
Nvidia GeForce GTX 460
Publié le 12/07/2010 par Damien Triolet



Architecture Fermi pour les joueursPour rappel, le GF100 repose sur une première grosse structure, les GPCs (Graphic Processing Clusters). Au nombre de 4, ces GPCs intègrent chacun une unité de rastérisation et 4 SMs (Streaming Multiprocessors). Pour alimenter ces GPCs, 6 contrôleurs mémoire de 64 bits forment un bus de 384 bits. Avec le GF104, Nvidia est parti dun demi-GF100 interfacé en 256 bits. Il repose ainsi sur 2 GPCs de 4 SMs. Jusque là, que du classique.
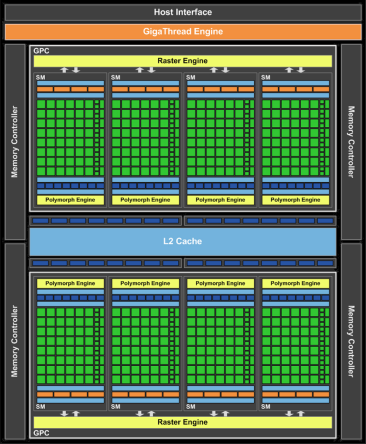
Maintenez la souris sur le schéma du GF104 pour le comparer à celui du GF100.
A y regarder de plus près, les SMs du GF104 semblent plus larges. Cest effectivement le cas. Dans le GF100, chaque SM dispose 32 « cores » et de 4 unités de texturing. Plus en détail, nous retrouvons 2 schedulers qui alimentent 5 blocs dexécution :
- unité SIMD0 16-way (les « cores ») : 16 FMA FP32
- unité SIMD1 16-way (les « cores ») : 16 FMA FP32
- unité SFU 4-way : 4 fonctions spéciales FP32 ou 8 interpolations
- unité Load/Store 16-way 32 bits
- unité de texturing 4-way
Pour le GF104, Nvidia a voulu ajouter des unités dexécutions à plus faible coût et augmenter le ratio dunités de texturing par rapport aux unités de calcul. Les SMs ont donc été élargis avec 48 « cores » et 8 unités de texturing. Un ratio qui vise directement le rendement dans les jeux. Plus en détail, les SMs du GF104 disposent de 2 doubles schedulers qui alimentent 6 blocs dexécution :
- unité SIMD0 16-way (les « cores ») : 16 FMA FP32
- unité SIMD1 16-way (les « cores ») : 16 FMA FP32
- unité SIMD2 16-way (les « cores ») : 16 FMA FP32
- unité SFU 8-way : 8 fonctions spéciales FP32 ou 16 interpolations
- unité Load/Store 16-way 32 bits
- unité de texturing 8-way
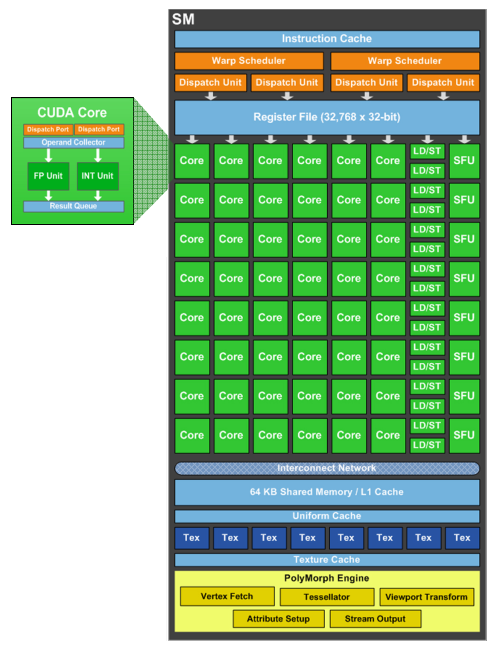
Maintenez la souris sur le schéma du GF104 pour le comparer à celui du GF100.
Le demi-GF100 se transforme ainsi en un GPU nettement plus véloce avec seulement 25% de déficit au niveau des unités de calcul générales et un nombre identique dunités de texturing et dexécution des fonctions spéciales. Qui plus est, les unités de texturing ont été améliorées pour filtrer les textures FP16 (ainsi que FP11, FP10 et RGB9E5) à pleine vitesse. Il perd cependant la faculté de traiter à demi-vitesse les calculs en double précision qui sont fortement ralentis, ce qui est de toute manière également le cas sur les versions grand public du GF100.
Si le GF104 peut envoyer 4 instructions par SM et par cycle contre seulement 2 pour le GF100, vous remarquerez que nous parlons de 2 doubles schedulers et non de 4 schedulers. La différence est subtile et marque un changement de religion chez Nvidia. Du G80 au GF100, tous les GPUs de la marque ont eu naturellement un rendement optimal grâce à un fonctionnement vu comme scalaire de la part du programme exécuté. Cela en opposition aux GPUs des Radeon qui ont un comportement vectoriel a lefficacité forcément moindre.
Si chaque SM du GF100 lance 2 instructions par cycle, elles sexécutent sur 2 groupes de données différents, les warps de 32 éléments. Il ny a donc jamais de problème de dépendance des instructions et le rendement est optimal ou presque. Cela change avec le GF104 dont chacun des 2 schedulers, pour alimenter ses unités supplémentaires, peut lancer 2 instructions par warp. Celles-ci ne peuvent bien entendu pas dépendre lune de lautre.
Nvidia préfère parler de fonctionnement superscalaire plutôt que vectoriel 2D étant donné que chaque scheduler peut lancer nimporte quelle combinaison dinstructions indépendantes. Pour conserver un bon rendement, le compilateur des pilotes a été modifié et va essayer dorganiser le code de manière à sadapter à cette particularité. La problématique se rapproche donc de celle dAMD, bien que ce soit dans une toute autre mesure. Si toutes les instructions sont scalaires et dépendantes, le rendement de la puissance de calcul brute des Radeon tombe à 20% alors que dans le pire des cas il restera de 66% avec le GF104. Et dans le meilleur des cas il pourra égaler le GF100 avec moitié moins de SMs !
Pour le reste, les SMs du GF104 conservent le même nombre de registres, la même mémoire de 64 Ko pour le cache L1 et la mémoire partagée (16/48 Ko ou 48/16 Ko) et le Polymorph Engine chargé dune partie des opérations géométriques telles que le vertex fetch, le culling et la tessellation. Le cache L2 global est toujours présent et lié aux contrôleurs mémoire, ce qui voit sa taille réduite de 768 Ko à 512 Ko.
Dans lensemble nous retrouvons donc une architecture optimisée pour offrir un meilleur rendement dans les jeux actuels. Elle conserve cependant une limitation importante au niveau du fillrate
Sommaire
1 - Introduction
2 - Architecture Fermi pour les joueurs
3 - Architecture (suite), spécifications
4 - Tests théoriques - pixels
5 - Tests théoriques - géométrie
6 - Les cartes
7 - Consommation, bruit
8 - Températures
9 - Overclocking, protocole de test
10 - Need for Speed Shift
11 - ArmA 2
12 - Anno 1404
2 - Architecture Fermi pour les joueurs
3 - Architecture (suite), spécifications
4 - Tests théoriques - pixels
5 - Tests théoriques - géométrie
6 - Les cartes
7 - Consommation, bruit
8 - Températures
9 - Overclocking, protocole de test
10 - Need for Speed Shift
11 - ArmA 2
12 - Anno 1404
Vos réactions
Contenus relatifs
- [+] 10/04: Nvidia : fin du support Fermi et 32...
- [+] 12/03: Nvidia lance les GeForce 800M avec ...
- [+] 08/10: Comparatif : les super GeForce GTX ...
- [+] 24/03: Nvidia répond à AMD avec la GeForce...
- [+] 17/03: Nvidia GeForce GTX 550 Ti et Asus D...
- [+] 11/03: EVGA lance une bi-GTX 460
- [+] 28/02: Nvidia annonce CUDA 4.0
- [+] 01/02: Nvidia lance une autre GeForce GT 4...
- [+] 25/01: GeForce GTX 560 Ti contre Radeon HD...
- [+] 24/01: Comparatif : 14 GeForce GTX 460 1 G...