
Actualités informatiques du 04-04-2013
- GDC: Windows RT et les jeux : quel succès ?
- GDC: L'architecture PowerVR Series 6 Rogue
- GDC: Architecture GPU : IMR, TBR ou TBDR ?
- L'Obsidian 900D de Corsair arrive
- Les SSHD WD Black en approche
- 15, 12 et 10 coeurs pour les futurs Xeon
- Nouveaux pilotes graphiques Intel
| Avril 2013 | ||||||
|---|---|---|---|---|---|---|
| L | M | M | J | V | S | D |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | |||||
GDC: Windows RT et les jeux : quel succès ?



Une image vaut parfois mieux qu'un long discours :

Le moins que l'on puisse dire c'est qu'à la GDC les développeurs ne se bousculaient pas pour assister aux quelques sessions liées à Windows RT. Ici en exemple le portage de Vendetta Online vers cet OS, présenté en association avec Qualcomm et que nous nous sommes contentés d'illustrer à partir du milieu de la salle. En dehors des représentants de Guild Software, de Microsoft et de Qualcomm, la salle était tristement vide.
Notez qu'à l'opposé, les sessions de Sony sur la PS4 et de Valve faisaient partie des plus populaires avec des files énormes et l'impossibilité de faire rentrer tout le monde dans les salles pourtant plutôt grandes qui avaient été prévues. De toute évidence, les déçus ne se sont pas rabattus sur les sessions Windows RT !
GDC: L'architecture PowerVR Series 6 Rogue
Dans une session dédiée à l'architecture PowerVR, Imagination a donné quelques détails sur l'architecture Series 6, nom de code Rogue, qui a été dévoilée il y a plus de deux ans et qui devrait très bientôt arriver dans différents SoC.
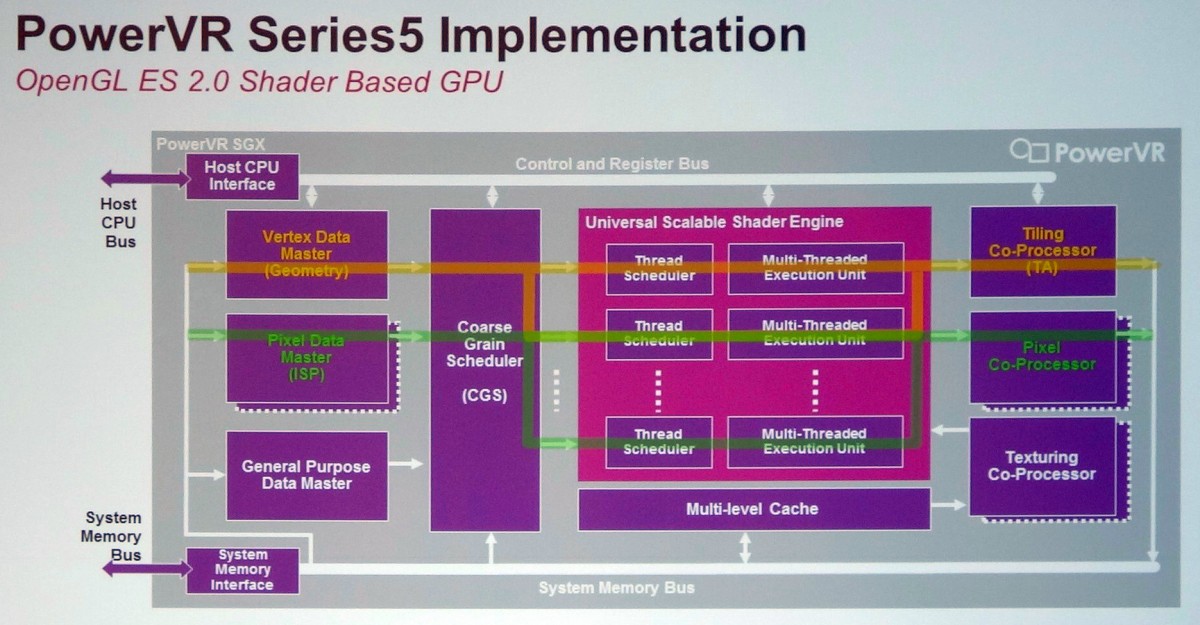
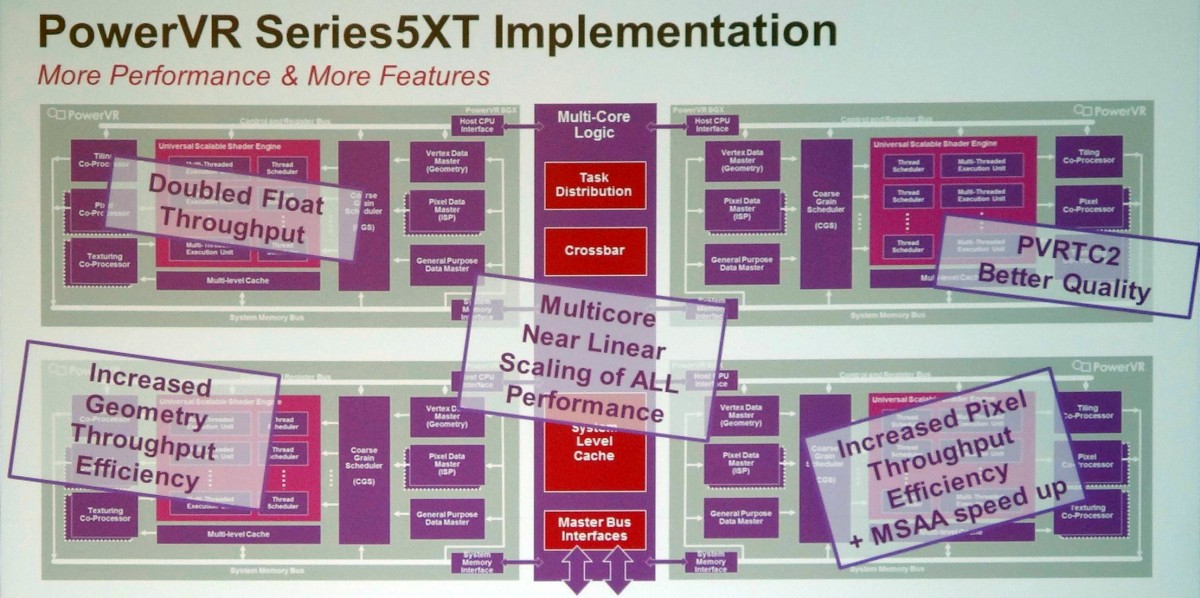
L'architecture PowerVR Series 5 est exploitée depuis de nombreuses années, par exemple dans les SoC Atom Intel ou dans l'A4 d'Apple. Elle a évolué il y a un peu plus de 3 ans pour passer en version Series 5XT avec le PowerVR SGX543 qui a doublé la puissance de calcul (elle passe de 8 à 16 MAD par cycle) et amélioré l'efficacité au niveau des débits de triangles et de pixels, notamment avec MSAA. Le support d'OpenCL a par ailleurs été introduit.
Par ailleurs, Imagination a introduit la possibilité d'avoir recours au multicore pour démulitplier la puissance des GPU PowerVR. L'ensemble du GPU SGX543 représente alors un core qui peut être dédoublé jusqu'à 8x, le tout étant piloté par un distributeur de tâche qui intègre un cache commun. Cette notion de core est donc ici assez proche d'un core CPU et n'a rien avoir avec la notion de core utilisée par Nvidia dans ses GPU, y compris Tegra. Comparer le GeForce ULP 72 cores du Tegra 4 au PowerVR SGX543MP4 "seulement 4 cores" est donc un non-sens, même si comme vous vous en doutez le côté commercial ne s'en prive pas.
Notez que le PowerVR SGX544 a ajouté le support de DirectX en niveau 9_3 alors que le PowerVR SGX554 a doublé une nouvelle fois la puissance de calcul qui passe à 32 MAD par cycle par core.
Avec l'architecture PowerVR Series 6, Imagination a dû faire face à la problématique de la consommation énergétique. Dédoubler les cores Series 5XT c'était "simple", mais les GPU finissaient alors par devenir trop gourmands. L'architecture a donc été revue pour devenir similaire à celle des GPU desktops modernes et pouvoir multiplier, à l'intérieur d'une structure fixe, des blocs (USC - Unified Shading Clusters) comprenant des unités de calcul et d'autres des unités de texturing. De quoi supprimer la redondance pour rendre le GPU plus compact et plus économe.
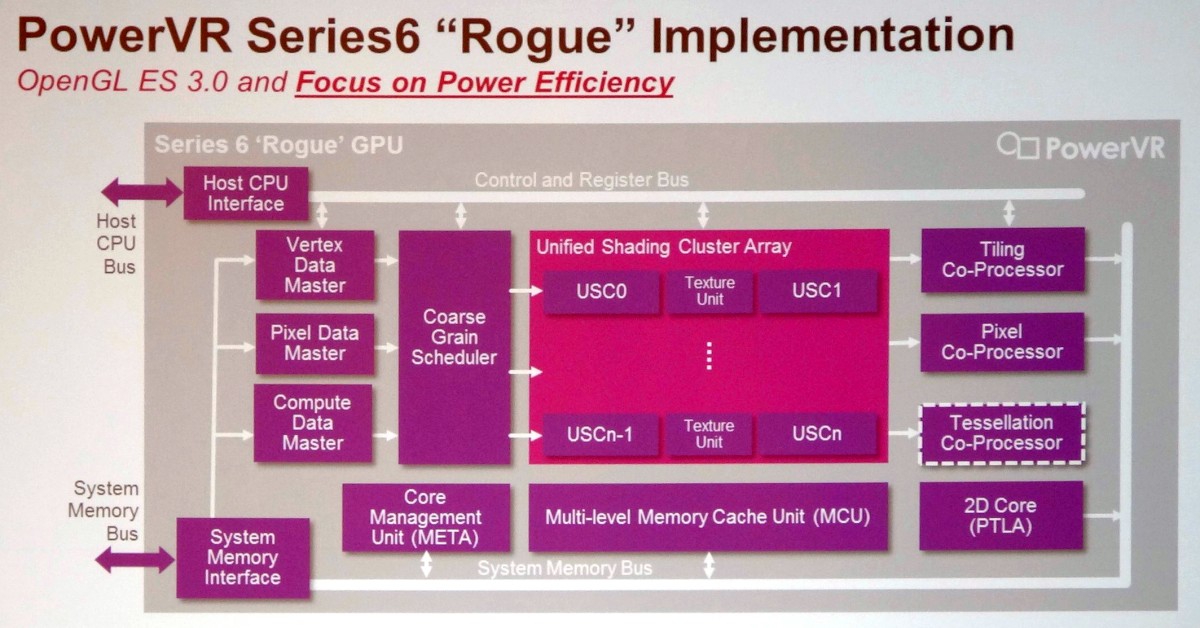
De nombreux petits raffinements ont été apportés à l'architecture, toujours dans le but de la rendre plus efficace. C'est le cas par exemple du passage à un fonctionnement perçu de type scalaire des unités de calcul (comme pour les GeForce 8+ et les Radeon HD 7000+) ou encore du support d'une compression lossless pour la géométrie et les pixels. Le support d'OpenGL 3.0 est complet et du côté DirectX on passe au niveau 10_0. Le support de DirectX 11_1 est par ailleurs possible, optionnellement, avec notamment l'ajout d'un tessellateur.
Parmi les détails, Imagination précise ceci :
- les unités de texturing ont gagné en performances lors d'accès dépendants
- le support de la basse précision lowp (FX10) a été abandonné, ne restent que le mediump (FP16) et le highp (FP32)
- les branchements dynamiques sont dorénavant traités par groupes de threads et peuvent être moins performants en cas de divergence, comme sur GPU desktop et contrairement aux Series 5
- lors de l'utilisation de MRT - Multiple Render Targets (écriture vers plusieurs buffers en une seule passe), il faut prendre garde à ne pas dépasser 128 bits par pixel, le maximum supporté pour profiter du buffer lié au tile rendering, ce qui se traduit grossièrement par "HDR + MSAA + MRT = pas bien"
Imagination prévoit actuellement 6 variantes, les PowerVR G6100, G6200 et G6400 ainsi que les PowerVR G6230, G6430 et G6630. D'après ce que communique Imagination, les G6x30 affichent des débits bruts similaires aux G6x00 mais avec quelques améliorations de l'architecture pour gagner en performances. S'il est possible que ces G6x30 soient compatibles avec le niveau 11_1 de DirectX, nous estimons plus probable que ce support ne soit prévu que pour une variante future.
Le second chiffre représente le nombre d'USC : 1 pour le G6100 jusqu'à 6 pour le G6630. Chaque paire d'USC, excepté pour le G6100 bien entendu, est associée à un bloc d'unités de texturing, mais Imagination ne précise pas le nombre d'unités de calcul (MAD) par USC. Il s'agira probablement de 32 unités de calcul par USC, avec, en terme de puissance brute et à fréquence égale, un G6100 qui serait équivalent à un SGX544MP2 et un G64x0 qui serait équivalent à un SGX554MP4.
Si ces GPU semblent prometteurs sur le papier, il faudra cependant patienter jusqu'à l'arrivée des premiers SoC qui les intégreront, et d'informations plus complètes, pour se faire une idée plus précise de leur niveau de performances.
Annoncé il y a plus de 2 ans, le Nova A9600 de ST-Ericsson devait être le premier SoC à intégrer un GPU PowerVR Series 6. Malheureusement le Nova A9600 a fait les frais du divorce entre STMicro et Ericsson.
GDC: Architecture GPU : IMR, TBR ou TBDR ?
Durant la GDC, il n'était pas question uniquement des GPU PC ou console : le monde du GPU mobile était également à l'honneur tant il se développe à une vitesse fulgurante. Compte tenu du nombre important d'acteurs à ce niveau, des contraintes fortes en terme d'efficacité énergétique et une bande passante mémoire très limitée, différents types d'architectures s'y côtoient, avec des compromis différents. L'occasion de faire le point entre les variantes IMR, TBR ou TBDR, en nous basant sur quelques slides récapitulatives proposées par Imagination.
Rappelons tout d'abord deux concepts :

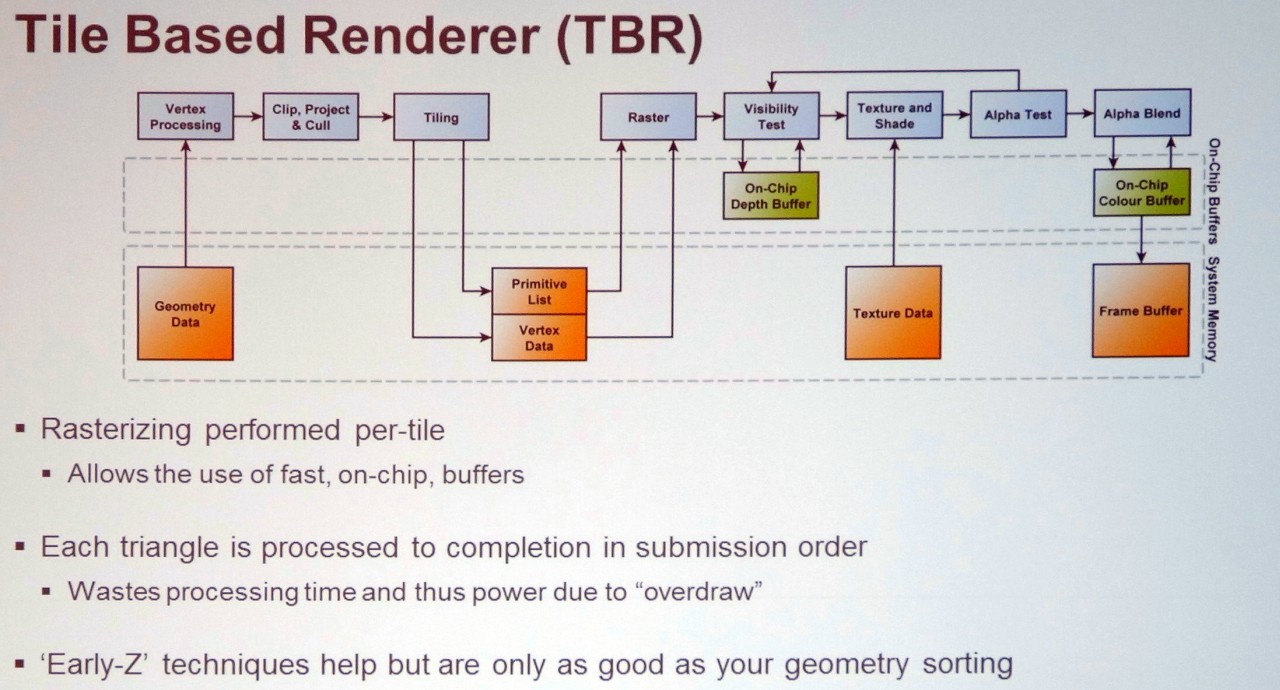
Le rendu basé sur des tiles (tuiles), également appelé binning, consiste à subdiviser le framebuffer en un ensemble de petites zones de l'image qui seront rendues les unes après les autres et qui peuvent tenir dans un petit cache interne au GPU. Cela a pour avantage d'éviter de passer par la mémoire externe et de gaspiller de la bande passante mémoire lors de l'écriture de pixels "temporaires". Imagination parle par exemple de tiles de 32x32 pixels, en précisant que la taille exacte est variable selon le GPU Power VR.
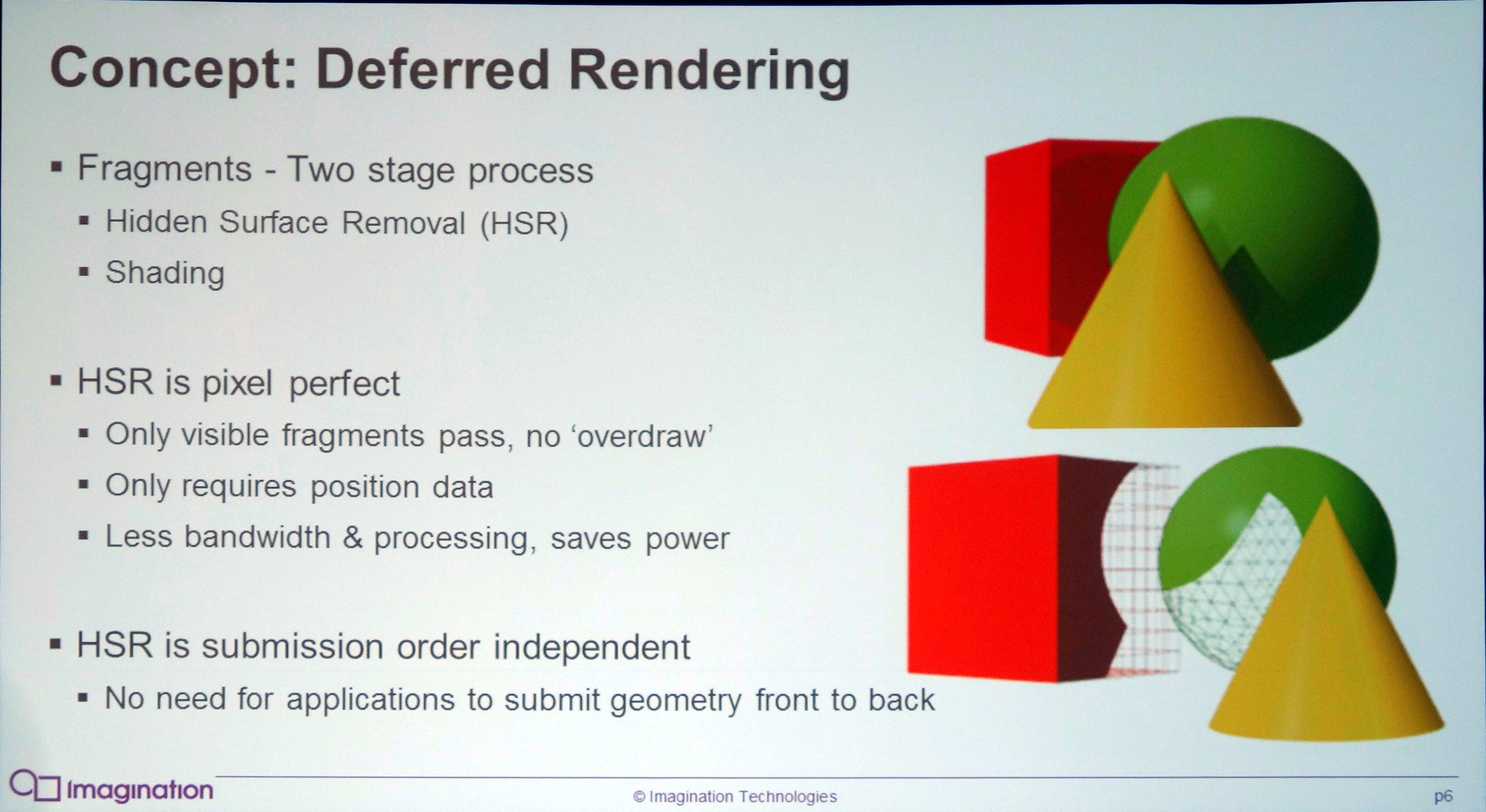
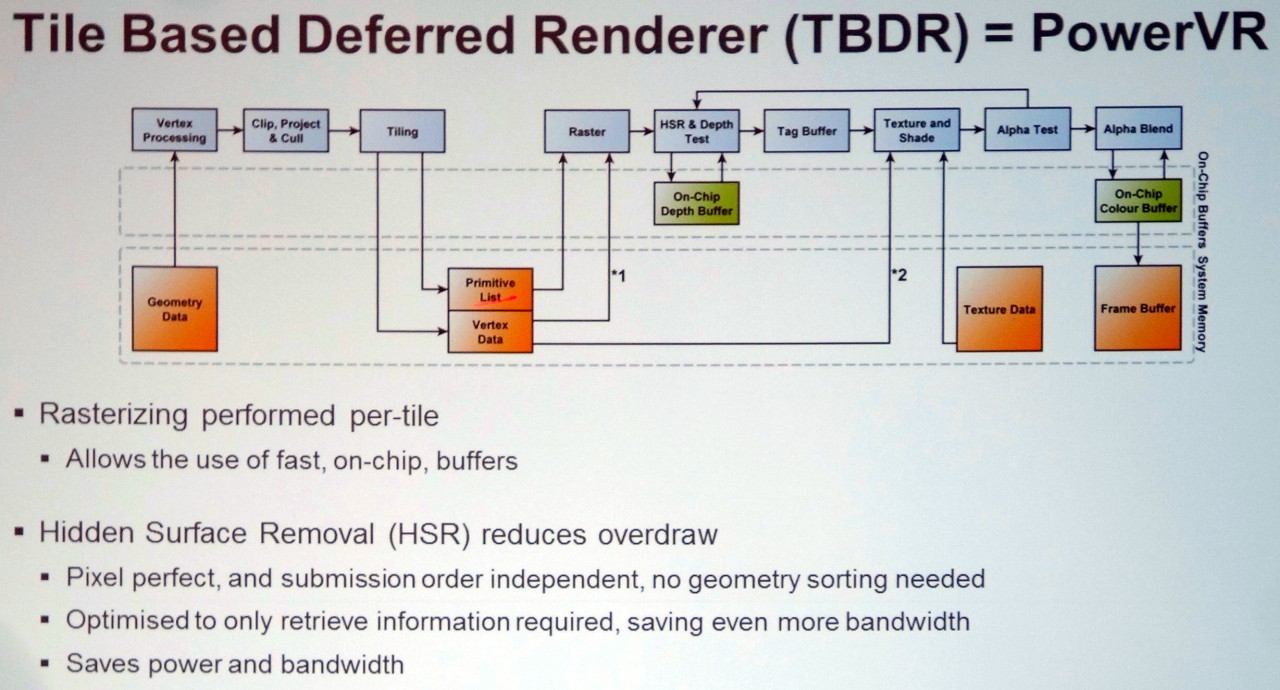
Le rendu différé permet de se baser sur une première passe dans laquelle la géométrie est passée en revue pour ne retenir qu'un seul pixel à finaliser par point de l'écran et ainsi réduire, voire supprimer, l'overdraw (le rendu de pixels masqués). Le rendu différé peut être implémenté de manière logicielle comme le font de nombreux moteurs graphiques pour ne calculer la partie complexe de l'éclairage qu'une fois par pixel. Il peut également être implémenté de façon matérielle en tant que technique de HSR (Hidden Surface Removal) pour permettre au GPU de déterminer l'unique pixel visible par point de l'écran.
Il existe trois grands groupes d'architectures GPU (notez qu'étant donné qu'il s'agit de slides d'Imagination, les points cités sur celles-ci se contentent de mettre en avant les avantages du TBDR maison) :
| [ IMR Immediate Mode Renderer ] [ TBR Tile Based Renderer ] [ TBDR Tile Based Deferred Renderer ] | Agrandir Agrandir Agrandir |
{kind=link}
{kind=link}
{kind=link}
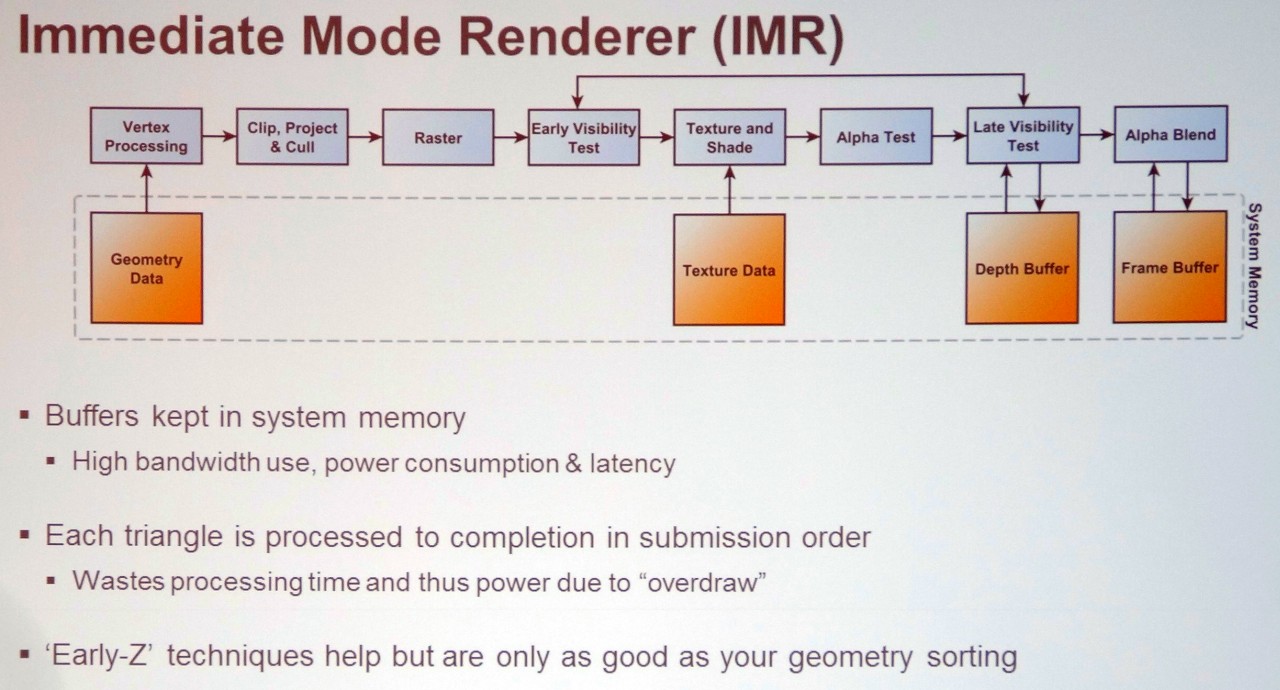
L'IMR ou le rendu immédiat représente l'approche "naturelle" du rendu sur base de primitives : la géométrie est transformée pour prendre place dans la scène, les triangles sont directement découpés en pixels les uns à la suite des autres, les pixels sont rendus et écris en mémoire. Cette approche est très flexible mais peut consommer beaucoup de bande passante mémoire et entraîner le calcul de pixels masqués quand un triangle caché par un autre est rendu avant celui-ci. Les GPU d'AMD, d'Intel et de Nvidia (y compris Tegra), ainsi qu'optionnellement les GPU Adreno de Qualcomm, exploitent l'IMR et disposent de nombreuses optimisations pour éviter de gaspiller trop de ressources.
Le TBR ou binning, soit le rendu tile par tile "simple", est exploité à des degrés divers par les GPU Mali d'ARM, Adreno de Qualcomm voire dans certains cas Xenos de la Xbox 360 et HD Graphics d'Intel. Pour être efficace et éviter de devoir traiter plusieurs fois la géométrie (pour chaque tile), cette approche doit être combinée à un rendu en deux étapes. La première consiste à passer en revue toute la géométrie et à écrire en mémoire la position de chaque primitive (triangles) après transformation ainsi qu'un lien vers toutes les tiles que chacune affecte. Le rendu classique peut ensuite se faire tile par tile, en ne traitant que les triangles qui s'y retrouvent et en ne gaspillant pas de bande passante mémoire externe, que ce soit pour écrire des pixels cachés ou pour des opérations de mélange lorsque des objets transparents sont rendus.
Dans certains cas, cette approche est cependant peu efficace, par exemple lorsque la géométrie est très complexe et représente autant, voire plus, de données à écrire en mémoire que ce qui est économisé au niveau des pixels. Par ailleurs, lorsque de petits triangles (qui peuvent être traités en un seul cycle) croisent plusieurs tiles, le rasterizer peut se retrouver débordé puisqu'il va devoir les traiter une fois pour chaque tile. Cette perte d'efficacité potentielle est la raison pour laquelle les GPU d'Intel et de Qualcomm supportent l'IMR en plus du TBR.
Le TBDR exploité par les GPU PowerVR ajoute au TBR le principe du rendu différé : se débarrasser de l'overdraw. Ainsi une technique de HSR (Hidden Surface Removal) hardware basée sur un lancer de rayon permet pour chaque pixel de retrouver le triangle visible au milieu de l'ensemble de la géométrie liée à la zone de rendu, ce qui est bien entendu facilité par le rendu par tile. Notez que le TBDR peut perdre d'avantage en efficacité que le TBR quand la géométrie devient très complexe puisque le moteur de HSR va avoir plus de mal à déterminer les triangles visibles et potentiellement devenir le facteur limitant.
Par contre, en plus de n'écrire en mémoire externe qu'un seul pixel par point de l'écran, seulement un pixel est calculé par les GPU de type TBDR, ce qui permet des économies supplémentaires au niveau de la puissance de calcul et de texturing. Notez qu'en contrepartie, certaines techniques de rendu demandent des adaptations particulières, qui peuvent avoir un coût, pour fonctionner sur ce type d'architecture : c'est le cas de certains effets de transparences ou qui modifient la profondeur effective du pixel après le traitement géométrique (bump mapping avancé par exemple).
Chaque approche a donc des avantages et des désavantages. Comme pour tout ce qui concerne le rendu 3D temps réel en général, il s'agit toujours d'un compromis. En dehors de Nvidia, il semble cependant y avoir un consensus dans le monde mobile en faveur de l'utilisation de tiles, tout du moins optionnellement, pour économiser autant que possible la bande passante mémoire et l'énergie qui y est liée, quitte à complexifier l'architecture du GPU.
L'Obsidian 900D de Corsair arrive
Déjà présenté lors du CES, l'imposant Obsidian 900D est désormais présent sur le site de Corsair à l'approche de sa commercialisation. Alors que le 800D mesurait 609x229x609mm (longueur, largeur, hauteur), le 900D culmine à 650x229x692mm pour 19,6 Kgs. C'est grand, très grand, trop grand pour beaucoup !

Cet espace énorme lui permet d'accueillir des cartes E-ATX et HPTX en sus des ATX classiques (avec 10 slots d'extensions), deux alimentations (à la verticale), 9 disques 3.5" ou 2.5" (dont 3 en hot-swap mais internes) et 4 lecteurs 5.25". Il est possible d'ajouter en option des cages pour disque pour porter le total de 9 à 15.
Côté ventilation ce ne sont pas moins de 5 radiateurs pour watercooling qui peuvent être intégrés dans la tour sur les divers emplacements pour ventilateurs :
- 3 de 120mm à l'avant (avec 3 AF120L livrés)
- 4 de 120mm ou 3 de 140mm haut dessus (ou 3 de 140mm)
- 4 de 120mm ou 3 de 140mm en bas à gauche (ou 3 de 140mm) (2 si deux alimentations sont installées)
- 2 de 120mm ou 140mm en bas à droite
- 1 de 120mm ou 140mm à l'arrière (avec 1 AF140L livré)
Le Corsair Obsidian 900D devrait être disponible avant la fin du mois pour environ 330 , rien que ça.



Les SSHD WD Black en approche
Dans un document indiquant la fin de vie de certains WD Black (WD5002AALX et WD7500AAEX en décembre 2012, WD1002FAEX et WD10002FAEX en juin 2013), Western donne quelques indications sur l'arrivée en mai prochain de sa gamme de SSHD :

Pour rappel les SSHD, déjà disponible chez Seagate, sont des disques durs classiques associés à une mémoire Flash de taille variable faisant office de cache. Chez Seagate l'acronyme SSHD, qui est bien trop proche de SSD, signifie Solid State Hybrid Drive alors que chez WD utilise ce sigle pour Solid State Hard Drive.
Le WD10E12X devrait donc être un disque dur 3.5" de gamme WD Black offrant une capacité de 1 To associée à 16 Go de Flash. WD avait également fait la démonstration au CES de deux SSHD 2.5", le WD5000M13K de 5mm de hauteur faisait 500 Go pour 24 Go de Flash, alors que le WD10S13X avait une épaisseur de 7mm pour 1 To de capacité et 24 Go de Flash.
A cette occasion Western Digital indiquait que ses SSHD WD Black intégreraient jusqu'à 32 Go de Flash, reste donc à voir quels seront les autres modèles. Dans tous les cas on peut se réjouir de la taille du cache Flash, nettement plus important que chez Seagate qui le limite à 8 Go.
15, 12 et 10 coeurs pour les futurs Xeon
CPU-World donne quelques informations sur les futurs processeurs Intel Xeon gravés en 22nm destinés aux systèmes multi-Socket, l'occasion de faire le point sur ce qui est prévu au cours des prochains trimestres sur ce segment.

On commence par le très haut de gamme Xeon E7 v2 (Ivy Bridge-EX) destiné à la plate-forme Brickland et qui débarquera au quatrième trimestre 2013. Alors que les précédents Xeon E7 se "limitaient" à 10 curs et 30 Mo de cache L3, on passera cette fois à 15 curs et 37,5 Mo de cache L3. Le processeur supportera en sus 32 lignes PCI-Express 3.0 et pourra être utilisé dans des machines intégrant jusqu'à 8 sockets. Côté mémoire chaque processeur pourra être connecté à 4 Scalable Memory Buffers (SMB) pouvant gérer au total 24 barrettes DDR3-1600, mais une prochaine génération de ces SMB prévus sur Brickland ajoutera le support de la DDR4.
A titre d'information un Xeon E7-8870 (10 curs, 30 Mo de L3, 2,4 GHz, 130W) se monnaye tout de même 4616$. La plate-forme Brickland introduite à l'occasion de ce lancement devrait être compatible avec les futurs Haswell-EX (Xeon E7 v3) ainsi que leurs successeurs, une compatibilité qu'on aimerait voir sur d'autres gammes.
Les Xeon E5-2600 v2 et E5-4600 v2 (Ivy Bridge-EP) seront pour leur part destiné aux plates-formes Romley-EP 2 et 4 Socket déjà utilisée par Xeon E5-2600 et E5-4600 actuels (Sandy Bridge-EP). Prévus respectivement pour le troisième trimestre 2013, comme les Core i7 Ivy Bridge-E, et le premier trimestre 2014 ces processeurs Socket 2011 intégreront jusqu'à 12 curs pour 30 Mo de cache L3, contre 8 curs et 20 Mo actuellement. Ils disposeront également de 40 lignes PCI-Express 3.0 et de 4 canaux DDR3-1866.
Toujours sur la plate-forme Romley mais "-EN" 2 Socket 1356, le Xeon E5-2400 v2 (Ivy Bridge-EN) est pour sa part prévu pour le premier trimestre 2014. Cette version bridée de l'E5-2600 v2 sera limitée à 10 curs, 3 canaux DDR3 et 24 lignes PCI-Express.
Il faut noter que les futurs Haswell-EP et Haswell-EN (ainsi que d'éventuels Haswell-E en Core i7), prévus pour le second semestre 2014, utiliseront une nouvelle plate-forme dénommée Grantley utilisant un Socket R succédant au 2011. Le nombre de curs maximum devrait être porté de 12 à 14 et le cache L3 de 30 à 35 Mo. On restera à 40 lignes PCI-Express 3.0 alors que le contrôleur mémoire supportera officiellement la DDR4-2133 sur 4 canaux.
Enfin le nouveau chipset Wellsburg C610 gravé en 32nm (contre 65nm pour les actuels X79/C600) intégrera notamment la gestion de 10 ports SATA 6 Gbps et de 6 ports USB 3.0 pour un TDP de 7 watts, contre 8 watts pour un C602J (équivalent du X79) et 12 watts pour un C606 (avec la SCU ajoutant 8 SATA/SAS 3G active).
Malheureusement les 8 lignes PCI-Express gérées par le chipset seront toujours de type Gen2 et l'interconnexion avec le processeur se fera à toujours en DMI 2.0 ce qui correspond à un lien PCI-Express 4x Gen2 à 2 Go /s dans chaque sens : c'est loin d'être suffisant si on utilise pleinement tous les SATA. Ce choix est assez étrange alors que le chipset C606 intégrait en sus du lien DMI 2.0 un lien supplémentaire à 4 Go /s pour les 8 ports SATA/SAS 3G gérés par la SCU.
Nouveaux pilotes graphiques Intel
La société américaine vient de rendre disponible une nouvelle fournée de pilotes destinés à ses processeurs embarquant un core graphique.
Le premier pilote, baptisé 15.31.3.3071 concerne les processeurs Ivy Bridge. Cette version apporte pour ces derniers une amélioration du support d'OpenCL 1.2, notamment lorsque l'on souhaite l'utiliser en parallèle avec DirectX 11 ou OpenGL. Comme ses petits camarades, Intel met en avant des gains de performances dans les jeux :
- Gains de 7% sous Batman : Arkham Asylum (DX9) en 1280 par 1024
- Entre 8 et 22% de gains sous Starcraft 2 : Wings of Liberty (DX9) en 1280 par 1024
- Entre 9% (DX11, 1280 par 1024) et 100% (DX9, 1366 par 768) de gains sous Oil Rush
- Entre 26 et 87% de gains sous Dragon Age 2 selon les scènes en 1366 par 768
Diverses corrections de bugs sont également évoquées, notamment des crashs sous Metro 2033/CyberLink PowerDirector et des artefacts dans Max Payne 3, Portal 2, Shogun 2 et Far Cry.

La plus grosse nouveauté concerne cependant le support, sous Windows 8, des technologies QuickSync et OpenCL sur des machines équipées d'une carte graphique additionnelle. Une fonctionnalité fort pratique et qui évitera de devoir utiliser une solution annexe comme celle de Lucid.
Les possesseurs d'Ivy Bridge pourront consulter les releases notes ici (PDF) , et télécharger le pilote pour 7 et 8 sur le site d'Intel .
Ceux qui possèdent un processeur Sandy Bridge, par contre, devront utiliser un autre pilote, le 15.28.15.3062 qui ne bénéficie malheureusement d'aucune des améliorations précitées ! Les pilotes n'intègrent pas de support OpenCL, n'apportent pas de gains de performances dans les jeux et ne permettent pas l'utilisation de QuickSync sous Windows 8. Le pilote contient par contre une très longue liste de correctifs que vous pourrez consulter dans ces releases notes (PDF) .
Il est assez dommage que la génération précédente ait été si vite oubliée par Intel au point qu'ils ne proposent plus, pour des puces d'architecture extrêmement proches rappelons le, de pilote unifié. Le téléchargement des pilotes Sandy Bridge s'effectue ici sur le site du constructeur.