
Actualités informatiques du 20-03-2013
- Prix de la DDR3 : enfin une accalmie
- GTC: FaceWorks: rendu de visage réaliste
- GTC: CUDA on ARM: Tegra 3 + Tesla K20
- GTC: CUDA on ARM: Kayla, Tegra 3 et GK208
| Mars 2013 | ||||||
|---|---|---|---|---|---|---|
| L | M | M | J | V | S | D |
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Prix de la DDR3 : enfin une accalmie



Les prix de la mémoire semblent enfin se calmer, après avoir encore augmenté en flèche jusqu'à la mi-mars. Au plus haut, il fallait en effet compter 3,478$ pour une puce de 512 Mo de DDR3-1600, contre 2,01$ fin novembre (+73%) et 1,748$ pour une puce de 256 Mo contre 0,82$ fin novembre (+113%).

Pour faire une barrette de 4 Go DDR3-1600 la moins chère possible il fallait utiliser en fin d'année passée des puces 256 Mo pour un coût total en DDR3 de 13,12$, contre des puces 512 Mo pour 27,824$ (+112%) mi-mars.
Depuis un peu moins d'une semaine la hausse est terminée et on observe même un léger repli : il faut en effet compter 1,68$ pour 256 Mo de DDR3-1600 et 3,403$ pour 512 Mo. Les prix ont tout de même plus que doublé pour une barrette de 4 Go en l'espace de 4 mois, une hausse qui n'a pas encore été complètement répercutée sur les prix de vente en France grâce aux stocks des divers intervenants. Reste à savoir quelle sera l'évolution des prix dans les prochaines semaines
GTC: FaceWorks: rendu de visage réaliste
Au début de la keynote d'ouverture de la GTC, le CEO de Nvidia, Jen-Hsun Huang, a présenté une nouvelle démo technologique plutôt impressionnante. Elle s'attaque à une tâche complexe : le rendu du visage humain.

Si la partie graphique est très évoluée, il est question de pixels shaders de plus de 8000 instructions pour l'éclairage qui prend en compte la diffusion sous-cutanée ou encore la réflexion partielle sur la transpiration, c'est la représentation des mouvements et des micro-mouvements qui représente ici le challenge. Dénommée FaceWorks, la technologie de Nvidia a été développée en collaboration avec l'Institute for Creative Technology de l'USC et se base sur des prototypes de systèmes de capture de mouvements extrêmement précis (au dixième de millimètre).
Ceux-ci génèrent une quantité énorme de données : Nvidia parle de 32 Go pour une poignée d'expression. Impossible pour un GPU de travailler sur une telle base. FaceWorks consiste à organiser les composantes de ces expressions sous forme de textures, de les compresser et de détecter les similitudes avec d'autres expressions pour en supprimer les données superflues. Avec une perte de fidélité limitée, Nvidia parvient à passer de 32 Go à 400 Mo de données et rend ainsi leur utilisation viable.
Pour observer la qualité de l'animation du visage, nous vous conseillons de jeter un coup d'il au segment de la keynote qui concerne FaceWorks, avec un visage rendu et animé en temps réel sur une GeForce GTX Titan. Notez pour l'anecdote qu'AMD ne manquera probablement pas de faire remarquer à Nvidia que son personnage manque de cheveux !
GTC: CUDA on ARM: Tegra 3 + Tesla K20
En plus des plateformes CUDA on ARM destinées à simuler de futurs SoC que ce soit pour une utilisation de type périphérique mobile grand public ou de type micro-serveur, des développements se font également autour d'accélérateurs très puissants tels que les Tesla K20.
C'est le cas chez l'européen PRACE qui développe des systèmes dédiés au supercomputing et s'intéresse à CUDA on ARM depuis quelques temps. En collaboration avec le Barcelona Supercomputing Center, PRACE est en train de mettre au point une plateforme ARM équipée en GK110 : Pedraforca v2. Celle-ci est composée d'une carte mini-ITX sur laquelle prend place un module Q7 Tegra 3 dont 4 des lignes PCI Express 2.0 sont connectées à un switch PLX PCI Express 3.0 sur lequel vont venir se greffer un accélérateur Tesla K20 et une carte contrôleur InfiniBand 40 Gbps.

Cette plateforme a la particularité de ne pas rechercher la complémentarité entre les cores CPU et GPU. Grossièrement, le but est d'utiliser le SoC ARM uniquement pour activer un système CUDA plus ou moins indépendant. C'est la raison pour laquelle le Tesla K20 est associé à un contrôleur InfiniBand sur un même switch PCI Express 3.0 : ils peuvent ainsi communiquer très rapidement avec les accélérateurs d'autres nuds en ignorant autant que possible la communication avec les SoC et leurs mémoires.
Les développeurs de Pedraforca v2 sont bien conscients qu'une telle approche n'est pas une solution de remplacement générale à un système CUDA classique et se contentera de répondre avantageusement à un sous-ensemble de problématiques : si un problème massivement parallèle peut être résolu sans CPU, autant réduire l'encombrement et la consommation de celui-ci.
Une telle solution permet par ailleurs de simuler le comportement de futurs GPU haut de gamme qui pourraient intégrer un ou plusieurs cores ARMv8 Denver pour gagner en indépendance. De quoi commencer à préparer des algorithmes qui leur seront adaptés ?
GTC: CUDA on ARM: Kayla, Tegra 3 et GK208
Nvidia l'a enfin confirmé, CUDA arrivera enfin dans les SoC Tegra avec Logan. Cela ne veut pas dire pour autant que CUDA sur plateforme ARM doit attendre. Il s'agit d'un point important de la stratégie de Nvidia pour son futur autant dans le monde professionnel que grand public. C'est la raison pour laquelle, depuis quelques temps déjà, Nvidia s'est associé à SECO pour proposer un kit de développement dénommé CARMA. Pour 529, la plateforme propose un connecteur Q7 qui reçoit un SoC Tegra 3 (T30 à 1.3 GHz) et un connecteur MXM sur lequel prend place une Quadro 1000M de génération Fermi (GF108 avec 96 cores).

Tout cela va évoluer à partir du mois de mai, d'une part avec une couche logicielle qui supportera Ubuntu 12.04 et CUDA 5.0, et d'autre part avec la plateforme KAYLA, toujours développée en partenariat avec SECO, et qui existera en 2 versions : connecteur MXM ou PCI Express (câblés en 4x dans les 2 cas). Si nous aurions pu supposer que le SoC passerait en version Tegra 4, c'est bel et bien le Tegra 3 T30 qui reste exploité pour la simple et bonne raison que ses successeurs ne disposent plus de liens PCI Express. La différence (unique ?) entre les 2 cartes concerne les GPU supportés. La version PCI Express en supporte un large choix et la version MXM est annoncée être équipée d'un GPU Kepler de next generation.
Nvidia indique à ce sujet que ce GPU dispose de 2 SMX (384 cores), supporte les compute capabilities 3.5 (Dynamic Parallelism etc.) et est très proche du niveau de fonctionnalité du futur SoC Logan. Nous apprenons ainsi que le GPU de cette plateforme et celui de Logan disposent d'un processeur de commande plus évolué que sur les premiers GPU de la génération Kepler, dérivé de celui du GK110 (Tesla K20 et GTX Titan).
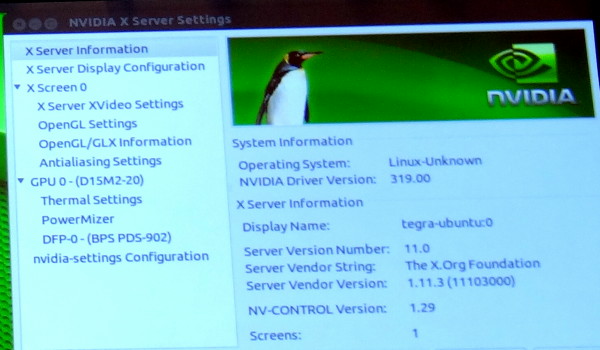
De toute évidence ce GPU est ainsi le GK208 qui prendra place dans les GeForce 700 d'entrée de gamme. Une supposition renforcée par un panneau de contrôle des pilotes Linux que Nvidia a malencontreusement oublié de masquer pendant quelques secondes et qui fait référence à un nom de code produit : D15M2-20. Cela correspond à la famille GeForce 700 desktop (D12 = GeForce 400, D13 = GeForce 500, D14 = GeForce 600 ).

Cette plateforme CUDA on ARM continuera bien entendu à évoluer, tout d'abord avec CUDA 5.5 qui intégrera un compilateur CUDA pour l'architecture ARM, et plus tard avec l'arrivée de Logan et de Parker.
Correction du 01/07/2013: le nom du GPU que nous pensions être GK117 est en réalité GK208.