
Les contenus liés au tag Nvidia
Afficher sous forme de : Titre | FluxGTC: N'attendez pas de GeForce en GP100 !
GTC: Nvidia Tesla P100: 10 Tflops, HBM2...
GTC: Deep-learning : +70% pour Pascal
GTC: Multi-Res Shading, pas que pour la VR ?
GTC: VKCPP et NVK pour simplifier Vulkan
330mm² pour le GP104



Si nous avions entrevu lors de la GTC le GP106, un petit GPU de 200mm² environ, Nvidia prépare également un GP104 un peu plus gros. Un forumeur en avait déjà posté une photo sur Chiphell il y'a une dizaine de jours, alors accompagné de GDDR5 8 Gbps, il a de nouveau fait son apparition sur ce même forum .


Les clichés permettent d'estimer une taille de l'ordre de 330mm², à comparer aux 398mm² d'un GM204 (GTX 970/980). De quoi embarquer avec le doublement de la densité permis par le 16nm TSMC aux alentours de 8,5 milliards de transistors, le GM200 (GTX 980 Ti/Titan X) en embarquant pour rappel 8 milliards dans 601mm².
On notera sur la photo que la puce est très récente puisque le marquage fait état d'une production début avril. L'auteur de la fuite précise que le bus mémoire est 256-bit et que 8 Go équiperont les cartes, respectivement avec de la GDDR5X pour la GTX 1080 et de la GDDR5 pour la GTX 1070. Wait & See !
GTC: Nvidia annonce CUDA 8, prêt pour Pascal
Comme souvent, l'arrivée d'une nouvelle architecture est associée à une révision majeure de CUDA, l'environnement logiciel de Nvidia destiné au calcul massivement parallèle. Ce sera évidemment le cas pour les GPU Pascal qui pourront profiter dès cet été d'un CUDA 8 taillé sur mesure. Au menu : un support plus évolué de la mémoire unifiée, un profilage plus efficace et un compilateur plus rapide.

La principale nouveauté de CUDA 8 sera le support complet de l'architecture Pascal et particulièrement du GP100 qui équipe l'accélérateur Tesla P100. Déjà introduit avec CUDA 7.5 pour permettre aux développeurs de s'y préparer, le support de la demi-précision (FP16) sera finalisé et pourra permettre des gains conséquents pour les algorithmes qui peuvent s'en contenter. Dans le cas du GP100, CUDA 8 ajoutera évidemment le pilotage des accès mémoire à travers les liens NVLink.
La plus grosse évolution est cependant à chercher du côté de la mémoire unifiée qui va faire un bond en avant avec Pascal, ou tout du moins avec le GP100 puisque nous ne sommes pas certains que les autres GPU Pascal en proposeront un même niveau de support. Si vous avez l'impression qu'on vous a annoncé le support de cette mémoire unifiée avec chaque nouveau GPU, ne vous inquiétez pas, vous n'avez pas rêvé, nous avons la même impression.
Elle est en fait supportée depuis CUDA 6 pour les GPU Kepler et Maxwell mais de façon limitée, que nous pourrions qualifier d'émulée. Pour ces GPU, l'espace de mémoire unifié est en fait dédoublé dans la mémoire centrale et dans la mémoire physiquement associée au GPU. L'ensemble logiciel CUDA se charge de piloter et de synchroniser ces deux espaces mémoires pour qu'ils n'en représentent qu'un seul du point de vue du développeur. De quoi faciliter sa tâche mais au prix de sérieuses limitations : la zone de mémoire unifiée ne peut dépasser la quantité de mémoire rattachée au GPU, le CPU et le GPU ne peuvent y accéder simultanément et de nombreuses synchronisations systématiques sont nécessaires pour forcer la cohérence entre les copies CPU et GPU de cette mémoire.
Pour proposer un support plus avancé de la mémoire unifiée, des modifications matérielles étaient nécessaires au niveau du GPU, ce qui explique pourquoi nous estimons possible que cela soit spécifique au GP100. Tout d'abord l'extension de l'espace mémoire adressable à 49-bit pour permettre de couvrir l'espace de 48-bit des CPU ainsi que la mémoire propre à chaque GPU du système. Ensuite la prise en charge des erreurs de page qui permet d'éviter les coûteuses synchronisations systématiques. Si un kernel essaye d'accéder à une page qui ne réside pas dans la mémoire physique du GPU, il va produire une erreur qui va permettre suivant les cas soit de rapatrier localement la page en question, soit d'y accéder directement à travers le bus PCI Express ou un lien NVLink.
La cohérence peut ainsi être garantie automatiquement, ce qui permet aux CPU et aux GPU d'accéder simultanément à la zone de mémoire unifiée. Sur certaines plateformes, la mémoire allouée par l'allocateur de l'OS sera par défaut de la mémoire unifiée, et il ne sera plus nécessaire d'allouer une zone mémoire spécifique. Nvidia indique travailler à l'intégration de ce support avec Red Hat et la communauté Linux. Par ailleurs, CUDA 8 étend également le support de la mémoire unifiée à Mac OS X.

Ce support plus avancé de la mémoire unifiée va faciliter le travail des développeurs et surtout rendre plus abordable leurs premiers pas sur les GPU tout en maintenant un relativement bon niveau de performances. Tout du moins si le pilote et le runtime CUDA font leur travail correctement puisque c'est à ce niveau que tout va se jouer. A noter que les développeurs plus expérimentés conservent la possibilité de gérer explicitement la mémoire.
Parmi les autres nouveautés, Nvidia introduit une première version de la librairie nvGRAPH (limitée au mono GPU) qui fournit des routines destinées à accélérer certains algorithmes spécifiques au traitement des graphes. Traiter rapidement les opérations sur ces structures mathématique prend de plus en plus d'importance, que ce soit pour les moteurs de recherche, la publicité ciblée, l'analyse des réseaux ou encore la génomique. Faciliter l'exécution de ces opérations sur le GPU est donc important pour leur ouvrir la porte à de nouveaux marchés potentiels.
Une autre évolution importante est à chercher du côté des outils de profilages qui vont dorénavant fournir une analyse des dépendances. De quoi par exemple permettre de mieux détecter que les performances sont limitées par un kernel qui bloque le CPU trop longtemps. Ces outils revus prennent également en compte NVLink et la bande passante utilisée à ce niveau.
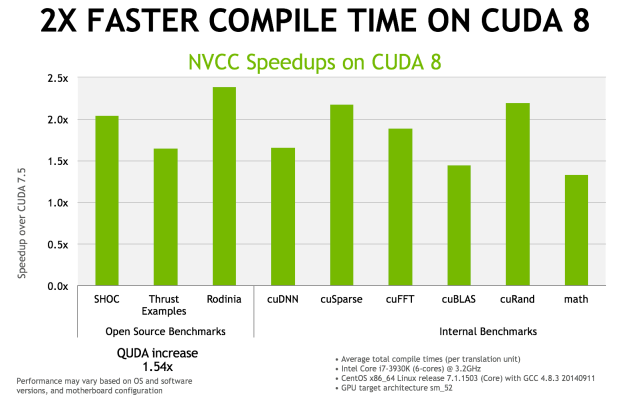
Enfin, le compilateur NVCC 8.0 a reçu de nombreuses optimisations pour réduire le temps de compilation. Nvidia annonce qu'il serait réduit de moitié, voire plus, dans de nombreux cas. Ce compilateur étend également le support expérimental des expressions lambda de C++11.
La sortie de CUDA 8.0 est prévue pour le mois d'août mais une release candidate devrait être proposée dès le mois de juin.
GTC: 200 mm² pour le petit GPU Pascal ?
Il y 3 mois, lors du CES, Jen-Hsun Huang avait présenté le Drive PX 2, le nouveau boîtier dédié à la conduite autonome de Nvidia qui embarque entre autre deux GPU Pascal. Seul petit problème c'est alors un prototype équipé de GM204 Maxwell et non de GPU Pascal qu'avait présenté Jen-Hsun Huang, en oubliant de préciser ce détail, ce qui n'avait pas manqué de susciter la polémique.

Le CEO de Nvidia a profité de la GTC pour rectifier cela en affichant cette fois le "vrai" Drive PX 2 équipé des nouvelles puces Pascal. Le module était ensuite visible dans la zone d'exposition de la GTC mais Nvidia avait malheureusement pris soin de le positionner de manière à ce que les GPU ne soient pas clairement visibles. Nous pouvions cependant les apercevoir suffisamment pour obtenir un second angle de vue pour confirmer la taille de la puce.


Sur la photo où Jen-Hsun Huang présente le Drive PX 2, nous mesurons à peu près 200 mm², alors que sur les autres photos nous sommes plutôt à 205 mm². Suffisamment proche pour pouvoir estimer la taille de ce GPU Pascal (GP106 ?) à +/- 200 mm² en 16nm.
Les spécifications de ce GPU ne sont pas encore connues, tout ce que nous savons est qu'il atteint 4 TFlops dans la configuration qui a été retenue pour le Drive PX 2 et qu'il semble équipé d'un bus mémoire de 128-bit vu la bande passante annoncée de 80 Go /s et malgré la présence de 8 puces 32 bits. De quoi imaginer par exemple un plus gros GPU Pascal grand public (GP102 ? GP104 ?) qui pourrait doubler tout cela. 350 à 400 mm² en 16nm, 8 TFlops et un bus mémoire GDDR5X 256-bit pourrait correspondre à ce que nous prépare Nvidia.
GTC: Nvidia DGX-1: 8 Tesla P100 pour 129.000$
Lors de la keynote d'ouverture de la GTC, Jen-Hsun Huang ne s'est pas contenté d'annoncer l'accélérateur Tesla P100, mais a également dévoilé un nouveau serveur qui sera commercialisé sous sa propre marque : le DGX-1. Orienté deep learning, ce supercalculateur embarque pas moins de 8 Tesla P100 pour un tarif de 129.000$ HTVA.

On n'est jamais aussi bien servi que par soi-même. C'est probablement ce qu'a dû se dire Nvidia pour accélérer la disponibilité du Tesla P100 sur un marché qui peut prendre du temps à bouger de lui-même, d'autant plus quand la compétition est rude et quand la plateforme change significativement. Après quelques expériences avec les serveurs GRID VCA (Visual Computing Appliance) et Quadro VCA, Nvidia propose ainsi un supercalculateur orienté vers le deep learning, un domaine en pleine explosion et pour lequel l'architecture Pascal a été optimisée.
Le DGX-1 est un serveur 3U capable d'atteindre 170 Tflops FP16, mode de calcul basse précision qui peut être exploité par les algorithmes de deep learning. Il atteint également 85 Tflops en FP32 et 42 Tflops en FP64 grâce à l'intégration de GPU Pascal. De quoi permettre à Nvidia de mettre en avant un gain de 75x au niveau de la vitesse d'entrainement d'un réseau de neurones artificiels par rapport à un serveur qui se conterait de CPU classiques.

Ce supercalculateur très dense embarque pas moins de 8 accélérateurs Tesla P100, chacun équipé de 16 Go de mémoire HBM2. Ceux-ci sont pilotés par 2 Xeon E5-2698 v3 (16 coeurs à 2.3 GHz), chacun associé à 256 Go de DDR4 2133. Nvidia a également opté pour un stockage plutôt costaud avec 4 SSD de 1.92 To en RAID 0. De quoi pouvoir prendre en charge de larges datasets. Si le DGX-1 est relativement compact au vu de la puissance de calcul qu'il embarque, il n'est par contre pas léger avec 60 kg sur la balance, ce qui s'explique en partie par l'alimentation et le refroidissement qui sont prévus pour encaisser 3200W, dont 2400W rien que pour les 8 Tesla P100.
Nvidia a bien entendu prévu le DGX-1 pour profiter pleinement de la connectique NVLink. Pour rappel, chaque GPU GP100 intègre 4 de ces liens qui offrent chacun une bande passante bidirectionnelle de 40 Go/s . Voici la topologie qui a été retenue et que Nvidia nomme NVLink Hybrid Cube Mesh :
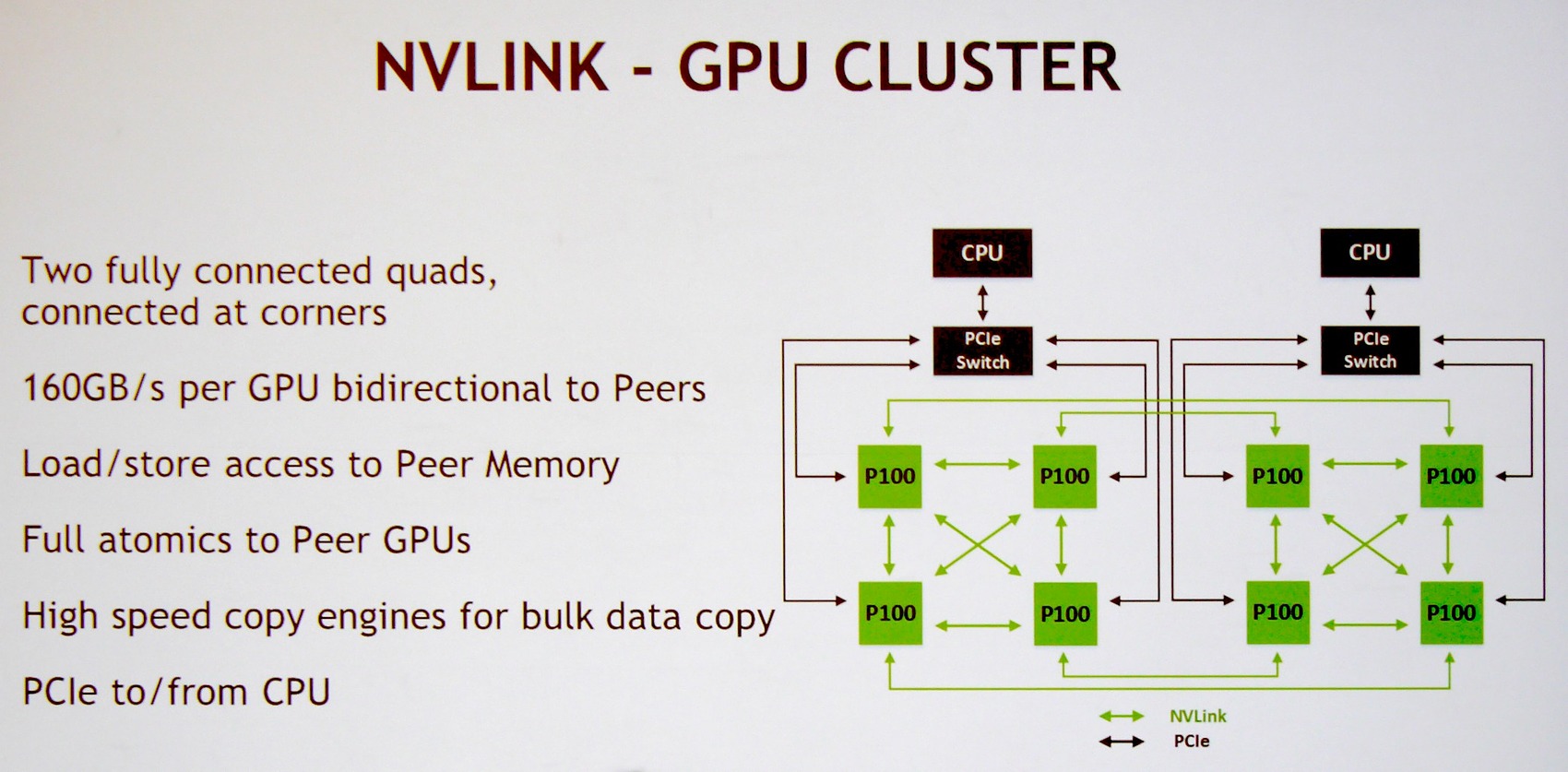
Assez logiquement 4 Tesla P100 sont reliés à chaque CPU via des liens PCI Express qui passent par un switch. Ensuite ces 4 GPU sont reliés entre eux via 3 de leurs liens NVLink. Enfin, leur quatrième lien est exploité pour les relier à l'un des GPU du second groupe de 4 Tesla P100. Il y aura donc quelques limitations au niveau de la communication entre ces 2 groupes de Tesla P100, mais elle est maintenue possible par cette topologie.
Nvidia annonce une disponibilité dès le mois de juin pour le DGX-1, ce qui semble très rapide, même si dans un premier temps cela ne concernera que les Etats-Unis. Il faudra en effet attendre le troisième trimestre pour une disponibilité plus globale.
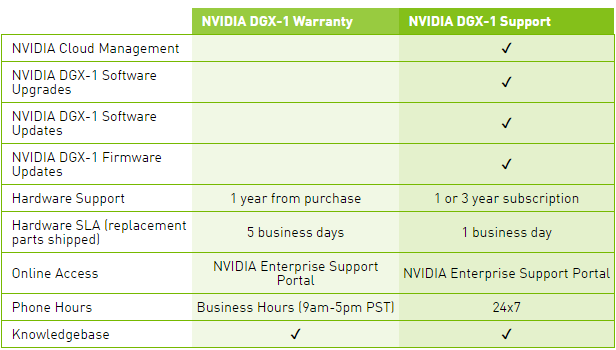
Le tarif communiqué par Nvidia monte à pas moins de 129.000$ HTVA, et ce pour le package basique, Warranty, qui n'inclus aucune mise à jour pour la suite logicielle, ce qui est étrange compte tenu de l'évolution très rapide et continuelle de ses outils dédiés au deep learning. Pour avoir accès à ces mises à jour, il faudra ajouter une cotisation annuelle pour passer au package Support.
Une politique tarifaire qui nous laissent penser que l'accélérateur Tesla P100 seul sera commercialisé à un prix très élevé. Nous ne serions pas étonnés de voir Nvidia atteindre la barre symbolique des 10.000$.
Rise of the Tomb Raider avec les GTX 960
Après l'avoir offert en début d'année sur les gammes supérieures, Nvidia offre désormais Rise of the Tomb Raider avec les GTX 960. Pour rappels les GTX 970, 980 et 980 Ti profitent à l'heure actuelle du titre The Division.

Comme d'habitude cette offre n'est valable que chez les revendeurs partenaires affichant l'offre. Ils vous fourniront généralement après le délai de rétractation un premier code qui permettra d'obtenir auprès de Nvidia un second code pour télécharger le jeu sur Steam.