
Les derniers contenus liés au tag GDC 2017
GDC: Wave programming pour booster les perfs
GDC en approche, AMD et Nvidia sur les rangs
GDC: Après les R9 Fury, les Radeon RX Vega
GDC: Nvidia parle du Tile Caching de Maxwell et Pascal
GDC: Nvidia va proposer des GTX 1080 et 1060 OC
GDC: Nvidia annonce la GeForce GTX 1080 Ti 11 Go (maj)
GDC: AMD Vega : démo du FP16 et du HBCC
GDC: Après les R9 Fury, les Radeon RX Vega



Lors de la GDC, AMD n'a pas dévoilé de nouvelles informations techniques concernant sa future architecture et son futur GPU Vega 10. Mais à côté d'une démonstration du FP16 et du HBCC, le nom commercial des Radeon basées sur ce futur GPU haut de gamme a été dévoilé : ce sera tout simplement Radeon RX Vega.

AMD compte profiter de toute la communication qui a déjà été effectuée autour de ce nom de code pour en faire une marque, ce qui est assez logique. Et il n'est pas impossible que cette marque soit dérivée en Radeon RX Vega X, Radeon RX Vega ou encore Radeon RX Vega Nano, tout cela sera précisé à l'approche du lancement de ces cartes graphiques.
Parallèlement à ces Radeon haut de gamme, AMD devrait proposer des Radeon RX 500 qui reprendront les GPU Polaris actuels et peut-être un second plus petit GPU Vega. Après une année de recul, AMD pourra probablement profiter d'une nouvelle révision, d'un procédé de fabrication en 14nm qui a gagné en maturité ou tout simplement d'un tri plus fin des puces pour proposer des fréquences en hausse et/ou une consommation en baisse.
Les Radeon RX 500 et les Radeon RX Vega sont attendues pour le second trimestre 2017.
GDC: Nvidia parle du Tile Caching de Maxwell et Pascal
En parallèle de la GDC et lors de la présentation à la presse de la GeForce GTX 1080 Ti, Nvidia a communiqué officiellement pour la première fois au sujet d'une optimisation introduite depuis les GPU Maxwell : le Tile Caching.
Cet été, David Kanter de real world technologies avait mis en évidence un comportement étrange pour les GPU Maxwell et Pascal. Avec ceux-ci, la rastérisation de plusieurs triangles progressait par blocs plus ou moins petits de l'image (appelés tiles en anglais) et non pas strictement triangle par triangle. Contrairement à certaines analyses, nous étions alors sceptiques par rapport au rapprochement qui était fait avec le tile based rendering (TBR) ou tile based deffered rendering (TBDR) des GPU mobiles Adreno, Mali ou PowerVR. Ces modes de rendu sont peu efficaces avec une géométrie complexe et posent problème avec certaines techniques de rendu avancées. Des contraintes qui sont incompatibles avec un GPU haut de gamme destiné au PC. Nous estimions alors qu'il s'agissait d'une optimisation opportuniste spécifique à certaines situations.
Face à ces discussions et à l'introduction par AMD d'une approche similaire, voire identique, Nvidia vient de clarifier le fonctionnement de la rastérisation sur ses GPU Maxwell et Pascal. Ce qui commence par lui donner un nom : le Tile Caching.
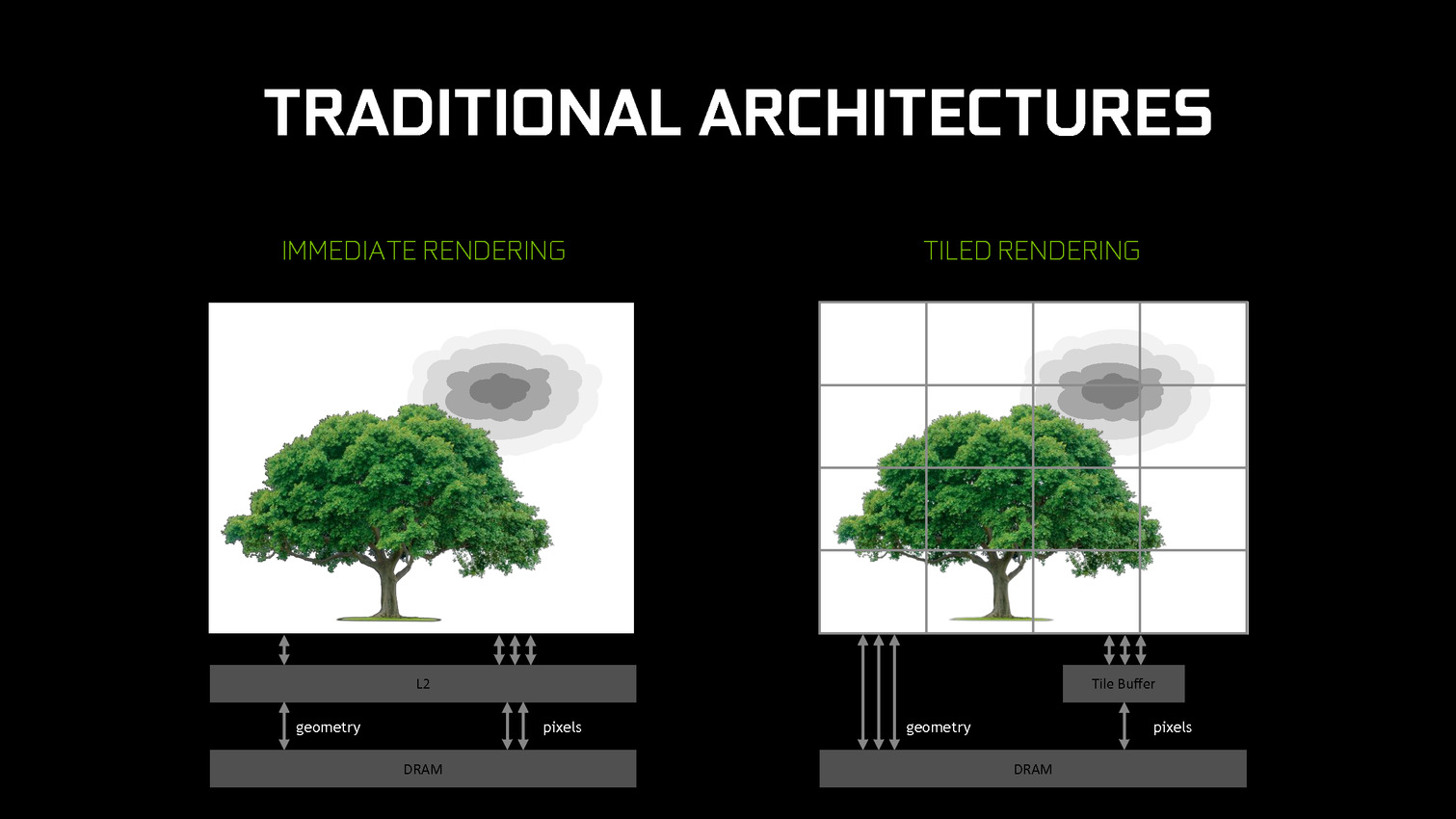
Traditionnellement, les GPU d'AMD et de Nvidia fonctionnent suivant le principe du rendu immédiat. Un triangle est pris en charge, il est découpé en pixels, les pixels sont écrits en mémoire. Si un second triangle traité par la suite se trouve entre le premier et la caméra, des pixels auront inutilement été calculés et écrits en mémoire. Différentes approches sont utilisées pour éviter ce gaspillage de ressources, mais il reste en partie présent.
De leur côté, les GPU mobiles font appel au TBR/TBDR qui fonctionne en deux passes. La première consiste à traiter toute la géométrie et à la récrire en mémoire en la réorganisant de manière à savoir quels triangles sont présents chaque bloc de l'image. Lors d'une seconde passe, ces triangles sont envoyés vers le moteur de rastérisation tile par tile (avec tri de visibilité dans le cas du TBDR). La construction de l'image dans de petites tiles en cache fait que les pixels ne seront écrits qu'une seule fois en mémoire. Cela revient à utiliser plus de bande passante pour la géométrie mais moins pour les pixels. Un compromis dont l'intérêt dépend évidemment du ratio entre la charge sur ces deux points.
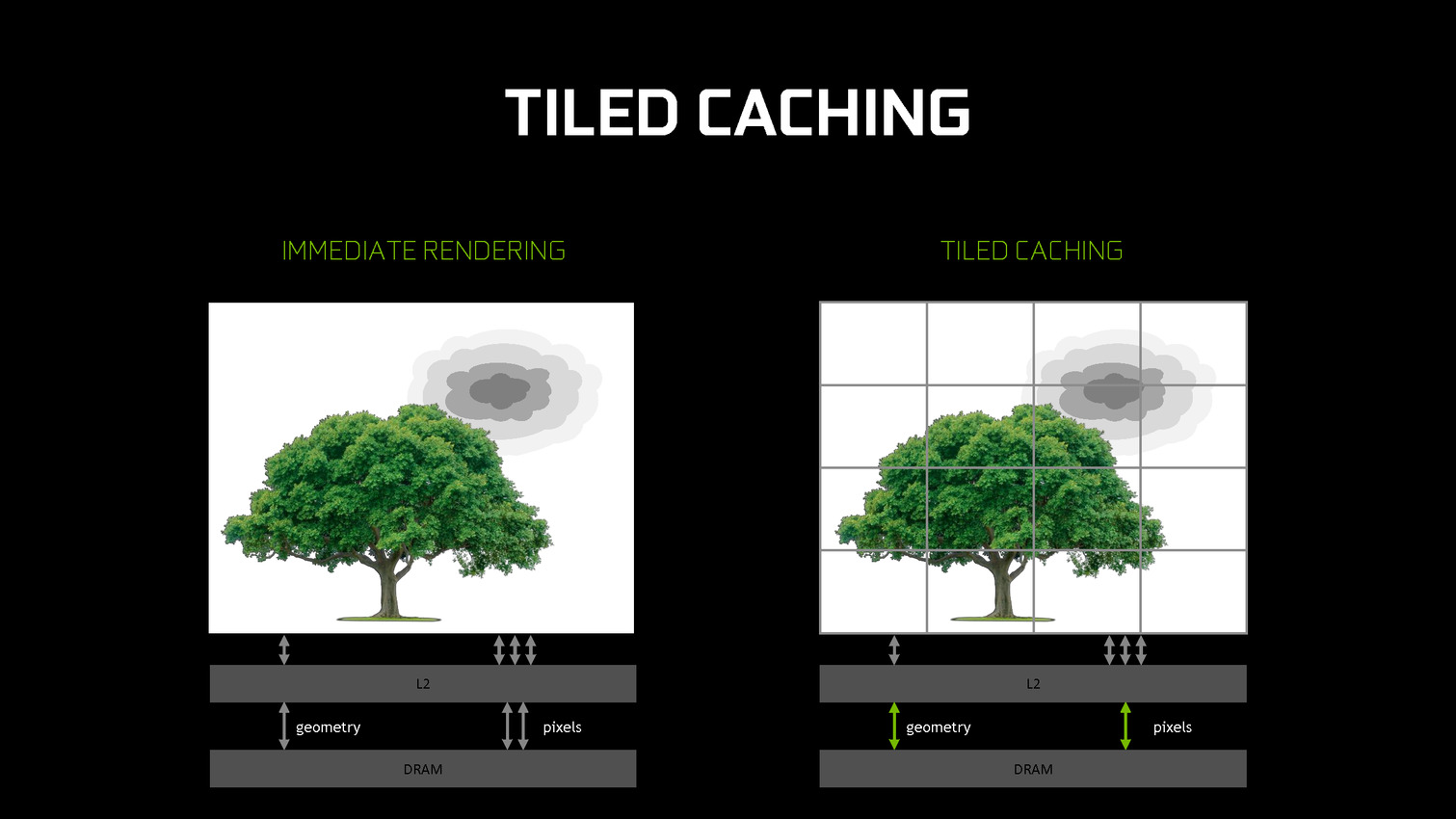
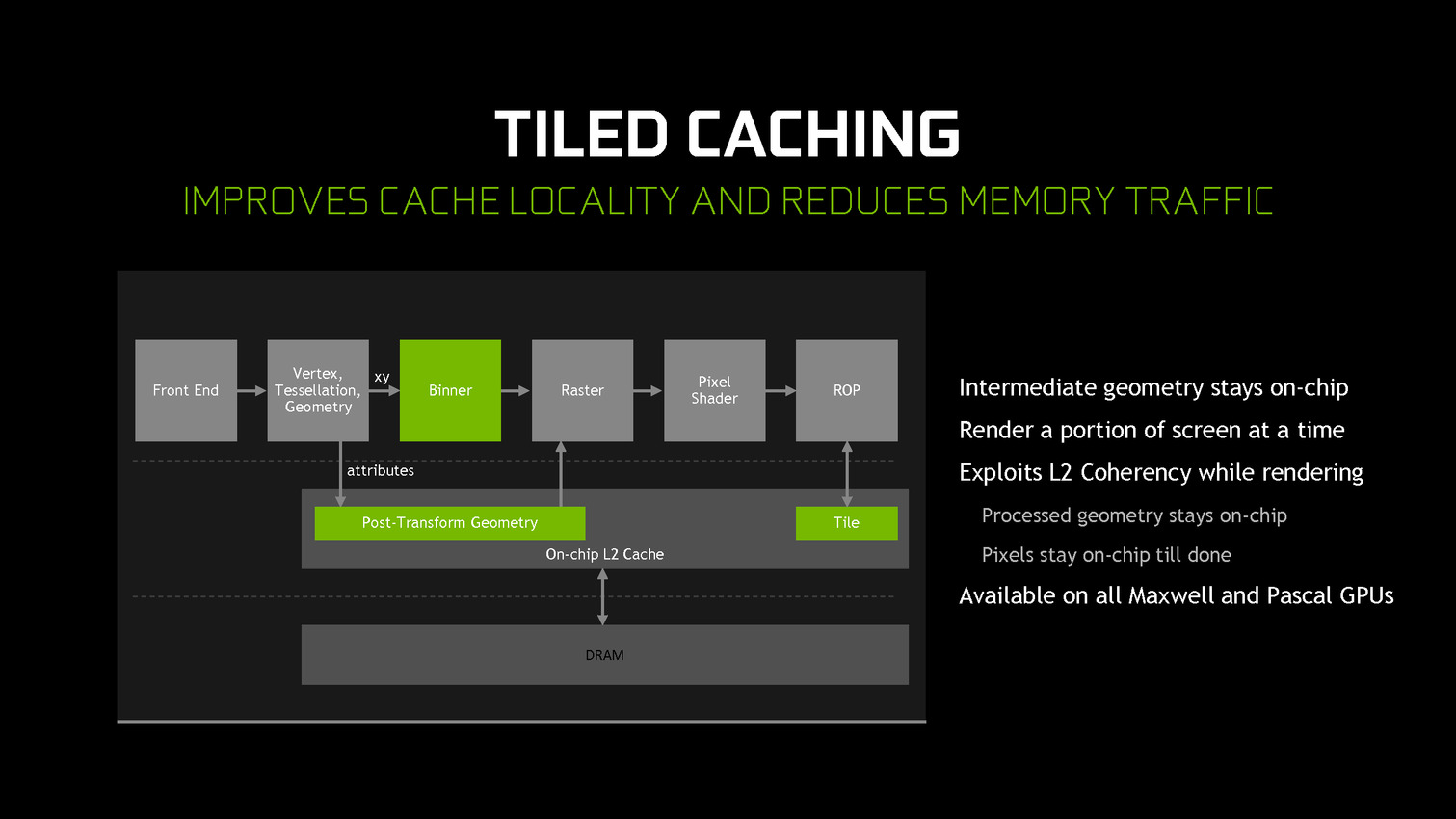
A partir des GPU Maxwell, Nvidia a cherché à pouvoir bénéficier d'une partie des avantages de cette seconde approche sans perdre la flexibilité du rendu immédiat. C'est le Tile Caching qui peut être vu comme un "rendu avec rastérisation retardée". Une fois un triangle traité, au lieu de l'envoyer vers le moteur de rastérisation, Nvidia le conserve en cache interne, ainsi que tous ses paramètres. Quand ce cache est rempli, la rastérisation peut débuter. Grossièrement, il s'agit d'interrompre le rendu et d'attendre d'avoir un plus d'informations (mais pas toutes) avant de le poursuivre plus efficacement.
Une petite unité fixe supplémentaire, appelée binner, se charge de suivre la position et la couverture de chaque triangle en cache. Quand le temps de leur rastérisation est arrivé, parmi ces quelques triangles, le GPU sait lesquels seront assurément et totalement masqués. L'inverse n'est par contre pas vrai puisque, contrairement au TBR/TBDR, tous les triangles n'ont pas été traités en amont, juste quelques-uns. Il s'agit d'une optimisation localisée et opportuniste plus que d'un changement de philosophie global pour ces GPU.
Cette approche permet de traiter la rastérisation par tile et non pas par triangle. Il y a un surcoût au niveau de la rastérisation (même si Nvidia profite probablement de son moteur de projection multiple pour le limiter) mais ces tiles peuvent rester en cache. Elles ne sont alors écrites en mémoire que quand que tous les triangles en cache et qui y sont visibles ont été traités. Contrairement au TBR/TBDR, ces tiles seront réécrites en mémoire plusieurs fois lorsque d'autres morceaux de géométrie qui les parcourent seront traités.
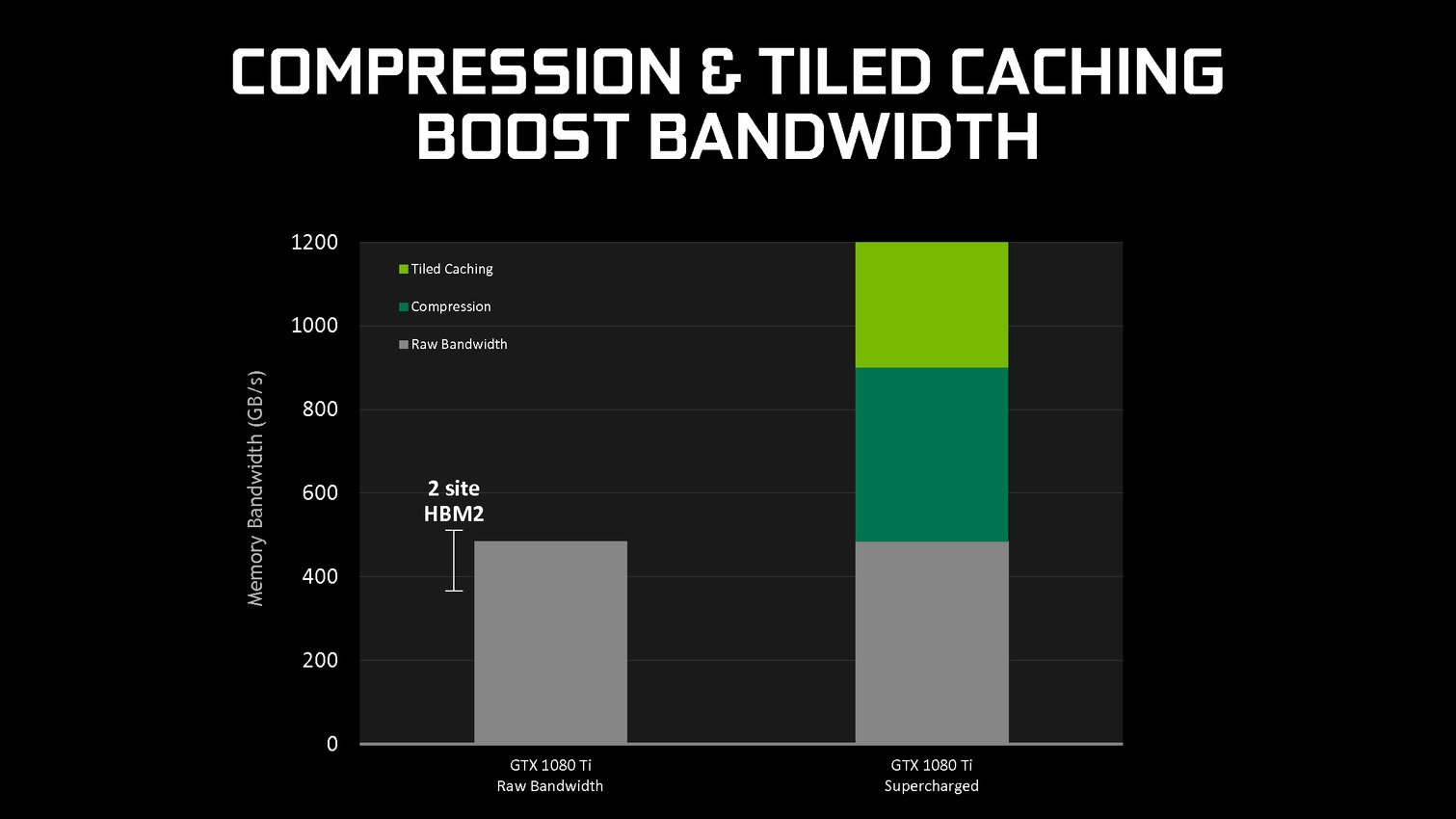
Nvidia nous précise qu'aucun cache spécifique n'a été implémenté et que c'est le cache L2 qui est exploité. C'est la raison pour laquelle il a fait un bond énorme en taille à partir des GPU Maxwell (1 voire 2 Mo par 128-bit de bus contre 256 Ko sur Kepler). Un système d'optimisation automatique à base d'heuristiques a été mis en place pour opter pour la taille la plus adaptée au niveau du buffer de triangle et des tiles, mais Nvidia peut configurer tout cela manuellement pour chaque jeu ou débrayer le Tile Caching s'il est contreproductif.
En se contentant de chercher des opportunités d'optimisation locales, par morceau de géométrie, Nvidia parvient à obtenir des gains sympathiques, certes inférieurs à ceux obtenus par une architecture purement TBR/TBDR, mais qui permettent de conserver plus de flexibilité et de performances dans un maximum de situations. C'est un des piliers de l'excellente efficacité des GPU Maxwell et Pascal. Cela fait également partie d'une stratégie réfléchie qui consiste à chercher à créer de la valeur au niveau de ses propres puces plutôt que via l'exploitation d'une mémoire plus onéreuse (bus 512-bit, HBM ).
GDC: Nvidia va proposer des GTX 1080 et 1060 OC
Nvidia va proposer à ses partenaires des versions OC de ses kits GPU et mémoire pour les GTX 1080 et GTX 1060 qu'ils conçoivent. Si les GPU seront identiques, ils seront associés à de la mémoire plus rapide.

La GeForce GTX 1080 8 Go OC profitera de la nouvelle GDDR5X 11 Gbps de Micron pour un gain de 10% au niveau de la bande passante mémoire. Du côté de la GeForce GTX 1060 6 Go OC, la mémoire GDDR5 passera de 8 Gbps à 9 Gbps. Aucune indication tarifaire ne nous a été donnée.
A voir bien entendu ce que feront les partenaires de ces nouvelles sous-déclinaisons et s'ils les réserveront à leurs versions OC les plus chères ou s'ils essayeront de les généraliser. Il sera également intéressant d'observer sur la marge d'overclocking, très élevée actuellement, progressera ou s'il s'agit uniquement de pouvoir proposer une certification à une fréquence légèrement supérieure.
GDC: Nvidia annonce la GeForce GTX 1080 Ti 11 Go (maj)
Mise à jour du 01/03 : ajout de quelques précisions sur les fréquences, prix et date de lancement.
Comme attendu, Nvidia a profité de la GDC pour dévoiler une nouvelle carte graphique haut de gamme : la GeForce GTX 1080 Ti. Au menu, les performances de la Titan X pour 500 de moins.

Attendue depuis quelques mois, la GeForce GTX 1080 Ti va enfin faire son apparition. Jen-Hsun Huang, le CEO de Nvidia, a profité d'un évènement organisé en marge de la GDC pour annoncer cette nouvelle carte graphique haut de gamme, très proche de la Titan X sur le plan des spécifications :
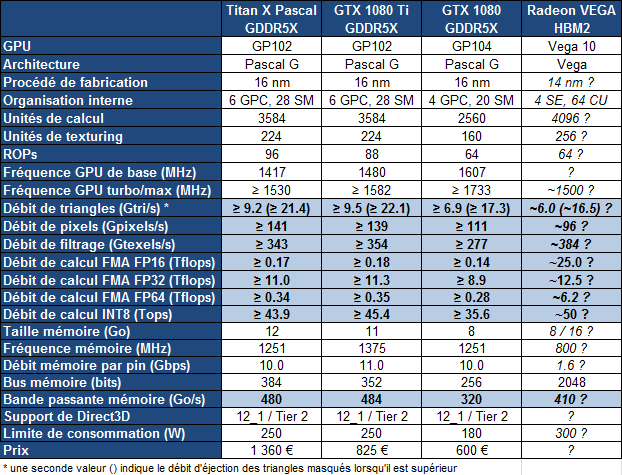
La GeForce GTX 1080 Ti reprend un GPU GP102 configuré de manière proche de celui de la Titan X, mais pas identique. Contrairement au nombre d'unités de calcul actives qui ne change pas (3584 sur 3840), l'interface mémoire a été bridée de 384-bit à 352-bit. C'est la raison pour laquelle la GTX 1080 Ti est équipée de 11 Go de mémoire GDDR5X et non de 12 Go.
Nvidia semble d'ailleurs avoir misé particulièrement sur le chiffre 11 qui se retrouve au niveau de la puissance de calcul mais également au niveau du débit de la GDDR5X qui monte à 11 Gbps. Nvidia indique sur ce point profiter de la capacité de son interface mémoire à monter en fréquence avec une nouvelle révision de la GDDR5X de Micron qui permet un signal plus propre. La bande passante reste donc similaire à celle de la Titan X.

Comme pour les précédentes GeForce 10 haut de gamme, Nvidia va proposer un modèle Founders Edition qui reprend une esthétique similaire à celle de la GTX 1080 mais avec des connecteurs d'alimentation 8+6 pins pour s'adapter au TDP de 250W. Sous le capot, Nvidia indique avoir amélioré quelque peu l'efficacité du ventirad mais sans nous en dire plus. Nous pouvons supposer qu'une bonne partie des gains proviennent de la surface plus importante du GP102 par rapport au GP104.

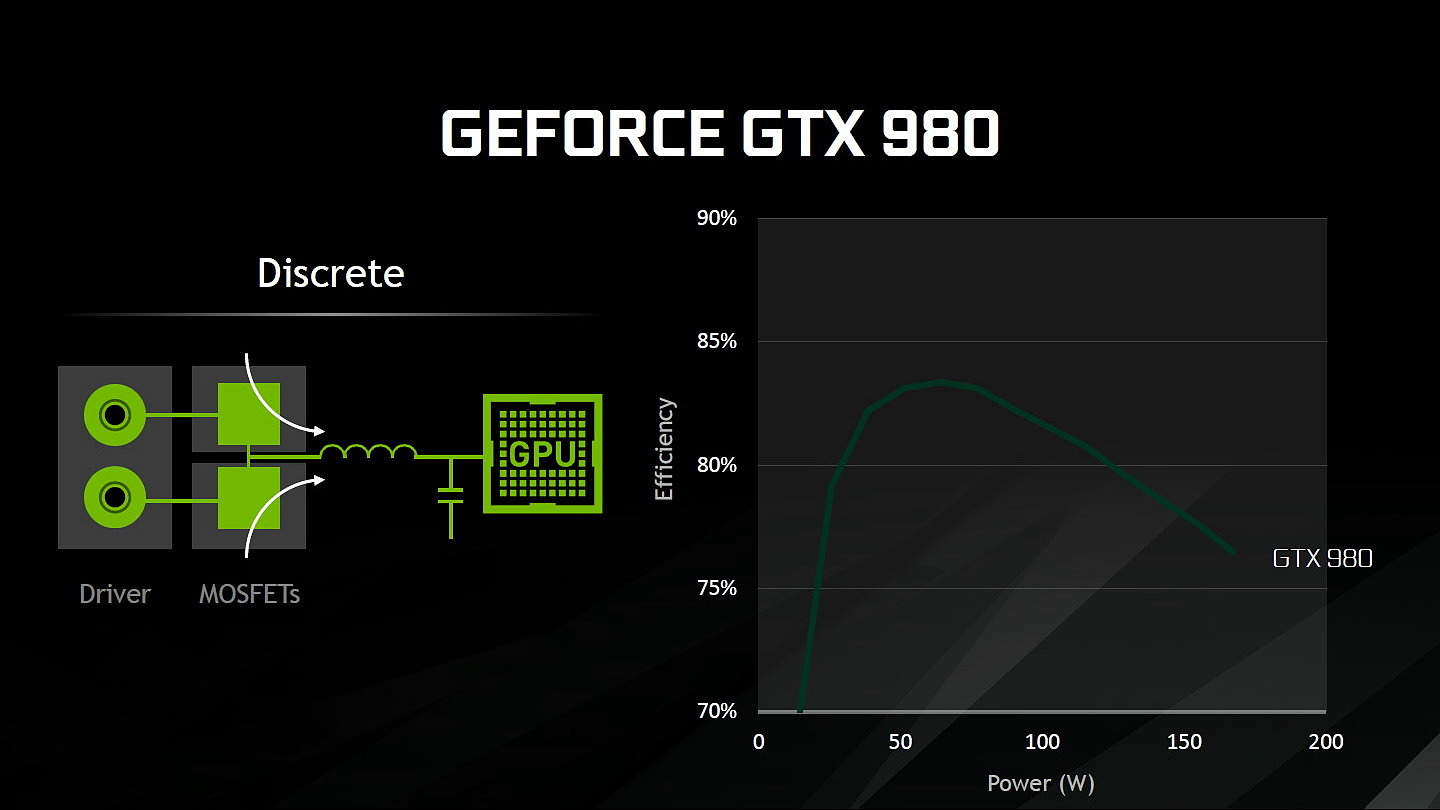
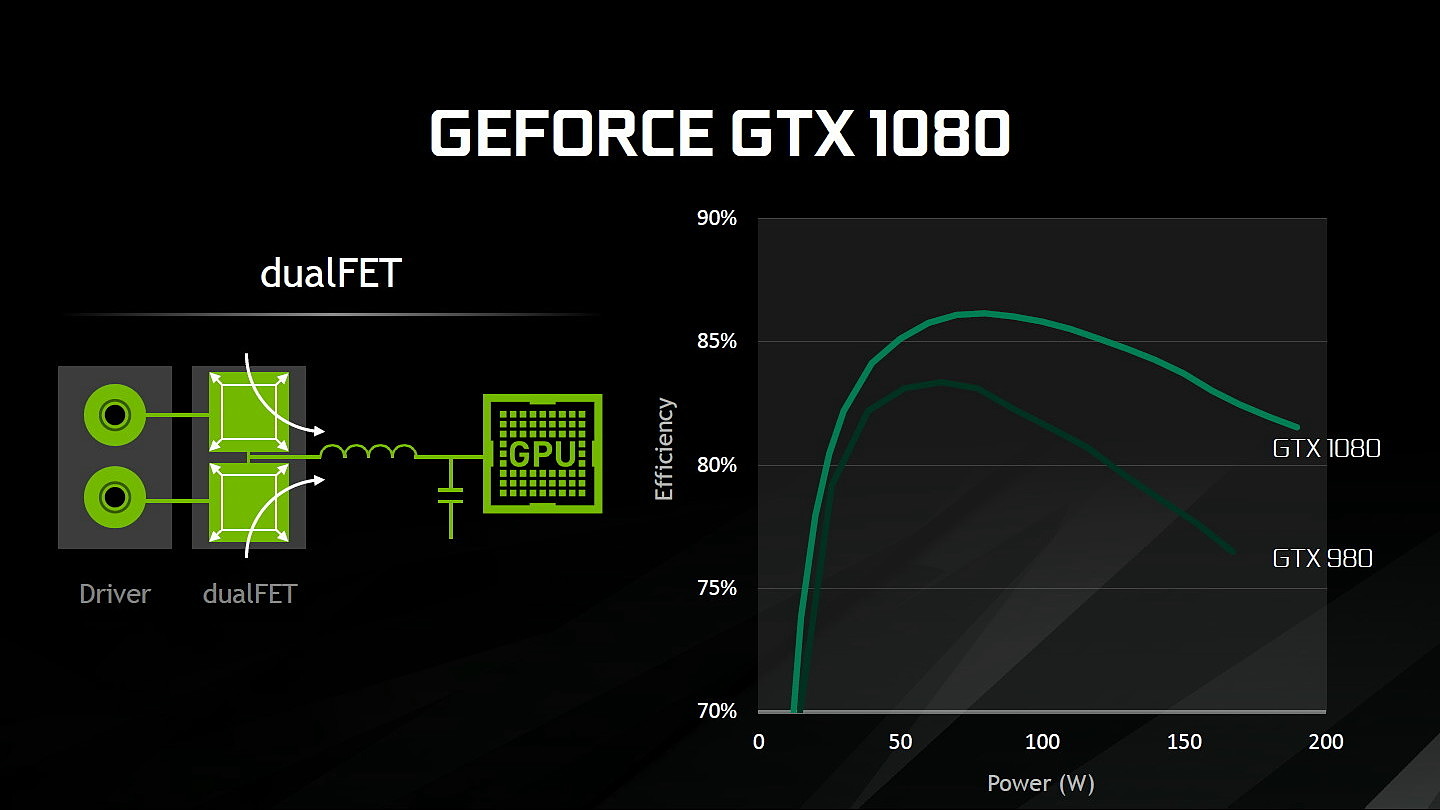
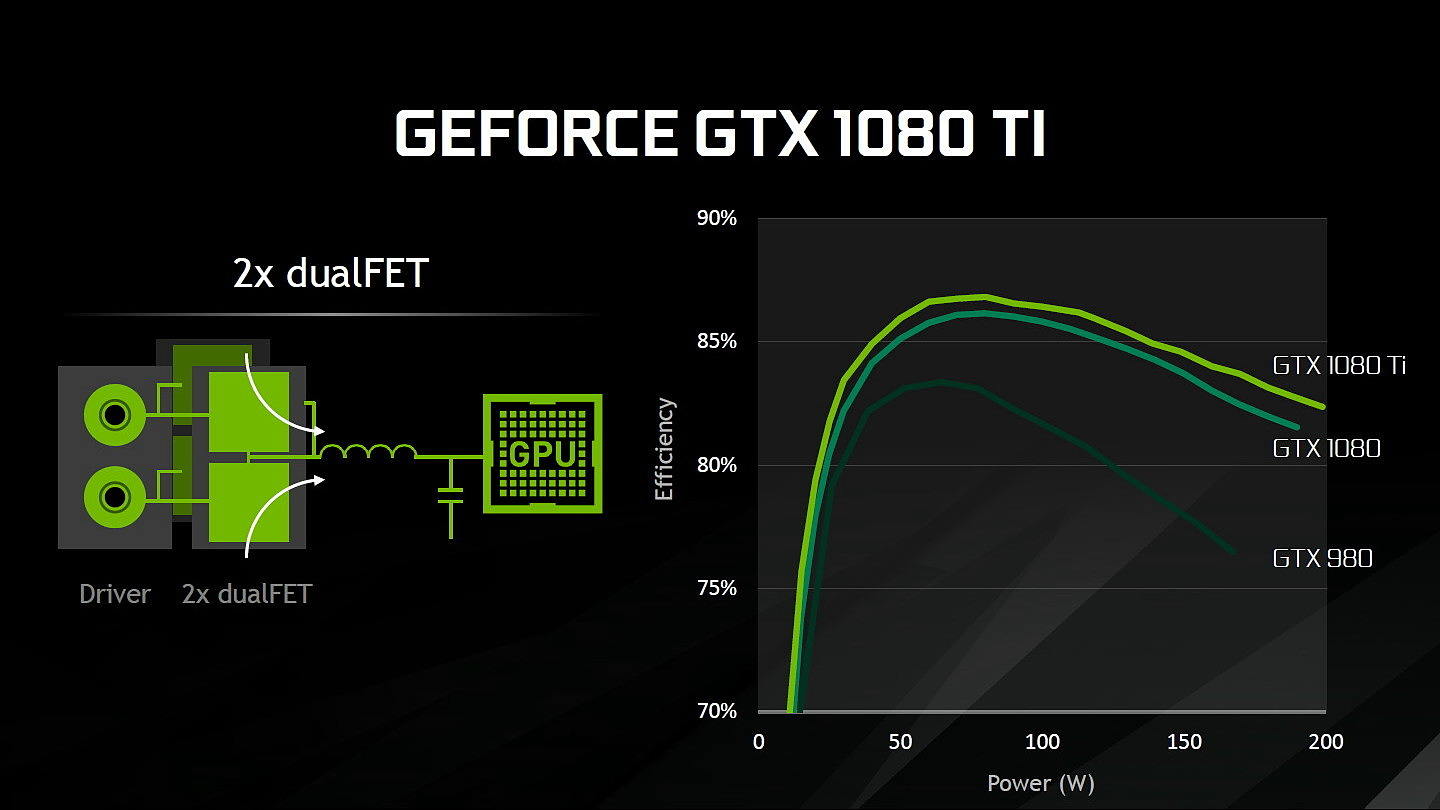
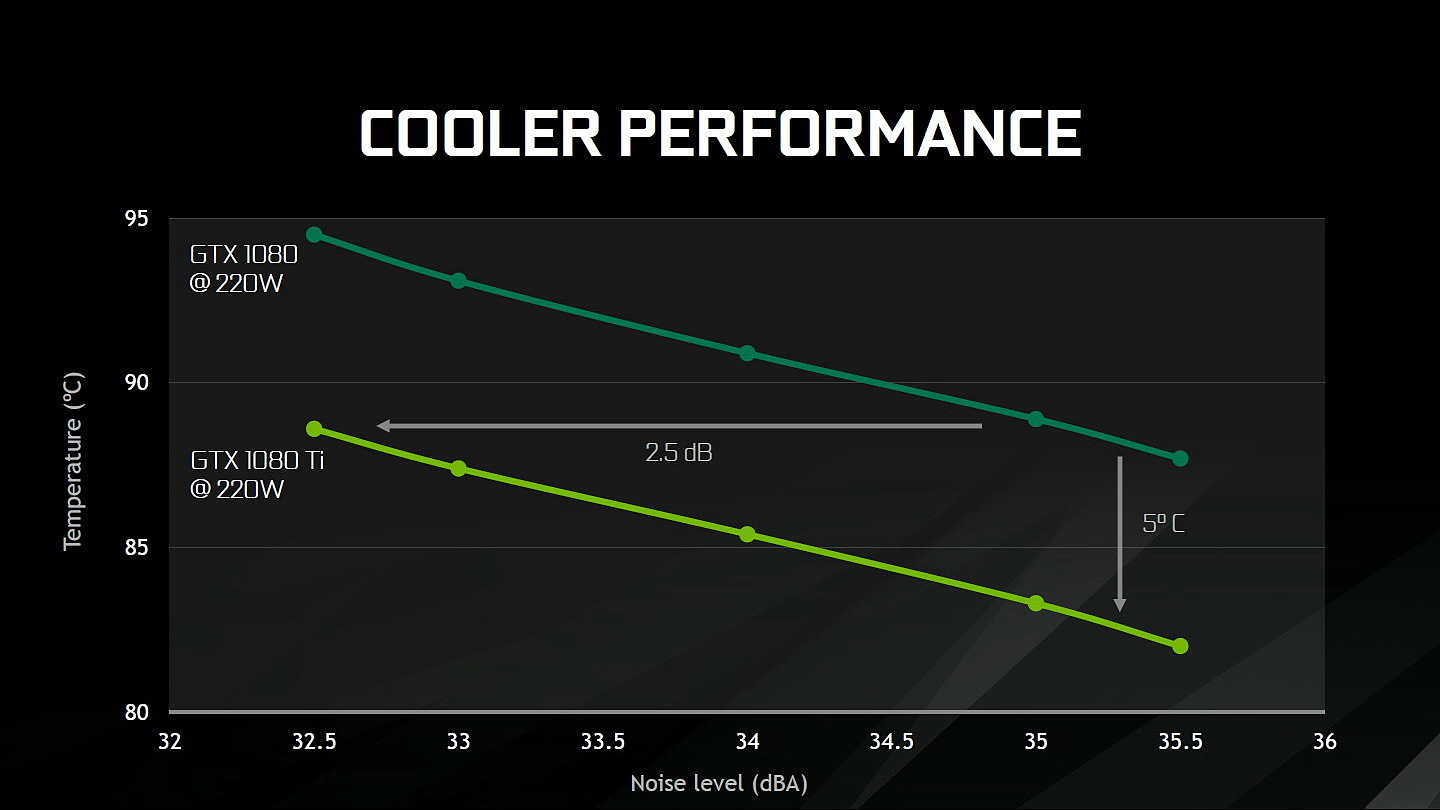

Au niveau du PCB, Nvidia explique avoir retravaillé l'étage d'alimentation. Equipé de 7 phases dédiées au GPU, il permet de délivrer jusqu'à 250A et pousserait le rendement encore un peu plus haut par rapport à la GTX 1080 grâce à un système à base de double DualFET.
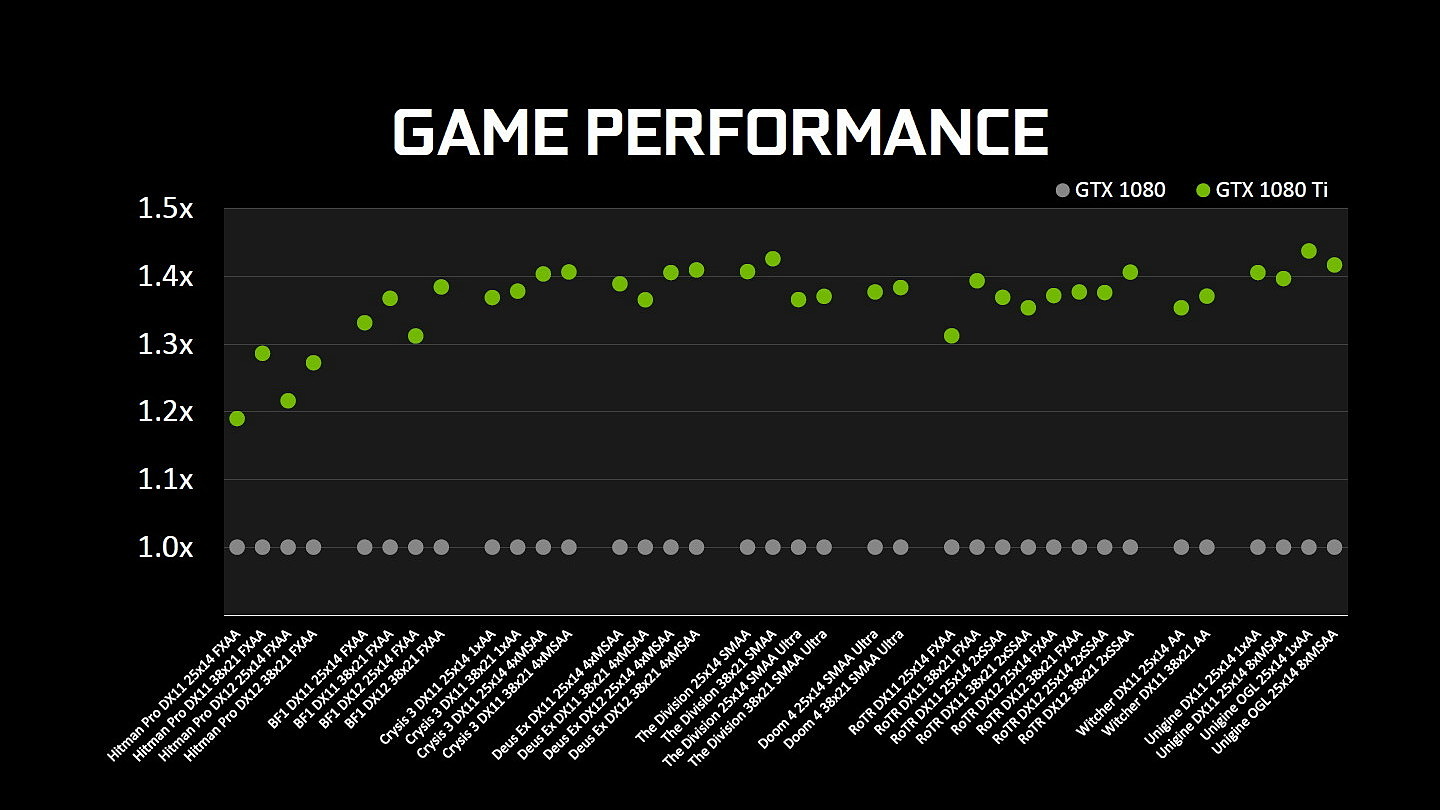
Sur le plan des performances, Nvidia parle d'un gain de 35% par rapport à la GTX 1080 mais nous supposons qu'il devrait en pratique se situer autour de 25% dans nos tests, comme pour la Titan X. Contrairement à cette dernière, les partenaires de Nvidia pourront proposer leurs propres designs qui devraient cette fois apporter assez facilement un gain de 35% sur la GTX 1080 FE.
La GeForce GTX 1080 Ti Founders Edition sera disponible au tarif de +/- 825 dès vendredi prochain alors que nous devrions vous en proposer un test la veille. Cette version FE sera la seule disponible au lancement et elle sera commercialisée en direct par Nvidia (les précommandes débutent demain) mais pas de manière exclusive comme c'est le cas pour la Titan X. Les versions personnalisées arriveront quelques semaines plus tard. Et bonne nouvelle, Nvidia en profite pour repositionner la GeForce GTX 1080 qui voit son tarif chuter d'une centaine d'euros.
La question qui ne trouve pas de réponse aujourd'hui concerne évidemment la comparaison avec la future Radeon Vega d'AMD. Sera-t-elle capable de lutter avec la GeForce GTX 1080 Ti ou devra-t-elle se contenter de la GTX 1080 ? Ce lancement début mars, nous laisse par contre penser que Nvidia estime que sa nouvelle solution conservera la première place.
Enfin notons que la Titan X actuelle perd tout intérêt et qu'il semble évident qu'elle sera remplacée sous peu par un modèle plus musclé. A base de GP102 complet ? Ou de GP100 ?
GDC: AMD Vega : démo du FP16 et du HBCC
AMD a profité de sa conférence Capsaicin organisée pendant la GDC pour effectuer de nouvelles démonstrations autour de son futur GPU Vega 10 et mettre en avant ses spécificités.
Ne vous attendez pas à un lancement d'une carte graphique à base de GPU Vega, ni a plus d'informations sur ses performances en jeu. Il est encore trop tôt pour cela, la GDC n'est pas une plateforme qui y est adaptée au vu d'un lancement plutôt attendu pour mai ou juin. Le but d'AMD est de continuer le teasing et de montrer aux développeurs ce dont est capable sa nouvelle architecture.
La première démonstration a mis en avant l'intérêt du FP16. Une précision réduite qui est pour rappel supportée pour un ensemble d'instructions exécutées avec un débit doublé par rapport au FP32 classique (grossièrement via un vecteur dans le vecteur) suivant les opportunités offertes par le code au compilateur.
AMD a développé une nouvelle version de TressFX (4.0), sa librairie de rendu et de simulation des cheveux, capable de profiter du FP16. Tout l'aspect simulation est ainsi accéléré, ce qui permet au gain global de 50% dans la démonstration de TressFX. Un gain serait également possible sur GCN 3 et GCN 4 qui ne sont pas capables d'exécuter le FP16 plus rapidement mais peuvent en profiter pour compacter les registres.
La seconde démonstration essaye de mettre en avant ce que va permettre le High Bandwidth Cache Controller de Vega. Pour rappel il s'agit d'un contrôleur mémoire plus évolué qui va pouvoir traiter la HBM ou tout autre type de mémoire comme cache local en association avec l'utilisation de mémoire système quand cela est nécessaire.
Cela nous rappelle bien entendu les promesses de l'AGP, d'HyperMemory ou encore du TurboCache. Voire même des pilotes plus intelligents censés être capables d'aider le GPU Fiji et les Radeon Fury à se contenter de 4 Go. Rien de tout cela ne nous a convaincus jusqu'ici. Mais AMD promet que cette fois avec Vega, sa solution tient la route et est réellement capable de gérer les déplacements de mémoire de manière efficace.
La première carte graphique basée sur Vega est attendue avec 8 Go de HBM2 et n'aura donc pas réellement besoin de faire appel à cette possibilité avant quelques temps. Pour démontrer cette capacité, AMD a donc limité artificiellement à 2 Go de mémoire deux cartes graphiques équipées d'un GPU Vega 10. La première utilise une gestion classique de la mémoire alors que le HBCC est actif sur la seconde. Deus Ex en mode DirectX 11 est exécuté avec un niveau de qualité adapté pour viser +/- 30 fps. Sur la première carte graphique, des saccades importantes apparaissent alors que tout est parfaitement fluide avec le HBCC. Les FPS minimaux sont presque doublés sur ce second système.
AMD ne veut pas, tout du moins pour l'instant, présenter le HBCC comme une approche qui permet de réduire les coûts en limitant la quantité de mémoire embarquée. Au contraire pour AMD, le HBCC représente une valeur ajoutées pour les joueurs, qui va permettre d'augmenter la pérennité de ses cartes graphiques qui ne verraient plus leurs performances être massacrées dès que les jeux commencent à utiliser plus de mémoire vidéo. Evidemment c'est également un point important pour positionner les cartes graphiques Vega par rapport à une éventuelle nouvelle GeForce GTX 1080 Ti qui proposerait plus de 8 Go.