
GDC: Nvidia parle du Tile Caching de Maxwell et Pascal



En parallèle de la GDC et lors de la présentation à la presse de la GeForce GTX 1080 Ti, Nvidia a communiqué officiellement pour la première fois au sujet d'une optimisation introduite depuis les GPU Maxwell : le Tile Caching.
Cet été, David Kanter de real world technologies avait mis en évidence un comportement étrange pour les GPU Maxwell et Pascal. Avec ceux-ci, la rastérisation de plusieurs triangles progressait par blocs plus ou moins petits de l'image (appelés tiles en anglais) et non pas strictement triangle par triangle. Contrairement à certaines analyses, nous étions alors sceptiques par rapport au rapprochement qui était fait avec le tile based rendering (TBR) ou tile based deffered rendering (TBDR) des GPU mobiles Adreno, Mali ou PowerVR. Ces modes de rendu sont peu efficaces avec une géométrie complexe et posent problème avec certaines techniques de rendu avancées. Des contraintes qui sont incompatibles avec un GPU haut de gamme destiné au PC. Nous estimions alors qu'il s'agissait d'une optimisation opportuniste spécifique à certaines situations.
Face à ces discussions et à l'introduction par AMD d'une approche similaire, voire identique, Nvidia vient de clarifier le fonctionnement de la rastérisation sur ses GPU Maxwell et Pascal. Ce qui commence par lui donner un nom : le Tile Caching.
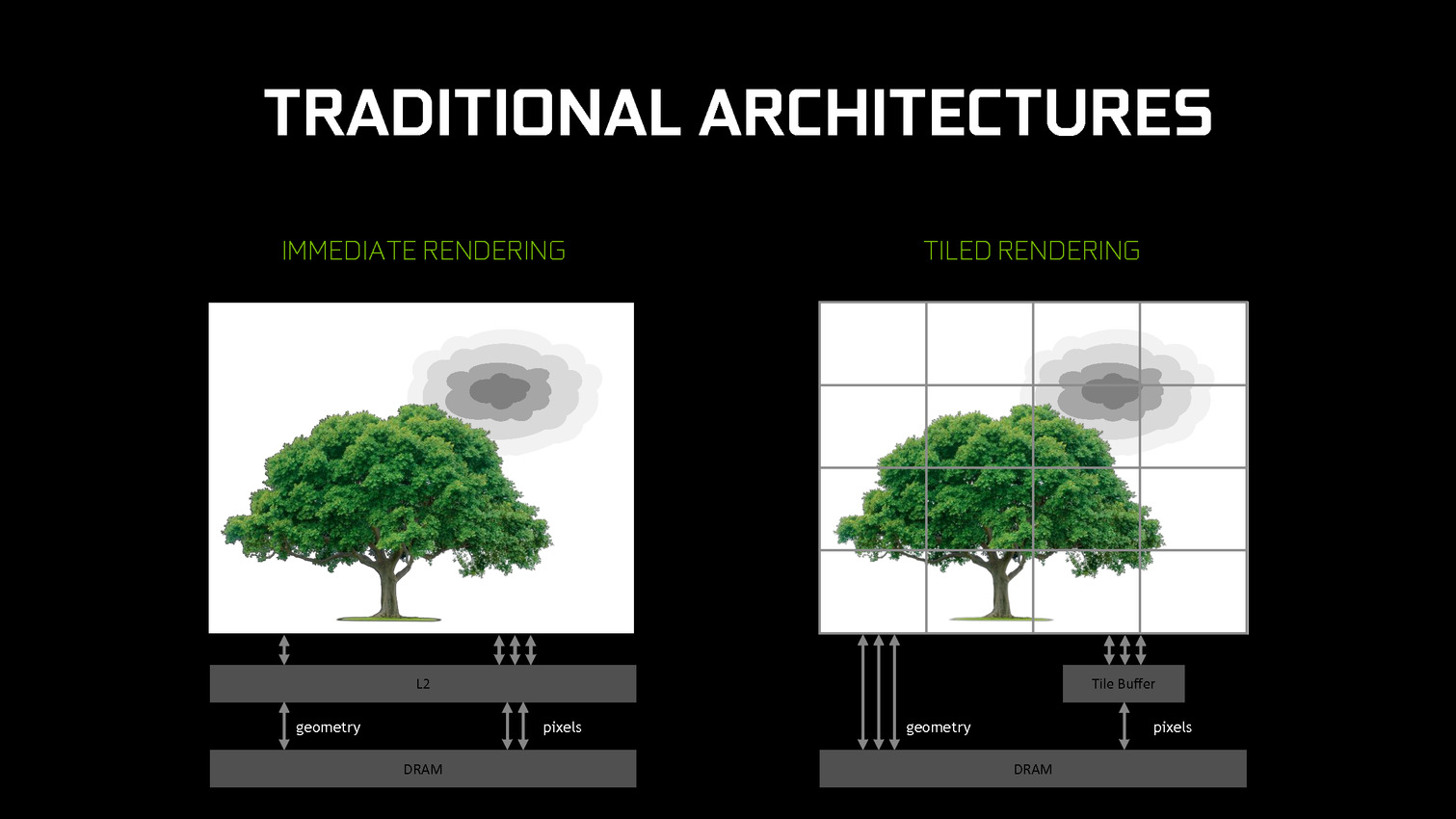
Traditionnellement, les GPU d'AMD et de Nvidia fonctionnent suivant le principe du rendu immédiat. Un triangle est pris en charge, il est découpé en pixels, les pixels sont écrits en mémoire. Si un second triangle traité par la suite se trouve entre le premier et la caméra, des pixels auront inutilement été calculés et écrits en mémoire. Différentes approches sont utilisées pour éviter ce gaspillage de ressources, mais il reste en partie présent.
De leur côté, les GPU mobiles font appel au TBR/TBDR qui fonctionne en deux passes. La première consiste à traiter toute la géométrie et à la récrire en mémoire en la réorganisant de manière à savoir quels triangles sont présents chaque bloc de l'image. Lors d'une seconde passe, ces triangles sont envoyés vers le moteur de rastérisation tile par tile (avec tri de visibilité dans le cas du TBDR). La construction de l'image dans de petites tiles en cache fait que les pixels ne seront écrits qu'une seule fois en mémoire. Cela revient à utiliser plus de bande passante pour la géométrie mais moins pour les pixels. Un compromis dont l'intérêt dépend évidemment du ratio entre la charge sur ces deux points.
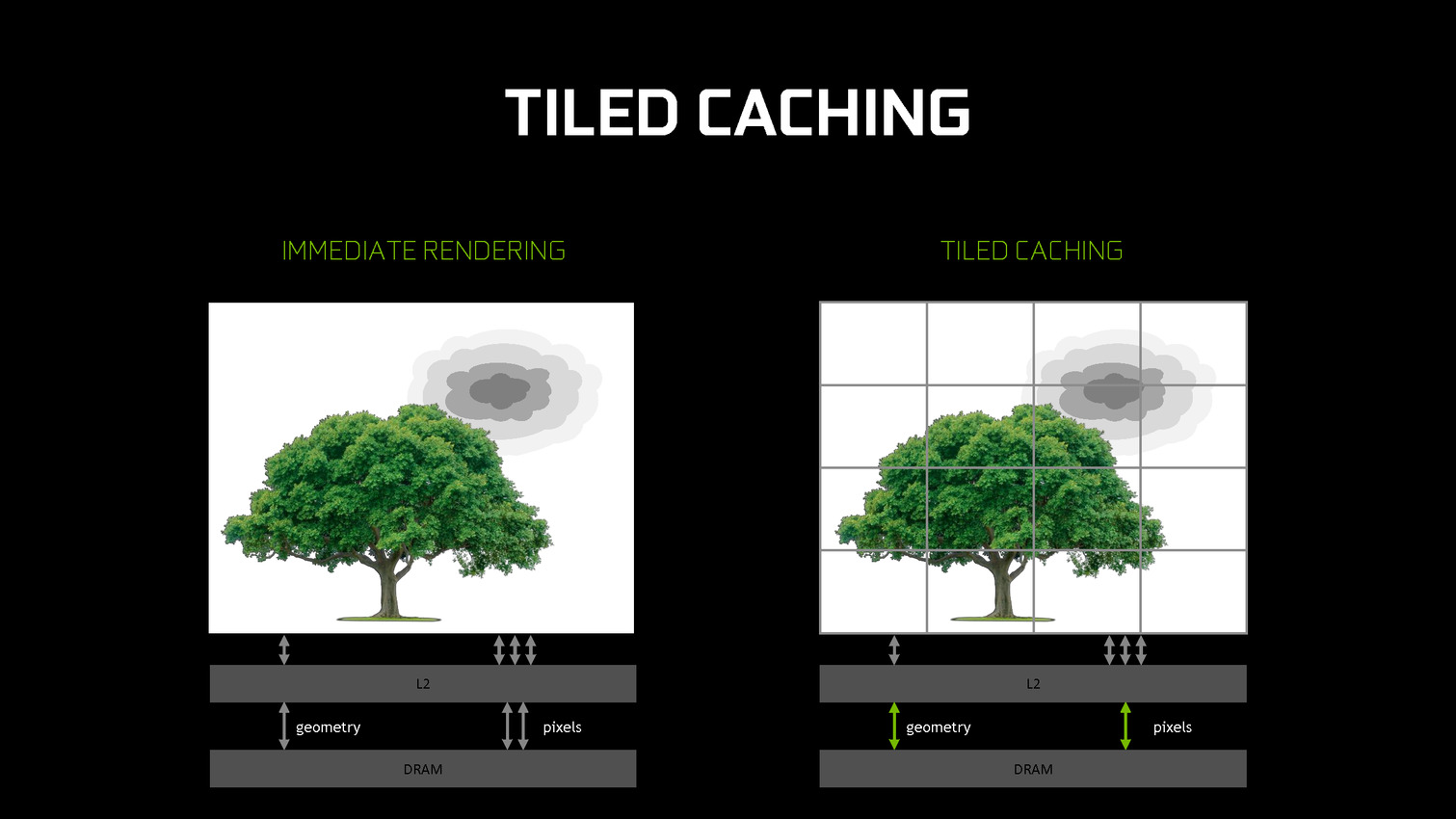
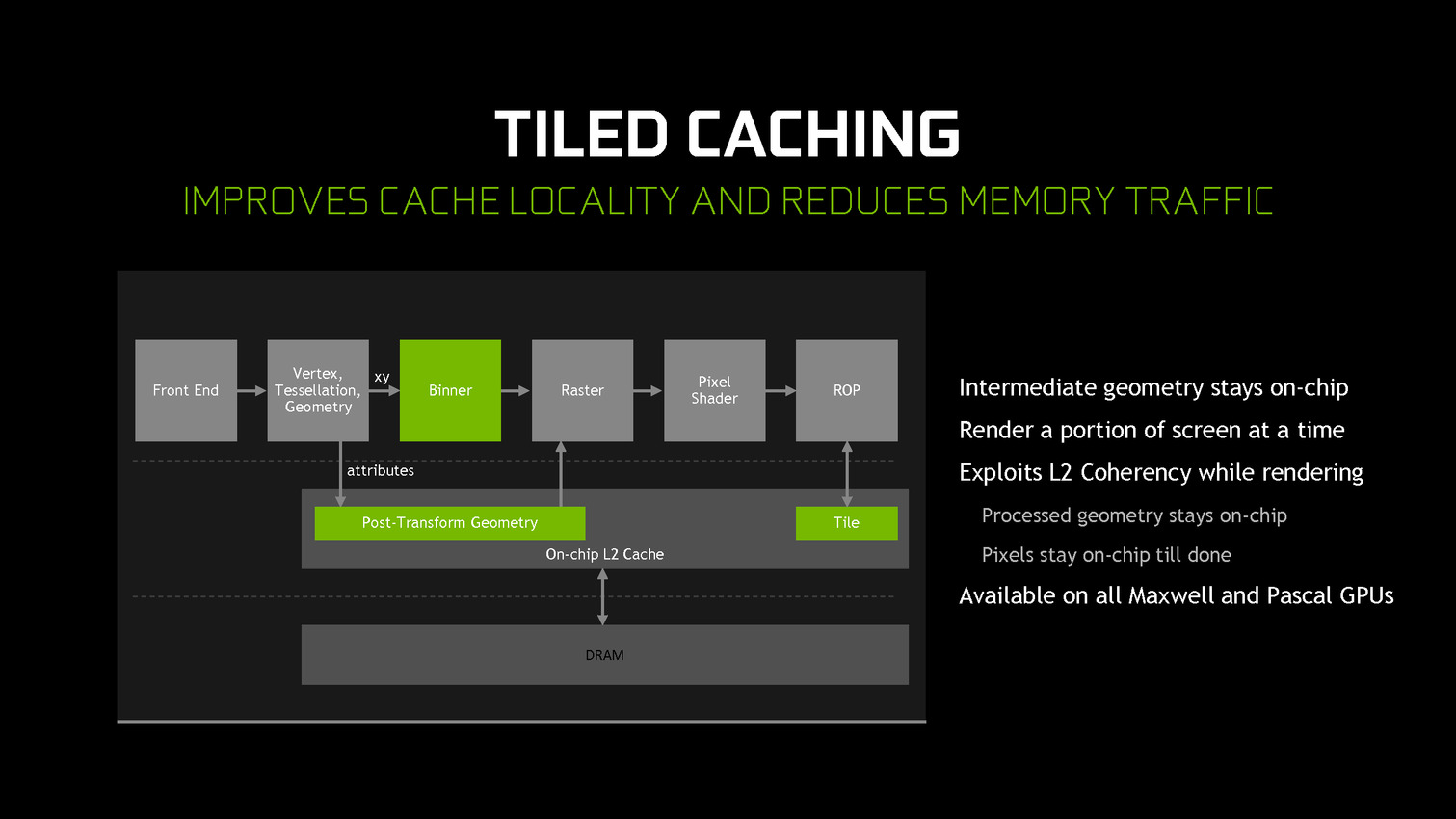
A partir des GPU Maxwell, Nvidia a cherché à pouvoir bénéficier d'une partie des avantages de cette seconde approche sans perdre la flexibilité du rendu immédiat. C'est le Tile Caching qui peut être vu comme un "rendu avec rastérisation retardée". Une fois un triangle traité, au lieu de l'envoyer vers le moteur de rastérisation, Nvidia le conserve en cache interne, ainsi que tous ses paramètres. Quand ce cache est rempli, la rastérisation peut débuter. Grossièrement, il s'agit d'interrompre le rendu et d'attendre d'avoir un plus d'informations (mais pas toutes) avant de le poursuivre plus efficacement.
Une petite unité fixe supplémentaire, appelée binner, se charge de suivre la position et la couverture de chaque triangle en cache. Quand le temps de leur rastérisation est arrivé, parmi ces quelques triangles, le GPU sait lesquels seront assurément et totalement masqués. L'inverse n'est par contre pas vrai puisque, contrairement au TBR/TBDR, tous les triangles n'ont pas été traités en amont, juste quelques-uns. Il s'agit d'une optimisation localisée et opportuniste plus que d'un changement de philosophie global pour ces GPU.
Cette approche permet de traiter la rastérisation par tile et non pas par triangle. Il y a un surcoût au niveau de la rastérisation (même si Nvidia profite probablement de son moteur de projection multiple pour le limiter) mais ces tiles peuvent rester en cache. Elles ne sont alors écrites en mémoire que quand que tous les triangles en cache et qui y sont visibles ont été traités. Contrairement au TBR/TBDR, ces tiles seront réécrites en mémoire plusieurs fois lorsque d'autres morceaux de géométrie qui les parcourent seront traités.
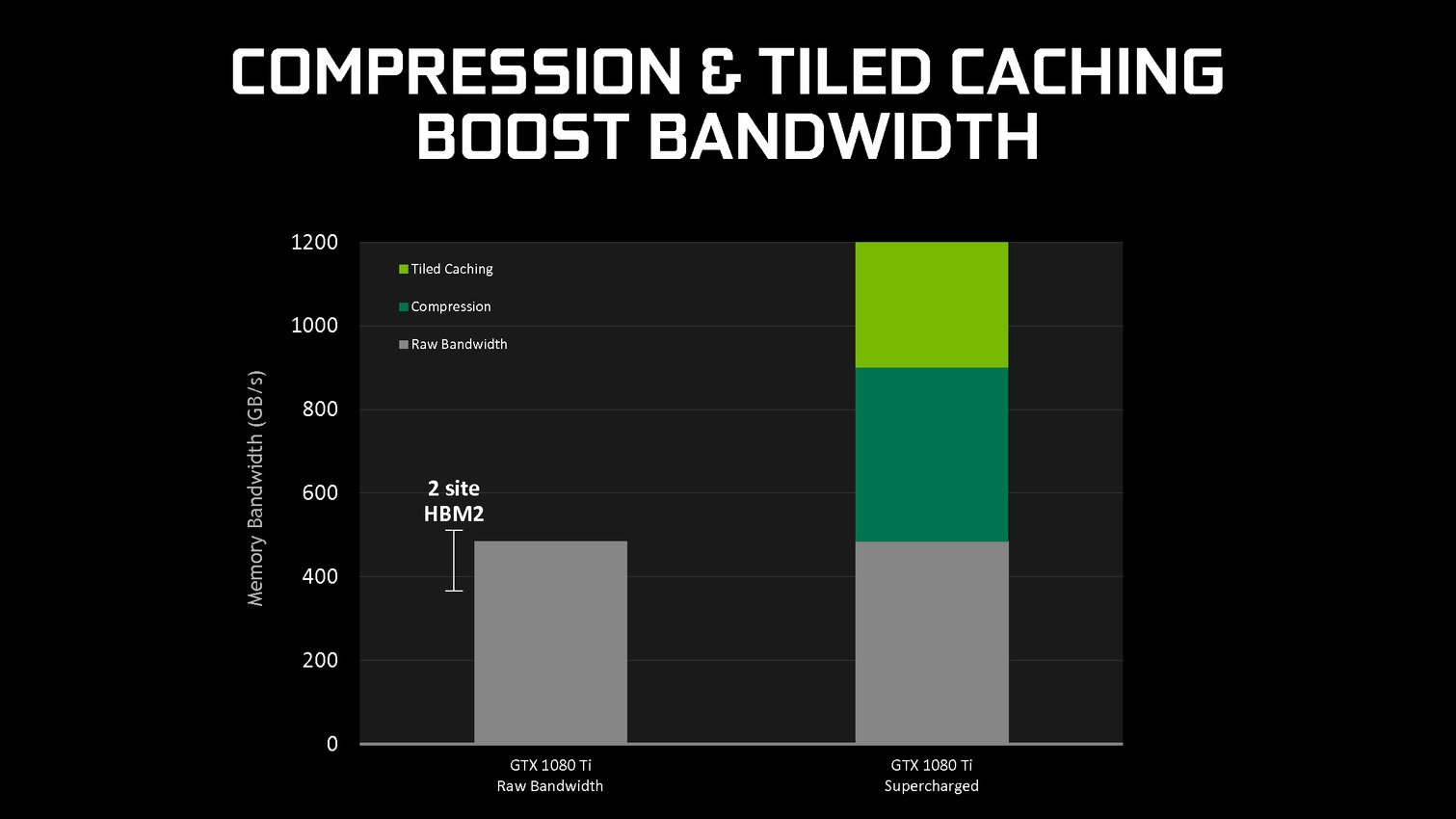
Nvidia nous précise qu'aucun cache spécifique n'a été implémenté et que c'est le cache L2 qui est exploité. C'est la raison pour laquelle il a fait un bond énorme en taille à partir des GPU Maxwell (1 voire 2 Mo par 128-bit de bus contre 256 Ko sur Kepler). Un système d'optimisation automatique à base d'heuristiques a été mis en place pour opter pour la taille la plus adaptée au niveau du buffer de triangle et des tiles, mais Nvidia peut configurer tout cela manuellement pour chaque jeu ou débrayer le Tile Caching s'il est contreproductif.
En se contentant de chercher des opportunités d'optimisation locales, par morceau de géométrie, Nvidia parvient à obtenir des gains sympathiques, certes inférieurs à ceux obtenus par une architecture purement TBR/TBDR, mais qui permettent de conserver plus de flexibilité et de performances dans un maximum de situations. C'est un des piliers de l'excellente efficacité des GPU Maxwell et Pascal. Cela fait également partie d'une stratégie réfléchie qui consiste à chercher à créer de la valeur au niveau de ses propres puces plutôt que via l'exploitation d'une mémoire plus onéreuse (bus 512-bit, HBM ).
Contenus relatifs
- [+] 08/03: GDC: Après les R9 Fury, les Radeon ...
- [+] 08/03: GDC: Nvidia parle du Tile Caching d...
- [+] 01/03: GDC: Nvidia va proposer des GTX 108...
- [+] 01/03: GDC: Nvidia annonce la GeForce GTX ...
- [+] 28/02: GDC: AMD Vega : démo du FP16 et du ...
- [+] 28/02: GDC: Wave programming pour booster ...
- [+] 21/02: GDC en approche, AMD et Nvidia sur ...
- [+] 01/08: Tile rendering pour Maxwell et Pasc...
- [+] 24/03: GDC: VR: Nvidia Multi-Res Shading e...
- [+] 23/03: GDC: Async Compute : ce qu'en dit N...