
AMD Radeon HD 7970 & CrossFireX en test : 28nm et GCN
Publié le 22/12/2011 (Mise à jour le 24/12/2011) par Damien Triolet



Tahiti : 2048 unités de calcul, 32 ROP et bus mémoire 384 bitsComme tous les GPU actuels, Tahiti et ses petits frères organisent leurs unités d'exécution en blocs fondamentaux qui englobent des unités de calcul, du cache, des unités de texturing, de la logique de gestion etc. Précédemment, AMD nommait ces blocs SIMD, ce qui était peu clair puisqu'il s'agit également du nom des unités de calcul vectorielles. Avec GCN AMD parle dorénavant de Compute Unit (CU). Par soucis de clarté, nous utiliserons également ce terme pour parler des blocs fondamentaux des GPU Radeon actuels et nous réserverons le terme SIMD à sa définition première : une unité de calcul vectorielle. Du côté des GeForce, ces blocs se nomment pour rappel Shader Multiprocessors (SM).
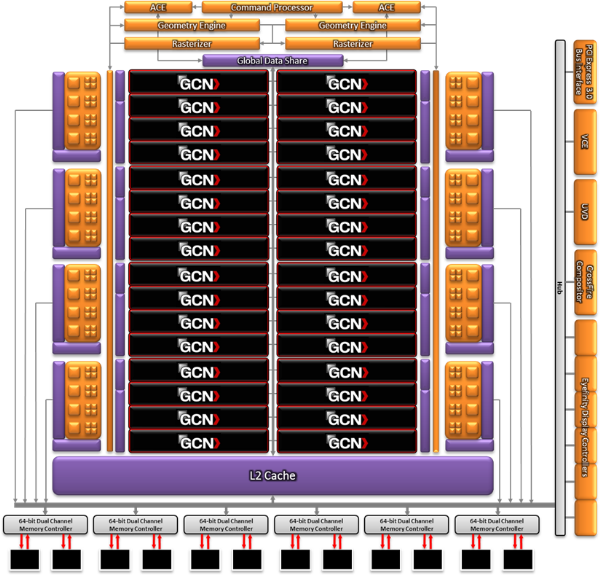
Première évolution pour Tahiti (HD 7900) par rapport à Cayman (HD 6900), le nombre de CU passe de 24 à 32 tout en conservant le même débit de calcul et de texturing. Un gain de 33% qui porte le nombre d'unités de calcul de 1536 (384 vec4) à 2048 et de texturing de 96 à 128, ce qui profitera directement aux performances. Des CU qui optent également pour un fonctionnement de type scalaire, plus efficace (voir page suivante), comme c'est le cas chez Nvidia depuis les GeForce 8.
Les unités de texturing n'évoluent pas et traitent toujours le filtrage des textures HDR 64 bits (FP16) à demi vitesse et HDR 128 bits (FP32) à une vitesse réduite à un quart. La qualité du filtrage évolue par contre légèrement pour réduire quelque peu le fourmillement, une petite différence que nous avons pu constater. AMD a également ajouté un support matériel des Partially Resident Textures (PRT), qui correspond grossièrement au MegaTexturing utilisé par l'id Tech5 de John Carmack. Actuellement exposée via une extension OpenGL propriétaire, cette accélération des PRT permettra d'accélérer les moteurs qui y feront appel mais aura du mal à trouver son public si AMD ne parvient pas à l'exposer via Direct3D.

Pour alimenter ces nouveaux CU, AMD fait évoluer le bus mémoire de 256 à 384 bits, ce qui représente un gain de bande passante de 50% à mémoire identique. Le nombre de ROP est cependant découplé de la taille du bus mémoire, une possibilité que nous avions déjà pu apercevoir avec la Radeon HD 6790. AMD a ainsi opté pour ne pas augmenter leur nombre, qui reste figé à 32. Conséquence : le fillrate n'évolue pas. Il était déjà plutôt élevé auparavant, ce n'est donc pas un gros problème, d'autant plus que pour écrire plus de 32 pixels en mémoire, il faut encore pouvoir en générer plus ! C'est d'ailleurs le problème des GeForce GTX 400 et 500. La GeForce GTX 580 est par exemple capable d'enregistrer 48 pixels en mémoire par cycle mais ne peut en générer que 32, ce qui n'est utile que pour accélérer l'antialiasing de type multisample.
32 ROP peuvent-ils profiter d'un bus mémoire de 384 bits ? Pas toujours, mais ils ne sont pas les seuls à consommer de la bande passante mémoire, les textures en ont également besoin. Dans certains cas par contre, 32 ROP sont limités par un bus de 256 bits, c'est le cas lors du mélange des couleurs et en HDR 64 et 128 bits. Ces modes profiteront ainsi pleinement du bus étendu.
Tout comme Cayman, Tahiti est capable de traiter 2 triangles par cycle, avec ou sans tessellation, contre 4 pour le GF100/110 de Nvidia. Cette non évolution est cependant compensée par quelques petites optimisations pour augmenter les performances lorsqu'un niveau élevé de tessellation est utilisé : de plus gros caches, moins de pénalités lorsqu'il faut utiliser la mémoire vidéo comme tampon et un recours à la réutilisation des vertices déjà traités (triangles voisins) aussi souvent que possible. Des gains qui peuvent monter à 4x par rapport à Cayman selon AMD.
Implémenter ces unités supplémentaires ainsi que toutes les évolutions de l'architecture fait exploser le nombre de transistors qui passe de 2.64 pour Cayman à 4.31 milliards pour Tahiti. Grâce au 28 nanomètres, ce dernier est cependant légèrement plus petit avec 352 mm² contre 389 mm² pour Cayman. Notez qu'AMD se refuse pour l'instant à préciser quelle variante du procédé de fabrication en 28 nm est utilisée.
Sommaire
1 - Introduction
2 - Tahiti : 2048 unités de calcul et bus 384 bits
3 - GCN : l'abandon du VLIW
4 - GCN : des caches et 2 ACE pour le GPU computing
5 - Video Codec Engine et HDMI 1.4a 3 GHz
6 - PowerTune et ZeroCore Power
7 - Spécifications, Radeon HD 7970 de référence, overclocking
8 - PowerTune : influence sur les performances
9 - Consommation et performances/watt
10 - Nuisances sonores et température GPU
11 - Thermographie infrarouge
12 - Performances théoriques : pixels
13 - Performances théoriques : géométrie
2 - Tahiti : 2048 unités de calcul et bus 384 bits
3 - GCN : l'abandon du VLIW
4 - GCN : des caches et 2 ACE pour le GPU computing
5 - Video Codec Engine et HDMI 1.4a 3 GHz
6 - PowerTune et ZeroCore Power
7 - Spécifications, Radeon HD 7970 de référence, overclocking
8 - PowerTune : influence sur les performances
9 - Consommation et performances/watt
10 - Nuisances sonores et température GPU
11 - Thermographie infrarouge
12 - Performances théoriques : pixels
13 - Performances théoriques : géométrie
14 - Protocole de test
15 - Benchmark : Anno 2070
16 - Benchmark : Batman Arkham City
17 - Benchmark : Battlefield 3
18 - Benchmark : Bulletstorm
19 - Benchmark : Civilization V
20 - Benchmark : Crysis 2
21 - Benchmark : F1 2011
22 - Benchmark : Metro 2033
23 - Benchmark : Project Cars
24 - Benchmark : Total War Shogun 2
25 - Récapitulatif des performances
26 - Conclusion
15 - Benchmark : Anno 2070
16 - Benchmark : Batman Arkham City
17 - Benchmark : Battlefield 3
18 - Benchmark : Bulletstorm
19 - Benchmark : Civilization V
20 - Benchmark : Crysis 2
21 - Benchmark : F1 2011
22 - Benchmark : Metro 2033
23 - Benchmark : Project Cars
24 - Benchmark : Total War Shogun 2
25 - Récapitulatif des performances
26 - Conclusion
Vos réactions
Contenus relatifs
- [+] 14/08: AMD annonce son bundle Never Settle...
- [+] 06/08: Baisse de prix sur les Radeon 7900
- [+] 05/08: Never Settle Forever, nouveau souff...
- [+] 15/05: AMD muscle Never Settle Reloaded
- [+] 12/04: Bundle: AMD ajoute Far Cry 3 Blood ...
- [+] 03/02: AMD HD 7900 & 7800: nouveau bundle ...
- [+] 26/10: Asus Radeon HD 7970 Matrix Platinum...
- [+] 26/10: Comparatif : les Radeon HD 7970 et ...
- [+] 11/10: MSI dope sa HD7970 Lightning
- [+] 28/09: Asus officialise ses Matrix HD7970