
Nvidia GeForce GTX 750 Ti & GTX 750 : Maxwell fait ses débuts
Publié le 26/02/2014 par Damien Triolet



1.9 milliards de transistors pour le premier GPU MaxwellAvec Maxwell, nom de code sa nouvelle architecture, Nvidia continue l'effort entrepris lors du passage de Fermi vers Kepler, pour une meilleure efficacité énergétique. C'est d'autant plus nécessaire que pour ce premier GPU, pour lequel Nvidia précise "Maxwell de première génération" (ce qui implique qu'il y en a une seconde), le procédé de fabrication n'évolue pas et reste la même variante du 28 nanomètres de TSMC (HP) que pour l'ensemble des GPU Kepler. Les GPU Maxwell de seconde génération devraient présenter quelques retouches au niveau de l'architecture et surtout exploiter un process plus évolué qui sera probablement le 20 nanomètres de TSMC.
Pour rappel, voici la liste des GPU actuellement fabriqués par Nvidia en 28 nanomètres :
GK110 : 7.1 milliards de transistors pour 551 mm²
GK104 : 3.5 milliards de transistors pour 294 mm²
GK106 : 2.5 milliards de transistors pour 214 mm²
GM107 : 1.9 milliards de transistors pour 148 mm²
GK107 : 1.3 milliards de transistors pour 118 mm²
GK208 : 1.0 milliards de transistors pour 79 mm²

Le GM107 de Nvidia.
Un petit calcul rapide montre que les 3 GPU les plus récents de Nvidia, à savoir les GK110, GK208 et GM107, affichent une densité de transistors un peu plus élevée que celle de ses premières puces fabriquées en 28 nm. Ceci peut s'expliquer par une petite évolution des règles de design et sur un effort d'optimisation plus poussé mais aussi par la proportion de mémoire SRAM (plus dense que les autres circuits) qui peut être plus élevée, ce qui est particulièrement le cas pour les GPU GM107 et GK208.
Le GM107 se place ainsi logiquement entre les GK107 et GK106. Grâce à l'évolution de son architecture, ce GM107 est cependant plus proche du GK107 en terme de taille de puce, de coûts de fabrication et de consommation mais est par contre plus proche du GK106 sur le plan des performances, sans toutefois pouvoir égaler celui-ci.
A noter que pour ce lancement, Nvidia a décidé de ne communiquer d'une manière générale qu'un nombre très limité de détails, tout en nous donnant l'opportunité de creuser le sujet en envoyant des questions aux responsables techniques. Ainsi, dans cette analyse de l'architecture, les détails découlent en partie de ces échanges et en partie de tests ciblés qui nous permettent d'observer le comportement des différents GPU.
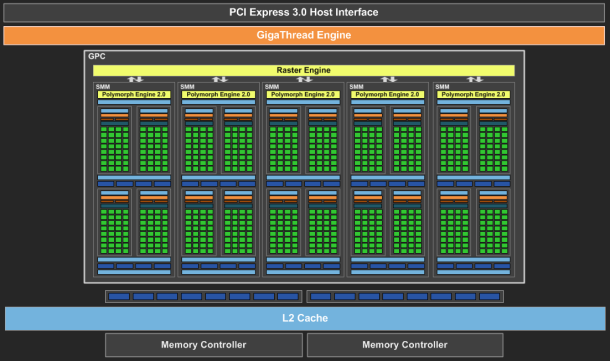
Le cache L2 du GM107 explose : 2 MoAlors que les GPU Kepler reposaient sur des blocs fondamentaux appelés SMX (Streaming Multiprocessor), qui contiennent unités de calcul et autres unités de texturing, ceux-ci sont appelés SMM dans le cas de la génération Maxwell. Ils ont subi un régime assez drastique afin de les simplifier suffisamment pour pouvoir en augmenter significativement le nombre.
Tout comme les SMX, les SMM sont organisés en petits groupes, appelés GPC (Graphics Processing Cluster). Chaque GPC inclus un moteur de rastérisation qui reçoit les triangles traités par les SMX/SMM, les découpes en pixels avec lesquels il forme de petits groupes qui sont renvoyés vers les SMX/SMM en vue de leur calcul. Alors que sur Kepler, les GPC sont formés de 1, 2 ou 3 SMX suivant les produits, le GM107 se contente d'un seul gros GPC équipé de 5 SMM.
Voici une représentation visuelle des différents GPU d'entrée / milieu de gamme de Nvidia (notez que la représentation miniature des SMX/SMM est basée sur la version officielle qui n'est pas tout à fait correcte comme nous le verrons par la suite) :
| [ GK106 ] [ GM107 ] [ GK107 ] [ GK208 ] |
Si nous comparons le GM107 au GK107, nous pouvons observer que Nvidia conserve la même structure de base du GPU, à savoir 1 GPC et 2 contrôleurs mémoire 64-bit, mais passe de 2 SMX à 5 SMM et de 256 à 2048 Ko de cache L2.
Un dernier point intéressant à observer, voici pour comparaisons les spécificités de tous les GPU 28 nm de la marque :
GK110 : 5 GPC, 15 SMX, bus 384-bit, 1536 Ko de L2
GK104 : 4 GPC, 8 SMX, bus 256-bit, 512 Ko de L2
GK106 : 3 GPC, 5 SMX, bus 192-bit, 384 Ko de L2
GM107 : 1 GPC, 5 SMM, bus 128-bit, 2048 Ko de L2
GK107 : 1 GPC, 2 SMX, bus 128-bit, 256 Ko de L2
GK208 : 1 GPC, 2 SMX, bus 64-bit, 512 Ko de L2
Nous pouvons constater que Nvidia est passé d'un cache L2 de 128 Ko par contrôleur mémoire 64-bit sur les premiers GPU Kepler à 256 Ko sur le GK110 puis à 512 Ko pour le GK208 et enfin à 1024 Ko pour le GM107.
Auparavant, nous avions interrogé Nvidia (mais également AMD) sur les raisons qui faisaient qu'ils n'optaient pas pour un cache L2 plus important. Leur réponse avait été similaire : cela a un coût élevé pour un rendement réduit dans le cas d'un GPU. Une explication logique : puisque les GPU sont des machines prévues pour masquer une énorme latence, plusieurs centaines de cycles, et qui effectuent des accès plutôt séquentiels qu'aléatoires, les caches généraux ont moins d'importance.
Du coup qu'est-ce qui a changé avec le GM107 ? Pourquoi celui-ci bénéficierait-il plus d'un gros cache L2 ? Nvidia nous a répondu que pour ce GPU GM107, compte tenu de la non-évolution du bus mémoire par rapport au nettement moins véloce GK107, le compléter par un plus large cache L2 était une bonne idée.
Le plus large cache L2 viendrait donc en quelque sorte compenser pour le manque d'évolution des interfaces mémoire. De notre côté nous rajouterons qu'il y a probablement d'autres arguments en jeu tels qu'une réduction progressive du coût du cache L2 avec l'évolution des procédés de fabrication et un intérêt grandissant pour celui-ci dans le cadre du GPU computing.
1.66 triangles et 16 pixels par cycleLe GM107 intègre un GPC et par conséquent un seul moteur de rastérisation, ce qui signifie que le débit de triangles affichés à l'écran est de 1 par cycle, tout comme pour le GK107, un point qui peut être important avec un niveau de tessellation élevé.
N'exploiter qu'un seul GPC pour ce GPU Maxwell de première génération permet de simplifier le design de la puce, notamment au niveau du tissu d'interconnexion global du GPU, ce qui autorise probablement des gains sur le plan de la consommation. Cela fait partie des points sur lesquels Nvidia a travaillé dans le cadre du GPU GK20A du Tegra K1, qui pousse par contre la simplification plus loin en n'intégrant qu'un seul SMX. Un second GPU Maxwell serait en préparation, le plus petit GM108, et reprendrait évidemment ce même principe d'un seul GPC, peut-être avec 2 ou 3 SMM et bus 64-bit.
Sur Kepler, chaque moteur de rastérisation est capable de débiter jusqu'à 8 pixels par cycle, si le triangle en couvre au moins autant. Pour autoriser un débit de 16 pixels par cycle pour le GM107, équipé de 16 ROP, Nvidia a poussé son moteur de rastérisation à un débit équivalent, mais nous ne savons pas s'il s'agit d'une particularité spécifique à l'architecture Maxwell ou au GM107.
A noter que tout comme les SMX, les SMM sont capables de débiter 128 bits de pixels par cycle, ce qui équivaut à 4 pixels 32-bit ou à 2 pixels HDR. Avec 5 SMM, et même avec 4 SMM dans le cas de la version castrée du GM107 utilisée sur la GeForce GTX 750, le débit de 16 pixels par cycle peut donc être soutenu.
Du côté du traitement de la géométrie, les SMX sont capables de charger un vertex tous les deux cycles, mais ce débit a été réduit à un vertex tous les 3 cycles pour chaque SMM (ce qui correspond au chargement de 1 triangle par cycle quand le maillage des objets est optimisé). Comme nous le disions plus haut, le débit de triangles affichés à l'écran est de 1 par cycle et 3 SMM permettent donc de le maintenir. Par contre, dans le rendu 3D en temps réel, il n'y a pas que des triangles qui sont réellement rendus et affichés, nombreux sont ceux qui sont masqués parce qu'ils sont en dehors du champ de vision ou parce qu'ils tournent le dos à la caméra (c'est le cas statistiquement de la moitié des triangles qui composent personnages et autres objets).
Le débit du culling, qui consiste à éjecter du pipeline de rendu ces triangles masqués, est donc important lui aussi. Cette opération est traitée au niveau des SMX ou des SMM avec le débit maximal de ceux-ci. Le SMX pouvait donc éjecter du rendu un triangle tous les 2 cycles, contre un tous les 3 cycles pour le SMM. Une GTX 750 Ti, avec 5 SMM peut ainsi traiter jusqu'à 1.67 triangle/cycle quand ceux-ci ne poursuivent pas leur chemin jusqu'au rendu final, contre 1.33 triangle/cycle pour la GTX 750, 1 triangle/cycle pour le GK107 et jusqu'à 2.5 triangles/cycle pour le GK106.
Moteur vidéo boostéLes GPU Maxwell de première génération reprennent le bloc vidéo NVENC introduit sur Kepler mais boosté pour l'occasion. L'encodage H.264 qui pouvait être traité à 4x la vitesse qui équivaut au temps réel (1080p30 ?) sur Kepler est 50 à 100% plus rapide, alors que le décodage est 8 à 10x plus rapide.
La consommation se retrouve réduite d'une part grâce à un nouveau cache local pour le décodeur, et d'autre part à travers un nouveau power state, le GC5, qui a été calibré spécifiquement pour les charges GPU légères.
Sommaire
1 - Introduction
2 - Maxwell 1st gen: 28nm, aperçu global
3 - Maxwell 1st gen: le SMM en détails
4 - Maxwell 1st gen: du mieux pour le GPU computing
5 - Performances théoriques : pixels
6 - Performances théoriques : géométrie
7 - Spécifications, la GTX 750 Ti de référence
8 - Consommation, efficacité énergétique
9 - Protocole de test
10 - Benchmark : Anno 2070
11 - Benchmark : Batman Arkham Origins
2 - Maxwell 1st gen: 28nm, aperçu global
3 - Maxwell 1st gen: le SMM en détails
4 - Maxwell 1st gen: du mieux pour le GPU computing
5 - Performances théoriques : pixels
6 - Performances théoriques : géométrie
7 - Spécifications, la GTX 750 Ti de référence
8 - Consommation, efficacité énergétique
9 - Protocole de test
10 - Benchmark : Anno 2070
11 - Benchmark : Batman Arkham Origins
12 - Benchmark : Battlefield 4
13 - Benchmark : Crysis 3
14 - Benchmark : Far Cry 3
15 - Benchmark : GRID 2
16 - Benchmark : Hitman Absolution
17 - Benchmark : Metro Last Light
18 - Benchmark : Splinter Cell Blacklist
19 - Benchmark : Tomb Raider
20 - Récapitulatif des performances
21 - Overclocking
22 - Conclusion
13 - Benchmark : Crysis 3
14 - Benchmark : Far Cry 3
15 - Benchmark : GRID 2
16 - Benchmark : Hitman Absolution
17 - Benchmark : Metro Last Light
18 - Benchmark : Splinter Cell Blacklist
19 - Benchmark : Tomb Raider
20 - Récapitulatif des performances
21 - Overclocking
22 - Conclusion
Vos réactions
Contenus relatifs
- [+] 08/03: GDC: Nvidia parle du Tile Caching d...
- [+] 01/08: Tile rendering pour Maxwell et Pasc...
- [+] 24/03: GDC: VR: Nvidia Multi-Res Shading e...
- [+] 23/03: GDC: Async Compute : ce qu'en dit N...
- [+] 22/09: Nvidia dévoile une 'vraie' GTX 980 ...
- [+] 09/09: Les GTX 900 supportent-elles correc...
- [+] 22/08: Nvidia GeForce GTX 950, MSI Gaming ...
- [+] 22/07: Nvidia baisse le prix de la GTX 750...
- [+] 02/06: Computex: Nvidia: pas besoin de wat...
- [+] 01/06: Nvidia GeForce GTX 980 Ti 6 Go : la...