
Les contenus liés au tag 16/14nm
Afficher sous forme de : Titre | FluxDu LGA pour Intel Skylake en 2015
Résultats Intel en baisse, perspectives 2013
Du LGA chez Intel au moins jusqu'en 2016 ?
Pas de Broadwell 14nm en 2014 sur desktop ?
Le 20nm en production chez TSMC



Lors d'une conférence dédiée à ses résultats, TSMC a donné quelques détails intéressants sur ses procédés de fabrication en cours et à venir, ainsi que répondu vivement à certaines critiques d'Intel.
Si l'on s'intéresse plutôt aux process à venir, TSMC a donné quelques nouvelles de la version 28HPM, une version high-k metal gates de son 28nm visant les hautes performances mobiles. Le fondeur indique que 100 tapeouts de la part de 60 clients différents sont attendus sur ce process cette année.
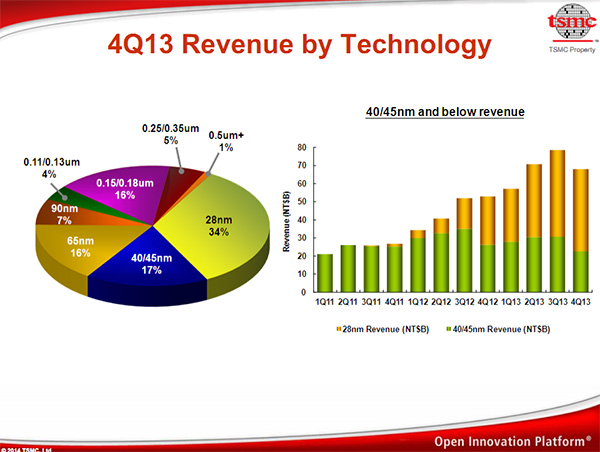
Plus surprenant, TSMC a indiqué être en avance sur son planning pour le 20nm. Prévu pour février en production en volume, le fondeur a annoncé que cette dernière avait déjà commencée dans deux fabs (12 et 14). TSMC insiste sur le volume très important attendu pour cette année, le 20nm devant compter pour 10% du revenu total de TSMC sur 2014. A titre de comparaison sur 2013, le 28nm représentait 30% du revenu de la société.
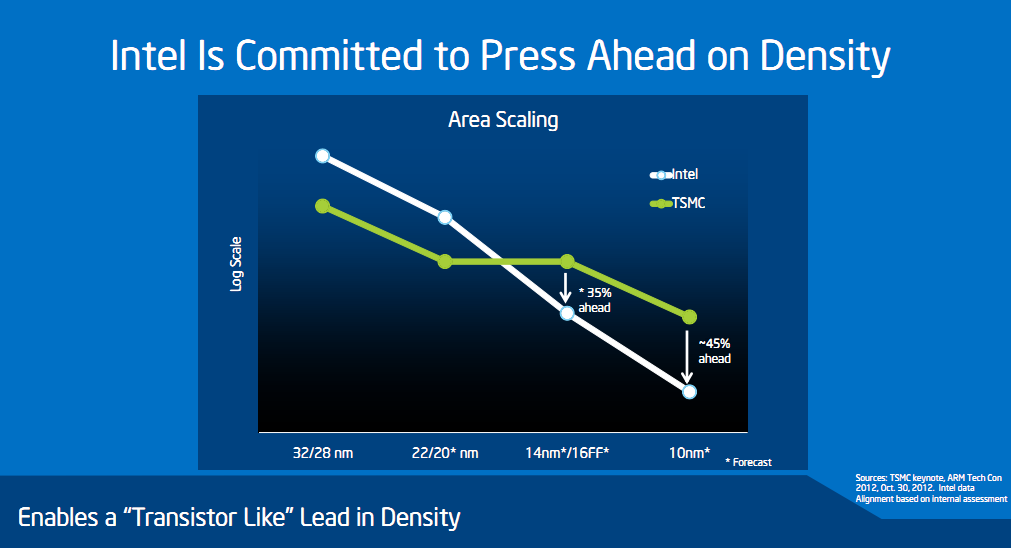
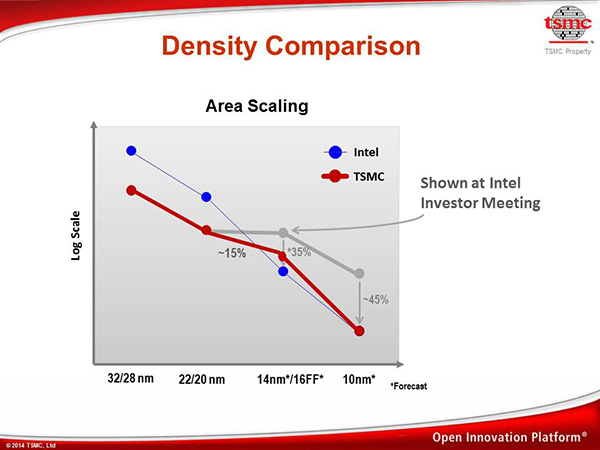
Concernant le 16nm, TSMC est revenu sur le graphique ci-dessus qu'Intel avait présenté à ses investisseurs à la fin du mois de novembre. Comme nous l'avions noté à l'époque, le graphique en plus d'être basé sur des informations assez anciennes n'était même pas exact (TSMC estimait à l'époque un gain de 5% de densité entre le 20 et le 16nm).
TSMC corrige et enfonce un peu le clou en communiquant de nouvelles informations. Le 16 nm du constructeur utilisera pour rappel des transistors FinFET (baptisés Tri-Gate chez Intel) dont les performances et la forme diffère. TSMC indique que les gains de performances obtenus sur les transistors, combinés à des améliorations au niveau de la manière dont on les place permet en pratique de voir un gain de densité de 15%.
Parmi les autres questions évoquées, le fondeur a également indiqué son scepticisme par rapport à la technologie EUV et si TSMC espère pouvoir utiliser l'EUV en 10nm, cela est plutôt considéré comme un plan B qui permettrait de réduire les couts. TSMC dispose dans ses cartons d'une solution pour le 10nm qui ne requiert pas l'EUV, quelque chose qui fait écho à ce que nous avait dit Mark Bohr en 2012 pour Intel.
On notera enfin que le fondeur a qualifié rapidement les gains attendus côté performances des transistors, un gain de 20% est attendu entre le 28HPM et le 20-SoC, et un gain de 30% entre 20-SoC et 16-FinFET. Ce dernier avait été annoncé en production en volume pour février 2015, TSMC n'a pas donné d'estimation plus précise dans sa conférence.
Intel donne quelques infos sur le 14nm
Intel tenait en fin de semaine dernière une journée dédiée aux analystes financiers, l'occasion pour nous de glaner quelques détails, plus particulièrement sur le 14nm qui était de manière fort surprenante massivement absent de l'Intel Developer Forum 2013.
En ce qui concerne le 14nm à proprement parlé, William Holt est revenu sur l'annonce du retard de Broadwell dont nous vous avions parlé précédemment. Pour rappel, Intel a indiqué qu'il décalerait le début de la production de ses puces 14nm d'un trimestre pour cause de yields plus faibles qu'attendus.
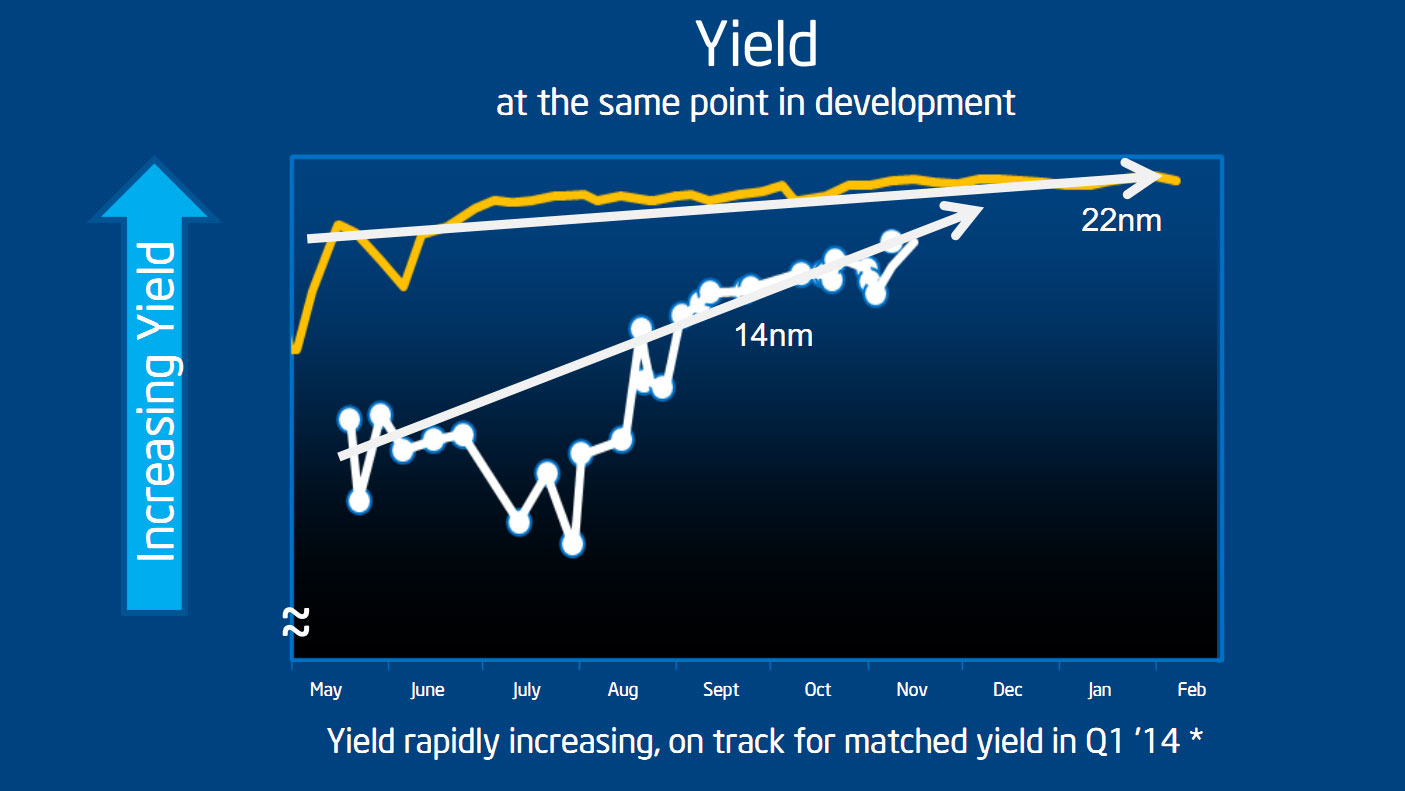
Intel a donné un peu plus d'informations sous la forme d'un graphique assez édifiant. Sur le graphique ci-dessus, Intel a dessiné l'évolution des yields (le pourcentage de puces produites « utilisables », une métrique qui n'est pas clairement définie et que William Holt indique pour vous donner son niveau de précision - comme « relativement similaire » pour les deux cas) sur deux ans à la fois pour le 22nm et pour le 14nm. Ces deux courbes montrent donc, en théorie, des yields à des niveaux de développement et d'avancement comparables, c'est comme cela en tout cas que les a présentées William Holt. Comme toujours sur ces graphiques forts sensibles, l'échelle n'est pas précisée, un point sur lequel nous allons revenir. Le commentaire d'Intel est que les yields étaient significativement en retard même si des progrès récents sur les derniers mois montrent que le 14nm (en blanc) se rapproche du 22nm avec pour but d'être au niveau du 22 nm au premier trimestre prochain.
Intel indique que le délai au-delà de la mise en production est surtout lié aux conséquences des faibles yields sur l'année précédente qui ont « diminué le nombre de bonnes unités » disponibles pour les différentes phases de tests, validation ou développements annexes (les drivers). Des propos que l'on peut comprendre pour le public visé (les investisseurs) qui préfèrent entendre que le problème est derrière plutôt que devant. Nous nous devons cependant de modérer quelque peu l'enthousiasme du constructeur.
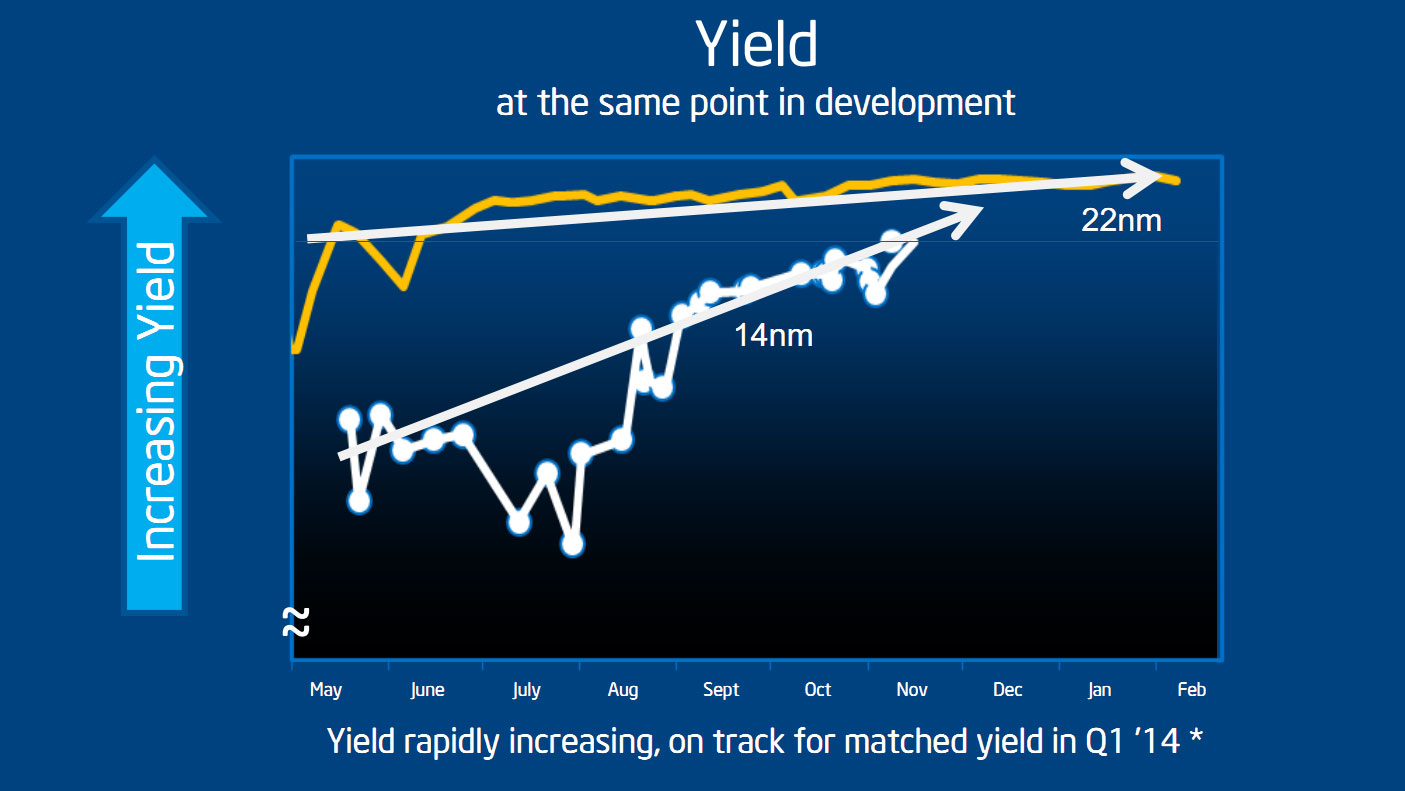
D'abord, nous avons tracé sur ce graphique en rouge le niveau du dernier point (indiqué comme un peu avant ou après la mi-novembre selon que l'on se fie au point ou à la ligne à laquelle il devrait être attaché ). Si l'on regarde précisément ou Intel en est aujourd'hui, les yields 14nm ont donc actuellement six mois de retard sur le 22nm, et non trois. La prédiction d'un rattrapage des yields pour le premier trimestre est donc avant tout basée sur la capacité d'Intel à rattraper ce qui ressemble à un tout petit gap sur cette échelle du graphique.
C'est l'autre point qui nous interpelle puisque pour rappel, la ligne jaune court de mai 2011 à février 2012, Ivy Bridge avait été lancé pour rappel en avril 2012. Or, si nous ne disposons pas d'un autre graphique de yields plus précis sur le 22 nm, Mark Bohr avait lors de l'IDF 2012 fourni le slide ci-dessous.
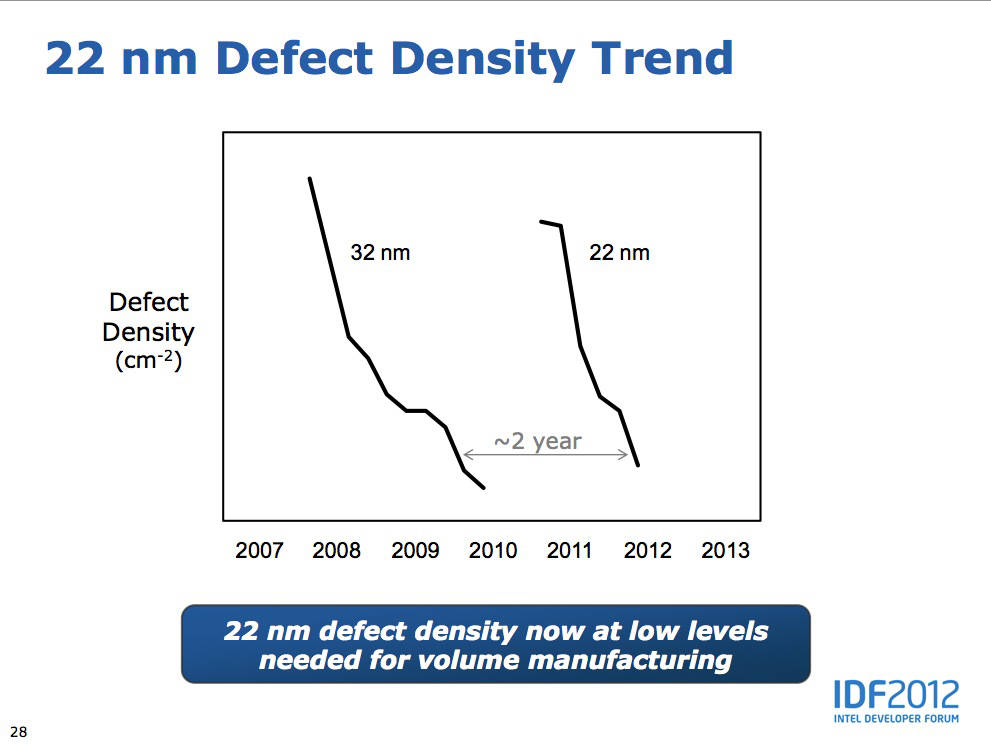
Ce slide mesure (avec une ambiguïté dans les échelles largement équivalente, pour ne pas dire supérieure !) la densité de défauts, ce qui n'est pas exactement l'inverse des yields même si les deux quantités sont inversement liées. Au minimum, on peut deviner qu'entre 2011 et 2012, l'évolution de la densité des défauts semble un peu plus dynamique que les yields très plats annoncés. Sans pouvoir en avoir la certitude, nous pensons que l'échelle du graphique de yields fournie par Intel est très compressée, diminuant quelque peu la réalité du travail restant à accomplir.
Cela ne remet bien entendu pas en cause la capacité d'Intel à lancer sa production ou ses futurs produits. Tant bien même que le rattrapage soit un peu plus long que prévu, le constructeur peut par exemple accepter de lancer la production avec des niveaux de yields un peu en dessous de ce qu'il attendait en rognant sur ses marges, ou lancer dans des volumes de production plus faibles le temps que le reste du travail (perpétuel) sur les yields se termine. Il faut également rappeler que Broadwell sera lancé de manière assez différente à ce qui s'était passé jusqu'ici chez Intel, dans un premier temps uniquement en format BGA pour les plateformes mobiles (qui sont toujours plus longues à adopter les nouvelles puces) puis, pour la fin d'année dans une version desktop qui cohabitera avec un Haswell Refresh en 22nm.
Ce changement des règles de lancement ne sera pas sans aider le constructeur et il serait fort intéressant de savoir en quelle mesure l'état du process 14 nm à influé sur la décision de ne pas lancer Broadwell en premier sur desktop comme à l'habitude. Une information qui avait filtré il y a un an de cela (soit six mois en amont du premier point de yield indiqué sur le graphique) et que l'on avait mise sur le compte de la volonté d'Intel de pousser sur la mobilité au détriment du desktop. Si la volonté sur la mobilité est bien entendu réelle, on aimerait savoir en quelle mesure l'état d'avancement du process 14nm a joué sur la décision.
Une chose est en tout cas certaine, si Intel n'a communiqué qu'il y a quelques semaines officiellement sur les problèmes de son 14nm, le constructeur était conscient de ces problèmes bien en amont. On notera que dans les questions/réponses, William Holt aura indiqué que si ce n'est pas la première fois qu'Intel rencontre des problèmes de yields de ce type, c'est la première fois depuis « un certain nombre de générations ».
On notera aussi un sous-entendu sur le multiple patterning, l'augmentation de son utilisation dans de plus en plus de couches des puces conduit à des interactions problématiques et complexes à débuguer. Officiellement Intel n'a pas vraiment dévoilé les différences entre le 22 et le 14nm, à part qu'il s'agira d'une seconde génération de tri-gate mais une augmentation du multiple patterning semble être au programme. On se souviendra que la Common Platform avait aussi fait ce choix (un peu contraint) dès le 20nm.
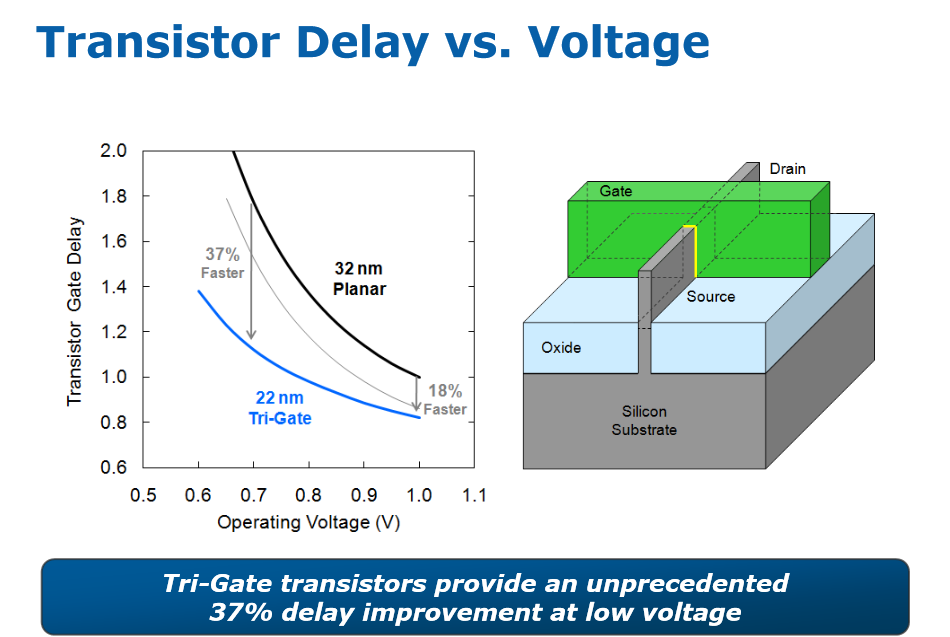
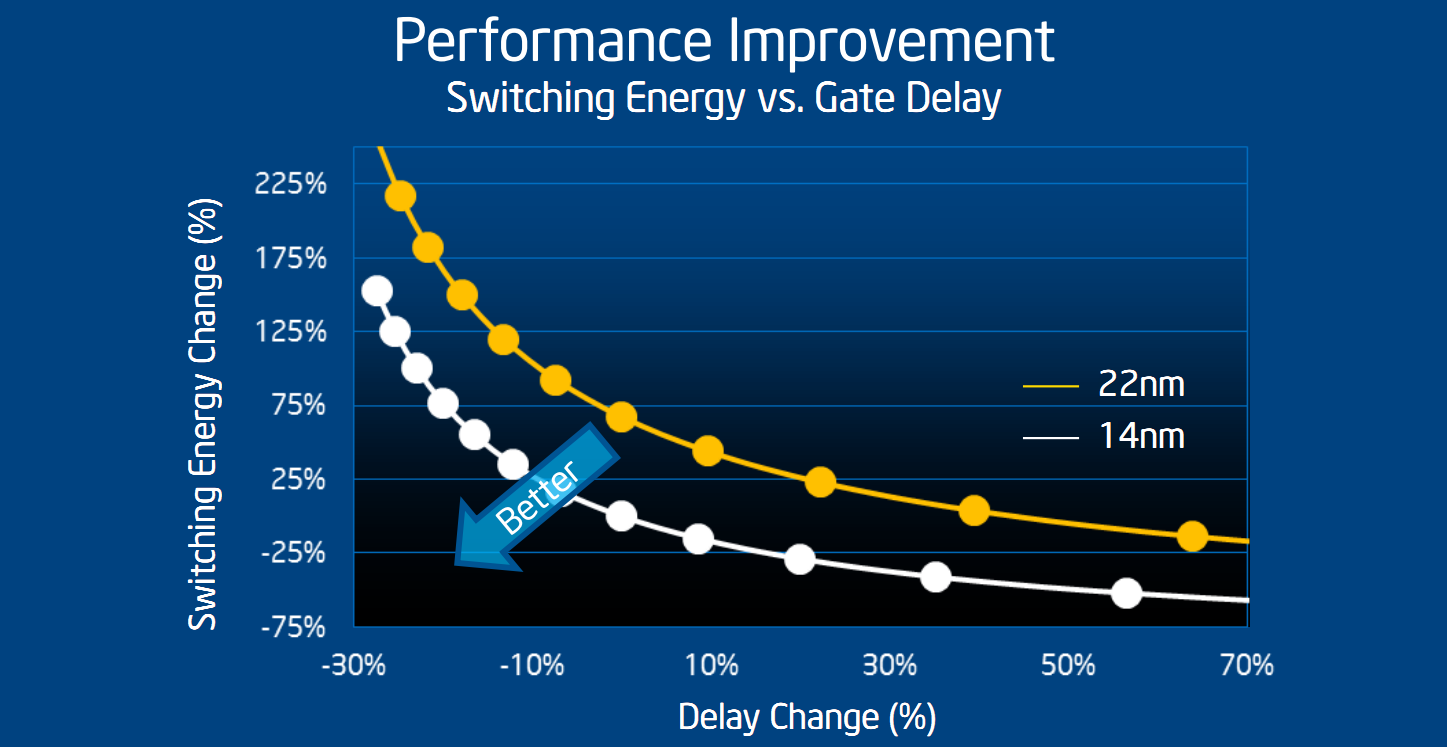
A gauche, une comparaison 32/22nm fournie par Intel à l'IDF 2011, à droite, le slide présenté par Intel comparant 22/14nm
Au-delà de tout ceci, Intel a également, par le biais d'un slide, donné un petit aperçu de ce qu'apporterait le 14nm. Là encore difficile d'en tirer quoique ce soit, à titre indicatif nous avons ajouté un graphique du même type comparant le 32 et le 22 nm. Attention cependant aux comparaisons hâtives. D'une, Intel a inversé les axes ce qui renverse quelque peu la donne et de deux, aucun point de référence n'est donné sur les axes, Intel se contentant d'indiquer des pourcentages. Difficile donc d'en tirer quoique ce soit si ce n'est que l'on attend un gain probablement un peu plus faible sur la vitesse des transistors qu'au passage 32-22 (les gros gains que l'on devine en bas à droite du second graphique sont à très faible tensions ils correspondent au haut à gauche du graphique de gauche, ce qui ne correspond pas forcément aux tensions qu'Intel utilisera en pratique).
La production de Broadwell repoussée d'un trimestre
Lors de la présentation de ses résultats financiers pour le troisième trimestre 2013, Brian Krzanich, CEO d'Intel a indiqué que la mise en production des puces Broadwell serait repoussée d'un trimestre, et ne commencerait donc qu'au cours du premier trimestre 2014. Pour rappel, la mise en vente de Broadwell était attendue jusqu'ici pour le second semestre 2014.
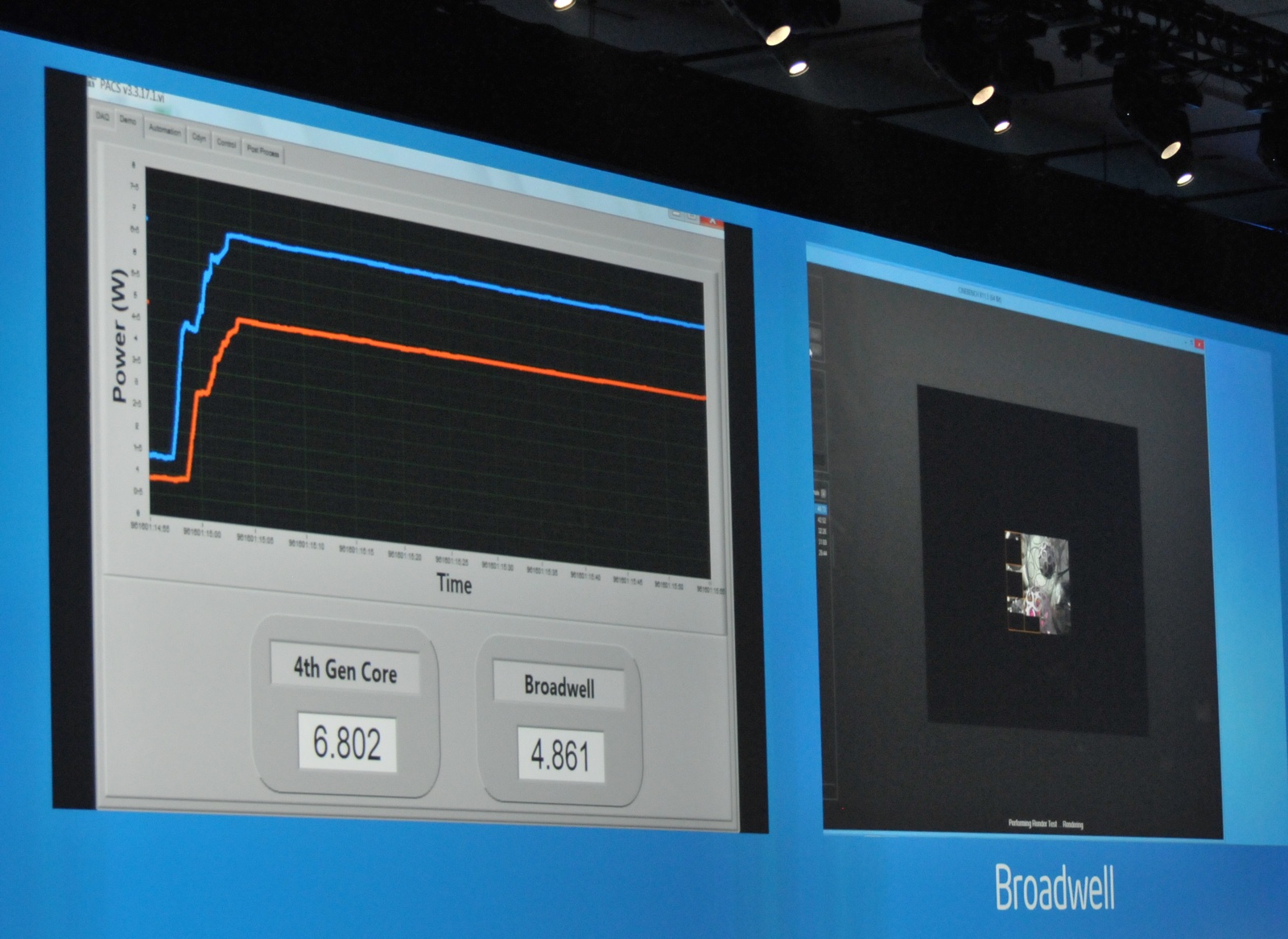
Selon le CEO d'Intel, le retard a été causé par des yields plus faibles qu'attendus sur le 14nm. Une demi surprise étant donné que si Broadwell avait été montré rapidement lors de l'IDF, Intel n'avait pas évoqué en détail son process durant sa conférence contrairement à ses habitudes (Mark Bohr était même absent de la conférence). Intel indique avoir entrepris des actions correctives et indique rester confiant sur les yields, tentant d'insister sur le fait qu'ils sont simplement en retard sur les projections, et qu'il ne s'agirait pas d'un problème plus complexe à résoudre.
Notez enfin que le CEO a indiqué qu'aucun impact n'est attendu sur Skylake, la génération suivante attendue en 2015.
Des SoC Atom et Broadwell 14nm en 2014
Intel a dévoilé un peu de ses projets dans le domaine de processeurs et SoC basse consommation destinés à sa gamme Xeon.
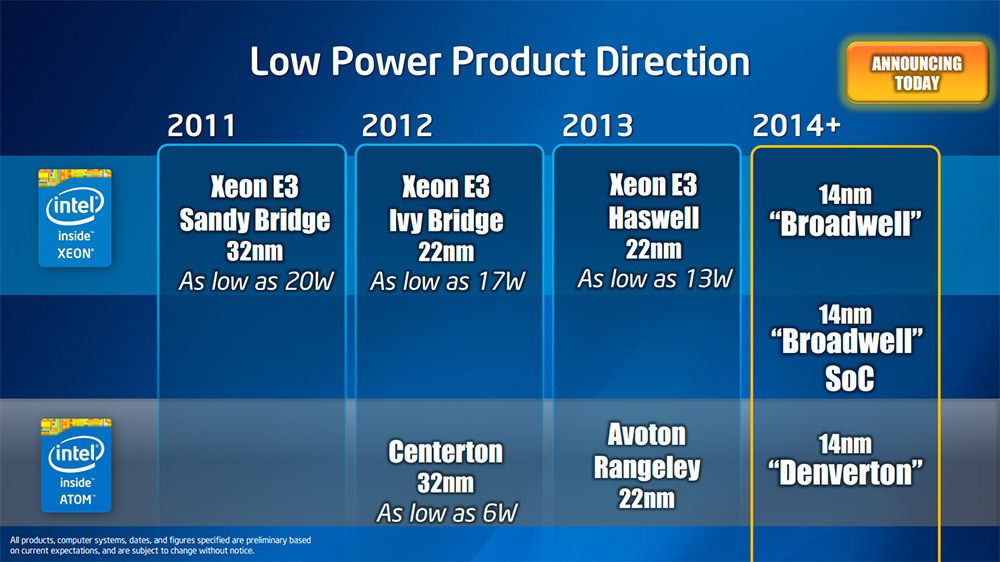
On le sait depuis 2011, Intel a pour projet pour 2014 de décliner son architecture basse consommation sur la même finesse de gravure que son architecture haute performance. On devrait donc voir débarquer dès 2014 de nouveaux Atom basés sur l'architecture Airmont, le nom de code de ces nouveaux SoC est Denverton.
Ce ne seront toutefois pas les seuls produits 14nm destinés au monde serveur pour 2014. Broadwell, le "Tick" 14nm de Haswell, ne sera finalement pas seulement confiné au monde du portable puisqu'il sera également décliné sur Xeon mono processeur (et a priori en LGA, reste à savoir si la compatibilité avec les cartes mères existantes sera assurée).
Mais l'annonce la plus intéressante est l'arrivée d'un SoC basé sur l'architecture Broadwell. Pour le moment l'architecture la plus performante d'Intel n'a jamais été déclinée en tant que SoC, tout au plus avons-nous une version de Haswell destinée au portable qui embarque sur le même packaging un die CPU et un die chipset.

Attention toutefois, il est ici question d'un SoC pour la gamme Xeon et il n'est pas dit qu'Intel développera dès Broadwell un SoC pour la gamme grand public. En effet les SoC Xeon sont tout de même assez spécifiques. Les futurs SoC Atom C2000 22nm (Avoton et Rangeley) prévus pour la fin de l'année intégreront par exemple 4 contrôleurs Gigabit Ethernet, mais pas d'USB 3.0.
16nm en 2013, 10nm EUV en 2015 chez TSMC
Nos confrères d'EE Times ont publié le résumé d'une présentation par TSMC de ses nodes à venir, un article dans lequel on peut relever quelques informations intéressantes.
TSMC revient d'abord rapidement sur l'état de son node 28nm. Sa Gigafab 15 produirait aujourd'hui 50000 wafers dans ce node par mois. Cette quantité devrait cependant rapidement doubler avec la mise en route de la seconde tranche de la Gigafab 15. La production devrait démarrer d'ici un mois et arriver, d'ici cinq mois, à un débit de production identique à la première tranche.

En ce qui concerne le 20nm, TSMC donne quelques détails intéressants. Avec l'arrivée du double patterning sur ce node, les gains habituels de densité et de performances devraient être réduits, une tendance que l'on avait déjà entendue du côté de la Common Platform. Le 20nm sera vraisemblablement un node de transition vers le FinFET (le node suivant en 16nm), même si TSMC se refuse de le dire. Côté performances, quelques chiffres ont été donnés à savoir 20% de fréquence en plus, ou 30% de consommation en moins par rapport au 28nm, ce qui reste tout de même assez élevé. Une vingtaine de tapeouts sont attendus cette année dans les Gigafab 12 et 14 avec une production en volume pour 2014. Parmi ceux-ci, un Cortex-A15 20nm est attendu pour le mois de mai.
Pour le 16nm, le développement du node est actuellement en cours en parallèle, on se souvient de cette annonce en début de mois d'un premier tapeout de Cortex-A57. Assez peu de détails sont donnés, si ce n'est que les premiers wafers de tests clients pourraient être lancés vers la fin de l'année avec une production qui monterait (probablement très doucement) en volume en 2014. Actuellement, TSMC travaille principalement sur des structures SRAM 128 Mbit dont les yields sont en avance par rapport aux estimations. Si les blocs logiques ont déjà été testés (cf l'annonce du Cortex), les blocs d'interface (mémoire ou autre) devraient commencer à être testés en juin.
De manière beaucoup plus surprenante, TSMC à indiquer espérer produire d'ici 2015 des wafers 10nm utilisant la technologie EUV. Pour rappel, TSMC a investit également dans le fournisseur d'outils ASML.

Une machine EUV ASML
La firme se réserve cependant assez prudente, indiquant qu'elle ne dispose toujours pas du dernier modèle d'outil de ASML (le NXE:3300 ). TSMC indique également continuer a travailler sur une technologie alternative pour ce node, le multiple electron beams sur lequel TSMC avait annoncé travailler avec MAPPER . La particularité de la technologie est qu'il ne s'agit plus littéralement de photolithographie, le masque disparaît et la source lumineuse est remplacée par des flux d'électrons qui viennent réagir avec un film préalablement déposé sur le wafer. Le débit de ces machines est qualifié par TSMC "d'encore trop lent", même s'il n'est pas comparé à celui, lui aussi très lent, de la technologie EUV actuellement (nous vous renvoyons a cette interview ou Mark Bohr évoquait le problème).
On notera enfin quelques informations sur les technologies de die stacking et les progrès en matière de 2.5D et 3D. Le concept du die stacking consiste à relier plusieurs dies directement entre eux par une couche de silicium, sans nécessiter de fils (des TSVs, Through Silicon Vias, sont utilisésà la place, ce qui permet d'augmenter significativement la bande passante et réduire la complexité). Les technologies dont on parle visent à terme à relier plusieurs dies logiques entre eux même si ce n'est pour l'instant qu'un objectif lointain.
La technologie 2.5D consiste à placer côte a côte deux dies, qui reposent sur un interposer qui contient lui-même des TSV pour interconnecter les dies. L'épaisseur de cet interposer est actuellement de 100nm mais devrait se réduire de moitié. Xilink propose actuellement un FPGA fabriqué sur le process 28HPL de TSMC qui interconnecte quatre dies, le Virtex 7 2000T.

Sur cette photo de nos confrères de 52solution , vous pouvez voir à gauche les quatre dies logiques et l'interposer. La puce assemblée est en quatrième position.
TSMC indique que les yields obtenus dépassent les 95% sur les interposers utilisés pour cette puce et plusieurs autres tape-outs devraient avoir lieu cette année, sans plus de précision. TSMC continue de travailler sur le sujet de Wide I/O avec des puces de test qui lient un die 40nm avec une puce mémoire Hynix, un montage qui a passé les tests de validation du JEDEC.
En ce qui concerne la superposition de dies (la "vraie" 3D), TSMC pense effectuer le tapeout d'une puce 28nm avec sur chaque couche des dies mémoire, avant de passer au mélange logique/mémoire. Il faudrait cependant attendre 2015 ou 2016 pour retrouver ces puces en production selon TSMC.
Notons enfin qu'en ce qui concerne le 450mm (la taille des wafers, elle est actuellement de 300mm de diamètre pour les nodes haut volume de TSMC), la production ne devrait pas démarrer au mieux avant 2016 voir 2017 malgré des tests en cours. Les outils EUV sont ceux qui poseront - là encore- le plus de problème selon TSMC, ils pourraient ne pas arriver avant 2017 en version 450mm.