
Les derniers contenus liés aux tags Intel et Nvidia
Afficher sous forme de : Titre | FluxVentes iGPU / GPU : marché en berne, AMD recule
GPU, 71% pour Intel et 76% pour Nvidia
Focus: Perfs avec 2, 4, 6 et 8 curs : 4 jeux à la loupe
Baisse des ventes de cartes 3D en Q2
GDC: DirectX 12: 'Mantle' standardisé en 2015
Le prix de la RAM pousse les ventes de Samsung
Apple attaque Qualcomm et réclame 1 milliard
Hot Chips : M1, SVE, Parker, InFo et Skylake !
AMD continue de gagner des parts de marché GPU
Dossier: Les solutions de streaming : Streaming local Steam et Nvidia GameStream en test
Le prix de la RAM pousse les ventes de Samsung



Comme nous vous l'indiquons régulièrement, les prix de la RAM n'ont cessé d'augmenter ces derniers mois. En septembre dernier, on pointait un doublement du prix en un an. Depuis les choses ne se sont pas arrangées avec une hausse en octobre, et encore en novembre.

Par rapport à notre relevé de septembre, les puces DDR4-2133 de 512 et 1Go ont augmenté 27.1 et 25% respectivement, atteignant aujourd'hui 4.795 et 9.595$. La DDR3 de son côté suit le mouvement, restant 10% moins chère sur les puces 512 Mo, un écart semblable a ceux que l'on a pu constater ces derniers mois.
Au delà des conséquences très concrètes sur le prix des barrettes mémoires pour les utilisateurs de PC (en se rappelant qu'aujourd'hui, le PC compte pour une part limitée de la demande mondiale de mémoire), ces écarts favorisent largement les vendeurs de mémoire et de NAND comme Samsung qui, selon IC Insights devrait prendre la tête du classement des ventes de semi conducteurs pour l'année 2017, une place historiquement réservée à Intel !
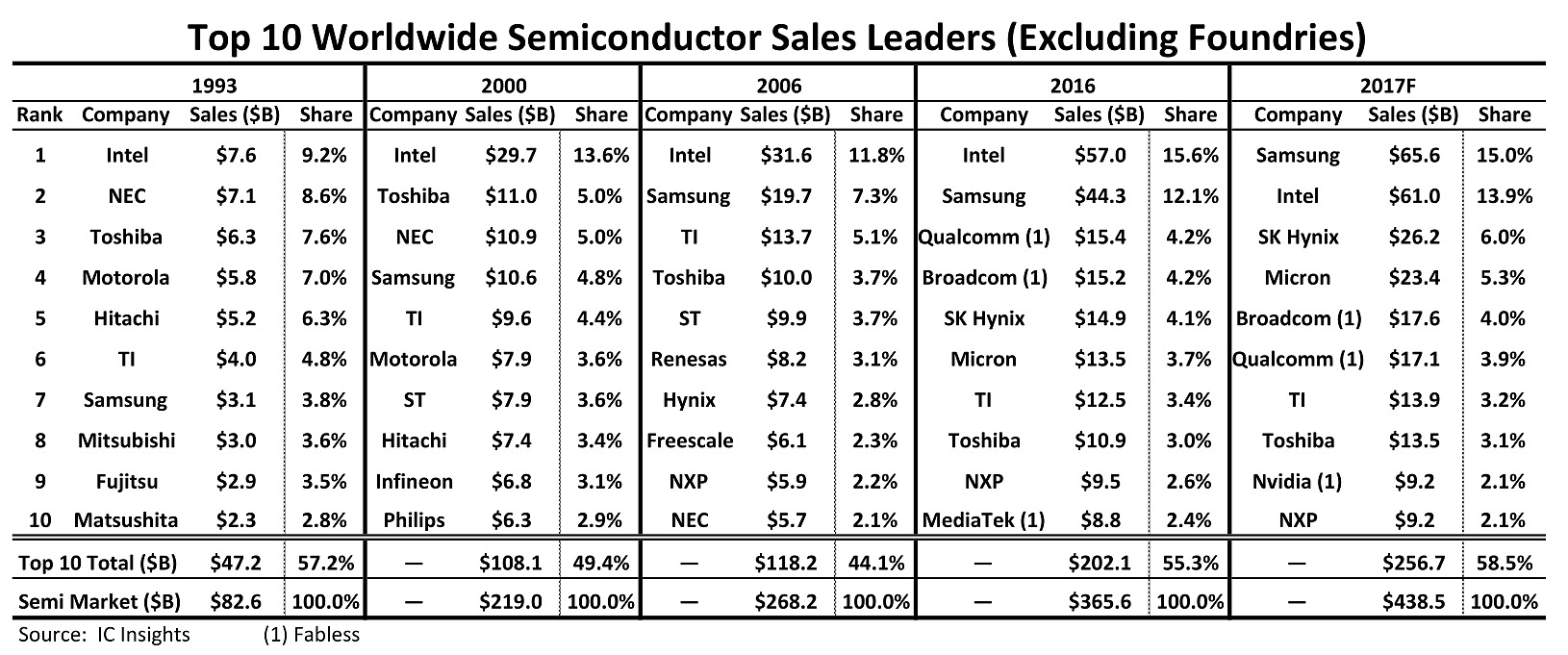
Le classement d'IC Insights se base sur les ventes de semi conducteurs des sociétés en excluant les fabs comme TSMC et GlobalFoundries.
Ces chiffres sont préliminaires, l'année n'étant pas terminée, mais sur 2017, l'ensemble du marché des semi-conducteurs devrait progresser assez fortement, d'environ 20% par rapport à 2016.
Ce sont les acteurs de la RAM/NAND qui sont principalement derrière ces gains, et pas qu'un peu puisque l'on note des progressions de ventes de 48% pour Samsung, 75.8% pour SK Hynix et 73% pour Micron ! Ces deux dernières passent pour l'occasion devant Broadcom et Qualcomm. On notera enfin que Nvidia devrait rentrer dans le top 10 cette année au dépend de MediaTek.
Apple attaque Qualcomm et réclame 1 milliard
Entre Apple et Qualcomm, le torchon brûle. Le géant américain réclame un milliard de dollars à son fournisseur, auquel il reproche des composants facturés à des tarifs trop élevés, et le non-respect d'une remise que Qualcomm avait pourtant consentie à Apple.
Pour expliquer le pourquoi de ces plaintes, il convient de s'attarder sur les soucis d'ordre judiciaire auxquels Qualcomm est actuellement confronté. Début 2015, la Chine a infligé une amende de près de 975 millions de dollars à la marque, sans que celle-ci n'y trouve à redire. Fin décembre dernier, c'est au tour de la Korea Fair Trade Commission (Corée du Sud) de pénaliser Qualcomm, à hauteur de 850 millions de dollars. Et le 17 janvier dernier, la Federal Trade Commission (FTC) américaine a, elle aussi, attaqué la firme. A chaque fois, ce sont les mêmes arguments qui sont avancés : Qualcomm exercerait des pratiques anticoncurrentielles.
Ce qui est reproché au fournisseur, c'est un abus de position dominante généré par des contrats imposés aux fabricants de smartphones et liant l'utilisation de licences et d'approvisionnement de puces.

D'après ces différentes enquêtes, Qualcomm aurait abusivement utilisé son portefeuille de brevets comme levier commercial. La marque dispose en effet de brevets essentiels pour l'utilisation des réseaux mobiles dans les smartphones, et même une entreprise de renom comme Apple a été contrainte de négocier.
C'est ainsi que, de 2011 à 2016, le géant de Cupertino a accordé une exclusivité à Qualcomm quant à la fourniture de puces modem. En échange, ce dernier avait consenti une ristourne sur les tarifs d'utilisation des brevets.
Cette réduction, Qualcomm ne l'a jamais appliquée, la firme reprochant à Apple d'avoir participé à l'enquête menée par la Korea Fair Trade Commission en Corée du Sud.
Quoi qu'il en soit, cette exclusivité a empêché toute concurrence de s'exercer sur les appareils de la firme à la pomme.
La Commission Européenne travaille sur un dossier similaire, puisqu'elle reproche à Qualcomm d'avoir tenté d'évincer Icera du marché (entre 2009 et 2011) en vendant à perte ses puces, et en versant illégalement des sommes pour s'assurer l'exclusivité auprès d'un constructeur dont le nom n'a pas été dévoilé. Le Japon et Taïwan ont également ouvert des enquêtes concernant les pratiques de Qualcomm.
Abus de position dominante
En s'assurant de réduire ainsi à peau de chagrin la concurrence (Freescale, NXP, Infineon, Texas Instruments, Renesas Electronics ou STMicroelectronics en ont fait les frais, Nvidia -qui avait racheté Icera-, Broadcom ou Marvell ne sont jamais parvenus à percer), Qualcomm aurait alors été en mesure de renverser la machine avec de nouveaux accords. Puisqu'il devenait le premier fournisseur du marché (66% de parts de marché en 2014, 59% en 2015, largement devant Mediatek), il pouvait n'accepter de fournir ses puces qu'à la condition que les constructeurs acceptent de payer le prix fort pour l'utilisation de ses licences.

Enfin, cette position dominante permettait à Qualcomm de vendre ses puces à un tarif supérieur à celui du marché. Ce sont ces tarifs qu'Apple met également en avant dans sa plainte.
Qualcomm se défend trop tard ?
De son côté, Qualcomm a décidé de faire appel quant à la décision du régulateur coréen et dit vouloir contester "avec vigueur" l'accusation de la FTC américaine, dont elle estime qu'elle est « erroné, ne repose sur aucune base économique et s'appuie sur une mauvaise compréhension de l'industrie mobile. »
Mais les relations entre le fournisseur et les fabricants de smartphones semblent s'être considérablement détériorées depuis le début de ces enquêtes, et la réaction d'Apple n'est que le symbole d'un mouvement d'émancipation de plusieurs constructeurs vis à vis de Qualcomm.
MediaTek, bien sûr, mais aussi Intel sont ainsi en train de récupérer certains des marchés auparavant réservés à Qualcomm, tandis que Samsung a commencé à produire ses propres puces pour équiper ses smartphones. Et les chinois Spreadtrum, HiSilicon et Leadcore arrivent sur le marché pleins d'ambition. Résultat : à la fin du premier semestre 2016, Qualcomm devait "se contenter" de 50% du marché des modems cellulaires. Un chiffre qui pourrait encore baisser à l'avenir.
Hot Chips : M1, SVE, Parker, InFo et Skylake !
La conférence Hot Chips qui se tenait la semaine dernière a donné lieu a d'autres annonces intéressantes que nous avons essayé de regrouper dans cette actualité !
Rajouter des tiers de mémoire côté serveur
On avait déjà noté un peu plus tôt la volonté de rajouter de la mémoire HBM à divers endroits, et même la volonté de Samsung de travailler sur une version moins onéreuse, mais l'on rajoutera ce slide issu d'une présentation d'AMD qui rappelle les objectifs de la société côté serveurs, prenant pour le coup l'exemple du big data
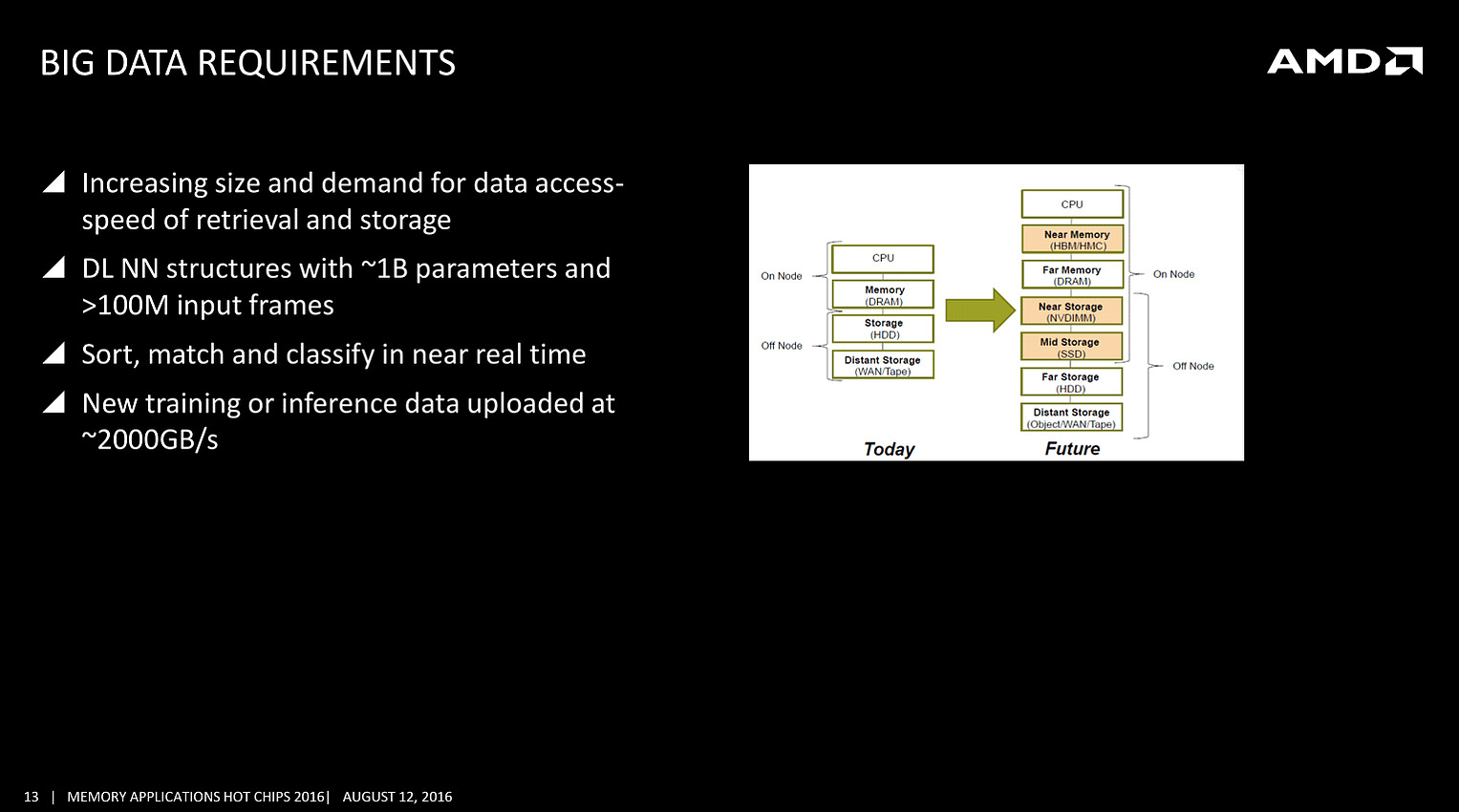
On s'attardera sur le graphique à droite qui pointe l'ajout d'une mémoire intermédiaire côté CPU, type HBM ou HMC (AMD misera plutôt sur la HBM pour les déclinaisons serveurs de Zen), et aussi l'utilisation de NVDIMM pour s'intercaler avant un SSD. Il faudra attendre encore un peu pour voir comment seront déclinées ces technologies, mais il est intéressant de noter la manière dont les avancées côté mémoire sont mises en avant, parfois un peu trop tôt comme l'a fait Intel avec 3D XPoint, dans toute l'industrie.
Quelques détails de plus sur SVE
Chez ARM, outre une présentation de Bifrost côté GPU dont on vous avait déjà parlé, l'annonce principale concernait SVE, la nouvelle extension vectorielle introduite par la société.
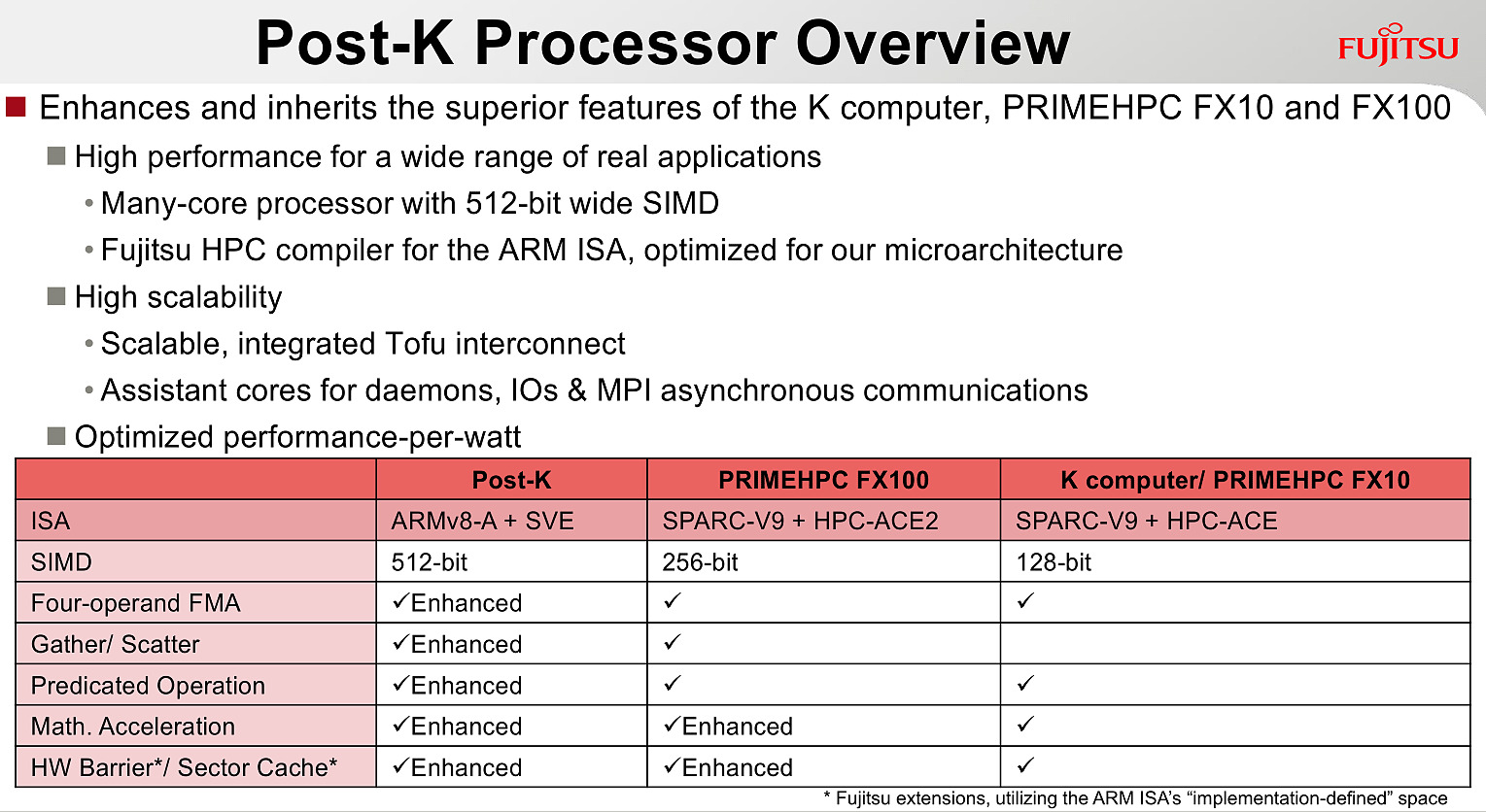
Le premier partenaire annoncé par ARM est Fujitsu, qui mettra au point des processeurs ARMv8 avec extension SVE pour le futur supercalculateur japonais Post-K. Fujitsu a donné quelques détails, indiquant par exemple que les unités vectorielles auraient une largeur de 512 bits sur ses puces.


Chez ARM, le constructeur présente plusieurs benchmarks assez théoriques, on notera surtout sur les barres grises les améliorations qui ont été effectuées côté auto-vectorisation, c'est a dire la capacité du compilateur à utiliser des instructions vectorielles pour extraire du parallélisme. ARM devrait proposer dans les semaines qui viennent des patchs pour les différents compilateurs open source, incluant LLVM et GCC.
Le Samsung M1, un timide premier pas
La particularité de l'écosystème d'ARM est que les partenaires peuvent soit utiliser des coeurs "clefs en main", développés par ARM (les gammes Cortex, comme par exemple le Cortex A57), ou créer leurs propres implémentations de l'architecture ARM (qui restent compatibles, tout en étant différentes, à l'image des processeurs d'AMD et d'Intel qui diffèrent bien que restant compatibles). Plusieurs sociétés disposent de licences "architecture" qui permettent de créer ces puces, Apple étant jusqu'ici la société la plus à la pointe sur armv8 même si de nombreuses sociétés proposent tour à tour leurs architectures.

Parmi les nouveaux venus, il y a Samsung qui s'est lancé lui aussi dans le design d'une architecture armv8 custom pour ses Exynos M1. A la tête du projet, on retrouve Brad Burgess qui était architecte chez AMD pour les Bobcat. Il aura même été rejoint un court instant par Jim Keller (K8 chez AMD, A7 chez Apple, puis Zen chez AMD), qui n'est cependant pas resté très longtemps chez Samsung et qui n'aura probablement pas eu un grand impact. Le projet aura nécessité trois années, et en soit arriver a produire quoique ce soit du premier coup en un temps si court est un exploit.
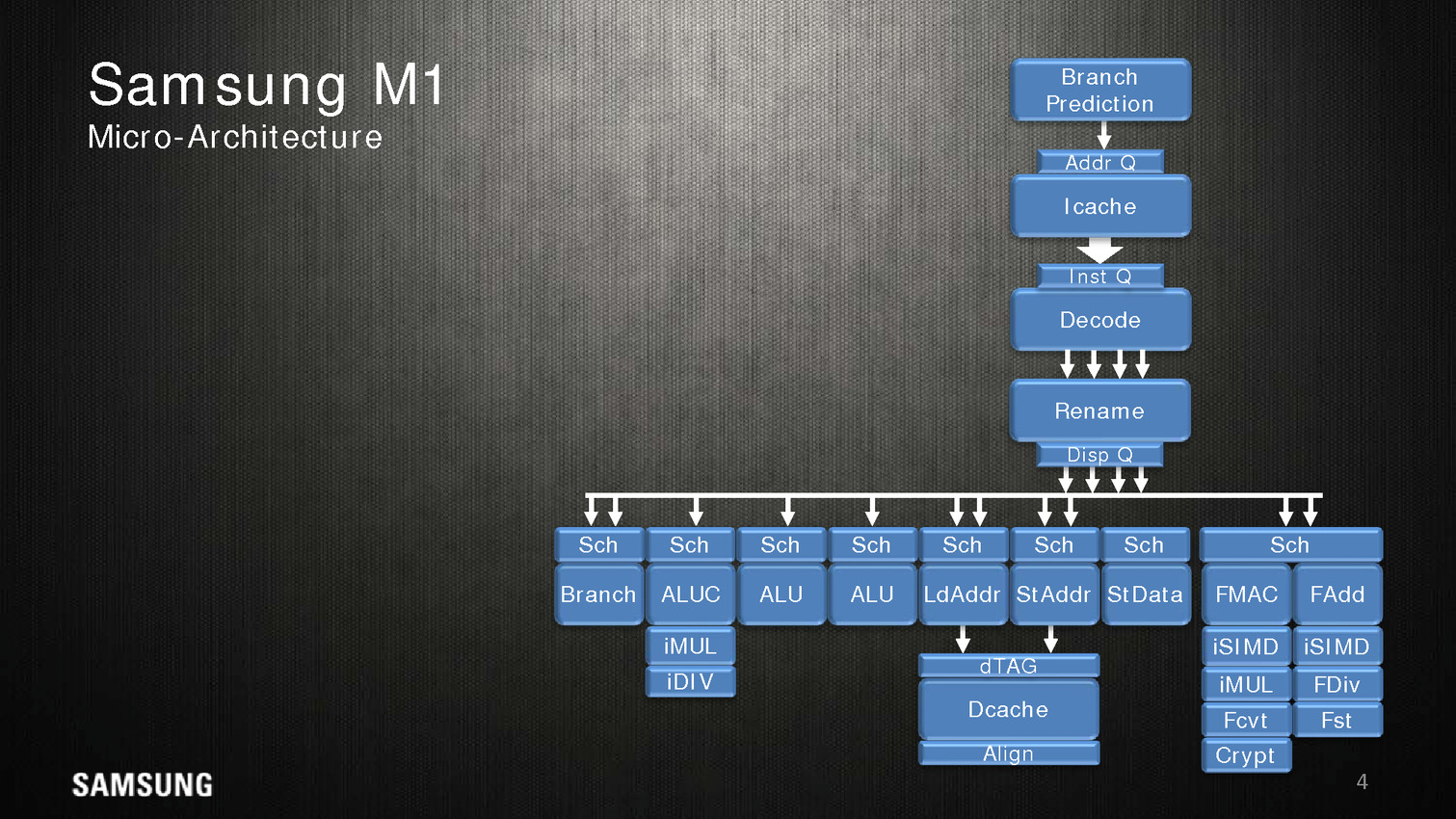
Côté architecture, Samsung indique utiliser un perceptron (un réseau de neurones simple) au niveau de ses mécanismes de prédiction de branches. Deux branches sont considérées par cycle, mais il est difficile d'estimer quoique ce soit sur l'éventuelle efficacité.
Quatre instructions peuvent être décodées/dispatchées par cycle aux unités d'exécutions qui sont regroupées sur sept files. On note deux files dédiées aux écritures mémoires, trois aux opérations mathématiques simple (avec un port sur lequel sont ajoutés les multiplications/divisions) et une aux branchements. Les opérations en virgules flottantes sont regroupées séparément avec un scheduler unique pour deux files. Samsung annonce 5 cycles pour effectuer une opération FMA.
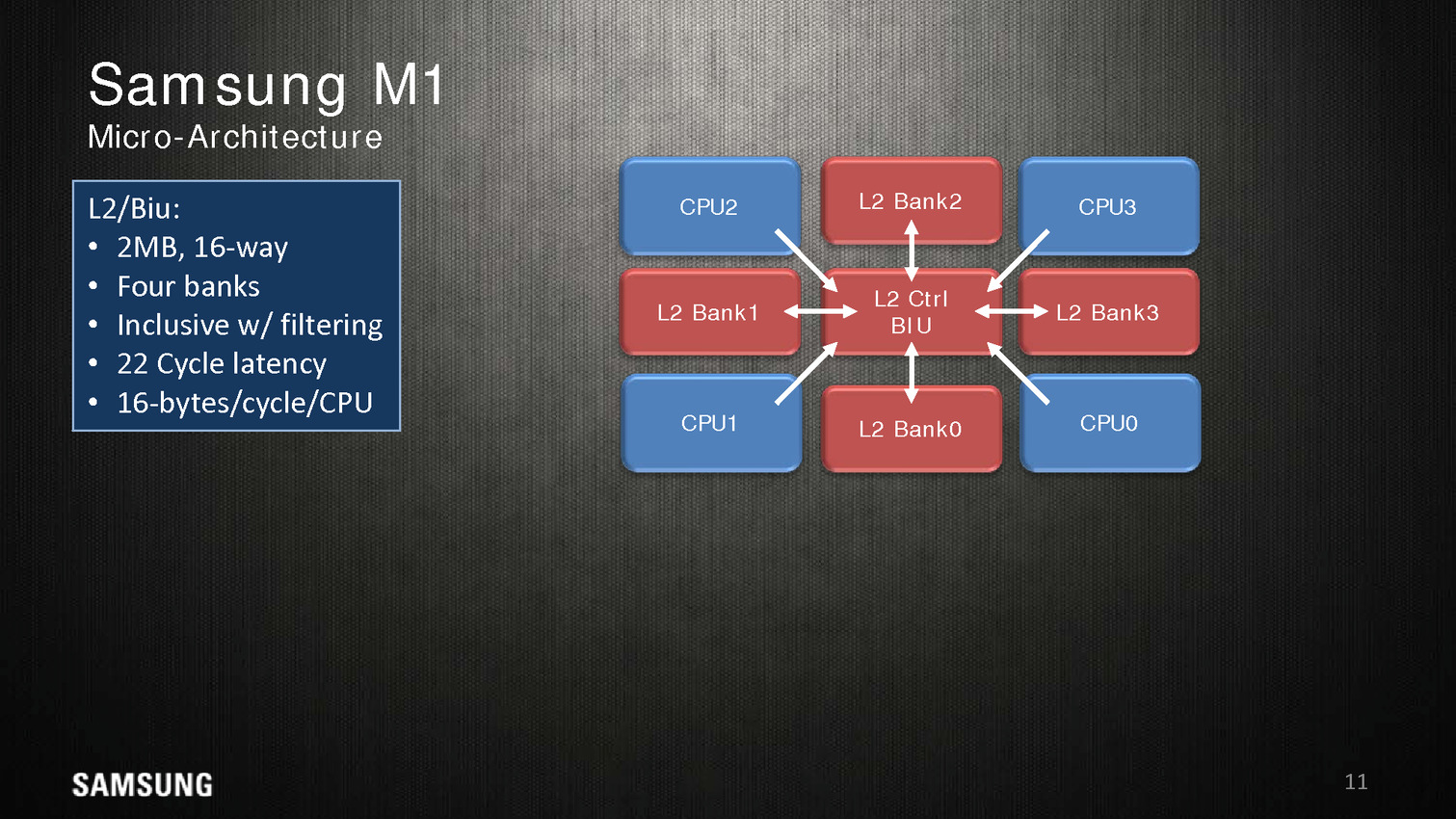
Dans une configuration quatre coeurs, le M1 dispose de 2 Mo de cache L2 coupé en quatre blocs, les coeurs accèdent au L2 via une interface commune. On appréciera aussi les schémas très spécifiques que propose Samsung, pas vraiment avare de détails techniques.

Reste qu'en pratique, les benchmarks mis en avant par Samsung ne sont pas forcément très convaincants. Avec 200 MHz de plus, sur un coeur, un M1 propose 10% de performances en plus qu'un Cortex A57 à consommation égale, ce qui est tout de même très peu. Samsung fait beaucoup mieux sur les opérations mémoires (c'est relativement facile, on l'a évoqué de nombreuses fois, les contrôleurs mémoires ARM ne sont pas particulièrement véloces/adaptés aux hautes performances), mais n'en tire pas particulièrement profit hors des benchmarks théoriques.
La présentation se termine en indiquant que ce n'est qu'un premier pas pour Samsung et que d'autres designs sont en cours d'élaboration. En soit si les performances ne vont pas révolutionner le monde des SoC ARM, Samsung a au moins une base de travail qu'ils pourront faire évoluer par la suite. A condition évidemment que Samsung continue d'investir sur le sujet dans les années à venir !
Les curieux pourront retrouver la présentation en intégralité ci dessous :














Parker/Denver 2 : design asymétrique
Nvidia était également présent à Hot Chips, donnant quelques détails sur son futur SoC baptisé Parker. Ce dernier est annoncé comme crée spécifiquement pour le marché automobile avec des fonctionnalités dédiées à ce marché. On ne sait pas si le constructeur le déclinera en d'autres versions plus génériques.

Les détails techniques ne sont pas particulièrement nombreux, on notera côté SoC que l'encodage 4K est désormais accéléré à 60 FPS, que l'on peut contrôler jusque trois écrans en simultanée, et que le contrôleur mémoire passe sur 128 bits (contre 64 précédemment). Côté GPU, Parker utilisera une version dérivée de son architecture Pascal.



C'est du côté CPU que les choses sont les plus originales, après avoir utilisé son architecture Denver sur les TK1, puis être revenu aux Cortex A57 sur les TX1, Nvidia propose une architecture asymétrique avec deux coeurs "Denver 2" (sur lesquels aucun détail n'aura été donné, à part un gain performance/watts de 30% donné sans précision sur les process comparés) et quatre coeurs Cortex A57. Ce n'est pas la première fois que l'on voit des configurations originales, durant Hot Chips, le taiwannais MediaTek présentait un SoC 10 coeurs avec quatre coeurs Cortex A53 à 1.4 GHz, quatre coeurs Cortex A53 à 2 GHz, et deux coeurs Cortex A72 à 2.5 GHz !
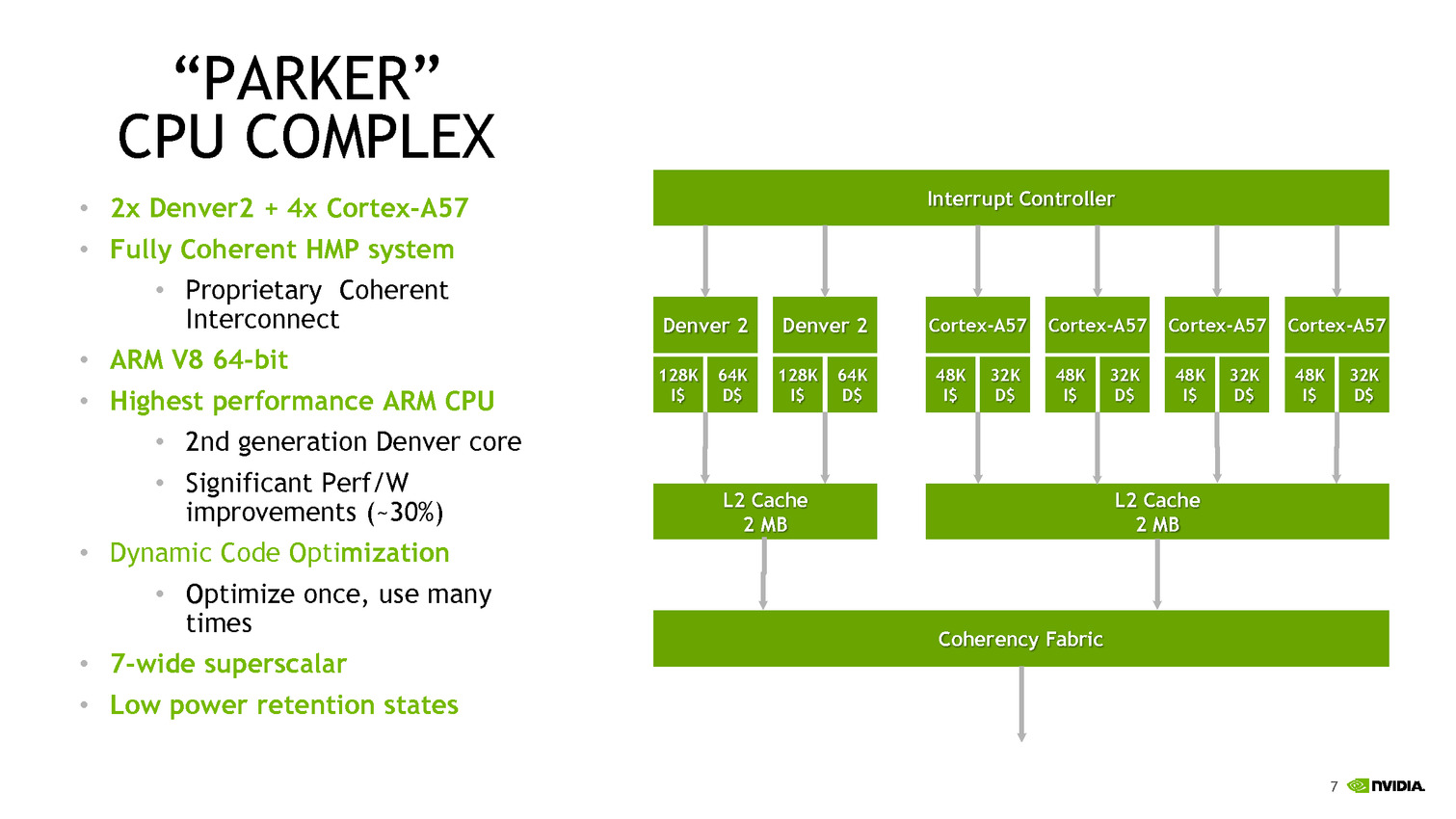
Dans le cas de MediaTek, l'idée est de proposer différentes options à différents niveaux de consommation. Pour ce qui est de Nvidia, le choix est différent, le Cortex A57 étant "haute performance" contrairement aux A53 de MediaTek. Il faut dire surtout que le marché visé, l'automobile, n'a pas les mêmes contraintes de consommation que le marché mobile. Reste que Nvidia se doit de gérer cette asymétrie avec un scheduler qui doit décider sur quel coeur placer les threads, ce qui n'est pas particulièrement simple. On notera que chaque groupe de coeurs dispose de son propre cache L2 de 2 Mo.
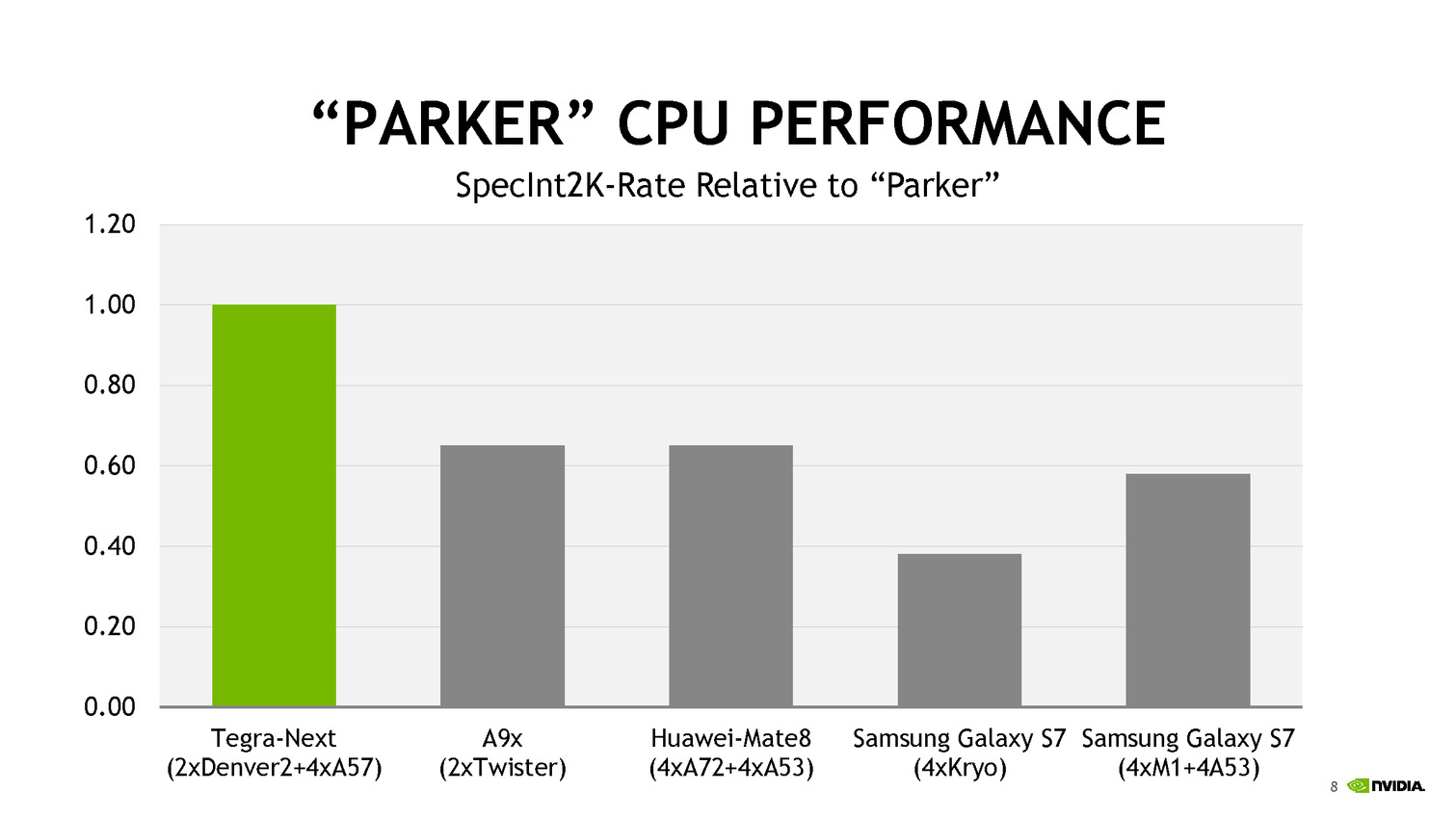
Côté performances, Nvidia avec ses 6 coeurs se présente comme moitié plus rapide qu'un A9X d'Apple en deux coeurs. Le graphique mélangeant des puces à TDP différents (on y retrouve des puces pour smartphones et pour tablettes), on admettra que la comparaison n'est pas faite à TDP identique.
TSMC parle de ses packages InFo
Une des nouveautés présentées cette année par TSMC est la disponibilité d'un nouveau type de packaging, l'InFo-WLP. L'idée est de permettre de relier plusieurs dies en les "moulant" dans un substrat commun très fin qui contient également les interconnexions entre les puces. Il s'agit d'une version à cout beaucoup plus faible que les interposer (utilisés par exemple par AMD pour Fiji).
La présentation de TSMC est dédiée aux interconnexions entre les puces, et présente une puce 16nm reliant un SOC à une puce mémoire avec une bande passante de 89.6 Go/s sur 256 bits, le tout avec une consommation très réduite.
En plus de la solution présentée qui évoque le cas simple d'une puce mémoire et d'un Soc, TSMC évoque la solution comme permettant un jour de relier également plusieurs dies de logique, par exemple des groupes de coeurs séparés, pour réduire le coût de fabrication des puces (qui augmentent exponentiellement avec la taille des dies).
































La présentation est technique mais reste intéressante, l'InFo-WLP ouvre des opportunités supplémentaires pour réaliser des produits qui mélangent processeur et mémoire. Le coût réduit et la finesse de l'interconnexion fait qu'on pourrait retrouver assez rapidement cette technique utilisée, y compris sur le marché mobile. Les prochains SoC d'Apple pourraient par exemple utiliser un tel package.
Et Skylake !
Juste avant la présentation de Zen, Intel proposait aussi une présentation de son architecture Skylake, lancée l'année dernière. Si la majorité du contenu est déjà connu, on aura noté un détail intéressant : un diagramme sur les unités d'exécution de Skylake. On rappellera que l'année dernière durant l'IDF, Intel nous avait promis plus de détails sur le sujet, sans jamais nous les donner !
Pour rappel, voici la répartition sur Haswell :
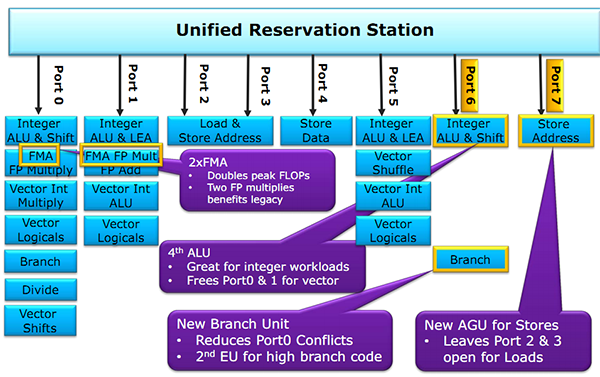
Récapitulatif des ports/unités d'exécution sur Haswell
Un an après, voici enfin un diagramme similaire pour Skylake :
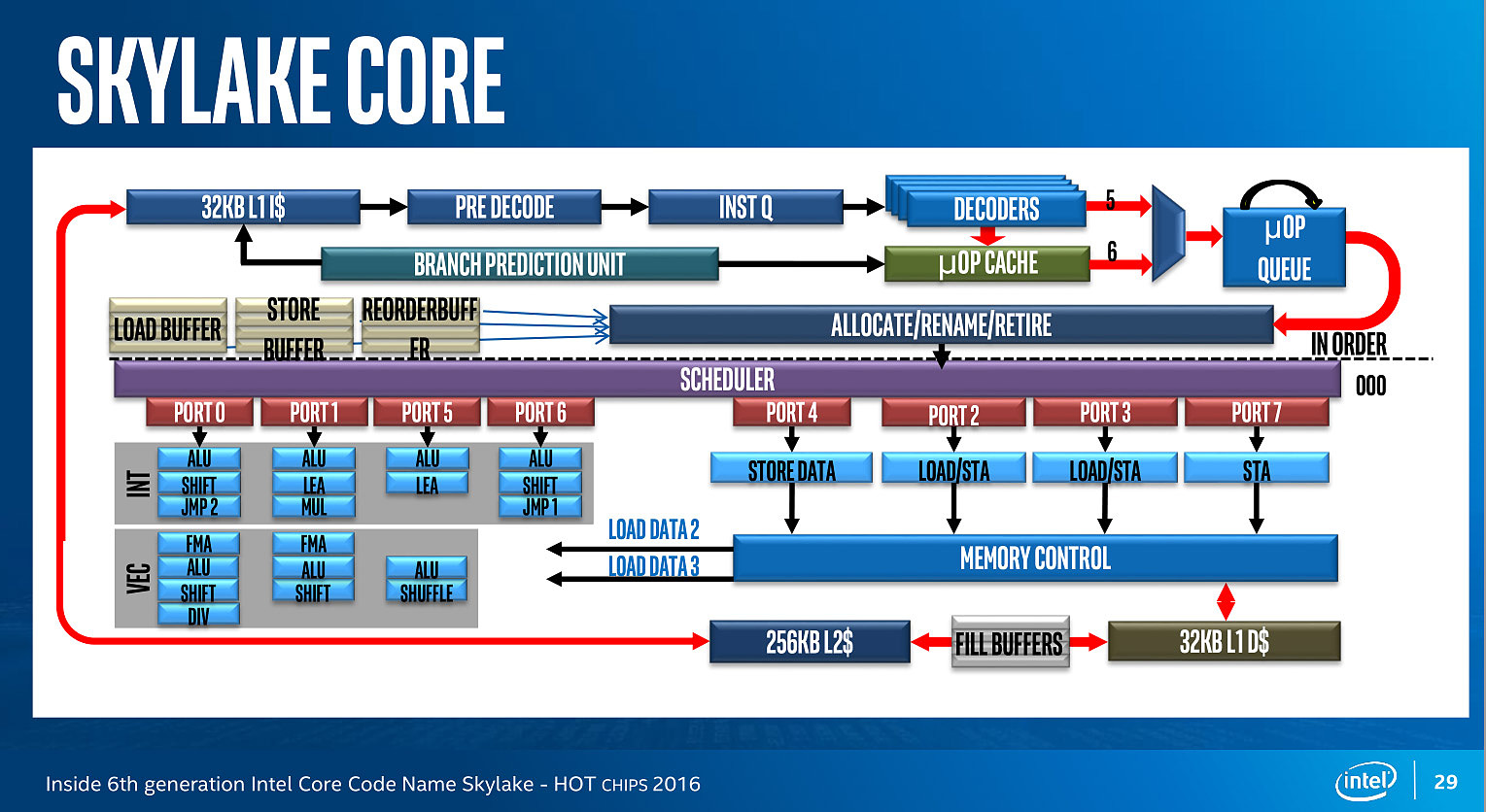
Conformément à ce que nous avaient indiqué les ingénieurs d'Intel l'année dernière, le nombre d'unité a bel et bien augmenté. Le nombre de ports reste constant, à 8, mais l'on compte... une nouvelle unité. Sur le port 1, Intel a en effet ajouté une unité de shift vectorielle. Pour le reste, la répartition reste similaire à celle d'Haswell. Un mystère enfin élucidé !
AMD continue de gagner des parts de marché GPU
Mercury Research vient de publier ses derniers chiffres (format PDF) concernant les ventes de GPU sur le second trimestre.
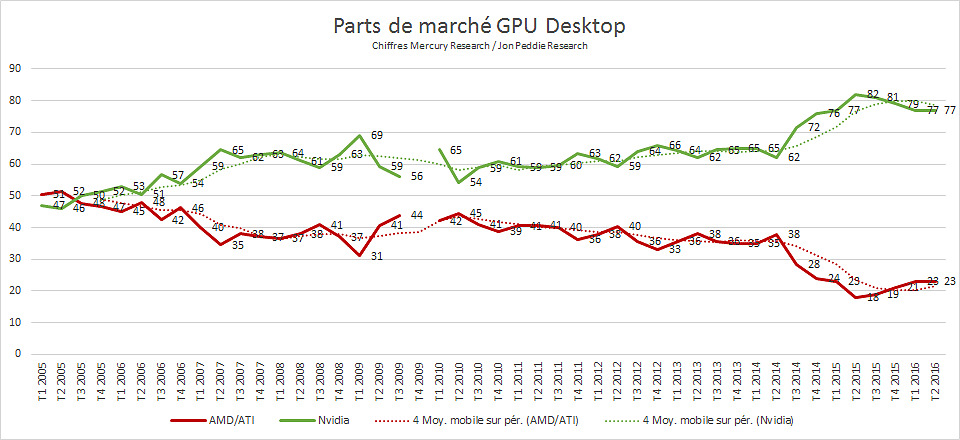
Du côté des GPU desktop, les changements sont restreints puisque AMD passe seulement de 22.7 à 22.8% de parts de marché, pas de quoi compenser le déclin qui avait commencé au troisième trimestre 2014.
En ce qui concerne le marché des GPU additionnels mobiles, là aussi AMD note un gain, passant de 35.9% sur le trimestre précédent à 36.4%. Si l'on considère la totalité du marché GPU, Intel baisse très légèrement (pour la première fois depuis 10 ans selon la firme) passant de 71.7% au trimestre précédent à 71.5%. Nvidia passe de 16.3% à 16.1% tandis qu'AMD progresse de 11.8% à 12.3%. A l'inverse d'Intel, c'est la première fois qu'AMD inverse sa courbe de baisse depuis le premier trimestre 2012. On peut tout de même tempérer cela en rappelant qu'au second trimestre 2015, AMD disposait de 14% de parts de marché GPU global.
Côté tendances, le marché global du GPU reste à la baisse avec -3.1% de ventes par rapport à la même période l'année dernière, et -6.5% séquentiellement en nombres d'unités. Sur les GPU desktop, la baisse par rapport au trimestre précédent a atteint un impressionnant -20%, majoritairement lié à un inventaire important chez les distributeurs, concernant principalement Nvidia.
Le constructeur a compensé cela par l'arrivée de ses références haut de gamme, Mercury Research remarquant que le prix de vente moyen des GPU desktop a atteint sur ce trimestre un nouveau record.
Dossier : Les solutions de streaming : Streaming local Steam et Nvidia GameStream en test
Aujourd'hui, les solutions de streaming local pour profiter de la performance de son PC et de ses jeux dans son salon se multiplient. Que valent ces solutions ? Quelles concessions imposent-elles ?
[+] Lire la suite
