
Nvidia GeForce GTX 680 en test
Publié le 22/03/2012 par Damien Triolet



GK104 : Fermi au régimePour la génération Kepler, Nvidia n'est pas reparti de zéro, la génération Fermi ayant posé de bonnes bases, faites pour durer. Kepler est ainsi une petite évolution de l'architecture Fermi qui a pour but d'en corriger le gros point noir : le rendement énergétique plutôt faiblard. N'y cherchez pas un but écolo, mais simplement un moyen d'éviter de foncer droit dans le mur puisque conserver l'architecture Fermi en passant à une fabrication en 28 nanomètres n'aurait pas permis d'en profiter pleinement. La consommation excessive aurait été un frein à la complexification du GPU.
Alors que Nvidia compare dans toutes ses documentations techniques l'architecture du GK104 à celle du GF100/110, cela n'a aucun sens en dehors de brouiller les pistes. Avec le GF104/114, introduit dans la GeForce GTX 460, Nvidia a proposé une variante de son architecture Fermi optimisée pour un meilleur rendement en jeu, là où le gros GPU visait un compromis laissant plus de place au GPU Computing. Pour rappel, vous pouvez retrouver notre description des différences par ici. C'est bien entendu à cette architecture du GF1x4 qu'il faut comparer celle du GK104 de manière à bien en saisir les évolutions.
Les GPU Nvidia se basent sur des blocs fondamentaux appelés SM pour Streaming Multiprocessors. Ces SM contiennent un certain nombre d'unités de calcul et de texturing, du cache et de la logique de gestion. Chaque groupe de 4 SM forme un GPC, Graphics Processing Cluster, et dispose de son propre rasterizer, ce qui permet de traiter efficacement les petits triangles. Avec le GK104, le SM évolue et prend le nom de SMX. Voici une représentation de l'évolution du SM du GF1x4, à gauche, vers le SMX du GK104, à droite :
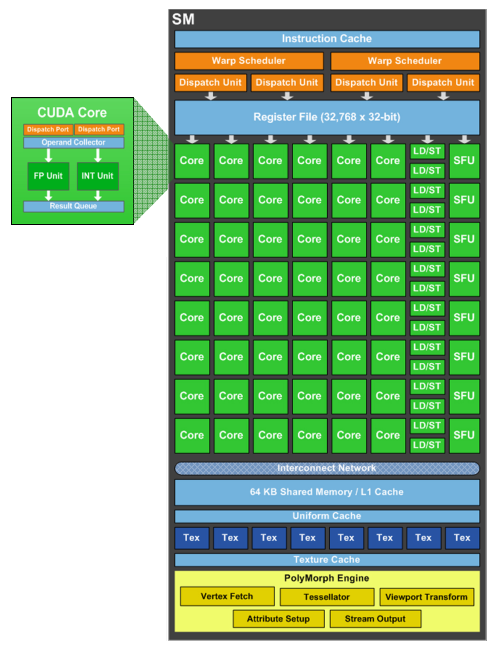
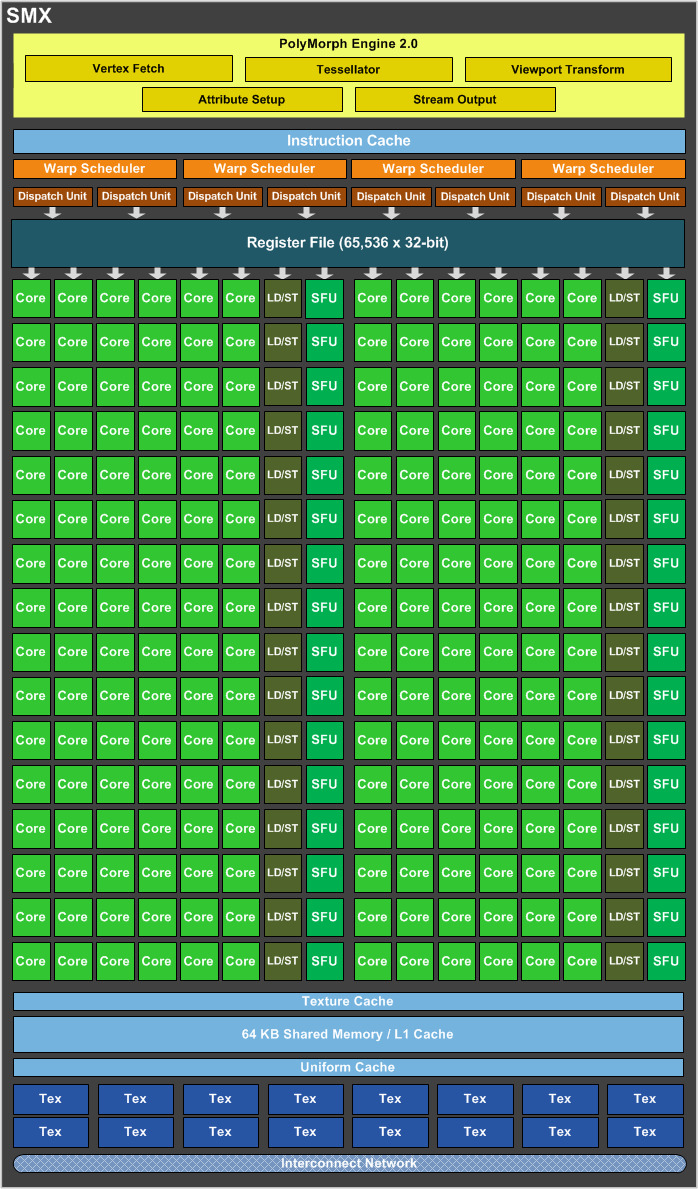
La taille du SMX explose ! Il passe de 48 unités de calcul principales et de 8 unités de texturing à 192 unités de calcul et 16 unités de texturing. Un changement radical ? Pas vraiment si nous y regardons de plus près.
Nvidia introduit avec le SMX une première optimisation énergétique : l'abandon de la fréquence double pour les unités de calcul. Introduit avec le G80 et les GeForce 8800 GTX, le fonctionnement des unités de calcul à une fréquence double a permis à Nvidia de faire beaucoup en termes de performances avec relativement peu d'unités de calcul. Malheureusement cette approche a un coût, avec en besoin d'énergie plus important pour les unités elles-mêmes ainsi que pour la distribution du signal d'horloge.
En passant au 28 nanomètres, Nvidia est moins limité par la surface qu'occupent les unités que par l'énergie nécessaire pour les animer. Ce compromis fait précédemment n'a donc plus de sens et le GK104 abandonne cette double fréquence et double l'ensemble des unités de calculpour compenser, y compris les SFU qui traitent les opérations spéciales (mais pas les unités chargées du calcul en double précision qui chute donc à un débit équivalent à 1/24ème de la simple précision). Voilà qui explique la moitié de l'évolution du SM vers le SMX.
Pour la seconde, il faut en réalité voir le SMX comme deux SM collés l'un à l'autre de manière à partager un même cache L1 pour réduire le coût de ce dernier qui n'est pas très utile dans les jeux puisque les unités de texturing disposent de leurs propres caches dédiés. Rappelons qu'une partie de ce cache L1 fait office de mémoire partagée qui permet à différents éléments traités en parallèle de communiquer lors de l'utilisation du GPU Computing. Les GPU Fermi pouvaient répartir leur cache de 64 Ko entre une partie cache L1 de 16 ou 48 Ko et une partie mémoire partagée de 48 ou 16 Ko. Pour le GK104 un mode 32 Ko / 32 Ko est possible, ce qui permet de s'aligner plus efficacement sur les spécifications de DirectX 11. Par ailleurs, la bande passante offerte par ce cache a été doublée de manière pour éviter de créer une trop forte limitation.
Chaque moitié de SMX est, en dehors du cache, indépendante l'une de l'autre. Ainsi, les 2 premiers schedulers ne peuvent accéder qu'à la première moitié des unités d'exécution et les 2 autres à la seconde. Tout comme pour le GF1x4, il s'agit d'une architecture superscalaire, puisque pour maximiser l'utilisation des unités de calcul, au moins 50% des instructions mathématiques doivent pouvoir s'exécuter par paire pour un warp donné (groupe de 32 éléments à traiter). Nous ne sommes donc pas en présence d'une architecture au comportement perçu strictement scalaire, mais le travail du compilateur reste relativement simple.
Chaque scheduler dispose de ses propres registres (4096 x 32 bits) et de son propre groupe de 4 unités de texturing (chacun disposant d'un petit cache dédié) et peut initier l'exécution de 2 opérations par cycle. Il doit cependant partager les ressources à ce niveau avec un second scheduler :
- unité SIMD0 32-way (les « cores ») : 32 FMA FP32 ou 4 FMA FP64
- unité SIMD1 32-way (les « cores ») : 32 FMA FP32
- unité SIMD2 32-way (les « cores ») : 32 FMA FP32
- unité SFU 16-way : 16 fonctions spéciales FP32 ou 32 interpolations
- unité Load/Store 16-way 64 bits
Notez que ce dernier point n'est pas très clair. Nvidia indique que la capacité en Load/Store d'un SMX n'évolue pas lorsqu'il s'agit de transactions 32 bits par rapport au SM Fermi, mais qu'elle est doublée en 64 bits. Nous supposons donc que le diagramme, qui est une simplification d'une architecture très complexe, est en partie erroné et qu'en réalité les 2 moitiés du SMX se partagent ces ressources. Charger ou écrire des données de 64 bits se fait par contre sans coût supplémentaire par rapport au 32 bits, Nvidia précisant que ce premier type d'accès est plus souvent un facteur limitant que le second.
Nous en arrivons à la seconde évolution destinée à réduire l'empreinte énergétique de l'architecture. Les schedulers de Fermi font appel au scoreboarding pour vérifier à chaque instant quels registres sont en cours d'utilisation (et donc possiblement de modification) de manière à déterminer quelle instruction peut être initiée sur quel groupe de données. Kepler conserve ce mode de fonctionnement, important lorsque certaines opérations affichent une latence très importante, mais n'y a plus recours lorsque ce n'est pas nécessaire.
L'exécution des instructions mathématique est parfaitement déterministe, leurs débits et leurs latences sont fixes. Il est dès lors possible pour le compilateur de prédire leur comportement exact et de le notifier dans le flux d'instructions de manière à ne plus faire appel à la logique complexe d'ordonnancement pour le traitement de séquences d'instructions à l'intérieur d'un même groupe de donnée. C'est ce que fait Kepler qui n'y a recours que pour les instructions à latence indéterminée (texturing, load, store) ainsi que pour déterminer sur quel groupe de données travailler. Une approche qui permet de réduire l'énergie consommée pour alimenter les unités de calcul.
Notez enfin que le SMX étant grossièrement un assemblage de deux SM, le débit en terme de pixels et de triangles d'un SMX est égal ou double de celui d'un SM, soit un triangle (=un vertex fetch) tous les deux cycle et 4 pixels simples (32bits) par cycle.
Sommaire
1 - Introduction
2 - GK104 : Fermi au régime
3 - GK104 : GF114 x2
4 - GPU Boost : le turbo non déterministe
5 - Spécifications, GeForce GTX 680 de référence
6 - Nuisances sonores et température GPU
7 - Relevés et thermographie infrarouge
8 - Consommation et performances/watt
9 - Performances théoriques : pixels
10 - Performances théoriques : géométrie
11 - Les pilotes, le test
12 - Benchmark : Alan Wake
2 - GK104 : Fermi au régime
3 - GK104 : GF114 x2
4 - GPU Boost : le turbo non déterministe
5 - Spécifications, GeForce GTX 680 de référence
6 - Nuisances sonores et température GPU
7 - Relevés et thermographie infrarouge
8 - Consommation et performances/watt
9 - Performances théoriques : pixels
10 - Performances théoriques : géométrie
11 - Les pilotes, le test
12 - Benchmark : Alan Wake
13 - Benchmark : Anno 2070
14 - Benchmark : Batman Arkham City
15 - Benchmark : Battlefield 3
16 - Benchmark : Bulletstorm
17 - Benchmark : Civilization V
18 - Benchmark : Crysis 2
19 - Benchmark : F1 2011
20 - Benchmark : Metro 2033
21 - Benchmark : Total War Shogun 2
22 - Récapitulatif des performances
23 - Performances GPU Boost et overclocking
24 - Conclusion
14 - Benchmark : Batman Arkham City
15 - Benchmark : Battlefield 3
16 - Benchmark : Bulletstorm
17 - Benchmark : Civilization V
18 - Benchmark : Crysis 2
19 - Benchmark : F1 2011
20 - Benchmark : Metro 2033
21 - Benchmark : Total War Shogun 2
22 - Récapitulatif des performances
23 - Performances GPU Boost et overclocking
24 - Conclusion
Vos réactions
Contenus relatifs
- [+] 17/10: Nouveau bundle Nvidia: Assassin's C...
- [+] 30/08: Nvidia passe de Splinter Cell à Bat...
- [+] 09/07: Bundle GTX 600/700: Splinter Cell B...
- [+] 30/05: Une baisse pour les GTX 670 et 680
- [+] 19/03: UEFI GOP chez Asus pour les GTX 680
- [+] 11/02: Un bundle jeux free-to-play pour le...
- [+] 09/11: GTX680 4 Go DirectCU II pour Asus
- [+] 06/09: Sparkle Calibre X680 et X670 Captai...
- [+] 31/07: MSI GTX 680 Twin Frozr III en versi...
- [+] 09/07: PoV GTX 680 BEAST: 1162 MHz de base