
Les contenus liés au tag GlobalFoundries
Afficher sous forme de : Titre | Flux181 millions de pertes pour AMD
22nm FD-SOI chez GlobalFoundries
Premières puces en 7nm pour IBM !
Prévisions AMD en baisse
14nm dans les temps chez Samsung, en retard chez GloFo?
12nm FD-SOI pour GlobalFoundries



GlobalFoundries vient de publier un communiqué de presse indiquant l'arrivée d'un nouveau process FD-SOI sur sa roadmap, le 12FDX. Il s'agira d'une troisième version de FD-SOI proposée par le fondeur, après un 28nm offert en partenariat avec STMicroElectronics, et un 22nm fabriqué dans l'usine de Dresde.
Ce 12nm FD-SOI sera lui aussi fabriqué dans l'usine de Dresde et visera principalement les applications mobiles et les usages basse consommation, à l'image du positionnement du 22FDX. Il sera également possible de l'utiliser pour des puces radio (RF).

GlobalFoundries décrit ce process comme équivalent à un 10 FinFET côté performances, avec une meilleure consommation et un cout inférieur au 16 FinFET actuel. La société estime qu'il proposera 15% de performances en plus et 50% de consommation en moins que les process FinFET 14/16 actuels.
Si l'on pourrait croire que ce 12FDX viendra combler le creux dans la roadmap FinFET de GlobalFoundries, qui passera pour rappel d'un 14nm sous licence Samsung directement à un 7nm développé en interne, en pratique il n'en sera rien. A l'image du 22FDX qui n'a été lancé que l'année dernière, le communiqué évoque 2019 pour les premiers tape-out (soit encore plus loin pour les volumes commerciaux).
A titre de comparaison, TSMC, Samsung et Intel devraient produire en volume le 10 FinFET l'année prochaine.
Nouvel accord WSA entre AMD/GlobalFoundries
AMD vient d'annoncer par un communiqué avoir négocié un sixième amendement de son contrat cadre les liant à GlobalFoundries. Pour rappel, AMD avait transféré fin 2008 son activité fabrication (ses usines) dans une nouvelle entité (FoundryCo) détenue à l'époque en partie par AMD (44%) et par ATIC, un fond souverain d'Abu Dhabi. Une société que l'on connaît désormais commercialement sous le nom de GlobalFoundries, et qui est, depuis 2012, complètement indépendante d'AMD.

En 2009, AMD et FoundryCo (que l'on appellera GloFo par la suite pour simplifier, même si tous les accords sont encore aujourd'hui signés au nom de FoundryCo) avaient signé un accord cadre, appelé Wafer Supply Agreement. Cet accord obligeait AMD a acheter un certain volume de wafers (les galettes de silicium qui servent à la fabrication des puces) chez GlobalFoundries, avec des exclusivités pour tout ce qui concernait les CPU (MPU dans les documents), ainsi qu'un "plan" pour la fabrication exclusive à terme de GPU.
L'accord n'est pas totalement public, les très curieux pourront en retrouver une version sur le site de la SEC américaine . De nombreux détails confidentiels n'apparaissent pas. Le contrat court au minimum jusque mars 2019 et au maximum jusqu'en 2024.
Si l'accord est souvent décrit comme un poids pour AMD, on notera que le contrat dispose d'un grand nombre de clauses contraignantes pour son partenaire, concernant par exemple les yields, et le développement de nouveaux process. Et si les exclusivités indiquées plus haut sont dans le document, des mécanismes de "second source", autorisant AMD a aller fabriquer un certain volume de puces chez un concurrent de GloFo dans certaines conditions, particulièrement en cas de défaillance sur certains points techniques.
Reste qu'au fil des années, AMD et GloFo ont amendé ces accords, d'abord en 2011 en changeant les modalités de paiement sur le 32nm (paiement par puce fonctionnelle au lieu d'un prix fixe par wafer, pour tenter de compenser les mauvais yields de l'époque). En 2012, le second amendement au contrat repassait à un prix par wafer, mais levait certaines exclusivités sur la fabrication d'APU (pour un coût élevé de 703 millions de dollars).
L'amendement signé fin 2012 était beaucoup plus tendu, insistant sur les obligations d'AMD à utiliser GlobalFoundries, et forçant AMD a payer des pénalités (de 320 millions de dollars) pour ne pas avoir utilisé tout le volume négocié lors du précédent amendement. L'accord de volume est en effet de type take-or-pay, un volume de wafers est défini au début d'une période et si AMD ne fait pas produire ce volume, il doit payer des pénalités équivalent au prix des wafers qu'il aurait du commander.
Le quatrième amendement signé en mars 2014 prévoyait encore une fois de pousser la transition des APU consoles et des GPU vers GloFo. Le dernier amendement en date avait été signé en avril 2015 et montrait une fois de plus la tension entre les deux sociétés, la question de la fabrication des APU des consoles par TSMC semble au coeur du malaise, le document accuse aussi AMD d'avoir "renommé" certains produits par rapport à l'accord précédents pour se défaire de ses obligations (la partie rédigée de l'accord indiquerait, pour chaque produit, si l'exclusivité de GlobalFoundries s'applique ou non).
GlobalFoundries est bien entendu loin d'être innocent dans ces problèmes même si cela ne se lit pas dans les amendements ou AMD est quasi systématiquement pointé du doigt. On se souviendra de l'incapacité de GloFo a mettre au point ses process 20nm et 14nm, optant au final pour prendre sous licence le process 14nm de Samsung fin 2014.

Polaris P10, GPU fabriqué par GlobalFoundries
Les tensions semblaient cependant s'amenuiser ces derniers mois, AMD validant fin 2015 le process 14nm de son partenaire. On aura même vu arriver - enfin - des GPU fabriqués chez GloFo avec les Polaris/RX 480, ce qui laissait penser qu'AMD aurait un peu moins de mal a tenir les volumes d'achats imposés par le contrat cadre.
C'est dans ce contexte qu'AMD et GlobalFoundries viennent donc d'annoncer le sixième amendement au Wafer Supply Agreement. Plutôt que de renégocier tous les ans l'accord, cet amendement porte pour une période de cinq années, allant de janvier 2016 jusqu'au 31 décembre 2020 (soit au delà de la date théorique minimale de fin du contrat).







Le texte complet n'est pas encore disponible sur le site de la SEC, on se contentera donc de la présentation d'AMD à ses investisseurs que vous pouvez retrouver ci-dessus.
Le premier point à noter est que le modèle take-or-pay est enfin mis de côté. Il est remplacé par des "objectifs" d'achats annuels qui ont, qui plus est, été revus à la baisse. Ces objectifs étaient de 1.2 milliards de dollars en 2014 et 1 milliard en 2015, des chiffres complexes a atteindre pour le constructeur qui aura enchaîné les pénalités ces dernières années.
Pour 2016, l'accord prévoit seulement 650 millions de dollars, un chiffre beaucoup plus raisonnable, et les objectifs augmenteront annuellement, dans une proportion pour l'instant non indiquée. Les pénalités ne porteront que sur une portion de l'objectif non tenu (et non la totalité, comme dans un accord take-or-pay).
En ce qui concerne le coût des wafers, ils seront fixes pour 2016 et un système est mis en place pour les recalculer chaque année. GlobalFoundries et AMD collaboreront pour le développement du 7nm même si en pratique aucun détail n'est donné.
AMD s'offre également plus de flexibilité, les exclusivités dont nous parlions dans les amendements précédents semblent (au moins en partie) levées et AMD pourra choisir librement de fabriquer des puces, par exemple, chez TSMC.
GlobalFoundries ne fait bien évidemment pas ces concessions gratuitement. AMD va effectuer un paiement de 100 millions de dollars à son partenaire (sur quatre trimestre à compter du dernier trimestre 2016) et va également donner un mandat d'achat de 75 millions d'actions à une filiale de Mudabala (le nouveau nom d'ATIC, maison mère de GlobalFoundries). Le coût de l'opération est de 235 millions de dollars et empeche Mudabala de prendre une participation dans le capital d'AMD de plus de 20%.
Dernière concession faite par AMD, et non des moindres, la société devra effectuer un paiement à GlobalFounrdies chaque trimestre, sur ses volumes de productions effectués chez ses concurrents (comme TSMC ou Samsung). Le montant à payer n'est pas précisé.
En résumé...
Sans les détails exacts, il est très difficile de porter un jugement définitif sur l'accord, mais un certain nombre de points semblent aller dans le bon sens pour AMD.
Si la société avait jusqu'ici continué à utiliser TSMC pour la fabrication de GPU et de certains APU, cela était surtout lié à l'incapacité de GlobalFoundries de tenir ses engagements techniques. Sur le 14nm, les choses ont changées, ce qui nous a valu l'arrivée des Polaris, fabriqués chez GlobalFoundries. L'existence des clauses d'exclusivités risquaient d'empêcher AMD de facto à utiliser TSMC pour la fabrication de GPU.

Ce nouvel accord permet donc a AMD de choisir un peu plus librement entre GlobalFoundries et TSMC pour certains produits, ce qui ne peut qu'être une bonne chose. Devoir effectuer un paiement chaque trimestre sur la fabrication de puces chez TSMC jouera sur les marges d'AMD, mais cela reste un moindre mal à nos yeux, au moins pour le court terme. Cumulé aux pénalités réduites et aux objectifs d'achats revus à la baisse, on pourrait penser à priori que sur un pur plan financier, l'accord semble avantager un peu plus AMD que les accords précédents, quasi à sens unique.
Il ne faut pas oublier que si les choses se sont apparemment arrangées techniquement pour le 14nm chez GlobalFoundries, c'est avant tout grâce à la licence prise chez Samsung. Et pour le 7nm (GlobalFoundries saute pour rappel le 10nm), il s'agira à nouveau d'un développement interne. En cas de retards de GlobalFoundries sur le 7nm (ce qui, une fois de plus, est loin d'être impossible), AMD devrait pouvoir déporter plus facilement sa production chez TSMC (ou éventuellement Samsung) plutôt que de se retrouver lié par les clauses d'exclusivité.
Intel Custom Foundry prend une licence ARM !
 ARM l'a confirmé par un post de blog : Intel Custom Foundry, l'activité fabrication tiers d'Intel, est désormais détentrice d'une licence ARM Artisan pour le 10nm !
ARM l'a confirmé par un post de blog : Intel Custom Foundry, l'activité fabrication tiers d'Intel, est désormais détentrice d'une licence ARM Artisan pour le 10nm !
Il faut rappeler qu'Intel est plutôt un cas à part dans le monde des semi-conducteurs, étant l'une des rares sociétés à disposer de ses propres usines, utilisées quasi uniquement pour la production de ses propres puces. La plupart des autres acteurs du marché ont migré vers la séparation de l'activité design d'un côté (on parle de sociétés fabless, c'est le cas dans le monde du GPU avec AMD et Nvidia), et de l'autre la fabrication dans des sociétés tierces spécialisées (on parle de foundry, la plus connue étant TSMC qui fabrique des puces pour de multiples clients).
Avec la difficulté de la mise au point des nouveaux process de fabrication, qui n'a fait qu'empirer ces dernières années, il est de plus en plus complexe pour une société à elle seule de justifier l'investissement nécessaire pour faire évoluer sans cesse ses usines. Qui plus est, la réduction de la taille des transistors fait que la capacité des usines augmente d'année en année, et qu'il faut disposer de très larges volumes de puces à produire, au risque de voir ses usines tourner à vide.
Un casse tête qui aura poussé plusieurs sociétés à se séparer de leurs usines (pour des raisons différentes) d'abord AMD en 2009 (créant GlobalFoundries) et plus récemment IBM (dont l'activité fabrication à été rachetée elle aussi par GlobalFoundries).
Depuis quelques années, en plus de fabriquer ses propres puces dans ses usines, Intel a décidé d'entrer très timidement, en 2010, sur le marché des fondeurs tiers en ouvrant son process à de petites sociétés qui n'étaient pas en concurrence directe avec ses produits (le premier client était Achronix, designer de FPGA en 22nm). D'autres clients ont suivi, principalement sur les FPGA, le client le plus connu d'Intel ayant été Altera... même si au final Intel aura décidé de racheter son client à la mi-2015 !
Pour Intel, la nécessité d'ouvrir ses usines est un casse tête. D'un côté, la société tente d'être présent sur tout les marchés, en déclinant le x86 - technologie "maison" sur laquelle la concurrence est limitée - à toutes les sauces et avec un soupçon de recyclage, que ce soit avec des produits serveurs spécialisés comme les Xeon Phi basés sur des Pentium pour leur première génération, ou les Quark dédiés à l'embarqué et utilisant une architecture de 486 datant d'une bonne vingtaine d'années !
Si l'envie de la société d'être présente sur tous les marchés est là, en pratique les succès ne sont pas systématiquement au rendez vous, Intel ayant par exemple massivement raté le marché des smartphones. Cumulé à la baisse continue des ventes sur le marché historique des PC, l'ouverture des usines à des clients tiers se dessine de plus en plus comme une nécessité pour Intel, même si l'avouer semble impossible à la société, qui continuait donc d'envoyer des signaux mitigés aux possibles futurs clients de son activité fabrication.
Avec l'annonce d'aujourd'hui, les choses sont - peut être - en train de changer puisque la prise de licence ARM par Intel est tout sauf anodine. Ce n'est pas la première fois qu'Intel fabriquera des SoC ARM, on l'avait vu avec Altera qui utilisait un core ARM dans un usage très spécifique.
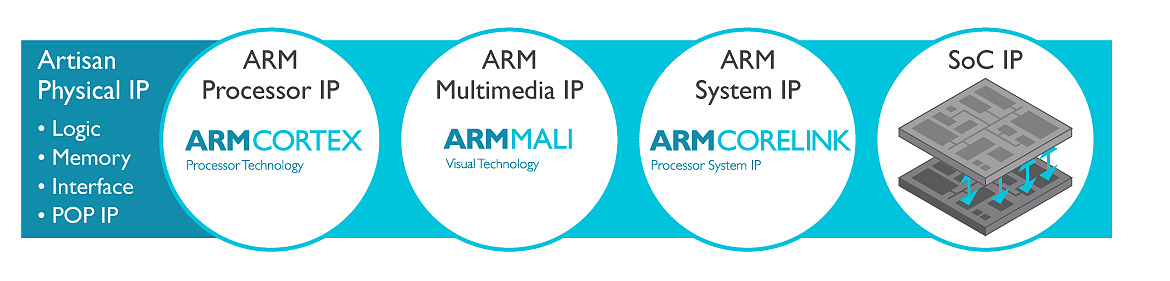
La licence Artisan Physical IP inclut en effet toutes les briques nécessaires pour la création de puces ARM de tout types. Il s'agit de tous les blocs de base avec des bibliothèques haute densité et haute performance de transistors logiques,et également tout le nécessaire pour les différents types de mémoire. La licence inclut surtout POP IP, qui est pour rappel l'idée qui fait le succès d'ARM : permettre l'utilisation de blocs interchangeables et compatibles pour créer des puces custom. Ainsi un client peut choisir d'utiliser des coeurs CPU dessinés par ARM (les gammes Cortex) ou créer ses propres coeurs (c'est le cas d'Apple et plus récemment de Nvidia), de choisir un GPU (que ce soit les Mali d'ARM, ou les populaires PowerVR d'Imagination Technologies), et également de choisir son fournisseur pour les interconnexions.
Concrètement, Intel va donc "porter" ces bibliothèques d'ARM aux particularités de son futur process 10 nm, ce qui permettra aux partenaires d'ARM de porter à leur tour - s'ils le souhaitent - leurs blocs POP IP. ARM et Intel travailleront conjointement pour le portage de deux futurs blocs CPU ARM Cortex-A (probablement un autre successeur 10nm de l'A72, voir l'annonce de l'A73 en 10nm lui aussi), la déclinaison que l'on retrouve dans les smartphones et tablettes.
Faut il y voir un virage pour Intel ? Fabriquer des puces ARM pour smartphones, ce qu'ils feront pour LG (nouveau client annoncé dans la foulée) va forcément à l'encontre des ambitions internes d'Intel d'imposer le x86 sur mobile. Car si un peu plus tôt dans l'année Intel avait décidé d'annuler sa nouvelle génération de SoC pour smartphones (Broxton et SoFIA), le constructeur continuait en interne à travailler sur les générations suivantes tout en essayant de développer dans l'intérim son activité modem (Intel aurait possiblement gagné le marché du modem du prochain iPhone). A l'heure où ARM augmente ses ambitions pour aller attaquer le marché juteux des serveurs, on peut se demander jusqu'où ira réellement l'ouverture d'Intel.

Un futur CPU ARMv8 24 coeurs de Qualcomm
En fabriquant des puces concurrentes, Intel s'ouvre à des comparaisons directes qui pourraient être assez défavorables à ses architectures x86, assez peu adaptées à la basse consommation. L'avantage supposé du process d'Intel, s'il existe, ne pourra plus jouer en la faveur de ses propres solutions pour compenser un éventuel déficit architectural. La structure de marges d'Intel, là aussi très différente de celle des fondeurs tiers, posera là aussi rapidement problème.
Qui plus est, en obtenant la licence Artisan d'ARM, Intel va devoir partager tous les détails techniques, y compris les plus secrets, de son process en ce qui concerne les règles et les dimensions exactes des transistors, ce qui va l'exposer là aussi à une comparaison directe avec les autres acteurs installés du milieu (comme TSMC et Samsung). Il faudra un peu de temps pour mesurer les conséquences concrètes de tout cela, car cet accord ne concerne que le 10nm, un process pour rappel en retard et qui n'est prévu chez Intel que pour la fin de l'année 2017 en version mobile. Les dernières nouvelles du 10nm, sur lequel Intel ne communique pas, n'étaient pour rappel pas particulièrement rassurantes avec l'arrivée possible sur sa roadmap de puces 14nm... pour 2018.
AMD annonce Polaris, sa future architecture GPU
Enfin, après 4 années de GCN en 28nm, les Radeon vont accueillir une nouvelle architecture gravée en 14nm : Polaris. Et pour AMD le focus se portera sur l'efficacité énergétique avec un bond en avant annoncé sans précédent !

Le Radeon Technology Group d'AMD profite de ce début d'année pour lever un (très petit) coin du voile qui entoure sa prochaine génération de GPU, notamment en donnant un nom de code à son architecture : Polaris (l'étoile polaire). Et pour positionner sans équivoque ses objectifs avec cette architecture, AMD explique avoir opté pour ce nom de code en faisant le parallèle entre l'efficacité des étoiles à générer des photons et l'efficacité demandée aux GPU pour générer des pixels.
Comme vous le savez, l'architecture actuelle des Radeon est globalement en retrait par rapport à l'architecture Maxwell de Nvidia au niveau de l'efficacité énergétique. Fort de larges parts de marché et ayant bien anticipé le très long passage par le procédé de fabrication 28nm (exploité pour les GPU depuis 4 ans déjà !), Nvidia a développé deux architectures pour celui-ci : Kepler et Maxwell. En face, AMD est resté sur une architecture GCN moins efficace en se contentant d'évolutions mineures de son cur. Pourquoi ? Probablement parce que, contrairement à Nvidia, AMD avait parié sur l'exploitation d'un procédé en 20nm qui ne s'est jamais concrétisée pour les GPU.
Tout cela va enfin changer en 2016 avec l'arrivée de GPU fabriqués en 16nm FinFET+ chez TSMC et en 14nm LPP chez GlobalFoundries et Samsung. Ces nouveaux procédés de fabrication ont pour point commun de donner enfin aux GPU l'accès à la technologie FinFET, de quoi donner un coup de pied dans une fourmilière bien trop tranquille à notre goût !
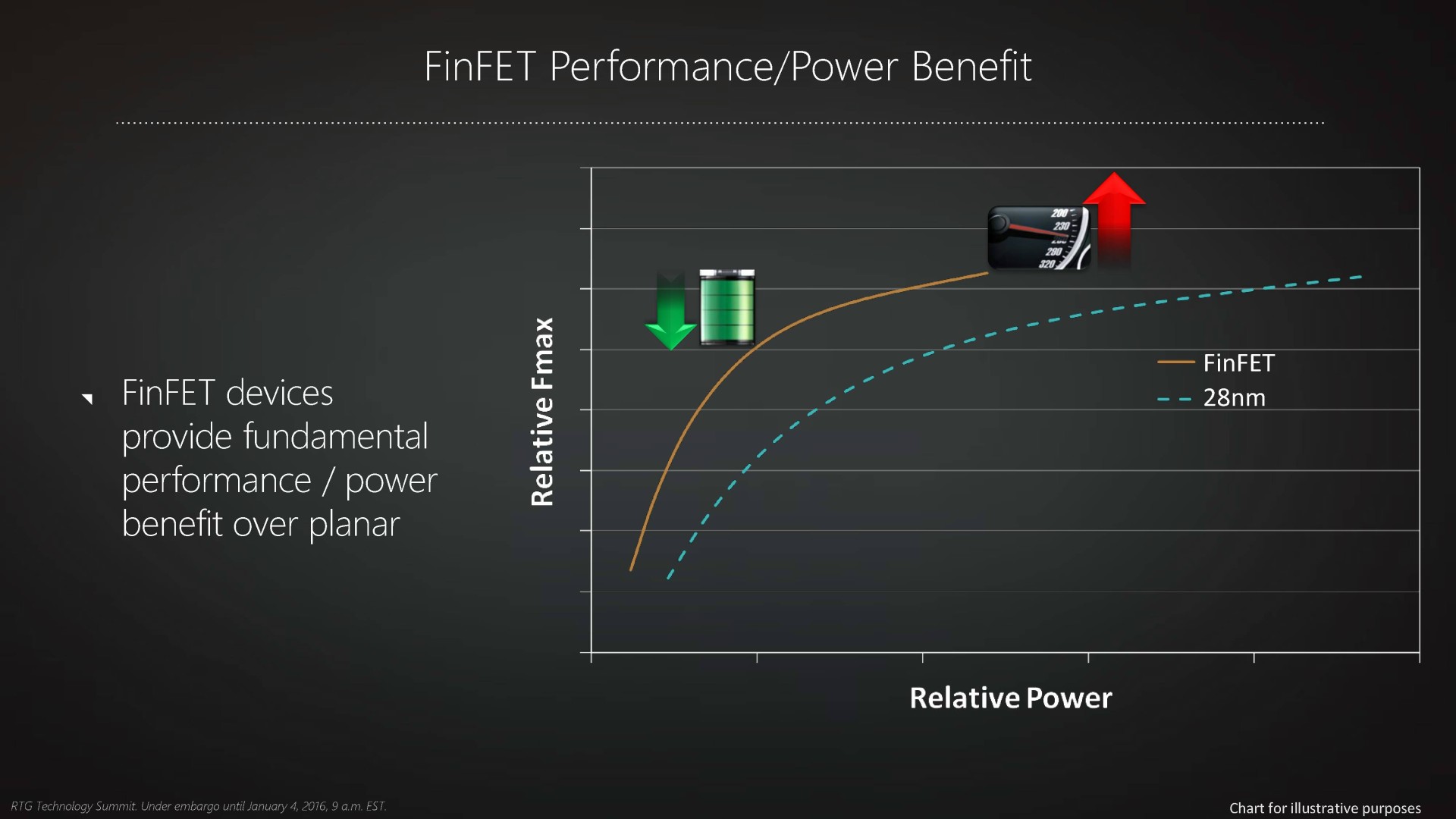
Introduit par Intel en 2012 sous les noms de "transistors tri-gates" ou de "transistors 3D", le FinFET se détache de la construction planaire classique des transistors en donnant une troisième dimension à la porte ce qui permet d'en augmenter la surface de contact et de mieux l'isoler. Les courants de fuite, qui peuvent représenter une grosse partie de la consommation d'un transistors classique, sont alors nettement réduits.
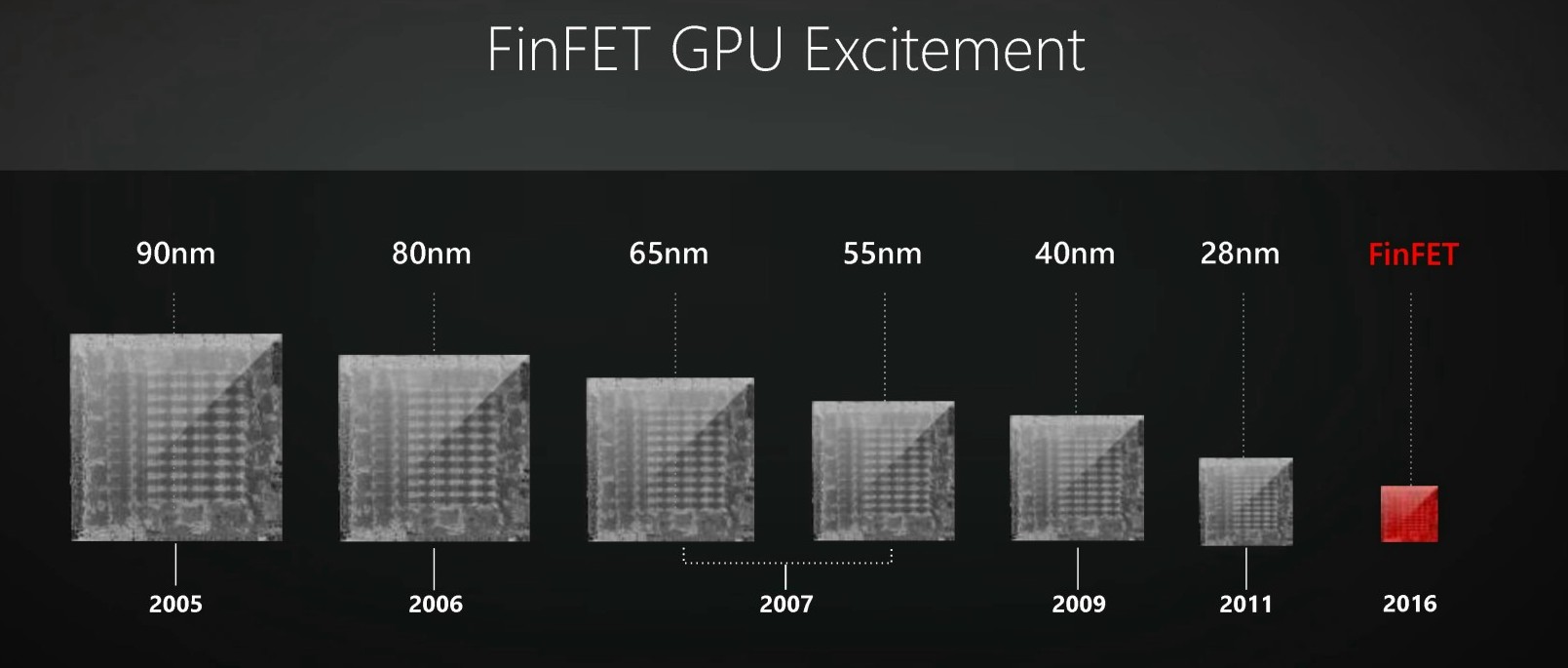
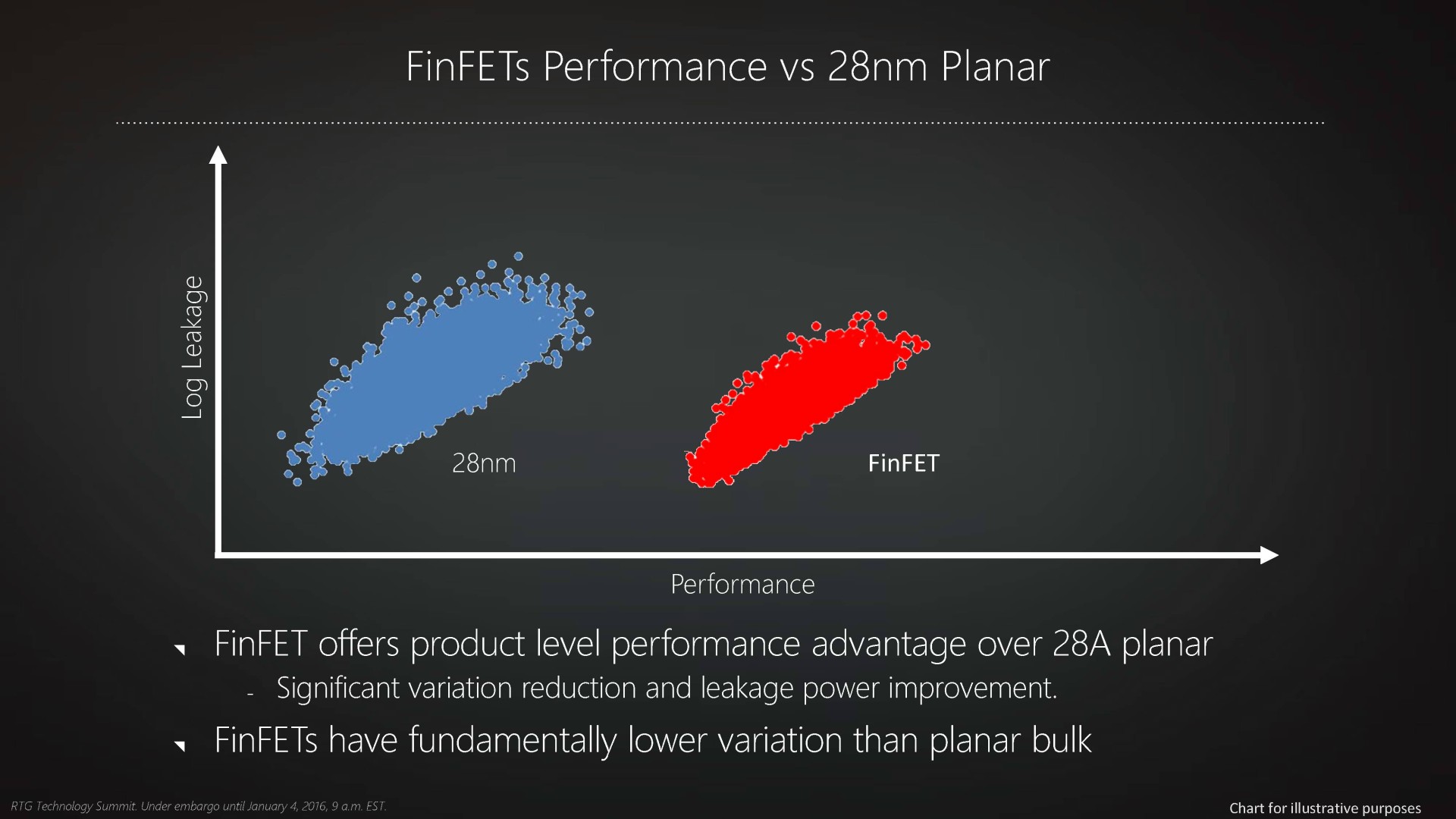
Autant, voire plus, que la finesse de gravure, c'est ainsi le passage au FinFET qui autorise une avancée significative dans les performances des transistors, ce qui peut se traduire par un gain de fréquence, une nette réduction de la consommation ou un mélange de ces deux points selon le positionnement de la puce. Autre avantage selon AMD, le FinFET permet d'obtenir un comportement plus homogène de l'ensemble des transistors, ce qui réduirait la variabilité dans les échantillons produits.
Comme c'est traditionnellement le cas pour les Radeon, c'est lors de ce changement de process qu'AMD va introduire une évolution significative de son architecture GPU, sur laquelle le Radeon Technology Group va bien entendu vouloir communiquer. Et pour cela il faut pouvoir lui mettre un nom.
La nomenclature des architectures GPU d'AMD, ou plutôt son absence, a été source de confusion ces dernières années. En l'absence de communication d'AMD, nous avons ainsi fait référence à GCN 1.1 et GCN 1.2 pour parler des petites évolutions apportées depuis la Radeon HD 7970 de décembre 2011. AMD préfère cependant concentrer le terme GCN sur les unités de calcul du GPU (ses "curs"), d'autres éléments du GPU pouvant évoluer indépendamment. Polaris représente ainsi le nom global de la nouvelle architecture et GCN 4 la nouvelle version de ses unités d'exécution (après GCN 1 / 1.0, GCN 2 / 1.1 et GCN 3 / 1.2).
Raja Koduri, qui dirige Le Radeon Technology Group, nous a indiqué vouloir faire en sorte que les cartes graphiques qui embarqueront un GPU de type Polaris soient clairement identifiables. Pragmatique et réaliste, il est bien conscient qu'avec une éventuelle future gamme de cartes graphiques, il pourra être difficile pour ses équipes de résister à la tentation d'y intégrer d'anciens GPU. Il sera ainsi important de permettre aux GPU Polaris d'être mis en avant de manière explicite.
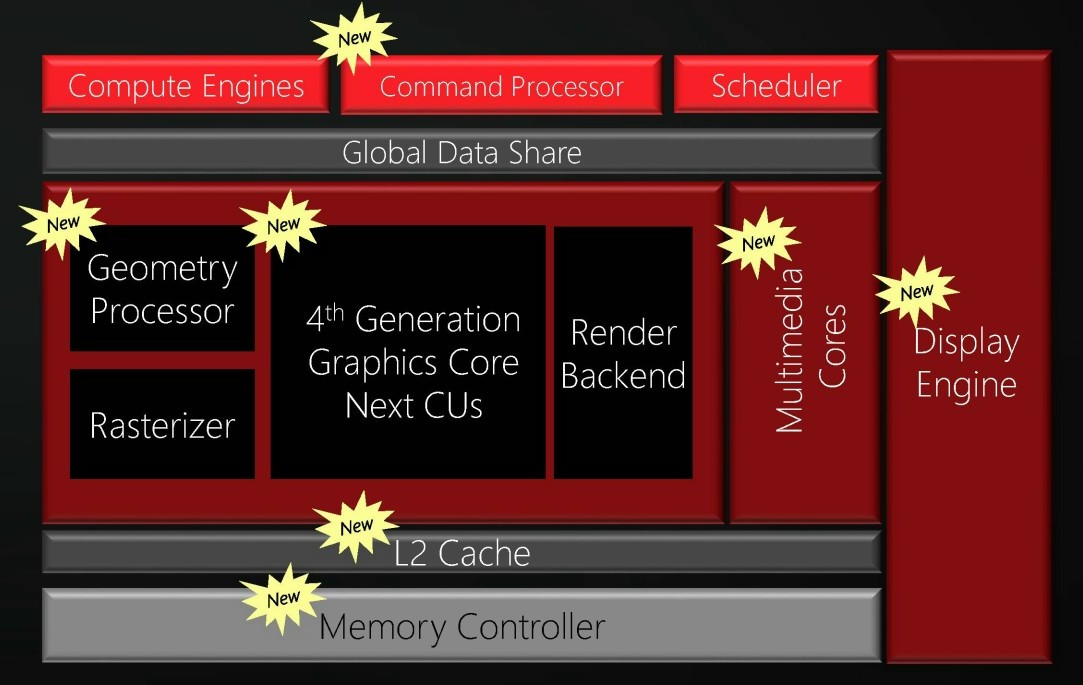
Avec Polaris, à peu près tous les blocs du GPU vont être mis à jour. Nous vous avons déjà parlé de l'aspect affichage et vidéo le mois passé. Pour rappel, les GPU Polaris supporteront le HDMI 2.0a, le DisplayPort 1.3 et le décodage des vidéo 4K en H.265.
Les processeurs de commandes (grahiques et compute), les processeurs géométriques, le cache L2 et le contrôleur mémoire seront également revus pour accompagner le passage aux Compute Units (CU) de type GCN de 4ème génération. Sur ce dernier point AMD précise que Polaris pourra supporter soit un bus GDDR5 soit un bus HBM, suivant les GPU.
Malheureusement, AMD en dit très peu sur les évolutions et ne donne que ces quelques maigres détails :

AMD indique tout d'abord que le cur de l'architecture a été amélioré pour une meilleure efficacité énergétique. Comme Nvidia a commencé à le faire à partir de la génération Kepler, nous pouvons supposer qu'AMD va essayer de ne plus avoir besoin d'une logique d'ordonnancement complexe et gourmande à l'intérieur des CU, là où le comportement d'une suite de certaines instruction est totalement déterministe et peut donc se contenter d'un ordonnancement statique préparé lors de la compilation.
AMD parle également d'amélioration des ordonnanceurs matériels, mais cette fois nous supposons qu'ils ne font pas référence aux CU mais au front-end et aux tâches globales initiées par les processeurs de commandes. Il s'agit ainsi probablement d'améliorations destinées au support du multi-engine de Direct3D 12. Il est également question de nouveaux modes de compression. Il pourrait s'agir de la compression ASTC, coûteuse à implémenter (mais le 14nm règle ce problème) et qu'AMD et Nvidia avaient évité jusqu'ici, contrairement aux concepteurs de GPU pour SoC pour lesquels quelques transistors de plus ne sont jamais trop chers payés pour économiser de la bande passante mémoire et de l'énergie.
Enfin, AMD mentionne un Primitive Discard Accelerator, soit un système d'éjection des triangles masqués du pipeline de rendu. Pour rappel, statistiquement, à peu près la moitié des triangles d'un objet tournent le dos à la caméra et peuvent être éjectés du rendu dès que cet état est confirmé. Pouvoir le faire rapidement permet de booster les performances géométriques en situation réelle.
Actuellement, les moteurs géométriques des Radeon ne sont pas capables d'effectuer cette tâche plus rapidement que le rendu d'un triangle, contrairement aux GeForce qui en profitent pour se démarquer dans certaines scènes, notamment quand la tesselation génère de nombreux triangles masqués. Avec Polaris, AMD devrait enfin combler ce déficit, probablement en doublant le nombre de moteurs d'éjection des primitives par moteur de rastérisation (Nvidia a opté pour une autre approche en décentralisant une partie du traitement géométrique mais nous ne nous attendons pas à ce qu'AMD suive cette voie).

Pour introduire Polaris, contrairement à ce qui se passe habituellement (à l'exception de Maxwell 1 et des GTX 750), AMD met en avant non pas son futur haut de gamme mais un petit GPU prévu pour les PC compacts et pour les portables. Il est équipé de mémoire GDDR5. Nous n'avons pas encore de nom pour ce GPU et n'avons pu l'apercevoir que brièvement sans pouvoir en prendre une photo. Tout juste de quoi apercevoir qu'il s'agit effectivement d'une petite puce et d'un packaging compact.
Sans confirmer que ce serait le premier GPU Polaris disponible, AMD a indiqué que ce petit GPU était important pour sa division graphique, qu'il serait lancé mi-2016 et qu'il serait fabriqué en 14nm chez GlobalFoundries. En précisant ne pas exclure que d'autres GPU soient fabriqués ailleurs, chez Samsung (probablement) ou chez TSMC (de moins en moins probable).
Au niveau de ses spécifications, nous ne saurons rien. Il faudra encore patienter quelque peu, le but d'AMD aujourd'hui étant de nous mettre l'eau à la bouche pour nous faire patienter quelques mois de plus.

Nous avons par contre pu voir ce GPU en action dans une version alpha lors d'un événement presse organisé il y a quelques semaines. AMD a voulu illustrer les gains d'efficacité énergétique apportés par Polaris par rapport à un GPU Maxwell, déjà très efficace. Des chiffres à prendre avec des pincettes, puisqu'ils restent dans le fond assez vagues et avec des conditions de mesure discutables, mais qui font état d'une progression fulgurante du rendement de l'architecture GCN.
Un système équipé d'un petit GPU Polaris est ainsi capable de maintenir 60 fps dans Star Wars Battlefront avec une consommation totale mesurée à la prise de 86W là où un même système équipé d'une GTX 950 demande 140W. Difficile d'en déduire exactement la consommation GPU et ce gain peut en partie être lié à la combinaison d'une puissance GPU supérieure avec un V-Sync à 60 Hz qui permet de rester à une plus faible fréquence, d'ailleurs le GPU utilisé est configuré à 850 MHz pour 0,8375v seulement. Mais de toute évidence Polaris en 14nm va enfin permettre à AMD de faire mieux que Maxwell en 28nm.
AMD tient d'ailleurs à préciser que cette démonstration a été effectuée avec un support partiel de Polaris par les pilotes. Les gains d'efficacité proviennent ainsi uniquement du 14nm et des CU GCN 4, le support des nouveaux mécanismes dédiés à économiser de l'énergie n'ayant pas encore été implémenté.
Bien entendu, les GPU Polaris n'auront pas simplement affaire aux GPU Maxwell actuels mais bien aux GPU Pascal et peut-être à de petits GPU Maxwell 2 fabriqués en 16/14nm. Et il est beaucoup trop tôt pour savoir comment s'opposeront ces futurs concurrents. Pour la première fois depuis très longtemps, il est d'ailleurs intéressant de noter qu'un élément tiers pourra venir semer le trouble dans le combat AMD vs Nvidia : les fondeurs. En effet, il semble de plus en plus probable qu'AMD exploite principalement les process 14nm de GlobalFoundries et Samsung alors que Nvidia exploiterait plutôt le 16nm de TSMC. Si l'un de ces process s'avère meilleur que l'autre, le fabricant de GPU qui aura misé sur le bon cheval s'en trouvera mécaniquement avantagé même si le process ne fait pas tout.
Vous retrouverez la présentation complète ci-dessous :















AMD valide le 14nm LPP de GloFo
GlobalFoundries vient d'annoncer dans un communiqué qu'il avait livré à AMD des puces fonctionnelles gravées avec le process 14nm LPP (Low Power Plus), la version la plus avancée du procédé de fabrication Samsung 14nm FinFet (l'Apple A9 utilisant le 14nm LPE Low Power Early) qui est pour rappel également déployé chez GF.
Le fondeur précise qu'AMD a "taped out" plusieurs produit chez GF en 14nm LPP et qu'il est actuellement en train de valider les échantillons produit. Il semble donc qu'un premier produit ai été validé, GF parlant de "silicon success". AMD indique au passage qu'il compte utiliser le process 14nm LPP sur des produits CPU, APU mais aussi GPU. Jusqu'alors les GPU AMD étaient comme ceux de Nvidia fabriqués par TSMC, mais sachant qu'AMD a toujours des engagements contractuels sur des volumes avec GF qu'il peine à remplir il est logique qu'il favorise ce dernier si le process est à la hauteur. On devrait donc avoir droit en 2016 à une bataille d'architecture entre AMD et Nvidia combinée à une bataille de fondeurs avec d'un côté le 16nm FinFET+ de TSMC et de l'autre le 14nm LPP de Samsung/GlobalFoundries !
GlobalFoundries indique que le 14nm LPP a été qualifié au cours du troisième trimestre pour la production, cette dernière va débuter au cours de ce quatrième trimestre et arrivera à plein débit en 2016, sans plus de précision. Difficile pour le moment de savoir quand les premières puces AMD produites en 14nm LPP seront lancées en 2016, mais il serait étonnant que ce soit avant le second trimestre côté GPU et le dernier trimestre côté CPU. Vivement !