
Intel Core 2 Duo
Publié le 22/06/2006 par Franck Delattre et Marc Prieur



Les caches de CoreLarchitecture Core introduit de nouvelles contraintes à son sous-système de cache. De fait, lIPC élevé nécessite dune part un sous-système de cache présentant un de taux de succès élevé, et ce afin de masquer efficacement les latences mémoire ; mais également un débit élevé afin de faire face à laugmentation en demande de données qui accompagne celle de lIPC.
Le tableau ci-dessous regroupe les principales caractéristiques des caches de la nouvelle architecture, et inclut les latences daccès ainsi que les débits obtenus avec le test de bande passante SSE2 (128 bits) de RightMark Memory Analyzer (RMMA) :
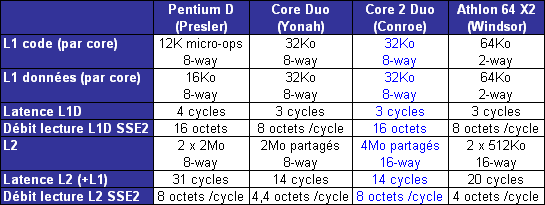
Les caches L1 de larchitecture Core partagent les mêmes caractéristiques de taille et dassociativité que ceux qui équipent Mobile. En revanche, la bande passante offerte est doublée, comme le montre le test de débit en lecture 128 bits de RMMA. Nous retrouvons ce résultat si nous regardons le débit de linstructions de lecture mémoire 128 bits SSE2 movapd : une lecture 128 bits par cycle, soit 16 octets / cycle.

Laccès au cache L2 nécessite un cycle supplémentaire, ce qui porte son débit à 8 octets par cycle.
A la différence des Pentium D et Athlon 64 X2, Core utilise la technique de lAdvanced Smart Cache inaugurée sur le Yonah et qui consiste à partager le cache L2 entre les deux cores dexécution. En comparaison à un cache L2 dédié à chaque core, cette méthode présente le principal avantage de partager des données entre les deux cores, et ce sans passer par le bus mémoire. Cela réduit les accès mémoire (et les latences qui laccompagnent) et optimise le remplissage du L2 (les redondances disparaissent).
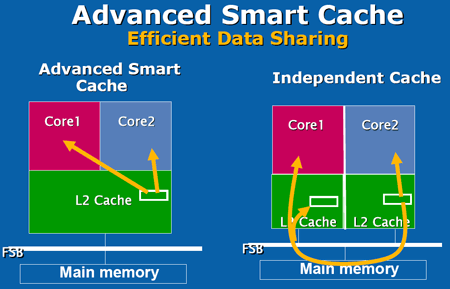
Le cache partagé offre également la possibilité dêtre dynamiquement alloué par chacun des deux cores, jusquà devenir accessible dans son intégralité par un seul des deux cores. Ainsi, cette technique développée spécifiquement pour une implémentation dual core savère paradoxalement plus efficace que les caches séparés lorsquun seul des deux cores est utilisé, cest-à-dire pour toutes les applications mono-thread.
Un accès intelligent à la mémoireEn plus des améliorations apportées sur les mémoires caches, Intel a développé de nouvelles techniques visant à améliorer les accès à la mémoire, techniques que le fondeur regroupe sous le terme un peu pompeux de Smart Memory Access.
Lidée consiste à répondre à deux critères visant, encore et toujours, à masquer les latences daccès à la mémoire :
La contrainte du « quand » réfère à la façon dont un processeur planifie les opérations de lecture et décriture mémoire. En effet, lorsque survient une instruction de lecture mémoire dans le moteur out-of-order, celui-ci ne peut la mener à terme avant que toutes les instructions décriture en cours soient complétées. Sil ne le faisait pas, le risque serait de lire une donnée qui na pas encore été mise à jour dans la hiérarchie mémoire. Cette contrainte impose donc des états dattente, et donc un ralentissement.sassurer quune donnée peut être utilisée le plus tôt possible (contrainte du « quand »). sassurer quune donnée est la plus proche possible (sous-entendu dans la hiérarchie mémoire) du noyau dexécution (contrainte du « où »).
Core a donc introduit un mécanisme spéculatif visant à prédire si une instruction de lecture est susceptible de dépendre des écritures en cours, cest-à-dire si elle peut être traitée sans attendre. Le rôle du prédicateur est ainsi de lever les ambiguïtés, et donne son nom de Memory Disambiguation à la technique utilisée. Outre la réduction des attentes, lintérêt de la méthode est de réduire les dépendances entre instructions, augmentant par là-même l´efficacité du moteur out-of-order.
Prefetch hardwareRépondre à la contrainte du « où », cest-à-dire sefforcer de rapprocher les données du noyau dexécution, est la fonction du sous-système de cache. Afin de lui donner un coup de pouce dans cette tâche, Core a recours au prefetch hardware. Cette technique, rappelons-le, consiste à mettre à profit les moments dinactivité du bus mémoire afin de précharger code et données de la mémoire vers le sous-système de cache.
Le prefetch hardware nest pas une technique inédite, loin sen faut. Elle a été inaugurée sur le Pentium III Tualatin, mais cest surtout Netburst qui la fondamentalement améliorée. De fait, la différence importante entre la fréquence du processeur et celle du bus rend Netburst particulièrement sensible aux effets néfastes dun cache miss, augmentant ainsi lintérêt dun prefetch performant. Une fois nest pas coutume, Core hérite ainsi des techniques de prefetch de Netburst, et les améliore quelque peu.
Plusieurs types de prefetcher équipent Core :
Ce qui nous donne un total de pas moins de 8 prefetchers sur un Core 2 Duo.Le prefetcher dinstructions précharge les instructions dans le cache L1 dinstructions en se basant sur les résultats de la prédiction de branchement. Chacun des deux cores en possède un. Le prefetcher IP scrute lhistorique des lectures afin den dégager un schéma, et charger les données ainsi « prévues » dans le cache L1. Chaque core en possède un également. Le prefetcher DCU détecte quant à lui les lectures multiples depuis une même ligne de cache sur une période donnée, et décide le cas échéant de charger la ligne suivante dans le L1. Toujours un par core. Le prefetcher DPL a un fonctionnement proche du DCU, à ceci près quil détecte les requêtes sur deux lignes de cache successives (N et N+1), et déclenche le cas échéant la lecture de la ligne N+2 de la mémoire centrale dans le cache L2. Le cache L2 en comprend deux, qui sont partagés de façon dynamique entre les deux cores.
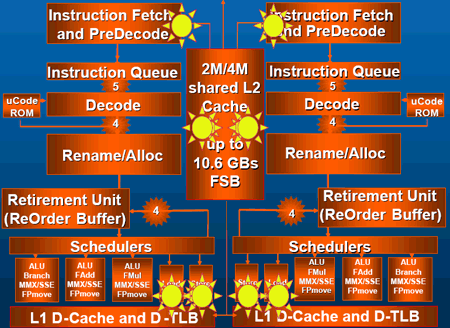
Les petits soleils représentent les huit prefetchers du Core 2 Duo.
Les mécanismes de prefetch hardware se montrent généralement très efficaces, et se traduisent en pratique par une augmentation du taux de succès du sous-système de cache. Hélas, il peut arriver que le prefetch se traduise par leffet inverse de celui escompté, car si les erreurs sont fréquentes elles tendent à polluer le cache avec des données inutiles, donc réduire son taux de succès. Pour cette raison la plupart des mécanismes de prefetch hardware sont désactivables. Intel préconise même de désactiver le prefetch DCU sur les processeurs destinées à un usage dans un server (en loccurrence le Woodcrest), son utilisation étant susceptible de réduire la performance dans certaines applications.
Sommaire
Vos réactions
Contenus relatifs
- [+] 09/05: AMD Ryzen 7 2700, Ryzen 5 2600 et I...
- [+] 04/05: Un Coffee Lake 8 coeurs en préparat...
- [+] 27/04: Le 10nm d'Intel (encore) retardé, l...
- [+] 26/04: Jim Keller rejoint... Intel !
- [+] 23/04: MAJ de notre test des Ryzen 7 2700X...
- [+] 20/04: MAJ de notre comparatif CPU géant
- [+] 19/04: AMD Ryzen 2700X et 2600X : Les même...
- [+] 19/04: 2008-2018 : tests de 62 processeurs...
- [+] 13/04: Les AMD Ryzen Pinnacle Ridge en pré...
- [+] 10/04: LGA4189 pour les Xeon Ice Lake !