que son implémentation est cependant plus efficace sur le plan énergétique que celle d'autres fabricants, notamment Samsung, qui ont fait un choix similaire. Il est question d'une réduction de moitié de la consommation à performances égales et d'un gain de performances de 40% à consommation égale. Nvidia explique cela d'une part par l'expérience acquise lors du design de puces 4+1 qui lui a donné une bonne maîtrise de l'exploitation des possibilités des process de TSMC pour intégrer sur une même puce deux ensembles de curs CPU au profil énergétique très différent. D'autre part, Nvidia exploite sa propre interconnexion, moins gourmande que celle proposée par ARM (CCI-400).
Au niveau du sous-système mémoire, l'ensemble de Cortex-A57 profite d'un cache L2 de 2 Mo, comme les précédents Tegra, alors que les Cortex-A53 se contentent de 512 Ko. Le bus mémoire reste large de 64-bit mais passe de la LPDDR3-1866 (au départ il était question de LPDDR3-2133 mais Nvidia n'en parle plus) à la LPDDR4-3200 (jusqu'à 4 Go) pour offrir un gain de bande passante de 70%. De quoi permettre notamment d'alimenter le GPU plus musclé.
Un GPU Maxwell de seconde génération avec support du FP16Rappelons que là où Kepler avait été portée dans le monde Tegra alors que Nvidia était déjà très avancé dans le développement de cette architecture, Maxwell est la première qui a été pensée dès le départ pour le monde mobile. Ce qui participe au fait que Nvidia ait fait un effort supplémentaire au niveau de son efficacité énergétique. Alors que de nombreux fabricants de SoC ont opté pour les mêmes curs CPU que ceux exploités par le Tegra X1, le GPU est bien entendu l'élément principal qui permet à Nvidia de se démarquer.
Le Tegra X1 fait ainsi appel à un GPU Maxwell de seconde génération, le GM20B, similaire au GM204 qui équipe les GeForce GTX 980 et GTX 970, mais bien entendu équipé de moins d'unités de calcul. Vous pourrez retrouver les détails à son sujet dans le dossier que nous avions consacré à ces cartes graphiques et à l'architecture Maxwell.
Là où le GM204 desktop embarque 16 blocs de 128 unités de calculs, appelés SMM, le GM20A s'en contente de 2. Le nombre d'unités de calcul principal passe donc de 2048 à 256, soit 1/8ème de la puissance de calcul du GPU le plus performant du moment, ce qui reste impressionnant pour un petit SoC. A noter que les Tegra K1 se contentaient d'un seul SMX, mais de 192 unités de calcul. Cependant sur cet ensemble, seules 128 unités était exploitables efficacement et les 64 supplémentaires n'offraient qu'un gain minime. En passant à 2 SMM avec le Tegra X1 et à une fréquence légèrement supérieure, Nvidia n'est pas loin de doubler la puissance de calcul pratique de son GPU.
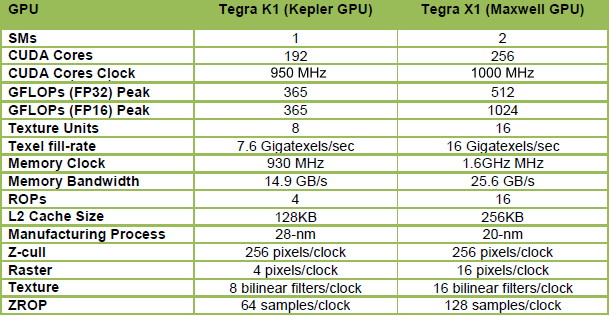
Mais ce n'est pas tout. Les 256 unités de calcul du Tegra X1 évoluent pour supporter de nouvelles instructions qui vont pouvoir doubler la puissance de calcul dans certains cas. Ces instructions sont des opérations FP16 vectorielles pour les FMA, les multiplications et les additions. De plus faible précision, le format de calcul FP16 est suffisant pour bien des usages, notamment pour les jeux mobiles, et alors que la concurrence y a massivement recours pour booster les performances et l'efficacité énergétique, il était devenu inévitable pour Nvidia d'en profiter également.
Pour les GPU Nvidia précédents, aucune précision inférieure au FP32 n'est supportée directement par les unités de calcul. Si celles-ci doivent traiter une opération basse précision en FP16, elles doivent donc les traiter comme des opérations FP32 avec un débit identique et uniquement quelques petites optimisations mineures.
Pour le Tegra X1, l'ajout d'instructions vec2 permet à chaque unité de calcul FP32 de traiter deux opérations FP16 simultanément et donc de doubler le débit. Ces unités restent alimentées par des registres 32-bits classiques dans lesquels sont placées deux valeurs 16-bits. Une implémentation basique qui implique une modification mineure de l'architecture mais qui transpose tout le travail de l'exploitation du FP16 au compilateur qui devra faire en sorte de trouver des opérations vec2 dans le code et parvenir à optimiser l'utilisation du fichier registres entre les valeurs FP32 et FP16.
Cela permet de doubler la puissance de calcul théorique, qui atteint 1 TFlops à 1 GHz, mais en pratique le taux d'utilisation sera rarement optimal. Ceci étant dit il s'agit dans tous les cas d'un gain performances appréciable qui profitera notamment aux jeux mobiles friands de FP16.
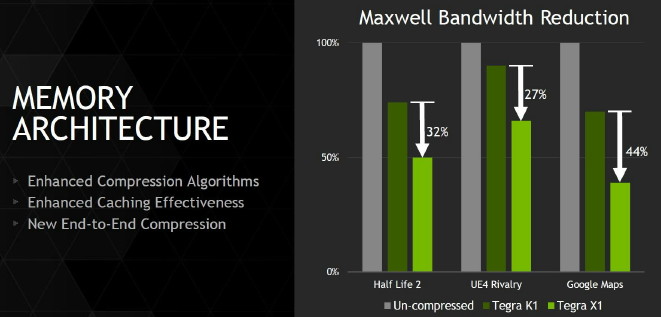
Nvidia a également implémenté la dernière itération de sa technologie de compression des couleurs, et plus spécifiquement du codage différentiel. Son principe de base consiste à ne pas enregistrer directement les couleurs mais leur différence par rapport à une autre qui fait office de repère. Suivant les spécificités de chaque scène, cette technique de compression sans perte permet d'économiser une part significative de la bande passante mémoire, ce qui profite aux performances.
L'ensemble de la chaine d'affichage supporte ces méthodes de compression, ce qui permet de réduire la bande passante à tous les niveaux, jusqu'au moteur d'affichage qui ne décompresse qu'au moment de l'envoi vers l'interface de l'écran. Le cache L2 passe par ailleurs de 128 à 256 Ko, de quoi également d'éviter certains accès à la mémoire centrale. Au final, les techniques de cache et de compressions sans perte permettent par exemple de réduire la bande passante nécessaire de moitié dans Half-Life avec un gain de 30% par rapport au Tegra K1 qui était pourtant déjà plutôt efficace de ce côté.
Pour le reste, toutes les technologies supportées par les gros GPU de bureau le sont par le Tegra X1 : Direct3D 12, OpenGL ES 3.1, AEP, OpenGL 4.5, CUDA 6.0, MFAA, VXGI
4K et 60 HzLe moteur vidéo, cette fois spécifique au SoC Tegra, a été lui aussi revu pour le X1. Nvidia s'est particulièrement penché sur le support de la 4K, qui lui permettra de se différencier par rapport à la concurrence sur un autre plan que la 3D. Tout le pipeline vidéo a ainsi été optimisé pour la lecture du contenu 4K à 60 fps, qui devrait être proposé notamment par le service de streaming de Netflix même s'il faut bien avouer que cela ne concernera qu'une minorité de vidéos et d'utilisateurs.
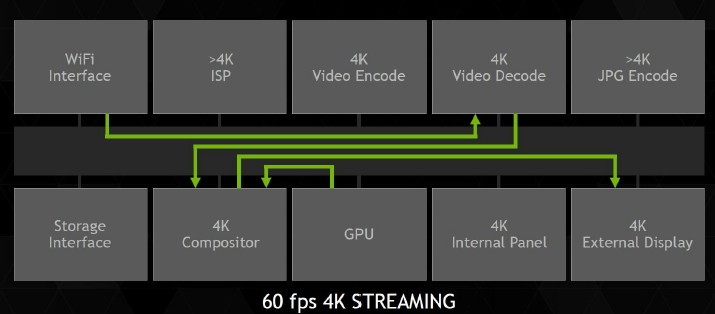
Cela passe bien entendu par un moteur de décodage 100% matériel. Il supporte la 4K à 60 fps en H.264, en H.265 (HEVC) ainsi qu'en VP9, avec un débit maximal non précisé. La profondeur des couleurs de 10-bit est également supportée en H.265 en 4K et 60 fps. Au niveau de l'encodage, Nvidia se "contente" par contre de la 4K à 30 fps en H.264 et H.265 et du 1080 à 60 Hz en VP8.
Deux écrans peuvent être supportés par le moteur d'affichage, compatible HDMI 2.0 et HDCP 2.2. Il supporte par ailleurs la technologie DSC de VESA qui permet de transmettre une image compressée à l'écran.
Le support de l'Adaptive Sync qui permettrait d'améliorer la fluidité dans le monde mobile de manière standardisée n'est par contre pas au menu. A cette question, Nvidia répond par son attachement à G-Sync accompagné d'un traditionnel "wait & see", de quoi nous laisser penser que cette technique d'affichage, ou un dérivé, pourrait être supporté sur le Tegra X1.
L'efficacité énergétique en démoPour mettre en avant les capacités de son SoC, Nvidia avait préparé quelques démos basées sur une plateforme de développement. Celle-ci est relativement compacte et se contente d'un dissipateur en aluminium relativement fin, censé représenter les capacités de refroidissement d'une tablette.


Quel est le TDP de ce SoC Tegra X1 ? Question délicate à laquelle il est toujours difficile d'obtenir une réponse directe. Pour ses démos, Nvidia parle d'environ 5W, mais lors de la présentation globale réalisée par son CEO, il était plutôt mentionné 10W.





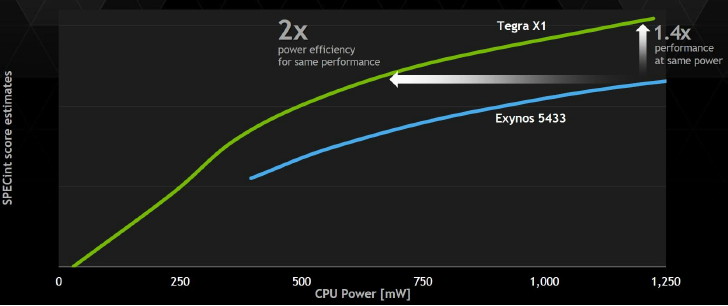
Comme à son habitude, Nvidia exploite des comparaisons "isoperf" (à performances égales) pour mettre en avant l'efficacité énergétique de ses futurs SoC face aux solutions actuelles déjà sur le marché. Des données qui ont selon nous un intérêt limité puisque cette approche consiste à réduire drastiquement les fréquences et tensions du SoC le plus performant. Un calcul du rendement énergétique sur base des conditions d'utilisation réelles des puces est plus pertinent, mais cela ne permet pas d'aller chercher le fameux 2x, un must pour mettre en avant les nouveautés.
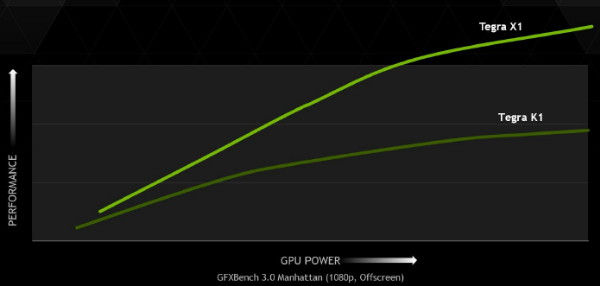
L'exemple le plus parlant est le test Manhattan, dans lequel le Tegra X1 se comporte très bien en doublant les performances par rapport au Tegra K1 et à l'A8x d'Apple. En réduisant les fréquences du Tegra X1, Nvidia observe un rendement énergétique supérieur de 77% (1.51W pour le GPU du Tegra X1, 2.68W pour celui de l'A8x). Nvidia nous indique par contre qu'à pleines performances (64 contre 33 fps), la consommation du GM20B se situe plutôt à environ 3.5W. Un petit calcul montre cette fois un gain du rendement énergétique de 48%. Un chiffre plus réaliste, mais qui reste un excellent résultat.
Le Tegra X1 face à la Xbox One ?Souvenez-vous, lors de l'introduction du Tegra K1, il avait été comparé à la Xbox 360. Nvidia poursuit dans cette voie et pour terminer la présentation du Tegra X1, nous avons eu droit à la démo de l'Unreal Engine qui avait été utilisée pour mettre en avant les consoles de "nouvelle génération", la PS4 et la Xbox One.

Il est sans aucun doute quelque peu exagéré de dire qu'un SoC Tegra X1 dispose de capacité CPU et GPU identique à celles de ces consoles, mais le fait que cette démo (ou même une version allégée) tourne correctement sur une telle puce, montre bien les progrès qui ont été accomplis.
Si Nvidia annonce donc une fois de plus un SoC prometteur au CES, la question du timing de sa disponibilité n'a pas été abordée. Ce sera plus tard dans l'année et la concurrence proposera probablement des évolutions d'ici-là. Nvidia estime cependant que son nouveau bébé gardera la tête au niveau des capacités et des performances de son GPU. De quoi proposer une évolution de sa tablette Shield dans le courant de l'été ? Avec fonction G-Sync ?
Restera ensuite à voir quand une variante à base de curs Denver pourra être proposée mais l'absence totale d'information ou de démos à son niveau laisse penser qu'elle n'arrivera pas avant fin 2015 ou 2016.