
Intel Core 2 Duo
Publié le 22/06/2006 par Franck Delattre et Marc Prieur



Les unités de calculVoici une rapide comparaison des unités de calcul des architectures actuelles :

... et les bandes passantes théoriques en instructions qui en découlent :
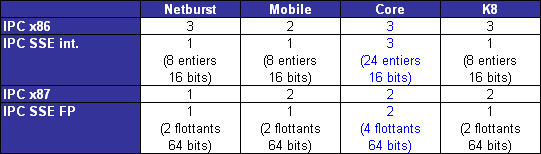
Core possède trois unités de calcul sur les entiers, soit une de plus que Mobile, le plaçant ainsi au niveau du K8 avec une capacité de trois instructions x86 par cycle. A noter que Netburst conserve sa suprématie en capacité de traitement des entiers avec ses unités double vitesse qui lui permettent de traiter jusquà 4 instructions entières par cycle (et non pas 5 comme le laisserait supposer la présence dune ALU supplémentaire en simple vitesse, car celle-ci partage son port avec une des deux ALUs double vitesse). Hélas, cette capacité de traitement nest pas exploitable en pratique car les unités de décodage de Netburst ne permettent pas de fournir un tel débit, limitant ainsi lIPC à 3.
Il nous a semblé intéressant détudier le comportement de Core sur des instructions courantes x86 telles quopérations arithmétiques, décalages, rotations... Nous avons pour cela utilisé un outil intégré à Everest qui fournit latence et débit de quelques instructions choisies parmi x86/x87, MMX, SSE 1, 2 et 3. Ce petit outil est présent dans la version dévaluation : il suffit de cliquer droit dans la barre détat dEverest, et sélectionner « CPU Debug » puis « Instructions latency dump » dans le menu qui apparaît.
A titre de rappel, la latence dune instruction représente, en nombre de cycles processeur, le temps quelle passe dans le pipeline de traitement. En pratique, le moteur OOO sefforce de traiter le flux dinstructions de telle façon que ces latences soient masquées, mais les dépendances entre instructions tendent à générer des attentes, dautant plus importantes que les latences de ces instructions le sont. Le débit dune instruction correspond au temps minimal, en cycles processeur, séparant la prise en charge de deux instructions similaires. Ainsi, par exemple, la division entière possède un débit de 40 cycles sur K8, ce qui signifie que le processeur ne pourra traiter, et donc fournir le résultat dun telle division entière quà raison dune tous les 40 cycles.
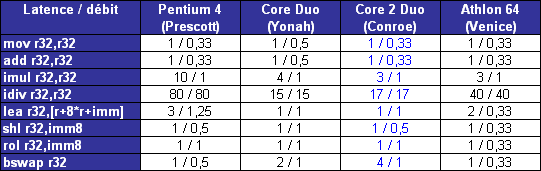
Sur certaines instructions, dont laddition, Core affiche un débit correspondant à son IPC maximal théorique (0,33 cycle par instruction, soit 3 instructions par cycle). La multiplication affiche une latence légèrement inférieure à celle obtenue sur le Yonah, et se place ainsi au niveau du K8. La division entière a subi en revanche une légère baisse de performance, quoiquelle reste beaucoup plus rapide que sur K8 et Netburst. En ce qui concerne les manipulations de registres, Core reste en dessous de K8, bien que le décalage (shl) ait été amélioré en comparaison au Yonah.
Ce quil faut retenir de ce tableau est que les efforts sur les unités de Core semblent avoir été portés sur les instructions pour lesquelles le K8 possédait jusque là une certaine avance sur Mobile et Netburst (addition et multiplication entières par exemple), alors quun peu de lest a été lâché sur les instructions pour lesquelles K8 ne brille pas (la division entière).
Performances SSE théoriquesUne des améliorations les plus notables des unités de calcul de Core consiste en la présence de trois unités SSE dédiées aux opérations SIMD entières et flottantes. Alliée aux unités arithmétiques concernées, chacune delles est capable deffectuer en un seul cycle des opérations paquées 128 bits (cest-à-dire agissant simultanément sur quatre données 32 bits ou deux données 64 bits), là où Netburst, Mobile et K8 nécessitent deux cycles. Sont concernées notamment les opérations arithmétiques courantes telles que la multiplication et laddition.
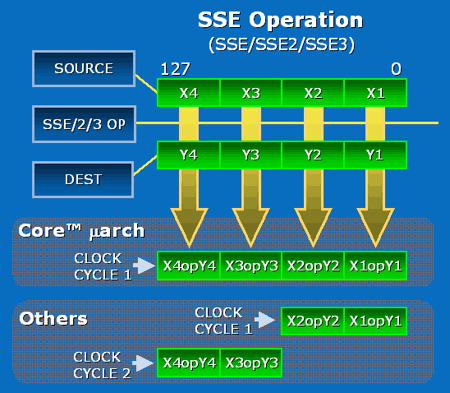
Chacune des trois ALUs est associée à une unité SSE, permettant ainsi de traiter jusquà trois opérations SSE entières 128 bits par cycle (soit 12 instructions sur des entiers 32 bits, ou encore 24 sur des entiers 16 bits). En comparaison, Mobile et K8 ne possèdent que deux unités SSE, et celles-ci ne peuvent traiter que 64 bits par cycle dhorloge. La capacité de Mobile et de K8 en SSE entier nest donc que de 2 x 64 bits, soit 4 instructions sur des entiers 32 bits (ou encore 8 instructions sur des entiers 16 bits).
Core possède deux unités de calcul flottant, une dédié aux additions et lautre aux multiplications et aux divisions. La capacité de calcul théorique atteint donc deux instructions x87 par cycle, et deux instructions flottantes SSE 128 bits par cycle (soit 8 opérations sur des flottants simple précision 32 bits, ou 4 opérations sur flottants double précision 64 bits). Core se montre ainsi en théorie deux fois plus rapide sur ce type dinstructions que Mobile, Netburst et K8. Voyons cela sur quelques instructions SSE2.
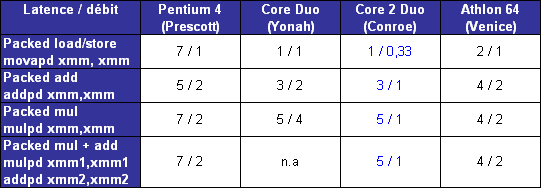
Le packed mov se montre particulièrement véloce sur Core, qui atteint là son pic de débit de 3 opérations 128 bits par cycle. Les débits affichés sur les opérations arithmétiques isolées sexpliquent par la prise en charge de ces opérations par une seule des unités FP, qui utilisée seule offre son débit maximal dune opération 128 bits par cycle. Lopération combinée mul + add exploite en revanche les deux unités conjointement, et sexécute alors avec un débit de 1 cycle pour les deux opérations, soit deux opérations 128 bits par cycle.
Intel communique beaucoup sur cette nouvelle capacité de calcul introduite par Core, et la désigne sous le terme de Digital Media Boost. On notera au passage que Core introduit une nouvelle extension du jeu dinstructions SSE. Initialement prévue pour sortir sur le Tejas, SSE4 consiste en 16 nouvelles instructions SIMD, la plupart opérant sur des données entières. Elles sont essentiellement destinées à accélérer le traitement dans les algorithmes de compression et de décompression vidéo. A titre dexemple, linstruction palignr permet deffectuer un décalage à cheval sur deux registres, opération qui est souvent utilisée dans lalgorithme de prédiction de mouvement dans le décodage MPEG.
Les capacités des unités dexécution de Core sont pour le moins impressionnantes. Intel a doté sa nouvelle architecture dun potentiel de calcul entre deux et trois fois supérieur à celle de ses prédécesseurs et de la concurrence. Mais posséder un IPC élevé sur le papier est une chose, et lexploiter en pratique en est une autre. Comme nous lavons vu un peu plus haut, un code x86 tend à faire chuter lIPC par les branches et des accès mémoire. Intel a ainsi logiquement apporté quelques améliorations destinées à réduire les effets néfastes de ces deux types de dépendances.
Sommaire
Vos réactions
Contenus relatifs
- [+] 09/05: AMD Ryzen 7 2700, Ryzen 5 2600 et I...
- [+] 04/05: Un Coffee Lake 8 coeurs en préparat...
- [+] 27/04: Le 10nm d'Intel (encore) retardé, l...
- [+] 26/04: Jim Keller rejoint... Intel !
- [+] 23/04: MAJ de notre test des Ryzen 7 2700X...
- [+] 20/04: MAJ de notre comparatif CPU géant
- [+] 19/04: AMD Ryzen 2700X et 2600X : Les même...
- [+] 19/04: 2008-2018 : tests de 62 processeurs...
- [+] 13/04: Les AMD Ryzen Pinnacle Ridge en pré...
- [+] 10/04: LGA4189 pour les Xeon Ice Lake !