
AMD Radeon HD 7970 & CrossFireX en test : 28nm et GCN
Publié le 22/12/2011 (Mise à jour le 24/12/2011) par Damien Triolet



GCN : des caches et 2 ACE pour le GPU computingSi le graphique est resté au cur du développement de GCN, le GPU computing a également pris beaucoup d'importance. Pour éviter qu'il ne reste cantonné qu'à quelques utilisations très spécifiques, il convient pour AMD et Nvidia de continuer à faciliter l'exploitation de leurs GPU. Avec Fermi, Nvidia a apporté de nombreuses évolutions dans ce sens et avec GCN c'est au tour d'AMD de faire de même.
Tahiti inaugure ainsi une nouvelle structure de caches en lecture/écriture. Le texture cache des précédentes générations évolue vers un cache L1 de 16 Ko qui peut être utilisé aussi bien par les unités de texturing que par les SIMD. Chaque unité scalaire dispose par ailleurs de son propre cache L1 de 4 Ko. Ce dernier est cependant implémenté en tant que cache de 16 Ko partagé entre 4 Compute Unit. Un compromis qui a été fait pour réduire le coût de son implémentation. Tahiti dispose donc au total de 40 caches L1 de 16 Ko.
Ils sont connectés avec un accès de 64 octets par cycle au cache L2 partitionné en morceaux de 128 Ko intégrés dans chacun de 6 contrôleurs mémoire. Ce cache L2 devient cohérent et traite les opérations atomiques beaucoup plus efficacement qu'auparavant.
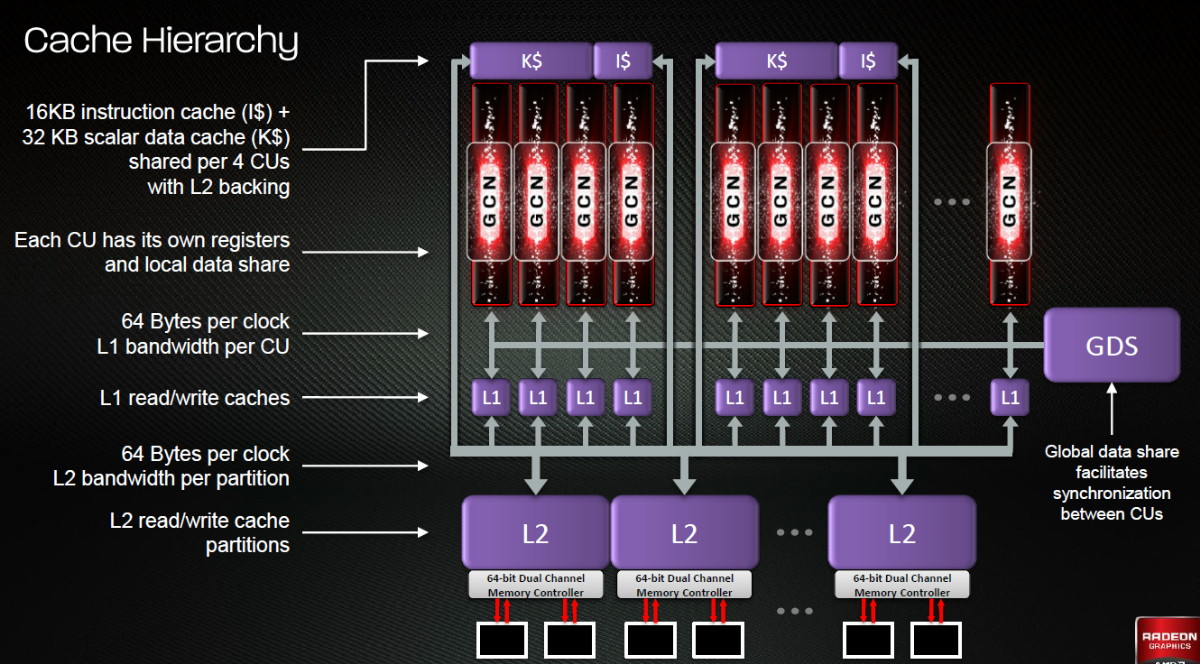
La mémoire partagée de chaque CU, Local Data Share, évolue elle aussi pour passer de 32 à 64 Ko. Pour rappel elle est destinée à partager des informations à l'intérieur d'un bloc d'éléments à traiter et les spécifications de Direct3D 11 exigent 32 Ko au minimum. Cette mémoire dispose d'un accès en lecture direct au L1 de sa Compute Unit, ce qui permet de la charger avec des données sans passer par les SIMD. Performances et consommation en tirent bénéfice.
Les registres généraux dédiés aux SIMDs de chaque CU n'évoluent par contre pas en nombre : 256 registres vectoriels de 2048 bits (64x 32 bits). L'unité scalaire dispose en plus de 256 registres de 32 bits dédiés.
Toujours sur le plan du sous-système mémoire, AMD a également implémenté une protection ECC, pour la SRAM (L1, L2 et registres) ainsi que pour la mémoire vidéo. L'implémentation est probablement similaire à celle de Nvidia, c'est-à-dire qu'elle consiste à réserver une partie de la mémoire pour stocker les données ECC qui vont donc également réduire la bande passante mémoire disponible en pratique.

Après le cache généralisé en lecture/écriture, AMD s'est attaqué à un autre problème qui touche le GPU Computing : le multitâche et l'overhead. Pour cela, Tahiti intègre 3 processeurs de commandes. Le principal, non représenté sur ce schéma, est capable de traiter toutes les tâches, graphique et compute. A côté de celui-ci prennent place 2 ACE pour Asynchronous Compute Engines qui sont limités aux tâches compute. Avec un système évolué de contrôle des ressources, des priorités et de la synchronisation, ils sont capables de gérer simultanément plusieurs contextes. De quoi permettre par exemple d'utiliser efficacement le GPU computing et la 3D en même temps. A l'avenir il est également possible qu'AMD dévie le traitement des Compute Shaders de DirectX 11 du processeur de commande principal vers les ACE, mais ce n'est pas encore le cas actuellement. Une optimisation possible pour 3DMark 11 ?
Pour alimenter tous ces processeurs de commande, et comme l'a déjà fait Nvidia, AMD a ajouté un second moteur DMA pour gérer la communication de et vers le CPU.
Sommaire
1 - Introduction
2 - Tahiti : 2048 unités de calcul et bus 384 bits
3 - GCN : l'abandon du VLIW
4 - GCN : des caches et 2 ACE pour le GPU computing
5 - Video Codec Engine et HDMI 1.4a 3 GHz
6 - PowerTune et ZeroCore Power
7 - Spécifications, Radeon HD 7970 de référence, overclocking
8 - PowerTune : influence sur les performances
9 - Consommation et performances/watt
10 - Nuisances sonores et température GPU
11 - Thermographie infrarouge
12 - Performances théoriques : pixels
13 - Performances théoriques : géométrie
2 - Tahiti : 2048 unités de calcul et bus 384 bits
3 - GCN : l'abandon du VLIW
4 - GCN : des caches et 2 ACE pour le GPU computing
5 - Video Codec Engine et HDMI 1.4a 3 GHz
6 - PowerTune et ZeroCore Power
7 - Spécifications, Radeon HD 7970 de référence, overclocking
8 - PowerTune : influence sur les performances
9 - Consommation et performances/watt
10 - Nuisances sonores et température GPU
11 - Thermographie infrarouge
12 - Performances théoriques : pixels
13 - Performances théoriques : géométrie
14 - Protocole de test
15 - Benchmark : Anno 2070
16 - Benchmark : Batman Arkham City
17 - Benchmark : Battlefield 3
18 - Benchmark : Bulletstorm
19 - Benchmark : Civilization V
20 - Benchmark : Crysis 2
21 - Benchmark : F1 2011
22 - Benchmark : Metro 2033
23 - Benchmark : Project Cars
24 - Benchmark : Total War Shogun 2
25 - Récapitulatif des performances
26 - Conclusion
15 - Benchmark : Anno 2070
16 - Benchmark : Batman Arkham City
17 - Benchmark : Battlefield 3
18 - Benchmark : Bulletstorm
19 - Benchmark : Civilization V
20 - Benchmark : Crysis 2
21 - Benchmark : F1 2011
22 - Benchmark : Metro 2033
23 - Benchmark : Project Cars
24 - Benchmark : Total War Shogun 2
25 - Récapitulatif des performances
26 - Conclusion
Vos réactions
Contenus relatifs
- [+] 14/08: AMD annonce son bundle Never Settle...
- [+] 06/08: Baisse de prix sur les Radeon 7900
- [+] 05/08: Never Settle Forever, nouveau souff...
- [+] 15/05: AMD muscle Never Settle Reloaded
- [+] 12/04: Bundle: AMD ajoute Far Cry 3 Blood ...
- [+] 03/02: AMD HD 7900 & 7800: nouveau bundle ...
- [+] 26/10: Asus Radeon HD 7970 Matrix Platinum...
- [+] 26/10: Comparatif : les Radeon HD 7970 et ...
- [+] 11/10: MSI dope sa HD7970 Lightning
- [+] 28/09: Asus officialise ses Matrix HD7970