
Nvidia, PGI et Cray dévoilent OpenACC
Publié le 17/11/2011 à 14:48 par Damien Triolet



Le SC11 aura vu débarquer officiellement un énième langage destiné aux accélérateurs massivement parallèle, et en particulier aux GPU : OpenACC. Standard ouvert proposé par Nvidia, The Portland Group (PGI) et Cray, avec l'aide de CAPS, il représente une alternative à une initiative similaire proposée par Microsoft avec C++ AMP.

OpenACC permet ainsi de définir très simplement dans le code les zones à accélérer, à l'aide de directives pour le compilateur, qui se charge ensuite de toute la complexité liée à l'utilisation d'un accélérateur. Cette approche simplifie nettement le travail des développeurs et permet de conserver la compatibilité avec les systèmes dépourvus d'accélérateur, puisqu'il suffit alors d'ignorer ces directives.
Reste bien entendu qu'une telle approche est moins efficace qu'un code optimisé manuellement pour une architecture spécifique, mais elle permet d'obtenir rapidement des résultats intéressants pour les morceaux de code naturellement parallèles, de pouvoir juger de l'intérêt des accélérateurs sans gros investissement et d'éviter d'être enfermé dans le support d'une seule architecture. Compte tenu de temps de développement qui peuvent être très longs, utiliser un langage tel qu'OpenACC et, éventuellement, intégrer quelques fonctions natives lors de la mise en production (cela reste bien entendu possible), permet de limiter les risques.
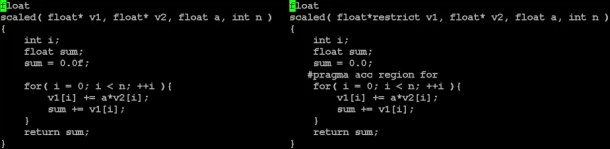
Un exemple simple de conversion d'un code classique vers le modèle de PGI à base de directives dont OpenACC est très proche.
OpenACC, défini pour C, C++ et Fortran, est une version étendue et ouverte du modèle de programmation à base de directives pour les accélérateurs de PGI, un petit peu comme OpenCL est une version étendue et ouverte de C pour CUDA. OpenACC complexifie légèrement le langage de PGI, ce qui était nécessaire pour étendre ses possibilités. Dans un premier temps 3 compilateurs seront compatibles :
- PGI Accelerator C/C++/Fortran pour CUDA (GPU Nvidia)
- Cray CCE pour systèmes Cray (qui supportent les GPU Nvidia)
- CAPS Enterprise HMPP Workbench (qui supporte OpenCL)
Grossièrement, les compilateurs OpenACC qui sont actuellement prévus concernent avant tout l'utilisation d'accélérateurs CUDA, Nvidia étant l'un des membres à l'origine du langage. Rien n'empêche cependant la mise en place de compilateurs OpenCL, comme le fait CAPS, ou dédiés aux GPU AMD, si ce n'est le fait qu'actuellement chacun semble développer son propre "standard" en prenant soin de nier les initiatives issues de la concurrence.
Reste qu'OpenACC semble avoir été tiré de la réflexion initiale du groupe de travail sur les accélérateurs d'OpenMP, dont l'exploitation représente un des objectifs de la version 4.0 de ses spécifications. Les membres fondateurs d'OpenACC ne cachent d'ailleurs pas leur intention de l'intégrer à OpenMP, précisant que ce lancement anticipé permettra à ce sujet d'obtenir de la part des développeurs des retours importants pour la finalisation du standard complet et robuste d'OpenMP pour le calcul hétérogène.
Vous pourrez obtenir les spécifications complètes de la version 1.0 d'OpenACC par ici .
Vos réactions
Contenus relatifs
- [+] 09/02: Nvidia lance les Quadro Pascal dont...
- [+] 05/04: GTC: Nvidia Tesla P100: 10 Tflops, ...
- [+] 15/12: GPUOpen, la réponse d'AMD à GameWor...
- [+] 16/11: AMD et HPC: nouveaux outils, suppor...
- [+] 09/07: AMD lance la FirePro S9170: Hawaii ...
- [+] 03/03: GDC: Khronos annonce OpenCL 2.1
- [+] 08/12: Nvidia lance la Tesla K80: double G...
- [+] 02/12: IBM Power9 et Nvidia Volta : 100+ p...
- [+] 07/04: AMD FirePro W9100 : 2.6 Tflops DP, ...
- [+] 25/11: Nvidia annonce la Tesla K40 et CUDA...