
Actualités informatiques du 30-03-2013
| Mars 2013 | ||||||
|---|---|---|---|---|---|---|
| L | M | M | J | V | S | D |
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Core i7-4960X, 4930K et 4820K pour Ivy Bridge-E



VR-Zone a mis en ligne un extrait d'une roadmap officielle Intel récente. Contrairement à ce qu'on avait pu lire de-ci de-là, les Ivy Bridge-E restent prévus pour le troisième trimestre et on a même droit à quelques détails.

Trois versions seront donc lancées :
- Core i7-4960X : Six curs à 3.6 GHz (Turbo à 4.0 GHz max), 15 Mo de cache L3
- Core i7-4930K : Six curs à 3.4 GHz (Turbo à 3.9 GHz max), 12 Mo de cache L3
- Core i7-4820K : Quatre curs à 3.7 GHz (Turbo à 3.9 GHz max), 10 Mo de cache L3
Ces processeurs partagent un TDP de 130 watts et le support natif de la DDR3-1600 mais aussi de là DDR3-1866, ainsi que du VT-d. Comme l'indique leurs dénominations ils ne seront pas bloqués au niveau du coefficient multiplicateur.
Par rapport à la gamme LGA 2011 actuelle ces nouveaux processeurs, qui devraient on l'espère être compatibles avec les cartes actuelles via une mise à jour du bios, offrent donc des caractéristiques similaires au niveau des caches. Comme pour Sandy Bridge-E, les versions non bridées d'Ivy Bridge-E dotées de 8 curs et de 20 Mo de cache L3 seront réservées à d'encore plus onéreux Xeon, bien que le 22nm permette d'abaisser nettement le coût de production de ces processeurs.
Intel profite quand même du passage en 22nm pour augmenter les fréquences malgré l'enveloppe thermique similaire avec +100 MHz pour le 4960X par rapport au 3970X sur la fréquence de base (même Turbo max), +200 MHz pour le 4930K par rapport au 3930K (+100 Mhz sur le Turbo max) et +100 MHz pour le 4820K par rapport au 3820 (Turbo max équivalent).
Si on ajoute à ceci le petit gain (3% environ) apportés par les évolutions sur l'architecture on devrait donc avoir un i7-4960X un peu plus de 6-7% plus rapide qu'un i7-3970X pas de quoi casser trois pattes à un canard alors que ce dernier a été lancé en novembre 2011 : encore une fois le manque de concurrence se fait tristement ressentir sur l'évolution des performances.
GDC: Intel PixelSync et InstantAccess
Intel profite de la GDC pour annoncer deux nouvelles extensions graphiques dédiées au GPU intégré des processeurs Core de 4ème génération (Haswell). Celles-ci permettent de passer outre les limitations des API graphiques et ont pour but de rendre l'utilisation du GPU plus efficace, principalement en économisant de la bande passante mémoire, une denrée rare pour les GPU intégrés.
PixelSync
La première technologie se nomme Pixel Shader Ordering, ou PixelSync en langage commercial. Elle permet de garantir l'ordre d'écriture en mémoire des pixels affectés par une transparence. Traditionnellement, ce sont les ROP qui s'en chargent aidés par un principe qui consiste à rendre les surfaces transparentes en dernier lieu, une fois que toutes les surfaces opaques ont été traitées.
Si le mélange (blending) est personnalisé et traité via un pixel shader, ce qui est nécessaire avec des formats de données personnalisés ou avec plusieurs niveaux de transparences, cet ordre n'est plus garanti et dès qu'un pixel est terminé, il est écrit en mémoire, peu importe si un pixel précédent, peut-être plus lourd à calculer est toujours en cours de traitement. Ce côté aléatoire dans l'ordre d'écriture des pixels en mémoire pose problème dans le cas du traitement des surfaces transparentes, d'autant plus si elles sont multiples : puisqu'elles doivent être mélangées à la surface qu'elles laissent entrevoir, cette dernière doit avoir été traitée avant.

A droite, un exemple de rendu sans technique de respect de l'ordre des pixels lors d'un mélange. Aléatoirement, la face inférieure du phare peut être rendue par-dessus la partie supérieure. A gauche, PixelSync évite ce problème.
Une solution à ce problème a été présentée par AMD avec les Radeon HD 5000 et se nomme Order Independant Transparency (OIT), une technique utilisée pour les cheveux TressFX dans Tomb Raider. Elle consiste, pour les zones affectées par des transparences multiples, à retenir en mémoire tous les pixels qui correspondent à une même coordonnée à l'écran. Une fois la scène passée en revue, ils sont triés et mélangés dans le bon ordre. Cette approche est lourde puisqu'elle peut décupler le nombre de pixels écrits en mémoire. Avec PixelSync, Intel en propose une version simplifiée : si le moteur graphique s'arrange pour soumettre les triangles transparents au GPU dans le bon ordre, cet ordre sera respecté.
Le coût en performances de Pixel Sync sera en général nettement moindre que celui de l'OIT, et simplement lié au fait que le traitement de certains pixels devra se mettre en pause pour garantir l'ordre d'écriture en mémoire. C'est cependant moins flexible et moins passe-partout mais cette approche peut avantageusement remplacer l'OIT dans certains cas simples (ce n'est pas utilisable pour TressFX bien entendu). Codemaster a d'ores et déjà annoncé mettre en place cette optimisation pour GRID 2, tout comme Creative Assembly pour Total War Rome 2.
Vous pourrez retrouver une démo de PixelSync par ici .
InstantAccess
La seconde extension proposée pour Haswell, Direct Ressource Access (DRA) ou InstantAccess, représente la version Intel de la technologie Zero Copy d'AMD. Attendue depuis des lustres, elle permet d'éviter des transferts presque surréalistes entre le CPU et le GPU. Bien que cela paraisse naturel puisque ceux-ci partagent une même mémoire centrale, le problème est que les API graphiques ne sont pas prévues pour ce cas de figure et qu'elles demandent le transfert inutile de certaines données d'une zone mémoire réservée au CPU à une autre zone mémoire réservée au GPU.
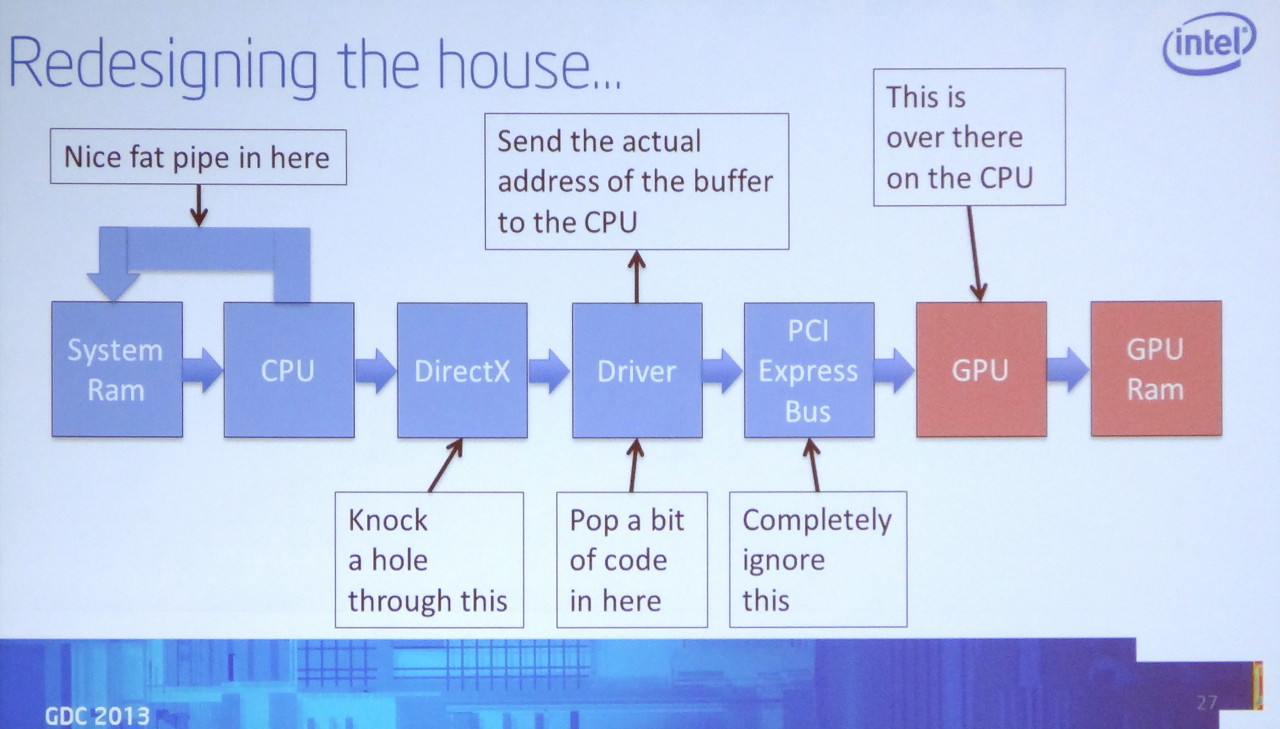
InstantAccess tout comme Zero Copy permettent d'éviter ce cas de figure à travers un mécanisme qui donne au CPU un pointeur vers certains buffers présents dans la mémoire réservée au GPU, tout en protégeant ces espaces mémoire lorsque cela est nécessaire, typiquement quand le GPU doit y accéder. De quoi éviter de perdre du temps et de gaspiller de la bande passante mémoire avec des copies inutiles.
Vous pourrez retrouver une démo d'InstantAccess par ici .