
Les derniers contenus liés aux tags Nvidia et Maxwell
Afficher sous forme de : Titre | FluxLes GTX 900 supportent-elles correctement DirectX 12 ?
Dossier: Nvidia GeForce GTX 950, MSI Gaming et Inno3D iChill Ultra en test : Maxwell 2 passe sous 200
Computex: Nvidia: pas besoin de watercooling, ni de HBM
Dossier: Nvidia GeForce GTX 980 Ti 6 Go : la petite soeur de la Titan X en test
Dossier: Nvidia GeForce GTX Titan X 12 Go et GM200 en test: big Maxwell débarque !

GDC: Nvidia parle du Tile Caching de Maxwell et Pascal



En parallèle de la GDC et lors de la présentation à la presse de la GeForce GTX 1080 Ti, Nvidia a communiqué officiellement pour la première fois au sujet d'une optimisation introduite depuis les GPU Maxwell : le Tile Caching.
Cet été, David Kanter de real world technologies avait mis en évidence un comportement étrange pour les GPU Maxwell et Pascal. Avec ceux-ci, la rastérisation de plusieurs triangles progressait par blocs plus ou moins petits de l'image (appelés tiles en anglais) et non pas strictement triangle par triangle. Contrairement à certaines analyses, nous étions alors sceptiques par rapport au rapprochement qui était fait avec le tile based rendering (TBR) ou tile based deffered rendering (TBDR) des GPU mobiles Adreno, Mali ou PowerVR. Ces modes de rendu sont peu efficaces avec une géométrie complexe et posent problème avec certaines techniques de rendu avancées. Des contraintes qui sont incompatibles avec un GPU haut de gamme destiné au PC. Nous estimions alors qu'il s'agissait d'une optimisation opportuniste spécifique à certaines situations.
Face à ces discussions et à l'introduction par AMD d'une approche similaire, voire identique, Nvidia vient de clarifier le fonctionnement de la rastérisation sur ses GPU Maxwell et Pascal. Ce qui commence par lui donner un nom : le Tile Caching.
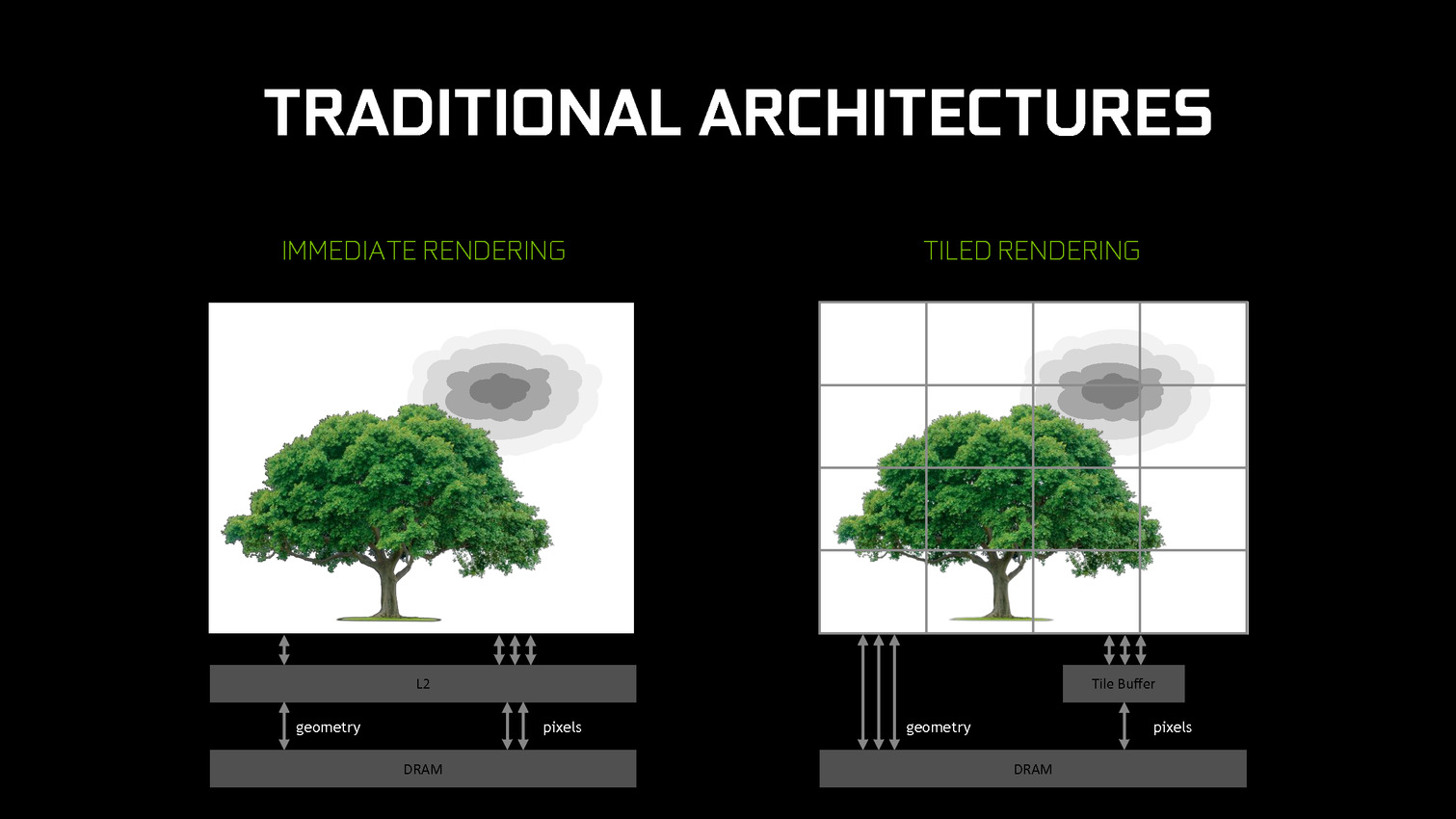
Traditionnellement, les GPU d'AMD et de Nvidia fonctionnent suivant le principe du rendu immédiat. Un triangle est pris en charge, il est découpé en pixels, les pixels sont écrits en mémoire. Si un second triangle traité par la suite se trouve entre le premier et la caméra, des pixels auront inutilement été calculés et écrits en mémoire. Différentes approches sont utilisées pour éviter ce gaspillage de ressources, mais il reste en partie présent.
De leur côté, les GPU mobiles font appel au TBR/TBDR qui fonctionne en deux passes. La première consiste à traiter toute la géométrie et à la récrire en mémoire en la réorganisant de manière à savoir quels triangles sont présents chaque bloc de l'image. Lors d'une seconde passe, ces triangles sont envoyés vers le moteur de rastérisation tile par tile (avec tri de visibilité dans le cas du TBDR). La construction de l'image dans de petites tiles en cache fait que les pixels ne seront écrits qu'une seule fois en mémoire. Cela revient à utiliser plus de bande passante pour la géométrie mais moins pour les pixels. Un compromis dont l'intérêt dépend évidemment du ratio entre la charge sur ces deux points.
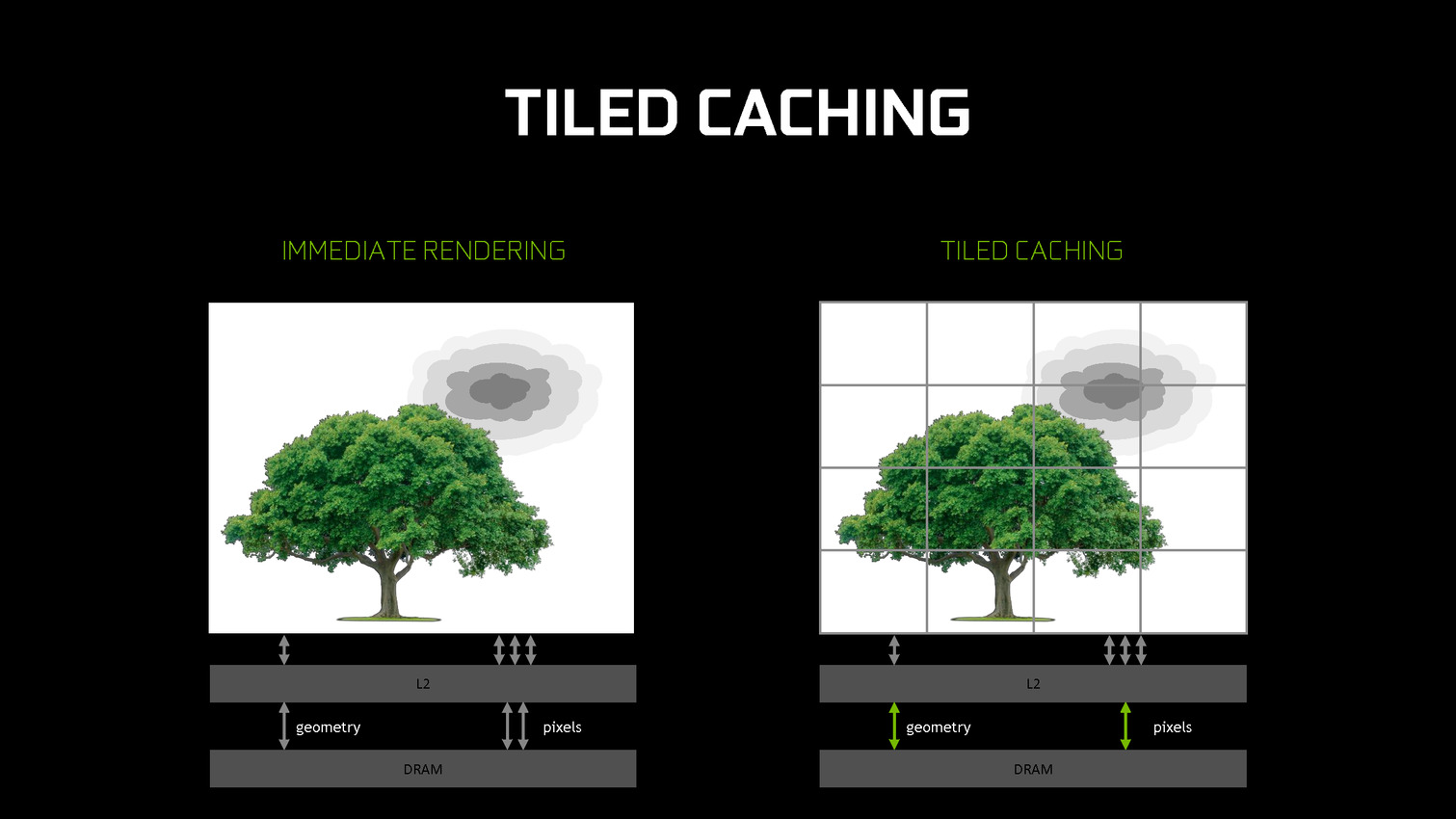
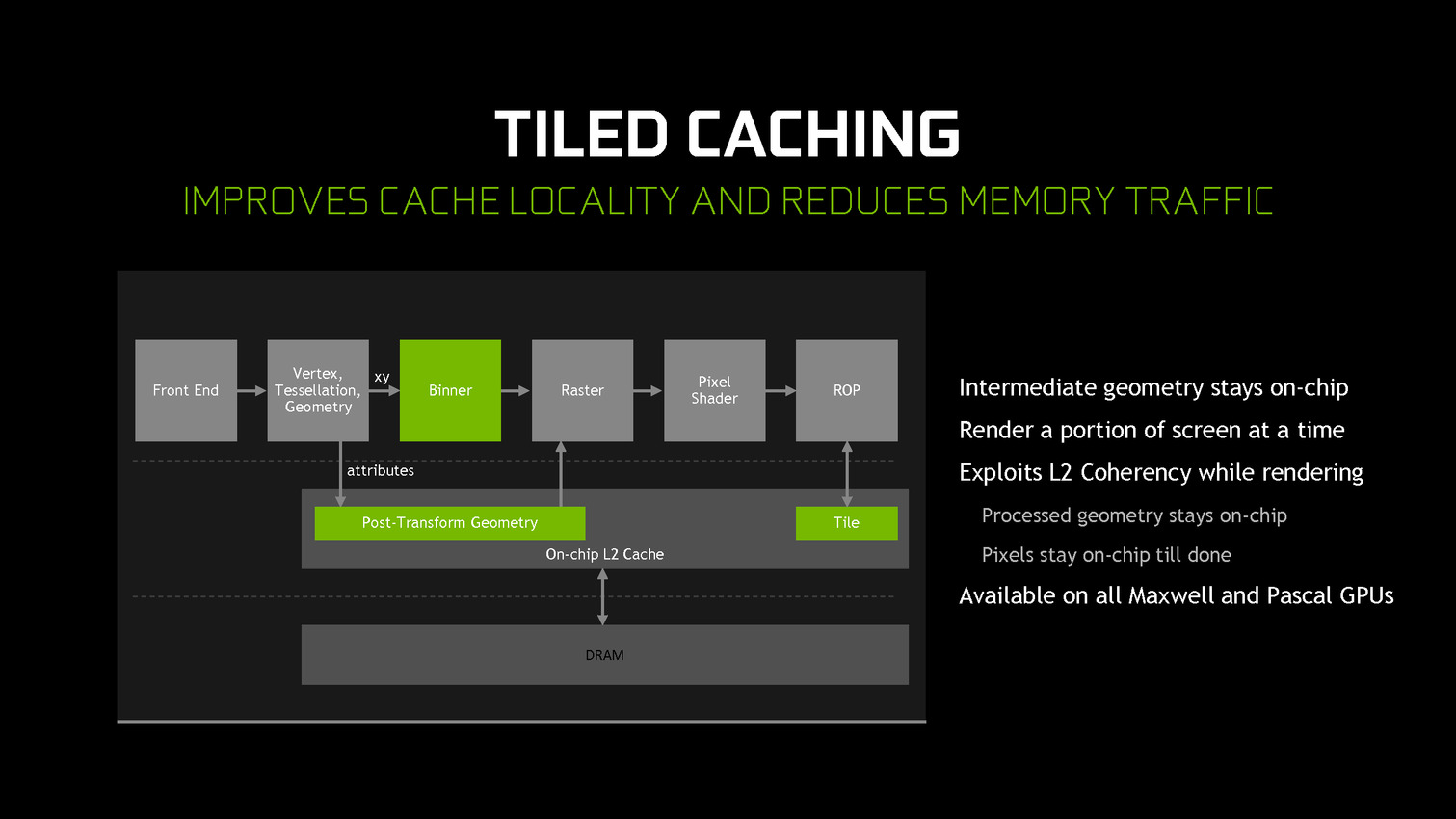
A partir des GPU Maxwell, Nvidia a cherché à pouvoir bénéficier d'une partie des avantages de cette seconde approche sans perdre la flexibilité du rendu immédiat. C'est le Tile Caching qui peut être vu comme un "rendu avec rastérisation retardée". Une fois un triangle traité, au lieu de l'envoyer vers le moteur de rastérisation, Nvidia le conserve en cache interne, ainsi que tous ses paramètres. Quand ce cache est rempli, la rastérisation peut débuter. Grossièrement, il s'agit d'interrompre le rendu et d'attendre d'avoir un plus d'informations (mais pas toutes) avant de le poursuivre plus efficacement.
Une petite unité fixe supplémentaire, appelée binner, se charge de suivre la position et la couverture de chaque triangle en cache. Quand le temps de leur rastérisation est arrivé, parmi ces quelques triangles, le GPU sait lesquels seront assurément et totalement masqués. L'inverse n'est par contre pas vrai puisque, contrairement au TBR/TBDR, tous les triangles n'ont pas été traités en amont, juste quelques-uns. Il s'agit d'une optimisation localisée et opportuniste plus que d'un changement de philosophie global pour ces GPU.
Cette approche permet de traiter la rastérisation par tile et non pas par triangle. Il y a un surcoût au niveau de la rastérisation (même si Nvidia profite probablement de son moteur de projection multiple pour le limiter) mais ces tiles peuvent rester en cache. Elles ne sont alors écrites en mémoire que quand que tous les triangles en cache et qui y sont visibles ont été traités. Contrairement au TBR/TBDR, ces tiles seront réécrites en mémoire plusieurs fois lorsque d'autres morceaux de géométrie qui les parcourent seront traités.
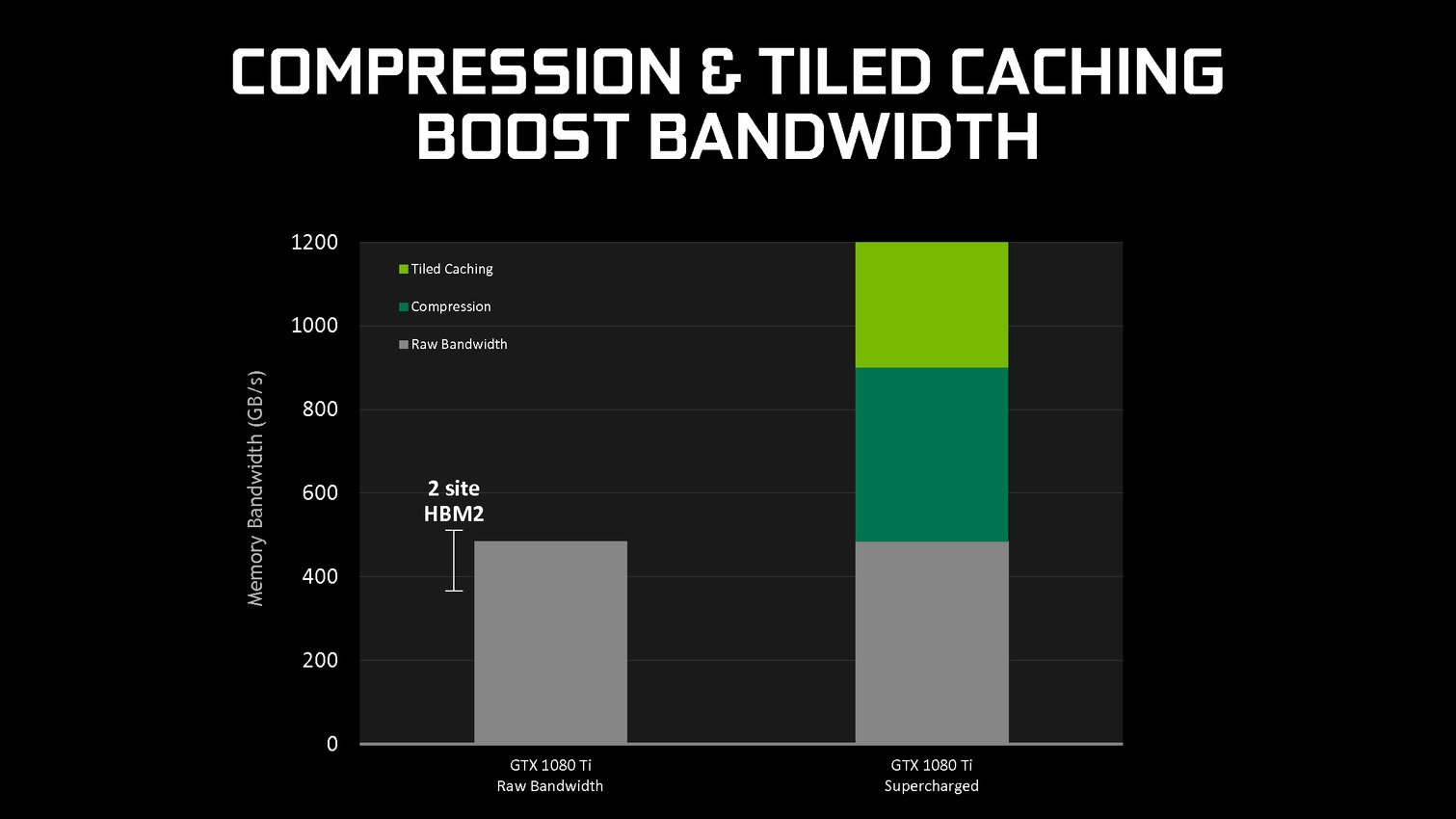
Nvidia nous précise qu'aucun cache spécifique n'a été implémenté et que c'est le cache L2 qui est exploité. C'est la raison pour laquelle il a fait un bond énorme en taille à partir des GPU Maxwell (1 voire 2 Mo par 128-bit de bus contre 256 Ko sur Kepler). Un système d'optimisation automatique à base d'heuristiques a été mis en place pour opter pour la taille la plus adaptée au niveau du buffer de triangle et des tiles, mais Nvidia peut configurer tout cela manuellement pour chaque jeu ou débrayer le Tile Caching s'il est contreproductif.
En se contentant de chercher des opportunités d'optimisation locales, par morceau de géométrie, Nvidia parvient à obtenir des gains sympathiques, certes inférieurs à ceux obtenus par une architecture purement TBR/TBDR, mais qui permettent de conserver plus de flexibilité et de performances dans un maximum de situations. C'est un des piliers de l'excellente efficacité des GPU Maxwell et Pascal. Cela fait également partie d'une stratégie réfléchie qui consiste à chercher à créer de la valeur au niveau de ses propres puces plutôt que via l'exploitation d'une mémoire plus onéreuse (bus 512-bit, HBM ).
Tile rendering pour Maxwell et Pascal ?
David Kanter de real world technologies nous a indiqué ce matin avoir publié une analyse intéressante concernant les GPU Maxwell et Pascal de Nvidia. Un test ciblé a permis de mettre en évidence une progression de la rastérisation de plusieurs triangles par blocs plus ou moins petits de l'image (appelés tiles) en opposition à un rendu classique pour les GPU de bureau qui consiste à traiter le rendu d'un triangle sur toute l'image avant de passer au suivant.
De quoi pouvoir faire un rapprochement avec le tile based rendered ou le tiled based deffered renderer des GPU mobiles Adreno, Mali ou PowerVR ? Il y a trop peu d'informations pour y répondre avec certitude, mais en l'état actuel des choses notre interprétation diverge quelque peu de celle de notre confrère. Nous pensons donc que ce n'est pas le cas, une telle approche généralisée aurait d'ailleurs peu de sens, ces types de rendu ayant tendance à être contreproductifs avec l'augmentation de la complexité géométrique, ce qui est justement un point fort des GPU Nvidia.
Tous les GPU fonctionnent à un niveau ou à un autre sur des tiles, ne serait-ce que pour harmoniser les accès mémoire et pouvoir mettre en place des techniques de compression. Le terme tiles est cependant souvent source de confusion puisqu'il peut ne pas avoir de lien avec ce qui est généralement compris quand on parle de tiled based rendering, à savoir un rendu en deux passes avec un tri de la géométrie après transformation pour lier chaque primitive à une ou plusieurs tiles. De quoi pouvoir effectuer le rendu sur de petits blocs qui resteront en cache durant toutes les opérations pour n'être écrits en mémoire qu'une seule fois en toute fin. Pour en savoir plus sur les différents modes de rendu, nous vous invitons à consulter cette actualité : GDC: Architecture GPU : IMR, TBR ou TBDR ?
Alors que se passe-t-il avec les GPU Maxwell et Pascal ? Nous pensons que ce qu'a mis en lumière David Kanter est plutôt une optimisation opportuniste par exemple pour le traitement des gros triangles, et peut-être d'autres cas, et non un rendu à base de tiles comme on l'entend en général et qui implique un tri des primitives au préalable. Tous les GPU Nvidia depuis Fermi doivent d'ailleurs travailler sur des tiles avec les gros triangles puisqu'ils doivent être segmentés pour être traités par plusieurs GPC et donc par plusieurs moteurs de rastérisation. Progressivement Nvidia en a probablement profité pour apporter quelques optimisations.
Nous supposons qu'avec de gros triangles, dont la couverture représente une partie importante de l'image, les GPU Nvidia récents font en sorte d'éviter de devoir écrire d'emblée en mémoire une quantité énorme de pixels dont une partie pourrait s'avérer par la suite être masquée et donc inutile, ce qui représenterait un gaspillage de bande passante et d'énergie. Etant donné que ces gros triangles sont en principe peu nombreux, il est relativement aisé d'en garder les données en cache ou dans une mémoire spécifique, pour les traiter par morceaux à un moment plus opportun.
Si notre supposition est correcte, cette approche peut sembler similaire à ce que l'on entend en général par tiled based rendering, mais uniquement dans des cas très particuliers, le mode de traitement de la géométrie restant fondamentalement différent. Ce type d'approche fait partie d'un ensemble de techniques qui ont permis à Nvidia d'augmenter le rendement de ses GPU, tant sur le plan énergétique que sur celui des performances en exploitant la bande passante disponible à meilleur escient.
GDC: VR: Nvidia Multi-Res Shading en pratique
Nous avons profité de la GDC pour revenir sur une technique introduite par Nvidia il y a quelques mois pour booster les performances de la réalité virtuelle. Baptisée Multi-Resolution Shading, elle consiste à réduire la résolution au niveau des zones visuelles périphériques et donc le nombre de pixels réellement rendus. Un subterfuge plutôt convainquant en pratique.




Pour pouvoir afficher une image sur un casque de réalité virtuelle, elle doit être déformée pour permettre, avec la lentille, de proposer l'angle de vue correct. Ce procédé, appelé warping et illustré ci-dessus, implique que seul le centre de l'image conserve la pleine résolution. Les zones périphériques représentent au final moins de pixels que le GPU n'en a calculés. En d'autres termes, elles reçoivent automatiquement une dose plus ou moins élevée de supersampling alors que ce n'est pas là que se pose notre regard. Un gaspillage de ressources que Nvidia tente de réduire avec le Multi-Res Shading.

La démonstration de Nvidia permet d'activer et désactiver le Multi-Res Shading à loisir, de quoi pouvoir essayer de discerner les différences éventuelles. Et force est de constater que même en ayant conscience de l'activation de cette optimisation il est difficile d'en discerner les effets. Il faut savoir exactement où regarder et déplacer le regard vers les coins de l'image (ce que nous ne sommes pas censés faire avec un casque de VR) pour observer une légère différence.
Comme vous pouvez l'observer sur les illustrations ci-dessus, Nvidia a recours à 9 viewports de résolutions différentes. Par exemple, la résolution peut être réduite à 1/2 sur les côtés et à 1/4 dans les coins. Mais si le principe est simple, l'exécution est un peu plus complexe et profite du multi-projection engine des GPU Maxwell 2 pour projeter rapidement, en une seule passe, tous les triangles dans chacun des 9 viewports. Sans cette capacité matérielle (également exploitée pour le VXGI et le VXAO), le coût sur les performances serait important à prohibitif suivant la complexité de la scène. AMD nous a d'ailleurs confirmé que cette technique n'était pas réaliste pour ses GPU, tout en précisant essayer d'obtenir un résultat similaire via d'autres approches.
Le Multi-Res Shasing est proposé par Nvidia aux développeurs à travers le SDK VR Works mais a également été implémenté dans l'Unreal Engine il y a quelques mois et, à l'occasion de la GDC, Unity a suivi le mouvement en annonçant son intégration, avec le reste de la suite VR de Nvidia.
GDC: Async Compute : ce qu'en dit Nvidia
Nous avons bien entendu profité de la GDC pour questionner Nvidia en vue d'en apprendre plus sur ce dont sont capables ses GPU en terme de prise en charge du multi engine de DirectX 12 sans réel succès ?
Au coeur de DirectX 12, cette fonctionnalité permet de décomposer le rendu en plusieurs files de commandes, qui peuvent être de type copy, compute ou graphics, et de gérer la synchronisation entre ces files. De quoi permettre aux développeurs de prendre le contrôle sur l'ordre dans lequel les tâches sont exécutées ou encore de piloter directement le multi-GPU. Cette décomposition permet également dans certains cas de profiter de la capacité des GPU à traiter plusieurs tâches en parallèle pour booster les performances.

Illustration du Multi Engine de DirectX 12, qui permet de traiter plusieurs files de commandes en parallèle.
C'est ce qu'AMD appelle Async Compute, bien que le terme ne soit pas correct. En effet, l'exécution asynchrone d'une tâche n'implique pas qu'elle soit traitée en concomitance d'une autre, or c'est ce dernier point qui est crucial et permet un gain de performances. Les GPU AMD profitent de multiples processeurs de commandes capables d'alimenter les unités de calcul du GPU à partir de plusieurs files différentes. Un traitement en simultané des tâches qui permet de maximiser l'utilisation de toutes les ressources du GPU : unités de calcul, bande passante mémoire etc.
Du côté de Nvidia c'est plus compliqué. Si les GeForce sont capables de prendre en charge les files copy en parallèle des files compute et graphics, traiter ces deux dernières en concomitance semble poser problème. Théoriquement les GPU Maxwell 2 (GTX 900) disposent d'un processeur de commandes capables de prendre en charge 32 files dont une peut être de type graphics. Et pourtant ce support n'est toujours pas fonctionnel en pratique, comme le démontrent par exemple les performances des GeForce dans Ashes of the Singularity.
Pourquoi ? Jusqu'ici, nous n'avons pu obtenir de réelle réponse de Nvidia. Alors bien entendu nous avons voulu profiter de la GDC pour tenter d'en savoir plus et avons questionné Nvidia lors d'un meeting organisé avec Rev Lebaredian, Senior Director GameWorks. Malheureusement pour nous, cet ingénieur qui fait partie du groupe de support technique aux développeurs de jeux vidéo avait été très bien préparé à ces questions qui concernent les spécificités du support du multi engine. Ses réponses ont au départ été mot pour mot celles de la brève déclaration officielle de Nvidia communiquée à la presse technique depuis quelques mois. A savoir "les GeForce Maxwell peuvent prendre en charge l'exécution en concomitance au niveau des SM (groupes d'unités de calcul)", "ce n'est pas encore actif dans les pilotes", "Ashes of the Singularity n'est qu'un seul jeu (pas trop important) parmi d'autres".
Une langue de bois inhabituelle qui démontre, si cela était encore nécessaire, que cette question dérange chez Nvidia. Nous avons donc changé d'approche et pour sortir de l'impasse nous avons abordé le sujet sous un angle différent : est-ce que l'Async Compute est important (pour les GPU Maxwell) ? De quoi détendre Rev Lebaredian et ouvrir la voie à une discussion bien plus intéressante. Deux arguments sont alors avancés par Nvidia.
D'une part, si Async Compute est un moyen d'augmenter les performances, ce qui compte au final ce sont les performances globales. Si les GPU GeForce sont à la base plus performants que les GPU Radeon, le recours au multi engine pour tenter de booster leurs performances n'est pas une priorité absolue.
D'autre part, si le taux d'utilisation des différents blocs des GPU GeForce est relativement élevé à la base, le gain potentiel lié à Async Compute est moins important. Nvidia précise sur ce point que globalement il y a beaucoup moins de trous (bubbles en langage GPU) au niveau de l'activité des unités de ses GPU que chez son concurrent. Or le but de l'exécution concomitante est d'exploiter une synergie dans le traitement de différentes tâches pour remplir ces "trous".
Derrière ces deux arguments avancés par Nvidia se cachent en fait celui de la bonne planification d'une architecture GPU. Intégrer dans les puces un ou des processeurs de commandes plus évolué a un coût, un coût qui peut par exemple être exploité différemment pour proposer plus d'unités de calcul et booster les performances directement et dans un maximum de jeux.

Lors du développement d'une architecture GPU, une bonne partie du travail consiste à prévoir le profil des tâches qui seront prises en charge quand les nouvelles puces seront commercialisées. L'équilibre de l'architecture entre ses différents types d'unités, entre la puissance de calcul et la bande passante mémoire, entre le débit de triangles et le débit de pixels, etc., est un point crucial qui demande une bonne visibilité, beaucoup de pragmatisme et une vision stratégique. Force est de constater que Nvidia s'en tire plutôt bien à ce niveau depuis quelques générations de GPU.
Pour illustrer cela, faisons quelques petites comparaisons entre le GM200 et Fiji sur base des résultats obtenus dans Ashes of the Singularity sans Async Compute. La comparaison est grossière et approximative (le GM200 exploité est tiré de la GTX 980 Ti qui en exploite une version légèrement castrée), mais reste intéressante :
- GM200 (GTX 980 Ti) : 6.0 fps / Gtransistors, 7.8 fps / Tflops, 142.1 fps / To/s
- Fiji (R9 Fury X) : 5.6 fps / Gtransistors, 5.8 fps / Tflops, 97.9 fps / To/s
Nous pourrions faire de même avec de nombreux jeux et le résultat serait similaire, voire encore plus marqué (AotS est particulièrement efficace sur Radeon) : le GM200 exploite mieux les ressources à sa disposition que Fiji. C'est un choix d'architecture, ce qui n'implique pas directement qu'il est meilleur qu'un autre. Augmenter le rendement de certaines unités peut avoir un coût supérieur à l'augmentation de leur nombre dans une mesure plus importante. Le travail des architectes consiste à trouver le meilleur équilibre à ce niveau.
De toute évidence, AMD a plutôt misé sur les débits bruts de ses GPU, ce qui implique en général un rendement inférieur et plus d'opportunité d'optimisation au niveau de celui-ci. Ajoutez à cela que l'organisation de l'Async Compute dans AotS semble plutôt optimiser l'utilisation du surplus de bande passante mémoire et vous comprendrez aisément qu'il y a moins à gagner du côté de Nvidia. D'autant plus que les commandes de synchronisation liées à Async Compute ont un coût qui ne sera masqué que par un gain significatif.
Si notre propre réflexion nous amène à être plutôt d'accord avec ces arguments de Nvidia, il reste un autre point important pour les joueurs et c'est probablement ce qui fait que le numéro un du GPU aborde le sujet du bout des lèvres : Async Compute apporte un gain gratuit aux utilisateurs de Radeon. Alors que cette possibilité a été prévue dans les GPU AMD depuis plus de 4 ans, ils n'ont pas pu en tirer un bénéfice commercial, ils n'ont pas été vendus plus chers pour la cause. Cela change quelque peu avec la dernière gamme d'AMD qui mise fortement sur ce point, mais, en terme de perception, les joueurs apprécient d'obtenir gratuitement un tel petit coup de boost, même s'il ne concerne qu'une poignée de jeux. A l'inverse, le rendement globalement plus élevé des GPU Nvidia a pu avoir un bénéfice immédiat dans un maximum de jeux, et a pu être pris en compte directement dans le tarif des GeForce. Et du point de vue d'une société dont le but n'est pas d'afficher des pertes, il est évident qu'une approche a plus de sens qu'une autre.
Reste que nous sommes en 2016 et que l'exploitation de l'Async Compute devrait progressivement se généraliser, notamment grâce à la similitude entre l'architecture des GPU des consoles et celle des Radeon. Nvidia ne peut donc pas totalement ignorer cette possibilité qui pourrait réduire voire supprimer son avance en termes de performances. Sans rentrer dans le moindre détail, Rev Lebaredian a ainsi tenu à réaffirmer qu'il y avait bel et bien des possibilités au niveau des pilotes pour implémenter un support qui permette de profiter dans certains cas d'un gain de performances avec l'Async Compute. Des possibilités que Nvidia réévalue en permanence, non sans oublier que ses futurs GPU pourraient changer la donne à ce niveau.
Nvidia dévoile une 'vraie' GTX 980 mobile
Une "vraie" GTX 980 dans le monde mobile ? Impossible ? C'est pourtant ce que s'apprête à commercialiser Nvidia pour équiper les plus gros portables gamers à venir.

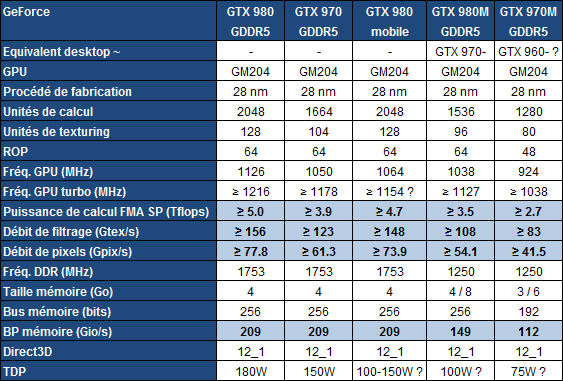
Comme nous vous l'expliquons régulièrement, les versions mobiles des cartes graphiques sont généralement très inférieures à leurs variantes desktop. Par exemple, une GeForce GTX 980M dispose de moins d'unités de calcul qu'une GTX 970 desktop et est par ailleurs nettement sous-cadencée. Une GTX 970M sera également inférieure à une GTX 960 desktop et ainsi de suite.
Cela s'explique d'une part par les contraintes thermiques du monde mobile qui rendent difficile l'intégration d'un GPU trop gourmand, et d'autre part par des commerciaux avides d'exploiter des marques bien connues pour attirer le chaland et créer de la valeur. Grossièrement, cela revient pour Nvidia à appeler GTX 980M la meilleure configuration qu'ils peuvent proposer dans une enveloppe thermique de 100W, peu importe son niveau de performances, et à profiter de l'aura de la "vraie" GTX 980, nettement plus performante.
Sans abandonner cette stratégie, qui induit malheureusement beaucoup de confusion, Nvidia s'est également demandé ce qui empêchait d'exploiter directement une "vraie" GTX 980 dans un portable. Après tout, les plus gros d'entre eux sont capables d'accueillir un SLI de GTX 980M et Intel a annoncé l'arrivée des premiers processeurs Core de série K destinés aux portables. Nvidia y a vu l'opportunité de travailler avec les fabricants pour qu'ils poussent d'un cran l'enveloppe thermique qu'ils peuvent dédier à un GPU.
De quoi cette fois pouvoir proposer une "vraie" GeForce GTX 980 dans le monde mobile. C'est à cette nouvelle déclinaison mobile que certaines rumeurs faisaient référence en tant que GTX 990M, mais le nom commercial sera au final simplement GTX 980, comme sur desktop. Par défaut, la configuration du GPU sera identique et il en ira de même pour les 4 Go de GDDR5 et leur fréquence de 1750 MHz. Seule la fréquence GPU est légèrement réduite, mais pourra être relevée par les fabricants au niveau de la GTX 980 desktop, c'était le cas lors d'une démonstration à laquelle nous avons pu assister.
Nvidia a par contre refusé de répondre à toute question liée aux limites de températures et de consommation, deux points pourtant cruciaux qui définiront les performances réelles de cette GTX 980 mobile. Pour rappel, une GTX 980 desktop de référence a une limite de consommation de 180W et une limite de température de 80 °C. Dès que l'une d'elle est atteinte, la fréquence GPU est réduite (throttling) pour ne pas la dépasser, ce qui définit donc les performances.
Qu'en est-il pour la GTX 980 mobile ? Nvidia propose probablement à ses partenaires une large plage de limites de consommation. Peut-être de 100W à 180W, qu'ils adapteront suivant les capacités de refroidissement de leur châssis, avec potentiellement des écarts importants au niveau des performances. A noter qu'en pratique le système de refroidissement de la GTX 980 desktop de référence ne peut encaisser que de 150 à 165W suivant l'environnement et le boîtier, au-delà de quoi la température maximale est atteinte après une brève période de jeu. Une limite de consommation inférieure à 180W pour la GTX 980 mobile n'implique donc pas directement un déficit de performances par rapport à la version desktop, d'autant plus que Nvidia indique avoir sélectionné les meilleurs puces, soit les moins gourmandes.
Au niveau de la température, cela devrait par contre être différent. Lors d'une brève démonstration, et seulement quelques secondes après que le présentateur nous ait affirmé le contraire , nous avons pu apercevoir une température GPU de 84 °C. Nvidia a donc probablement relevé la limite de température de 80 à 85°C pour ne pas trop brider cette GTX 980 mobile. Par ailleurs, Nvidia explique avoir prévu un nouveau mécanisme de modification de la vitesse du ventilateur via un offset qui décale l'ensemble de la courbe vers le haut. De quoi permettre de réduire la baisse de fréquence facilement, mais au prix de nuisances sonores en hausse.

Ce paramètre sera disponible à côté des autres destinés à l'overclocking, à savoir les fréquences GPU et mémoire. Il sera possible d'atteindre des résultats similaires à ceux obtenus sur desktop, soit plus de 1400 MHz pour la fréquence GPU maximale. Il sera par contre plus compliqué de maintenir celle-ci en jeu compte tenu des limites thermiques qui ne pourront pas être modifiées, contrairement à ce qui est possible sur desktop.
A noter que dans un sens, la GeForce GTX 980 mobile est similaire à une Radeon R9 Nano. Elle consiste à essayer de placer une "grosse" carte graphique dans un format plus compact avec des contraintes thermiques plus fortes, en profitant de mécanismes de réduction automatique de la fréquence et de la tension GPU pour éviter tout débordement. Dans les deux cas c'est une niche particulière qui est visée, d'un côté les très gros portables gamers, d'un autre les plus petits PC mini-ITX.
Pour l'heure, Aorus (X7 DT), Asus (GX700VO), Clevo (P870DM, P775DM) et MSI (GT72, GT80) ont répondu présents à l'appel de Nvidia et proposeront sous peu cette nouvelle référence mobile, systèmatiquement en combinaison avec un Skylake K mobile et une dalle G-Sync 1080p. A noter qu'Asus aura recours à une base qui fait office de système de watercooling et que MSI prévoit la possibilité d'un SLI de GTX 980 dans un format 18.4". Attendez-vous à une tarification à la hauteur de la domination de Nvidia face à une concurrence d'AMD à peu près inexistante sur le marché mobile.


















