
Intel Core i7-4770K et i5-4670K : Haswell en test
Publié le 01/06/2013 par Guillaume Louel et Marc Prieur



Si le marketing parle souvent de "nouvelle architecture", dans la pratique les constructeurs capitalisent sur leurs acquis et font évoluer au fur et à mesure leurs architectures existantes. Dans le cas d'Haswell, on ne s'étonnera donc pas de retrouver un grand nombre de similarités, mais aussi des différences avec l'architecture de Sandy Bridge. Vous pouvez retrouver notre présentation de Sandy Bridge dans cet article pour rappel.
Avant d'entrer dans les détails sur les changements effectués au niveau de l'architecture, il faut noter qu'Intel a effectué deux additions assez importantes au jeu d'instruction d'Haswell. La première est baptisée TSX, une série d'instructions qui permettent d'accéder de manière différente à la mémoire et que nous avions détaillées l'année dernière.
L'idée est d'ajouter un concept de transaction, qui sera peut être familier à ceux qui connaissent les bases de données : les instructions TSX permettent de marquer un bloc d'instruction comme atomique, c'est-à-dire dont l'exécution doit être réalisé en intégralité avant que quiconque d'autre touche à la mémoire utilisée par le bloc.
Le problème que résout TSX est complexe, en effet les architectures processeurs modernes partagent un espace mémoire commun. Cela permet à tous les curs de travailler sur des données identiques, mais n'est pas sans inconvénient. Des problèmes de synchronisation, assez pénibles à débuguer pour les développeurs, arrivent assez vite. Imaginez deux curs qui lisent une donnée dans le but de la réécrire quelques secondes après : l'un va écraser le résultat de l'autre.

Des mécanismes de sémaphores ou d'exclusion mutelles (mutex ) ont donc été mis au point côté algorithmique, ce sont les développeurs qui doivent les implémenter dans leur code avec tous les problèmes que cela peut poser.
TSX apporte deux réponses, avec tout d'abord le mode Hardware Lock Elision (HLE). Il s'agit de deux nouvelles instructions (XACQUIRE et XRELEASE) que l'on doit placer autour de blocs que l'on souhaite considérer comme atomiques. Attention cependant : le programmeur devra toujours implémenter manuellement son système de "lock", il sera cependant désormais accéléré et surveillé par le processeur.

Quel intérêt ? La réalité est que tous les locks ne sont pas utiles, ils sont juste là pour éviter les cas de collisions. En indiquant au processeur quels sont les blocs qui peuvent poser problème, Haswell pourra décider d'effectuer les opérations non mutuellement bloquantes en simultanée, le lock inutile étant alors omis ("elision" en anglais) sur Haswell. On notera que dans le cas ou une transaction est impossible (par exemple, le programmeur a oublié d'utiliser le lock a un endroit de son programme avant d'utiliser une ressource partagée, créant un conflit), Haswell exécutera le code atomique de manière non transactionnelle. HLE n'apporte donc pas de bénéfice direct côté sécurité ou facilité de programmation, mais permet d'améliorer les performances dans certains cas (les programmeurs tendant très souvent à abuser des locks lorsque cela n'est pas nécessaire) sur Haswell tout en laissant le code fonctionnel sur d'autres plateformes.
L'autre mode de fonctionnement proposé par Intel est baptisé Restricted Transactional Memory (RTM). Il s'agit cette fois ci d'une implémentation complète de mémoire transactionnelle. Trois instructions sont disponibles, XBEGIN, XEND et XABORT.

Contrairement au mode HLE où le programmeur devait toujours créer ses propres locks, RTM permet de s'en passer et d'entourer simplement les blocs que l'on souhaite devenir atomiques : ils seront alors exécutés comme des transactions. Cependant, dans le cas où une transaction est impossible, le programmeur doit impérativement proposer un plan de secours. L'implémentation du plan de secours (une adresse où l'on reroute le programme) n'est pas optionnelle car de nombreuses choses peuvent faire rater une transaction. La première est le programmeur lui-même qui peut utiliser l'instruction XABORT pour l'arrêter. La seconde concerne des opérations à l'intérieur du bloc qui ne sont pas compatibles. Dans certains cas, mixer des instructions SSE et AVX (qui utilisent les registres XMM et YMM du processeur) peut causer un arrêt de la transaction. D'autres instructions sont définies dans la documentation d'Intel comme dépendant de l'implémentation, mais la question de la cohérence de la mémoire cache (seule la ligne est vérifiée et non la donnée précise) risque de générer un certain nombre d'arrêts également.
Bien entendu si ces instructions supportées par le processeur sont disponibles manuellement en assembleur, dans la majorité des cas c'est le compilateur qui devra implémenter les instructions. Intel, en collaboration avec IBM et Sun avait définit un modèle mémoire transactionnel pour la norme C++11 qui sera implémenté entre autre par GCC (à partir de la version 4.7). Intel proposera également dans son compilateur C/C++ des intrinsèques (des fonctions C qui indiquent au compilateur d'utiliser une instruction assembleur donnée).
En soit le mécanisme HLE pourrait être implémenté assez rapidement et de manière bénéfique pour les performances sur Haswell. Cependant en ce qui concerne RTM, il faut plus y voir un travail préparatoire. En attendant la standardisation, côté langages de programmation, d'extensions transactionnelles, l'utilisation de TSX se fera au cas par cas et il ne faudra pas espérer voir une généralisation rapide. D'autant plus qu'Intel est pour l'instant le seul à proposer une telle accélération, AMD ne s'étant pas encore prononcé sur le sujet. Ce travail préparatoire, qui résout un vrai problème concret se doit cependant d'être salué, même si l'on en observera pas forcément les résultats de suite.
Attention, à l'instar de VT-d, Intel a eu la "bonne" idée de pas activer ces instructions TSX sur une partie de la gamme, notamment les processeurs K.
Si TSX est l'extension la plus originale du jeu d'instruction, AVX2 est la plus pragmatique. Annoncée dès 2011 par Intel, AVX2 ajoute un grand nombre d'instructions vectorielles, c'est-à-dire capables de s'appliquer à plusieurs données en simultanées (on parle d'instructions SIMD : Single Instruction, Multiple Data).
Une grande nouveauté d'AVX2 est l'arrivée d'instructions entières vectorielles 256 bits, Intel offre ainsi un pendant vectoriel aux instructions x86 classiques, ce qui peut être intéressant.
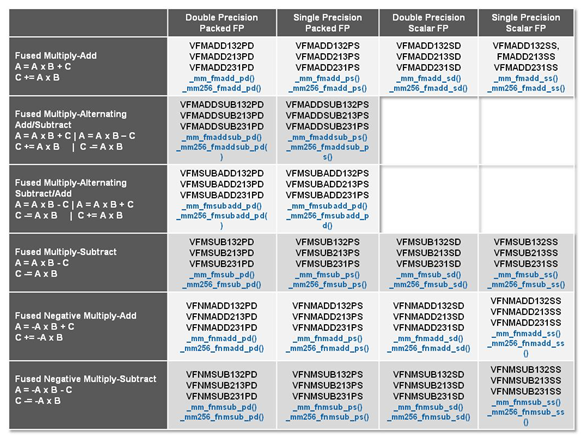
Un autre changement concerne l'ajout d'instructions dites FMA (Fused Multiply Add). Plutôt issues du monde GPU, ces opérations fusionnent une multiplication et une addition, c'est-à-dire une opération de la forme A = A x B + C. Celles utilisées par Intel sont de type FMA3 (trois opérandes) quand AMD avait lancé avec Bulldozer une implémentation FMA4 (D = A x B + C), avant de proposer également un FMA3 via Piledriver. Notez enfin que ces instructions sont accompagnées d'autres instructions essentielles permettant de charger dans des registres des données mémoires non adjacentes (instructions type gather).
 Introduction
Les améliorations de l'architecture CPU
Introduction
Les améliorations de l'architecture CPU

Jeu d'instruction : TSX
Avant d'entrer dans les détails sur les changements effectués au niveau de l'architecture, il faut noter qu'Intel a effectué deux additions assez importantes au jeu d'instruction d'Haswell. La première est baptisée TSX, une série d'instructions qui permettent d'accéder de manière différente à la mémoire et que nous avions détaillées l'année dernière.
L'idée est d'ajouter un concept de transaction, qui sera peut être familier à ceux qui connaissent les bases de données : les instructions TSX permettent de marquer un bloc d'instruction comme atomique, c'est-à-dire dont l'exécution doit être réalisé en intégralité avant que quiconque d'autre touche à la mémoire utilisée par le bloc.
Le problème que résout TSX est complexe, en effet les architectures processeurs modernes partagent un espace mémoire commun. Cela permet à tous les curs de travailler sur des données identiques, mais n'est pas sans inconvénient. Des problèmes de synchronisation, assez pénibles à débuguer pour les développeurs, arrivent assez vite. Imaginez deux curs qui lisent une donnée dans le but de la réécrire quelques secondes après : l'un va écraser le résultat de l'autre.
Des mécanismes de sémaphores ou d'exclusion mutelles (mutex ) ont donc été mis au point côté algorithmique, ce sont les développeurs qui doivent les implémenter dans leur code avec tous les problèmes que cela peut poser.
TSX apporte deux réponses, avec tout d'abord le mode Hardware Lock Elision (HLE). Il s'agit de deux nouvelles instructions (XACQUIRE et XRELEASE) que l'on doit placer autour de blocs que l'on souhaite considérer comme atomiques. Attention cependant : le programmeur devra toujours implémenter manuellement son système de "lock", il sera cependant désormais accéléré et surveillé par le processeur.
Quel intérêt ? La réalité est que tous les locks ne sont pas utiles, ils sont juste là pour éviter les cas de collisions. En indiquant au processeur quels sont les blocs qui peuvent poser problème, Haswell pourra décider d'effectuer les opérations non mutuellement bloquantes en simultanée, le lock inutile étant alors omis ("elision" en anglais) sur Haswell. On notera que dans le cas ou une transaction est impossible (par exemple, le programmeur a oublié d'utiliser le lock a un endroit de son programme avant d'utiliser une ressource partagée, créant un conflit), Haswell exécutera le code atomique de manière non transactionnelle. HLE n'apporte donc pas de bénéfice direct côté sécurité ou facilité de programmation, mais permet d'améliorer les performances dans certains cas (les programmeurs tendant très souvent à abuser des locks lorsque cela n'est pas nécessaire) sur Haswell tout en laissant le code fonctionnel sur d'autres plateformes.
L'autre mode de fonctionnement proposé par Intel est baptisé Restricted Transactional Memory (RTM). Il s'agit cette fois ci d'une implémentation complète de mémoire transactionnelle. Trois instructions sont disponibles, XBEGIN, XEND et XABORT.
Contrairement au mode HLE où le programmeur devait toujours créer ses propres locks, RTM permet de s'en passer et d'entourer simplement les blocs que l'on souhaite devenir atomiques : ils seront alors exécutés comme des transactions. Cependant, dans le cas où une transaction est impossible, le programmeur doit impérativement proposer un plan de secours. L'implémentation du plan de secours (une adresse où l'on reroute le programme) n'est pas optionnelle car de nombreuses choses peuvent faire rater une transaction. La première est le programmeur lui-même qui peut utiliser l'instruction XABORT pour l'arrêter. La seconde concerne des opérations à l'intérieur du bloc qui ne sont pas compatibles. Dans certains cas, mixer des instructions SSE et AVX (qui utilisent les registres XMM et YMM du processeur) peut causer un arrêt de la transaction. D'autres instructions sont définies dans la documentation d'Intel comme dépendant de l'implémentation, mais la question de la cohérence de la mémoire cache (seule la ligne est vérifiée et non la donnée précise) risque de générer un certain nombre d'arrêts également.
Bien entendu si ces instructions supportées par le processeur sont disponibles manuellement en assembleur, dans la majorité des cas c'est le compilateur qui devra implémenter les instructions. Intel, en collaboration avec IBM et Sun avait définit un modèle mémoire transactionnel pour la norme C++11 qui sera implémenté entre autre par GCC (à partir de la version 4.7). Intel proposera également dans son compilateur C/C++ des intrinsèques (des fonctions C qui indiquent au compilateur d'utiliser une instruction assembleur donnée).
En soit le mécanisme HLE pourrait être implémenté assez rapidement et de manière bénéfique pour les performances sur Haswell. Cependant en ce qui concerne RTM, il faut plus y voir un travail préparatoire. En attendant la standardisation, côté langages de programmation, d'extensions transactionnelles, l'utilisation de TSX se fera au cas par cas et il ne faudra pas espérer voir une généralisation rapide. D'autant plus qu'Intel est pour l'instant le seul à proposer une telle accélération, AMD ne s'étant pas encore prononcé sur le sujet. Ce travail préparatoire, qui résout un vrai problème concret se doit cependant d'être salué, même si l'on en observera pas forcément les résultats de suite.
Attention, à l'instar de VT-d, Intel a eu la "bonne" idée de pas activer ces instructions TSX sur une partie de la gamme, notamment les processeurs K.
Jeu d'instruction : AVX2
Si TSX est l'extension la plus originale du jeu d'instruction, AVX2 est la plus pragmatique. Annoncée dès 2011 par Intel, AVX2 ajoute un grand nombre d'instructions vectorielles, c'est-à-dire capables de s'appliquer à plusieurs données en simultanées (on parle d'instructions SIMD : Single Instruction, Multiple Data).
Une grande nouveauté d'AVX2 est l'arrivée d'instructions entières vectorielles 256 bits, Intel offre ainsi un pendant vectoriel aux instructions x86 classiques, ce qui peut être intéressant.
Un autre changement concerne l'ajout d'instructions dites FMA (Fused Multiply Add). Plutôt issues du monde GPU, ces opérations fusionnent une multiplication et une addition, c'est-à-dire une opération de la forme A = A x B + C. Celles utilisées par Intel sont de type FMA3 (trois opérandes) quand AMD avait lancé avec Bulldozer une implémentation FMA4 (D = A x B + C), avant de proposer également un FMA3 via Piledriver. Notez enfin que ces instructions sont accompagnées d'autres instructions essentielles permettant de charger dans des registres des données mémoires non adjacentes (instructions type gather).
Sommaire
1 - Introduction
2 - Les améliorations du jeu d'instruction x86 : TSX et AVX2
3 - Les améliorations de l'architecture CPU
4 - Les améliorations côté GPU
5 - LGA 1150, Régulateur de tension intégré
6 - Overclocking plus libre sur K, plus strict par ailleurs
7 - Chipsets Intel Serie 8, Lynx Point et Lynx Point-LP
8 - Les gammes Haswell
9 - Core i7-4770K, i5-4670K, i5-4430 et cartes mères
10 - Bug de l'USB 3.0 sur C1, compatibilité des alimentations
11 - Consommation, efficacité énergétique
12 - Températures, overclocking et undervolting
13 - HD Graphics 4600 : Consommation, Overclocking, Jeux
2 - Les améliorations du jeu d'instruction x86 : TSX et AVX2
3 - Les améliorations de l'architecture CPU
4 - Les améliorations côté GPU
5 - LGA 1150, Régulateur de tension intégré
6 - Overclocking plus libre sur K, plus strict par ailleurs
7 - Chipsets Intel Serie 8, Lynx Point et Lynx Point-LP
8 - Les gammes Haswell
9 - Core i7-4770K, i5-4670K, i5-4430 et cartes mères
10 - Bug de l'USB 3.0 sur C1, compatibilité des alimentations
11 - Consommation, efficacité énergétique
12 - Températures, overclocking et undervolting
13 - HD Graphics 4600 : Consommation, Overclocking, Jeux
14 - HD Graphics 4600 : OpenCL, Quicksync
15 - Protocole CPU, Rendu 3D : Mental Ray et V-Ray
16 - CPU Compilation : Visual Studio et MinGW/GCC
17 - CPU Compression : 7-zip et WinRAR
18 - CPU Encodage : x264 et Rovi H.264
19 - CPU Traitement photo : Lightroom et Bibble
20 - CPU IA d'échecs : Houdini et Fritz
21 - CPU Jeux 3D : Crysis 2 et Arma II : OA
22 - CPU Jeux 3D : Rise of Flight et F1 2012
23 - CPU Jeux 3D : Total War Shogun 2 et Skyrim
24 - CPU Jeux 3D : Starcraft II et Anno 2070
25 - Gains et Moyennes CPU
26 - Conclusion
15 - Protocole CPU, Rendu 3D : Mental Ray et V-Ray
16 - CPU Compilation : Visual Studio et MinGW/GCC
17 - CPU Compression : 7-zip et WinRAR
18 - CPU Encodage : x264 et Rovi H.264
19 - CPU Traitement photo : Lightroom et Bibble
20 - CPU IA d'échecs : Houdini et Fritz
21 - CPU Jeux 3D : Crysis 2 et Arma II : OA
22 - CPU Jeux 3D : Rise of Flight et F1 2012
23 - CPU Jeux 3D : Total War Shogun 2 et Skyrim
24 - CPU Jeux 3D : Starcraft II et Anno 2070
25 - Gains et Moyennes CPU
26 - Conclusion
Vos réactions
Contenus relatifs
- [+] 09/05: AMD Ryzen 7 2700, Ryzen 5 2600 et I...
- [+] 05/04: Pas de MAJ Microcode pour les Gulft...
- [+] 03/04: Intel lance la 2ème vague de sa 8èm...
- [+] 07/02: Windows 10, Meltdown et Spectre : q...
- [+] 05/10: Intel Core i7-8700K, Core i5-8600K,...
- [+] 12/09: Core i7-7820X : Un Skylake-X mieux ...
- [+] 07/09: Les Skylake en fin de vie chez Inte...
- [+] 23/08: Coffee Lake incompatible avec les L...
- [+] 29/06: Intel Core i9-7900X et Core i7-7740...
- [+] 03/01: Core i5-7600K et i7-7700K : pour qu...